



一般而言,数据分析包括结构化与非结构化数据分析两类。前者比如常见的列表格式的结构化数据分析,后者则是针对文本、图像和视频等非结构化格式的数据分析。其实,类似于结构化数据,纯文本也是常见的数据格式。
文本分析通过运用自然语言处理(NLP)、信息检索和机器学习(ML)等技术将非结构化文本数据解析为更结构化的形式,从而提取对终端用户有益的模式与见解。
诸如文本分类、文本聚类、情感分析以及相似性分析与关系建模,都是常见的文本分析技术。
对于非结构化文本数据,我们需要借助Python自然语言工具包NLTK(The Python Natural Language Toolkit)进行分析。源于2001年的NLTK设计初衷是用于教学,其中包括一个名为corpora的文本样本集。显然,展开文本分析需要我们首先获得NLTK。


01

点击NLTK Downloader右下角Refresh按钮,首先将服务器索引(Server Index)右侧的网址修改为NLTK官网“https://www.nltk.org/nltk_data”;
选择拟下载的安装包后点击Download,即可将nltk_data语料库下载至“C:\Users\Administrator\AppData\Roaming\nltk_data”文件夹,参见图1。
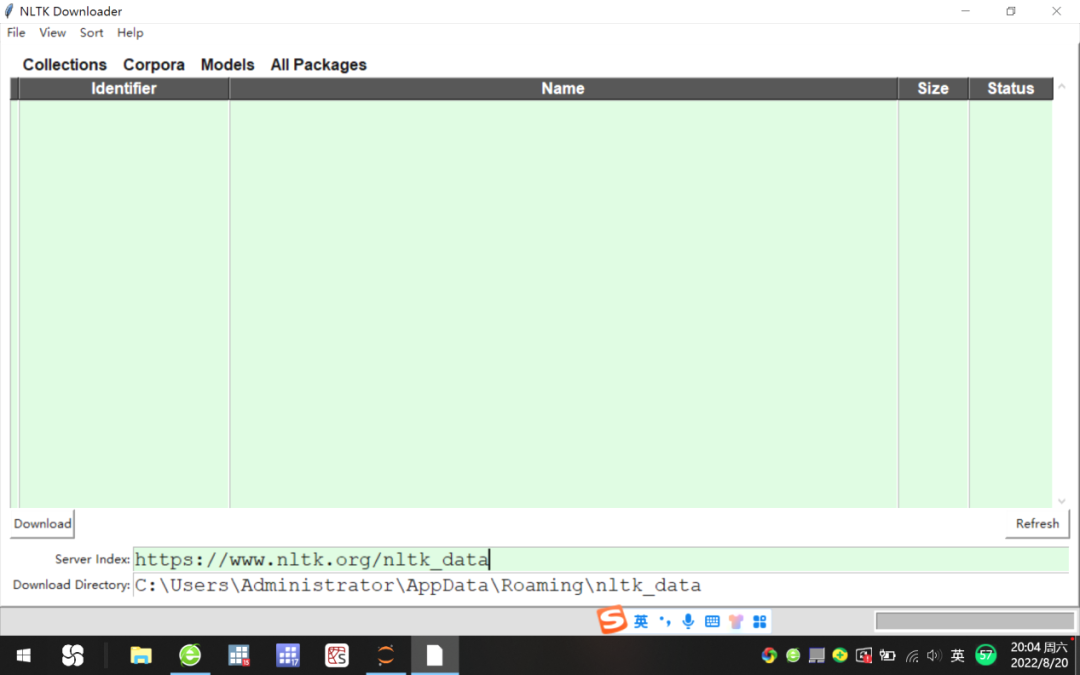
图1 官网下载nltk语料库
官网下载的nltk语料库容量高达1.8GB,下载速度较慢。一个可行的替代方案是利用百度云下载压缩包,相应的代价是需要人工解压nltk_data.zip中的每一个子压缩文件。

