美国时间2022年5月7日,Go 1.19版本开发分支进入新特性冻结(freeze)阶段,即只能修Bug,不能再向Go 1.19版本中增加新特性了。由于上一个版本Go 1.18因引入泛型改动较大,推迟了一个月发布,这直接导致了Go 1.19版本的开发周期被缩短。
虽然开发周期少了近一个月,但Go 1.19版本仍然会按计划在2022年8月份发布。而Go 1.19的第一个beta版也于今天凌晨发布了。Go 1.19版本都有哪些重要变化呢,我通过这篇文章带大家先睹为快。
注1:版本特性变化以最终发布为准!注2:本文仅是前瞻,不会过于深入细节。细节待Go 1.19正式发布后再聊。
泛型问题的fix
尽管Go核心团队在Go 1.18泛型上投入了很多精力,但Go 1.18发布后泛型这块依然有已知的天生局限,以及后续逐渐发现的一些问题,而Go 1.19版本将继续打磨Go泛型,并重点fix Go 1.18中发现的泛型问题。目前Go 1.19开发版本中大约有5-6个泛型问题待解决。之前谈到的可能放开一些泛型约束,在Go 1.19估计不会如期兑现了。
不过可以确定的是Go 1.19将包含Go语法规范中的一处关于泛型的修正,即由下面表述:
The scope of an identifier denoting a type parameter of a function or declared by a method receiver is the function body and all parameter lists of the function.(译文:一个用于表示函数的类型参数或由方法接收器声明的类型参数的标识符的作用域范围包括函数体和函数的所有形式参数列表。)
改为下面更新版的表述:
The scope of an identifier denoting a type parameter of a function or declared by a method receiver starts after the function name and ends at the end of the function body.(译文:一个用于表示函数的类型参数或由方法接收器声明的类型参数的标识符的作用域始于函数名,终止于函数体末尾。)
这样一个改动,使得原本在当前版本Go编译器(Go 1.18.x)下编译报错的源码,在Go 1.19版本中可以正常编译通过:
type T[T any] struct {}func (T[T]) m() {} // error: T is not a generic type
修订Go memory model
Go memory model是Go文档中最抽象的一篇,没有之一!随着Go的演进,原先的Go memory model描述有很多地方不够正式,也缺少对一些同步机制的说明,如atomic等。
这次修订,参考了Hans-J. Boehm和Sarita V. Adve在“Foundations of the C++ Concurrency Memory Model,(PLDI 2008)”中对C++ memory model的描述方式,对Go memory model做了更正式的整体描述,增加了对multiword竞态、runtime.SetFinalizer、更多sync类型、atomic操作以及编译器优化方面的描述。
修订go doc comment格式
Go内置了将comment直接提取为包文档的能力,这与其他语言通过第三方工具生成文档不同。go doc comment为Gopher提供了很大便利。但go doc comment设计于2009年,有些过时。对很多呈现形式的支持不够或缺少更为精确的格式描述,这次Russ Cox主导了go doc comment的修订,增加了对超链、列表、标题、标准库API引用等格式支持,修订后的go doc comment并非markdown语法,但从markdown语法中做了借鉴,同时兼容老comment格式。下面是Russ Cox提供的一些新doc comment的渲染后的效果图:

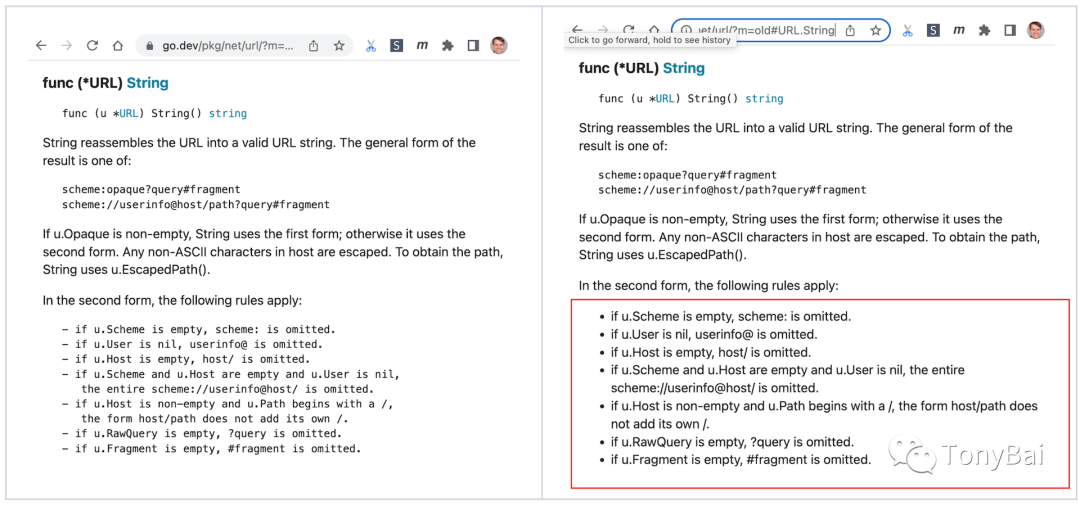
同时,Go团队还提供了go/doc/comment包,gopher使用它可以轻松解析go doc comment。
runtime.SetMemoryLimit
在Go1.19中,一个新的runtime.SetMemoryLimit函数以及一个GOMEMLIMIT环境变量被引入。有了这个memory软限制,Go运行时将通过限制堆的大小,以及更积极地将内存返回给底层os,来试图维持这个内存限制,以尽量避免Go程序因分配heap过多,超出系统内存资源限制而被kill。
