Python lambdas are little, anonymous functions, subject to a more restrictive but more concise syntax than regular Python functions.
Taken literally, an anonymous function is a function without a name. In Python, an anonymous function is created with the lambda keyword. More loosely, it may or not be assigned a name.
-
stateless,无状态,处理输入数据的过程中数据不变; -
immutable,不改变输入数据,每个函数都返回新数据集。
-
没有状态就没有伤害 -
并行执行无伤害 -
Copy-Paste 重构代码无伤害 -
函数的执行没有顺序上的问题
-
first class function(头等函数),因此函数可以像变量一样被创建、修改,并当成变量一样传递、返回,或是在函数中嵌套函数; -
map & reduce,函数式编程最常见的技术就是对一个集合做 Map 和 Reduce 操作。如果是传统过程式语言,需要使用 for/while 循环,并创建临时变量,因此函数式编程在代码上要更容易阅读; -
pipeline(管道),将函数实例成一个一个的 action,然后将一组 action 放到一个数组或是列表中,再把数据传给这个 action list,数据就像一个 pipeline 一样顺序地被各个函数所操作,最终得到我们想要的结果; -
recursing(递归),递归最大的好处就是简化代码,它可以把一个复杂的问题用很简单的代码描述出来。注意:递归的精髓是描述问题,而这正是函数式编程的精髓; -
currying(柯里化),将一个函数的多个参数分解成多个函数, 然后将函数多层封装起来,每层函数都返回一个函数去接收下一个参数,这可以简化函数的多个参数; -
higher order function(高阶函数),所谓高阶函数就是函数当参数,把传入的函数做一个封装,然后返回这个封装函数。现象上就是函数传进传出,就像面向对象满天飞一样。这个技术用来做 Decorator 很不错。
// 非函数式,不是pure funciton,有状态int cnt;void increment(){cnt++;}
// 函数式,pure function, 无状态int increment(int cnt){return cnt+1;}
(1 + 2) * 3 - 4var a = 1 + 2;var b = a * 3;var c = b - 4;
var result = subtract(multiply(add(1,2), 3), 4);-
把函数当成变量来用,关注描述问题而不是怎么实现,这样可以让代码更易读; -
因为函数返回里面的这个函数,所以函数关注的是表达式,关注的是描述这个问题,而不是怎么实现这个事情。
lambda arguments: expressiondef identity(x):return x
lambda x: x-
关键字,lambda -
变量,bound variable,x -
函数体,x
> import dis> add_lambda = lambda x, y: x + y> type(add_lambda)<class 'function'>> dis.dis(add_lambda)1 0 LOAD_FAST 0 (x)2 LOAD_FAST 1 (y)4 BINARY_ADD6 RETURN_VALUE> add_lambda<function <lambda> at 0x00000201B792D0D0>
> def add_def(x, y): return x + y> type(add_def)<class 'function'>> dis.dis(add_def)1 0 LOAD_FAST 0 (x)2 LOAD_FAST 1 (y)4 BINARY_ADD6 RETURN_VALUE> add_def<function add_def at 0x00000201B7927E18>
> div_zero = lambda x: x / 0> div_zero(2)Traceback (most recent call last):File "<stdin>", line 1, in <module>File "<stdin>", line 1, in <lambda>ZeroDivisionError: division by zero
> def div_zero(x): return x / 0> div_zero(2)Traceback (most recent call last):File "<stdin>", line 1, in <module>File "<stdin>", line 1, in div_zeroZeroDivisionError: division by zero
> add_one = lambda x: x + 1> add_one(2)3
Another pattern used in other languages like JavaScript is to immediately execute a Python lambda function. This is known as an Immediately Invoked Function Expression (IIFE, pronounce “iffy”).
(lambda x: x + 1)(2)3
上面的匿名函数中有一个参数,实际上也可以没有参数或有多个参数。
> hello = lambda : "hello world"> hello()'hello world'
full_name = lambda first, last: f'Full name: {first.title()} {last.title()}'full_name('guido', 'van rossum')'Full name: Guido Van Rossum'
-
不支持语句,比如赋值语句; -
不支持多条表达式,仅支持单条表达式; -
不支持类型注解。
-
expression,表达式,仅支持标识符、字面量与运算符,生成至少一个值,因此只能作为右值; -
statement,语句,通常由表达式组成,用一行或多行代码完成特定功能,比如赋值语句、if 语句、return 语句。
> x + 2 # an expression> x = 1 # a statement> y = x + 1 # a statement> print(y) # a statement (in 2.x)2
>>> (lambda x: return x)(2)File "<input>", line 1(lambda x: return x)(2)^SyntaxError: invalid syntax>>>>>> lambda x: int: x + 1 -> intFile "<input>", line 1lambda x: int: x + 1 -> int^SyntaxError: invalid syntax
-
将匿名函数赋值给变量,像普通函数调用; -
将 lambda 嵌套到普通函数中,lambda 函数本身做为 return 的值; -
将 lambda 函数作为参数传递给其他函数。
Lambda functions are frequently used with higher-order functions, which take one or more functions as arguments or return one or more functions.