02
在360浏览器搜索栏输入以下文件链接:“https://pan.baidu.com/s/1LWM3o7iRZMF8XaD91vx9Dw”,输入手机发送的动态验证码可打开百度网盘,然后输入提取码“cnpf”即可下载压缩包nltk_data.zip,参见图2。
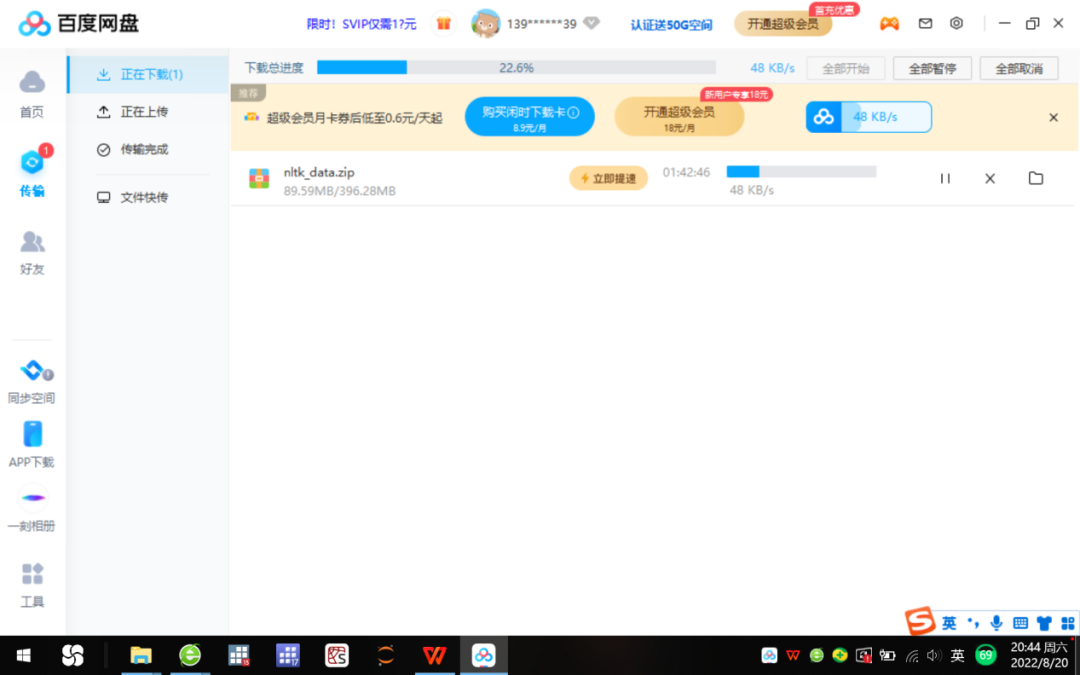
图2 百度云下载nltk语料库
解压下载所得压缩包,可得chunkers、corpora等9个子文件夹,我们将其置于Download Directory路径“C:\Users\Administrator\AppData\Roaming\nltk_data”,参见图3。
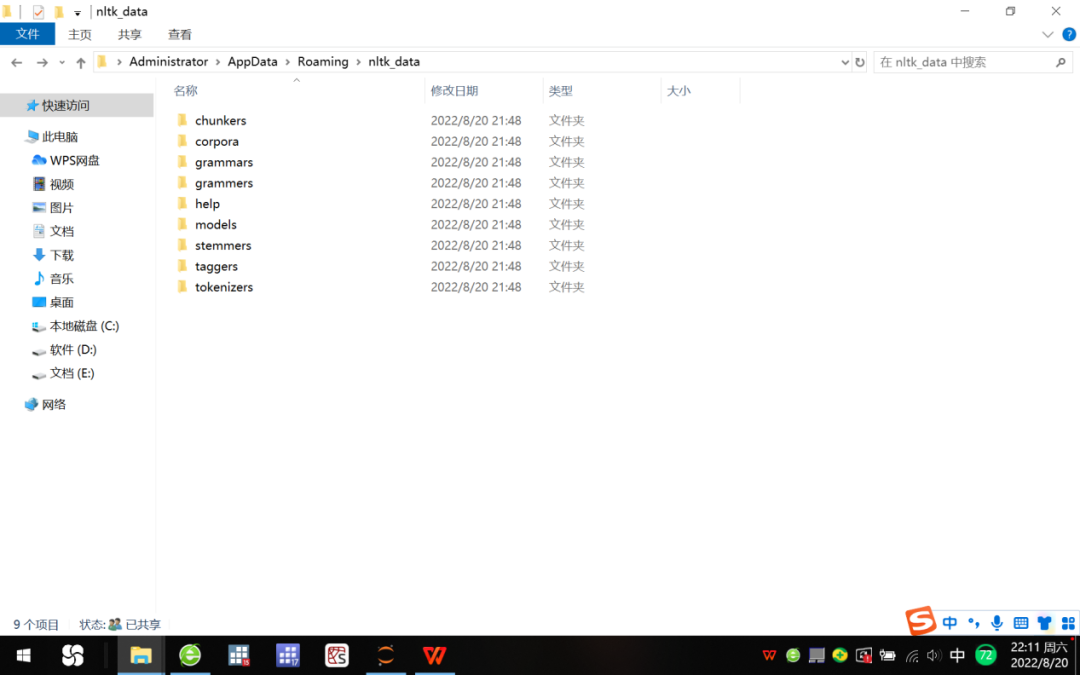
