https://chrome.google.com/webstore/detail/web-scraper-free-web-scra/jnhgnonknehpejjnehehllkliplmbmhn?hl=zh-CN
最近想通过爬虫爬一下招聘网站的职位信息,但又不会写代码,就想通过Web Scraper插件来代劳,网上虽然有很多教程,但都不太适合我,或者就是教程的无用信息太多,对于只是使用它的用户来说,内容就显得非常冗余。所以我打算写一篇简短且实用的文章,如果想深入研究,建议可以阅读下方的官方文档。安装教程我就不写了,打开上方的链接一键安装就行了(打不开链接的用户去百度搜索一下“谷歌打不开怎么办?”)。
首先,我需要明确一下我的爬取目标,我需要找到Boss直聘上:
1、地理位置在成都
2、数据分析相关职位
3、爬取薪资、学历、福利待遇、职位描述、公司名称、公司地理位置
接下来,我们开始获取以上信息:
通过Boss直聘网站我们完成了前两项的筛选。
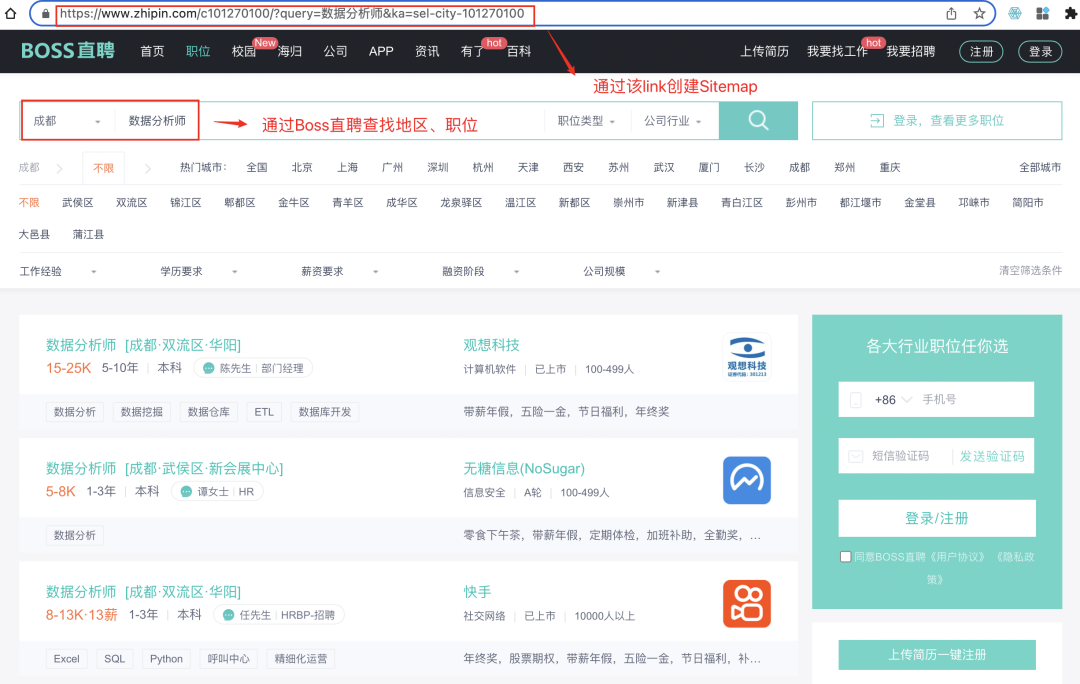
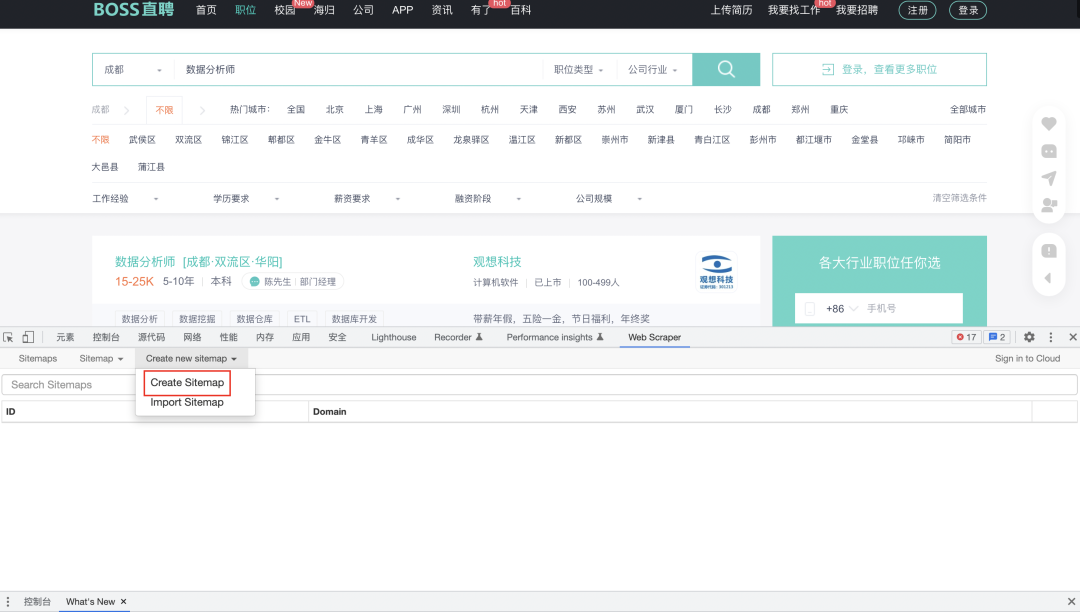
我们通过快捷键MacCommand+Option+I ;WinCtrl+Shift+I 打开Web Scraper,选择Creat Sitemap。
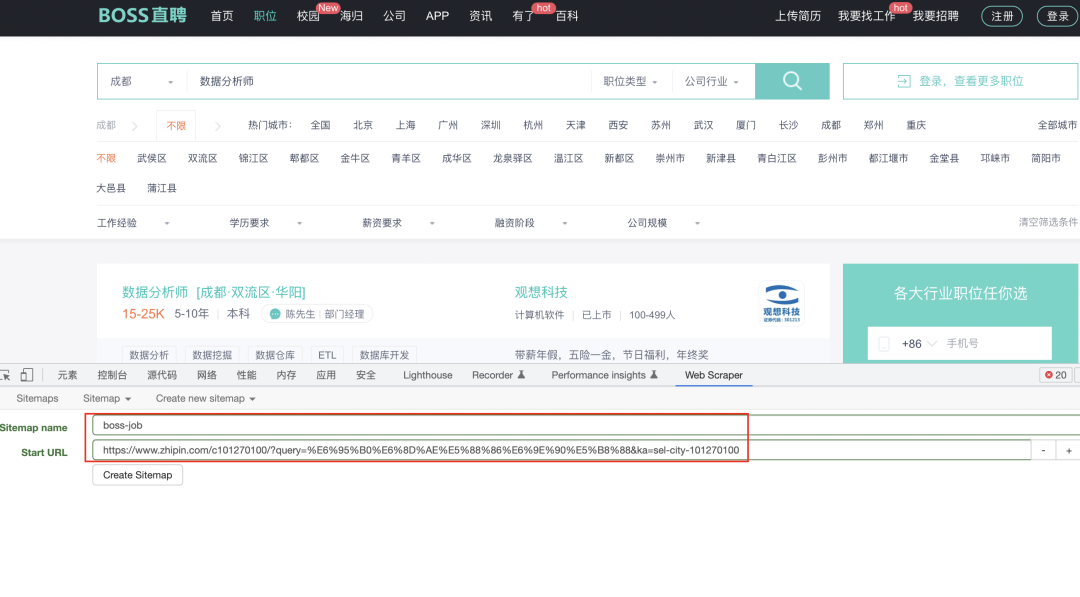
输入我们为该事件取的名字和粘贴刚才确定好条件的Boss直聘链接。
接下来,重点部分来了,我们需要开始创建选择器了,首先我们需要知道的是选择器是带有层级概念的,我将我的查询分为了四个部分:
-
第一个是不同页的抓取
-
第二个是不同块的抓取
-
第三个是块中元素的抓取
-
第四个是页内元素抓取
现在你可能还不太理解,没关系,跟着我一起实践。
通过上方的动图我已经完成了第一步不同页的抓取,让我再详细的讲解一下原理:
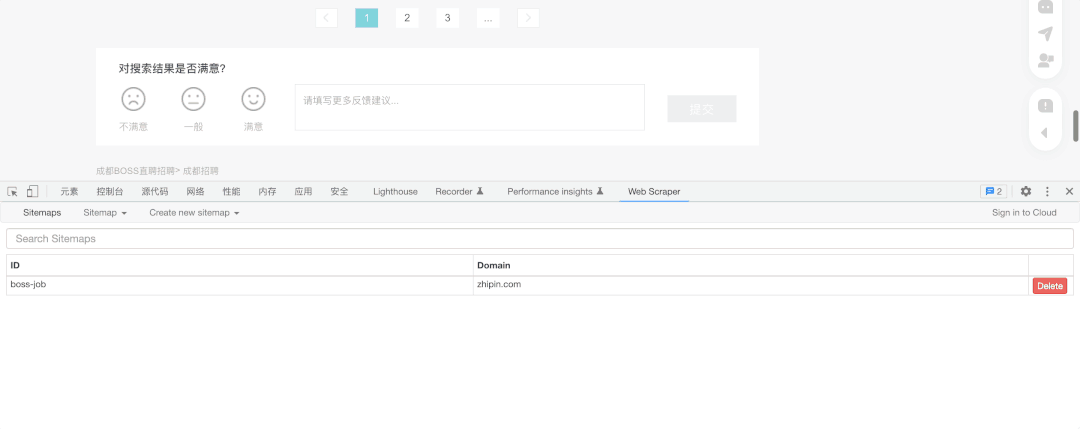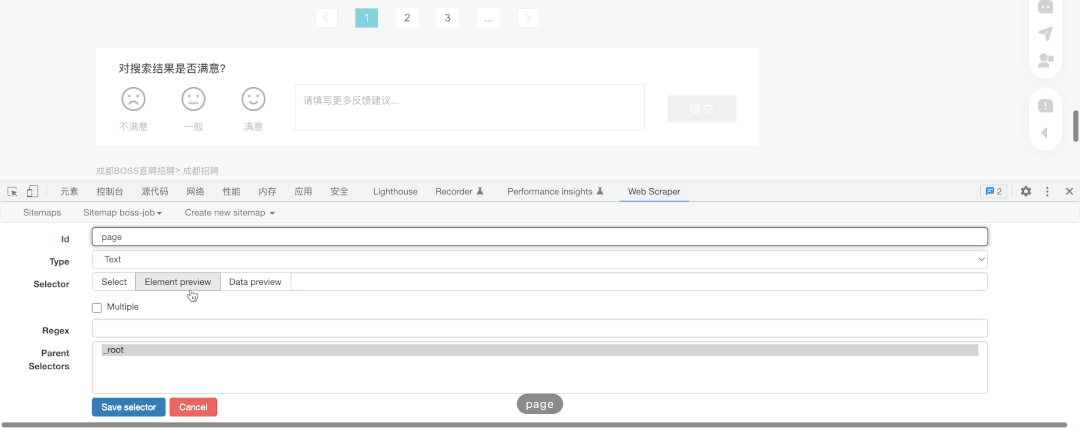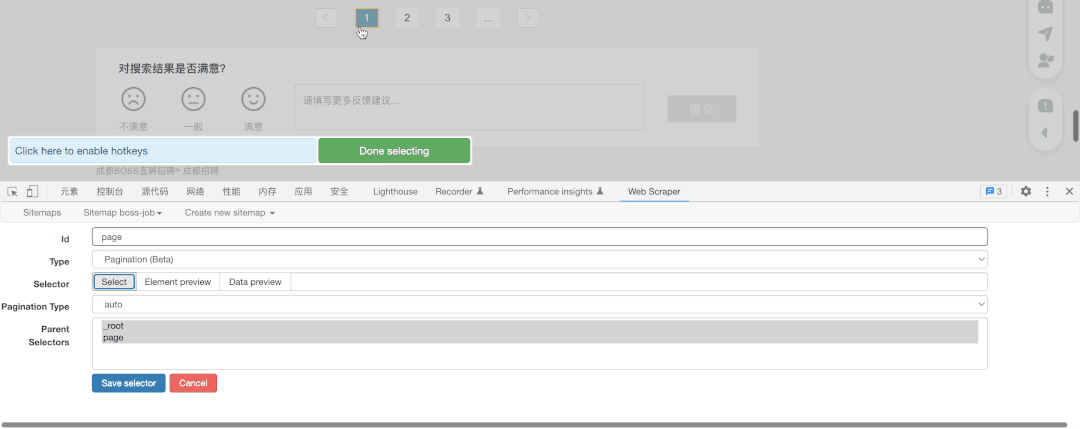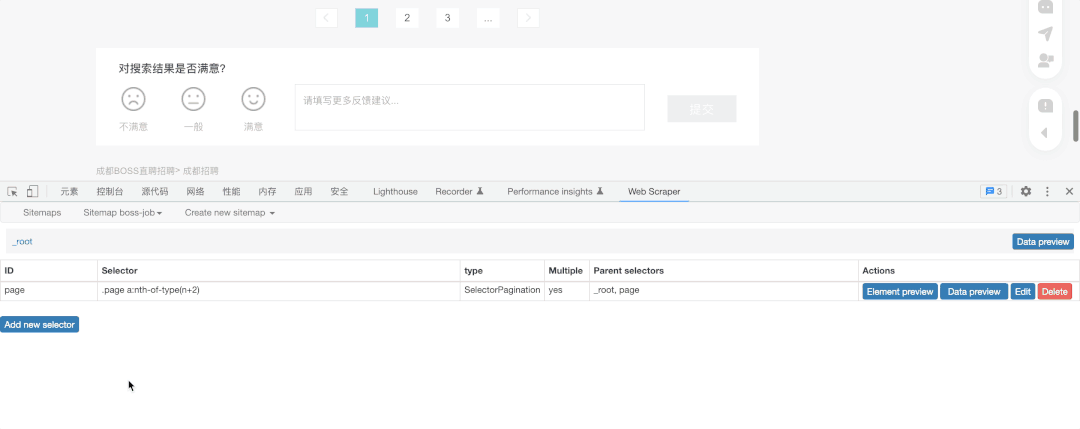
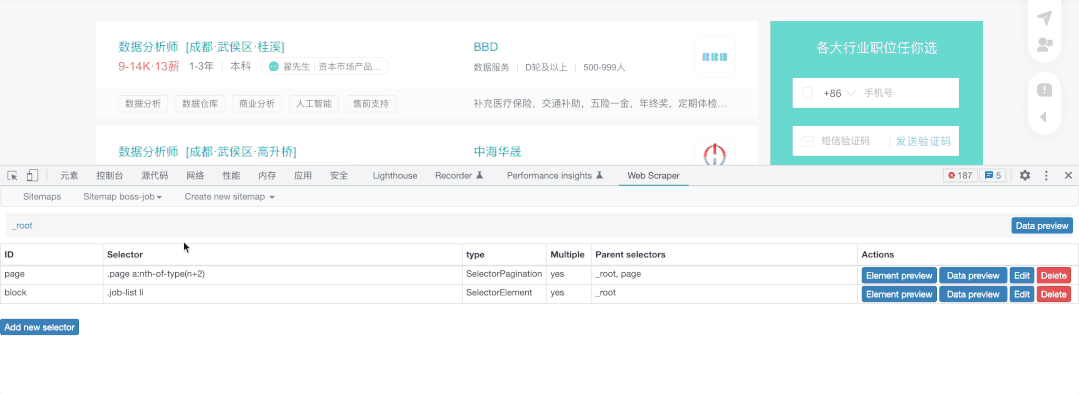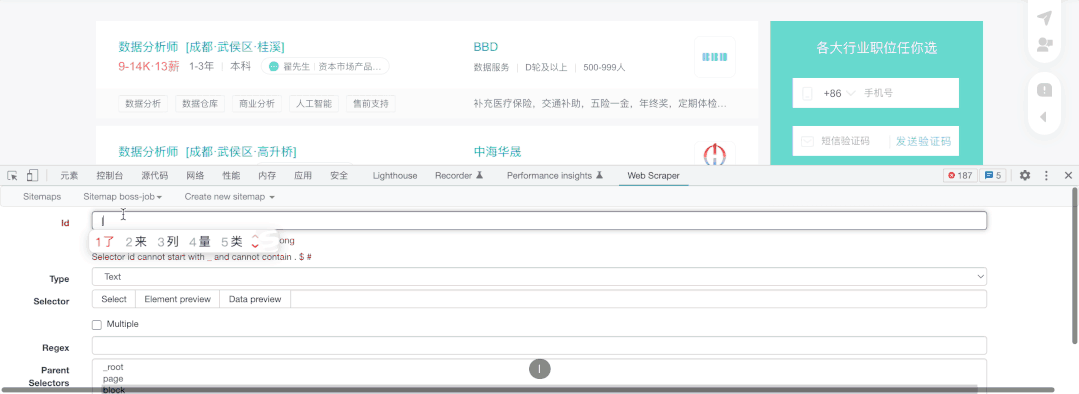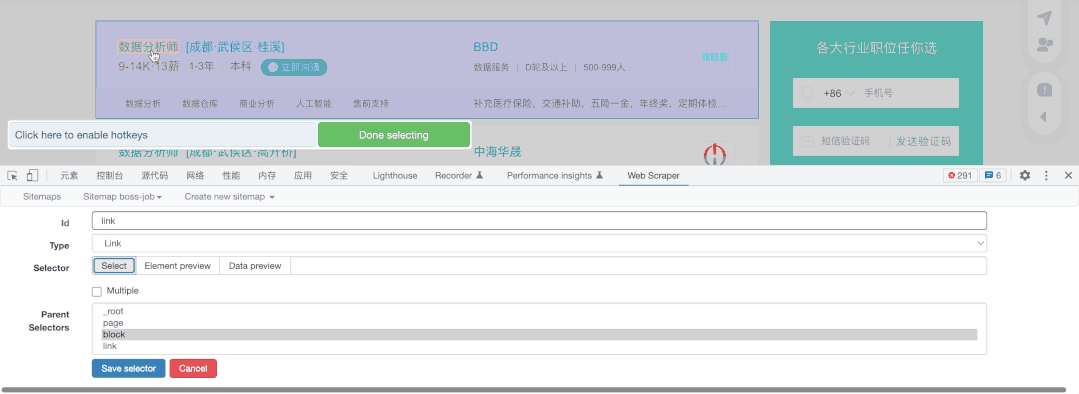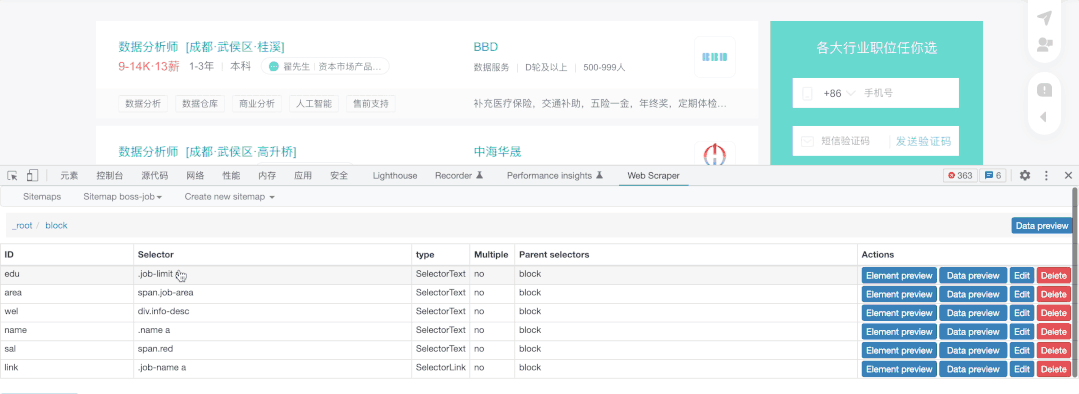
首先我点击了之前创建的Sitemap,开始在该页面创建抓取要求,因此我新建了一个选择器(Add new selecter)并命名为Page,目的是为了实现在不同页之间抓取。
其次,我选择了抓取类型为Pagination(页码),然后点击了Select选择该页最下方的页选项(通常我们选择两项后该插件就会自动补齐剩余内容),之后选择Done Selecting完成选择。
