spark 2.x和spark 1.x在dataframe语法上有一个重要区别:Dataframe/Dataset在使用map、mapPartitions等转换函数时需要指定Encoder,如下所示:
df.mapPartitions(new BinaryRowDecodeIterator(_, schema))(RowEncoder(schema))
细心的同事点开spark源码,看到的mapPartitions函数定义如下:
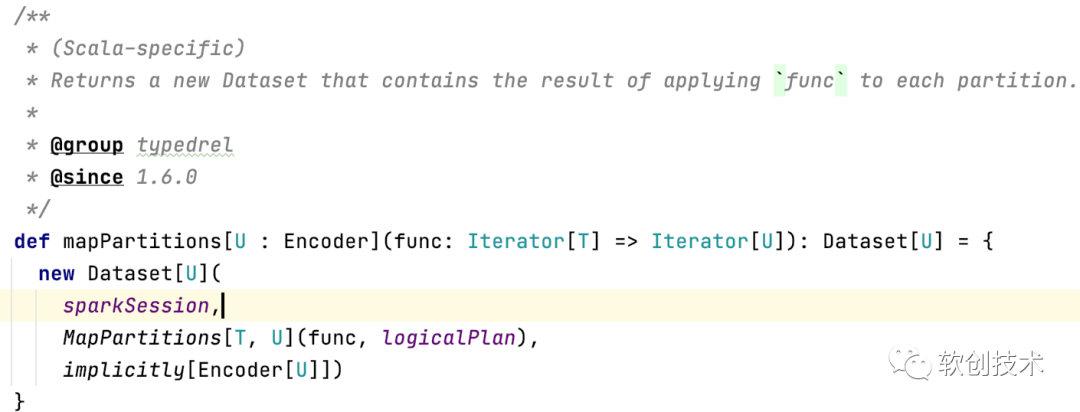
从上述的定义来看,mapPartitions方法其实只有一个形参,那为啥在调用该方法时,如果我们只传递一个function参数就会抛出如下的异常呢?

这是因为mapPartitions方法定义时,使用了scala上下文界定语法。
Scala上下文界定语法
上下文界定语法形式为[U:M],其中:M是一个泛型类。上下文界定语法要求上下文中要存在类型为M[U]的隐式变量,或者说在调用mapPartitions时就要传递第二个参数。
下面给出的案例,是对Person对象进行排序,然后返回排序结果中的第一个Person对象:
// 定义一个pojo类,作为容器的元素;
// Person本身是不带排序规则的;
class Person(var position: Int, var age: Int) {
override def toString: String = s"position is:${position};age is :${age}"
}
object ContextBounds extends App {
// 定义一个带有上下文界定的方法;它用来从输入的集合中获取职位最高,年纪最大的人;
def getMaxValue[T: Ordering](data: List[T]): T = {
data.sorted
data.head
}
// 初始化集合数据;
val data = List(new Person(1, 72), new Person(1, 69), new Person(2, 70))
// 定义一个隐式变量,这样就不用去在调用上述方法时,就可以将比较的规则隐式的带进去;
// scala 中的Ordering对标java中的Comparator;
implicit object PersonOrdering extends Ordering[Person] {
override def compare(p1: Person, p2: Person): Int = {
if(p1.position<p2.position){
1
}else{
if(p1.age>p1.age){
1
}else{
-1
}
}
}
}
// 显示的定义一个Ordering[Person]对象,作为第一个参数传给方法;
val customOrdering = new Ordering[Person] {
override def compare(x: Person, y: Person): Int = {
if (x.position < y.position) {
1
} else {
if (x.age > y.age) {
1
} else {
-1
}
}
}
}
// 显示赋予排序规则;
println(getMaxValue(data)(customOrdering))
// 在scala在编译不过去的情况下,就会寻找隐式变量,如果依然编译不过,才会提示;
println(getMaxValue(data))
}
总结


文章评论