在大型微服务架构中,服务监控和实时分析需要大量的时序数据。存储这些时序数据最高效的方案就是使用时序数据库 (TSDB)。设计时序数据库的重要挑战之一便是在效率、扩展性和可靠性中找到平衡。这篇论文介绍的是 Facebook 内部孵化的内存时序数据库,Gorilla。Facebook 团队发现:
-
监控系统的用户主要关注的是数据的聚合分析,而不是单个数据点 -
对于线上问题的根源分析来说,最近的数据比过去的数据更有价值
Gorilla 以可能抛弃少量数据为代价,在读写高可用方面做了优化。为了改进查询效率,开发团队使用了激进的压缩技术:
-
delta-of-delta timestamps -
XOR'd floating point values
相比基于 HBase 的方案,Gorilla 将内存消耗缩小 10 倍,并使得数据得以存放在内存中,进而将查询时延减少 73 倍,查询吞吐量提高了 14 倍。这样的性能改进也解锁了更多的监控、调试工具,如相关性分析、密集可视化。Gorilla 甚至能够优雅的解决单点到整个可用区域故障的问题。
介绍
以下是 FB 内部对时序数据库的要求:
Write Dominate
对时序数据库的首要限制就是必须一直能够写入数据,即写数据的高可用。因为 FB 内部的服务集群每秒将产生 1 千万个采样数据点。相较之下,读数据比写数据要求通常要低好几个数量级,因为数据的消费者是一些运维、开发使用的控制面板以及自动化报警系统,它们的请求频率低且通常只关注部分时序数据。由于用户关注的往往是整组时序数据的聚合结果,而不是单个数据点,因此传统数据库中的 ACID 保证也并不是时序数据库的核心要求,即便在极端情况下,丢弃少量数据也不会影响核心用途。
State Transition
FB 内部希望能够及时发现一些系统的状态转移事件,如:
-
服务新版本发布 -
服务配置修改 -
网络切换 -
...
因此要求时序数据库能支持对较短的时间窗口内的采样数据进行细粒度的聚合。具备在十秒级内展示捕获到的状态转移事件能够帮助自动化工具快速发现问题,阻止其发生扩散。
High Availability
即便当不同 DC 之间发生网络分区,DC 内部的服务也应当能够将实时监控的数据写入到 DC 内部的时序数据库,也能够从中读取数据。
Fault Tolerance
如果能够将数据复制到多个区域 (regions),就可以在单个 DC 或整个地理区域发生问题时也能正常运作。
