点击蓝字
关注我们
前言
net/http实现第一个爬虫
import ("fmt""io/ioutil""net/http")
常规请求方式
//GETresp, err := http.Get(url)//POSTresp, err := http.Post("http://example.com/upload", "image/jpeg", &buf)//PostFormresp, err := http.PostForm("http://example.com/form",url.Values{"key": {"Value"}, "id": {"123"}})复杂请求方式 当需要在请求的时候设置头参数、cookie之类的数据,就可以使用http.Do方法。
client := &http.Client{}req, _ := http.NewRequest("GET", url, nil)//(参数头设置)resp, err := client.Do(req)
参数头设置
设置请求header和cookie
req.Header.Set("User-Agent", "*****")req.Header.Set("Cookie", "****")//也可以用Add方法req.Header.Add("User-Agent", "*****")req.Header.Add("Cookie", "****")
区别:
-
当我们使用Set时候,如果原来这一项已存在,后面的就修改已有的。 -
当使用Add时候,如果原本不存在,则添加,如果已存在,就不做任何修改。
resp, err := client.Do(req)if err != nil {fmt.Println("Http get err:", err)return ""}if resp.StatusCode != 200 {fmt.Println("Http status code:", resp.StatusCode)return ""}defer resp.Body.Close()//程序在使用完回复后必须关闭回复的主体。body, err := ioutil.ReadAll(resp.Body) //ioutil.ReadAll用于读取文件或者网络请求if err != nil {fmt.Println("Read error", err)return ""}
重点注意下这两个地方
defer resp.Body.Close()//程序在使用完回复后必须关闭回复的主体。body, err := ioutil.ReadAll(resp.Body) //ioutil.ReadAll用于读取文件或者网络请求
最终调用一下定义的方法,返回请求内容
package mainimport ("fmt""io/ioutil""net/http")func fetch(url string) string {client := &http.Client{}req, _ := http.NewRequest("GET", url, nil)req.Header.Set("User-Agent", "1")req.Header.Set("Cookie", "1")resp, err := client.Do(req)//resp, err := http.Get(url)//若不需要请求头信息上边的内容换成这一条就可以了if err != nil {fmt.Println("Http get err:", err)return ""}if resp.StatusCode != 200 {fmt.Println("Http status code:", resp.StatusCode)return ""}defer resp.Body.Close()body, err := ioutil.ReadAll(resp.Body) //读取文件或者网络请求时if err != nil {fmt.Println("Read error", err)return ""}return string(body)}func main() {s := fetch("https://blog.csdn.net/weixin_54902210?type=lately")fmt.Println(s)}
解析页面
import ("fmt""io/ioutil""net/http""regexp""strings")
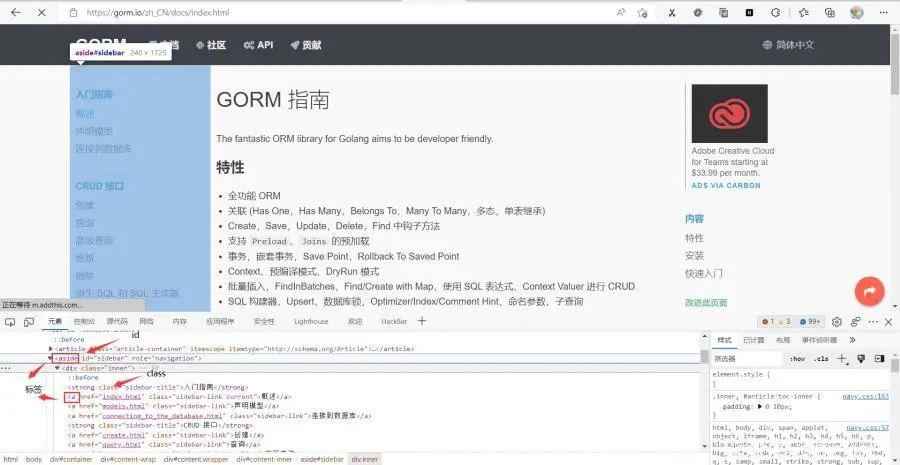
通过正则表达式获取当前页面的,边栏链接信息
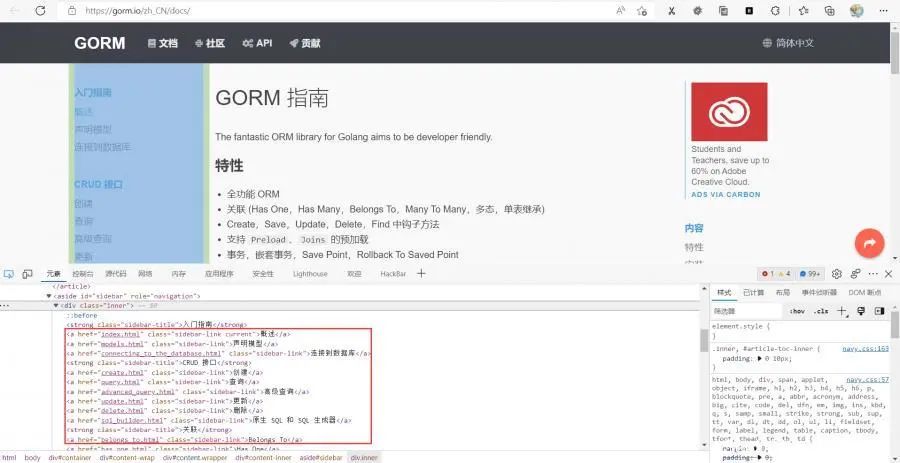
