
机器学习发展迅猛,但对理论知识的理解却跟不上?本文将给出一名数据科学家的反思,他通过效用矩阵梳理了模型的实验结果和基础理论的关系,并探讨机器学习各个子领域的进展。
引入
博客原文
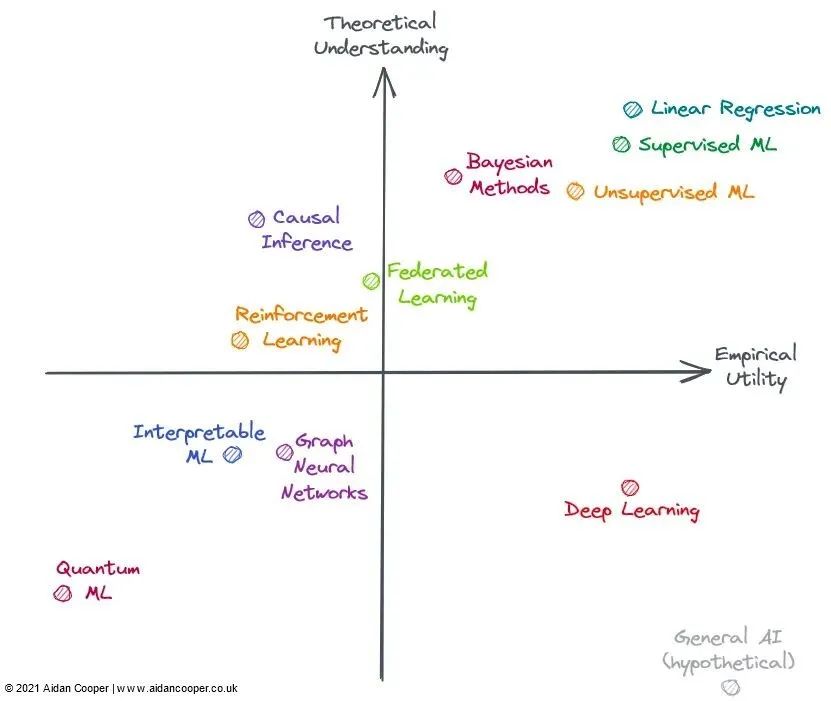
2022 年的机器学习领域
右上象限:高理解、高效用
右下象限:低理解,高效用
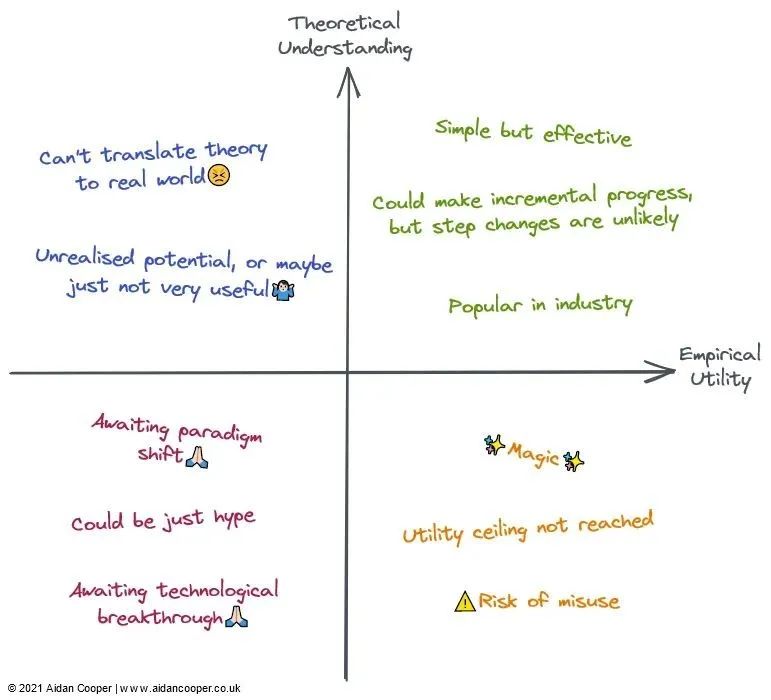
左上象限:高理解,低效用
左下象限:低理解,低效用
渐进式进步、技术飞跃和范式转变
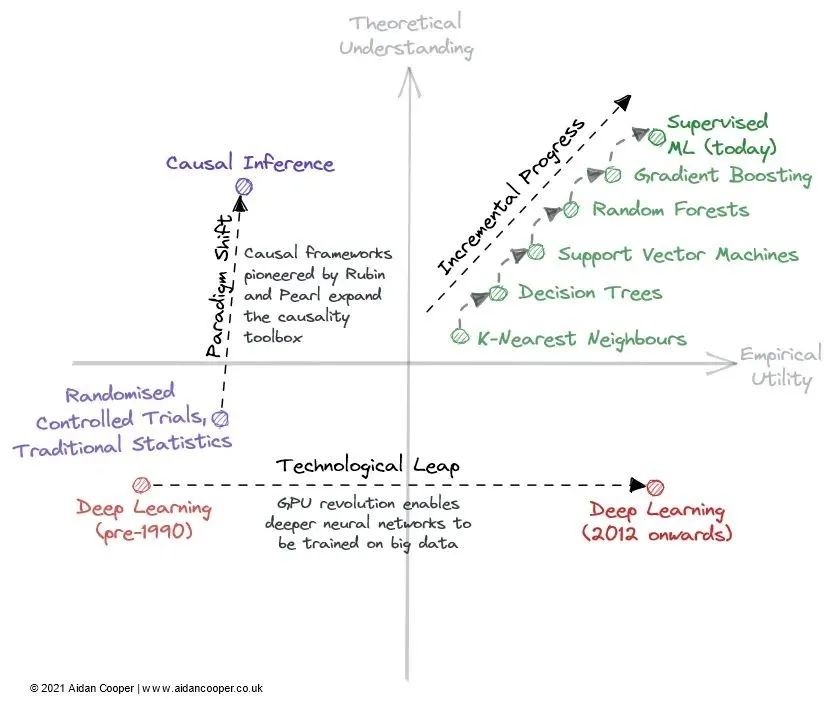
预测和深度学习的科学革命
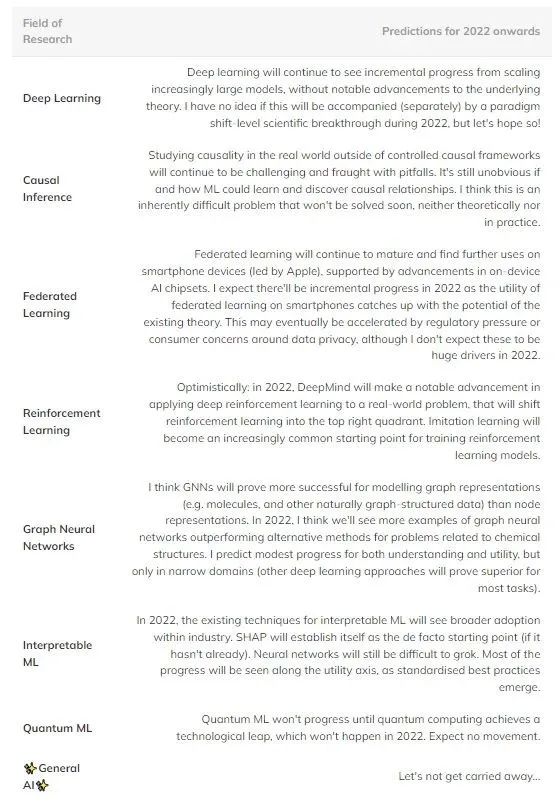
