
import os
import sys
import ssl
import ffmpeg
import xlwings as xw
from pathlib import Path
from aip import AipSpeech
from pydub import AudioSegment
from wordcloud import WordCloud
from pydub.utils import make_chunks
from moviepy.editor import AudioFileClip
# 安装
pip install baidu-aip
# 创建项目
xlwings quickstart transcriber --standalone

import xlwings as xw
def main():
wb = xw.Book.caller()
sheet = wb.sheets[0]
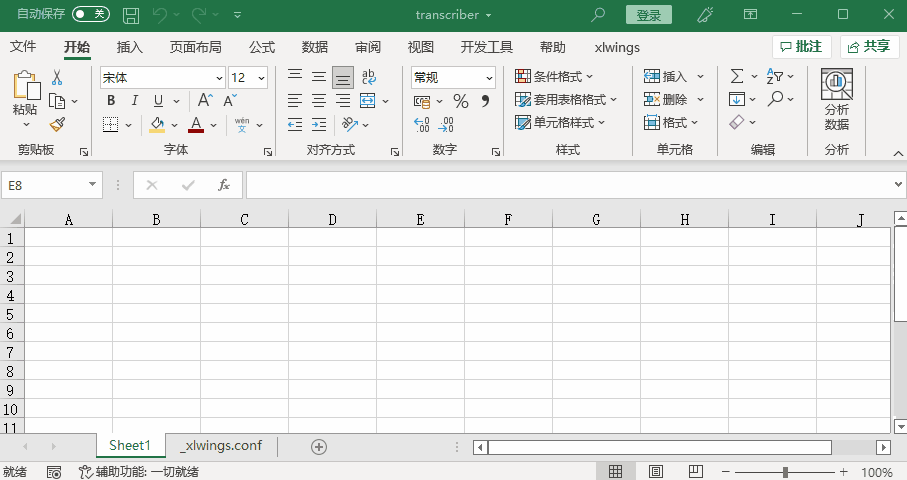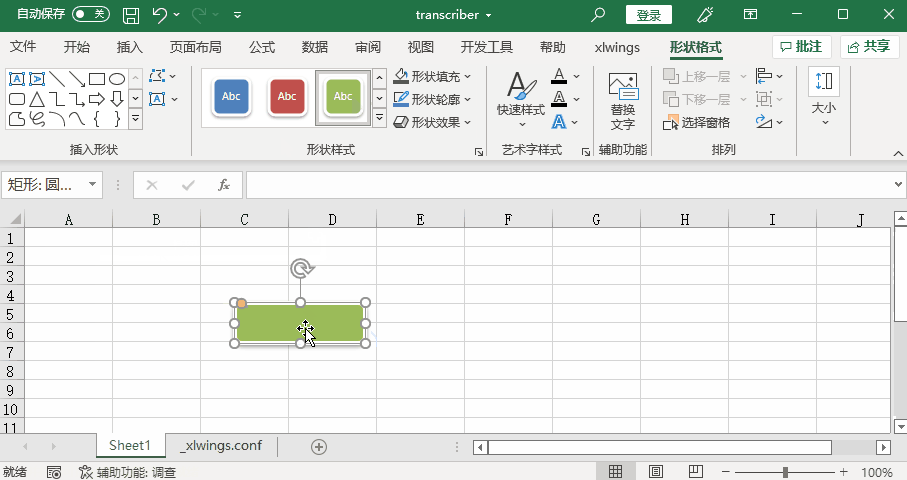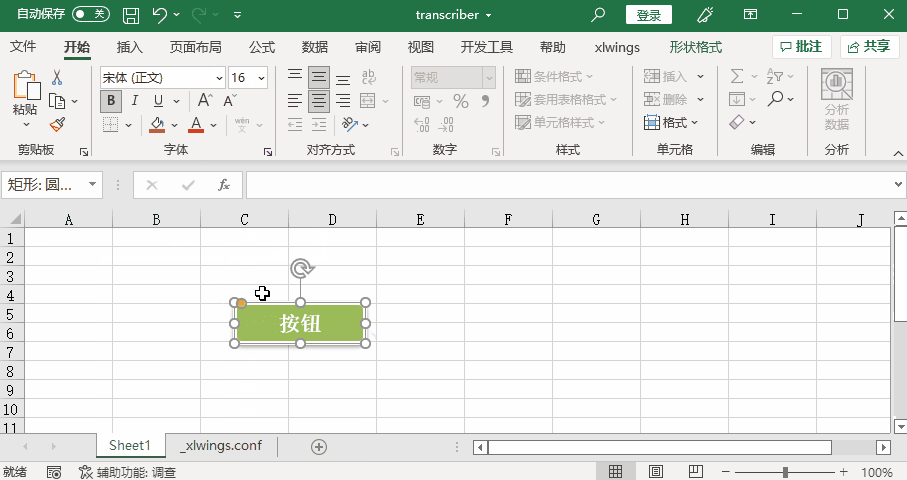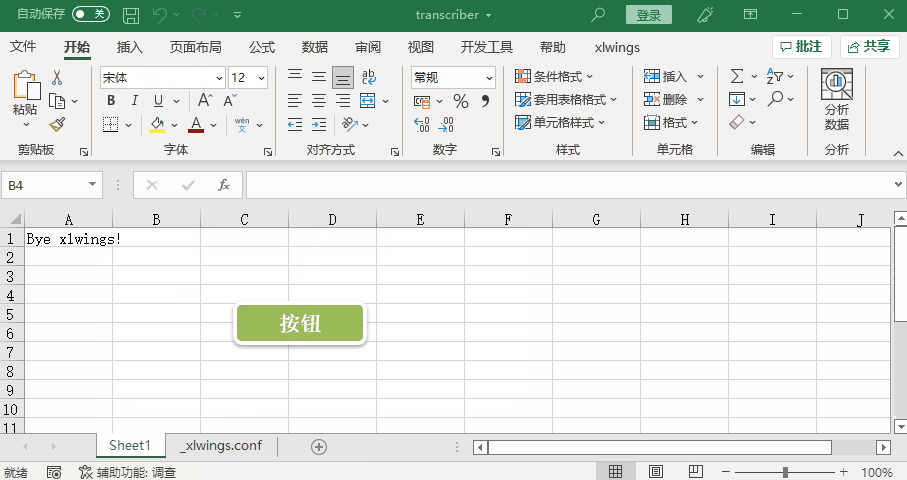
if sheet["A1"].value == "Hello xlwings!":
sheet["A1"].value = "Bye xlwings!"