图3 nltk_data文件夹所包含的9个子文件夹
03
打开Jupyter Notebook,点击右侧的New按钮创建一个Python新文件,依次输入以下命令以检测nltk语料库是否下载成功,参见图4。

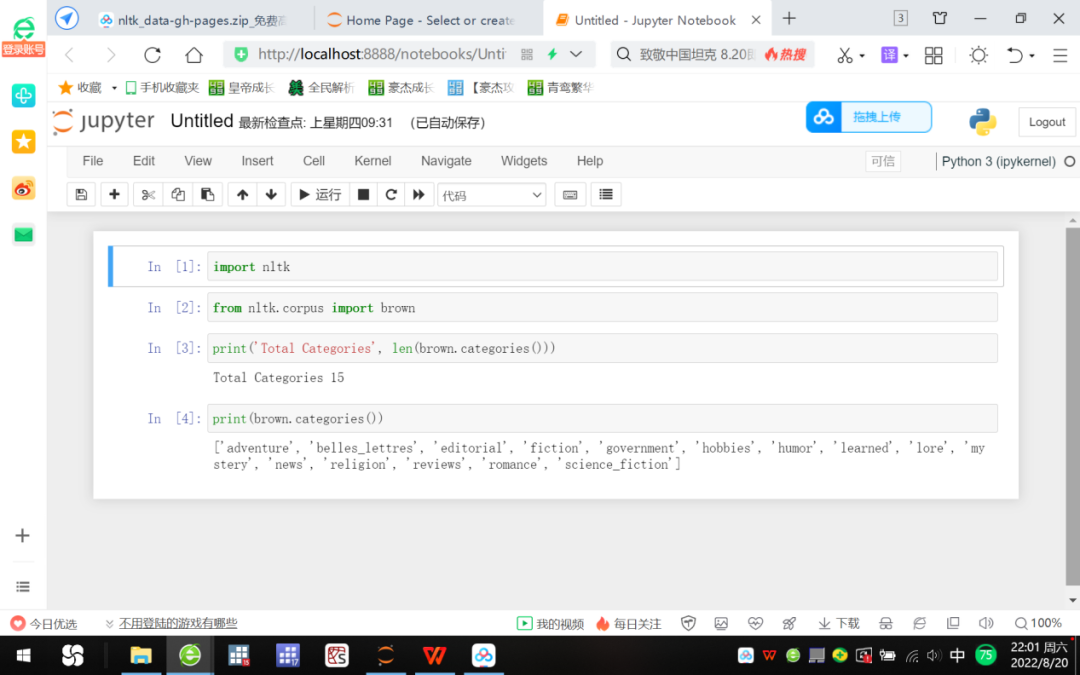
图4 nltk下载测试:访问Brown语料库
Brown是全世界第一个百万级的英文语料库,也称为“当代美国英语标准语料库”,由布朗大学Kucera和Francis于1961年开发。该语料库由来自不同来源和分类的文本组成。
图4的命令运行结果告诉我们,该语料库中共有15个类型,例如新闻(news)、推理小说(mystery)、传说(fiction)等等,这表明本机nltk语料库已经成功安装。
