
本文系东北大学在读博士生方伯阳所著,本篇也是 OceanBase 学术系列稿件第五篇。
「方伯阳:东北大学计算机科学与工程学院在读博士生,主要研究方向是数据存储与管理相关,现在正在 AI4DB 的基数估计领域中努力探索。」
今天分享的论文是 —— Learned Cardinality Estimation: A Design Space Exploration and A Comparative Evaluation. PVLDB, 15(1): 85 - 97, 2022. doi:10.14778/3485450.3485459
希望阅读完本文,你可以对学习型基数有新的收获,当然也可以有不同看法,欢迎在底部留言探讨。
今天分享的这篇论文是李国良教授的团队今年发表的一篇综述,主要内容是从现有的学习型基数估计论文中抽象出 3 种统一工作流程,并对各个种类的基数估计方法中选择效果明显的几种作为代表,从多个方面进行全面的测试。
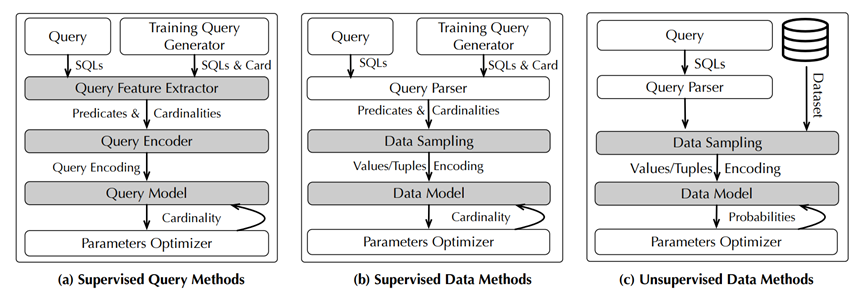
图1. 不同方法的统一工作流程

统一工作流程
首先是对查询的建模,数据库 D 中,在一个查询 Q 和它对应的基数|Q(D)|直接学习一个映射模型 f(Q)。这一类模型把基数估计问题作为ML中的典型回归问题,并且这类模型只能是有监督的。图 a 是这种模型的统一工作流。首先是模型训练。所有有监督的基数估计方法都需要构造一个训练查询生成器,在模式中采样查询表和列,再从谓词的每一列中采样值。还需要建立一个统一的参数优化器训练模型,以及查询特征提取器,查询编码器和查询模型。具体来说查询特征提取器首先决定哪些特征在一个查询中对于基数估计是有用的,然后查询编码器需要将所有特征编码在单独的向量中,如使用 one-hot 编码,在这之后选用合适的查询模型建模。其次是模型推理,推理阶段的过程与训练阶段的过程是相同的。训练数据是一个三元组的集合,元组包括一个查询,数据集,和真实的基数。
然后是对数据的建模,这一类方法是将基数估计视为密度估计问题,为每个数据点学习联合数据分布。给定一个 SQL 查询,这类方法抽样满足这个查询的数据点,然后把这些被抽样的数据点的概率相加估计基数。通常来说有 2 种方法学习数据分布,分别是有监督的和无监督的。有监督的是使用 SQL 查询和对应的真实基数来训练模型,而无监督的是直接使用数据训练。在训练完模型后,估计一个模型的基数通常通过均匀采样元组,并估计在样本中被选中的元组的累积概率。
