第八期“原力释放 云原生可观测性分享会”云杉网络 研发 VP 向阳分享《DeepFlow —— 开启高度自动化的可观测性新时代》,DeepFlow 第一个开源版本正式发布,它是一个高度自动化的可观测性平台,能够显著降低开发者的埋点、插码、维护负担。
点击下方卡片观看视频回放。
 哔哩哔哩 , 交易担保 , 放心买 , DeepFlow —— 开启高度自动化的可观测性新时代
哔哩哔哩 , 交易担保 , 放心买 , DeepFlow —— 开启高度自动化的可观测性新时代  小程序
小程序
直播间的朋友们大家好,很高兴能和大家分享 DeepFlow 首个开源版本的正式发布。我相信通过我今天的介绍,大家能够感受到一个高度自动化的可观测性新时代,让我们一起来去见证和开启。
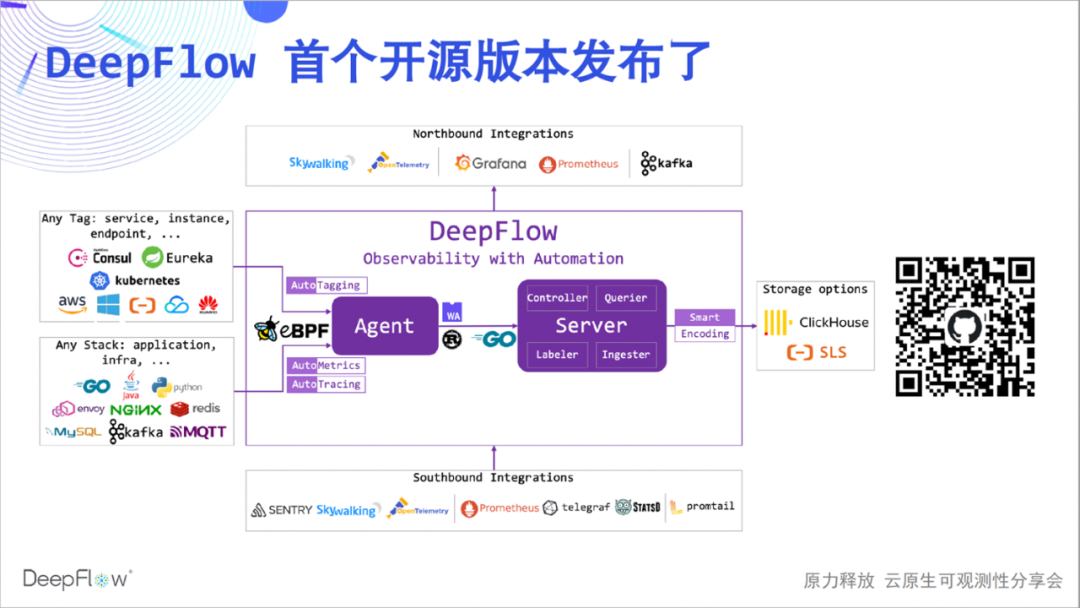
下面是 DeepFlow 社区版的架构图,有些朋友对 DeepFlow 还不太了解,我简单介绍一下。DeepFlow 是云杉网络自研的可观测性平台,基于eBPF 等技术的一系列创新,使得它具备高度的自动化,为开发者构建可观测性显著降低工作负担。
我们可以看到它能够自动同步资源、服务、K8s 自定义 Label 并作为标签统一注入到观测数据中(AutoTagging),它能够自动采集应用性能指标和追踪数据而无需插码(AutoMetrics、AutoTagging),它的 SmartEncoding 创新机制将标签存储的资源消耗降低了 10 倍。此外它还有很好的集成能力,能集成广泛的数据源,并基于 SQL 提供良好的北向接口。DeepFlow 的内核基于 Apache 2.0 License 开源,欢迎给我们?Star(扫描下图二维码前往)!
当我们在谈论高度自动化的时候,我们想传达哪些信息呢?今天的分享将会从四个方面展开:
-
首先介绍 DeepFlow 自动化的指标数据采集能力 AutoMetrics,自动展示全栈性能指标和全景服务关系;
-
接下来是自动化的 Prometheus、Telegraf 集成能力,汇集最全的指标数据,并解决数据孤岛和高基数烦恼;
-
在此之后带你体验 DeepFlow 基于 eBPF 的创新的自动化分布式追踪能力 AutoTracing,相信这绝对是世界级的创新;
-
最后是自动化的 OpenTelemetry、SkyWalking 集成能力,展示惊艳的无盲点的分布式追踪能力,解决追踪不全的痛苦。
高度的自动化能让开发者有更多的时间进行业务开发,团队协同解决问题时也会更加丝滑自如。
那我们首先来看今天的第一弹吧,AutoMetrics。
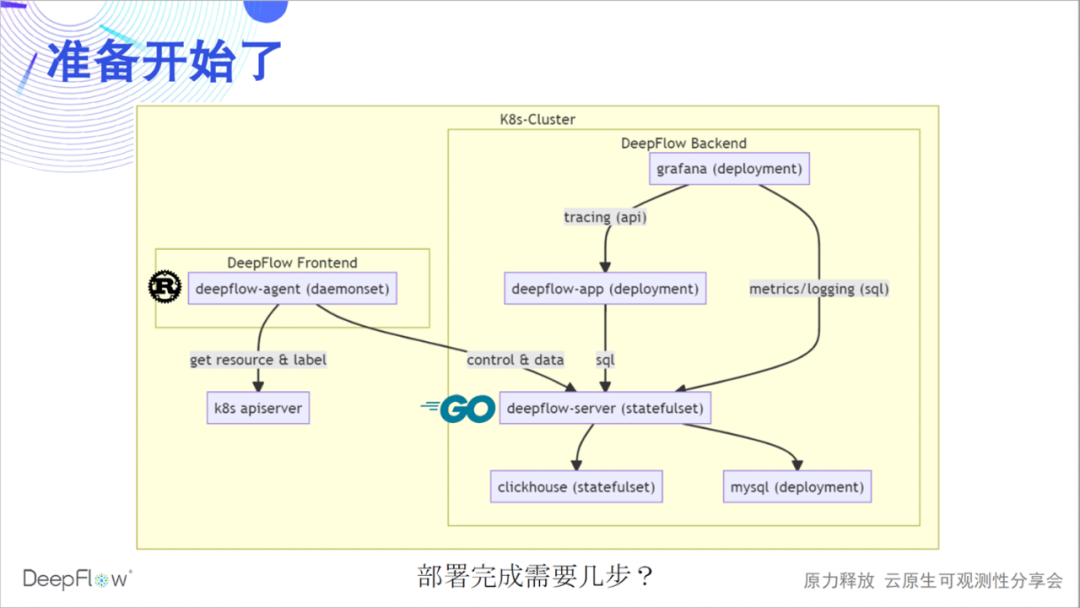
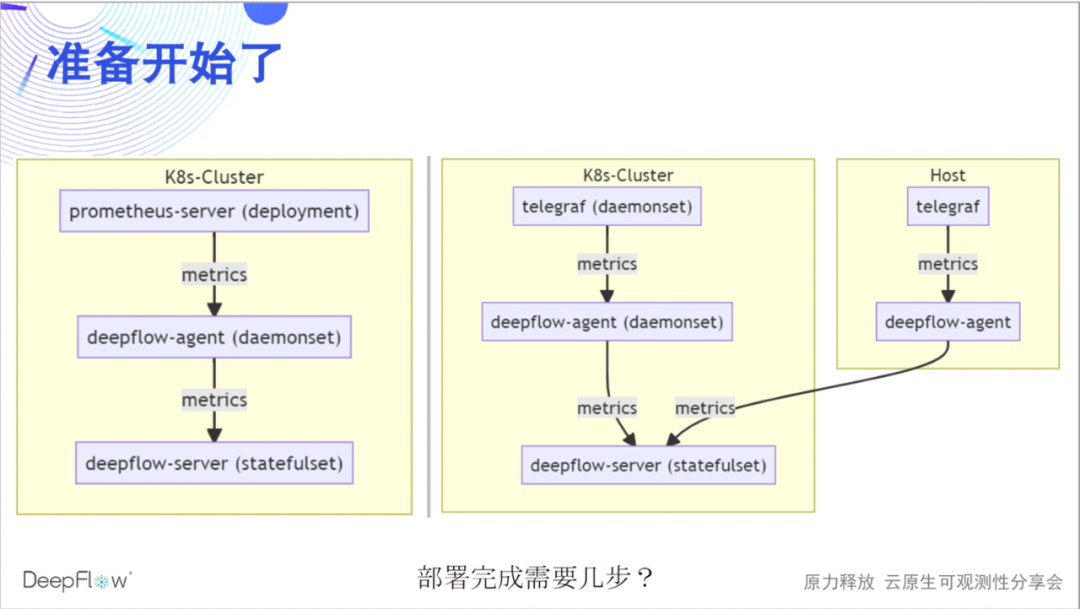