Gorilla 正是为满足以上所有要求而开发的时序数据库,它可以被理解成是时序数据的 write-through cache,由于数据都在内存中,Gorilla 几乎可以在 10 毫秒级别内处理大部分请求。通过对 FB 内部已经投入使用很长时间的 Operational Data Store (ODS,基于 HBase 的时序数据库解决方案)的研究,发现超过 85% 的数据查询只涉及到过去 26 小时内产生的数据,通过进一步的调研发现,如果使用内存数据库来代替磁盘(disk-based)数据库,就能够达到用户对响应时间的要求。
在 2015 年春,FB 内部的监控系统共产生超过 20 亿组时间序列,每秒产生 1200 万个,每天 1 万亿个数据点。假设每个采样点需要 16 字节来存储,就意味着一天需要 16 TB 内存。Gorilla 团队通过基于 XOR 的浮点数压缩算法将每个采样点所需字节数降到 1.37,将内存总需求量缩小将近 12 倍。
针对可用性要求,Gorilla 团队在不同区域、DC 中部署多个 Gorilla 实例,实例时间相互同步数据,但不保证一致性。数据的读取请求将被转发到最近的 Gorilla 实例。
背景和需求
ODS
ODS 是 FB 线上服务监控系统的重要组成部分,它由一个基于 HBash 的时序数据库,数据查询服务以及报警系统共同构成。它的整体架构如下图所示:
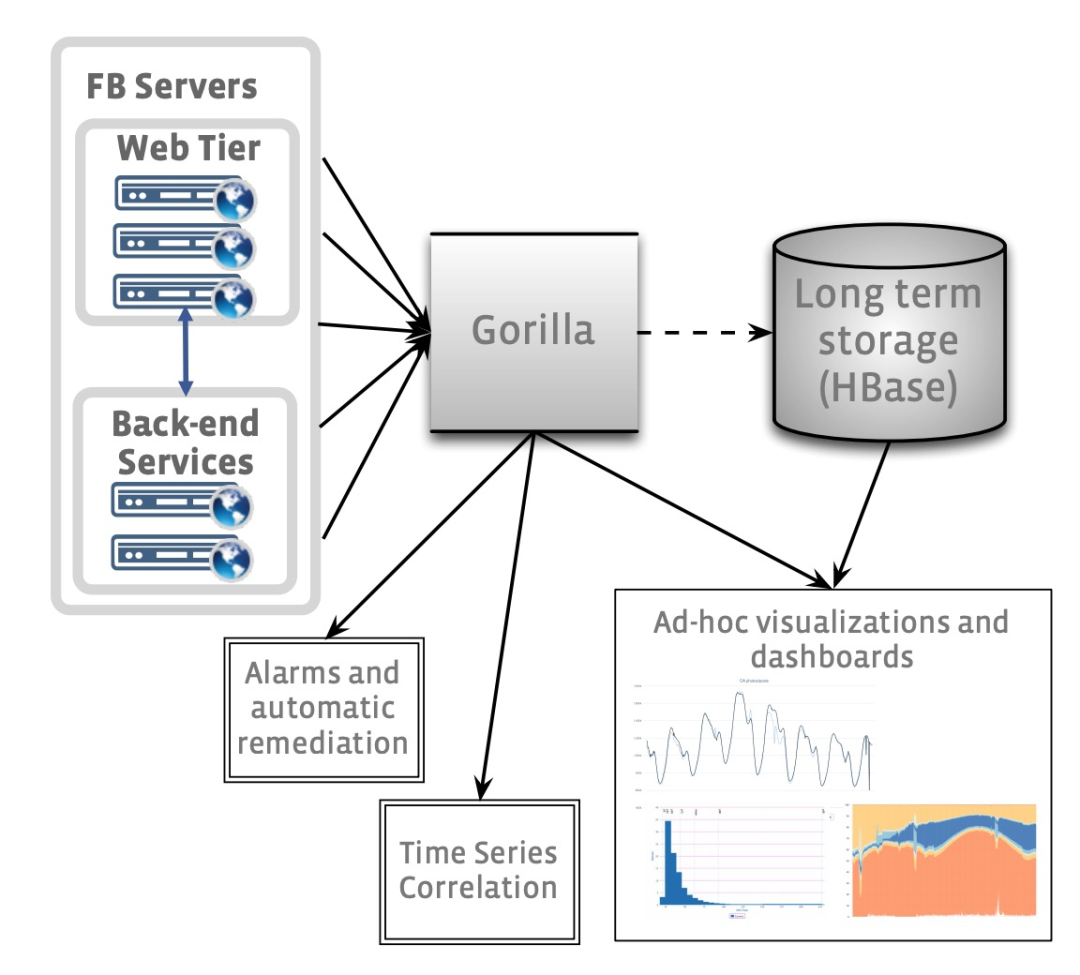
ODS 的消费者主要由两部分构成:
-
便于开发人员分析问题的可交互图表系统 -
自动化报警系统
在 2013 年初,FB 的监控团队意识到基于 HBase 的时序数据库无法处理未来的读负载,尽管图标分析时数据查询的延迟还可以容忍,但达到几秒钟的查询 90th 分位点已经阻塞了自动化报警的正常运作。在眼下其它现成方案都无法满足要求的情况下,监控团队开始将关注点转向缓存解决方案。尽管 ODS 就使用了简单的 read-through cache,但这种方案只是缓存多张图表中共同的时序数据,但每当图表查询最新的数据时,依然还会出现 cache miss,这时候数据读取就击穿到了 HBase。监控团队也考虑过使用 Memcache 作为 write-through cache,但每次写入大量最新数据会对 memcache 引入很大的流量,最终这个方案也被否决了。监控团队需要更加高效的解决方案。
Gorilla 需求
以下是对新的解决方案的要求陈述:
-
20 亿组不同的时序数据,每组时序数据用一个唯一的字符串标识 -
每分钟 7 亿个数据采样点 -
保存 26 小时的全量数据 -
数据读取在 1ms 内完成 -
支持最小采样间隔为 15s -
两个复制节点来支持容错,即使有一个节点挂掉也能够继续处理读请求 -
能够快速扫描所有内存数据 -
