文末有惊喜
12.6 神经网络回归算法
12.6.1类、参数、属性和方法
类
class sklearn.neural_network.MLPRegressor(hidden_layer_sizes=100, activation='relu', *, solver='adam', alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, n_iter_no_change=10, max_fun=15000)参数
|
参数 |
解释 |
|
hidden_layer_sizes |
tuple, length = n_layers - 2, default=(100,) ith元素表示ith隐藏层中的神经元数量。 |
|
activation |
{'identity', 'logistic', 'tanh', 'relu'}, default='relu'隐藏层的激活功能。 'identity',无操作激活,用于实现线性瓶颈,返回f(x) = x 'logistic',即logistic sigmoid函数,返回f(x) = 1 / (1 + exp(-x))。 'tanh',双曲tan函数,返回f(x) = tanh(x)。 'relu'是已校正的线性单位函数,返回f(x) = max(0,x) |
|
solver |
{'lbfgs', 'sgd', 'adam'}, default='adam'重量优化求解器。 'lbfgs'是拟牛顿方法家族中的优化器。 'sgd'指随机梯度下降。 'adam'指的是由金马、迪德里克和吉米巴提出的基于梯度的随机优化器注意:就训练时间和验证分数而言,默认解算器'adam'在相对较大的数据集(有数千个或更多的训练样本)上工作得相当好。然而,对于小数据集,'lbfgs'可以更快地收敛,性能更好。 |
|
alpha |
float, default=0.0001。L2惩罚(正则项)参数。 |
属性
|
属性 |
类别 |
介绍 |
|
loss_ |
float |
用损耗函数计算的电流损耗。 |
|
best_loss_ |
float |
求解器在整个拟合过程中达到的最小损失。 |
|
loss_curve_ |
list of shape (n_iter_,) |
列表中的第i个元素表示第i次迭代的损失。 |
|
t_ |
int |
拟合期间解算器看到的训练样本数。 |
|
coefs_ |
list of shape (n_layers - 1,) |
列表中的第i个元素表示与第i层对应的权重矩阵。 |
|
intercepts_ |
list of shape (n_layers - 1,) |
列表中的第i个元素表示对应于层i+1的偏置向量。 |
|
n_iter_ |
int |
解算器已运行的迭代次数。 |
|
n_layers_ |
int |
层数。 |
|
n_outputs_ |
int |
输出数量。 |
|
out_activation_ |
str |
输出激活函数的名称。 |
|
loss_curve_ |
list of shape (n_iters,) |
在每个训练步骤结束时评估损失值。 |
|
t_ |
int |
数学上等于n iters*X.shape[0],表示时间步长,由优化器的学习率调度器使用。 |
方法
|
fit(X, y) |
将模型拟合到数据矩阵X和目标y。 |
|
get_params([deep]) |
获取此估计器的参数。 |
|
predict(X) |
采用多层感知器模型进行预测。 |
|
score(X, y[, sample_weight]) |
返回预测的确定系数R2。 |
|
set_params(**params) |
设置此估计器的参数。 |
12.6.2神经网络回归算法
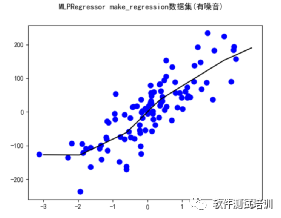
def MLPRegressor_make_regression():warnings.filterwarnings("ignore")myutil = util()X,y = datasets.make_regression(n_samples=100,n_features=1,n_informative=2,noise=50,random_state=8)X_train,X_test,y_train,y_test = train_test_split(X, y, random_state=8,test_size=0.3)clf = MLPRegressor(max_iter=20000).fit(X,y)title = "MLPRegressor make_regression数据集(有噪音)"myutil.draw_line(X[:,0],y,clf,title)
def My_MLPRegressor(solver,hidden_layer_sizes,activation,level,alpha,mydata,title):warnings.filterwarnings("ignore")myutil = util()X,y = mydata.data,mydata.targetX_train,X_test,y_train,y_test = train_test_split(X, y, random_state=8,test_size=0.3)clf = MLPRegressor(solver=solver,hidden_layer_sizes=hidden_layer_sizes,activation=activation,alpha=alpha,max_iter=10000).fit(X_train,y_train)mytitle = "MLPRegressor("+title+"):solver:"+solver+",node:"+str(hidden_layer_sizes)+",activation:"+activation+",level="+str(level)+",alpha="+str(alpha)myutil.print_scores(clf,X_train,y_train,X_test,y_test,mytitle)def MLPRegressor_base():mydatas = [datasets.load_diabetes(), datasets.load_boston()]titles = ["糖尿病数据","波士顿房价数据"]for (mydata,title) in zip(mydatas, titles):ten = [10]hundred = [100]two_ten = [10,10]Parameters = [['lbfgs',hundred,'relu',1,0.0001], ['lbfgs',ten,'relu',1,0.0001], ['lbfgs',two_ten,'relu',2,0.0001],['lbfgs',two_ten,'tanh',2,0.0001],['lbfgs',two_ten,'tanh',2,1]]for Parameter in Parameters:My_MLPRegressor(Parameter[0],Parameter[1],Parameter[2],Parameter[3],Parameter[4],mydata,title)
输出
