在人工智能时代,一款AI产品成功与否的终极衡量标准是能在多大程度上提高我们生活的效率。随着AI技术从云端向边缘发展,需要优化的工程问题将更为复杂。为了产品最终的成功,在芯片设计之前有效的评估变得越来越重要。然而由于AI芯片应用场景纷繁复杂的属性,所以行业内需要正确的且具有专业知识的评估工具。
AI行业的难题之一:
AI芯片跟不上算法的速度
早在2019年斯坦福大学就有报告指出,AI对算力需求的速度要快于芯片的发展速度。“在 2012年之前,AI的发展与摩尔定律的遵循度极高,计算能力每两年翻一番,但2012年之后,AI的计算能力每3.4个月就翻一番。”
当通用处理器算力跟不上 AI 应用的需求,针对 AI 计算的专用处理器便诞生了,也就是常说的“AI 芯片”。自2015年AI算法在视觉识别方面超越人类分数,业界对AI芯片关注度大增,也因此带动了相关IP技术的发展,加快了下一代处理器和存储器的速度,实现了更高的带宽接口,从而紧紧跟上AI算法的步伐。图1显示了自2012年引入反向传播和现代神经网络,并与NVIDIA的重型计算 GPU 引擎相结合后,AI典型错误率呈现肉眼可见的降低。
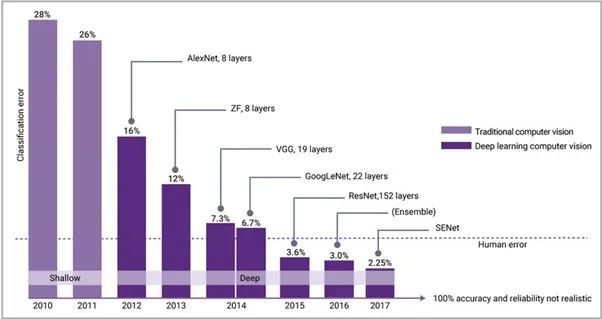
图 1:在 2012 年引入现代神经网络后,AI分类错误迅速减少,2015年起低于人类错误率
随着AI 算法日益复杂,无法在专为消费类产品设计的 SoC 上执行,需要使用修剪、量化等技术对齐进行压缩,从而减少系统需要的内存和计算量,但这样就会影响准确性。所以工程上面临一个挑战:如何实施压缩技术而不影响AI应用所需的精度?
除了AI算法复杂性的提升之外,由于输入数据的增加,推理所需的数据量也急剧增长。图 2 显示了优化后的视觉算法所需的内存和计算量。该算法设计为相对较小的 6MB 内存占用空间(SSD-MobileNet-V1 的内存要求)。在这个特定示例中,我们可以看到,随着像素大小和颜色深度的增加,最新的图像捕获中的内存要求已从 5MB 增加到 400MB 以上。
目前最新的三星手机CMOS图像传感器摄像头支持高达108MP。理论上,这些摄像头在30fps和超过1.3GB 内存下可能需要40 TOPS的性能。但ISP中的技术以及 AI 算法中特定的区域,无法满足这些要求,40 TOPS性能尚无法在手机上实现。但通过此示例能看出边缘设备的复杂性和挑战,并且也正在推动传感器接口IP的发展。MIPI CSI-2 具有专门的区域来解决这个问题,MIPI C/D-PHY 继续增加带宽,以处理驱动数亿像素的最新 CMOS 图像传感器数据。
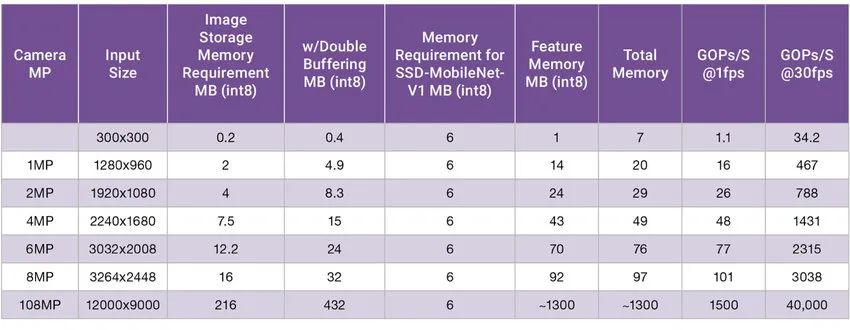
图 2:随着输入像素增大,SSD-MobileNet-V1 的内存变化测试
如今的解决方案就是压缩AI算法,压缩图像,这就使得芯片优化变得极其复杂,尤其是对于内存有限、处理量有限且功耗预算较小的 SoC。
AI行业难题二:AI芯片评估面临挑战
AI芯片厂商通常对会其芯片进行一些基准测试。现在的SoC有多种不同的衡量指标。首先,每秒万亿次运算 (TOPS) 是性能的一个主要指标,通过这项数据可以更清楚地了解芯片能力,例如芯片可以处理的运算类型和质量。再者,每秒推理数也是一个主要指标,但需要了解频率和其他参数。因此,行业内开发了额外的基准测试来帮忙AI 芯片进行评估。
MLPerf/ML Commons和AI.benchmark.com都是AI芯片标准化基准测试的工具。其中,ML Commons 主要提供芯片精度、速度和效率相关的测量规则,这对了解芯片处理不同 AI 算法的能力非常重要,如前所述,在不了解精度目标的情况下,我们是无法在芯片进度与压缩程度之间做取舍的。此外,ML Commons还提供通用数据集和最佳实践。
位于瑞士苏黎世的 Computer Vision Lab 还提供移动处理器的基准测试,并发布其结果和芯片要求以及支持重复使用的其它信息。包括 78 项测试和超过180 个性能方面的基准。
