基于因果推理的推荐系统是因果科学领域的热门应用研究,近期北京大学周晓华团队提出了一套因果分析框架来统一现有的各类因果启发的推荐方法,并详细讨论了因果假设的有效性问题。在集智俱乐部因果科学读书会第三季,北京大学吴鹏老师详细介绍了这项工作,本文是分享的文字整理。
研究领域:基于因果推理的推荐系统,因果学习
李昊轩 | 作者
邓一雪 | 编辑
论文题目:
Causal Analysis Framework for Recommendation
论文链接:
https://arxiv.org/abs/2201.06716
近年来,基于因果推理的推荐系统(RS)在工业界获得了广泛的关注,并在许多预测和去偏任务中表现出了良好的效果。然而,一个统一的因果分析框架还未建立。许多基于因果关系的预测和去偏研究很少讨论各种偏倚的因果解释和相应因果假设的合理性。在本文中,我们首先提供了一个正式的因果分析框架来综述和统一现有的因果启发的推荐方法,它可以适应 RS 中的不同场景。然后,我们提出了一个新的分类法,并从违反因果分析假设的角度给出了 RS 中各种偏倚的正式因果定义。最后,我们对 RS 中的许多去偏和预测任务进行了形式化,并总结了基于统计和机器学习的因果估计方法,期望为因果 RS 社区提供新的研究机会和视角。
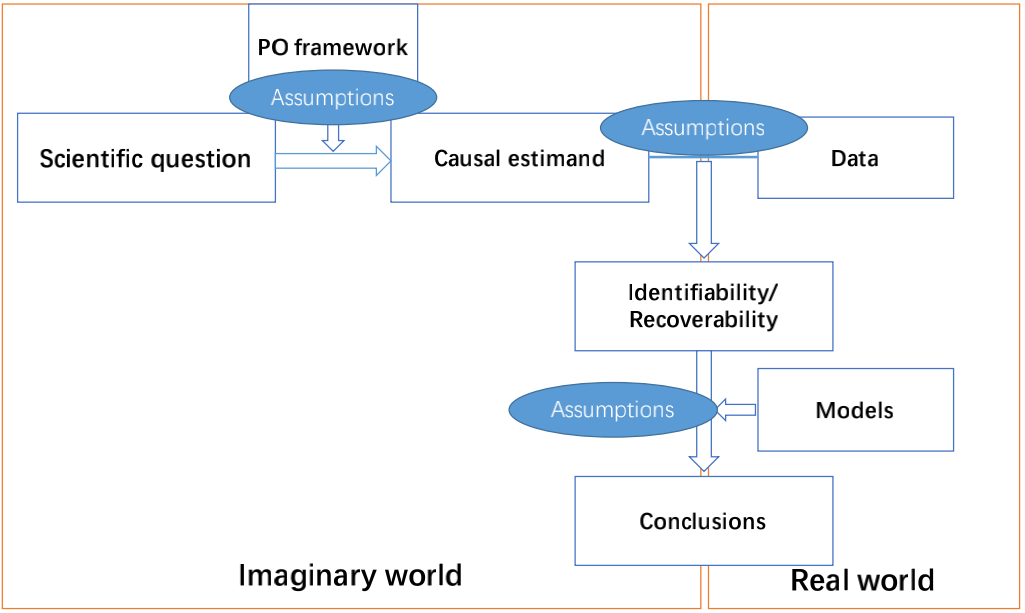
我们提出的因果分析框架(分析流程)由以下三步构成:(1) 定义因果估计量 (因果参数) 以回答科学问题;(2) 给定数据后,讨论因果估计量的可恢复性;(3) 建立模型,得到待估计量的相合估计。图 1 描述了这一因果分析框架。
图1: 因果分析框架
典型的因果推断方法在收集数据之前,先将所研究的科学问题转化为因果估计量。然而,RS 中很少有文献对估计量有明确的说明。通过将科学问题形式化为因果估计,我们可以回答以下问题:究竟是什么被估计以及出于什么目的。接下来,我们讨论在收集到观察数据后,估计量能否在适当的假设下被估计出,即估计量的可恢复性。
可恢复性是因果推断的关键要素,而它在推荐系统中很少被讨论。讨论可恢复性的意义至少是双重的:首先,我们可以确定一个反事实估计量在一些合理的假设下是否能够被估计出。若不可恢复,则需要考虑收集更多的新数据。其次,如果估计是可恢复的,我们可以明确地呈现获得可恢复性所需的假设。我们可以通过评估假设的合理性来评估纠偏方法的好坏;也可以通过弱化假设条件,来提出一些新的纠偏方法。以下 5 个假设是因果推荐中常用的可恢复性假设。
需强调的是,RS 中不同的因果问题对应于不同的因果估计量,给定收集的数据后,会遭受不同类型的偏倚影响,需要采用各种不同的假设和模型来估计因果参数,进而回答科学问题。
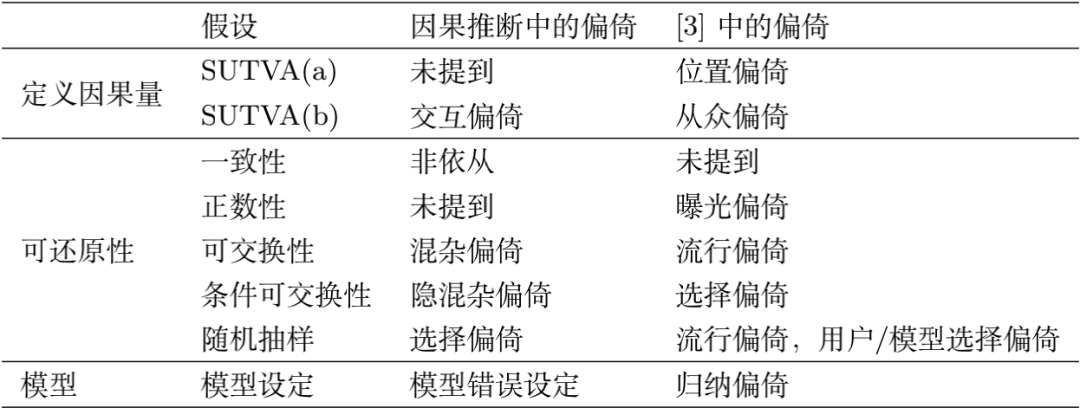
破坏假设 1-5 会导致各种各样的偏倚。尽管这些偏倚在推荐系统社区中有过讨论 [3], 关于偏倚的明确定义仍不清晰,这严重地制约了去偏方法的发展。在本节中,我们从破坏因果推断的假设出发,提出关于推荐系统中偏倚的新见解,见表 1。
3.1 混杂偏倚和选择偏倚
