
如何去掉list中重复元素
-
推荐方式
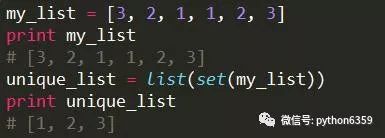
或者
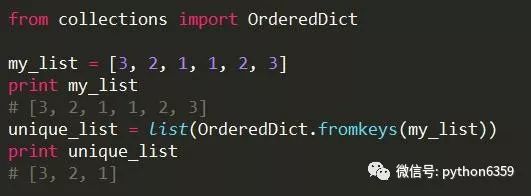
前一种方式不会保留list的元素顺序,后一种方式会保留list的元素顺序。
如何读取dict中的值
-
不推荐方式
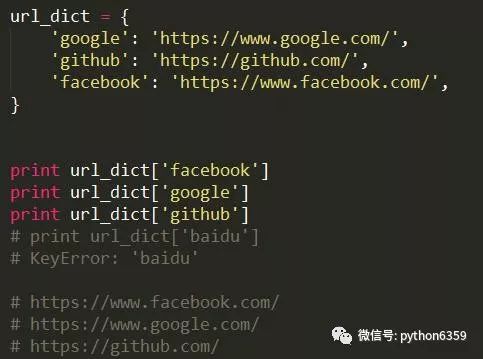
-
推荐方式
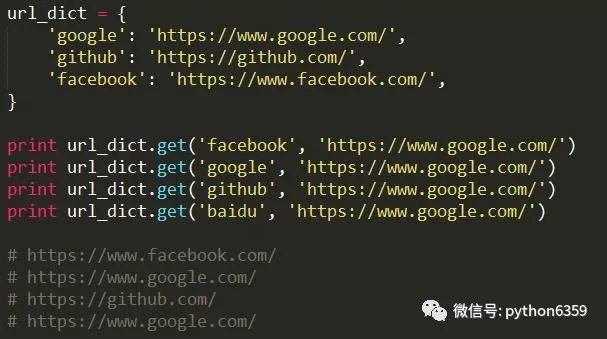
前一种方式读取一个不存在的key时,会导致KeyError,例如print url_dict['baidu'],因为字典中不存在baidu,所以会导致KeyError。后一种方式使用字典的get方法,如果key不存在,不会产生KeyError,如果给了默认值,会返回默认值,否则返回None。
如何排序字典
-
推荐方式
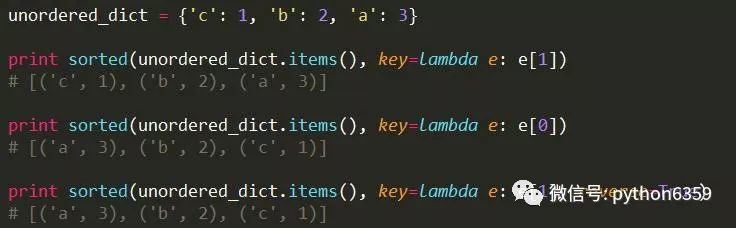
第一种方式是按字典的value升序排序,第二种方式是按字典的key升序排序,第三种方式是按字典的value降序排序,和第一种方式相反,因为指定了参数reverse为True。sorted函数功能挺强大,不止可以排序字典,任何iterable对象都可以排序。
如何打印更易读的类
-
不推荐方式
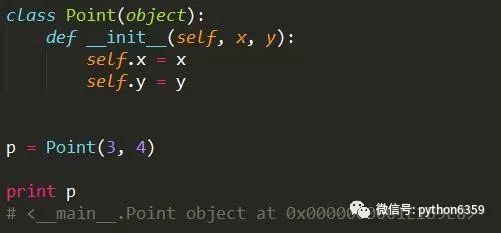
-
推荐方式
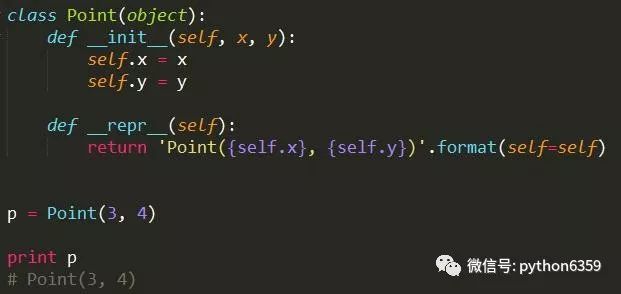
