链接:https://blog.devgenius.io/linux-troubleshoot-network-latency-a6da740f5cb8
在我的上一篇文章中,我向您展示了如何模拟 DDoS 攻击以及如何缓解它。简单回顾一下,DDoS 利用了大量的伪造请求,导致目标服务器消耗大量资源来处理这些无效请求,从而无法正常响应正常用户请求。
在 Linux 服务器中,可以通过内核调优、DPDK 以及 XDP 等多种方式提高服务器的抗攻击能力,降低 DDoS 对正常服务的影响。在应用程序中,可以使用各级缓存、WAF、CDN 等来缓解 DDoS 对应用程序的影响。
但是需要注意的是,如果 DDoS 流量已经到达 Linux 服务器,那么即使应用层做了各种优化,网络服务延迟一般也会比平时大很多。
因此,在实际应用中,我们通常使用 Linux 服务器,配合专业的流量清洗和网络防火墙设备,来缓解这个问题。
除了 DDoS 导致的网络延迟增加,我想你一定见过很多其他原因导致的网络延迟,例如:
网络传输慢导致的延迟。 Linux 内核协议栈数据包处理速度慢导致的延迟。 应用程序数据处理速度慢造成的延迟等。 那么当我们遇到这些原因造成的延误时,我们该怎么办呢?如何定位网络延迟的根本原因?让我们在本文中讨论网络延迟。
Linux 网络延迟
谈到网络延迟(Network Latency),人们通常认为它是指网络数据传输所需的时间。但是,这里的“时间”是指双向流量,即数据从源发送到目的地,然后从目的地地址返回响应的往返时间:RTT(Round-Trip Time)。
除了网络延迟之外,另一个常用的指标是应用延迟(Application Latency),它是指应用接收请求并返回响应所需的时间。通常,应用延迟也称为往返延迟,它是网络数据传输时间加上数据处理时间的总和。
通常人们使用
ping命令来测试网络延迟,ping是基于 ICMP 协议的,它通过计算 ICMP 发出的响应报文和 ICMP 发出的请求报文之间的时间差来获得往返延迟时间。这个过程不需要特殊的认证,从而经常被很多网络攻击所利用,如,端口扫描工具nmap、分组工具hping3等。因此,为了避免这些问题,很多网络服务都会禁用 ICMP,这使得我们无法使用 ping 来测试网络服务的可用性和往返延迟。在这种情况下,您可以使用
traceroute或hping3的 TCP 和 UDP 模式来获取网络延迟。例如:
# -c: 3 requests
# -S: Set TCP SYN
# -p: Set port to 80
$ hping3 -c 3 -S -p 80 google.com
HPING google.com (eth0 142.250.64.110): S set, 40 headers + 0 data bytes
len=46 ip=142.250.64.110 ttl=51 id=47908 sport=80 flags=SA seq=0 win=8192 rtt=9.3 ms
len=46 ip=142.250.64.110 ttl=51 id=6788 sport=80 flags=SA seq=1 win=8192 rtt=10.9 ms
len=46 ip=142.250.64.110 ttl=51 id=37699 sport=80 flags=SA seq=2 win=8192 rtt=11.9 ms
--- baidu.com hping statistic ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 9.3/10.9/11.9 ms当然,你也可以使用
traceroute:$ traceroute --tcp -p 80 -n google.com
traceroute to google.com (142.250.190.110), 30 hops max, 60 byte packets
1 * * *
2 240.1.236.34 0.198 ms * *
3 * * 243.254.11.5 0.189 ms
4 * 240.1.236.17 0.216 ms 240.1.236.24 0.175 ms
5 241.0.12.76 0.181 ms 108.166.244.15 0.234 ms 241.0.12.76 0.219 ms
...
24 142.250.190.110 17.465 ms 108.170.244.1 18.532 ms 142.251.60.207 18.595 ms
traceroute会在路由的每一跳(hop)发送三个数据包,并在收到响应后输出往返延迟。如果没有响应或响应超时(默认 5s),将输出一个星号*。案例展示
我们需要在此演示中托管 host1 和 host2 两个主机:
host1 (192.168.0.30):托管两个 Nginx Web 应用程序(正常和延迟)
host2 (192.168.0.2):分析主机
host1 准备
在 host1 上,让我们运行启动两个容器,它们分别是官方 Nginx 和具有延迟版本的 Nginx:
# Official nginx
$ docker run --network=host --name=good -itd nginx
fb4ed7cb9177d10e270f8320a7fb64717eac3451114c9fab3c50e02be2e88ba2
# Latency version of nginx
$ docker run --name nginx --network=host -itd feisky/nginx:latency
b99bd136dcfd907747d9c803fdc0255e578bad6d66f4e9c32b826d75b6812724运行以下命令以验证两个容器都在为流量提供服务:
$ curl http://127.0.0.1
<!DOCTYPE html>
<html>
...
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
$ curl http://127.0.0.1:8080
...