MLPRegressor(糖尿病数据):solver:lbfgs,node:[100],activation:relu,level=1,alpha=0.0001:68.83%MLPRegressor(糖尿病数据):solver:lbfgs,node:[100],activation:relu,level=1,alpha=0.0001:28.78%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10],activation:relu,level=1,alpha=0.0001:53.50%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10],activation:relu,level=1,alpha=0.0001:45.41%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:relu,level=2,alpha=0.0001:68.39%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:relu,level=2,alpha=0.0001:31.62%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=0.0001:64.18%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=0.0001:31.46%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=1:-0.00%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=1:-0.01%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[100],activation:relu,level=1,alpha=0.0001:90.04%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[100],activation:relu,level=1,alpha=0.0001:63.90%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10],activation:relu,level=1,alpha=0.0001:85.23%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10],activation:relu,level=1,alpha=0.0001:68.49%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:relu,level=2,alpha=0.0001:90.12%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:relu,level=2,alpha=0.0001:63.48%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=0.0001:18.19%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=0.0001:18.25%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=1:85.37%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=1:
73.75%
|
数据 |
solver |
node |
activation |
level |
alpha |
训练得分 |
测试得分 |
|
糖尿病 |
lbfgs |
[100] |
relu |
1 |
0.0001 |
68.83% |
28.78% |
|
lbfgs |
[10] |
relu |
1 |
0.0001 |
53.50% |
45.41% |
|
|
lbfgs |
[10,10] |
relu |
2 |
0.0001 |
68.39% |
31.62% |
|
|
lbfgs |
[10,10] |
tanh |
2 |
0.0001 |
64.18% |
31.46% |
|
|
lbfgs |
[10,10] |
tanh |
2 |
1 |
-0.00% |
-0.00% |
|
|
波士顿房价 |
lbfgs |
[100] |
relu |
1 |
0.0001 |
90.04% |
63.90% |
|
lbfgs |
[10] |
relu |
1 |
0.0001 |
85.23% |
68.49% |
|
|
lbfgs |
[10,10] |
relu |
2 |
0.0001 |
90.12% |
63.48% |
|
|
lbfgs |
[10,10] |
tanh |
2 |
0.0001 |
18.19% |
18.25% |
|
|
lbfgs |
[10,10] |
tanh |
2 |
1 |
85.37% |
73.75% |
文末惊喜
渗透式测试环境与代码
实验代码:
链接:https://pan.baidu.com/s/14XsCng6laiSiT_anuwr5dw?pwd=78dy
提取码:78dy
环境
Windows上安装tomcat、Apache和MySQL
Linux上安装tomcat、Apache和MySQL
操作
1、把tomcat中的sec拷贝到tomcat目录下,比如%TOMCAT-HOME%\webapps\
2、把Apache中的sec拷贝到Apache目录下,比如\htdocs\
3、tomcat中的sec目录下
include.jsp
<%StringWindows_IP="127.0.0.1";StringLinux_IP="192.168.0.150";StringJSP_PORT="8080";StringPHP_PORT="8100";%>
-
String Windows_IP:Windows的IP地址
-
String Linux_IP:Linux的IP地址
-
String JSP_PORT:JSP的端口号
-
String PHP_PORT:PHP的端口号
3、Apache中的sec目录下include.php
$windows_ip="http://127.0.0.1";$linux_ip="http://192.168.0.150";$jsp_port="8080";$php_port="8100";?>
-
$windows_ip:Windows的IP地址
-
$linux_ip=:Linux的IP地址
-
$jsp_port=:JSP的端口号
-
$php_port:PHP的端口号
打开浏览,输入http://192.168.0.106:8080/sec/
192.168.0.106为本机IP地址
数据库配置
在建立MySQL下建立sec数据库,root/123456。将DB下的4个csv文件导入sec数据库中
渗透测试操作系统虚拟机文件vmx文件
1)Windows 2000 Professional
链接:https://pan.baidu.com/s/13OSz_7H1mIpMKJMq92nEqg?pwd=upsm
提取码:upsm
2)Windows Server 2003 Standard x64 Edition
链接:https://pan.baidu.com/s/1Ro-BoTmp-1kq0W_lB9Oiww?pwd=ngsb
提取码:ngsb
开机密码:123456
3)Windows 7 x64
链接:https://pan.baidu.com/s/1-vLtP58-GXmkau0OLNoGcg?pwd=zp3o
提取码:zp3o
4)Debian 6(Kali Linux)
链接:https://pan.baidu.com/s/1Uw6SXS8z_IxdkNpLr9y0zQ?pwd=s2i5
提取码:s2i5
开机密码:jerry/123456
安装了Apatche、Tomcat、MySQL、 vsftpd并且配套Web安全测试练习教案。
启动Tomcat
#/usr/local/apache-tomcat-8.5.81/bin/startup.sh
启动MySQL
#service mysql start
启动Apache
#/etc/init.d/apache2 start
打开浏览器输入127.0.0.1:8080/sec/
5)Metasploitable2-Linux (with vsftpd 2.3.4)
链接:https://pan.baidu.com/s/1a71zOXGi_9aLrXyEnvkHwQ?pwd=17g6
提取码:17g6
开机密码:见页面提示
解压后直接为vmx文件,直接可用

文章评论