往期推荐
安装
pip install pandas目录
1、Pandas在工作中的使用
2、常用函数
1、Pandas在工作中的使用
2、常用函数
先创建一个excel文件
import pandas as pddata = {'city': ['北京', '上海', '广州', '深圳'],'2018': [33105, 36011, 22859, 24221]}data = pd.DataFrame(data)data.to_excel('excel练习.xlsx', index=False)
2.1、读取数据
df = pd.read_excel('excel练习.xlsx')print(df)print(type(df))print(df.values)print(type(df.values))
运行结果:
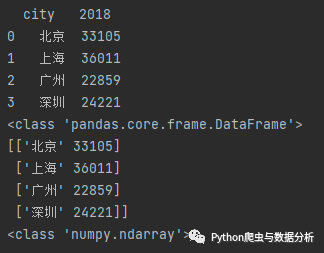
图2-1
注意:

图2-2
pd.read_excel(file_path, converters={'编号': str})读取某一列的数据
df = pd.read_excel('excel练习.xlsx')data = df['city']print(data)
运行结果:
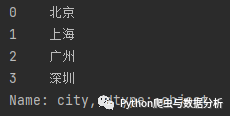
图2-3
2.2、存储数据
data = {'city': ['北京', '上海', '广州', '深圳'],'2018': [33105, 36011, 22859, 24221]}data = pd.DataFrame(data)data.to_excel('excel练习.xlsx', index=False)
2.3、删除数据
2.3.1、删除包含某值的行
data = df[df.city != '深圳']运行结果:
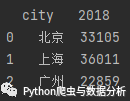
图2-4
2.3.2、删除指定行drop()
data = df.drop([0, 1], axis=0)删0、1行
运行结果:
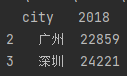
图2-5
2.3.3、删除指定列drop()
data = df.drop(['2018'], axis=1)运行结果:
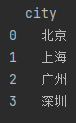
图2-6
2.3.4、去重drop_duplicates()
data.drop_duplicates(['city'])data.drop_duplicates(['city', '2018'], keep='last')
2.3.5、去0值
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川', '未知', 0],'2018': [33105, 36011, 22859, 24221, np.nan, 0, 0]}data2 = pd.DataFrame(data2)# 方法一df = data2[(data2.T != 0).any()]# 方法二df2 = data2.loc[(data2 != 0).any(1)]print(df)print('==================')print(df2)
运行结果:
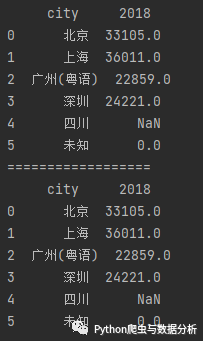
图2-7
讲解:
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川', '未知', 0],'2018': [33105, 36011, 22859, 24221, np.nan, 0, 0]}data2 = pd.DataFrame(data2)df = (data2.T != 0).any()
运行结果:
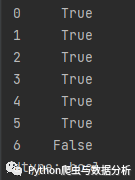
图2-8
指定列有0值就删除整行、参考2.3.1即可.
2.3.6、去空值dropna()
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川'],'2018': [33105, 36011, 22859, 24221, np.nan]}data2 = pd.DataFrame(data2)print(data2.dropna())
运行结果:
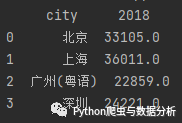
图2-9
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川'],'2018': [33105, 36011, 22859, 24221, np.nan]}data2 = pd.DataFrame(data2)print(data2.dropna(axis=1))
运行结果:
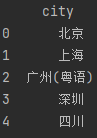
图2-10
2.4、追加数据

往期推荐
对了,看完记得一键三连呀,这个对我真的很重要。
文章评论