else:
sheet["A1"].value = "Hello xlwings!"
@xw.func
def hello(name):
return f"Hello {name}!"
if __name__ == "__main__":
xw.Book("transcriber.xlsm").set_mock_caller()
main()
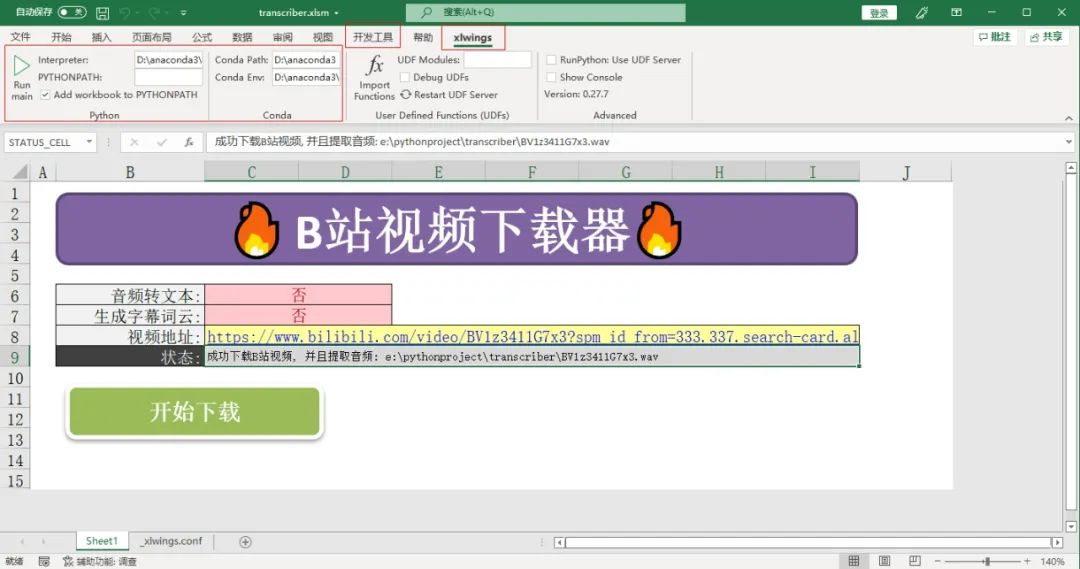
# 安装xlwings的Excel集成插件
xlwings addin install
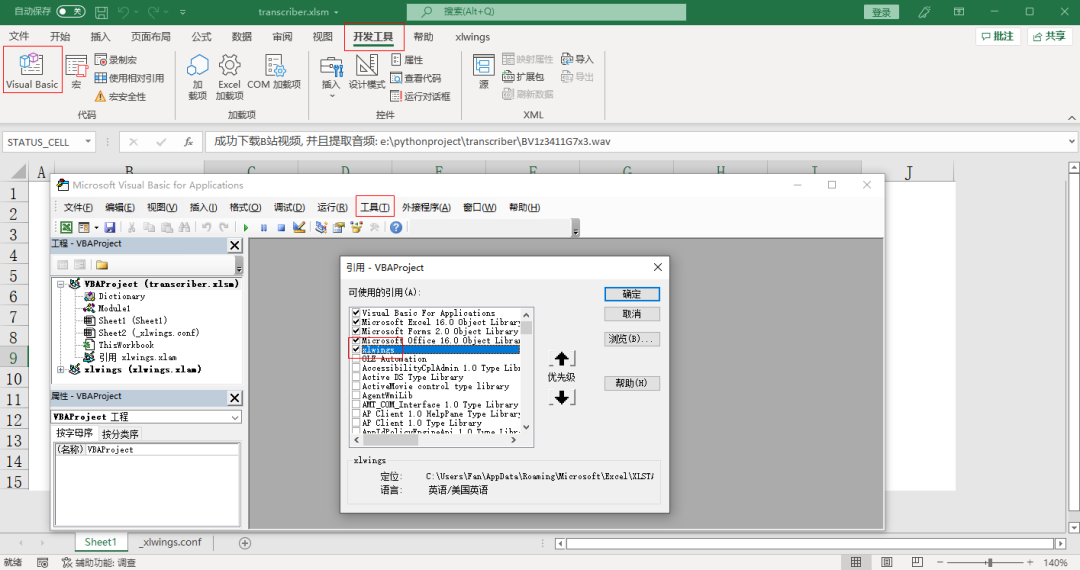
import xlwings as xw
def main():
wb = xw.Book.caller()
sheet = wb.sheets[0]
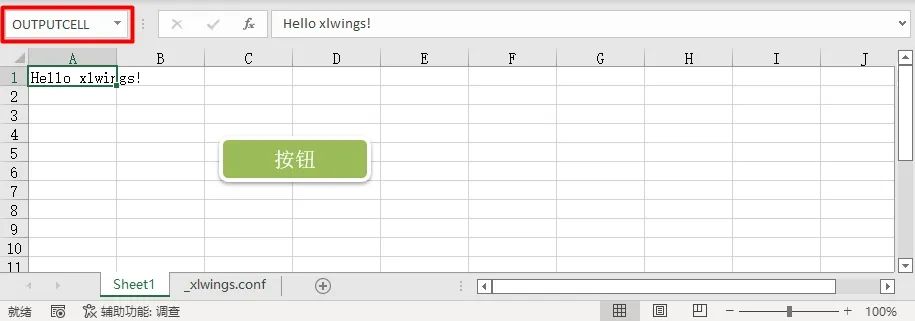
if sheet["OUTPUTCELL"].value == "Hello":
sheet["OUTPUTCELL"].value = "Bye"
else:
sheet["OUTPUTCELL"].value = "Hello"
@xw.func
def hello(name):
return f"Hello {name}!"