在因果推断领域,实现因果估计的两个最常见的障碍是混杂偏倚和选择偏倚 [4],我们严格定义这两种偏倚。
定义 1 (混杂偏倚)。混杂偏倚指由于存在某些同时影响处理和结局的因素而引起的(T 和 Y 之间的)关联性 [4],即 。通常会导致
。通常会导致
定义 2 (选择偏倚)。选择偏倚指样本分布与目标总体的分布不同 [8],即
混杂偏倚经常被当作是观察性研究的缺点。在观察性研究中,处理和结果可能由许多因素决定,然后这些因素的影响与处理效果纠缠(或混淆)在一起,导致不同处理组间的混杂因素分布存在显著差异。随着样本量的增加,混杂偏倚无法消除 [8]。
选择偏倚在推荐系统中大量存在。例如,某个系统旨在通过过滤掉预测评分较低的物品来推荐用户可能喜欢的物品,这种选择是以前的模型选择偏倚 [15];用户倾向于评价他喜欢的物品,很少评价他不喜欢的项目,这是用户的自我选择偏倚。在这种情况下,数据收集过程将反映样本比例的失真,并且,由于数据不再是目标人群的忠实代表,如混杂偏倚的情况,无论收集的样本数量如何,都将产生偏倚估计。
选择产生的偏倚与混淆产生的偏倚有着根本的不同。选择偏倚来自于样本采集过程中的系统性偏倚 [1]。设计良好的抽样程序可以减少选择偏倚。相反,混淆偏倚来自于另一种类型的系统性偏倚,该系统性偏倚本质上由特征、处理和结果之间的因果机制(关系)决定,与数据收集过程无关。处理分配的随机化可以消除(未测量的)混杂偏倚的影响,但不能消除选择偏倚的影响 [4]。
混杂偏倚和选择偏倚间有一定的联系。首先,它们都是系统性偏倚,会导致“虚假相关性”[1]。第二,如果我们把分析局限于非缺失单元,则缺失数据问题可被视为选择偏倚。混杂偏倚也可以被视为缺失数据问题。例如,考虑二值处理的情况,然后对于每个单元,只能观察到其中一个潜在的结果(Y (1) 或 Y (0)),另一个潜在结果可以被认为是缺失的。
3.2 推荐系统中偏倚的新分类
因果分析框架中的每个步骤都依赖于一些假设,违反这些假设将导致不同类型的偏倚。这种观点提供了一种统一的方式来讨论推荐系统中的各种偏倚,并使我们能够正式定义它们。
从推荐过程的角度来看,有关推荐系统的文献提出了各种偏倚,如选择偏倚、从众偏倚、曝光偏倚、位置偏倚、归纳偏倚、流行偏倚 [3]。值得注意的是 [3] 中选择偏倚的定义与本文中的定义不同。我们使用“用户选择偏倚”和“选择偏倚”来区分它们。
混杂偏倚和选择偏倚分别违反可交换性和随机抽样假设。有趣的是,根据偏倚的描述性定义, 流行偏倚、用户选择偏倚和曝光偏倚将导致 ,因此属于选择偏倚。类似的观点也见于 [2],它也将位置偏倚作为一种选择偏倚。
从众偏倚意味着用户倾向于给出与组中的其他人相似的评分。它违反了 SUTVA(b) 假设,即无交互作用。这是因为从众现象可能导致 Ym(t) 的值依赖于单元 j≠m 的处理值 tj。另外,位置偏倚可被视为违反 SUTVA(a)。例如,在点击率预测任务中,假设一个单元是一对用户和物品。如果物品 i 向用户 u 曝光,则将 Yu, i(1) 定义为单击行为。这时,Yu, i(1) 将取决于暴露的位置,并且会出现多种处理方案。对于位置偏倚,我们可以考虑作为处理的位置,然后它可以被视为多值处理的问题。曝光偏倚差源于用户只接触特定物品中的一部分。也就是说,一些用户以零概率接触某些物品。因此,曝光偏倚可视为违反正性假设。