func parse(html string) {// 替换空格html = strings.Replace(html, "\n", "", -1)//正则匹配内容块r_sidebar := regexp.MustCompile(`<aside id="sidebar" role="navigation">(.*?)</aside>`)//从传入的html开始匹配sidebar := r_sidebar.FindString(html)//正则匹配链接r_link := regexp.MustCompile(`href="(.*?)"`)//从上方匹配的内容中再次匹配链接link := r_link.FindAllString(sidebar, -1)url := "https://gorm.io/zh_CN/docs/"//切片遍历链接for _, v := range link {s := v[6 : len(v)-1]url1 := url + sfmt.Println(url1)body := fetch(url)}}
加上前一部分的代码
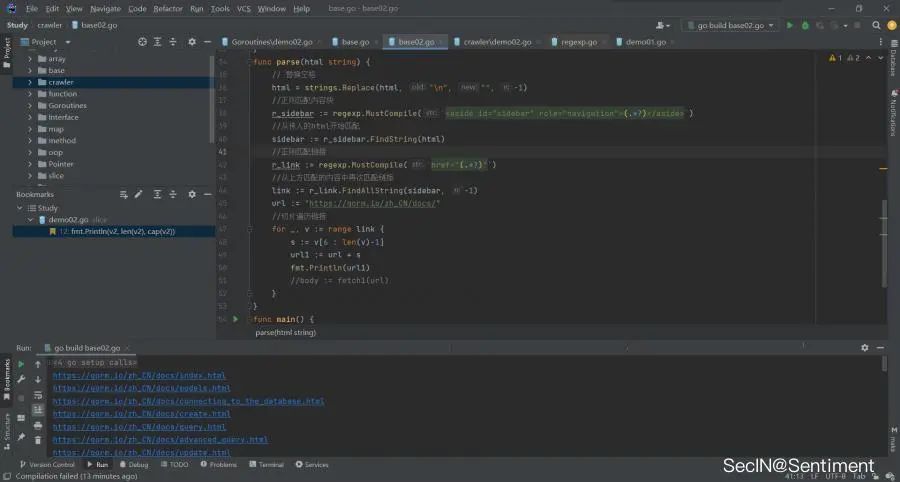
package mainimport ("fmt""io/ioutil""net/http""regexp""strings")func fetch(url string) string {client := &http.Client{}req, _ := http.NewRequest("GET", url, nil)req.Header.Set("User-Agent", "1")req.Header.Set("Cookie", "1")resp, err := client.Do(req)//resp, err := http.Get(url) //若不需要请求头信息上边的内容换成这一条就可以了if err != nil {fmt.Println("Http get err:", err)return ""}if resp.StatusCode != 200 {fmt.Println("Http status code:", resp.StatusCode)return ""}defer resp.Body.Close()body, err := ioutil.ReadAll(resp.Body) //读取文件或者网络请求时if err != nil {fmt.Println("Read error", err)return ""}return string(body)}func parse(html string) {// 替换空格html = strings.Replace(html, "\n", "", -1)//正则匹配内容块r_sidebar := regexp.MustCompile(`<aside id="sidebar" role="navigation">(.*?)</aside>`)//从传入的html开始匹配sidebar := r_sidebar.FindString(html)//正则匹配链接r_link := regexp.MustCompile(`href="(.*?)"`)//从上方匹配的内容中再次匹配链接link := r_link.FindAllString(sidebar, -1)url := "https://gorm.io/zh_CN/docs/"//切片遍历链接for _, v := range link {s := v[6 : len(v)-1]url1 := url + sfmt.Println(url1)}}func main() {s := fetch("https://gorm.io/zh_CN/docs/")parse(s)}
成功爬取边栏链接
提取各页面信息
要提取的主体内容在<div class="article">标签中,而标题在
\<h1 class="article-title" itemprop="name">,所以可以参考上方的正则提取方式,将标题提取出来
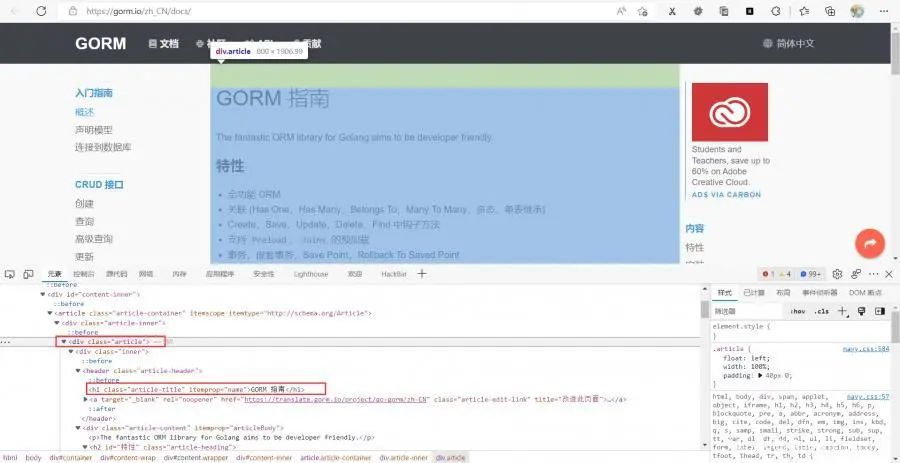
func parse2(body string) {// 替换空格body = strings.Replace(body, "\n", "", -1)//正则匹配内容块r_content := regexp.MustCompile(`<div class="article">(.*?)</div>`)//从传入的body内容匹配content := r_content.FindString(body)//正则匹配文章标题r_title := regexp.MustCompile(`<h1 class="article-title" itemprop="name">(.*?)</h1>`)//从上方匹配的内容中再次匹配标题title := r_title.FindString(content)//切片提取titletitle = title[42 : len(title)-5]fmt.Println(title)}之后就是需要调用parse2()了,在parse()的for循环最后加上:
body := fetch(url1)//启动另外一个线程处理go parse2(body)调用fetch()方法,将正则获取的url的内容解析出来赋值给body,再将body传给parse2(),获取标题内容
提取出我们想要的内容后,下一步就是保存内容了,实现起来也比较简单用的是os库
import ("fmt""io/ioutil""net/http""os""regexp""strings")
定义一个save方法
func save(title string, content string) {err := os.WriteFile("./crawler/file/"+title+".html", []byte(content), 0644)if err != nil {panic(err)}}
在parse2()的最后调用save(title, content),将标题和内容写入到文件中
package mainimport ("fmt""io/ioutil""net/http""os""regexp""strings")func fetch(url string) string {client := &http.Client{}req, _ := http.NewRequest("GET", url, nil)req.Header.Set("User-Agent", "1")req.Header.Set("Cookie", "1")resp, err := client.Do(req)//resp, err := http.Get(url) //若不需要请求头信息上边的内容换成这一条就可以了if err != nil {fmt.Println("Http get err:", err)return ""}if resp.StatusCode != 200 {fmt.Println("Http status code:", resp.StatusCode)return ""}defer resp.Body.Close()body, err := ioutil.ReadAll(resp.Body) //读取文件或者网络请求时if err != nil {fmt.Println("Read error", err)return ""}return string(body)}func parse(html string) {// 替换空格html = strings.Replace(html, "\n", "", -1)//正则匹配内容块r_sidebar := regexp.MustCompile(`<aside id="sidebar" role="navigation">(.*?)</aside>`)//从传入的html开始匹配sidebar := r_sidebar.FindString(html)//正则匹配链接r_link := regexp.MustCompile(`href="(.*?)"`)//从上方匹配的内容中再次匹配链接link := r_link.FindAllString(sidebar, -1)url := "https://gorm.io/zh_CN/docs/"//切片遍历链接for _, v := range link {s := v[6 : len(v)-1]url1 := url + sfmt.Println(url1)body := fetch(url1)//启动另外一个线程处理go parse2(body)}}func parse2(body string) {// 替换空格body = strings.Replace(body, "\n", "", -1)//正则匹配内容块r_content := regexp.MustCompile(`<div class="article">(.*?)</div>`)//从传入的body内容匹配content := r_content.FindString(body)//正则匹配文章标题r_title := regexp.MustCompile(`<h1 class="article-title" itemprop="name">(.*?)</h1>`)//从上方匹配的内容中再次匹配标题title := r_title.FindString(content)title = title[42 : len(title)-5]fmt.Println(title)save(title, content)}func save(title string, content string) {err := os.WriteFile("./crawler/file/"+title+".html", []byte(content), 0644)if err != nil {panic(err)}}func main() {s := fetch("https://gorm.io/zh_CN/docs/")parse(s)}成功写入 Goquery
