 文章:Python爬虫与数据挖掘
文章:Python爬虫与数据挖掘
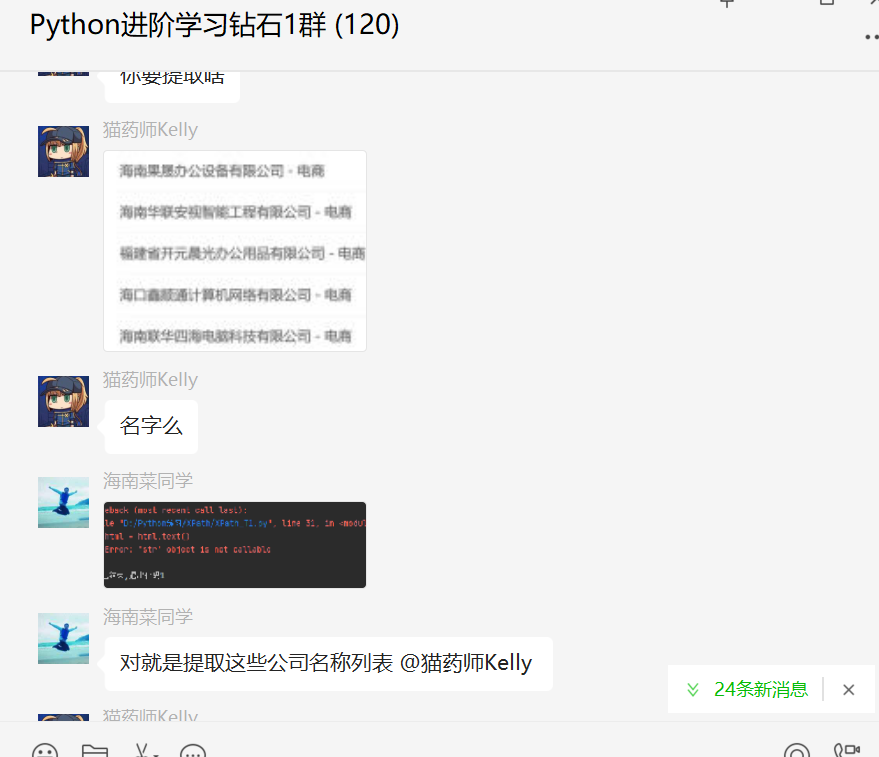
前几天在Python钻石交流群【海南菜同学】问了一个Python网络爬虫的选择器提取问题,下图是截图:
from lxml import etreeimport requestsurl = "http://zw.hainan.gov.cn/wssc/emalls.html"headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}html = requests.get(url,headers=headers)html = html.content.decode('utf-8')doc = etree.HTML(html)res = doc.xpath('/html/body/div[5]/ul/text()')print('*-*--'*20)for item in res: print(type(item)) print(item[0])
print('*-*--'*20)
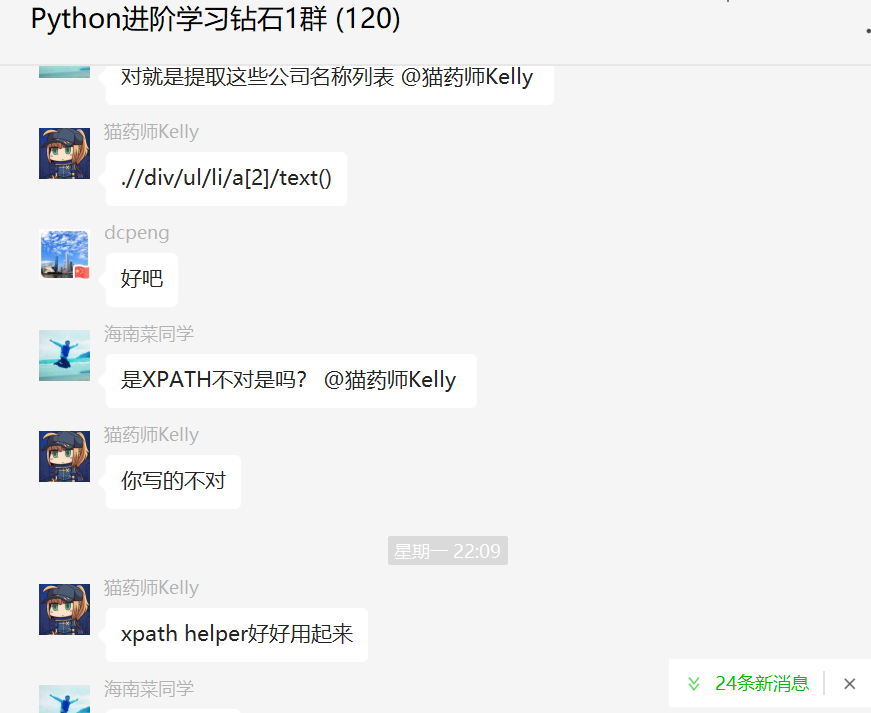