我们先热热身,部署一套完整的 DeepFlow。下图更清晰的展示了 DeepFlow 的软件架构:Rust 实现的 deepflow-agent 作为 frontend 采集数据,并与 K8s apiserver 同步资源和 Label 信息;Golang 实现的 deepflow-server 作为 backend 负责管理控制、负载均摊、存储查询。我们使用 MySQL 存储元数据,使用 ClickHouse 存储观测数据并支持扩展替换,使用 Grafana 展示观测数据。
目前我们还有一个 Python 实现的 deepflow-app 进程用于提供分布式追踪的 API,后续将会使用 Golang 重写并逐步合并到 deepflow-server 中。deepflow-server 向上提供 SQL API,我们基于此开发了 Grafana 的 DeepFlow DataSource 和拓扑、分布式追踪等 Panel。deepflow-agent 可以运行在主机或 K8s 环境下,但 deepflow-server 必须运行在 K8s 中。下面我们猜想一下在一个 K8s 集群中部署 DeepFlow 需要几步?
是的,只需要一步,复制粘贴这几条 helm 命名即可完成部署。如果你身边有电脑,可以现在就参考部署文档部署一下,期待在直播间或我们的微信群中反馈部署体验。
helm repo add deepflow https:helm repo update deepflowhelm install deepflow -n deepflow deepflow/deepflow --create-namespace
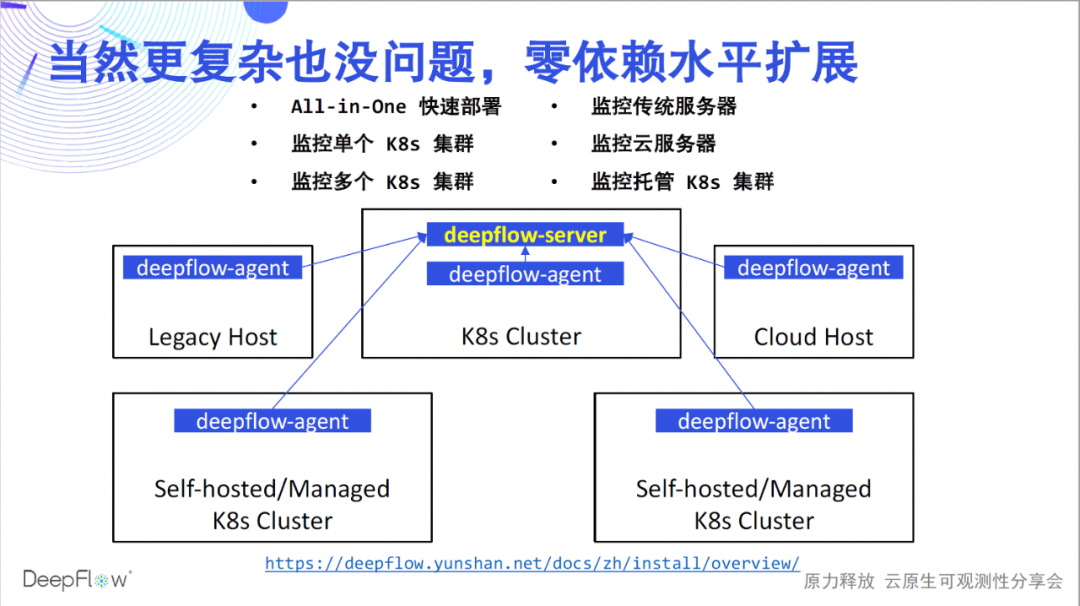
刚才的部署只解决了一个 K8s 集群的监控问题,DeepFlow 的能力当然不仅限于此。参考部署文档,可以在各种场景下丝滑的部署 DeepFlow。我们支持快速的 All-in-One 单节点体验;支持监控多个 K8s 集群并为所有数据自动注入 K8s 资源和自定义 Label 标签;支持监控传统服务器和云服务器并为所有数据自动注入云资源标签;最后我们也支持监控托管 K8s 集群,自动注入 K8s 及云资源标签。所有这些场景下,DeepFlow 无需依赖任何外部组件就能做到水平扩展。部署完成,让我们开启高度自动化的可观测性之旅吧。
我们最常谈论的黄金指标,一般是服务的 Request、Error、Delay。下图是 DeepFlow 部署完成后就能展现的、任意微服务的应用性能 RED 指标,不管它是用什么语言实现的。我们目前支持采集 HTTP 1/2/S、Dubbo、MySQL、Redis、Kafka、MQTT、DNS 应用的指标数据,且支持列表还在持续增加中。我们会为所有的指标数据自动注入几十甚至上百个维度的标签字段,包括资源、服务、K8s 自定义 Label,这让使用者能随心聚合、灵活下钻。但这里我们希望着重强调的还是还是自动化的能力,这些指标开发团队再也不用发愁插码了、运维团队再也不用发愁总要推着让开发插码了。DeepFlow 的自动化,让每个团队生产力高一点,团队协作融洽一点。
