


摘要:jieba是Python中一个重要的第三方中文分词函数库。
注:本文主要内容整理自北京理工大学嵩天老师的《Python语言程序设计基础》。)

1. jieba库的概率
> "Who we were does not dictate who we will be.".split()['Who', 'we', 'were', 'does', 'not', 'dictate', 'who', 'we', 'will', 'be.']>
> import jieba> jieba.lcut("中国是一个伟大的国家")['中国', '是', '一个', '伟大', '的', '国家']>
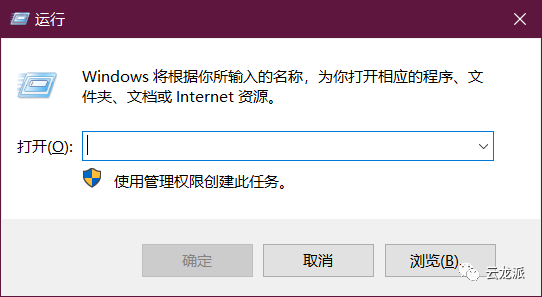
输入cmd,进入终端命令窗口
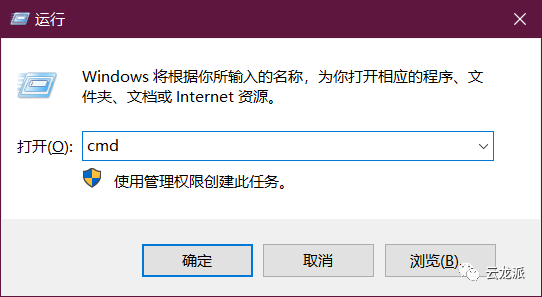
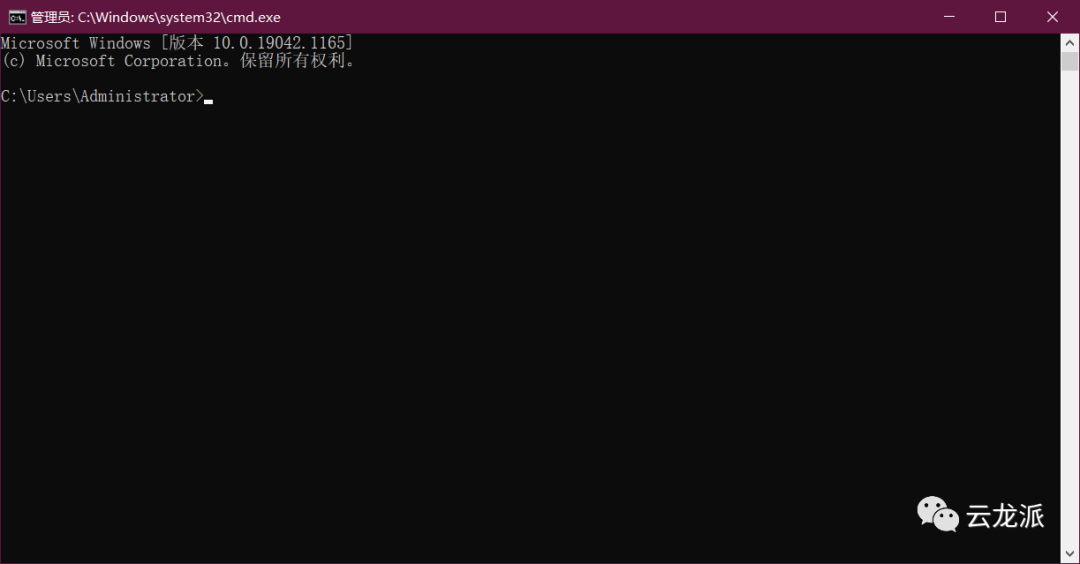
输入以下命令进行安装
pip install jieba2. jieba库解析
jieba库常用的分词函数(共7个)
| 函数 | 描述 |
| jieba.cut(s) | 精确模式,返回一个可迭代的数据类型 |
| jieba.cut(s,cut_all=True) | 全模式,输出文本s中所有可能的单词 |
| jieba.cut_for_search(s) | 搜索引擎模式,适合搜索建立索引的分词结果 |
| jieba.lcut(s) | 精确模式,返回一个列表类型,建议使用 |
| jieba.lcut(s,cut_all=True) | 全模式,返回一个列表类型,建议使用 |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回一个列表类型,建议使用 |
| jieba.add_word(w) | 向分词词典中增加新词w |
针对上述分词函数,举例如下:
> import jieba> jieba.lcut("中华人民共和国是一个伟大的国家")['中华人民共和国', '是', '一个', '伟大', '的', '国家']> jieba.lcut("中华人民共和国是一个伟大的国家",cut_all=True)['中华', '中华人民', '中华人民共和国', '华人', '人民', '人民共和国', '共和', '共和国', '国是', '一个', '伟大', '的', '国家']> jieba.lcut_for_search("中华人民共和国是一个伟大的国家")['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '一个', '伟大', '的', '国家']
-
jieba.lcut()函数返回精确模式,输出的分词能够完整且不多余地组成原始文本;
-
jieba.lcut(,True)函数返回全模式,输出原始文本中可能产生的所有问题,冗余性最大;
-
jieba.lcut_for_search()函数返回搜索引擎模式,该模式首先执行精确模式,然后再对其中的长词进一步切分获得结果。
由于列表类型的通用且灵活,一般是使用返回带有列表类型的分词函数。
> import jieba> jieba.lcut("湘潭大学信息工程学院2016级自动化四班")['湘潭', '大学', '信息', '工程学院', '2016', '级', '自动化', '四班']> jieba.add_word("湘潭大学")> jieba.add_word("信息工程学院")> jieba.lcut("湘潭大学信息工程学院2016级自动化四班")['湘潭大学', '信息工程学院', '2016', '级', '自动化', '四班']> jieba.lcut("湘潭大学琴湖9栋407成员:王建徽、刘先镨、谭湘勇、郭志龙")['湘潭大学', '琴湖', '9', '栋', '407', '成员', ':', '王建徽', '、', '刘先', '镨', '、', '谭湘勇', '、', '郭志龙']> jieba.add_word("刘先镨")> jieba.add_word("琴湖9栋")> jieba.lcut("湘潭大学琴湖9栋407成员:王建徽、刘先镨、谭湘勇、郭志龙")['湘潭大学', '琴湖9栋', '407', '成员', ':', '王建徽', '、', '刘先镨', '、', '谭湘勇', '、', '郭志龙']>
Python学习笔记往期回顾
本文内容来源于网络,仅供参考学习,如内容、图片有任何版权问题,请联系处理,24小时内删除。




文章评论