b 图显示了有监督数据模型的统一工作流。在模型训练中,也需要和有监督查询方法同样的训练查询生成器,此外有一个统一的查询转换器,对于任意元组可以把查询谓词中命中的输出 1 否则输出 0。在这种方法中,首先通过数据采样模块使用随机采样或基于查询的采样从数据集中抽样,然后基于这些样本建立数据模型。在模型推理阶段,数据抽样模块可以选择一个不同于训练阶段使用的抽样方法,所有被命中样本的累计密度被用于估计选中率,从此可以简单地推导出基数。对于连接查询,相关模块可以根据不同的连接模式联合模型或进行连接分解。
c 图显示了无监督数据模型的统一工作流。在模型训练阶段,这种方法也使用了和有监督数据方法同样的查询转换器,数据抽样模块首先均匀地抽样合理数量的数据集,然后将数据输入数据模型学习数据分布。如果数据集的规模太大无法全放在内存中,还要考虑在线抽样。无监督的模型推理阶段与有监督数据方法的模型推理阶段一样。

实验设计
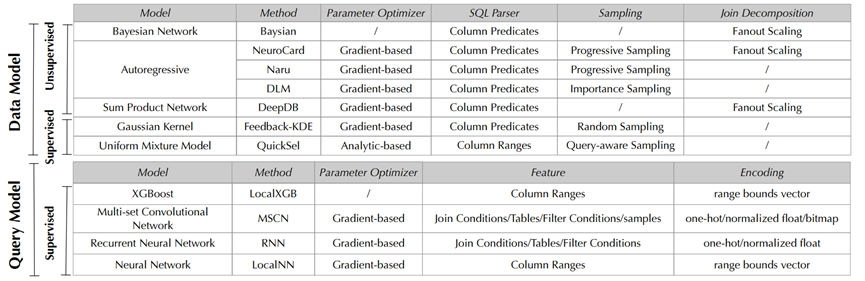
图2. 高水平学习型基数估计方法的总结
图 2 显示了接下来的实验中使用到的,每一个种类中最优秀的几个学习型基数估计方法(Bayesian[1], NeuroCard[9], Naru[10], DLM[2], DeepDB[4], Feedback-KDE[3], Quicksel[8], LocalXGB[6], MSCN[5], LocalNN[7]),以及每种方法对应的参数优化器,查询转换器,抽样方法,连接分解方法,特征提取器和编码器。
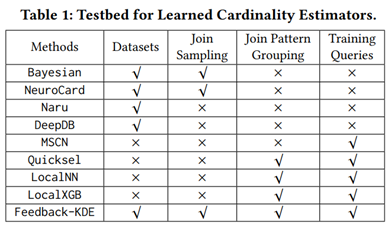
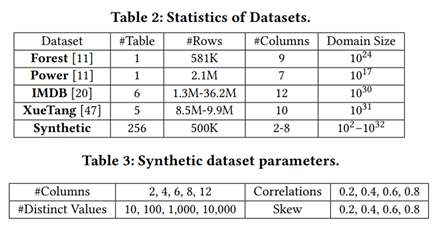
表 1 中打对号的表示被测的每类方法所需要的技术。后续实验所用数据集包含真实数据集和合成数据集,如表 2 所示,前 4 种为真实数据集。前 2 个(Forest, Power)[11] 被广泛用于基数估计的测试,其数据格式全部为整数,这些数据集的使用主要是为了可以将实验集中于性能分析。IMDB[12] 数据集的特点是其高偏斜和高相关性的特征,常用于连接操作的查询优化和开销估计的测试。XueTang[13] 是一个关于在线教育的真实世界 OLTPbenchmark。合成数据集根据表3中的四个方面的参数产生 256 个不同的数据集。使用 q-error 作为性能评估的一项指标。总共进行了 9 组实验,实验一比较了这些学习型方法在真实数据集上的结果;实验二研究了数据集中列的数量会如何影响学习型方法的正确率;实验三测试了独立值的数量如何影响学习型方法的正确率;实验四比较了列之间的不同相关性对学习型方法的正确率的影响;实验五研究了列中数据的偏斜程度对各类方法正确率的影响;实验六讨论了训练集的大小会如何影响有监督方法的正确率;实验七是关于连接抽样的大小如何影响无监督方法的正确率;实验八对比了各个方法在训练过程和推理过程中的效率;实验九的内容是关于各个方法增量数据更新的效率。