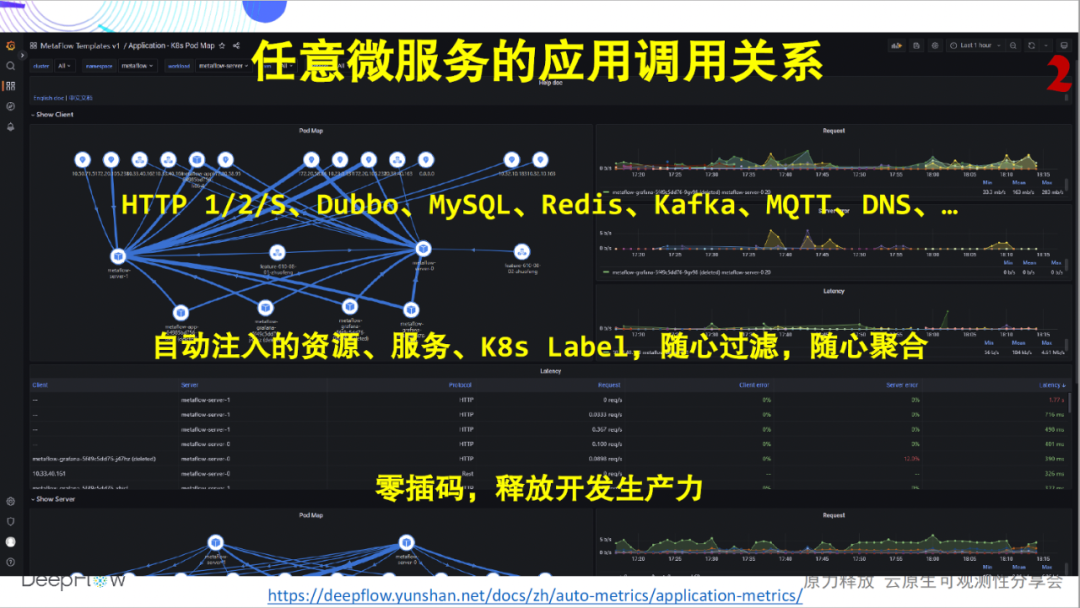
再来看另一张图,除了单个服务以外,DeepFlow 也能呈现任意微服务之间的应用调用关系。同样,完全零插码。通过文档可登录我们的在线 Demo 环境实景体验。
仅此而已了吗?远不止如此!在云原生环境下,网络的复杂性显著增加,成为故障排查的黑盒,定位问题通常靠猜。DeepFlow 拥有应用性能的全栈监控能力,能够自动化的采集任意微服务的吞吐、建连异常、建连时延、传输时延、零窗、重传、并发等上百个指标,同样也会自动注入几十甚至上百个维度的资源、服务、K8s 自定义 Label 标签。
同样,DeepFlow 也能呈现任意微服务之间的网络调用关系。依然完全零插码。
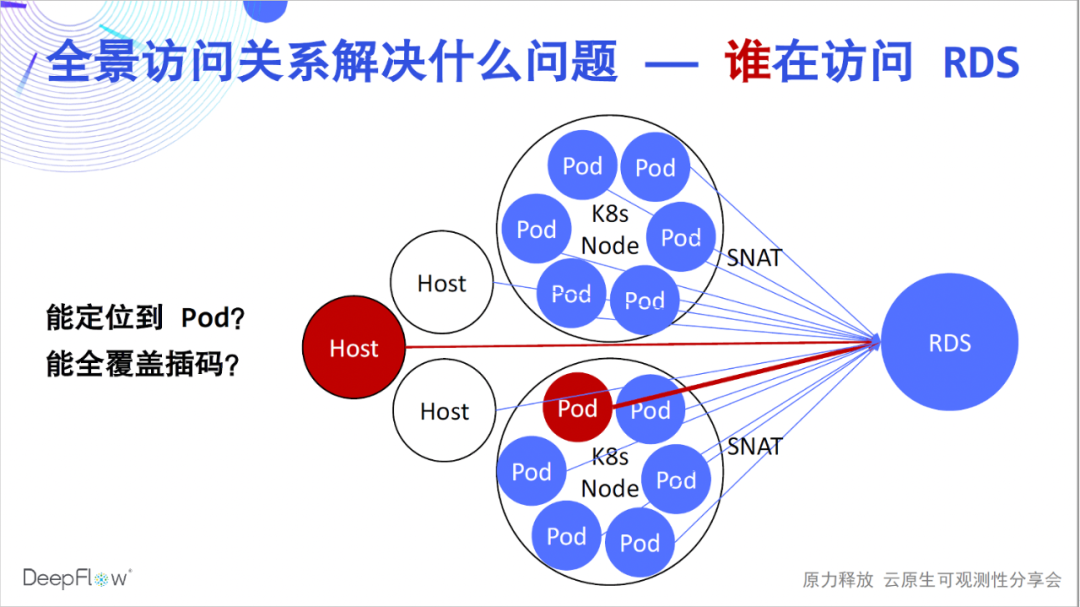
好了,相信大家已经开始更真切的感受到高度自动化的气息了。但它们能解决什么问题呢?依靠自动化的全景访问关系,DeepFlow 企业版的客户快速解决了大量的故障定位问题,常见的比如 RDS 运维用于定位哪个客户端造成了最大的访问负载。在 K8s 环境中由于 SNAT 的存在,没有办法知道哪些 Pod 在访问。传统的方法我们只能在客户端进行插码,但却很难做到全面覆盖。使用 DeepFlow 解决此类问题易如反掌,直接搜索 RDS 即可得知访问它的所有客户端的性能指标。
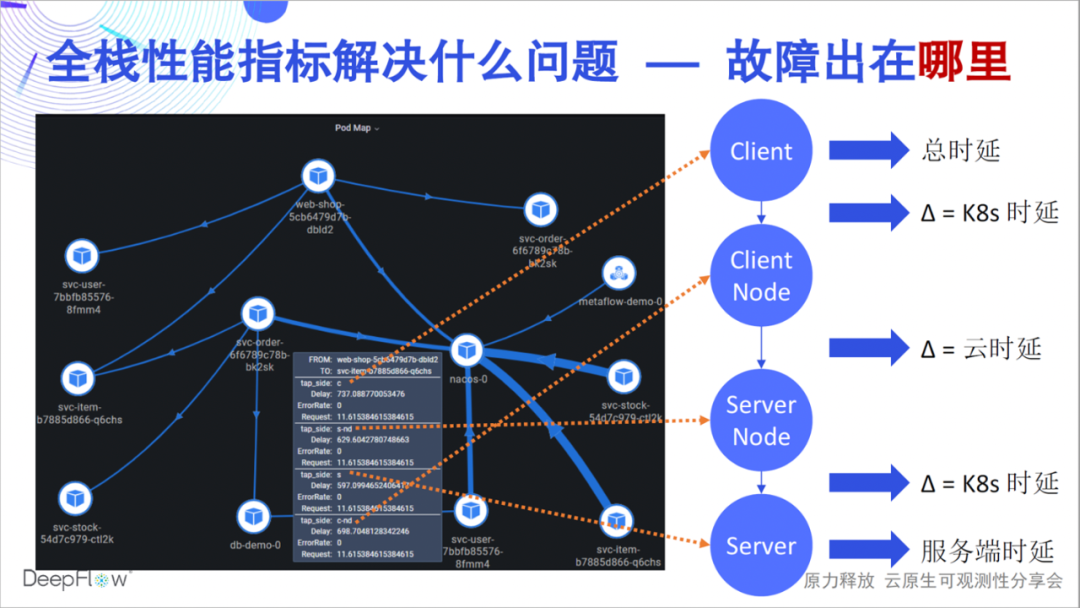
那么全栈性能指标又能解决什么问题呢?一个故障可能是某个 API 的时延过高,但这个时延究竟是哪个环节引起的,究竟应该由哪个团队上,你的团队解决这样的问题能有多快?DeepFlow 的全栈能力能够快速回答一个访问关系在各个关键节点的性能状况,例如这张图里展示的,我们能精准区分瓶颈到底是在服务端 Pod、服务度 K8s 网络、云网络、客户端 K8s 网络、还是客户端自身。DeepFlow 让分布式环境下的排障如同单机一样简单,而这一切仍然是完全自动化的。
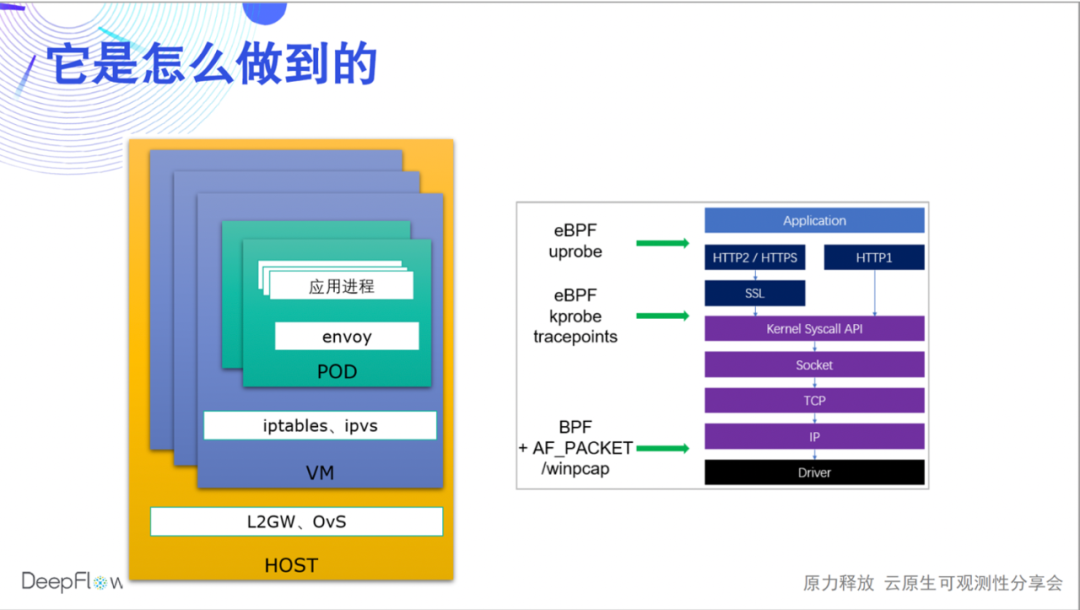
DeepFlow 到底是怎么做到的呢?今天我们只能蜻蜓点水,后续会有更多的直播和文章分享底层机制。我们使用 eBPF、BPF 采集每一个请求(DeepFlow 之名中的 Flow)在应用程序、系统调用、网络传输时的性能数据,并将他们自动关联起来。这样一来,一方面我们可以覆盖所有的通信端点(微服务),另一方面还能将每一跳的性能数据关联起来,快速定位问题到底出现在应用进程、Sidecar、Pod 虚拟网卡、Node网卡,DeepFlow 企业版还能继续定位宿主机网卡、NFV 网关网卡、物理网元端口等。