> f = lambda x, y, z: x * y * z> f(2, 3, 4)24
def f(x, y, z):return x * y * z
def add(n):return lambda x: x + nf = add(1)f(2)3
def high_ord_func(x, func: Callable):return x + func(x)
high_ord_func = lambda x, func: x + func(x)high_ord_func(2, lambda x: x * x)6high_ord_func(2, lambda x: x + 3)7
list(filter(lambda x: x % 2 == 0, [1, 2, 3, 4, 5, 6]))[2, 4, 6]
-
Classic Functional Constructs,如 map()、filter()、functools.reduce(); -
Key Functions,如 sort()、sorted() 。
Lambda functions are regularly used with the built-in functions map() and filter(), as well as functools.reduce(), exposed in the module functools.
-
map(function, iterable, ...),根据提供的函数对指定序列做映射; -
filter(function, iterable),根据提供的函数对指定序列做过滤; -
reduce(function, iterable[, initializer]),根据提供的函数对指定序列中两两相邻元素做累积;
# Python 2.xfrom collections import Iterable, Iteratorisinstance(map(lambda x: x.upper(), ['cat', 'dog', 'cow']), Iterable)Trueisinstance(map(lambda x: x.upper(), ['cat', 'dog', 'cow']), Iterator)False# Python 3.xfrom collections import Iterable, Iteratorisinstance(map(lambda x: x.upper(), ['cat', 'dog', 'cow']), Iterable)Trueisinstance(map(lambda x: x.upper(), ['cat', 'dog', 'cow']), Iterator)True
# mapping list by functionlist(map(lambda x: x.upper(), ['cat', 'dog', 'cow']))['CAT', 'DOG', 'COW']# filter list by functionlist(filter(lambda x: 'o' in x, ['cat', 'dog', 'cow']))['dog', 'cow']# aggregate list by functionfrom functools import reducereduce(lambda acc, x: f'{acc} | {x}', ['cat', 'dog', 'cow'])'cat | dog | cow'
Higher-order functions like map(), filter(), and functools.reduce() can be converted to more elegant forms with slight twists of creativity, in particular with list comprehensions or generator expressions.
# convert to list comprehension[x.upper() for x in ['cat', 'dog', 'cow']]['CAT', 'DOG', 'COW'][x for x in ['cat', 'dog', 'cow'] if 'o' in x]['dog', 'cow']
Generator expressions are especially useful with functions like sum(), min(), and max() that reduce an iterable input to a single value.
reduce(lambda x, y: x + y, [3, 1, 2])6# convert to generator expressionsum(x for x in [3, 1, 2])6
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
>> square_list = [n** 2 for n in range(5)]>> square_list[0, 1, 4, 9, 16]>> square_generator = (n** 2 for n in range(5))>> square_generator<generator object <genexpr> at 0x00000286B8671F90>
Key functions in Python are higher-order functions that take a parameter key as a named argument. key receives a function that can be a lambda.
-
sort(key, reverse),根据提供的函数对调用列表做排序; -
sorted(iterable[, key[, reverse]]),根据提供的函数对指定序列做排序。
-
key 用于指定进行比较的元素,只有一个参数,用于指定可迭代对象中的一个元素进行排序; -
reverse 用于指定排序规则,reverse = True 降序 , reverse = False 升序(默认)。
> ss = [(10, "Tom", ), (8, "Jack"), (5, "David")]# order by age (default desc)> ss.sort(key=lambda x: x[1])> ss[(5, 'David'), (8, 'Jack'), (10, 'Tom')]> sorted(ss, key=lambda x: x[1], reverse=True)[(10, 'Tom'), (8, 'Jack'), (5, 'David')]