实验结果和分析
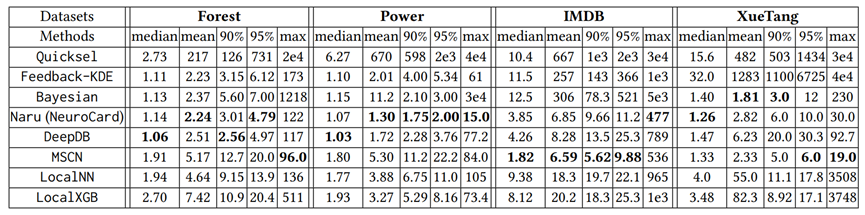
表4. 在真实数据集上所有方法的正确率对比
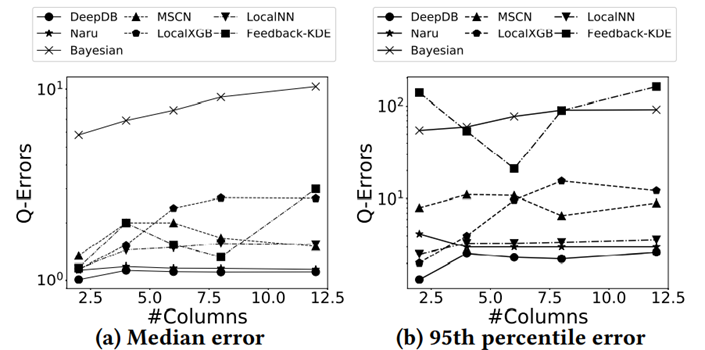
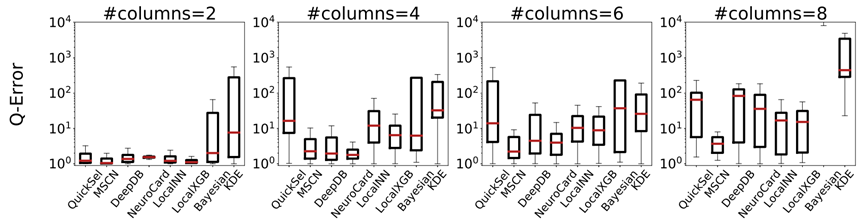
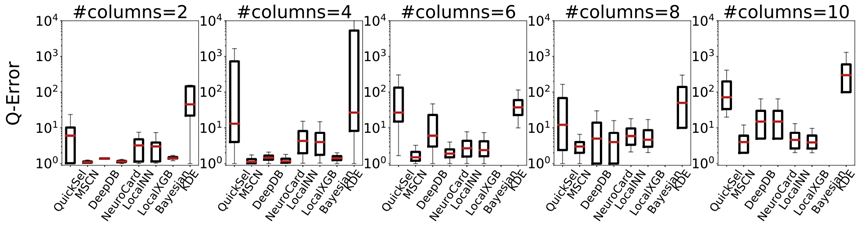
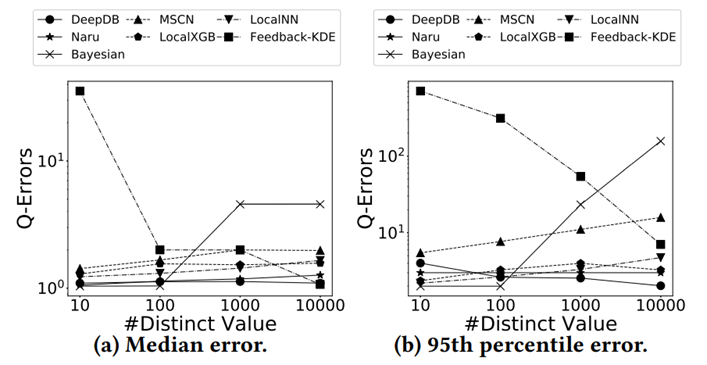
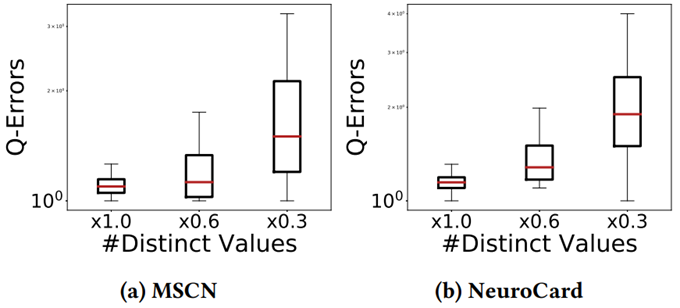
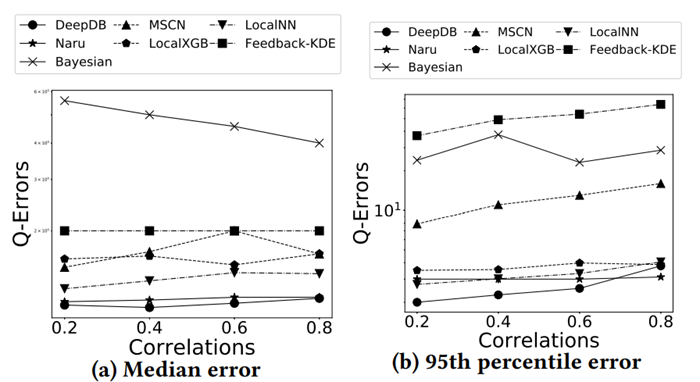
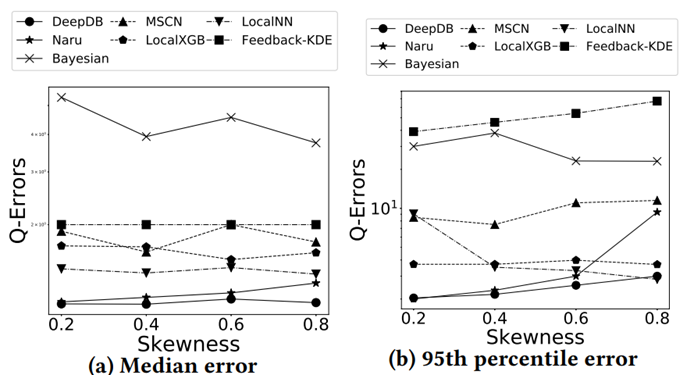
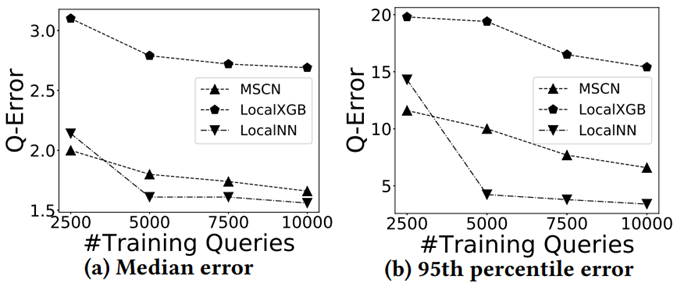
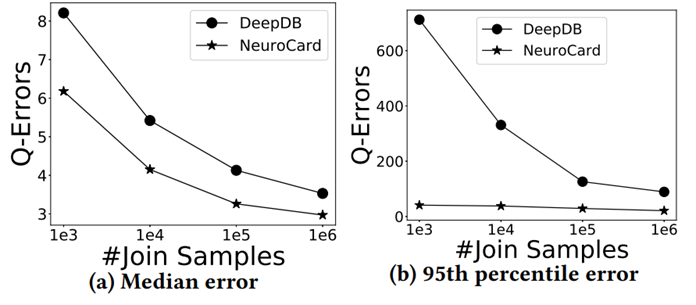
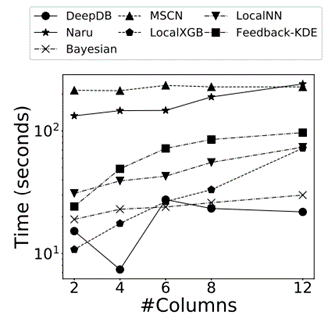
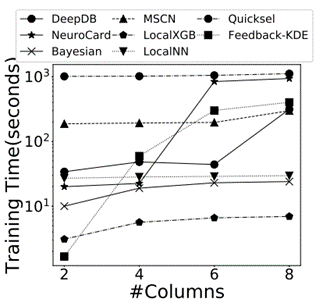
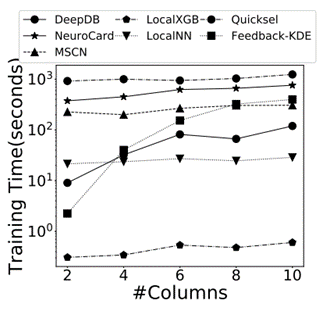
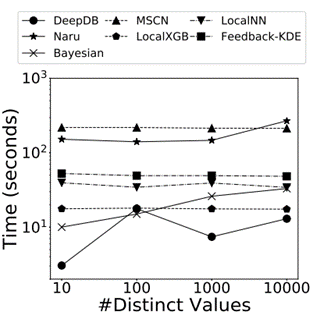
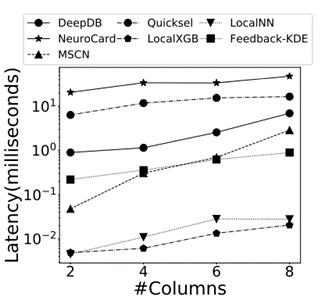
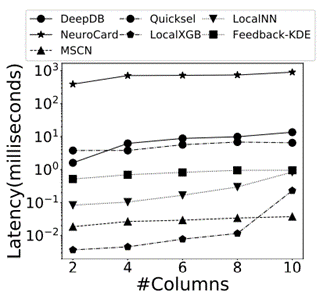
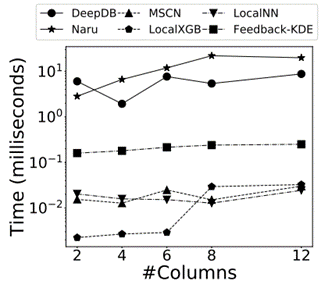
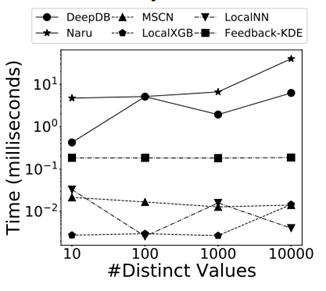
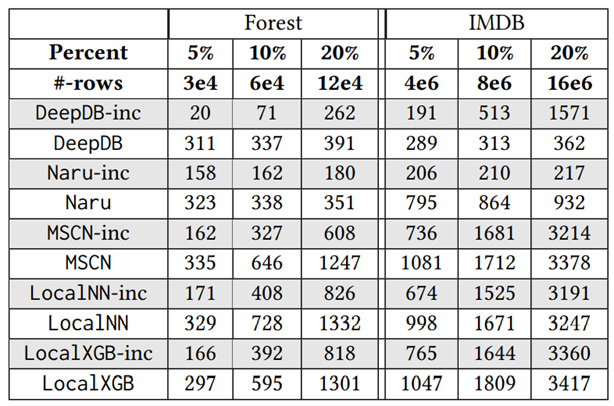

最后这篇论文总结出了关于学习的基数估计方法有关的 8 条发现:
*参考文献:
[1]Getoor, L., Taskar, B., and Koller, D. Selectivity estimation using probabilistic models. In Proceedings of the 2001 ACM SIGMOD international conference on Management of data, Santa Barbara, CA, USA, May 21-24, 2001 (2001), S. Mehrotra and T. K. Sellis, Eds., ACM, pp. 461–472.
