
压测监控最重要的 3 个指标:请求成功率、服务吞吐量(TPS)、请求响应时长(RT),这 3 个指标任意一个出现拐点,都可以认为系统已达到性能瓶颈。
这里特别说明下响应时长,对于这个指标,用平均值来判断很有误导性,因为一个系统的响应时长并不是平均分布的,往往会出现长尾现象,表现为一部分用户请求的响应时间特别长,但整体平均响应时间符合预期,这样其实是影响了一部分用户的体验,不应该判断为测试通过。因此对于响应时长,常用 99、95、90 分位值来判断系统响应时长是否达标。
另外,如果需要观察请求响应时长的分布细节,可以补充请求建联时长(Connect Time)、等待响应时长(Idle Time)等指标。
资源性能指标
压测过程中,对系统硬件、中间件、数据库资源的监控也很重要,包括但不限于:
-
CPU 使用率
-
内存使用率
-
磁盘吞吐量
-
网络吞吐量
-
数据库连接数
-
缓存命中率
... ...
详细可见《测试指标》[1]一文。
施压机性能指标
压测链路中,施压机性能是容易被忽略的一环,为了保证施压机不是整个压测链路的性能瓶颈,需要关注如下施压机性能指标:
-
压测进程的内存使用量
-
施压机 CPU 使用率,Load1、Load5 负载指标
-
基于 JVM 的压测引擎,需要关注垃圾回收次数、垃圾回收时长
开源压测工具如 JMeter 本身支持简单的系统性能监控指标,如:请求成功率、系统吞吐量、响应时长等。但是对于大规模分布式压测来说,开源压测工具的原生监控有如下不足:
-
监控指标不够全面,一般只包含了基础的系统性能指标,只能用于判断压测是否通过。但是如果压测不通过,需要排查、定位问题时,如分析一个 API 的 99 分位建联时长,原生监控指标就无法实现。
-
聚合时效性不能保证
-
无法支持大规模分布式的监控数据聚合
-
监控指标不支持按时间轴回溯
综上,在大规模分布式压测中,不推荐使用开源压测工具的原生监控。
下面对比 2 种开源的监控方案:
方案一:Zabbix
Zabbix 是早期开源的分布式监控系统,支持 MySQL 或 PostgreSQL 关系型数据库作为数据源。
对于系统性能监控,需要施压机提供秒级的监控指标,每秒高并发的监控指标写入,使关系型数据库成为了监控系统的瓶颈。
对于资源性能监控,Zabbix 对物理机、虚拟机的指标很全面,但是对容器、弹性计算的监控支持还不够。
方案二:Prometheus
Prometheus 使用时序数据库作为数据源,相比传统关系型数据库,读写性能大大提高,对于施压机大量的秒级监控数据上报的场景,性能表现良好。
对于资源性能监控,Prometheus 更适用于云资源的监控,尤其对 Kubernates 和容器的监控非常全面,对使用云原生技术的用户,上手更简单。
总结下来,Prometheus 相较 Zabbix,更适合于压测中高并发监控指标的采集和聚合,并且更适用于云资源的监控,且易于扩展。
当然,使用成熟的云产品也是一个很好选择,如压测工具 PTS[2]+可观测工具 ARMS[3],就是一组黄金搭档。PTS 提供压测时的系统性能指标,ARMS 提供资源监控和整体可观测的能力,一站式解决压测可观测的问题。
怎么使用 Prometheus 实现压测监控
Cloud Native
Prometheus 是拉数据模型,因此需要压测引擎暴露 HTTP 服务,供 Prometheus 获取各压测指标。
JMeter 提供了插件机制,可以自定义插件来扩展 Prometheus 监控能力。在自定插件中,需要扩展 JMeter 的 BackendListener,让在采样器执行完成时,更新每个压测指标,如成功请求数、失败请求数、请求响应时长。并将各压测指标在内存中保存,在 Prometheus 拉数据时,通过 HTTP 服务暴露出去。整体结构如下:
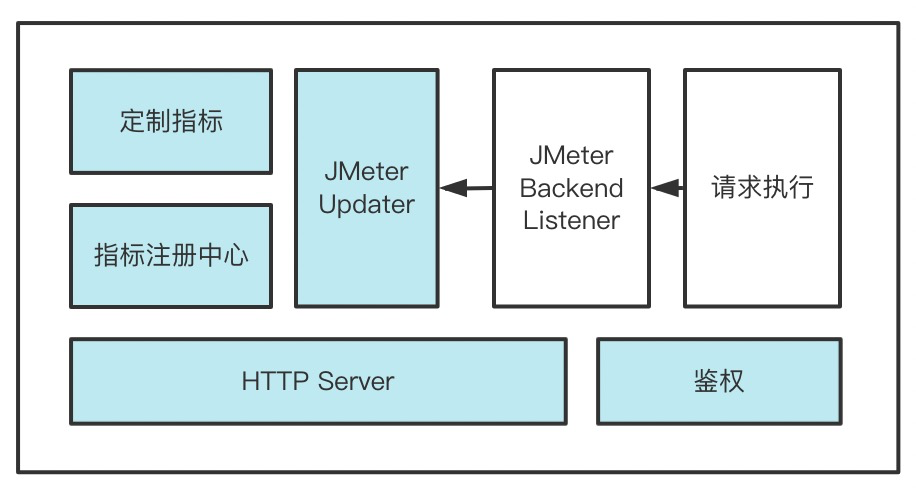
JMeter 自定义插件需要改造的点:
