
关注公众号,后台回复“python资料”,获取python资料大礼包。
大家好,欢迎收看思路实验室出品的Python入门教程,我是室长。
以前我们分析数据可能都是从数字开始,比如分析人口,分析经济,对文字的分析好像缺乏一些思路,因为语言这种东西实在是太复杂了。对于人工智能来说,如何理解人类语言目前仍然是一个重要的课题。但现在出现了非常多的语言分析工具,例如词频统计、词云图,它们有着共同的第一步,就是将段落拆分成句子,将句子拆分成词语。对于某些语言如英语来说,进行这样的拆分其实非常方便,学过python,会使用字符串的split方法就能够实现,毕竟英语中每两个词中间都是由空格分隔的。而对于中文来说就有些复杂了,每个句子里的字都是紧密连接的,该从哪里下刀是个问题。况且中文博大精深,很多时候怎么分隔都说得通,例如:
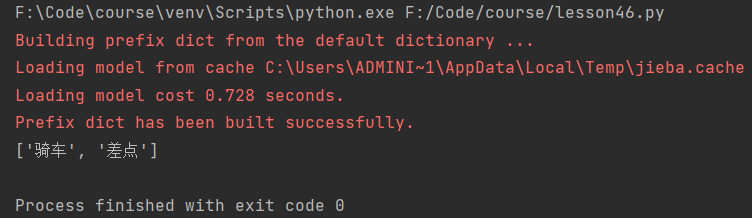
“我骑车差点摔倒,还好我一把把把把住了。”

别说对于程序,就算是对于歪果仁也太难了点。这时候就需要一个很会的程序来对句子进行分割,那么今天就来向大家介绍一下在中文分词领域大名鼎鼎的jieba模块:
我们先来安装一下jieba模块,安装名和导入名都是jieba:

然后编辑字符串,并调用lcut方法对其进行切割:

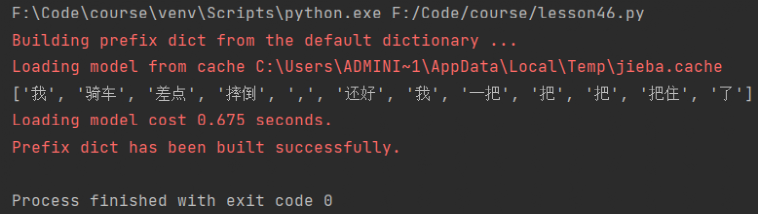
什么叫专业?这就叫专业!不同的词分割得清清楚楚。
需要注意的是,我们调用的是lcut方法,而不是cut方法,为什么呢?因为cut方法返回的是生成器,而并没有将句子进行分割。这个生成器每被调用一次就会切下来一个词,直到所有内容被切割完。相反lcut方法会在调用时就将所有的内容分割完并存入列表中。如果我们要分割很大的内容比如小说的话,直接调用lcut方法需要等上一段时间,而调用cut方法配合for循环能够更快地看到部分结果。
与此同时,jieba还支持词性标注。具体的实现需要使用jieba.posseg模块。模块导入之后我们只需要像jieba模块一样调用lcut方法就可以了:
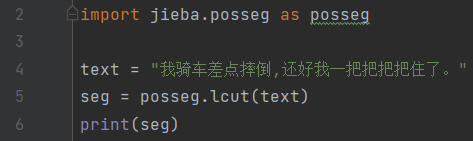