这项工作仍然还有很多需要继续迭代的事情。我们知道 HTTP2/gRPC 的头部字段是压缩的,目前我们支持了基于静态压缩表的协议头解析,后续将会利用 eBPF uprobe 获取动态压缩表进行完整的头部解析。对于 HTTPS 我们目前支持 eBPF uprobe 对 Golang 应用的采集能力,后续会逐渐支持 C/C++/Java/Python 等多种语言。同时我们也理解实际业务环境中会存在大量的私有应用协议,我们希望通过 WebAssembly 技术提供给开发者灵活的可编程能力。
但仅仅这些指标还不够完善,可观测性需要尽量丰富的数据。接下来我们介绍 DeepFlow 自动化的指标数据集成能力。
下图展示了 DeepFlow 和 Prometheus、Telegraf 的集成方法。我们通过 deepflow-agent 集成数据,作为 prometheus-server 的一个 remote-storage endpoint,或者作为 telegraf 的一个 output endpoint。整个流程比较简单,大家认为完成这样的部署需要几步呢?
只需要两步,分别在 prometheus/telegraf 和 deepflow-agent 侧修改一个配置即可。DeepFlow 这一侧的配置实际上只是个开关,我们没有默认开启,期望 deepflow-agent 默认不会监听任何端口,对运行环境能够零侵扰。
# prometheus-server config remote_write: - url: http: # telegraf config [[outputs.http]] url = "http://${DEEPFLOW_AGENT_SVC}/api/v1/telegraf" data_format = "influx" # deepflow config vtap_group_id: <your-agent-group-id> external_agent_http_proxy_enabled: 1
这样简单的配置同样可以试用于各种复杂的场景,覆盖多 K8s 集群、云服务器,并且不需要任何外部组件协助即可做到水平扩展。
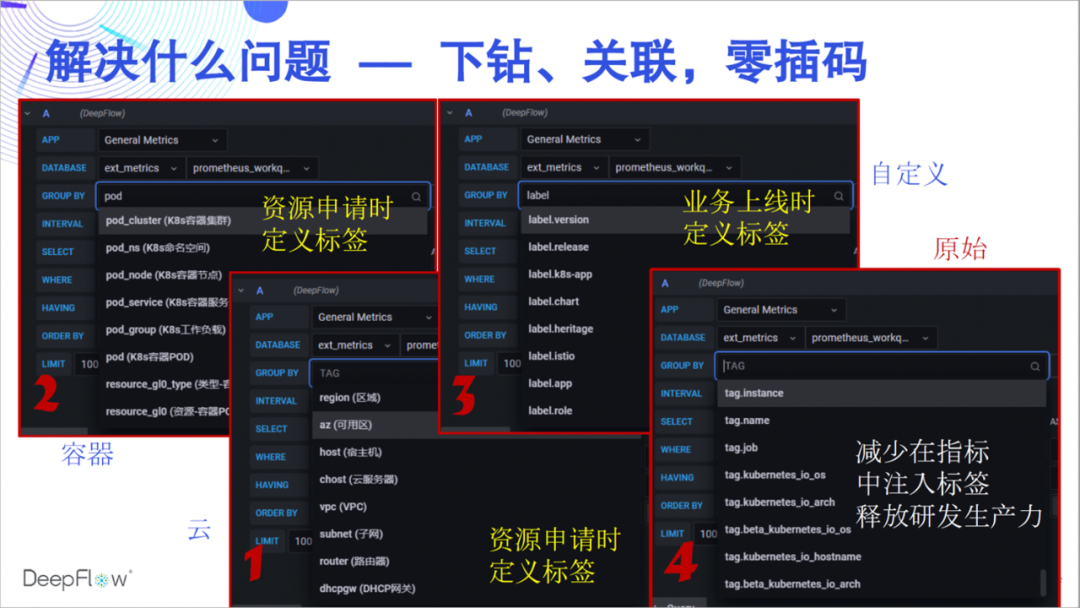
为什么要将数据汇集到 DeepFlow 呢,我们先感受一下强大的 AutoTagging 能力。我们为 DeepFlow 的所有原生数据和集成数据都自动注入了大量的标签,使得数据关联不再有屏障、数据下钻不再有缺陷。这些标签来自云资源、K8s 资源、K8s 自定义 Label,我相信开发人员一定很喜欢这个能力,再也不用在业务代码里面插一大堆零散的 Tag 了。我们建议大家将所有需要自定义的标签在服务上线时通过 K8s Label 的方式注入,与业务代码完全解耦。至于和业务相关的动态标签,DeepFlow 也会以非常高效的方式完整的存储下来,支持检索和聚合。
自动插入这么多标签,资源消耗怎样呢?DeepFlow 的 SmartEncoding 机制很好的解决了这一问题,我们提前将标签进行数值编码,指标数据在生成和传输时并不会携带这些标签,仅在存储之前统一插入已经编码后的数值化标签字段。对于 K8s 自定义 Label 我们甚至不会随指标数据存储,仅在查询时进行关联。对比 ClickHouse 的 LowCard 或直接存储标签字段,SmartEncoding 机制使得我们在算力和存储消耗上可以有高达一个数量级的降低。