04
NLTK包含Gutenberg语料库,这是一个供人们在互联网上阅读的数字图书馆计划。
1、解压nltk_data子文件夹corpora中的gutenberg、punkt、stopwords和words压缩包,参见图5。
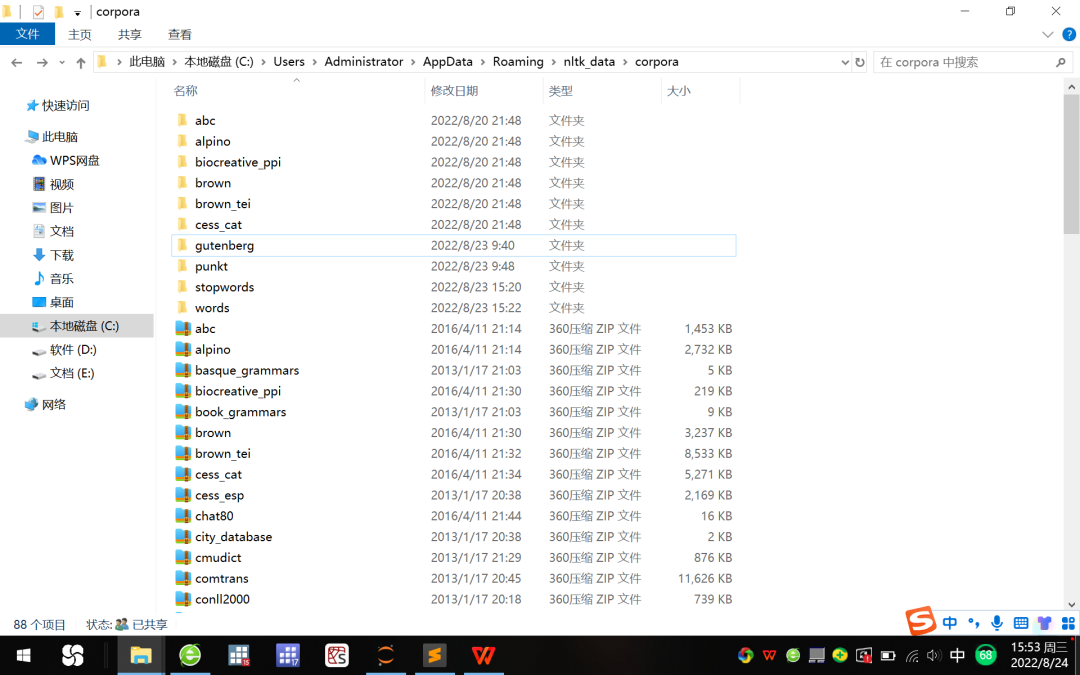
图5 nltk_data子文件夹的解压
2、在以下路径新建PY3子文件夹,并将该路径中的english.pickle文件置于这一新建的子文件夹PY3中,参见图6。
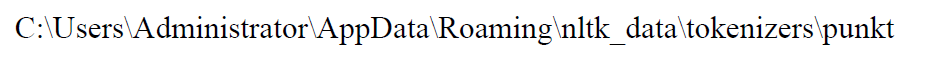
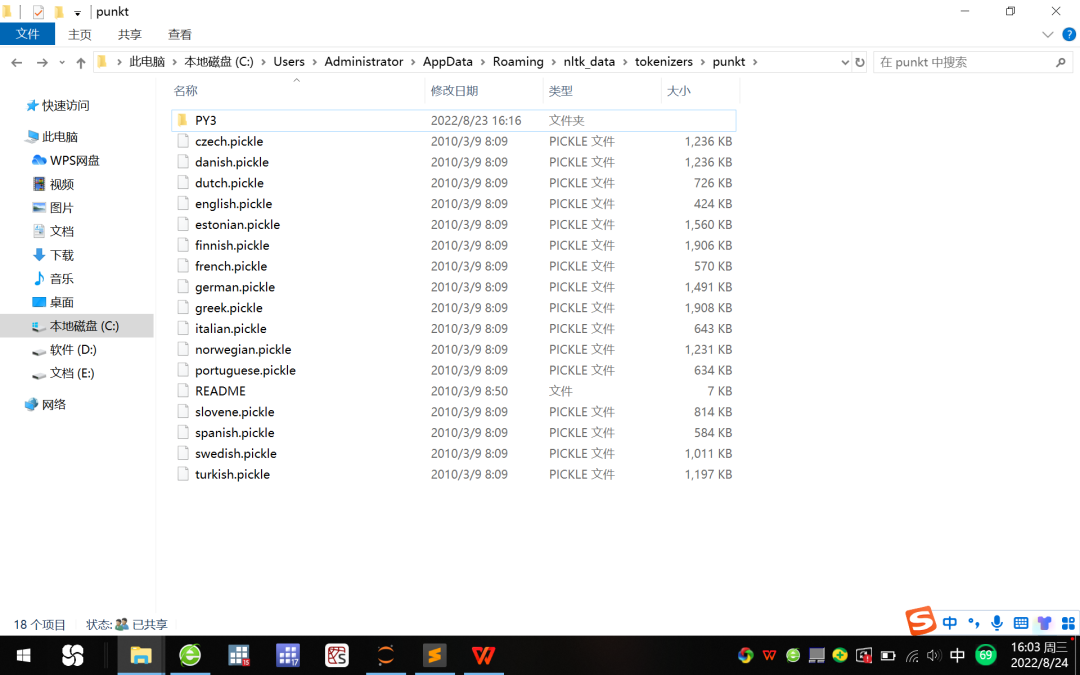
图6 新建子文件夹PY3