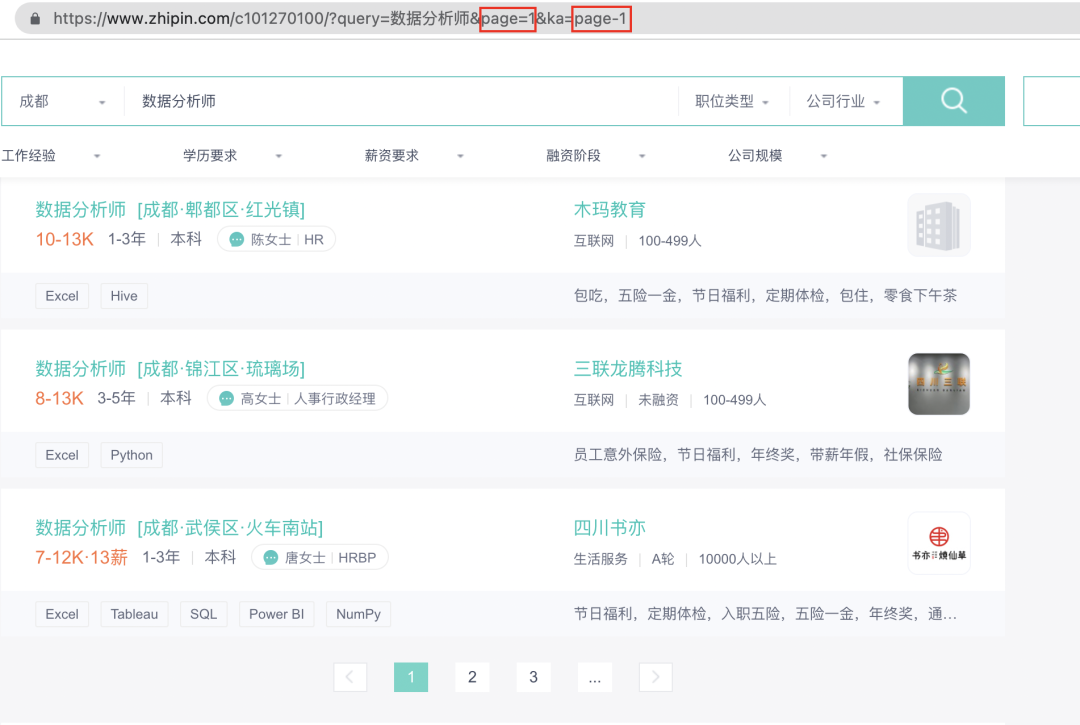
我们将
https://www.zhipin.com/c101270100/?query=数据分析师&page=1&ka=page-1改为
https://www.zhipin.com/c101270100/?query=数据分析师&page=[1-3]&ka=page-[1-3]重新创建一个Sitemap即可。
接下来我们讲解页面中不同块的抓取:
我们仍然在Pagination的Sitemap进行抓取,以方便大家理解抓取的层级结构:
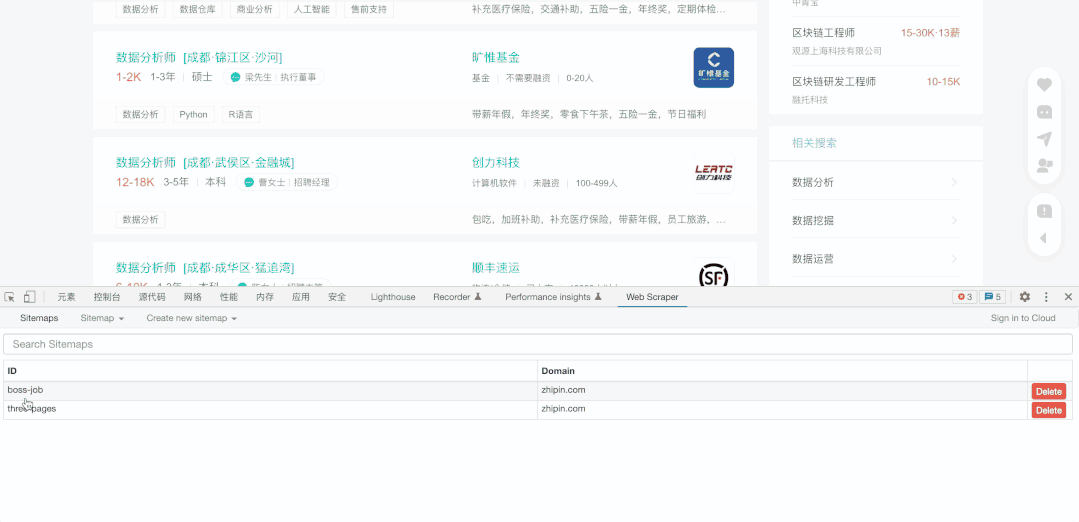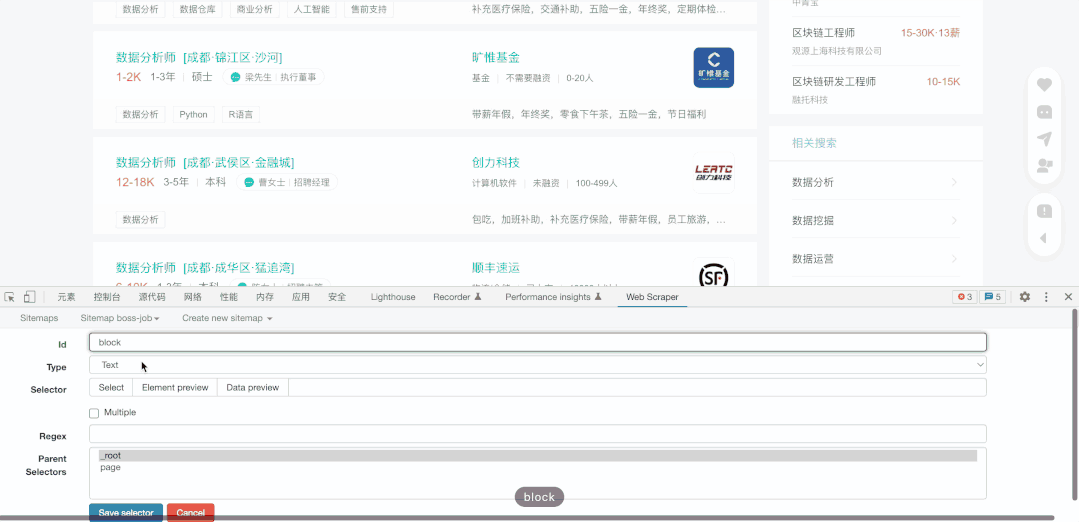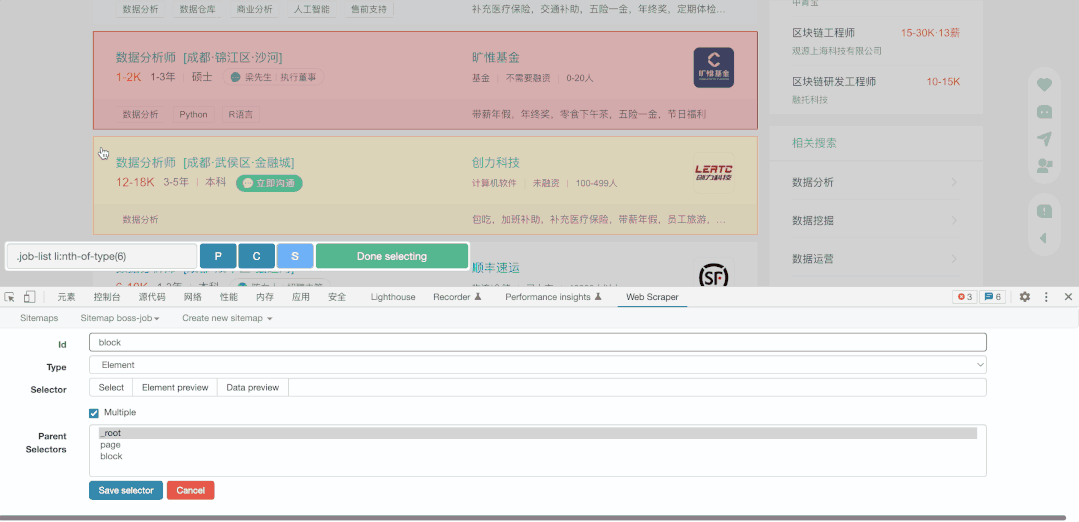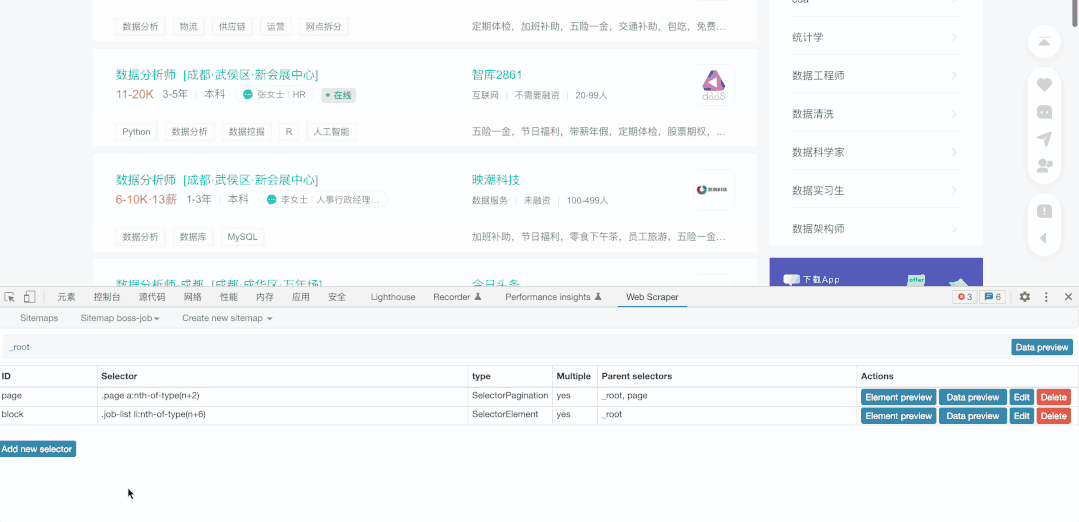