默认memory limit是math.MaxInt64。一旦通过SetMemoryLimit自行设定limit,那么Go运行时将尊重这个memory limit,通过调整GC回收频率以及及时将内存返还给os来保证go运行时掌控的内存总size在limit之下。
注意:limit限制的是go runtime掌控的内存总量,对于开发者自行从os申请的内存(比如通过mmap)则不予考虑。limit的具体措施细节可以参考该proposal design文档。
另外要注意的是:该limit不能100%消除out-of-memory的情况。
Go 1.19在启动时将默认提高打开文件的限值
经调查,一些系统对打开的文件数量设置了一个人为的soft限制, 主要是为了与使用select和其硬编码的最大文件描述符(由 fd_set 的大小限制)的代码兼容。通常限制为1024,有的更小,比如256。这样即便是gofmt这样的简单程序,当它们并行地遍历一个文件树时,也很容易遇到打开文件描述符超量的错误。
Go不使用select,所以它不应该受这些限制的影响。于是对于导入os包的go程序,Go将在1.19中默认提高这些限制值到hard limit。
Go 1.19 race detector将升级到v3版thread sanitizer
升级后的新版race detector的race检测性能相对于上一版将提升1.5倍-2倍,内存开销减半,并且没有对goroutine的数量的上限限制。
注:thread sanitizer检测数据竞态的工作原理:记录每一个内存访问的信息,并检测线程对这块内存的访问是否存在竞争。基于这种原理,我们也可以知道一旦开启race detect,Go程序的执行效率将受到很大影响,运行的开销将大幅增加。v3版thread sanitizer虽然得到了优化,但对程序的总体影响还是存在的并且依旧很大。
Go 1.19增加"unix" build tag
Go 1.19将增加"unix"构建标签:
//go:build unix等价于
//go:build aix || linux || darwin || dragonfly || freebsd || openbsd || netbsd || solaris不过要注意,"*_unix.go"还保留原语义,不能被识别,以便向后兼容现有文件,尤其是go标准库之外的使用。
标准库的一些变化
net软件包将使用EDNS
在Go 1.19中,net软件包将使用EDNS来增加DNS数据包的大小,以遵守现代DNS标准和实现。这应该有助于解决一些DNS服务器的问题。
flag包增加TextVar函数
Go flag包增加TextVar函数,这样flag包便可以与任何实现了encoding.Text{Marshaler,Unmarshaler}的Go类型集成。比如:
flag.TextVar(&ipaddr, "ipaddr", net.IPv4(192, 168, 0, 1), "what server to connect to?") // 与net.IPv4类型flag.TextVar(&start, "start", time.Now(), "when should we start processing?") // 与time.Time类型
其它
-
在linux上,Go正式支持64位龙芯cpu架构 (GOOS=linux, GOARCH=loong64)。
-
当Go程序空闲时,Go GC进入到周期性的GC循环的情况下(2分钟一次),Go运行时现在会在idle的操作系统线程上安排更少的GC worker goroutine,减少空闲时Go应用对os资源的占用。
-
Go行时将根据goroutine的历史平均栈使用率来分配初始goroutine栈,避免了一些goroutine的最多2倍的goroutine栈空间浪费。
-
sync/atomic包增加了新的高级原子类型Bool, Int32, Int64, Uint32, Uint64, Uintptr和Pointer,提升了使用体验。
-
Go 1.19中Go编译器使用jump table重新实现了针对大整型数和string类型的switch语句,平均性能提升20%左右。
小结
相对于Go 1.18,Go 1.19的确是一个“小版本”。但Go 1.19对memory model的更新、SetMemoryLimit的加入、go doc comment的修订以及对go runtime的持续打磨依然可以让gopher们产生一丝丝“小兴奋”,尤其是SetMemoryLimit的加入,是否能改善Go应用因GC不及时被kill的情况呢,让我们拭目以待。


文章评论