<p><em>Thank you for using nginx.</em></p>
</body>
</html>host2 准备
现在让我们用上面提到的
hping3来测试它们的延迟,看看有什么区别。在 host2 中,执行以下命令分别测试案例机的 8080 端口和 80 端口的延迟:80 端口:
$ hping3 -c 3 -S -p 80 192.168.0.30
HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes
len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=80 flags=SA seq=0 win=29200 rtt=7.8 ms
len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=80 flags=SA seq=1 win=29200 rtt=7.7 ms
len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=80 flags=SA seq=2 win=29200 rtt=7.6 ms
--- 192.168.0.30 hping statistic ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 7.6/7.7/7.8 ms8080 端口:
# 测试8080端口延迟
$ hping3 -c 3 -S -p 8080 192.168.0.30
HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes
len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=8080 flags=SA seq=0 win=29200 rtt=7.7 ms
len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=8080 flags=SA seq=1 win=29200 rtt=7.6 ms
len=44 ip=192.168.0.30 ttl=64 DF id=0 sport=8080 flags=SA seq=2 win=29200 rtt=7.3 ms
--- 192.168.0.30 hping statistic ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 7.3/7.6/7.7 ms从这个输出中您可以看到两个端口的延迟大致相同,均为 7 毫秒。但这仅适用于单个请求。如果换成并发请求怎么办?接下来,让我们用
wrk(https://github.com/wg/wrk) 试试。80 端口:
$ wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30/
Running 10s test @ http://192.168.0.30/
2 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 9.19ms 12.32ms 319.61ms 97.80%
Req/Sec 6.20k 426.80 8.25k 85.50%
Latency Distribution
50% 7.78ms
75% 8.22ms
90% 9.14ms
99% 50.53ms
123558 requests in 10.01s, 100.15MB read
Requests/sec: 12340.91
Transfer/sec: 10.00MB8080 端口:
$ wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/
Running 10s test @ http://192.168.0.30:8080/
2 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 43.60ms 6.41ms 56.58ms 97.06%
Req/Sec 1.15k 120.29 1.92k 88.50%
Latency Distribution
50% 44.02ms
75% 44.33ms
90% 47.62ms
99% 48.88ms
22853 requests in 10.01s, 18.55MB read
Requests/sec: 2283.31
Transfer/sec: 1.85MB从以上两个输出可以看出,官方 Nginx(监听 80 端口)的平均延迟为 9.19ms,而案例 Nginx(监听 8080 端口)的平均延迟为 43.6ms。从延迟分布上来看,官方 Nginx 可以在 9ms 内完成 90% 的请求;对于案例 Nginx,50% 的请求已经达到 44ms。
那么这里发生了什么呢?我们来做一些分析:
在 host1 中,让我们使用
tcpdump捕获一些网络数据包:$ tcpdump -nn tcp port 8080 -w nginx.pcap现在,在 host2 上重新运行