支持每年 2 倍的增长
与其他 TSDB 系统比较
由于 Gorilla 的设计是将所有数据放在内存中,因此它的内存数据结构与其它的时序数据库有所不同。也得益于这样的设计,开发者也可以将 Gorilla 看作是基于磁盘的时序数据库的 write-through cache。
OpenTSDB
OpenTSDB 是继续 HBase 的时序数据库解决方案,它与 ODS 的 HBase 存储层很相似。两个系统的表结构设计非常相似,也采用了类似的优化、横向扩容的解决方案。但前面也提到,基于磁盘的解决方案很难支持快速查询的需求。ODS 的 HBase 存储层会刻意降低旧数据的采样精度,从而节省总体空间占用;OpenTSDB 则会保存数据的完全精度。牺牲旧数据的精度,能够带来更快的旧数据查询速度以及空间的节省,FB 团队认为这是值得的。OpenTSDB 标识时序数据的数据模型相比 Gorilla 更加丰富,每组时序数据可以标记任意组键值数据,即所谓的标签 (tags)。Gorilla 只通过一个字符串来标记时序数据,它依赖于上层工中从去抽取标识时序数据的信息。
Whisper (Graphite)
Graphite 以 Whisper format 将时序数据存储在本地磁盘上。Whisper format 期望时序数据的采样区间是稳定的,如果采样区间发生抖动,Graphite 就无能为力了。相较之下,如果时序数据的采样区间是稳定的,Gorilla 能够更高效地存储数据,Gorilla 也能处理区间不稳定的情况。在 Graphite 中,每组时序数据都存在一个独立的文件中,新的样本点会覆盖超过一定时间的旧数据;Gorilla 也很类似,但区别在于它将数据存储在内存中。由于 Graphite 是基于磁盘的时序数据库,同样不满足 FB 内部的需求。
InfluxDB
InfluxDB 的数据模型表达力比 OpenTSDB 更加丰富,时序中的每一个样本都可以拥有完整元数据,但这种做法也导致它的数据存储需要占用更多的磁盘空间。InfluxDB 也支持集群部署,横向扩容,运维团队无需管理 HBase/Hadoop 集群。在 FB 中已经有专门的团队负责运维 HBase 集群,因此对于 ODS 团队来说这并不是一个痛点。与其它系统类似,InfluxDB 也将数据存储在磁盘中,其查询效率要远低于内存数据库。
Gorilla 架构
在 Gorilla 中,每条时序样本数据都由一个三元组构成:
-
string key:用于标识所属的时序 -
timestamp (int64):时间戳 -
value (float64):样本值