goquery package -
github.com/PuerkitoBio/goquery - Go Packages
goquery为Go语言带来了一种语法和一组类似于jQuery的功能。它基于Go的net/html包和CSSSelector库cascadia。由于net/html解析器返回节点,而不是功能齐全的DOM树,因此jQuery的有状态操作函数(如height(),css(),detach())被遗漏了。Go的著名爬虫框架colly就是基于goquery实现的。
安装
go get github.com/PuerkitoBio/goquery
Goquery爬虫简单实现
创建文档
dom, err := goquery.NewDocument(url)dom, err := goquery.NewDocumentFromResponse(url)dom, err := goquery.NewDocumentFromReader(reader io.Reader)
内容查找
主要用Find()方法,个人感觉还是通过class查找方式精确一些 dom.Find("#sidebar") //通过id查找dom.Find(".sidebar-link") //通过class查找dom.Find("asideid").Find("a") //通过标签链式查找内容获取
selection.Html()selection.Text()
属性获取
selection.Attr("href")selection.AttrOr("href", "")
遍历
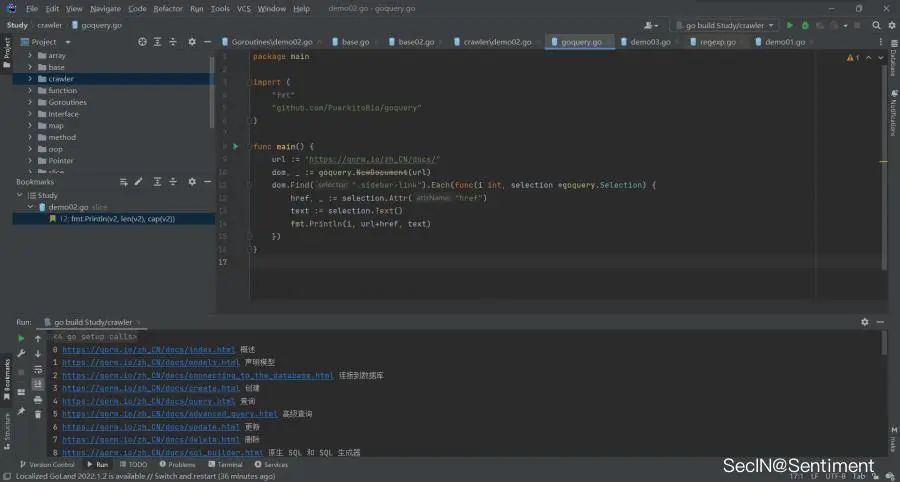
dom.Find(".sidebar-link").Each(func(i int, selection *goquery.Selection) {}
Demo
package mainimport ("fmt""github.com/PuerkitoBio/goquery")func main() {url := "https://gorm.io/zh_CN/docs/"dom, _ := goquery.NewDocument(url)dom.Find(".sidebar-link").Each(func(i int, selection *goquery.Selection) {href, _ := selection.Attr("href")text := selection.Text()fmt.Println(i, url+href, text)})}成功获取边栏链接
常见api
在爬虫的简单实现部分列举了创建文档、内容查找等方法,这里对上述用法做一点小总结
Document
GoQuery不知道要对哪个HTML文档执行操作。所以需要告诉它,这就是 Document 类的用途。它保存要操作的根文档节点,并且可以对此文档进行选择。
NewDocumentFromResponseNewDocumentFromResponse 是一个 Document 构造函数,它将 http 响应作为参数。它加载指定响应的文档,对其进行分析,并存储根文档节点,以便随时进行操作。响应的主体在返回时关闭。
这里是结合前边的http库一起使用
client := &http.Client{}req, _ := http.NewRequest("GET", url, nil)resp, _ := client.Do(req)dom, _ := goquery.NewDocumentFromResponse(resp)dom.Find(".sidebar-link").Each(func(i int, selection *goquery.Selection) {href, _ := selection.Attr("href")text := selection.Text()fmt.Println(i, url+href, text)})
NewDocumentFromReader
NewDocumentFromReader从io返回一个Document。读者。如果无法将读取器的数据解析为 html,它将返回错误作为第二个值。它不检查读取器是否也是
io。更近一点,提供的读取器永远不会被此调用关闭。如果需要,调用方有责任将其关闭。
传入的内容其实就是html的元素数据
resp, _ := http.Get(url)dom, _ := goquery.NewDocumentFromReader(resp.Body)dom.Find(".sidebar-link").Each(func(i int, selection *goquery.Selection) {href, _ := selection.Attr("href")text := selection.Text()fmt.Println(i, url+href, text)})