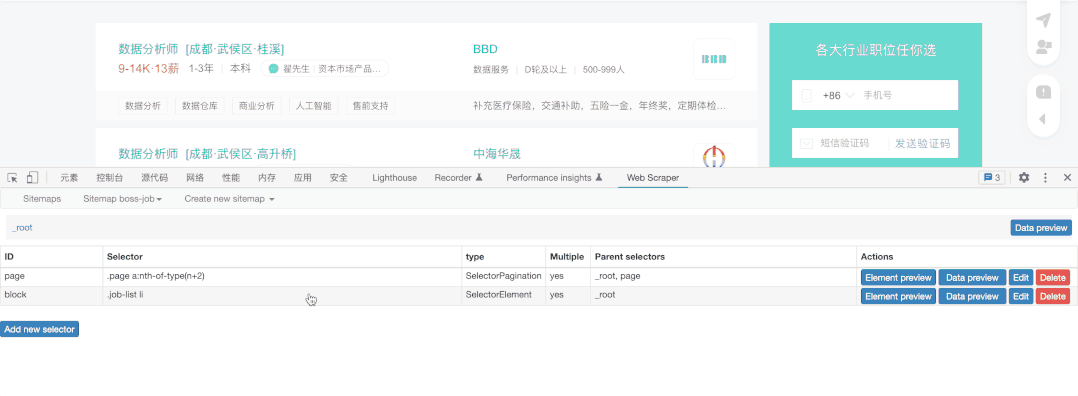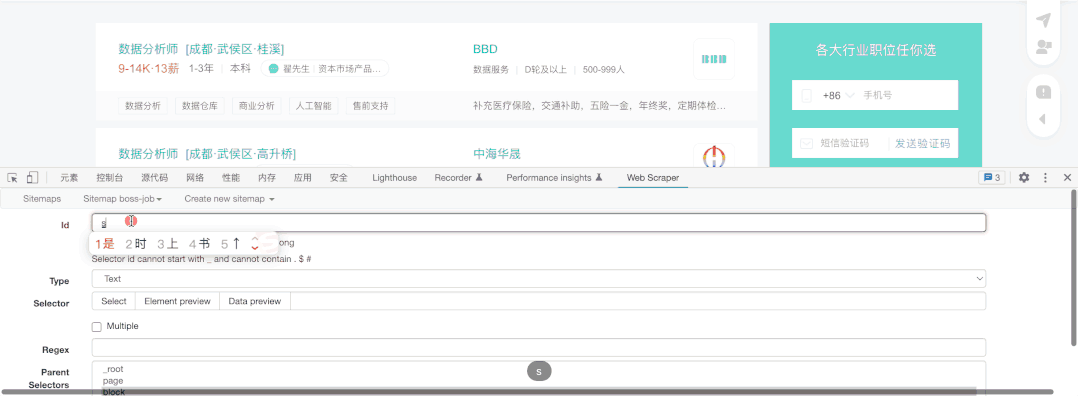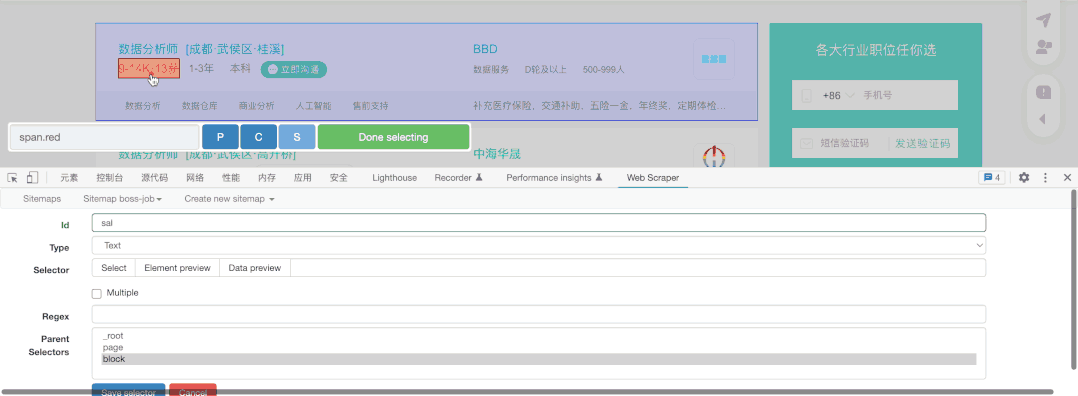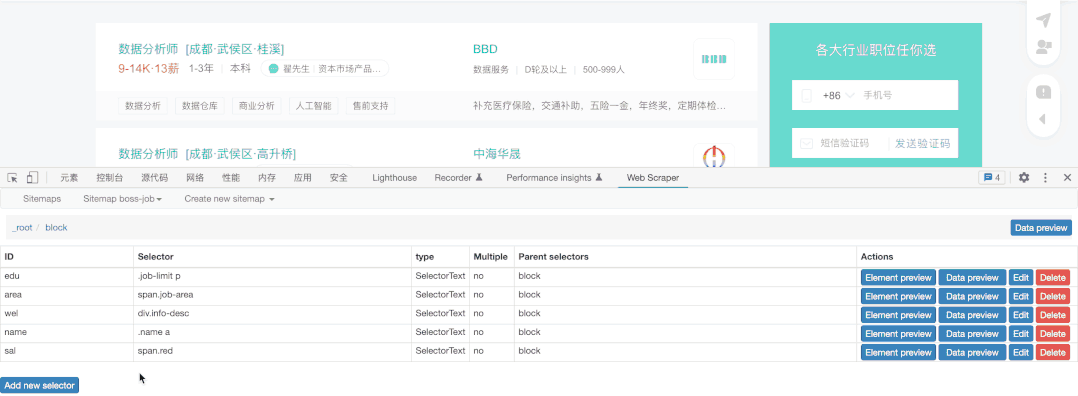
我们在Pagination的同级建立了新的选择器,然后命名为block,抓取类型选择了Element(元素),这里的一个元素就是一块内容,我们选择2个块后,插件自动选择了页面中的所有块,然后选择Done Selecting完成选择,仔细看你会发现,我们选择完成后会自动填入.job-list li:nth-of-type(-n+6) ,从代码来看,其实上方并未自动完后所有元素的填充,所以操作是错误的,我们需要记住:nth-of-type(-n+6) 