-
解析查询条件 -
获取数据 -
判断数据是否满足查询条件
> table.search(User.name == 'shawn')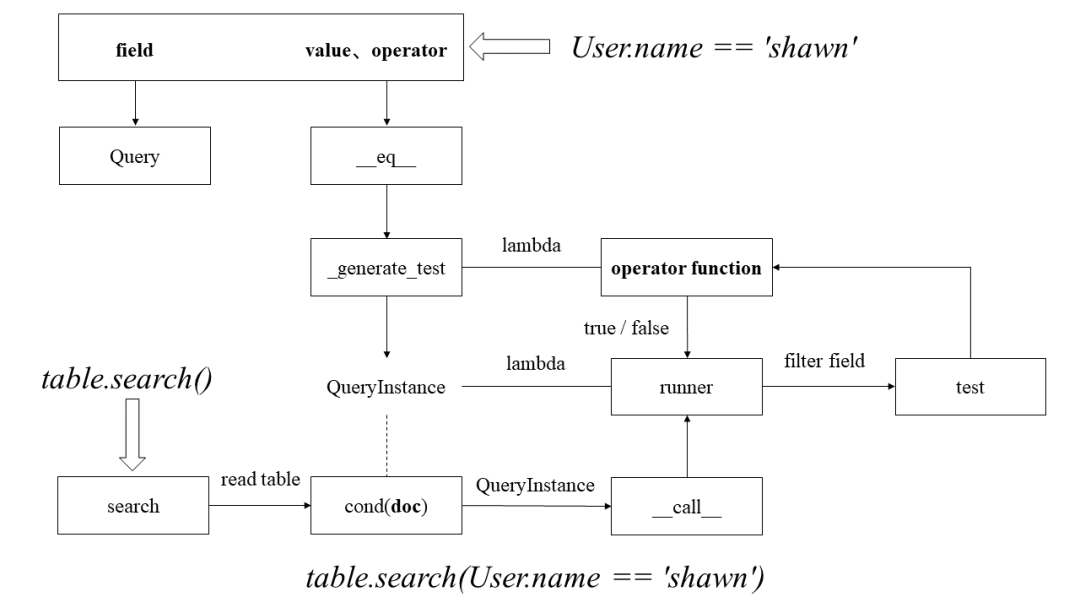
-
将查询条件 User.name == 'shawn' 转换成查询函数 lambda value: value == 'shawn',并将其保存在 QueryInstance 对象中。注意现在还并不知道具体表的数据; -
获取要查询的数据表,然后调用 cond(doc) 方法判断是否满足查询条件; -
由于 QueryInstance 类实现了 __call__() 方法,因此实际是传入表中数据并调用查询函数 lambda value: value == 'shawn'(doc.name)。
class Query(QueryInstance):def __eq__(self, rhs: Any):return self._generate_test(lambda value: value == rhs,('==', self._path, freeze(rhs)))
def __eq__(self, rhs: Any):def temp(value):return value == rhsreturn self._generate_test(temp,('==', self._path, freeze(rhs)))
def _generate_test(self,test: Callable[[Any], bool],hashval: Tuple,allow_empty_path: bool = False) -> QueryInstance:def runner(value):...# Perform the specified testreturn test(value)return QueryInstance(lambda value: runner(value),(hashval if self.is_cacheable() else None))
-
Classic Functional Constructs,如 map()、filter()、functools.reduce(),不过通常可以转换成列表推导式或生成器表达式;
-
Key Functions,如 sort()、sorted() 。
-
函数式编程
def generate_power(exponent):def power(base):return base ** exponentreturn power
def generate_power_lambda(exponent):return lambda base: base ** exponent
-
map 方法中自动调用 submit 方法,因此无需提前使用 submit 方法; -
map 方法中自动调用 result 方法,返回值是 result 的迭代器,而 as_completed 方法的返回值是 Future 实例对象的迭代器; -
map 方法中任务返回的顺序与任务提交的顺序一致,而 as_completed 方法中任务返回的顺序与任务提交的顺序可能不一致。
from concurrent.futures import ThreadPoolExecutorfrom my_thread.tasks import get_htmldef main():# 线程池初始化executor = ThreadPoolExecutor(max_workers=2)# 通过 submit 函数提交要执行的函数到线程池中,submit函数立即返回,不阻塞task1 = executor.submit(get_html, 3)task2 = executor.submit(get_html, 2)task3 = executor.submit(get_html, 2)# 主线程阻塞直到任务执行结束print(task1.result())print(task2.result())print(task3.result())
from concurrent.futures import as_completeddef main():pool = ThreadPoolExecutor(max_workers=2)urls = [3, 2, 4]all_task = [pool.submit(get_html, url) for url in urls]for future in as_completed(all_task):data = future.result()print("in main thread, result={}".format(data))
def main():pool = ThreadPoolExecutor(max_workers=2)urls = [3, 2, 4]for result in pool.map(get_html, urls):print(result)
def map(self, fn, *iterables, timeout=None, chunksize=1):"""Returns an iterator equivalent to map(fn, iter)."""fs = [self.submit(fn, *args) for args in zip(*iterables)]def result_iterator():try:# reverse to keep finishing orderfs.reverse()while fs:# Careful not to keep a reference to the popped futureif timeout is None:yield fs.pop().result()else:yield fs.pop().result(end_time - time.time())finally:for future in fs:future.cancel()return result_iterator()
-
How to Use Python Lambda Functions
-
Lambda Function in Python – How and When to use?
-
左耳听风:编程范式游记(4)- 函数式编程
-
阮一峰:函数式编程初探
-
python中lambda的用法
-
Python 之 lambda 函数完整详解 & 巧妙运用

文章评论