Gorilla 采用一种新的时序压缩算法,将存储每条时序样本数据所需的空间由之前的 16 字节降到了平均 1.37 个字节。
通过将每组时序数据通过 string key 分片到某个的 Gorilla 服务,就能比较容易地实现横向扩容。在 Gorilla 正式上线 18 个月后,存储 26 小时的数据约需要 1.3TB 内存,每个集群需要 20 台机器。在论文写作时,每个集群已经需要 80 台机器。
Gorilla 通过同时将时序数据写入两台位于不同 regions 的机器中,来抵御单点故障、网络分区、甚至整个 DC 故障。一旦发现故障,所有的读请求将被转发到备选 region 中的服务上,保证用户对故障无明显感知。
时间序列压缩
Gorilla 对压缩算法主要有两个要求:
-
流式压缩:无需读取完整数据 -
无损压缩:不能损失数据精度
对比连续的样本数据分析,能够观察到:
-
连续的时间戳之间间隔通常为常数,如 15 秒 -
连续的数据值之间的二进制编码差别较小
因此 Gorilla 对时间戳和数据值分别使用不同的压缩算法。在分析具体算法之前,可以看一下算法的整体流程:
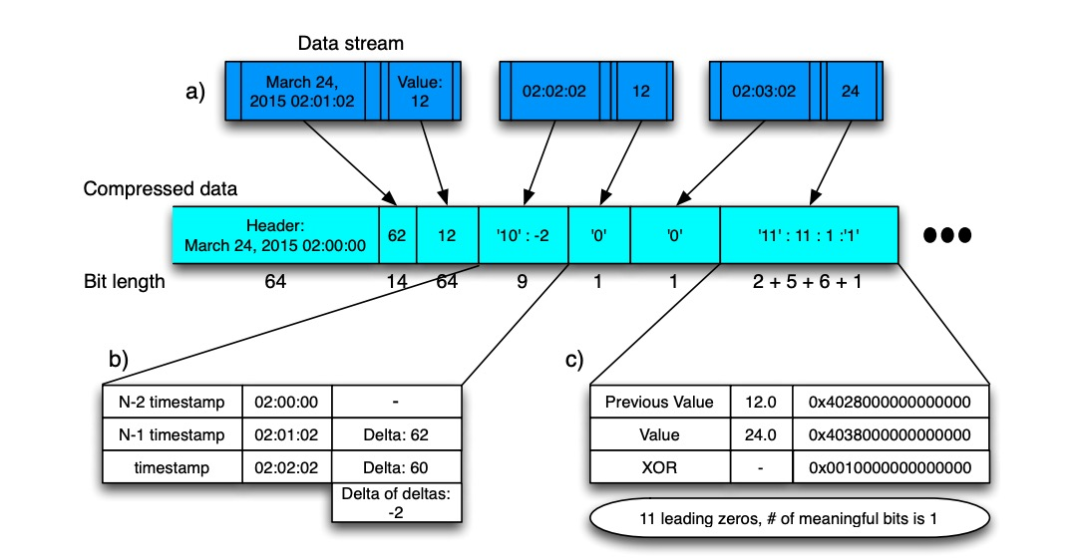
-
每块数据的开头记录起始时间戳 -
第一条样本数据 -
时间戳存储与起始时间戳的差值 -
数据值按原值存储 -
从第二条样本数据开始 -
时间戳存储 delta of delta -
数据值按差值存储
Time Stamps压缩
通过分析 ODS 中的时序数据,Gorilla 团队观察到大多数时序样本都是按固定区间到达服务,如 60 秒。尽管偶尔会出现 1 秒钟的延迟或提早,总体上时间窗口是稳定的。
假设连续时间戳的 delta 为:60, 60, 59, 61,那么 delta of delta 就是:0, -1, 2,于是通过起始时间、第一条数据与起始时间的 delta,以及剩下所有样本点的 delta of delta,就能够存储完整的数据。
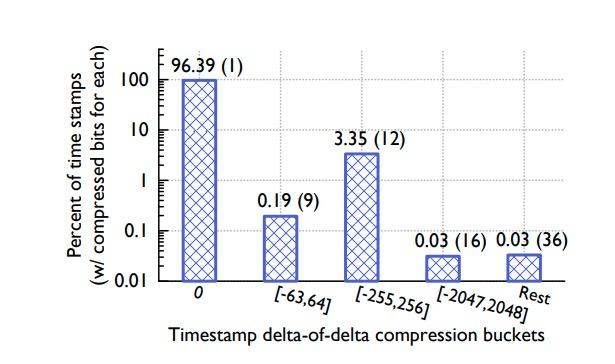
算法中为 D 选择的区间在真实数据能够获得最大的压缩率。一个时序数据可能随时出现数据点丢失,于是可能出现这样的 delta 序列:60, 60, 121, 59,这时候 delta of delta 就是:0, 61, -62,这时候就需要存储 10 bits 数据。下图是时序压缩的统计表现:
Values 压缩
通过分析 ODS 的数据,Gorilla 团队观察到大部分相邻的时序数据值之间不会有很大的变化。根据 IEEE 754 中定义的浮点数编码格式:
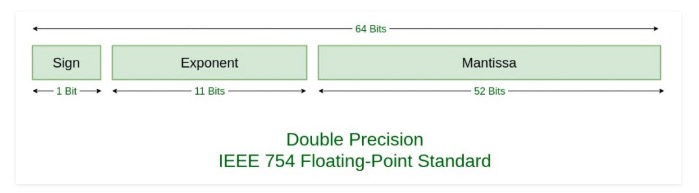
