
大数据文摘授权转载自数据派THU
作者:Even Oldridge,Karl Byleen-Higley
翻译:陈之炎
校对:zrx
新手在构建推荐系统时面临的最大挑战是缺乏对推荐系统的切实理解,将大多数推荐系统的在线内容集中在模型上,并且通常仅限于一个简单的协同过滤例子。对于新的从业者来说,推荐系统的简单模型示例和实际量产系统之间存在着巨大的差距。
本博将和读者分享一种模式,它涵盖了部署推荐系统的全流程,示例程序来自Meta公司、Netflix公司和Pintery公司等公司。这一模式是NVIDIAMerlin团队构建端到端系统的核心技术,很高兴能在社区分享推广它,帮助读者建立部署推荐系统(不仅仅是模型)的概念和共识。如果对这个领域的内容感兴趣,还可以参加 KDD工业推荐系统工作坊(KDD’s Industrial Recommender Systems workshop)组织的主题演讲。
遥望推荐模型
推荐模型所起的作用,无论是一个简单的协作过滤示例,还是像DLRM这样的深度学习模型,其实质都是排序,或者更准确地说,是一个评分系统,用户对一组感兴趣的数据项打分。然而,这些分数本身却往往不足以在现实世界中为用户提供合理的推荐,在探索解决方案,构造最终的推荐系统之前,将深入研究以下诸多原因。
数据项越多问题越多
首先遇到的第一个问题是推荐中的数据项的数量。在极端情况下,数据项目录可以长达数百万,数亿,甚至数十亿。在大多数情况下,为每个数据项进行评分是不可行的,评分的算力异常昂贵。在实践中,首先需要快速选择这些项的相关子集,比如对其中的一千或一万个数据项打分。
进入第二个阶段,在对数据项打分之前,需要选择一个合理相关集合,其中包含用户会最终参与的数据项。这个阶段通常称为候选检索阶段,也可称之为候选生成阶段。检索模型有多种形式,包括矩阵分解模型、双塔模型、线性模型、近似最近邻模型和图遍历模型,通常情况下,检索模型比评分模型的计算效率更高。
YouTube在2016年有一篇优秀的论文,是该架构的第一个公开参考文献之一,目前,该方法已广为采纳,在业界普遍应用。EugeneYan有一篇关于这个主题的精彩博文,他的两阶段图片是我们的四阶段推荐图的灵感来源,将在下文做详细介绍。值得注意的是,在同一个推荐系统中使用多个候选源来向用户呈现不同的候选项也很常见,随后会把这个主题保存到另一篇博客中。
二阶段之外!
虽然两阶段大规模推荐模型能解决大部分问题,但推荐系统还需要支持其他的约束条件。在某些场景下,用户不想显示某些数据项,如:当该数据项没有库存时、年龄不合适时、用户已经使用过该内容时,或者未授权该用户在该国家显示它时,用户并不想显示这些数据项。
依赖评分或检索模型来推断业务逻辑,适当地推荐数据项,除此之外,还需要向推荐系统中添加一个过滤阶段。过滤通常是在检索阶段之后完成,可以与之集成到一起(过滤确保检索后有足够的候选对象),甚至在某些情况下可以在评分之后再进行过滤。过滤阶段应用了业务逻辑规则,如果缺少了过滤,模型不可能(或至少非常难)执行业务逻辑规则。在某些情况下,过滤只是简单的排除查询,但另一些情况之下,也可能很复杂,像Bloom过滤器一样,可以用它来删除已经与用户交互过的数据项。
排序!