上述是通过http请求的方式传入的参数,并不是通过io读取,这里再用io读取举例:
f, _ := os.Open("crawler/file/Context.html")dom, _ := goquery.NewDocumentFromReader(f)dom.Find("h1").Each(func(i int, selection *goquery.Selection) {text := selection.Text()fmt.Println(text)})
除此外也可以从字符串中读取内容
data := `<html><head><title>Sentiment</title></head><body><h1>Hello</h1></body></html>`dom, _ := goquery.NewDocumentFromReader(strings.NewReader(data))dom.Find("title").Each(func(i int, selection *goquery.Selection) {text := selection.Text()fmt.Println(text)})结果: SentimentDemo package mainimport ("fmt""github.com/PuerkitoBio/goquery""net/http""os")func Document(url string) {client := &http.Client{}req, _ := http.NewRequest("GET", url, nil)resp, _ := client.Do(req)dom, _ := goquery.NewDocumentFromResponse(resp)dom.Find(".sidebar-link").Each(func(i int, selection *goquery.Selection) {href, _ := selection.Attr("href")text := selection.Text()fmt.Println(i, url+href, text)})}func Document1() {f, _ := os.Open("crawler/file/Context.html")dom, _ := goquery.NewDocumentFromReader(f)dom.Find("h1").Each(func(i int, selection *goquery.Selection) {text := selection.Text()fmt.Println(i, text)})}func main() {Document("https://gorm.io/zh_CN/docs/")Document1()}
选择器
选择表示与某些条件匹配的节点的集合,可以使用 Document.Find 创建初始选择。上边其实已经通过爬取页面举过例了,所以这里就简单看一下。
通过id查找
data := `<head><title id="t1">Sentiment</title>//id="t1"</head><body><h1 class="c1">Hello</h1></body>`dom, _ := goquery.NewDocumentFromReader(strings.NewReader(data))dom.Find("#t1").Each(func(i int, selection *goquery.Selection) {text := selection.Text()fmt.Println(text)})
通过class查找
data := `<head><title id="t1">Sentiment</title></head><body><h1 class="c1">Hello</h1>//class="c1"</body>`dom, _ := goquery.NewDocumentFromReader(strings.NewReader(data))dom.Find(".c1").Each(func(i int, selection *goquery.Selection) {text := selection.Text()fmt.Println(text)})通过标签查找 data := `<head><title id="t1">Sentiment</title>//title标签</head><body><h1 class="c1">Hello</h1></body>`dom, _ := goquery.NewDocumentFromReader(strings.NewReader(data))dom.Find("title").Each(func(i