[2]Hasan, S., Thirumuruganathan, S., Augustine, J., Koudas, N., and Das, G. Deep learning models for selectivity estimation of multi-attribute queries. In Proceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020 (2020), D. Maier, R. Pottinger, A. Doan, W. Tan, A. Alawini, and H. Q. Ngo, Eds., ACM, pp. 1035–1050.
[3]Heimel, M., Kiefer, M., and Markl, V. Self-tuning, gpu-accelerated kernel density models for multidimensional selectivity estimation. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Victoria, Australia, May 31 - June 4, 2015 (2015), T. K. Sellis, S. B. Davidson, and Z. G. Ives, Eds., ACM, pp. 1477–1492.
[4]Hilprecht, B., Schmidt, A., Kulessa, M., Molina, A., Kersting, K., and Binnig, C. Deepdb: Learn from data, not from queries! Proc. VLDB Endow. 13, 7 (2020), 992–1005.
[5]Kipf, A., Kipf, T., Radke, B., Leis, V., Boncz, P. A., and Kemper, A. Learned cardinalities: Estimating correlated joins with deep learning. In 9th Biennial Conference on Innovative Data Systems Research, CIDR 2019, Asilomar, CA, USA, January 13-16, 2019, Online Proceedings (2019), www.cidrdb.org.