这个代码,因为它的本质就是抓取量的筛选,我们可以把6修改为任意数字,也就是抓取任意多条数的内容,其实这里就是限制抓取页面6个元素,正确的情况应该是.job-list li ,另值得注意的是,我们一定要勾选Multiple ,否则抓取结果会只有一个。
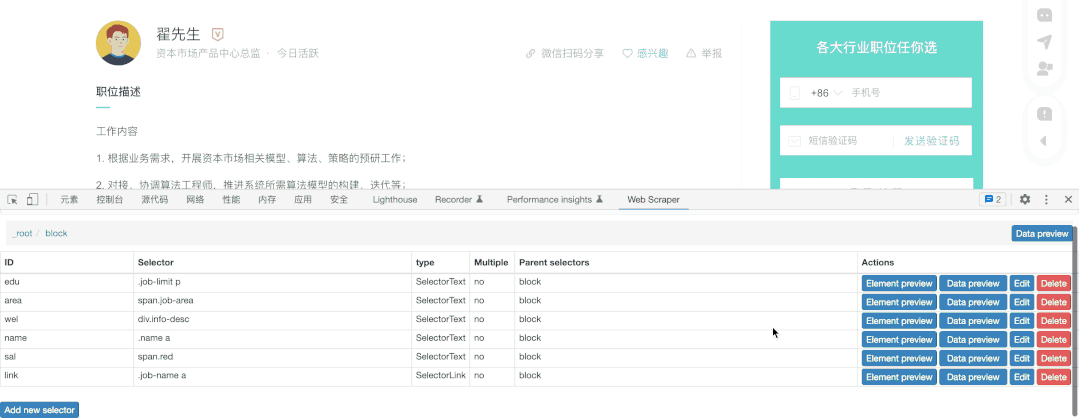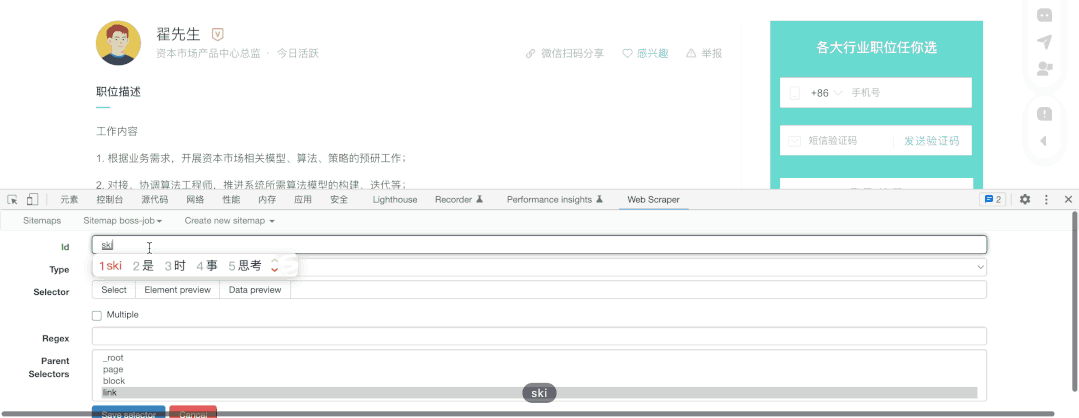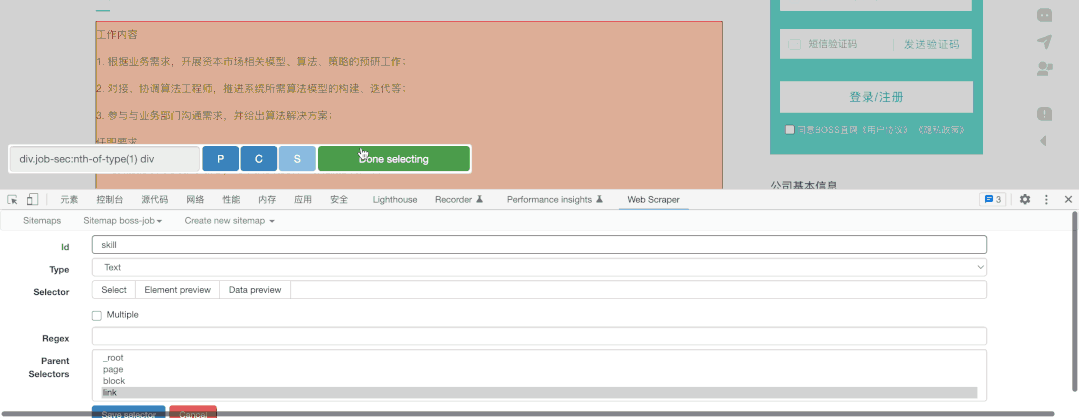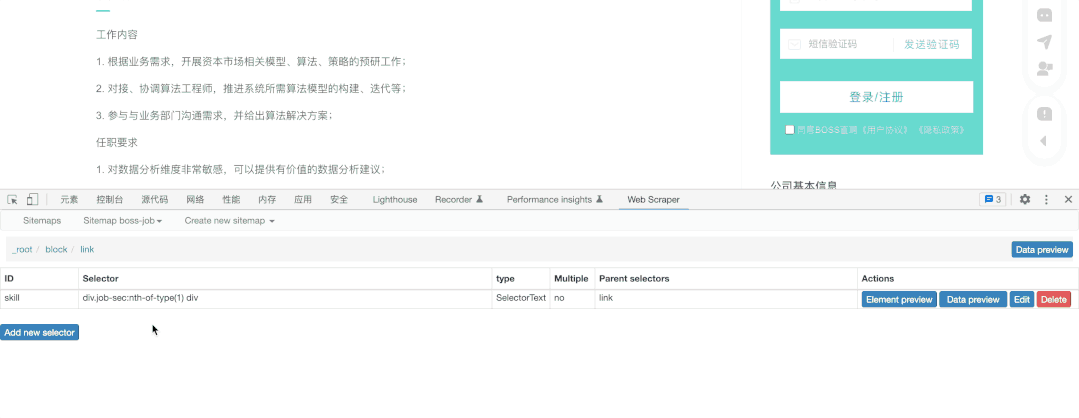
抓取块的目的是为了进一步的抓取块中的元素,也就来到了第三部分:
限于Gif大小,我仅展示薪水的抓取,其它元素的抓取方法相同,我们选择抓取类型为文本(Text),然后直接选择对应文本即可,需要注意这里千万不能勾选Multiple ,因为我们在block中已经勾选了多个block,这里就无须再次勾选。