int, selection *goquery.Selection) {text := selection.Text()fmt.Println(text)})Demo package mainimport ("fmt""github.com/PuerkitoBio/goquery""strings")func getId() {data := `<head><title id="t1">Sentiment</title></head><body><h1 class="c1">Hello</h1></body>`dom, _ := goquery.NewDocumentFromReader(strings.NewReader(data))dom.Find("#t1").Each(func(i int, selection *goquery.Selection) {text := selection.Text()fmt.Println(text)})}func getClass() {data := `<head><title id="t1">Sentiment</title></head><body><h1 class="c1">Hello</h1></body>`dom, _ := goquery.NewDocumentFromReader(strings.NewReader(data))dom.Find(".c1").Each(func(i int, selection *goquery.Selection) {text := selection.Text()fmt.Println(text)})}func find() {data := `<head><title id="t1">Sentiment</title></head><body><h1 class="c1">Hello</h1></body>`dom, _ := goquery.NewDocumentFromReader(strings.NewReader(data))dom.Find("title").Each(func(i int, selection *goquery.Selection) {text := selection.Text()fmt.Println(text)})}func main() {getId()//SentimentgetClass()//Hellofind()//Sentiment}结果:
SentimentHelloSentiment
Goquery爬虫重构
http方式中,提取了页面信息并本地保存了下来,这里再用Goquery实践一下
Final Demopackage mainimport ("fmt""github.com/PuerkitoBio/goquery""os")func save(title string, content string) {err := os.WriteFile("./crawler/file1/"+title+".html", []byte(content), 0644)if err != nil {panic(err)}}func main() {url := "https://gorm.io/zh_CN/docs/"dom, _ := goquery.NewDocument(url)dom.Find(".sidebar-link").Each(func(i int, selection *goquery.Selection) {//获取链接href, _ := selection.Attr("href")text := selection.Text()fmt.Println(i, url+href, text)dom, _ = goquery.NewDocument(url + href)//获取标题title := dom.Find(".article-title").Text()//fmt.Println(title)//获取内容content, _ := dom.Find(".article").Html()//fmt.Println(content)save(title, content)})}Colly
了解了一些基础爬虫和Goquery框架后,就到了Go比较核心的爬虫框架Colly 了
colly package - github.com/gocolly/colly - Go Packages
Colly 是用于构建 Web 爬虫的 Golang 框架。使用 Colly 你可以构建各种复杂的 Web
抓取工具,从简单的抓取工具到处理数百万个网页的复杂的异步网站抓取工具。Colly 提供了一个
API,用于执行网络请求和处理接收到的内容(例如,与 HTML 文档的 DOM 树进行交互)。
安装
go get -u github.com/gocolly/colly/...