[6]Tzoumas, K., Deshpande, A., and Jensen, C. S. Lightweight graphical models for selectivity estimation without independence assumptions. Proc. VLDB Endow. 4, 11 (2011), 852–863.
[7]Ortiz, J., Balazinska, M., Gehrke, J., and Keerthi, S. S. An empirical analysis of deep learning for cardinality estimation. CoRR abs/1905.06425 (2019).
[8]Park, Y., Zhong, S., and Mozafari, B. Quicksel: Quick selectivity learning with mixture models. In Proceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020 (2020), D. Maier, R. Pottinger, A. Doan, W. Tan, A. Alawini, and H. Q. Ngo, Eds., ACM, pp. 1017–1033.
[9]Yang, Z., Kamsetty, A., Luan, S., Liang, E., Duan, Y., Chen, P., and Stoica, I. Neurocard: One cardinality estimator for all tables. Proc. VLDB Endow. 14, 1 (2020), 61–73.
[10]Yang, Z., Liang, E., Kamsetty, A., Wu, C., Duan, Y., Chen, P., Abbeel, P., Hellerstein, J. M., Krishnan, S., and Stoica, I. Deep unsupervised cardinality estimation. Proc. VLDB Endow. 13, 3 (2019), 279–292.
[11]Dua, D., and Graff, C. UCI machine learning repository, 2017.
[12]IMDb.com. https://www.imdb.com/, 2019.
[13]XueTang, T. https://www.xuetangx.com/global, 2019.


文章评论