最后,如果我们还想要抓取到页内的内容,我们只需要增加一个Link类型的抓取,并点击进入详情页抓取需要的内容
这里我把需要的能力给抓取了下来:
到这里,我们的整个抓取流程就结束了,我们来看一下我们的抓取结构,选择Selecter Graph。
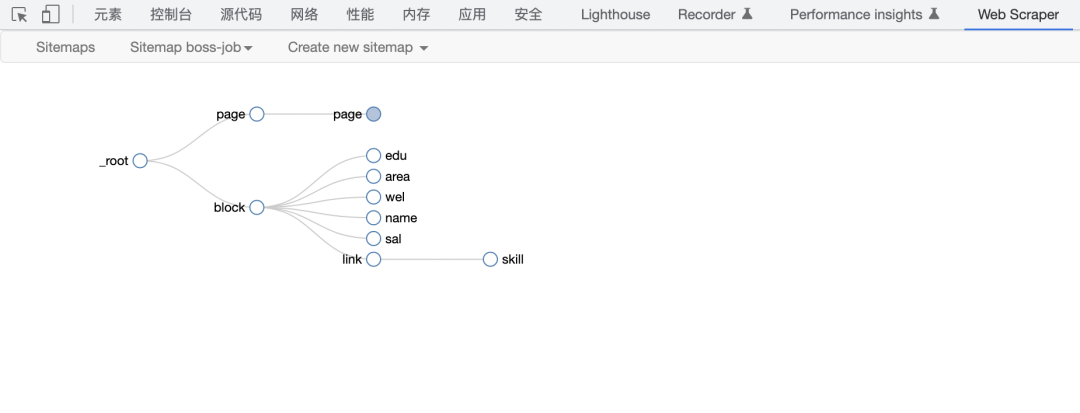
通过该图我们能更清楚地知道我们的抓取层级,页之间的循环抓取、页中区块的抓取实际上是两个同级的参数,而区块中的各参数与区块是父子关系,页内参数也和跳转链接是父子关系,明白这样的层级之后,我们就可以抓取所有的网页内容。
现在我们就可以选择Scrape进行内容抓取了。
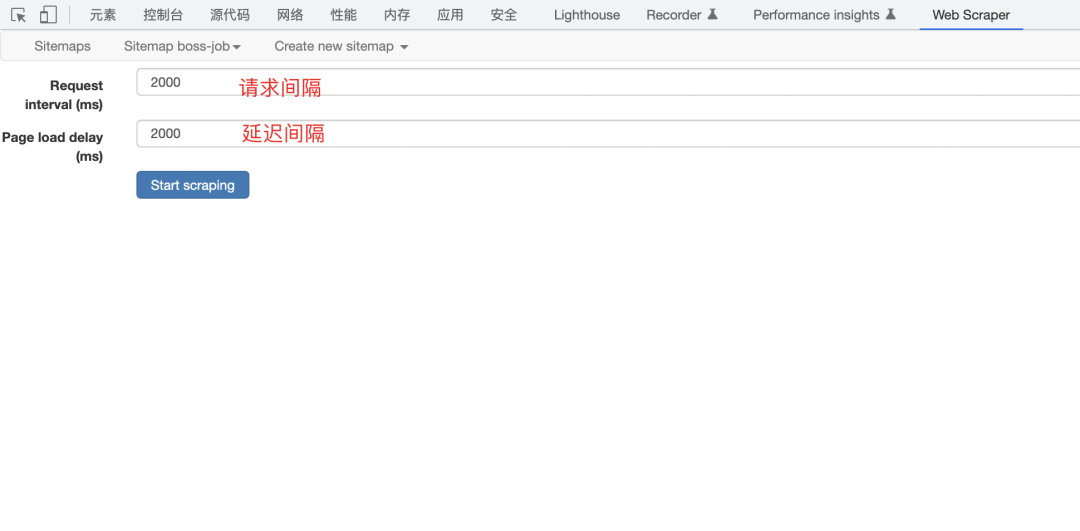
接下来是设置间隔时间,一般情况下默认2000ms就行了,数据量大可以延长间隔时间。
抓取完成后,我们点击Refresh data就可以加载出数据了。
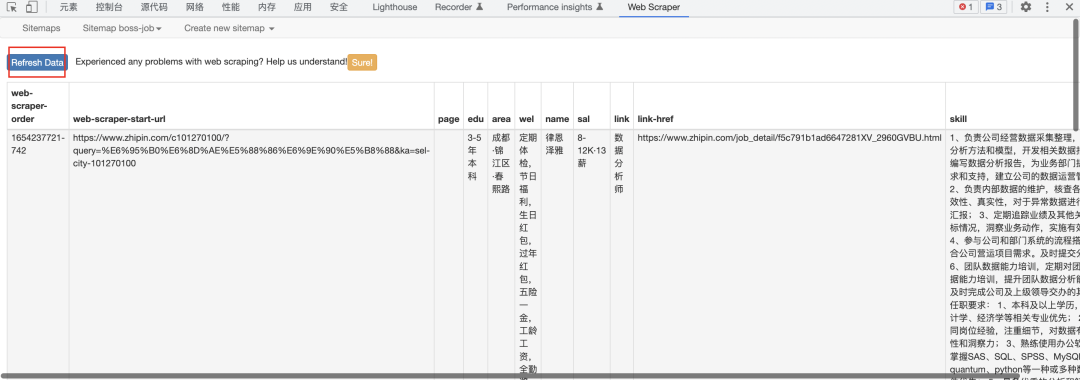