-
增加指标注册中心
-
扩展 Prometheus 指标更新器
-
实现自定义 JMeter BackendListener,在采样器执行结束后,调用 Prometheus 更新器
-
实现 HTTP Server,如果有安全需要,补充鉴权逻辑
性能测试 PTS(Performance Testing Service)是一款阿里云 SaaS 化的性能测试工具。PTS支持自研压测引擎,同时支持开源 JMeter 压测,在 PTS 上开放压测指标到 Prometheus,无需开发自定义插件来改造引擎,只需 3 步白屏化操作即可。
具体步骤如下:
-
PTS 压测的高级设置中,打开【Prometheus】开关
-
压测开始后,在【监控导出】一键复制 Prometheus 配置
-
自建的 Prometheus 中粘贴并热加载此配置,即可生效
详细参考:《如何将 PTS 压测的指标数据输出到 Prometheus》[4]
快速搭建 Grafana 监控大盘
Cloud Native
PTS 提供了官方 Grafana 大盘模板[5],支持一键导入监控大盘,并可以灵活编辑和扩展,满足您的定制监控需求。
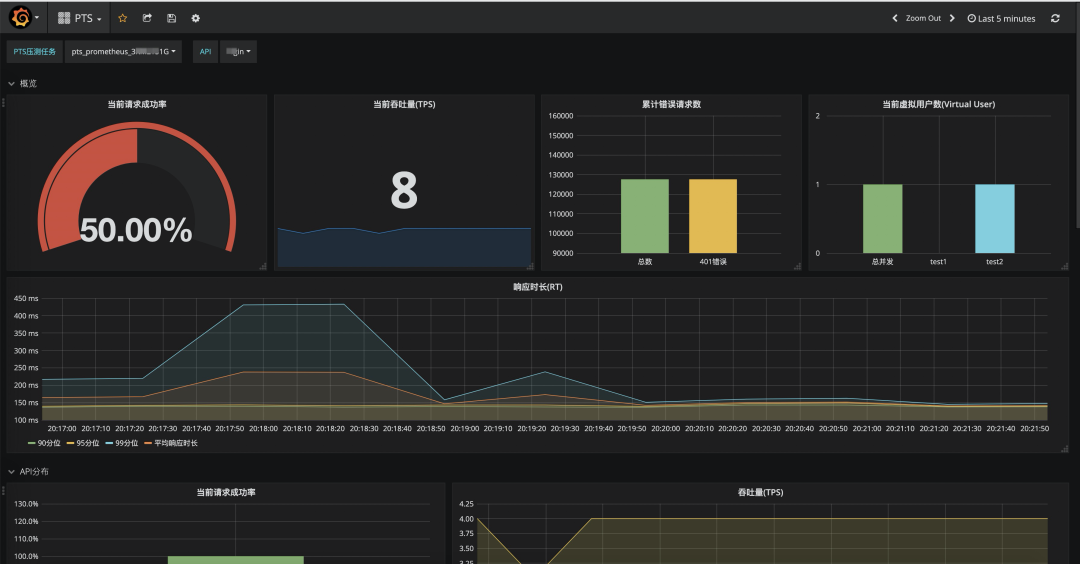
本大盘提供了全局请求成功率,系统吞吐量(TPS),99、95、90 分位响应时长,以及按错误状态码聚合的错误请求数等数据。
在 API 分布专栏中,可以直观的对比各 API 的监控指标,快速定位性能短板 API。
在 API 详情专栏中,可以查看单个 API 的详细指标,准确定位性能瓶颈。
另外,大盘还提供了施压机的JVM垃圾回收监控指标,可以辅助判断施压机是否是压测链路中的性能瓶颈。
导入步骤如下:
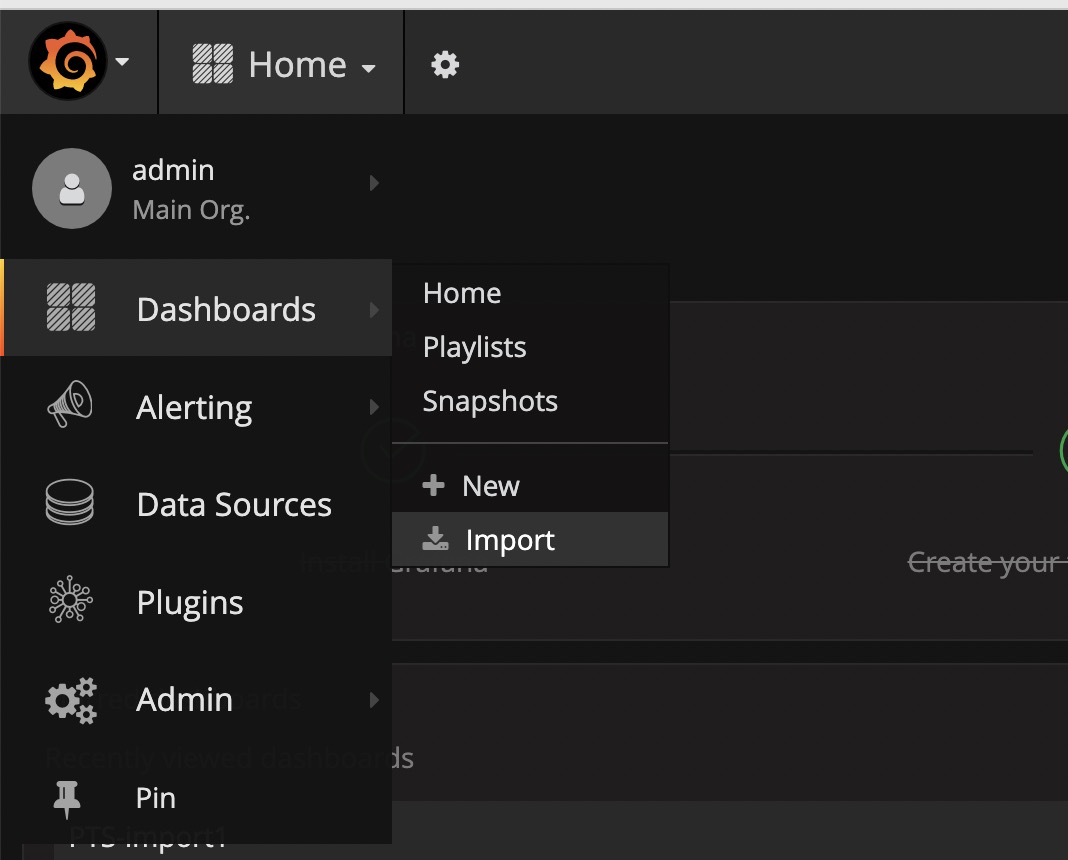
步骤一
在菜单栏,点击 Dashboard 下的 import:
步骤二