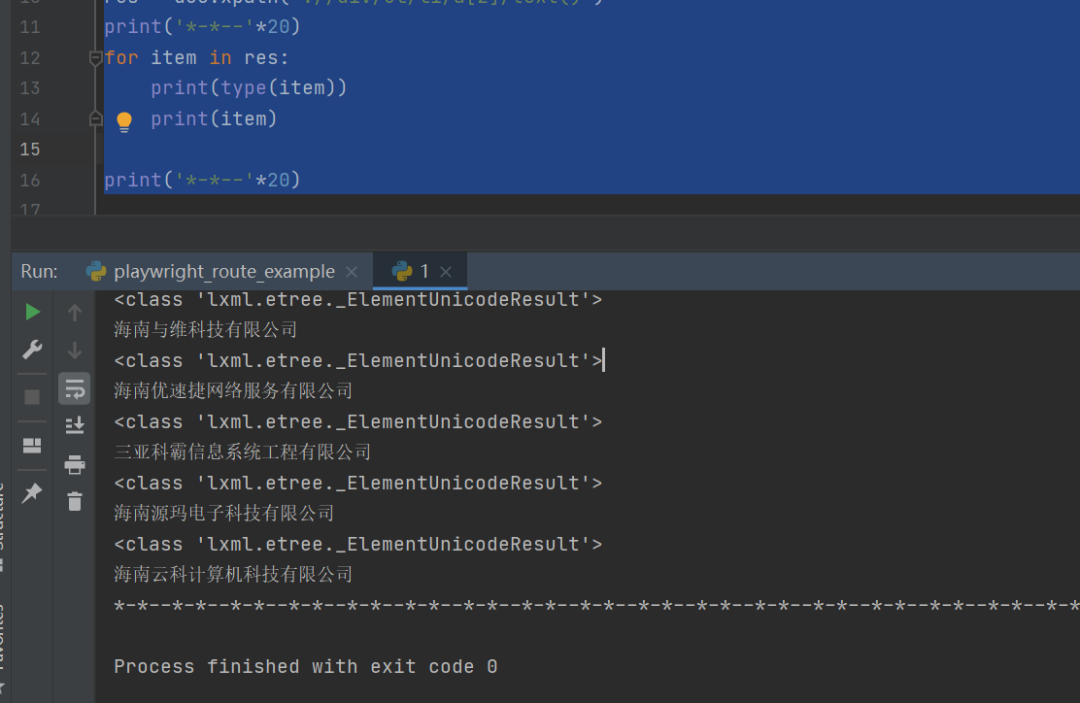
from lxml import etreeimport requestsurl = "http://zw.hainan.gov.cn/wssc/emalls.html"headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}html = requests.get(url,headers=headers)html = html.content.decode('utf-8')doc = etree.HTML(html)res = doc.xpath('.//div/ul/li/a[2]/text()')print('*-*--'*20)for item in res: print(type(item)) print(item)
print('*-*--'*20)
- 合作、交流、转载请添加微信 moonhmily1 -
 文章:Python爬虫与数据挖掘
文章:Python爬虫与数据挖掘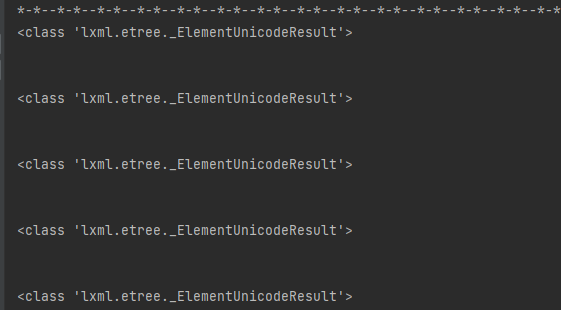

文章评论