if __name__ == "__main__":
xw.Book("transcriber.xlsm").set_mock_caller()
main()
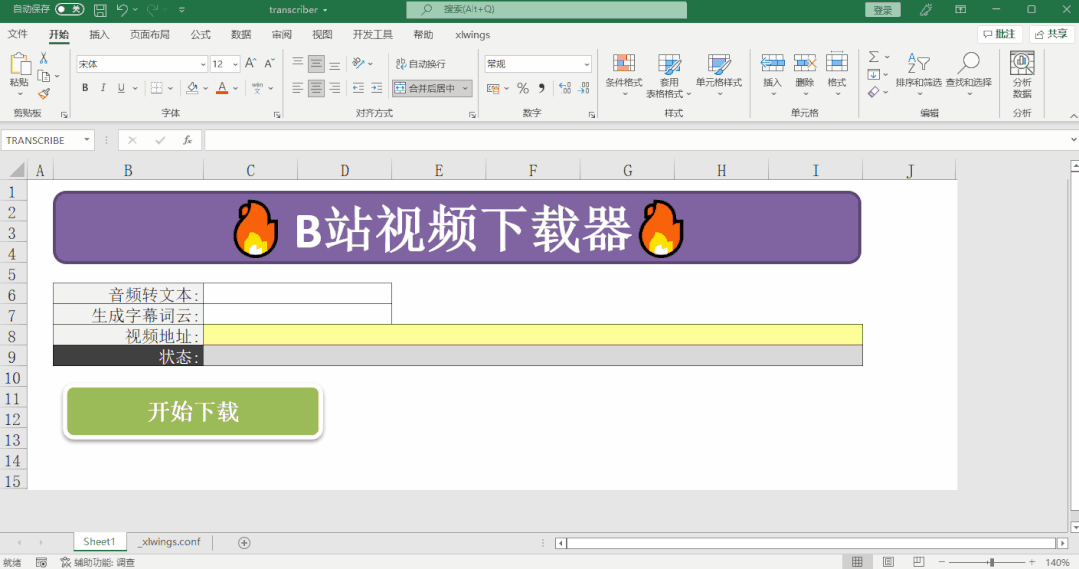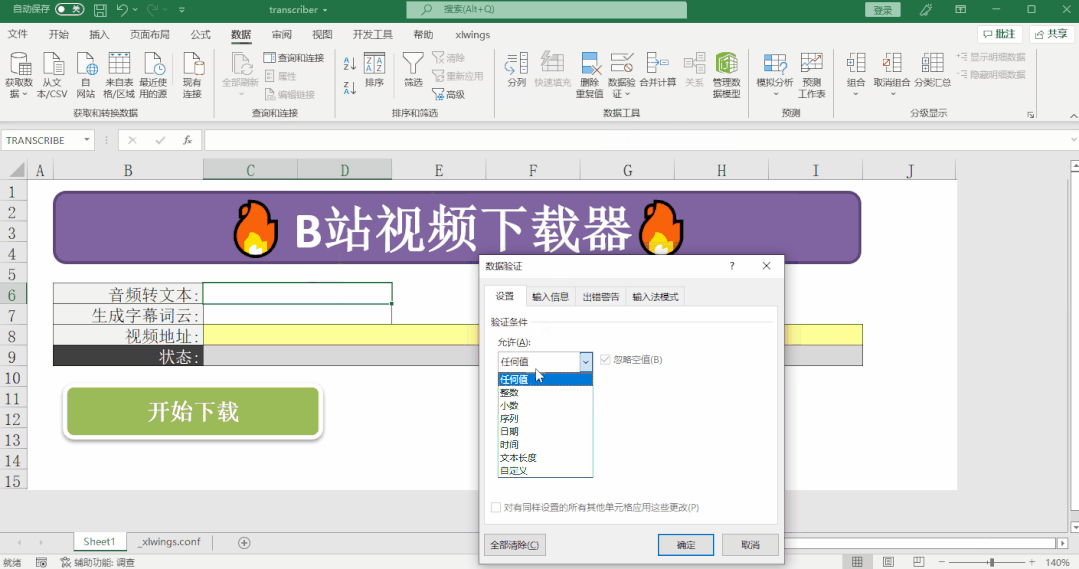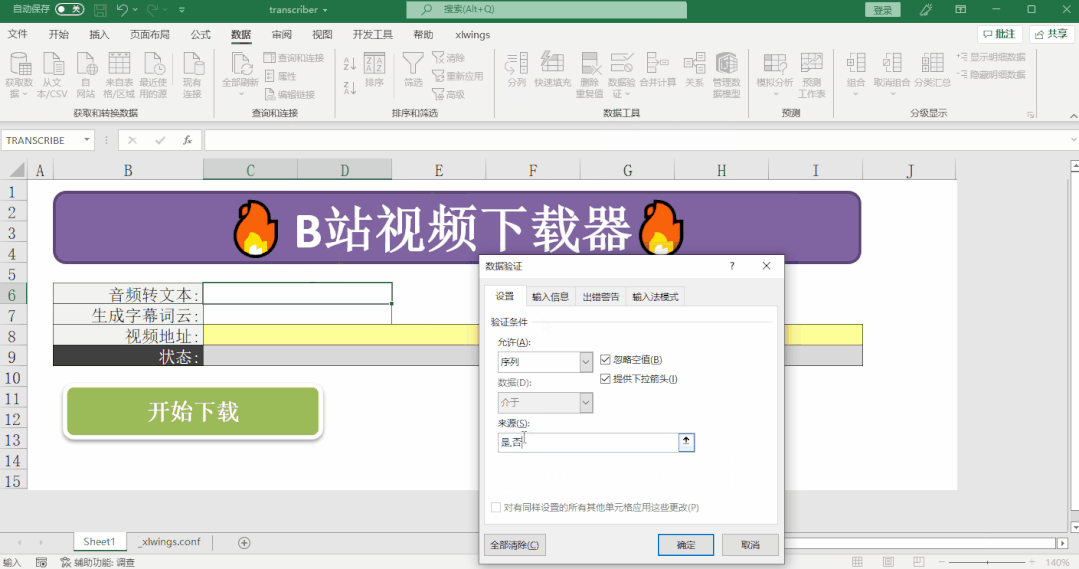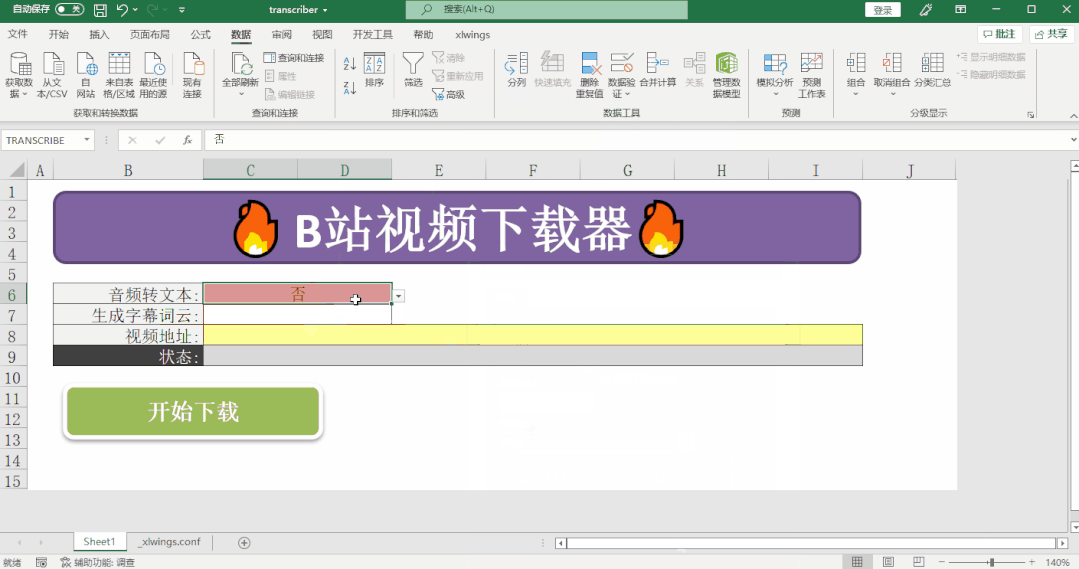