最近,越来越多的 RS 研究者试图应用因果推理方法来处理 RS 任务,如 CTR/CVR 预测、延迟反馈等,尽管如此,仍然存在许多挑战和机会。通过将现有的研究与上面讨论的因果分析框架相匹配,我们发现了以下的公开研究方向,这些方向在 RS 进行研究的潜在结果框架中很少被正式形式化。
4.1 数据融合 (Data Fusion)
一个典型的情况是将大量有偏的(观察性或非均匀性)数据集和少量无偏的(实验性或均匀性)数据集结合起来。有偏的数据和无偏的数据具有互补的特点。有偏的数据不可避免地受到隐藏/未测量的混杂因素的影响,即使样本量为无穷大,也会扭曲因果关系的结论。
相比之下,通过精心设计的实验收集的无偏数据没有(隐藏的)混杂偏倚,它为评估去偏方法提供了黄金标准。总之,数据融合是提高 RS 质量的一个有希望的策略。
4.2 序列推荐 (Sequential Recommendation)
通过对用户行为序列的建模,如购买商品的序列,RS 可以学习用户兴趣的变化并预测用户的下一步行为。从因果关系的角度看,可以认为 RS 的分配机制和潜在结果是随着时间序列的变化而变化的,其目的是动态地捕捉用户兴趣的变化,从而实现更准确的推荐。
4.3 推荐系统公平性 (Fairness in RS)
许多文献通过反事实的因果关系来定义群体公平和个人公平。然而,如何在RS中用因果框架来正式定义公平性仍然是模糊的,特别是当用户有社交网络时,会违反SUTVA(b),给因果公平性的良定性带来更大挑战。此外,如何修改传统的因果推荐模型以实现准确性和公平性的平衡,仍有很大的研究空间。
4.4 交互行为 (Interference)
尽管几乎所有关于因果关系启发建议的文章都默认了 SUTVA 假设,但正如前文所讨论的, SUTVA 假设在很多情况下会被违反,从而导致有偏的估计。另一种形式的干扰是在不同单位的潜在结果之间。例如,一个用户的购买行为会影响他社交网络中其他用户的购买行为,这在社交推荐中经常遇到。
因果关系为 RS 中去偏和预测任务的算法提供了新的机会,使相关算法具有更出色的性能。本文通过为 RS 提供一个统一的因果分析框架来回顾相关研究,揭示并详细讨论了一直被忽视但同样重要的因果假设的有效性。从违反因果假设的角度对 RS 中的各种偏倚进行了新的解释。所提出的 RS 因果分析框架被应用于严谨地形式化大量的 RS 任务,如非依从问题、交互偏倚和策略学习。
本文最后概述了因果估计方法,希望能在因果推荐领域提供新的研究机会,包括但不限于去偏和预测任务。此外,有望开发出具有弱化或替代 RS 研究中常见假设的新方法。
-
Elias Bareinboim, Jin Tian, and Judea Pearl. Recovering from selection bias in causal and statistical inference. In AAAI, 2014.