到目前为止介绍了三个阶段:检索、过滤和评分,这三个阶段提供了一份数据项建议列表及其相应的分值,这些分值代表了评分模型对用户感兴趣程度的猜测。推荐结果通常以列表的形式呈现给用户,这就提出了一个有趣的难题:最优的列表往往与数据项的得分不完全吻合。甚至相反,希望为用户提供一组完全不同的数据项,向他们展示推荐候选人之外的项目,以探索他们未见过的空间,防止出现过滤气泡。
在一些文献和例子中,推荐系统的第三阶段被称为排序,但向用户显示推荐的最终排名(或位置)很少会与模型的输出直接对齐,通过提供显式的排序阶段,能够将模型的输出与业务的其他需求或约束对齐。
四阶段推荐系统
检索、过滤、评分和排序,这四个阶段构成了推荐系统的设计模式,它几乎涵盖了每一个推荐系统。下图显示了这四个阶段,并展示了如何构建每个阶段的示例,它比基本的推荐模型要复杂得多,特别是考虑到了推荐系统的具体部署,它准确地代表了当今大多数量产推荐系统的架构。
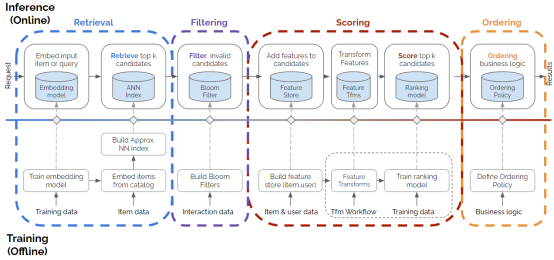
示例
有了对推荐系统模式的描述之后,来看看如何搭建一个推荐系统。首先,看看常见recsys任务示例,在较高层次上,它涵盖了四个阶段的用例,并展示了四个阶段的统一模式。
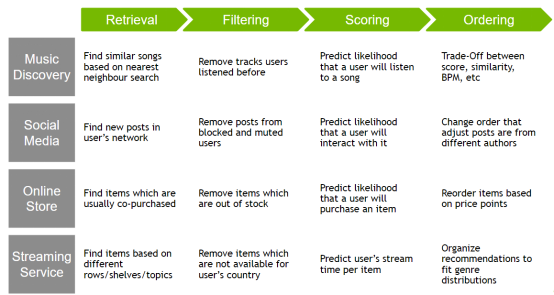
更进一步,可以看看现实中的推荐系统的例子,看看是否能从中识别出四个阶段。
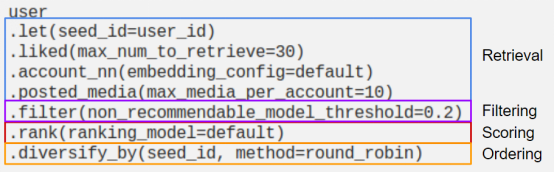
Meta’s Instagram有一篇关于他们开发的查询语言的好文章——由人工智能驱动:Instagram的推荐系统(IGQL查询语言)探究。从他们提供的示例中看出,可以将这种查询语言精确地映射成推荐模式的四个阶段:
Pinterest发布了一系列论文(Pinterest相关内容:现实世界推荐系统的演变、3亿+项目与2亿+实时用户的系统推荐,深度学习相关应用),其中第一篇文章中的一张图,对推荐系统架构随时间推移的发展历程做了描述。在这里,我们再现了相同的模式,但细微的区别是,将检索和过滤视为同一个阶段。
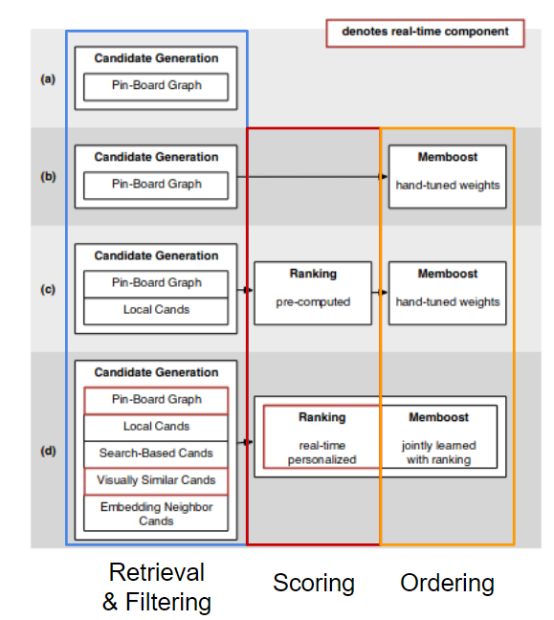
Instacart在2016年分享了这个架构,直接提出了遵循四个阶段的建议。首先检索到候选对象,然后过滤掉之前排序的数据项,再对最热门的候选结果进行评分,并对最终结果进行重新排序,以提高呈现给用户的最终结果的多样性。
复杂系统
在本文的4个阶段图中,阐明了在训练、部署和支持全阶段的推理时间查询过程中所需的组件。这个系统比单一模型要复杂得多,那些通过线上搜索推荐系统信息,并只找到协作过滤模型的人,在真正尝试构建复杂推荐系统时,会显得不知所措。
在下一篇博文中,将深入探讨这个复杂模型的细节,并为Merlin推荐系统框架提出一些解决方案,现在将挑战留给你:详细解读和使用推荐系统,是否能找出四个阶段,如果找不出,也可以和我们沟通!我们将不断地迭代和完善思路和库,争取能够为RecSys空间提供最好的解决方案,对您的输入,我们深表感谢。
最后,如果您热衷于构建开源库,简化推荐系统的构建和部署,欢迎与您沟通交流。
原文标题:
Recommender Systems, Not Just Recommender Models
原文链接:


文章评论