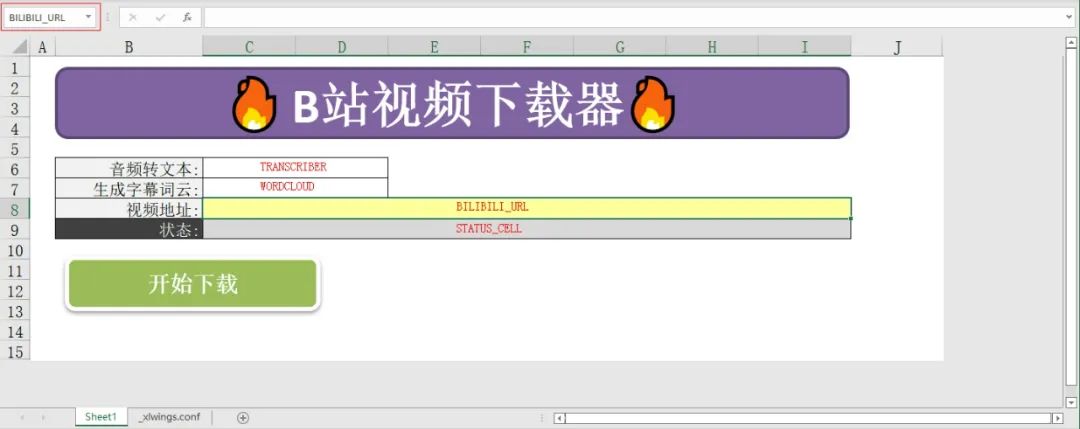
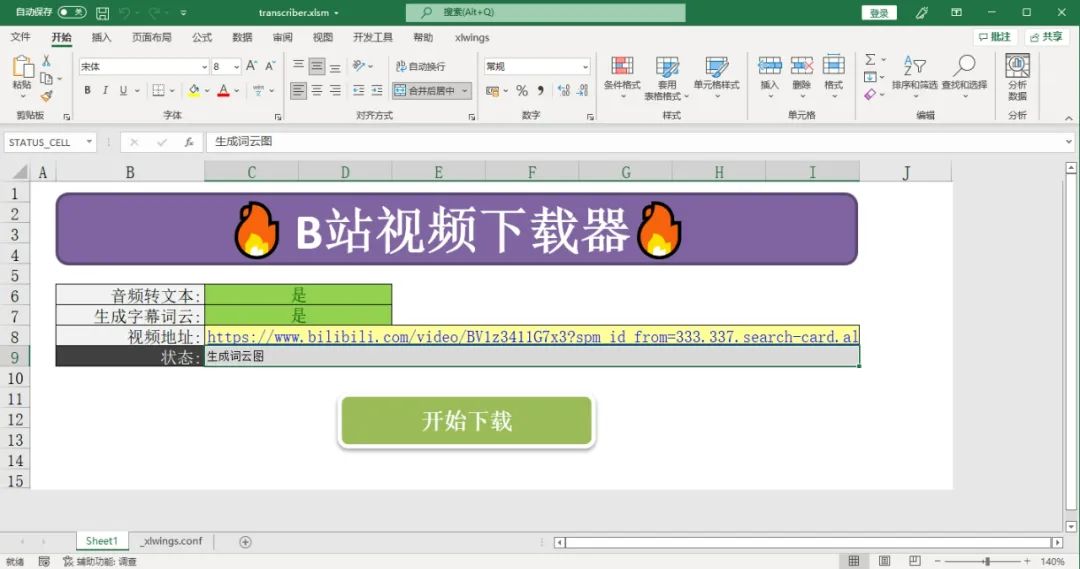
def main():
wb = xw.Book.caller()
sheet = wb.sheets[0]
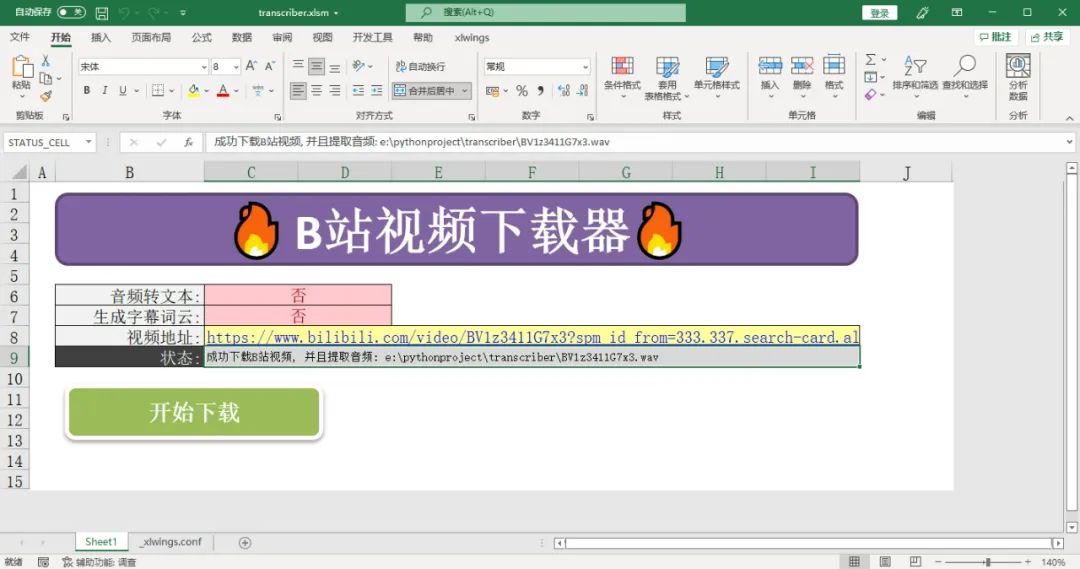
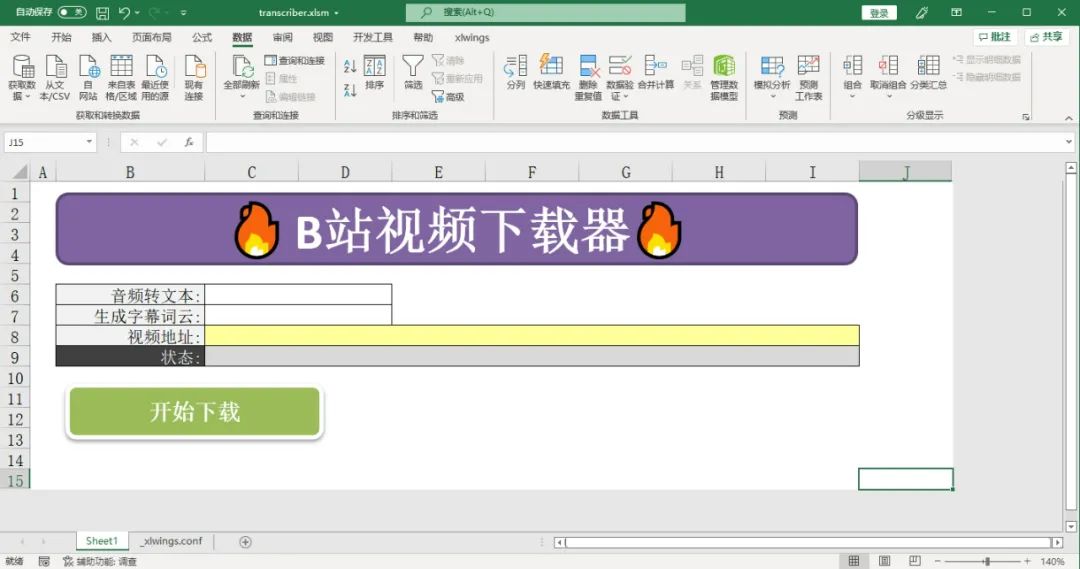
bilibili_url = sheet["BILIBILI_URL"].value
transcribe = sheet["TRANSCRIBE"].value
wordcloud = sheet["WORDCLOUD"].value
status_cell = sheet["STATUS_CELL"]
# 重置状态栏
status_cell.value = ""
# 获取程序运行路径
output_path = Path(__file__).parent
output_path = str(output_path)
# 下载
if bilibili_url:
status_cell.value = "开始下载音视频文件 ..."