因此,拒绝在业务代码中插标签不仅能偷懒,还很环保。
我们更加希望的是,通过广泛的数据集成和关联来激活团队协同。DeepFlow 有自动化的网络、应用指标,Prometheus/Telegraf 有自动化的系统性能指标,再加上开发者通过 Exporter/StatsD 等暴露的业务指标。我们将这些丰富的指标沉淀到一个数据平台中,并进行高效的自动关联,希望能够促进运维、开发、运营团队的相互协同,提供所有团队的工作效率。
在指标集成方面,我们也有一些计划中的工作。我们将会继续支持 Prometheus remote_read 接口,使得 DeepFlow 可以作为一个完整的 Prometheus remote-storage,这样能够不改变 Prometheus 用户的使用习惯。我们计划将 DeepFlow 的自动化指标 Export 到 prometheus-server,使得熟悉 Prometheus 的开发团队可以轻松获取到更强大的全景、全栈指标告警能力。我们也在持续支持其他 Agent 的集成,我们坚信可观测性必须要对数据能广泛采集。另外,DeepFlow 也会支持同步服务注册中心中的信息,让应用运行时的丰富信息能够自动化的作为标签注入到观测数据中。
下面我们进入一个新的议题 —— 追踪。我们首先来感受下 DeepFlow 自动化的 AutoTracing 能力。
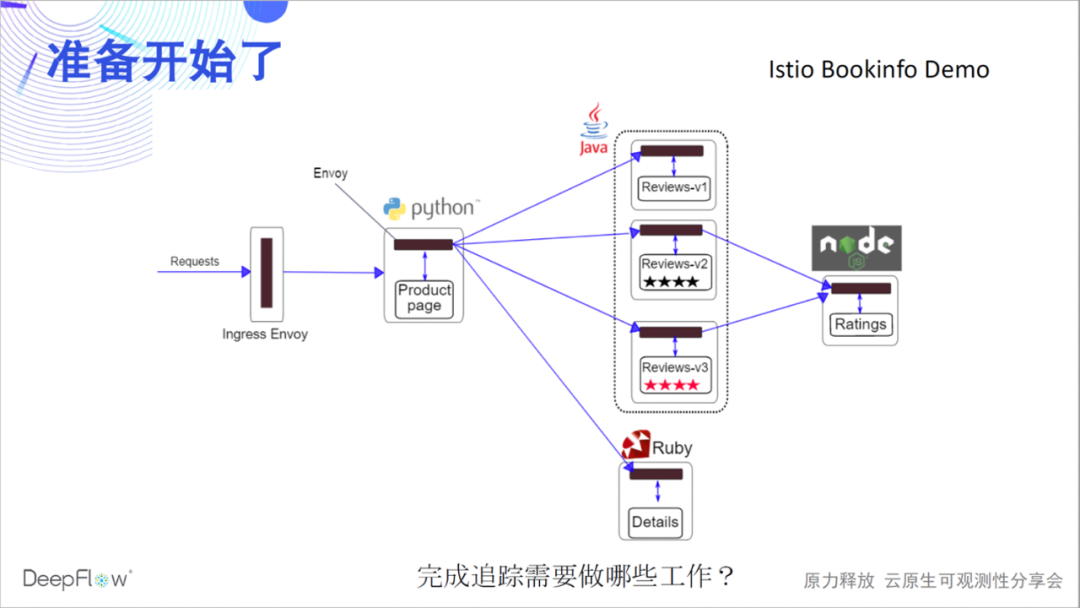
我们以一个 Istio 官方的 Bookinfo Demo 为例,和大家一起见证奇迹。这个 Demo 相信有不少朋友很熟悉,有 4 个各种语言的微服务,有 Envoy Sidecar。大家先猜测一下,完成对它的分布式追踪,我们需要做哪些事情?
我们先来看看 OpenTelemetry +
Jaeger 对这个 Demo 追踪效果怎样。你没有看错,由于这个 Demo 中没有做 instrumentation,Jaeger 看不到任何内容,空的。
那么 DeepFlow 需要做什么呢?实际上什么都不用做,因为我们已经早早的通过一条 helm 命令将 DeepFlow 部署好了,无需再做任何操作。见证奇迹的时刻到了。什么代码都没有插入的情况下,我们完整的追踪到了这 4 个微服务之间的调用。依靠 eBPF 和 BPF 的能力,完全的自动化!
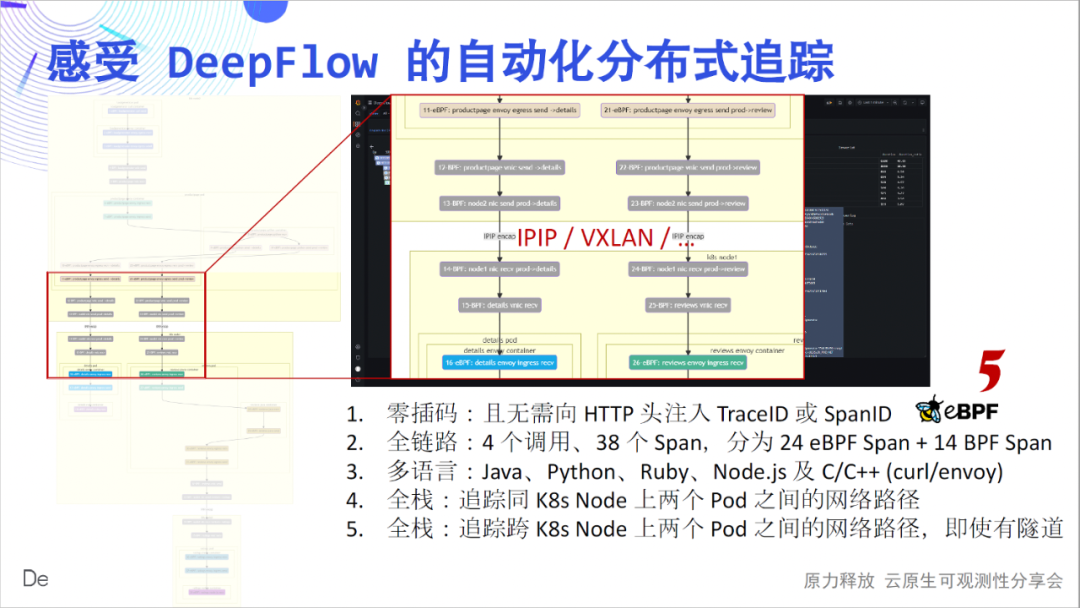
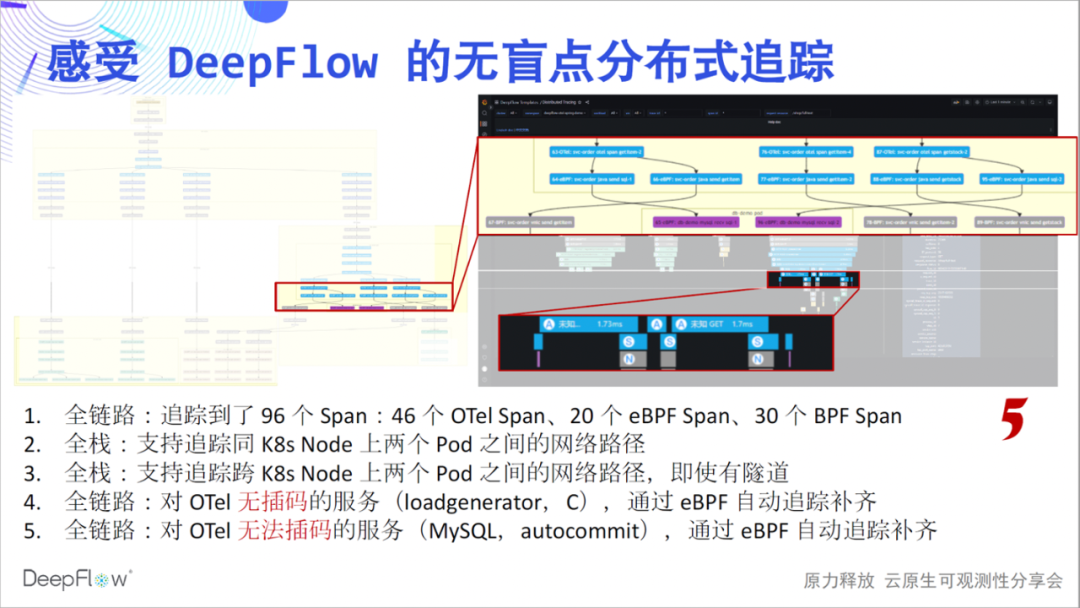