3、打开Jupyter Notebook,点击右侧的New按钮创建一个Python新文件,依次输入以下命令,运行结果参见图7和图8。

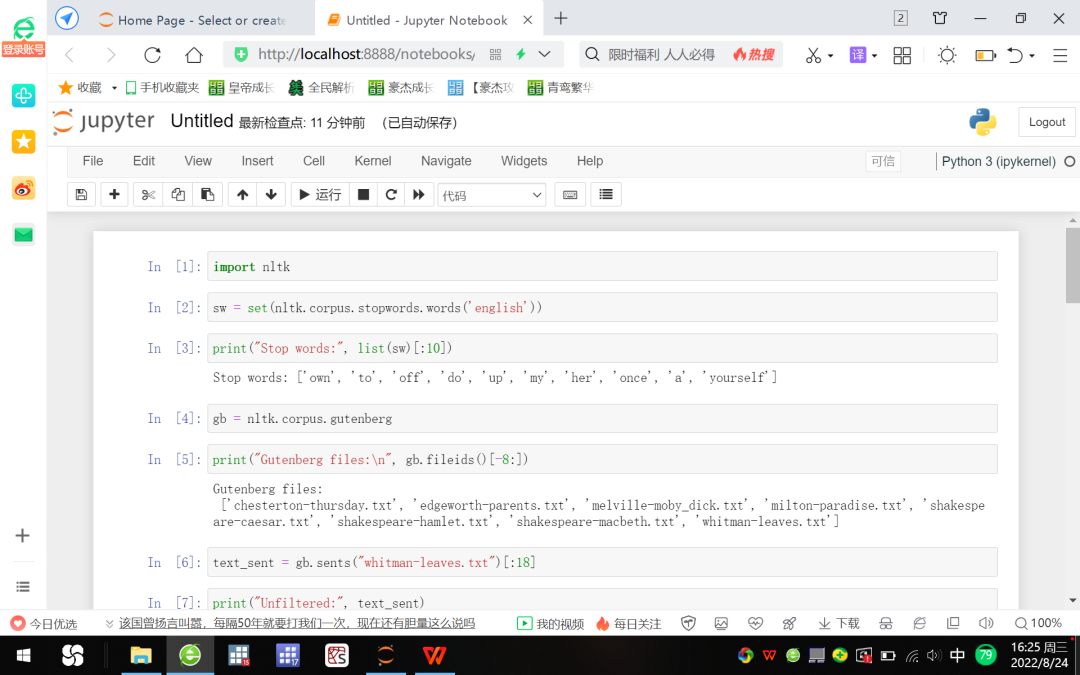
图7 基于Jupyter Notebook的NLP演示
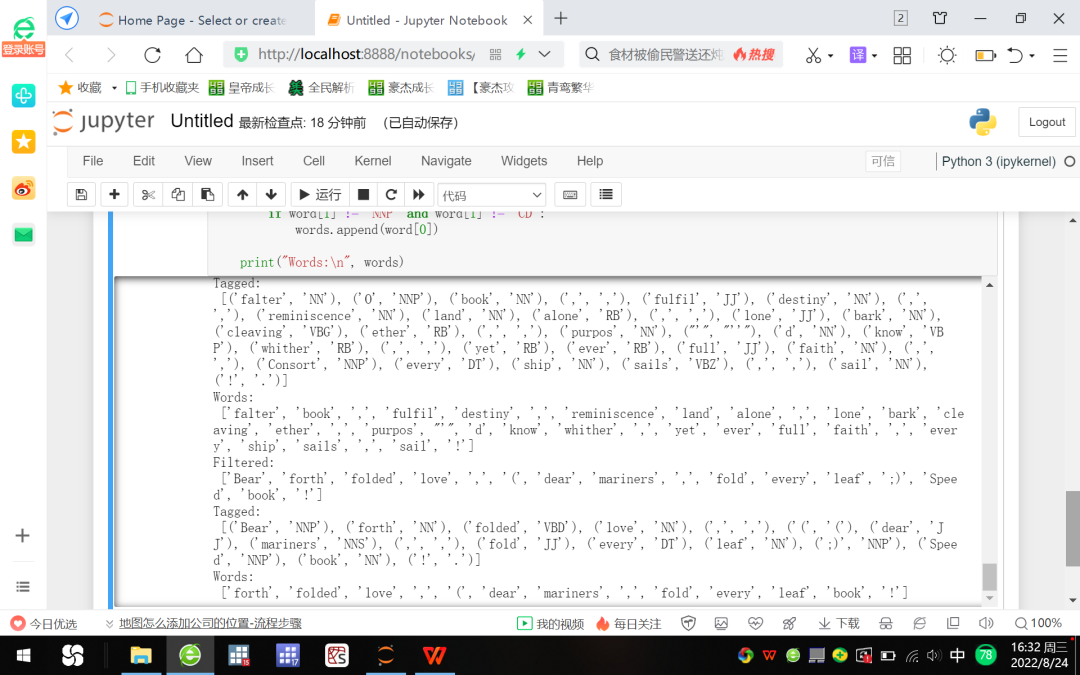
图8 滤除停用字、姓名和数字的NLP演示:基于Gutenberg项目
图8显示,停用字、姓名与数字在words列表中均已被滤除。

编辑:曹承洲
审核:杨 露

往期回顾:

实证会计入门一点通
扫描二维码关注我们
鼎园会计微信群
本群主旨:
交流Stata与Python,
分析结构化数据,
探讨非结构化文本会计,
共同书写鼎园会计人生。

文章评论