特性
-
清晰明了的 API -
速度快(单个内核上的请求数大于1k) -
管理每个域的请求延迟和最大并发数 -
自动 cookie 和会话处理 -
同步/异步/并行抓取 -
高速缓存 -
自动处理非 Unicode 编码 -
支持 Robots.txt -
支持 Google App Engine -
通过环境变量配置 -
可扩展
Colly爬虫简单实现
package mainimport ("fmt""github.com/gocolly/colly")func main() {c := colly.NewCollector()c.OnHTML(".sidebar-link", func(element *colly.HTMLElement) {element.Request.Visit(element.Attr("href"))})c.OnRequest(func(request *colly.Request) {fmt.Println(request.URL)})c.Visit("https://gorm.io/zh_CN/docs/")}
回调函数
-
OnRequest
在请求之前调用,这里只是简单打印请求的 URL。 -
OnError
如果请求期间发生错误则调用,这里简单打印 URL 和错误信息。 -
OnResponseHeaders
在收到响应标头后调用 -
OnResponse
收到回复后调用,这里也只是简单的打印 URL 和响应大小。 -
OnHTML
OnResponse如果收到的内容是HTML ,则在之后调用 -
OnXML
OnHTML如果接收到的内容是HTML或XML ,则在之后调用 -
OnScraped
OnXML回调后调用
回调顺序
OnRequest—>OnResponse—>OnHTML->OnXML—>OnScraped顺序可以用代码测试出来:
package mainimport ("fmt""github.com/gocolly/colly")func main() {c := colly.NewCollector()c.OnRequest(func(r *colly.Request) {fmt.Println("请求前调用:OnRequest")})c.OnError(func(_ *colly.Response, err error) {fmt.Println("发生错误调用:OnError")})c.OnResponse(func(r *colly.Response) {fmt.Println("获得响应后调用:OnResponse")})c.OnHTML("a[href]", func(e *colly.HTMLElement) {fmt.Println("OnResponse收到html请求后调用:OnHTML")})c.OnXML("//h1", func(e *colly.XMLElement) {fmt.Println("OnResponse收到xml内容后调用:OnXML")})c.OnScraped(func(r *colly.Response) {fmt.Println("结束", r.Request.URL)})c.Visit("https://gorm.io/zh_CN/docs/")}除此外还有一些常用方法
-
Attr(k string):返回当前元素的属性,上面示例中我们使用e.Attr("href")获取了href属性; -
ChildAttr(goquerySelector, attrName string):返回goquerySelector选择的第一个子元素的attrName属性; -
ChildAttrs (goquerySelector, attrName string): 返回goquerySelector选择的所有子元素的attrName属性,以[]string返回; -
ChildText(goquerySelectorstring): 拼接goquerySelector选择的子元素的文本内容并返回; -
ChildTexts(goquerySelector string): 返回goquerySelector选择的子元素的文本内容组成的切片,以[]string返回。 -
ForEach(goquerySelector string, callback func (int, *HTMLElement)): 对每个goquerySelector选择的子元素执行回调callback; -
Unmarshal(v interface{}):通过给结构体字段指定 goquerySelector 格式的 tag,可以将一个 HTMLElement 对象 Unmarshal 到一个结构体实例中。
参数设置
c := colly.NewCollector()//User-Agentc.UserAgent = ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36 Edg/103.0.1264.37")
设置Cookie
c.OnRequest(func(request *colly.Request) {request.Headers.Add("Cookie", "_ga=GA1.2.927242199.1656415218; _gid=GA1.2.165227307.1656415218; __atuvc=4%7C26; __atuvs=62bb96de45b68598000")})------------------------------------------------------------------//也可以使用获取到的url中的cookiecookie := c.Cookies("https://gorm.io/zh_CN/docs/")c.SetCookies("", cookie)
设置环境变量
-
COLLY_ALLOWED_DOMAINS (comma separated list of domains) -
COLLY_CACHE_DIR (string) -
COLLY_DETECT_CHARSET (y/n) -
COLLY_DISABLE_COOKIES (y/n) -