可以看到返回的每个词都是一个pair对象,里边包含了词本身和词性。词性对照如下:
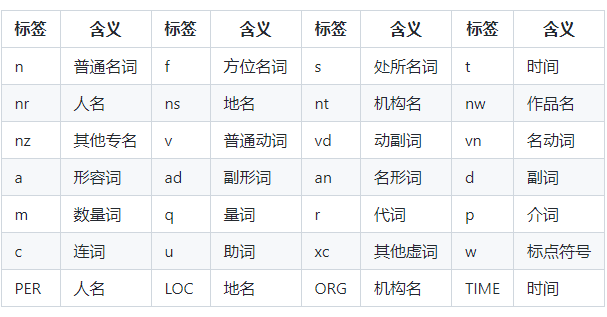
毕竟中文太复杂了,分词已经不易,标注词性更是容易出错。在这句话中“骑车”被标成了名词,“差点”也被标成了名词,还是有改进的空间。
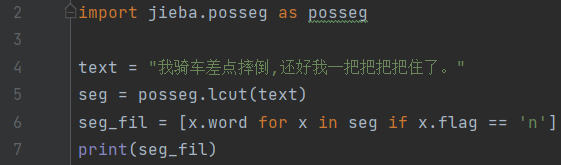
我们可以通过词的flag属性获取词性,word属性获取词,从而实现对词性的筛选:
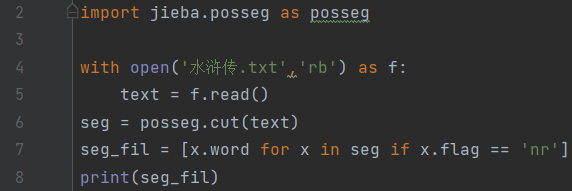
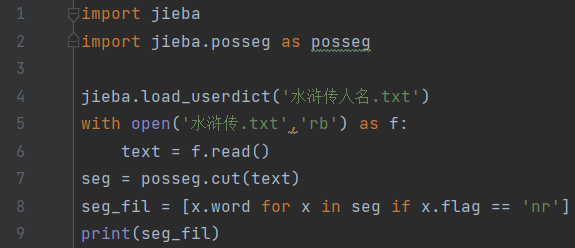
那我们今天来完成一个小任务,来统计一下《水浒传》中各英雄的出场频率。我们可以使用open方法打开txt格式的小说,并用read方法将小说内容存入字符串:

随后我们进行分词,因为人名的标记为nr,所以我们直接筛选出词性为nr的词:

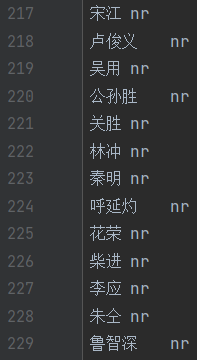
大体上不错,但是有些地方分割的不好,比如这个林冲谢,可能林冲看了真的会谢……
但毕竟不能苛责jieba,它也不知道水浒传里有哪些人物。所以我们要给它提供一个词典,表明这些名字是固定搭配。我们从百度百科上粘贴下来所有108将的天罡地煞、绰号和名字,并标记好它的词性,将其存入txt文件中,其中每个名字与词性以空格分隔,每个词条占一行:
然后在我们代码的开始处使用load_userdict方法,读取我们自定义的字典文件:

有的地方好了些,有的地方还是有问题,不过水浒传毕竟是半文半白,不是现代汉语,出现一些问题还是难免的,我们后期再手动整理即可。
接下来我们要进行词频的统计,不计效率的可以直接写个for循环,将各个名字的频率统计到DataFrame中并排序,最后存到csv文件中:
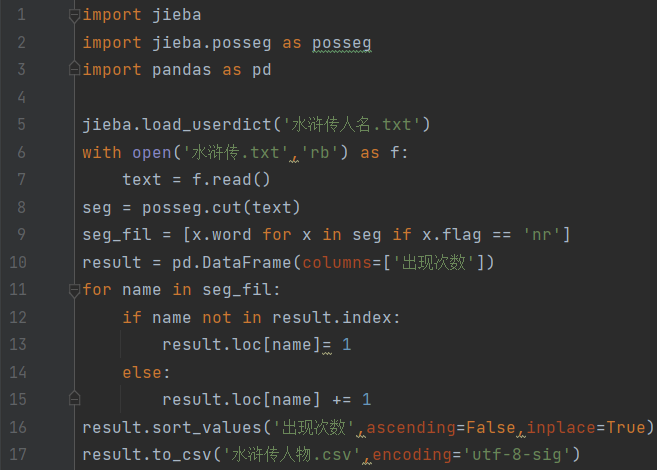
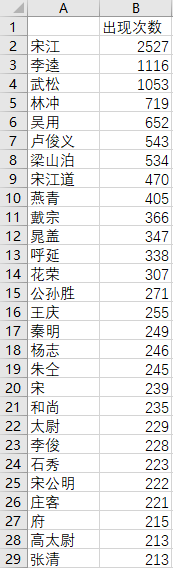
这么一看哥哥果然人气爆棚,李逵和武松紧随其后。而且有很多同人不同称呼的没有被列到一起,如宋公明就和宋江分开了。还有一些是分词的错误,比如宋江道,如果是按照现代汉语改成宋江说的话应该不至于分错。不过整体来说还是有非常高的研究价值的。获得这些数据之后,我们稍加修饰,就可以生成非常好看的词云图了。那么制作词云图就涉及到了另一个模块,我们将在下一期为大家讲解。如果这篇文章对你有所帮助,希望能帮室长点个赞和在看,你的鼓励是室长进步的动力!
另外,【室长原理课】系列在不正经地科普一些互联网小知识,没有太多高深的内容,把这个系列分享给你的朋友吧!


文章评论