下面我们带着大家详细感受一下这张朴素的火焰图深层次的魅力:零插码,是我们想传达的第一个感受。将火焰图的每个 Span 绘制作为一个节点,我们得到了一个调用流程图,从图中可以清晰的看到这个简单应用的复杂调用过程。全链路,是我们想传达的第二个感受。4 个调用,我们追踪到了 24 个 eBPF Span、14 个 BPF Span,并构建出了他们的关系。
多语言,是我们想传达的第三个感受。这里覆盖了Java、Python、Ruby、Node.js、C、C++ 实现的服务,DeepFlow 就这样悄无声息的追踪出来了。全栈,是我们想传达的第四个感受。我们可以看到,Pod 之间的逐跳网络访问路径清清楚楚,到底哪里是瓶颈明明白白。
全栈,也体现在跨容器节点上,无论中间的网络路径是 IPIP 还是 VXLAN 隧道封装,都可以追踪的稳稳当当。
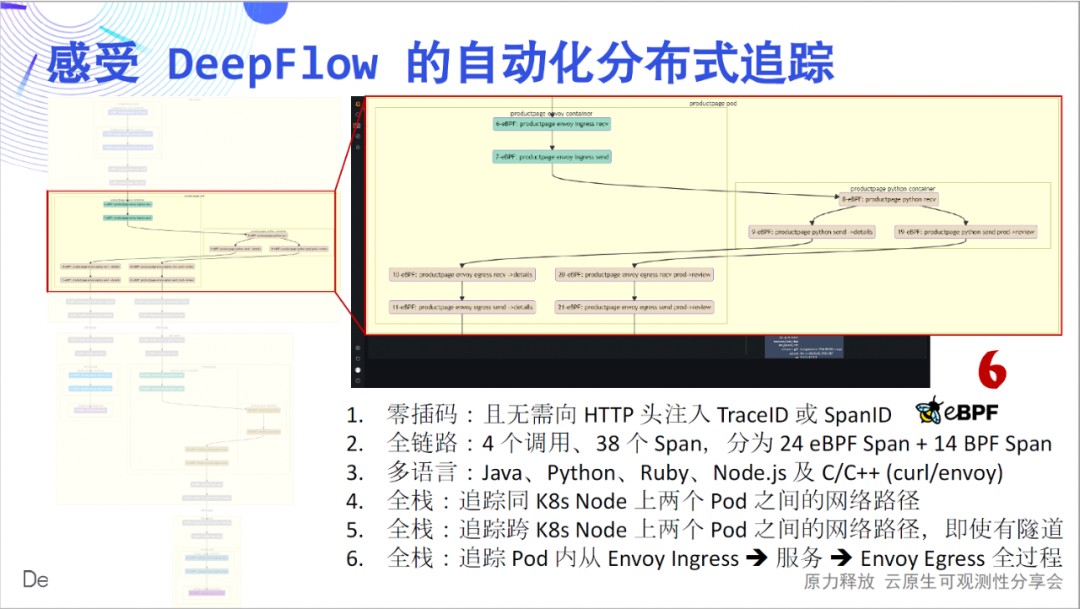
全栈,还体现在 Pod 内部的流量路径上。当你使用 Envoy 时,是否被迷宫一样的流量路径所困扰?DeepFlow 能轻轻松松的打开 Pod 内部的流量路径黑盒,看的一清二楚。

回顾一下上述六点,我相信他们都是非常酷的创新,我也相信大家也会同样相信。我们的文档中也对这个 Demo 进行了详细介绍,欢迎上手体验。
既然这是一项创新的工作,初期大概率会有一些缺陷。目前我们已经能完美的解决阻塞式 IO(BIO)场景下的自动追踪,也能解决大部分负载均衡、API 网关(Nginx、HAProxy、Envoy 等)的自动追踪,他们往往都使用非阻塞式同步 IO(NIO)。但还没有搞定所有的异步 IO(AIO)场景,例如轻量级线程、协程等。我们的工作还在进行中,目前已经有了一些不错的进展。对深层次技术原理的拆解,我们计划在 QCon 2022 上与大家分享。
AutoTracing 固然好,但能力发挥到极致也难以解决对应用程序内部指定函数之间调用的追踪。幸运的是,这方面整个开源社区已经有了 10 多年的积累,从 12 年前 Google Dapper 的奠基开始,到 SkyWalking 的火热,再到今天 OpenTelemetry 的统一标准。那么 DeepFlow 和他们能产生怎样的结合呢。
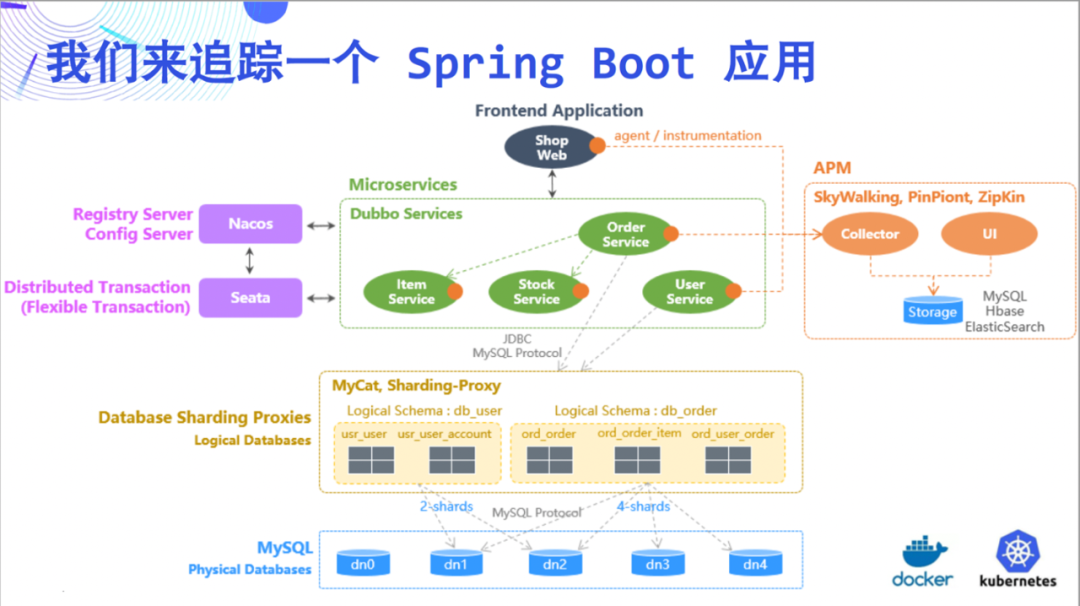
这一次,我们尝试以追踪一个 Spring
Boot 应用为例来阐述 DeepFlow 的惊艳能力。这个 Demo 比较简单,由 5 个微服务和 MySQL 组成。
我们先来看看 OpenTelemetry +
Jaeger 追踪效果,这回不是空的,页面上展示了 46 个 Span。
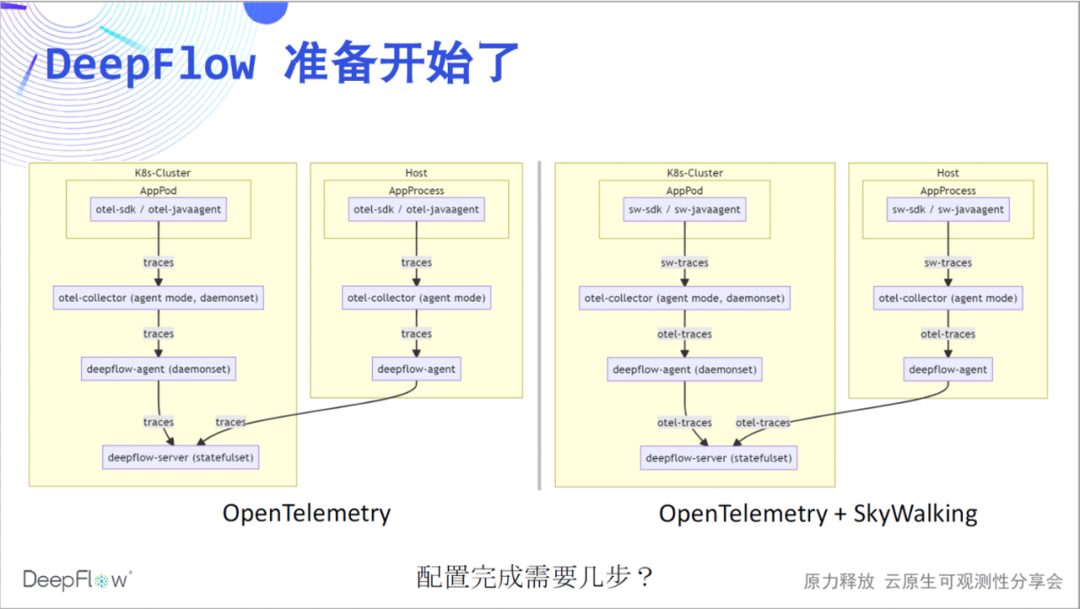
下面开始 DeepFlow 的表演了。我们推荐使用 otel-collector 的 agent 模式,将 trace 经由 deepflow-agent 发送给 deepflow-server。类似的,对 SkyWalking 数据的集成目前也通过 otel-collector 实现。大家现在可以猜想下我们需要几步完成我们的配置工作?