-
Jiawei Chen, Hande Dong, Yang Qiu, Xiangnan He, Xin Xin, Liang Chen, Guli Lin, and Keping Yang. Autodebias: Learning to debias for recommendation. In SIGIR, 2021.
-
Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. Bias and debias in recommender system: A survey and future directions. https://arxiv.org/abs/2010.03240v1, 2020.
-
Juan D. Correa, Jin Tian, and Elias Bareinboim. Identification of causal effect in the presence of selection bias. In AAAI, 2019.
-
Prem Gopalan, Jake M. Hofman, and David M. Blei. Scalable recommendation with hierar- chical poisson factorization. In UAI, 2015.
-
Tiankai Gu, Kun Kuang, Hong Zhu, Jingjie Li, Zhenhua Dong, Wenjie Hu, Zhenguo Li, Xiuqiang He, and Yue Liu. Estimating true post-click conversion via group-stratified coun- terfactual inference. In ADKDD, 2021.
-
Siyuan Guo, Lixin Zou, Yiding Liu, Wenwen Ye, Suqi Cheng, Shuaiqiang Wang, Hechang Chen, Dawei Yin, and Yi Chang. Enhanced doubly robust learning for debiasing post-click conversion rate estimation. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, pages 275–284. ACM, 2021.
-
Miguel A. Hernán and James M. Robins. Causal Inference: What If. Boca Raton: Chapman and Hall/CRC, 2020.
-
Nathan Kallus. More efficient policy learning via optimal retargeting. Journal of the American Statistical Association, 116:646–658, 2021.
-
Dawen Liang, Laurent Charlin, and David M. Blei. Causal inference for recommender systems. In RecSys, 2020.
-
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H Chi. Modeling task relationships in multi-task learning with multi-gate mixture-of experts. In KDD.
-
Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. Entire space multi-task model: An effective approach for estimating post-click conversion rate. In SIGIR, page 1137–1140, 2018.
-
Yuta Saito, Suguru Yaginuma, Yuta Nishino, Hayato Sakata, and Kazuhide Nakata. Unbiased recommender learning from missing-not-at-random implicit feedback. In James Caverlee, Xia (Ben) Hu, Mounia Lalmas, and Wei Wang, editors, WSDM ’20: The Thirteenth ACM International Conference on Web Search and Data Mining, Houston, TX, USA, February 3-7, 2020, pages 501–509. ACM, 2020.
-
Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, and Thorsten Joachims. Recommendations as treatments: Debiasing learning and evaluation. In ICML, 2016.
-
Bo-Wen Yuan, Jui-Yang Hsia, Meng-Yuan Yang, Hong Zhu, Chih-Yao Chang, Zhenhua Dong, and Chih-Jen Lin. Improving ad click prediction by considering non-displayed events. In Proceedings of the 28th ACM International Conference on Information and Knowledge Man- agement, CIKM 2019, Beijing, China, November 3-7, 2019, pages 329–338. ACM, 2019.
-
Bowen Yuan, Yaxu Liu, Jui-Yang Hsia, Zhenhua Dong, and Chih-Jen Lin. Unbiased ad click prediction for position-aware advertising systems. In Fourteenth ACM Conference on Recommender Systems, pages 368–377, 2020.
-
Wenhao Zhang, Wentian Bao, Xiao-Yang Liu, Keping Yang, Quan Lin, Hong Wen, and Ramin Ramezani. Large-scale causal approaches to debiasing post-click conversion rate estimation with multi-task learning. In WWW, 2020.
由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季,将主要面向两类人群:如果你从事计算机相关方向研究,希望为不同领域引入新的计算方法,通过大数据、新算法得到新成果,可以通过读书会各个领域的核心因果问题介绍和论文推荐快速入手;如果你从事其他理工科或人文社科领域研究,也可以通过所属领域的因果研究综述介绍和研讨已有工作的示例代码,在自己的研究中快速开始尝试部署结合因果的算法。读书自2021年10月24日开始,每周日上午 10:00-12:00举办,持续时间预计 2-3 个月。
详情请见:
因果+X:解决多学科领域的因果问题 | 因果科学读书会第三季启动
点击“阅读原文”,即可报名读书会



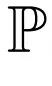 表示目标总体分布,
表示目标总体分布, 
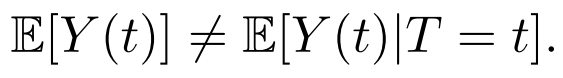
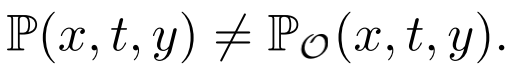


文章评论