表 1:机器学习几大领域未来进展预测。
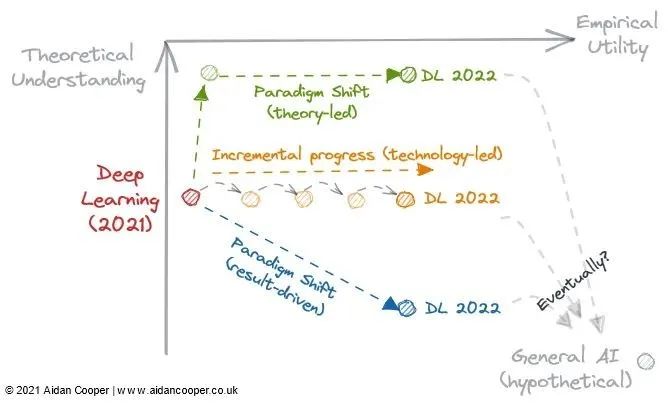
图 3:2022 年深度学习发展的 3 个潜在轨迹。
-
理论突破是否会让我们的理解赶上实用性,并将深度学习转变为像传统机器学习一样更有条理的学科?
-
现有的深度学习文献是否足以让效用无限地增加,仅仅通过扩展越来越大的模型?
-
或者,一个经验性的突破会带领我们进一步深入兔子洞,进入一种增强效用的新范式,尽管我们对这种范式了解得更少?
-
这些路线中的任何一条都通向通用人工智能吗?
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


文章评论