直播进行到现在,相信已经没有悬念了,我们两步即可打通 OpenTelemetry 和 DeepFlow。
otlphttp: traces_endpoint: "http://${HOST_IP}:38086/api/v1/otel/trace" tls: insecure: true retry_on_failure: enabled: true vtap_group_id: <your-agent-group-id> external_agent_http_proxy_enabled: 1 # 默认关闭,零端口监听
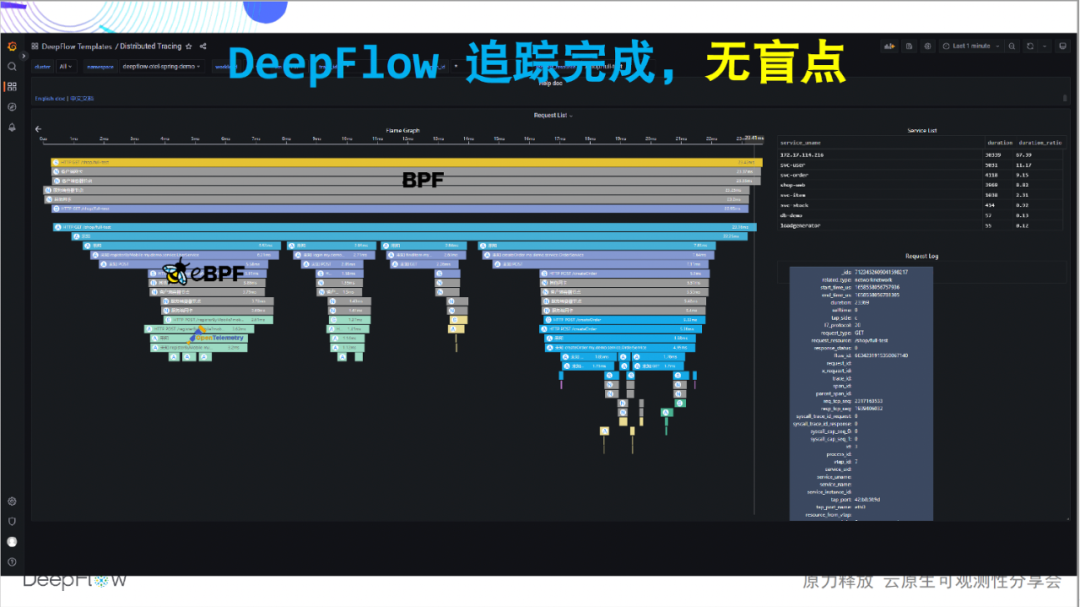
那么下面我们来感受一下 DeepFlow 的集成追踪能力,这张火焰图现在看起来平平淡淡,但却暗藏玄机,让我们一起慢慢揭开它神秘的面纱,感受无盲点追踪的震撼:全链路,是我们想传达出来的第一个感受。对比 Jaeger 显示的 46 个Span,DeepFlow 额外追踪到了 20 个 eBPF Span、30 个 BPF
Span。我们先有一个数字上的感受,更多的玄机一层一层来看。
全栈,是我们想传达出来的第二个感受。我们的网络路径追踪能力依然稳,清晰的展示了 Pod 之间的访问路径。全栈,此时同样也会展现在跨节点通信场景上,无论是否有隧道封装,无论采用何种隧道协议。
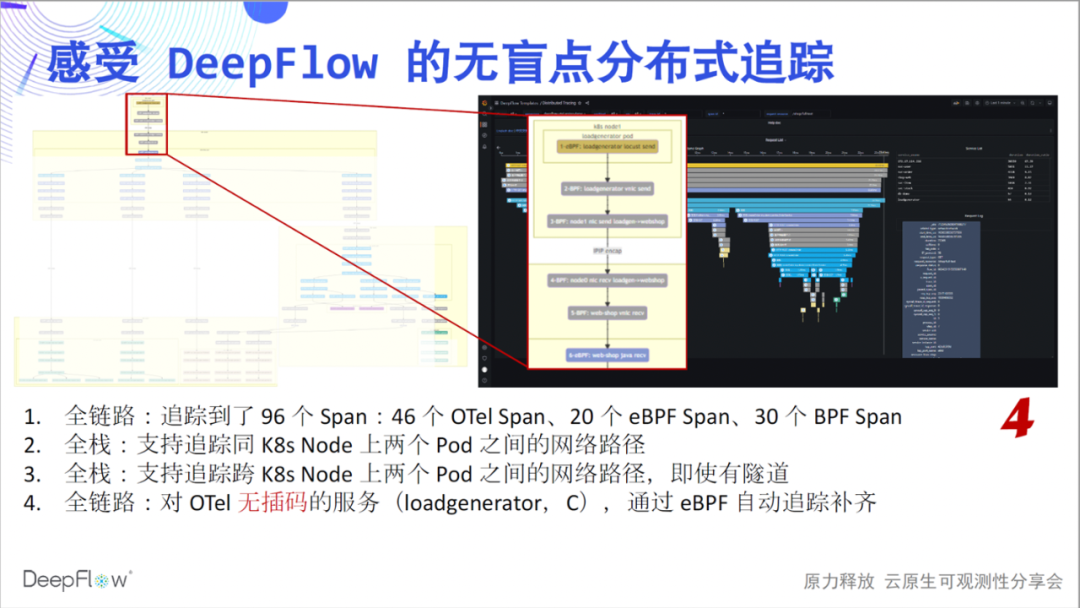
全链路,我们还想继续传达。仔细看这个图最上方的 6 个 Span。这是由于 loadgenerator 服务没有做插码,OpenTelemetry 不能给出它的追踪路径,但使用 DeepFlow 的追踪能力,自动补齐了 6 个 eBPF 及 BPF Span,整个过程不用手动做任何事情。
全链路,我们仍然想继续传达。再看图中这部分 Span,eBPF 自动发现了在一系列 OTel Span 之前和之后的两组 eBPF Span,他们是 MySQL 事务的开始和结束,非常酷。我在想如果没有疫情,我们能通过线下活动来给大家分享这些能力,会得到什么样的现场反馈。
无盲点,是我们想传达出来的第六个感受。我们看图中这段 Span,第一行的客户端调用和最后一行的服务端响应出现了显著的时差。这个时候一般上下游团队会去争吵,到底是谁的问题。DeepFlow 就像一个裁判,谈笑间回答了这里面的玄机。从图中我们能看到,靠近客户端的位置虽然 OpenTelemetry Span 的时延大,但 eBPF Span 时延明显降低了,云原生环境不再是一个黑盒,看的一清二楚。我相信大家此时应该也能感受到满满的团队协作感,再也不用争吵了。
我们的文档中也对这个 Demo 进行了详细介绍,欢迎上手体验。另一方面,我们的 AutoTagging 能力也适用于追踪数据,我们会为所有的 Span 自动注入了大量标签。我们不再需要配置过多的 otel-collector