audio_file = download_bilibili(bilibili_url, status_cell, output_path)
else:
status_cell.value = "未输入B站视频地址"
sys.exit()
# 语音转文字
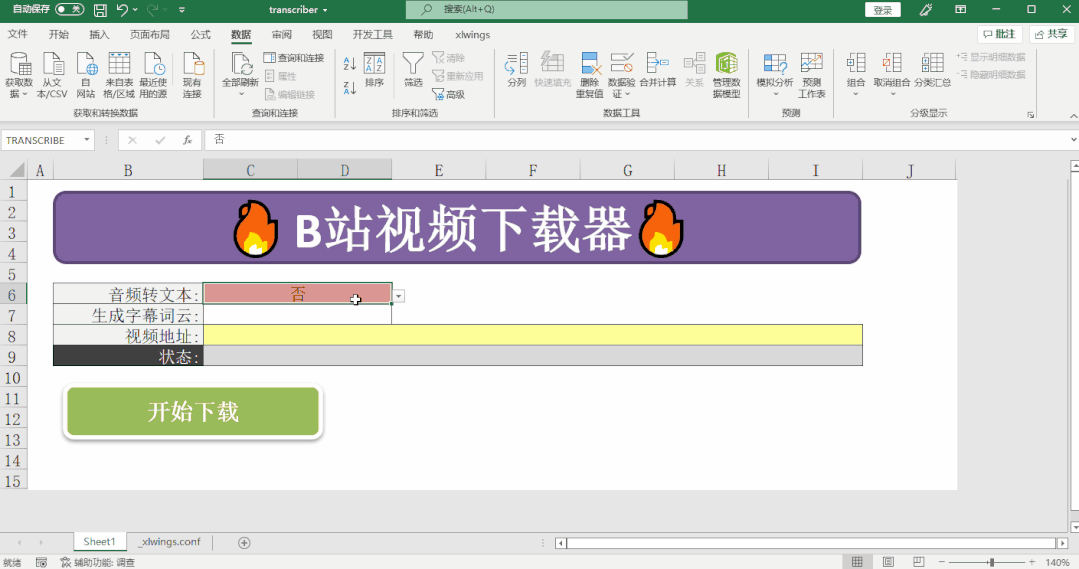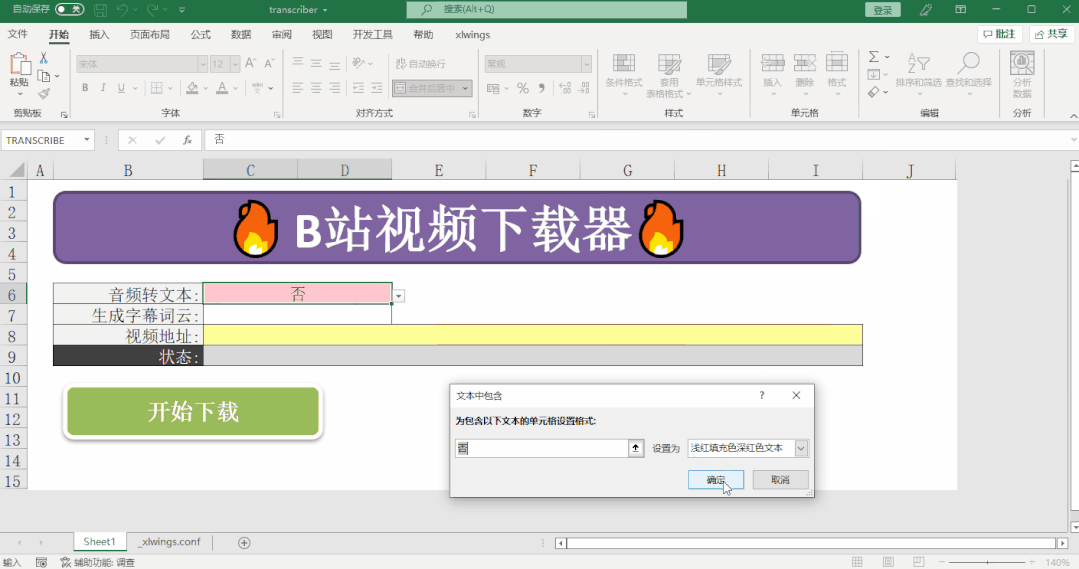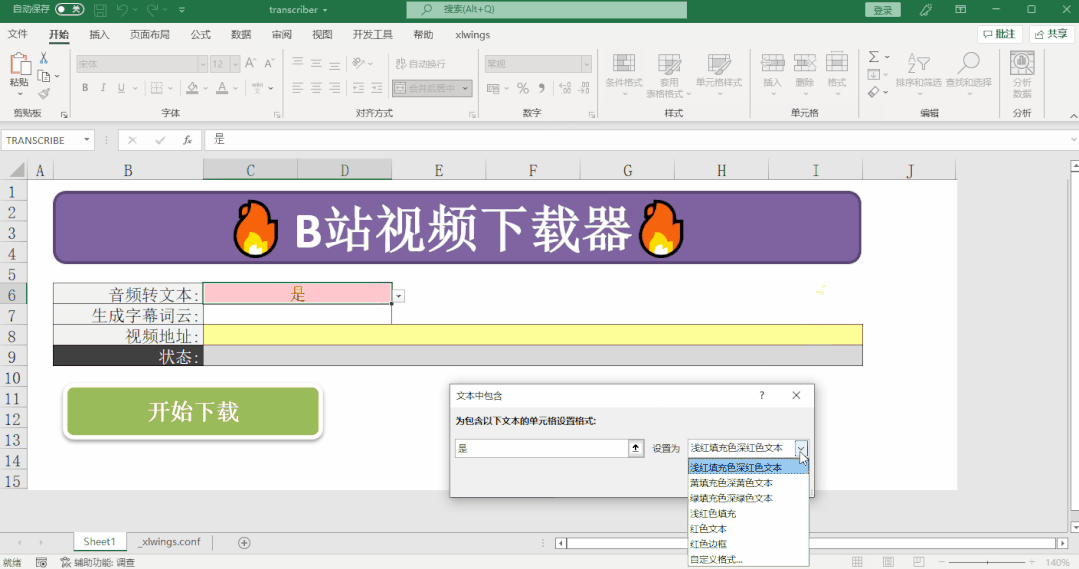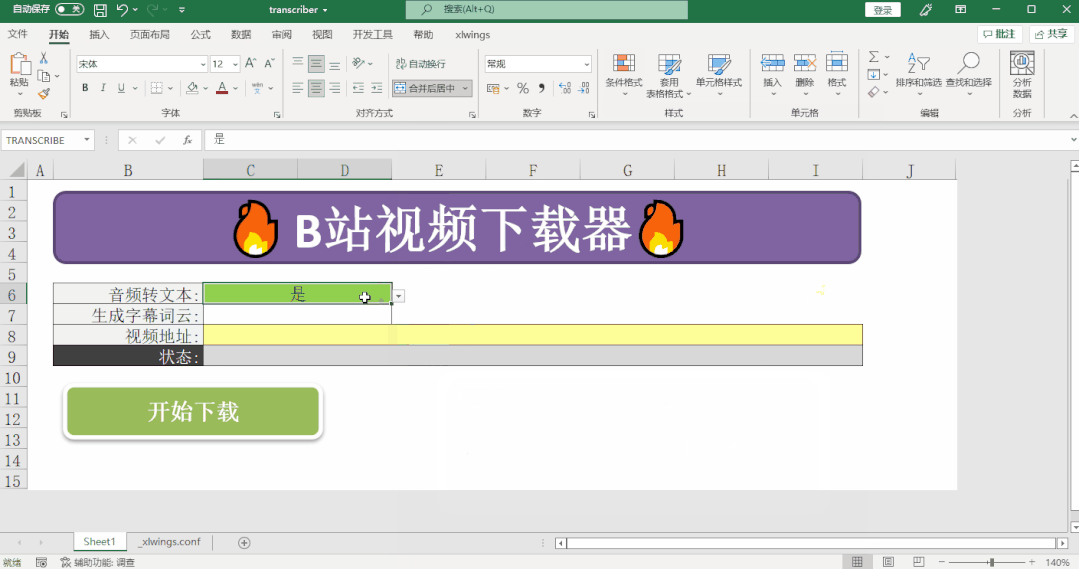
if transcribe == '是':
transcription_text = transcribe_audio_file(status_cell, audio_file, output_path)
# 生成词云
if transcribe == '是' and wordcloud == '是':
generate_wordcloud(transcription_text, output_path, status_cell)
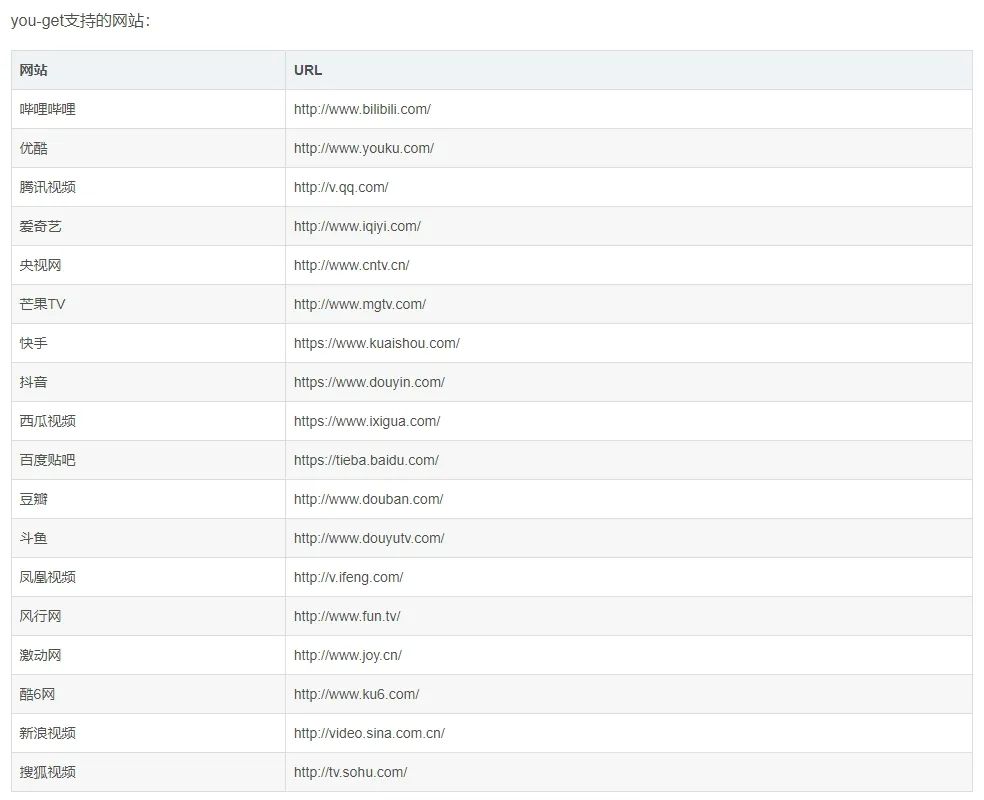
def download_bilibili(bilibili_url, status_cell, output_path):
"""下载音视频"""
filename = bilibili_url.split('/')[-1].split('?')[0]
cmd = 'you-get {} -o {} -O {}'.format(bilibili_url, output_path, filename)
os.system(cmd)
# 导入视频
my_audio_clip = AudioFileClip(output_path + "\\{}.flv".format(filename))
# 提取音频并保存
audio_file = output_path + "\\{}.wav".format(filename)