前一种方式打印的类不易读,不能获取更多的信息。通过类的repr方法可以将类打印得更易读。或者不定义repr方法,直接使用下面方式打印:
print p.__dict__# {'y': 4, 'x': 3}
使用dict方法,将类以字典形式打印出来,也比较易读。
如何将类打印成json字符串
-
推荐方式
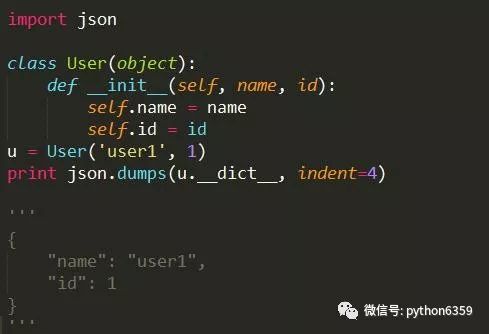
通过json模块的dumps方法,可以轻易将类打印成json字符串。
如何排序类列表
-
推荐方式
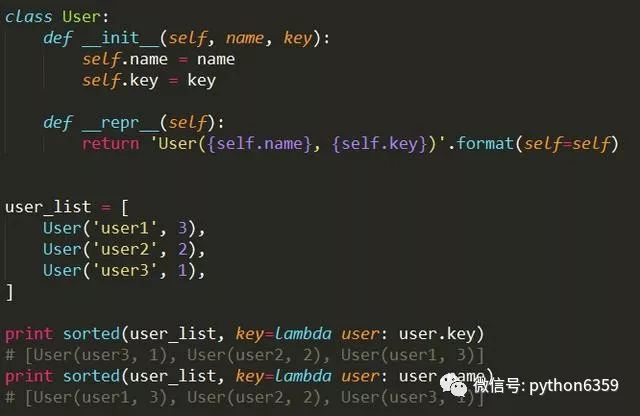
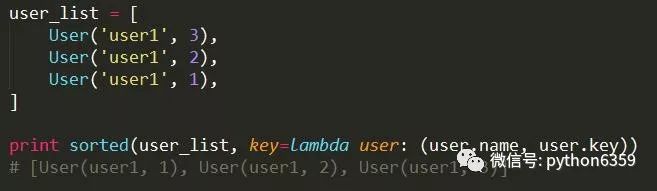
这里排序的方法和字典排序类似,第一种是按user的key升序排序,第二种是按user的name升序排序。其实还支持名字相同,再按key进行排序,如下:
如何在命令行查看python文档
-
推荐方式
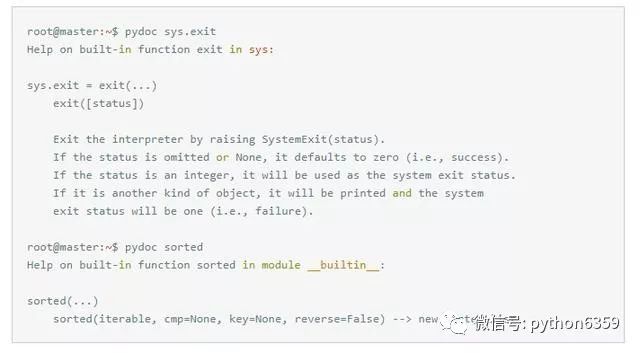
第一个命令pydoc sys.exit查看sys模块的exit函数文档信息,第二个命令pydoc sorted查看了内建函数sorted的文档信息。
如何将python代码打包成独立的二进制文件
-
推荐方式
需要编译的python代码如下:
#!/usr/bin/env python# -*- coding: utf-8 -*-print 'hello, world!'