wrk命令$ wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/当
wrk命令完成后,再次切换回 Terminal 1(host1 的终端)并按 Ctrl+C 结束tcpdump命令。然后,用Wireshark把抓到的nginx.pcap复制到本机(如果 VM1(host1 的虚拟机)已经有图形界面,可以跳过复制步骤),用Wireshark打开。由于网络包的数量很多,我们可以先过滤一下。例如,选中一个包后,可以右键选择 “Follow”->“TCP Stream”,如下图:
然后,关闭弹出的对话框并返回
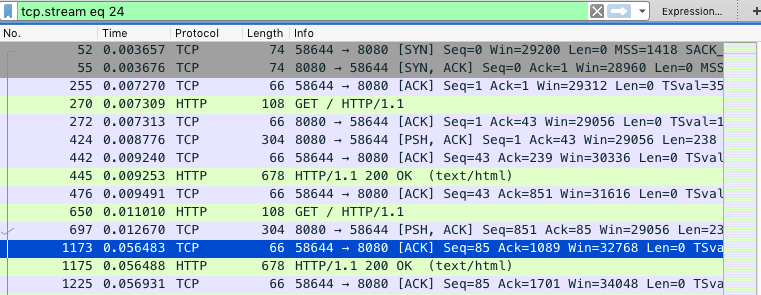
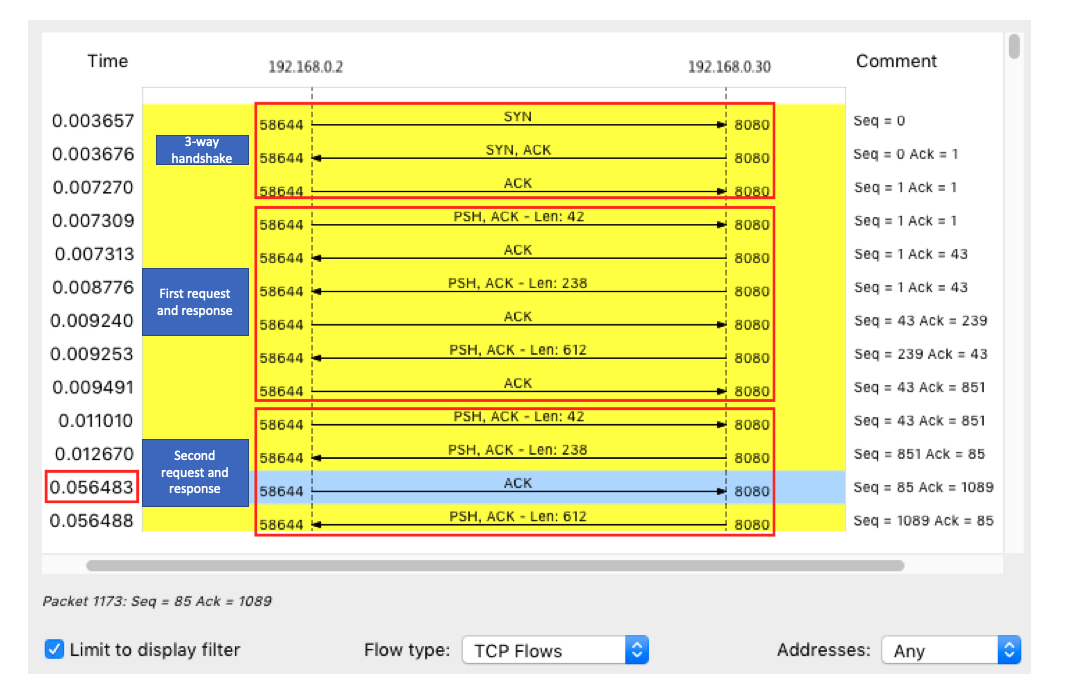
Wireshark主窗口。这时你会发现Wireshark已经自动为你设置了一个过滤表达式tcp.stream eq 24。如下图所示(图中省略了源 IP 和目的 IP):从这里,您可以看到从三次握手开始,此 TCP 连接的每个请求和响应。当然,这可能不够直观,可以继续点击菜单栏中的 Statistics -> Flow Graph,选择 “Limit to display filter”,将 Flow type 设置为 “TCP Flows”:
请注意,此图的左侧是客户端,而右侧是 Nginx 服务器。从这个图中可以看出,前三次握手和第一次 HTTP 请求和响应都相当快,但是第二次 HTTP 请求就比较慢了,尤其是客户端收到服务器的第一个数据包后,该 ACK 响应(图中的蓝线)在 40ms 后才被发送。
看到 40ms 的值,你有没有想到什么?事实上,这是 TCP 延迟 ACK 的最小超时。这是 TCP ACK 的一种优化机制,即不是每次请求都发送一个 ACK,而是等待一段时间(比如 40ms),看看有没有“搭车”的数据包。如果在此期间还有其他数据包需要发送,它们将与 ACK 一起被发送。当然,如果等不及其他数据包,超时后会单独发送 ACK。
由于案例中的客户端发生了 40ms 延迟,我们有理由怀疑客户端开启了延迟确认机制(Delayed Acknowledgment Mechanism)。这里的客户端其实就是之前运行的
wrk。根据 TCP 文档,只有在 TCP 套接字专门设置了
TCP_QUICKACK时才会启用快速确认模式(Fast Acknowledgment Mode);否则,默认使用延迟确认机制:TCP_QUICKACK (since Linux 2.4.4)
Enable quickack mode if set or disable quickack mode if cleared. In quickack mode, acks are sent imme‐
diately, rather than delayed if needed in accordance to normal TCP operation. This flag is not perma‐
nent, it only enables a switch to or from quickack mode. Subsequent operation of the TCP protocol will
once again enter/leave quickack mode depending on internal protocol processing and factors such as
delayed ack timeouts occurring and data transfer. This option should not be used in code intended to be
portable.让我们测试一下我们的质疑:
$ strace -f wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/
...
setsockopt(52, SOL_TCP, TCP_NODELAY, [1], 4) = 0
...可以看到
wrk只设置了TCP_NODELAY选项,没有设置TCP_QUICKACK。现在您可以看到为什么延迟 Nginx(案例 Nginx)响应会出现一个延迟。结论
在本文中,我将向您展示如何分析增加的网络延迟。网络延迟是核心网络性能指标。由于网络传输、网络报文处理等多种因素的影响,网络延迟是不可避免的。但过多的网络延迟会直接影响用户体验。
使用
hping3和wrk等工具确认单个请求和并发请求的网络延迟是否正常。使用
traceroute,确认路由正确,并查看路由中每个网关跳跃点的延迟。使用
tcpdump和Wireshark确认网络数据包是否正常收发。使用
strace等观察应用程序对网络 socket 的调用是否正常。
本公众号全部博文已整理成一个目录,请在公众号里回复「m」获取! 推荐阅读:
5T技术资源大放送!包括但不限于:C/C++,Linux,Python,Java,PHP,人工智能,单片机,树莓派,等等。在公众号内回复「1024」,即可免费获取
Linux 网络延迟故障排查



这个人很懒,什么都没留下
文章评论