processor 用于标签注入了,一切都是自动的、高性能的、环保的。
那么 SkyWalking 呢。目前我们可以三步配置解决 SkyWalking 数据的集成,虽然多了一步,但相信对比上面的震撼,大家不会认为很麻烦。欢迎参考我们的文档上手体验。
receivers: skywalking: protocols: grpc: endpoint: 0.0.0.0:11800 http: endpoint: 0.0.0.0:12800 service: pipelines: traces: receivers: [skywalking] spec: ports: - name: sw-http port: 12800 protocol: TCP targetPort: 12800 - name: sw-grpc port: 11800 protocol: TCP targetPort: 11800 vtap_group_id: <your-agent-group-id> external_agent_http_proxy_enabled: 1 # required
同样,我们的多集群、异构环境监控能力在追踪场景下仍然是就绪的,整个数据平台仍然不需要外部组件就能水平扩展。
是的,我们也依然还有一系列未来的工作。包括不经过 otel-collector 直接集成 SkyWalking 数据,包括集成 Sentry 数据以解锁 RUM 能力。目前我们的追踪数据通过自己实现的 Grafana Panel 来展现,我想对接 Tempo 应该是一个不错的主意。
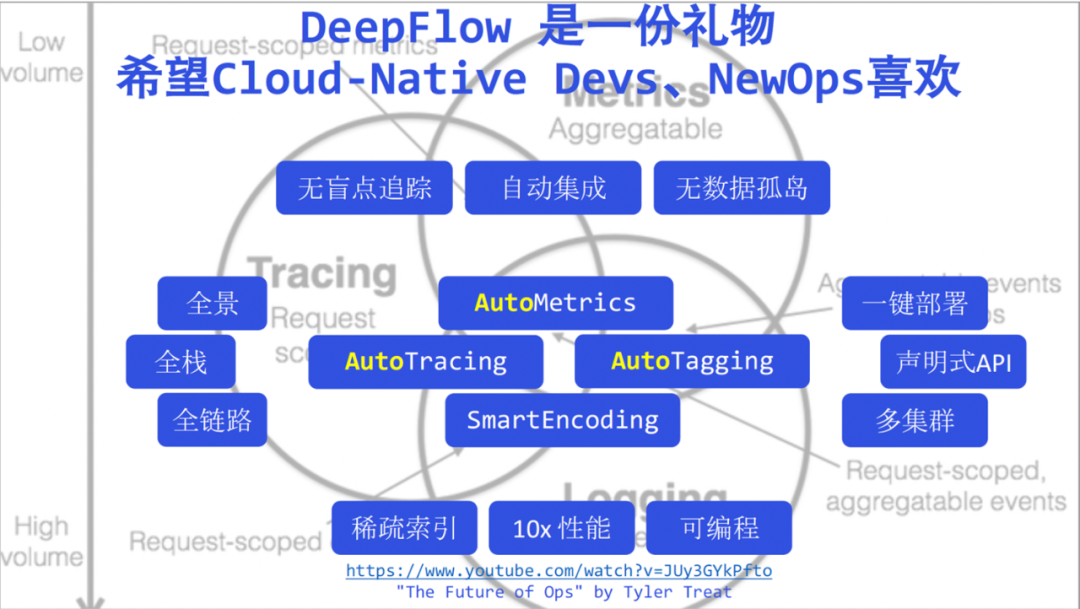
最后,作为一个回顾,我们将今天提到的 DeepFlow 关键词堆砌在这里,我不会在这里再去一个个强调这些乏力的关键词。现在我说 DeepFlow 将可观测性从此带进了高度自动化的新时代,相信大家不会再有任何疑虑了。我们相信DeepFlow 是送给新时代开发人员、运维人员的一份礼物。
我们希望开发人员能有更多的时间聚焦在业务上,将可观测性更多的交给自动化的 DeepFlow,让自己的代码更清晰整洁。这张图的下面我附带了 Tyler Treat 的演讲 —— The Future of Ops,Tyler在几年前很好的阐述了云原生时代 Ops 的挑战和机遇,我将它分享给运维同学们,在此也向 Tyler 致敬,也相信 DeepFlow 能被新时代 Ops 喜欢。
可能大家会有疑问为什么我们今天没有谈论日志。DeepFlow在这方面已经做了一部分工作,但一直对这一领域保持敬畏,下个月我们和云原生社区、阿里云 iLogTail 一起,对 DeepFlow 在日志方面的现状和计划进行介绍,欢迎大家关注。
我们希望打造一个世界级的开源可观测性平台。未来的路还有很长,就像攀登珠峰一样。如果将目前 DeepFlow 的版本号翻译成海拔,可能正好对应二号营地和三号营地之间。我们 8848 封顶见!谢谢大家!






文章评论