【导读】遇到编码问题怎么办?了解一下unicode和utf-8编码临危不乱!
大多数的我们,真正认识到有字符编码这回事,一般都是因为遇到了乱码,因为我国常用的编码是 GBK 以及 GB2312:用两个 Byte 来表示所有的汉字,这样,我们一共可以表示 2^16 = 65536 个字符,一旦我们的 GBK 以及 GB2312 编码遇到了其他编码,比如日本,韩国的编码,就会变成乱码,当然,这时候如果是 UTF-8,也会乱码。
我们知道,在计算机内部,为了把二进制数据转换为显示器上,需要进行编码,即将可显示的字符一一对应到二进制数据上,比如 ASCII 码,就是用一个 Byte 的数据来表示英文字符加上一些英文符号。
至于中文,我们显然不能使用仅仅一个 Byte 来表示,我们需要用到更大的空间。
Unicode 与 Code point
在如今这个小小的世界村里,有着那么多的语言与文字,为了兼容所有的字符,Unicode 出现了,但是它需要有更多的 Byte 来将这个世界上所有的字符收纳进去(这里面甚至包含了 Emoji)。
为了了解 Unicode,你需要了解 Code point 即所谓的码点,也就是用 4 个 Byte 大小的数字来表示所有的字符。
至于 Unicode 本身,你可以认为它就是 Code point 的集合,而 UTF-8 呢?就是 Unicode 的编码方式。
Unicode 与 UTF-8 编码
下面的图来自 UTF-8 的截图:
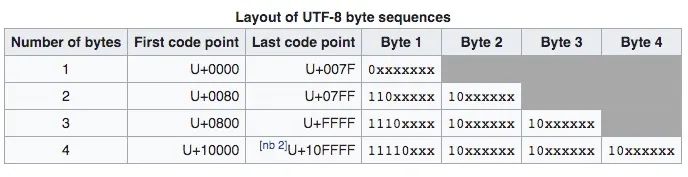
这幅图简单明了的告诉我们,UTF-8 的编码方式,比如汉字一般用三个 Byte,每个 Byte 的开头都是固定的,各种文字软件解析 UTF-8 编码的时候,它就会按照这个格式去解析,一旦解析错误(毕竟还可能会有不符合要求的数据,或者是文件错误了),错误的字节就会被替换为 "�" (U+FFFD),然后神奇的地方就来了:即使遇到这种错误,它也不会影响接下来的其他字符的解析,因为这种编码不必从头开始,使得它可以自我同步(Self-synchronizing)。与此同时,其它的一些编码一旦遇到错误编码就会出问题,导致错误编码之后的正确编码也会跟着出错。
当然,UTF-8 编码也有缺点,由于它是可变的,当英文字符偏多的时候,它会省空间,然而比如当中文偏多的时候,它理论上(3 Byte)会比 GBK 编码(2 Byte)最多多出 1/3 的存储空间。
UTF-8 的例子
我们拿 Unicode 中最受欢迎的 Emoji 表情 ? 1 来举例:它的 Code point 是 U+1F602(对,1F602 是以 16 进制表示的),然而在内存中它的存储方式的却是 0xf09f9882,为什么?这就是 UTF-8 的编码了(注意对比上图的编码方式):
000 011111 011000 000010 1f602
11110000 10011111 10011000 10000010 f0 9f 98 82
通过把 UTF-8 的编码格子里面数据提取出来,我们就能获得 Code point 1F602。
你也可以用 Golang 来查看其它字符的编码:
package main
import ( "fmt"
"unicode/utf8"
)
func main() { fmt.Printf("%b\n", []byte(`?`)) fmt.Printf("% x\n", []byte(`?`)) r, _ := utf8.DecodeRuneInString(`?`) fmt.Printf("% b\n", r) fmt.Printf("% x\n", r)}
Unicode 的其他编码
Unicode 当然不止一种编码,还有 UTF-16、UTF-32 等,它们的关系就是 UTF-16 用 2 个 Byte 来表示 UTF-8 分别用 1/2/3 个 Byte 来表示的字符,然后 4 个 Byte 与 UTF-8 一致,UTF-32 是完全用 4 个 Byte 来表示所有的字符,另外,详细的可以在 Comparison of Unicode encodings 中看到,
好,基础讲完,现在开始正式介绍。
Unicode 与 Golang 2
这里特别需要提到的是 Golang 与 UTF-8 的关系,他们背后的男人,都是 Ken Thompson跟 Rob Pike 3 4 5,由此,大家就会明白 Golang 的 UTF-8 设计是有多么重要的参考意义。比如 Golang 设计了一个 rune 类型来取代 Code point 的意义。
rune 看源码就知道,它就是 int32,刚好 4 个 Byte,刚可以用来表示 Unicode 的所有编码 UTF-8 与 UTF-16。
在继续之前,我想帮各位明白一个事实:Golang 的源码是默认 UTF-8 编码的,这点从上面我给出的例子中就能明白,所以表情字符在编译的时候,就已经能被解析。
好了,那么我们来看看 Golang 的 unicode 包,其中就会有很多有用的判断函数:
func IsControl(r rune) bool
func IsDigit(r rune) bool
func IsGraphic(r rune) bool
func IsLetter(r rune) bool
func IsLower(r rune) bool
func IsMark(r rune) bool
func IsNumber(r rune) bool
func IsPrint(r rune) bool
func IsPunct(r rune) bool
func IsSpace(r rune) bool
func IsSymbol(r rune) bool
func IsTitle(r rune) bool
func IsUpper(r rune) bool
另外,在 src/unicode/tables.go 中,有大量的 Unicode 中,各类字符的 Code point 区间,会有比较大的参考价值。
再看看 unicode/utf8 包,这里面的函数,大多数时候你都用不到,但是有这么几类情况就需要你必须得用到了:
-
统计字符数量; -
转编码,比如将 GBK 转为 UTF-8; -
判断字符串是否是 UTF-8 编码,或者是否含有不符合 UTF-8 编码的字符;
后面两个可以忽略,第一个需要特地提醒下:
s := `?`
fmt.Println(len(s))
这句输出是什么?上面提过了,刚好就是 4。于是,你不能使用 len 来获取字符数量,也就不能以此来判断用户输入的字符是不是超过了系统的限制。另外,你也不能通过 s[0] 这样的方式来获取字符,因为这样你只能取到这 4 个 Byte 中的第一个,也就是 0xf0。
你应该做的就是把 string 转为 rune 数组,然后再去进行字符的操作。
具体的使用方法就不细谈了,相信你们能搞定。
另外,这里需要另外提示下,在 Node.js 中,string 本身就是 Unicode,而不是像 Golang 的 string 是二进制,因此在这里可以认为 Node.js 的 Buffer 才是 Golang 中的 string。
好了,最后留给你一个思考题:在 Node.js 中,为什么在处理 Buffer 时候,不能直接拼接?
转自:
github.com/xizhibei/blog/issues/150
- EOF -
Go 开发大全
参与维护一个非常全面的Go开源技术资源库。日常分享 Go, 云原生、k8s、Docker和微服务方面的技术文章和行业动态。

关注后获取
回复 Go 获取6万star的Go资源库
分享、点赞和在看
支持我们分享更多好文章,谢谢!

文章评论