填写 PTS Dashboard 的 id:15981
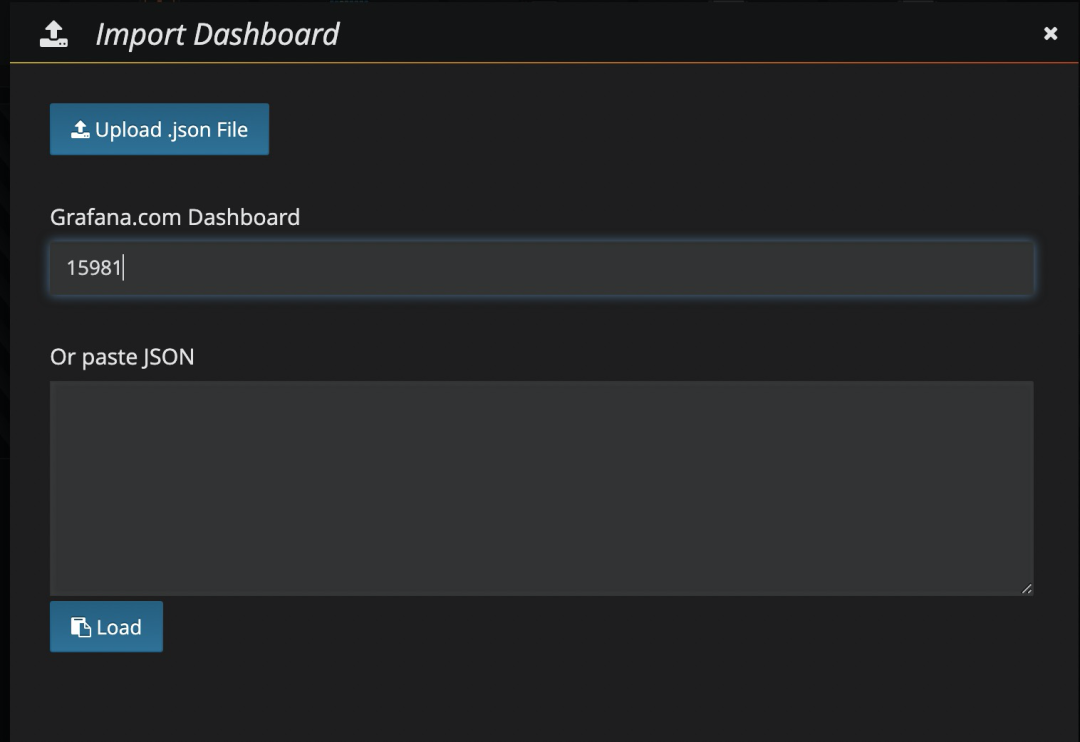
在 Prometheus 选择您已有的数据源,本示例中数据源名为 Prometheus。选中后,单击 Import 导入
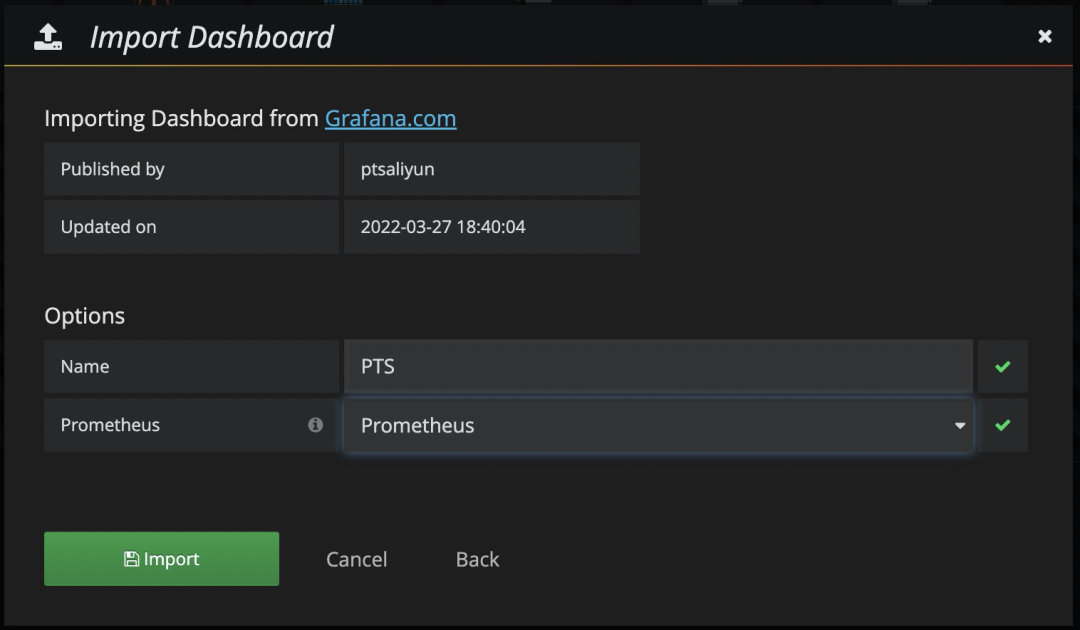
步骤三
导入后,在左上角【PTS 压测任务】,选择需要监控的压测任务,即可看到当前监控大盘。
此任务名对应 PTS 控制台在监控导出-Prometheus 配置中的 jobname。
总结
Cloud Native
本文阐述了
-
什么是性能测试可观测
-
为什么用 Prometheus 做压测性能指标监控
-
如何使用开源 JMeter 和云上 PTS 实现基于 Prometheus 的压测监控
PTS 压测监控导出 Prometheus 功能,目前免费公测中,欢迎使用。
同时,PTS 全新售卖方式来袭,基础版价格直降 50%!百万并发价格只需 6200!更有新用户 0.99 体验版、VPC 压测专属版,欢迎大家选购!

相关链接
Cloud Native
[1] 测试指标
https://help.aliyun.com/document_detail/29338.html
[2] 压测工具 PTS
https://www.aliyun.com/product/pts
[3] 可观测工具 ARMS
https://www.aliyun.com/product/arms
[4] 如何将 PTS 压测的指标数据输出到 Prometheus
https://help.aliyun.com/document_detail/416784.html
[5]官方 Grafana 大盘模板
https://grafana.com/grafana/dashboards/15981
点击阅读原文,了解性能测试 PTS 更多资讯!

文章评论