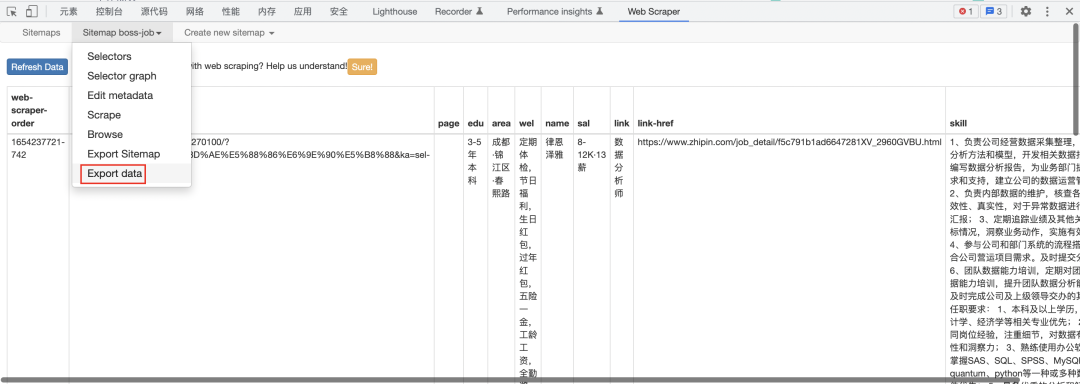
然后选择Export Data导出数据。
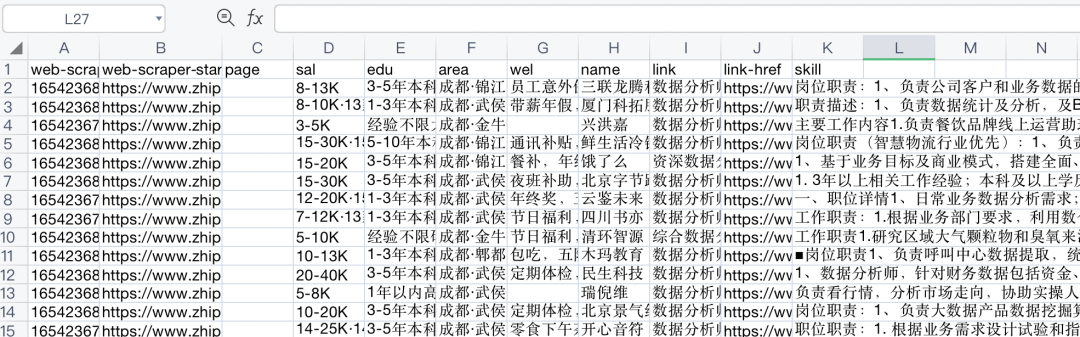
最终数据结果如图:
此外,表格类型抓取我觉得也可以用一下,因为从网上复制粘贴的效果不太好。
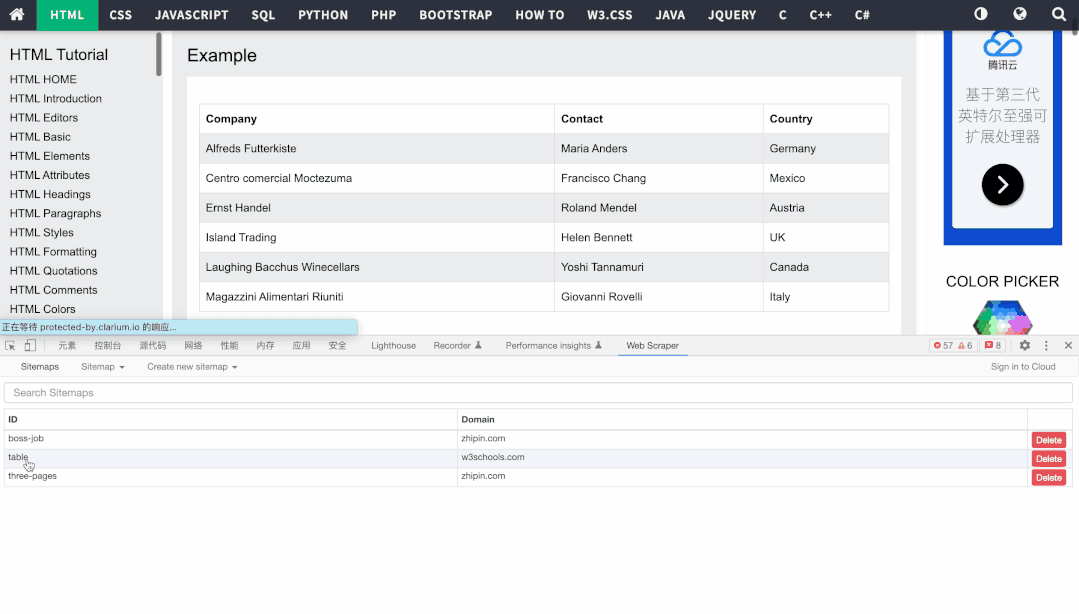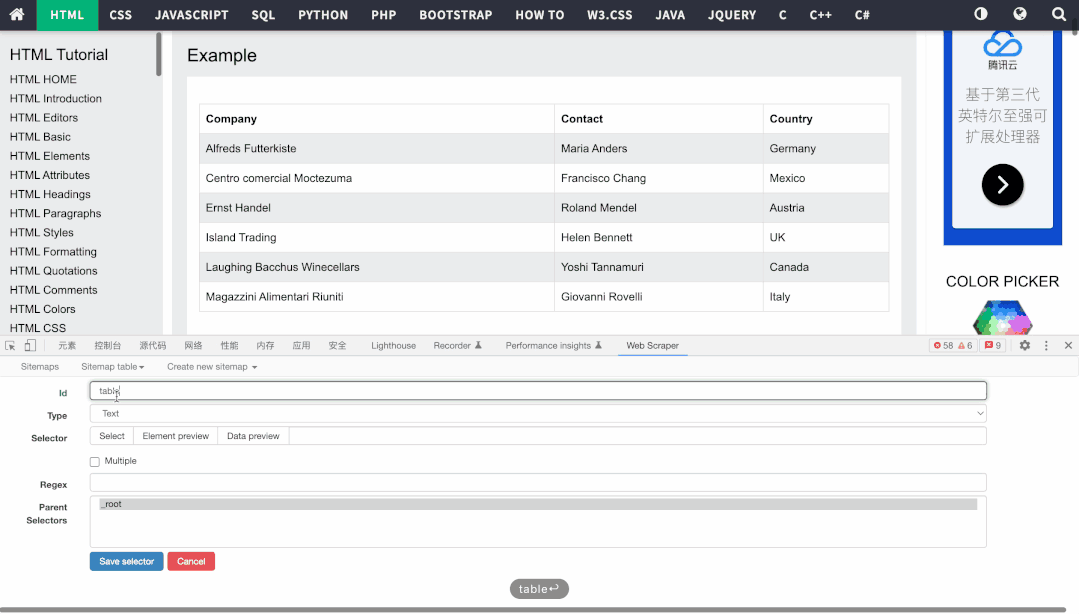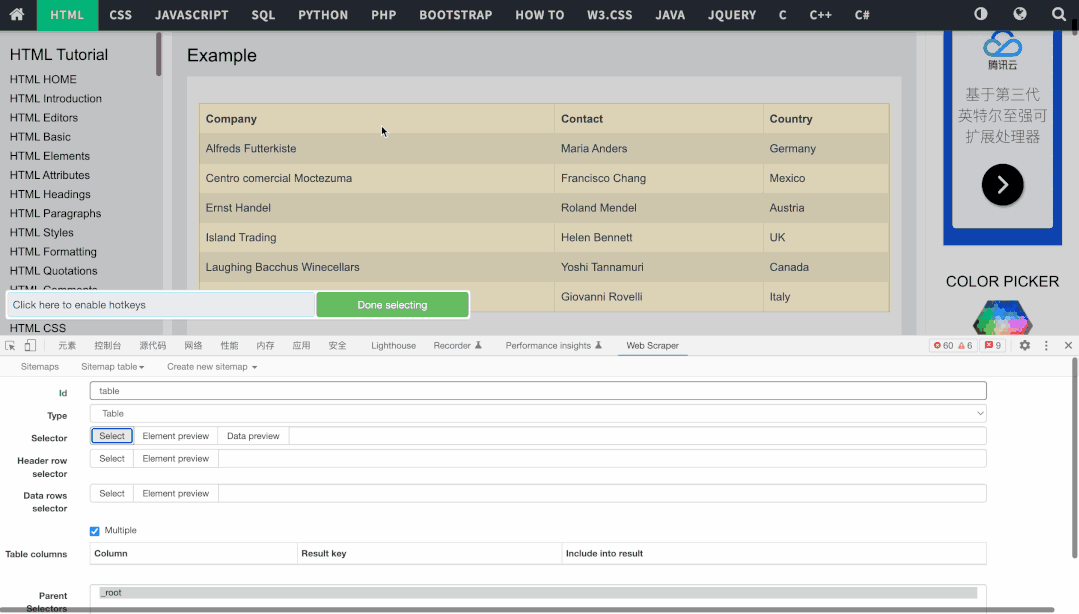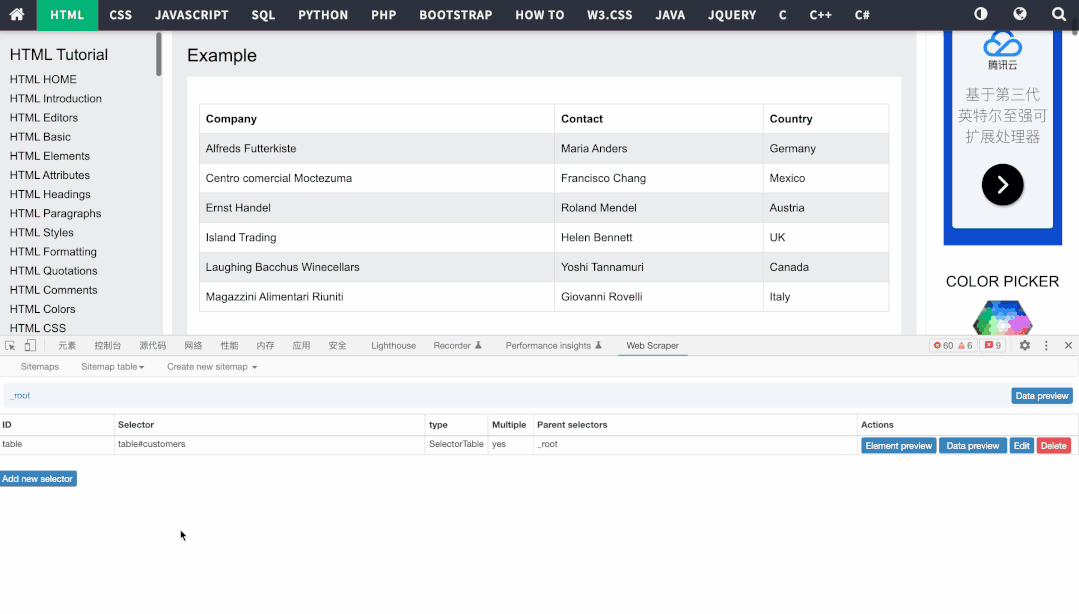
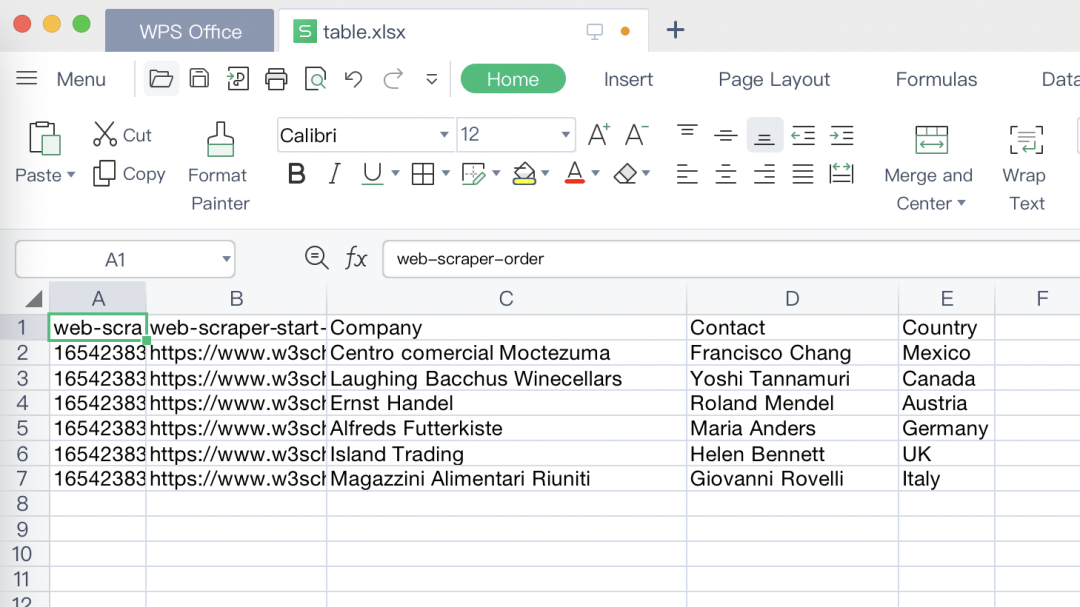
表格抓取的操作非常简单,只需要创建表格页面的Sitemap,然后新建表格类型选择器,选择对应表格即可,导出结果如下:
此外,还有几种类型的抓取,不经常用到,有兴趣可以自己去研究。

文章评论