通常相邻的数值之间,sign、exponent 以及 mantissa 前面的一些 bits 不会改变,如下图所示:
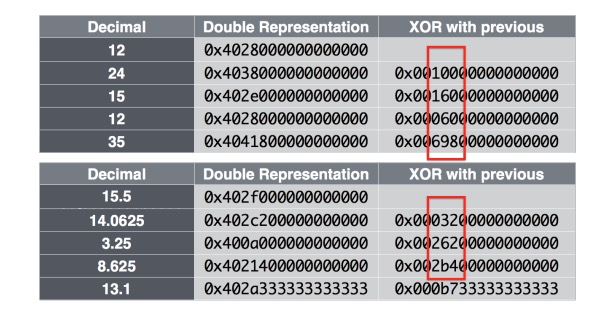
因此利用这个,我们可以通过记录相邻数值的 XOR 中不同的信息来压缩数据。完整的算法流程如下:
-
第一个数值无压缩存储 -
如果与上一个数值 XOR 的结果为 0,即数值未发生改变,则存储 1 bit,'0' -
如果与上一个数值 XOR 的结果不为 0,则先存储 1 bit,'1' -
(Control bit '0'):如果当前 XOR 的区间在前一个 XOR 区间里面,那么可以复用前一个 XOR 区间的位置信息,只存储区间内部的 XOR 的值 -
(Control bit '1'):如果当前 XOR 的区间不在前一个 XOR 区间里面,则先利用 5 bits 存储前缀 0 的数量,再利用 6 bits 存储区间的长度,最后存储区间内部 XOR 的值
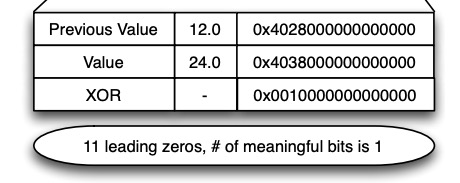
具体可参考流程图中的例子,即:
下图展示时序数据值压缩算法的统计表现:
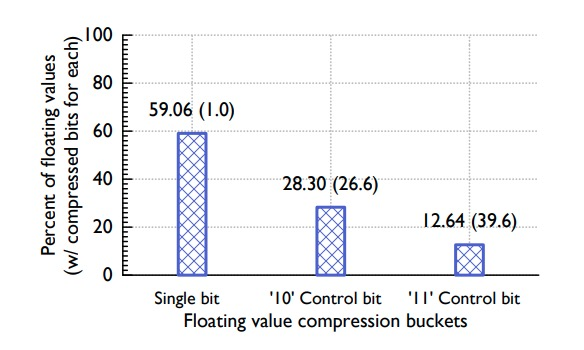
-
59% 的数值只需要 1 bit 即可以存储 -
28% 的数值只需要 26.6 bits 即可存储 -
13% 的数值需要 39.6 bits 可以存储
这里有一个 trade-off 需要考虑:每个数据块所覆盖的时间跨度。更大的时间跨度可以获得更高的压缩率,然而解压缩所需的资源也越多,具体的统计结果展示如下:
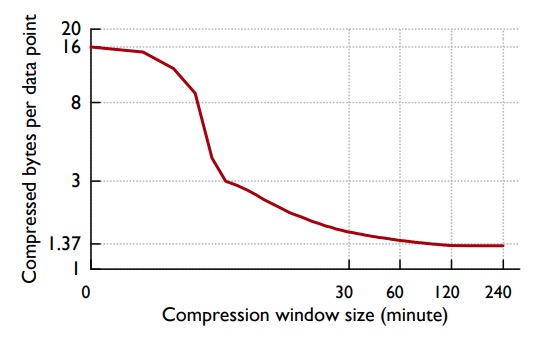
从图中可以看出在 2 小时之后,继续增大跨度带来压缩率提升的边际收益已经非常小,因此 Gorilla 最终选择 2 小时的时间跨度。
内存中的数据结构
Gorilla 在内存中的数据结构如下图所示
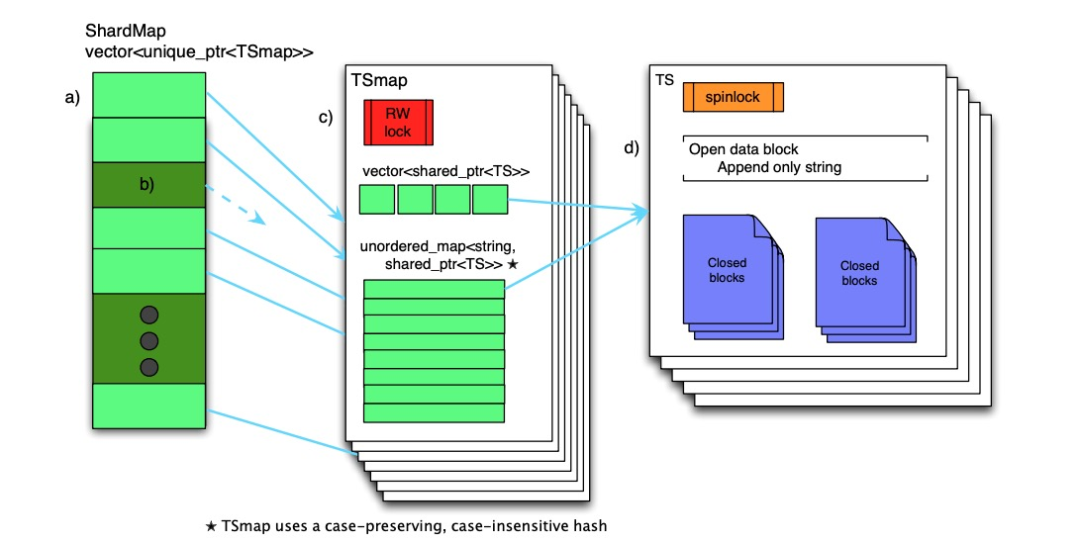
整个数据结构可以分三层:
-
ShardMap -
TSmap -
TS
ShardMap
每个 Gorilla 节点上都维护着一个 ShardMap,后者负责将时序名称的哈希值映射到相应的 TSmap 上。如果 ShardMap 上对应的指针为空,则目标时序数据不在当前的节点 (分片) 上。由于系统中分片的数量是常数,且预期数量级在 3 位数内,因此存储 ShardMap 的成本很低。ShardMap 的并发访问通过一个 read-write spin lock 来控制。