将python代码打包成独立的二进制文件步骤:
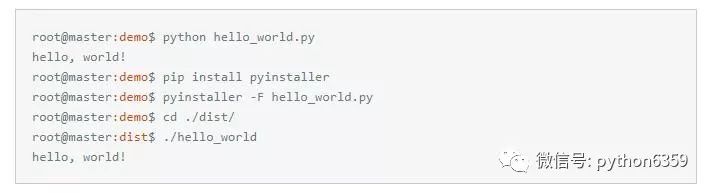
我解释下上面命令行,首先使用python直接运行需要编译成独立二进制文件的hello_world.py,程序正常打印hello, world!,然后使用pip安装pyinstaller,通过pyinstaller将hello_world.py打包成独立的二进制文件,然后进入当前目录下的dist目录,运行打包成功的二进制文件hello_world,程序正常打印hello, world!。除了pyinstaller,还有其他工具可以实现类似功能
如何自动格式化python代码
-
推荐方式
格式化前的demo.py代码:
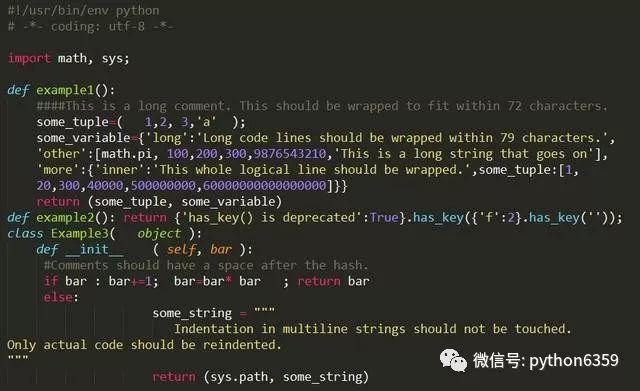
安装autopep8,并使用autopep8格式化demo.py代码:
root@master:demo$ pip install autopep8root@master:demo$ autopep8 --in-place --aggressive --aggressive demo.py
格式化后的demo.py代码:
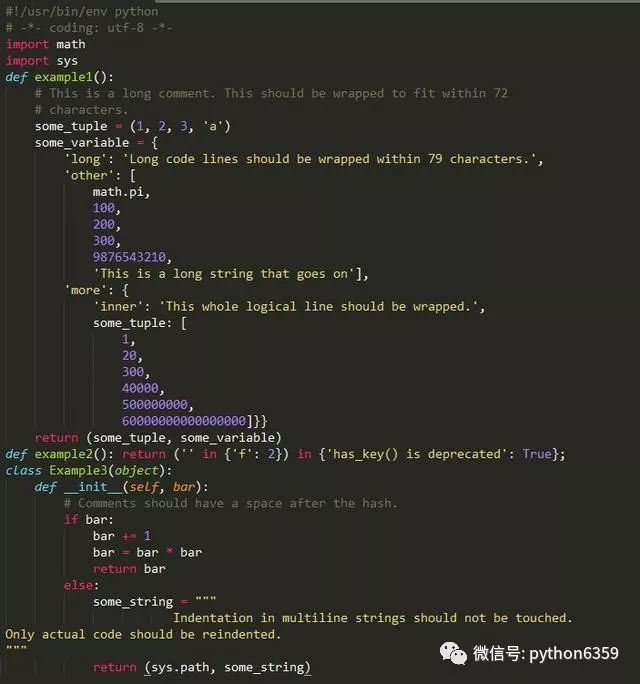
可以看到,经过autopep8格式化后的python代码更易读,也符合python的代码风格,这里的示例代码使用autopep8官方例子。
正确的函数返回
-
不推荐方式
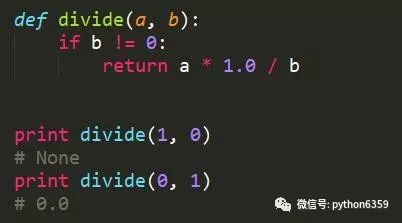
-
推荐方式
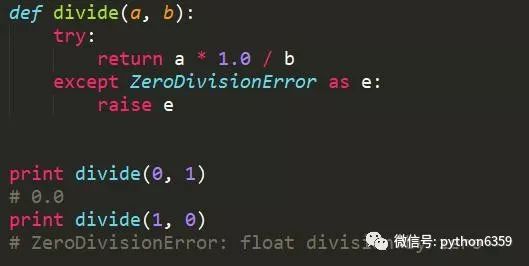
前一种方式中,如果输入的参数b为0,函数会默认返回None,这是一个不太好的编程习惯。例如,当把函数的返回值作为if条件判断时,0.0和None都是False,这样容易导致bug。后面这种方式,将除数是0当成异常抛出,让调用者处理异常,是比较合理的做法。
正确使用函数默认参数
-
不推荐方式
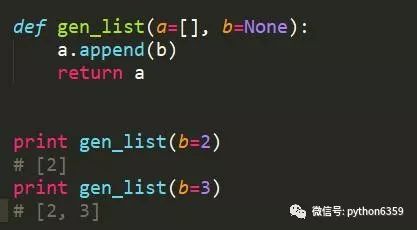
-
推荐方式
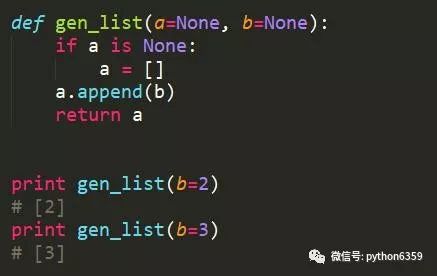
前一种方式会导致函数默认值改变,多次调用相互影响。正确方式是将函数默认值设置成None,在函数内部初始化默认参数。这里只是针对传递引用类型的参数,如果是数字、字符串等类型就不存在该问题。
利用元组传递多个函数参数
-
推荐方式


文章评论