本文作者:万 浩,中南财经政法大学统计与数学学院
本文编辑:冀思慧
技术总编:王子一
Stata&Python云端课程来啦!
为了感谢大家长久以来的支持和信任,爬虫俱乐部为大家送福利啦!!!Stata&Python特惠课程双双上线腾讯课堂~爬虫俱乐部推出了Python编程培训课程、Stata基础课程、Stata进阶课程。报名课程即可加入答疑群,对报名有任何疑问欢迎在公众号后台和腾讯课堂留言哦。我们在这篇推文的最后提供了每门课程的课程二维码,大家有需要的话可以直接扫描二维码查看课程详情并进行购买哦~
据国家卫健委的数据,2月26日我国新增确诊病例239例,其中本土病例112例。现在处在开学季,师生返校导致人员流动大,针对返程人员中的密切接触者,学校也积极应对。目前全国各省的疫情发展情况如何呢?下面小编就带领大家爬取疫情数据,并进行简单的可视化分析。
一、采集最近一日的疫情数据
首先,我们进入丁香园新冠肺炎疫情首页('https://ncov.dxy.cn/ncovh5/view/pneumonia')获取前一天(2月26日)的疫情数据(疫情首页数据即是最近一日的疫情数据),命令如下:
import requestsfrom bs4 import BeautifulSoupresponse = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia')home_page = response.content.decode()soup = BeautifulSoup(home_page, 'lxml')print(soup)
输出的soup部分结果如下图所示:

由上图可知,最近一日全国各省疫情数据的id="getAreaStat"(红色箭头所指),下面我们正式采集前一日的疫情数据,鉴于内地省份中广东省疫情较为严重,我们将全国各省疫情和广东省疫情数据可视化,命令如下:
import requestsfrom bs4 import BeautifulSoupimport reimport jsonimport pandas as pdimport matplotlib.pyplot as plt# 采集最近一日疫情数据class ChinaCoronaVirusSpider():def __init__(self):self.home_url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia'# 获取数据函数def get_content_from_url(self, url):response = requests.get(url) # 发送请求,获取疫情首页return response.content.decode() # 提取最近一日全国各省疫情数据# 解析数据函数def parse_home_page(self, home_page):soup = BeautifulSoup(home_page, 'lxml') # 从HTML或XML文件中提取数据script = soup.find(id="getAreaStat")text = script.textjson_str = re.findall(r'\[.+\]', text)[0] # 正则表达式提取json字符串python_str = json.loads(json_str) # json字符串转化为python类型数据return python_str# 保存数据函数def save(self, data, path):with open(path, 'w') as fp:json.dump(data, fp, ensure_ascii=False)# 爬虫函数def crawl_china_last_day_corona_virus(self):home_page = self.get_content_from_url(self.home_url) # 调用获取数据函数data = self.parse_home_page(home_page) # 调用解析数据函数self.save(data, 'china_last_day_corona_virus.py') # 调用保存数据函数# 数据可视化china_data_set = []for i in data:china_data_dict = {}china_data_dict['省份'] = i['provinceShortName']china_data_dict['现存确诊数'] = i['currentConfirmedCount']china_data_dict['累计确诊数'] = i['confirmedCount']china_data_dict['死亡数'] = i['deadCount']china_data_dict['治愈数'] = i['curedCount']china_data_set.append(china_data_dict)china_df = pd.DataFrame(china_data_set)china_df1 = china_df[china_df['现存确诊数']>10]plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']china_df1.plot.bar(x='省份', y='现存确诊数')plt.show()shanxi_data_set = []for i in data:if i['provinceShortName'] == '广东':for k, v in i.items():if k == 'cities':for i in v:guangdong_data_dict = {}guangdong_data_dict['城市'] = i['cityName']guangdong_data_dict['现存确诊数'] = i['currentConfirmedCount']guangdong_data_dict['累计确诊数'] = i['confirmedCount']guangdong_data_dict['死亡数'] = i['deadCount']guangdong_data_dict['治愈数'] = i['curedCount']guangdong_data_set.append(shanxi_data_dict)guangdong_df = pd.DataFrame(guangdong_data_set)guangdong_df1 = guangdong_df[guangdong_df['现存确诊数']>0]# 设置matplotlib中文字体(mac系统)# plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']# 设置matplotlib中文字体(windows系统)# from matplotlib.pylab import style# style.use('ggplot')# plt.rcParams['font.sans-serif'] = ['SimHei']# plt.rcParams['axes.unicode_minus'] = False# 如果未设置,matplotlib所绘制的图无法显示中文guangdong_df1.plot.bar(x='城市', y='现存确诊数')plt.show()def run(self):self.crawl_china_last_day_corona_virus() # 调用爬虫函数if __name__ == '__main__':spider = ChinaCoronaVirusSpider()spider.run()
将现存确诊数大于50的省份、广东省现存确诊数大于0的城市的疫情数据绘制成柱状图,如下图所示:
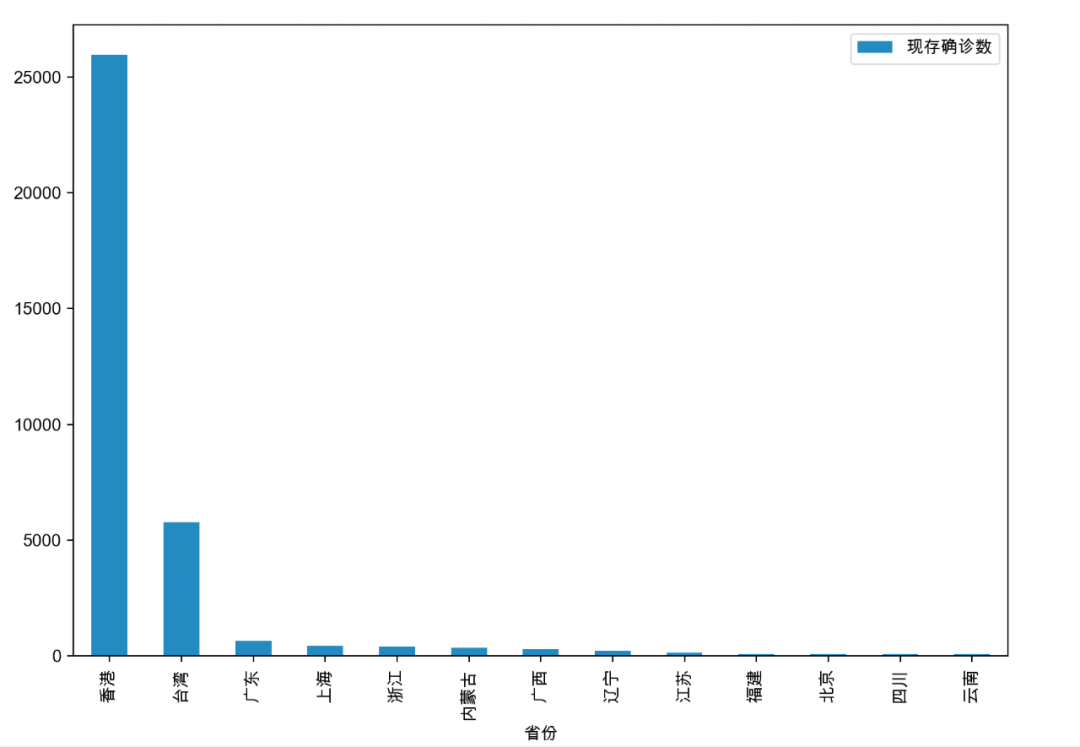
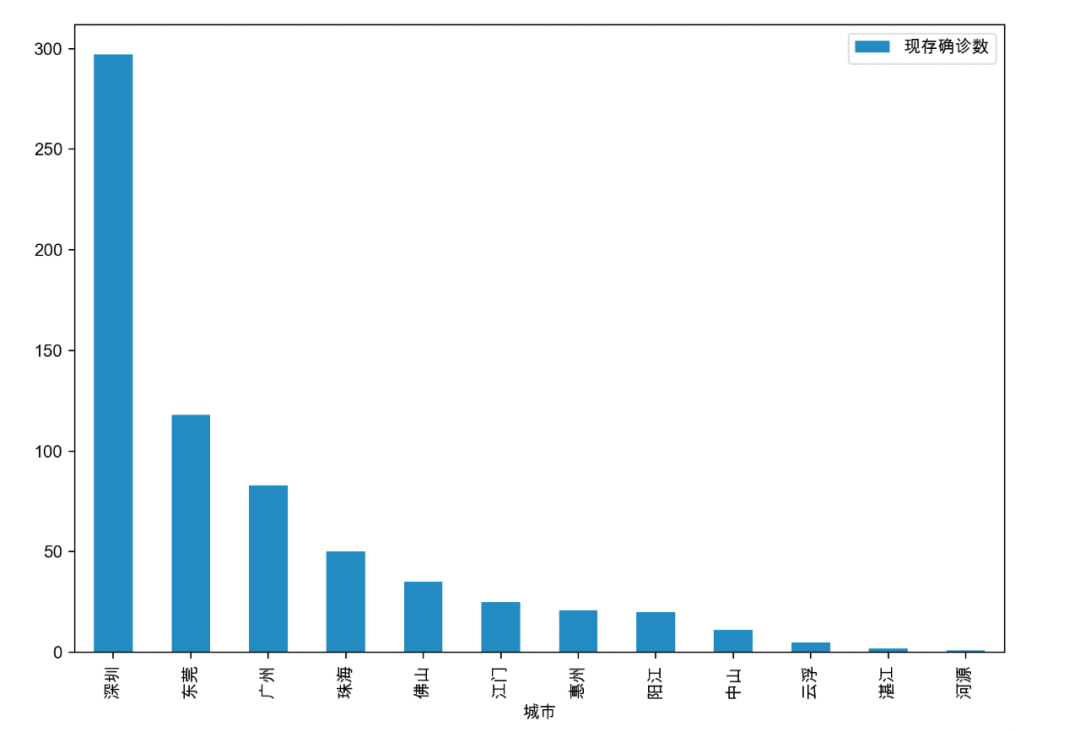
从以上的柱状图可知,香港的现存确诊数超过了25000,一方面,圣诞节和春节使得香港市民有所放松;另一方面,确诊数的猛增与特区政府更新检测方式也有关,特区政府直接承认了快速测试和私营化验所的检测结果。在内地省份中,广东省的疫情最为严重,根据图示,深圳市的确诊数接近300例,东莞市也超过了100例,并且全省多个地级市都存在数十例确诊病例。
二、采集记录以来的疫情数据
以上我们采集了最近一日全国各省的疫情数据,那么如何知晓疫情的动态变化呢?方法是通过最近一日的数据,得到记录以来全国各省疫情数据的url,就可以获取记录以来的各省疫情数据了,命令如下:(丁香园从2020年1月份开始记录疫情数据)
import requestsfrom bs4 import BeautifulSoupimport reimport jsonfrom tqdm import tqdm# 采集记录以来疫情数据class ChinaCoronaVirusSpider():def __init__(self):self.home_url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia'# 获取数据函数def get_content_from_url(self, url):response = requests.get(url) # 发送请求,获取疫情首页return response.content.decode() # 提取最近一日全国各省疫情数据# 解析数据函数def parse_home_page(self, home_page):soup = BeautifulSoup(home_page, 'lxml') # 从HTML或XML文件中提取数据script = soup.find(id="getAreaStat")text = script.textjson_str = re.findall(r'\[.