TSmap
TSmap 是时序数据的索引。它由以下两部分构成:
-
所有 TS 的指针构成的向量,标记为 vector -
将时序名称的哈希值映射到 TS 指针的字典,标记为 map
vector 用于快速扫描所有数据;map 用于满足稳定、快速的查询请求。TSmap 的并发控制通过一个 read-write spin lock 实现。扫描完整数据时,只需要复制 vector,后者是由一批指针构成,速度很快,critical section 很小;删除数据时,通过 tombstoned 标记删除,被动回收。
TS
每组时序数据都由一系列数据块构成,每个数据块保存 2 小时的数据,最新的数据块还处于打开状态,上面维持着最近的数据。最新的数据块中只能往后追加数据,一旦时间满 2 小时,数据块就会被关闭,已经关闭的数据块在被清出内存之前不允许再被修改。
读取数据时,查询所涉及的所有数据块将被复制一份,直接返回给 RPC 客户端,数据的解压缩过程由客户端完成。
磁盘结构
Gorilla 的设计目标之一就是能抵御单点故障,因此 Gorilla 同样需要通过持久化存储做故障恢复。Gorilla 选择的持久化存储是 GlusterFS,后者是兼容 POSIX 标准的分布式文件系统,默认 3 备份。其它分布式文件系统,如 HDFS 也可以使用。Gorilla 团队也考虑使用单机 MySQL 或者 RocksDB,但最终没有选择,原因是 Gorilla 并不需要使用查询语言支持。
一个 Gorilla 节点会维持多个分片的数据,于是它会为每个分片建立一个文件夹。每个文件夹中包含四类文件:
-
Key Lists -
Append-only Logs -
Complete Block Files -
Checkpoint Files
Key Lists
Key Lists 实际上就是时序名称到 integer identifier 的映射,后者是时序在 TSmap vector 中的偏移值。Gorilla 会周期性地更新 Key Lists 数据。
Append-only Logs
当所有时序数据的样本点流向 Gorilla 节点时,Gorilla 会将他们压缩后的数据交织地写入日志文件中。但这里的日志文件并不是 WAL,Gorilla 也并没有打算提供 ACID 支持,当日志数据在内存中满 64 KB 后会被追加到 GlusterFS 中相应的日志文件中。故障发生时,将有可能出现少量数据丢失,但为了提高写吞吐,这个牺牲还算值得。
Complete Block Files