COLLY_DISALLOWED_DOMAINS (comma separated list of domains) -
COLLY_IGNORE_ROBOTSTXT (y/n) -
COLLY_FOLLOW_REDIRECTS (y/n) -
COLLY_MAX_BODY_SIZE (int) -
COLLY_MAX_DEPTH (int - 0 means infinite) -
COLLY_PARSE_HTTP_ERROR_RESPONSE (y/n) -
COLLY_USER_AGENT (string)
HTTP 配置
c := colly.NewCollector()c.WithTransport(&http.Transport{Proxy: http.ProxyFromEnvironment,DialContext: (&net.Dialer{Timeout: 30 * time.Second,KeepAlive: 30 * time.Second,DualStack: true,}).DialContext,MaxIdleConns: 100,IdleConnTimeout: 90 * time.Second,TLSHandshakeTimeout: 10 * time.Second,ExpectContinueTimeout: 1 * time.Second,})://gorm.io/zh_CN/docs/")
Colly爬虫重构
package mainimport ("fmt""github.com/gocolly/colly""os")func save2(title string, content string) {err := os.WriteFile("./crawler/file2/"+title+".html", []byte(content), 0644)if err != nil {panic(err)}}func main() {var t1 stringvar c1 stringc := colly.NewCollector()c.OnHTML(".sidebar-link", func(e *colly.HTMLElement) {href := e.Attr("href")if href != "index.html" {c.Visit(e.Request.AbsoluteURL(href))save2(t1, c1)}})c.OnHTML(".article-title", func(t *colly.HTMLElement) {title := t.Textt1 = title})c.OnHTML(".article", func(c *colly.HTMLElement) {content, _ := c.DOM.Html()c1 = content})c.OnRequest(func(request *colly.Request) {fmt.Println(request.URL.String())})c.Visit("https://gorm.io/zh_CN/docs/")}c.Visit开始访问第一个页面后,先进行OnRequest进行回调,之后当遇到class标签的值为sidebar-link时回调,并取出对应的href的值,之后再通过AbsoluteURL获取href的绝对路径,再次通过c.Visit请求,当遇到class的值为article-title,article时,再次回调对应的OnHTML函数,并将对讲的title值和content内容分别返回给全局变量t1、c1,在进行一轮回调结束后执行save2(),将内容全部写入
练习Golang的爬虫框架先了解这么多,最后以爬取Suyoleaves师傅的博客做个结尾吧 package mainimport ("fmt""github.com/gocolly/colly""os""time")func save3(title string, content string) {err := os.WriteFile("crawler/Sentiment/"+title+".html", []byte(content), 0644)if err != nil {panic(err)}}func main() {var t1 stringvar c1 stringc := colly.NewCollector()c.Limit(&colly.LimitRule{DomainRegexp: `https://www.fishfond.guru/`,Delay: 1 * time.Second,})c.OnHTML(".post-title", func(e *colly.HTMLElement) {href := e.Attr("href")//fmt.Println("href:", href)c.Visit(e.Request.AbsoluteURL(href))if href != "index.html" {c.Visit(e.Request.AbsoluteURL(href))save3(t1, c1)}})c.OnHTML("title", func(t *colly.HTMLElement) {title := t.Textt1 = string(title[0 : len(title)-12])//fmt.Println("t1:", t1)})c.OnHTML(".entry-content", func(c *colly.HTMLElement) {content, _ := c.DOM.Html()c1 = content//fmt.Println("c1", c1)})c.OnRequest(func(request *colly.Request) {fmt.Println(request.URL.String())})c.OnError(func(response *colly.Response, err error) {panic(err.Error())})c.Visit("https://www.fishfond.guru/")}往期推荐

文章评论