+\]', text)[0] # 正则表达式提取json字符串python_str = json.loads(json_str) # json字符串转化为python类型数据return python_str# 保存数据函数def save(self, data, path):with open(path, 'w') as fp:json.dump(data, fp, ensure_ascii=False)# 爬虫函数def crawl_china_corona_virus(self):# 加载最近一日全国各省数据with open('china_last_day_corona_virus.py') as fp:last_day_china_corona_virus = json.load(fp)china_corona_virus = []for province in last_day_china_corona_virus:statistics_url = province['statisticsData'] # 遍历已经保存的最近一日全国各省数据,获取各省记录以来疫情数据的urlstatistics_json_str = self.get_content_from_url(statistics_url) # 调用获取数据函数statistics_python_str = json.loads(statistics_json_str)['data'] # json字符串转化为python类型数据(只获取其中的'data')for one_day in tqdm(statistics_python_str, '采集丁香园开始记录疫情以来全国各省疫情数据'):one_day['provinceName'] = province['provinceName']china_corona_virus.extend(statistics_python_str)self.save(china_corona_virus, 'china_corona_virus.py') # 调用保存数据函数def run(self):self.crawl_china_corona_virus() # 调用爬虫函数if __name__ == '__main__':spider = ChinaCoronaVirusSpider()spider.run()
由于数据较大,为了避免网络走失了我们却傻傻等候,通过导入了tqdm库,就可以在采集数据的时候看到进度君了!
'china_corona_virus.py'部分展示如下:(其中红色箭头所指"dateId"表示的就是日期)
接下来,我们只需要进行可视化分析就可以知道全国各省疫情数据的动态变化啦!小编在这里就偷懒了,大家可以自行操作奥。


腾讯课堂课程二维码



对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
log——为你的操作保驾护航
一行代码教你玩转emoji
票房遇冷的春节档口碑冠军丨《狙击手》影评分析
学习丰县,营造良好营商环境!
大国丢娃图:从川渝到徐州!
丰县“失火”,殃及徐州:股市超跌近30亿!
Unicode转义字符——编码与解码
徐州!徐州!
B站弹幕爬虫——冬奥顶流冰墩墩&雪容融
不会用Stata做描述性统计表?so easy!
丰沛之地:备足姨妈巾
过年啦,用Python绘制一幅属于你的春联吧!
【基础篇】查找并输出子字符串的定位
Stata中的小清新命令——添加观测值
PCA(主成分分析法)降维——Python实现
超好用的事件研究法
如何绘制任泽平《鼓励生育基金》的几幅图
Python 第六天——字符串
findname——想要什么找什么
Python字符串之“分分合合”
PDF转docx可批量操作?——wordconvert的小技巧
考研之后,文科生需以“do”躬“do”!
手绘五星兴家国——用Stata绘制五星红旗
Python与数据库交互——窗口函数
爬虫俱乐部成员的Stata学习经验分享来啦!
我几乎画出了“隔壁三哥”家的国旗
如何用Stata绘制带指向性箭头标注的图像
Seminar丨荐仆贷款——19世纪中国的信任辅助贷款
Seminar丨公司董事会的人才增长:来自中国的证据
关于我们
微信公众号“Stata and Python数据分析”分享实用的Stata、Python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
武汉字符串数据科技有限公司一直为广大用户提供数据采集和分析的服务工作,如果您有这方面的需求,请发邮件到[email protected],或者直接联系我们的数据中台总工程司海涛先生,电话:18203668525,wechat: super4ht。海涛先生曾长期在香港大学从事研究工作,现为知名985大学的博士生,爬虫俱乐部网络爬虫技术和正则表达式的课程负责人。
此外,欢迎大家踊跃投稿,介绍一些关于Stata和Python的数据处理和分析技巧。
投稿邮箱:[email protected]投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。



文章评论