每隔 2 小时,Gorilla 会将数据块压缩后复制到 GlusterFS 中。每当一块数据持久化完成后,Gorilla 就会创建一个 checkpoint 文件,同时删除相应的日志文件。checkpoint 文件被用来标识数据块持久化成功与否。故障恢复时,Gorilla 会通过 checkpoint 和日志文件载入之前的数据。
容错
在容错方面,Gorilla 优先支持以下场景:
-
单点故障,如果是临时故障则客户端完全无感知,常用于新版发布 -
大范围、区域性故障:如 region 范围的网络分区
高可用
Gorilla 通过在两个不同区域的 DC 维护两台独立的实例保障服务的可用性。同一组时序数据写入时,会被发送给这两台独立的实例上,但不保证两次写操作的原子性。当一个区域故障时,读请求将被尝试发送到另一个区域。如果该区域的故障持续超过 1 分钟,读请求将不再发送给它,直到该区域中的实例数据已经正常写入 26 小时为止。
在每个区域内部,一种基于 Paxos 的 ShardManager 用于维护分片与节点之间的关系。当一个节点发生故障时,ShardManager 会将它维护的分片重新分配给集群内部的其它节点。分片转移通常能够在 30 秒内完成,在分片转移的过程中,写入数据的客户端将缓存待写入的数据,并且最多缓存最近 1 分钟的数据。当客户端发现分片转移操作执行完时,客户端会立即掏空缓存,将数据写入到节点中。如果分片转移速度太慢,读请求可以被手动或自动地转发到另一个区域。
当新的分片被分配给一个节点时,该节点需要从 GlusterFS 中读入所有数据。通常加载和预处理这些数据需要 5 分钟。当该节点正在恢复数据时,新写入的时序样本数据会被放入一个待处理队列。在老节点发生故障后,新节点加载分片数据完毕之前,读请求可能会读到部分数据,并打上标记。如果客户端发现数据被标记为部分数据,会再次请求另一个区域中的数据,如果数据完整则返回后者,失败则返回两组部分数据。
最后,FB 仍然使用 HBase TSDB 来存储长期数据,工程师仍然可以通过它来分析过去的时序数据。
NewTools on Gorilla
由于 Gorilla 的数据存放在内存中,这样让更多的实时分析成为可能。
-
相关性分析引擎,主要用于快速发现相关性很高的时序数据,从而辅助根源分析 -
监控绘图 -
聚合分析
论文地址:http://www.vldb.org/pvldb/vol8/p1816-teller.pdf
翻译原文:https://zhenghe.gitbook.io/open-courses/papers-we-love/gorilla-a-fast-scalable-in-memory-time-series-database

文章评论