my_audio_clip.write_audiofile(audio_file)
status_cell.value = f"成功下载B站视频, 并且提取音频: {audio_file}"
return audio_file
def transcribe_audio_file(status_cell, audio_file, output_path):
"""语音转文字"""
status_cell.value = "开始处理音频文件..."
old_name = audio_file
new_name = audio_file.split('.')[0] + '_16000.wav'
split_name = audio_file.split('.')[0]
# 对音频进行降频处理
ffmpeg.input(old_name).output(new_name, ar=16000).run(cmd=FFMPEG_PATH)
# 切割音频
audio = AudioSegment.from_file(new_name, "wav")
# 切割的毫秒数
size = 30000
# 将文件切割为30s一块
chunks = make_chunks(audio, size)
for i, chunk in enumerate(chunks):
# 枚举,i是索引,chunk是切割好的文件
chunk_name = split_name + "_{0}.wav".format(i)
# 保存文件
chunk.export(chunk_name, format="wav")
status_cell.value = "使用百度语音接口识别音频..."
# 使用百度语音接口
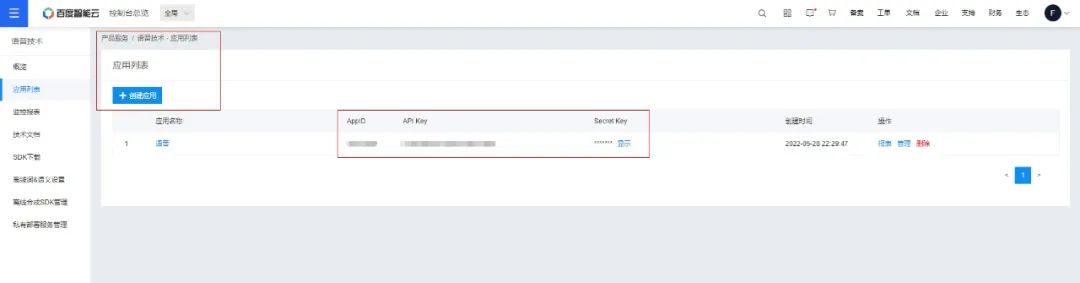
""" 你的 APPID AK SK """
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(file_path):