斯坦福大学的DAWNBench为ML Commons的工作提供了支持。这些测试不仅能解决 AI 性能评分问题,还解决了处理器执行 AI 算法训练和推理的总时间问题。这解决了芯片设计工程目标的一个关键问题,即降低整体拥有成本或总拥有成本。AI 处理时间,决定了云端 AI 租赁或边缘计算的芯片所有权,对于组织的整体 AI 芯片策略更有用。
另一种流行的基准测试方法,是利用常见的开源图形和模型,但这些模型也有一些弊端。例如,ResNET-50 的数据集为 256x256,但这不一定是最终应用中可能使用的分辨率。其次,该模型较旧,层数少于许多较新模型。第三,模型可以由处理器 IP 供应商手动优化,但这并不代表系统将如何与其他模型一起执行。除了ResNET-50之外,还有大量可用的开源模型,通过它们可以看到该领域的最新进展,并为性能提供良好的指标。
最后,针对特定应用的定制图形和模型变得越来越普遍。理想情况下,这是对 AI 芯片进行基准测试,以及合理优化以降低功耗和提高性能的最佳方案。
由于SoC开发者各有不同的目标,有些是应用于高性能领域,有的是用于较低性能的领域,还有的是通用AI领域,以及ASIC领域。对于不知道需要按照哪种 AI 模型进行优化的 SoC,自定义模型和开放可用模型的良好组合,可以很好地指示性能和功耗。这种组合在当今市场中最常用。然而,在 SoC 进入市场后,上述较新的基准测试标准的出现,似乎在比较中具有一定的相关性。
边缘AI芯片设计之前的评估尤为重要
现在越来越多的数据计算在边缘发生,鉴于边缘优化的复杂性,当今的 AI 解决方案必须协同设计软件和芯片。为此,它们必须利用正确的基准测试技术,同时还必须有工具支持,从而使设计人员能够准确探索系统、SoC 或半导体 IP 的不同优化方式,调查工艺节点、存储器、处理器、接口等。
在这方面,新思科技可针对特定领域提供有效的工具,来对 IP、SoC 和更广泛的系统进行模拟、原型验证和基准测试。
首先,新思科技HAPS® 原型验证解决方案通常用于展示不同处理器配置的能力和权衡。该工具能够检测出除了处理器之外, AI 系统的带宽在什么情况下开始成为瓶颈?传感器输入(通过 MIPI)或存储器访问(通过 LPDDR)在处理不同任务时的最佳带宽是多少?
再一个,新思科技ZeBu® 仿真系统可用于功率模拟。ZeBu Empower可采用AI、5G、数据中心和移动SoC应用的真实软件工作负载,在数小时内完成功耗验证周期。此仿真系统已被证明优于 AI 工作负载的模拟和/或静态分析。
用户还可以通过新思科技的 Platform Architect 探索 SoC 设计的系统层面。Platform Architect 最初用于内存、处理性能和功耗探索,最近越来越多地用于了解 AI 的系统级性能和功耗。使用预构建的LPDDR 、ARC处理器模型用于 AI、存储器等,可以进行灵敏度分析,以确定最佳设计参数。
新思科技拥有一支经验丰富的团队,负责开发从 ASIP Designer 到 ARC 处理器的 AI 处理解决方案。包括内存编译器在内的经过验证的基础 IP 产品组合已广泛应用于 AI SoC。AI 应用的接口 IP 范围从传感器输入到 I3C 和 MIPI,再到通过 CXL、PCIe 和 Die to Die 解决方案的芯片到芯片连接,以及通过以太网的网络功能。
总结
软件和芯片协同设计已经成为现实,选择正确的工具和专业知识至关重要。新思科技正在利用专业知识、服务和成熟的IP,为客户提供最适合的方法,在不断变化的情况下优化 AI 芯片。
本文作者
新思科技IP 战略营销经理 Ron Lowman
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3120内容,欢迎关注。
推荐阅读
半导体行业观察

『半导体第一垂直媒体』
实时 专业 原创 深度
识别二维码,回复下方关键词,阅读更多
晶圆|集成电路|设备|汽车芯片|存储|台积电|AI|封装
回复 投稿,看《如何成为“半导体行业观察”的一员 》
回复 搜索,还能轻松找到其他你感兴趣的文章!

文章评论