with open(file_path, 'rb') as fp:
return fp.read()
transcription_txt = output_path + "\\transcription.txt"
# 识别本地文件
for i, chunk in enumerate(chunks):
result = client.asr(get_file_content(split_name + "_{0}.wav".format(i)), 'wav', 16000, {
'dev_pid': 1537 # 默认1537(普通话 输入法模型),dev_pid参数见本节开头的表格
})
print(result['result'])
with open(transcription_txt, "a") as file:
file.write(result['result'][0])
file.close()
status_cell.value = f"音频转文本成功, 文件保存到 {transcription_txt}"
return transcription_txt
def generate_wordcloud(textfile, output_path, status_cell):
"""生成词云"""
textfile = Path(textfile)
content = textfile.read_text()
wordcloud = WordCloud(font_path=output_path + '\\simhei.ttf').generate(content)
wordcloud.to_file(Path(output_path) / f"{textfile.stem}.png")
status_cell.value = "生成词云图"
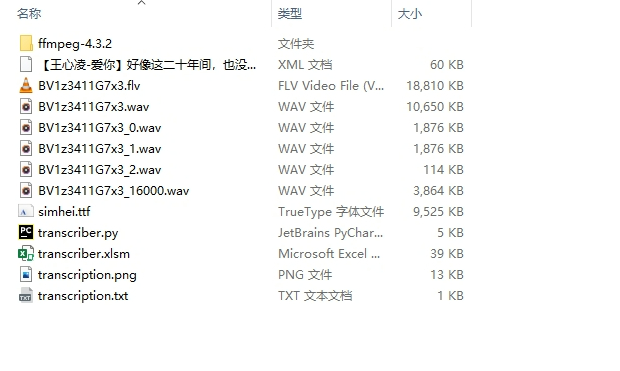

链接:https://pan.baidu.com/s/1nalAluRM-CyzYX5PUSYieg?pwd=95cu
提取码:95cu


文章评论