-
数据提供了信息。数据储存了信息,包括用户与内容的属性,用户的行为偏好例如对新闻的点击、玩过的英雄、购买的物品等等。这些数据特征非常关键,甚至可以说它们决定了一个算法的上限。
-
算法提供了逻辑。数据通过不断的积累,存储了巨量的信息。在巨大的数据量与数据维度下,人已经无法通过人工策略进行分析干预,因此需要基于一套复杂的信息处理逻辑,基于大量的数据学习返回推荐的内容或服务。
-
架构解放了双手。架构保证整个推荐自动化、实时性的运行。架构包含了接收用户请求,收集、处理,存储用户数据,推荐算法计算,返回推荐结果等。一个推荐系统的实时性要求越高、访问量越大,那么这个推荐系统的架构会越复杂。
二、推荐系统的整体框架
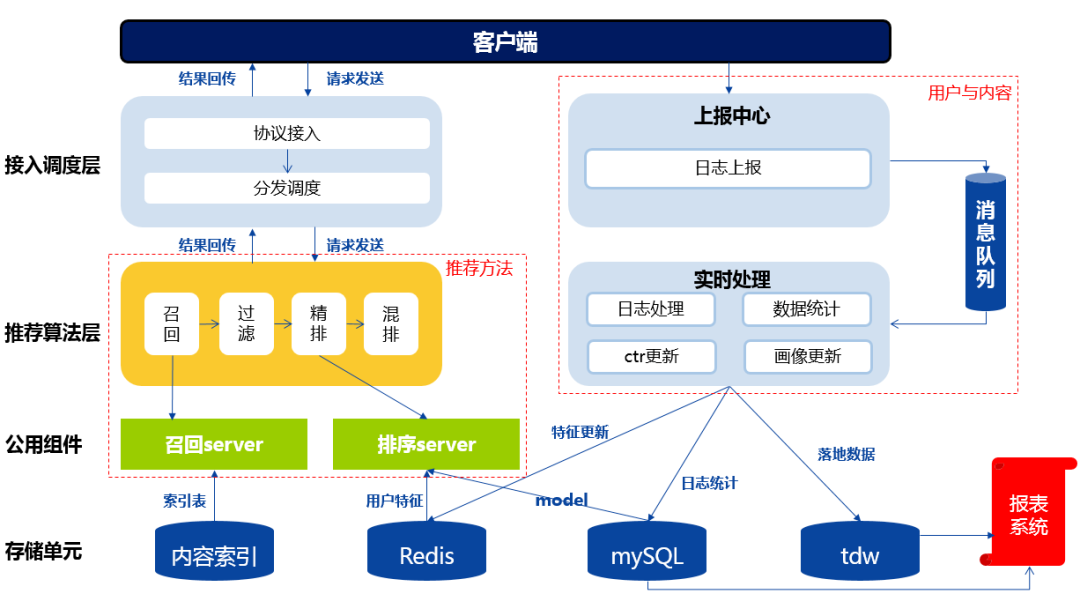
-
协议调度:请求的发送和结果的回传。在请求中,用户会发送自己的ID,地理位置等信息。结果回传中会返回推荐系统给用户推荐的结果。
-
推荐算法:算法按照一定的逻辑为用户产生最终的推荐结果,不同的推荐算法基于不同的逻辑与数据运算过程。
-
消息队列:数据的上报与处理。根据用户的ID,拉取例如用户的性别、之前的点击、收藏等用户信息。而用户在APP中产生的新行为,例如新的点击会储存在存储单元里面。
-
存储单元:不同的数据类型和用途会储存在不同的存储单元中,例如内容标签与内容的索引存储在mysql里,实时性数据存储在redis里,需要进行数据统计的大量离线数据存储在hivesql里。
三、用户画像
3.1 用户标签
3.2 用户画像的分类
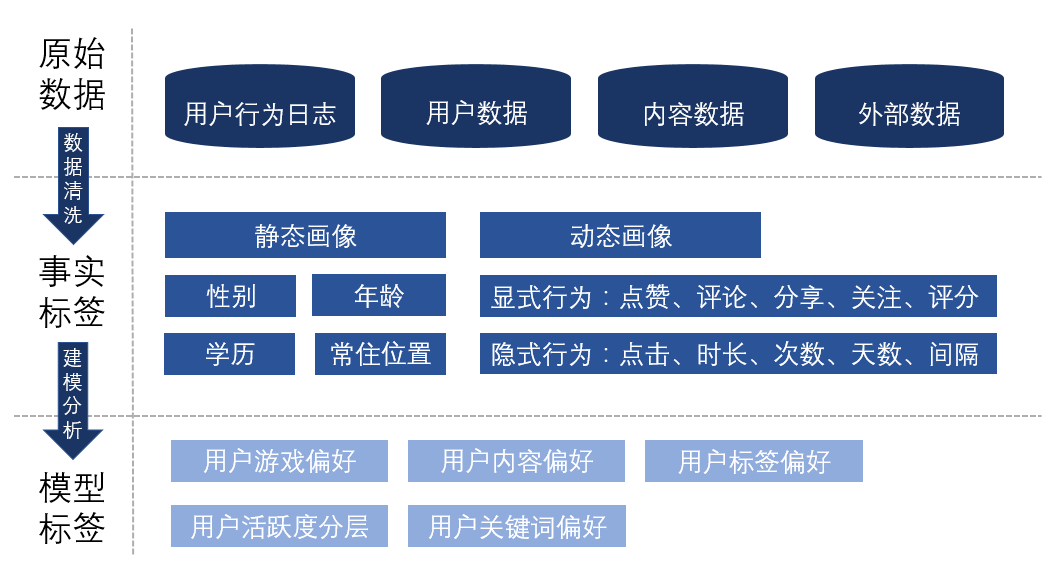
3.2.1. 原始数据
-
用户数据:例如用户的性别、年龄、渠道、注册时间、手机机型等。
-
内容数据:例如游戏的品类,对游戏描述、评论的爬虫之后得到的关键词、标签等。
-
用户与内容的交互:基于用户的行为,了解了什么样的用户喜欢什么样的游戏品类、关键词、标签等。
-
外部数据:单一的产品只能描述用户的某一类喜好,外部数据标签可以让用户更加的立体。
3.2.2. 事实标签
-
静态画像:用户独立于产品场景之外的属性,例如用户的自然属性,这类信息比较稳定,具有统计性意义。
-
动态画像:用户在场景中所产生的显示行为或隐式行为:
-
显示行为:用户明确的表达了自己的喜好,例如点赞、分享、评分、评论(可以通过NLP来判断情感的正负向)等。
-
隐式行为:用户没有明确表达自己的喜好,但用户会用实际行动,例如点击、停留时长等隐性的行为表达自己的喜好。隐式行为的权重小于显性行为,但是在实际业务中,用户的显示行为都比较稀疏,所以需要依赖大量的隐式行为。
3.2.3. 模型标签
-
聚类分析:例如按照用户的活跃度进行聚类,将用户分为高活跃-中活跃-低活跃三类。
-
加权计算:根据用户的行为将用户的标签加权计算,得到每一个标签的分数,用于之后推荐算法的计算。
四、内容画像
4.1 内容画像
-
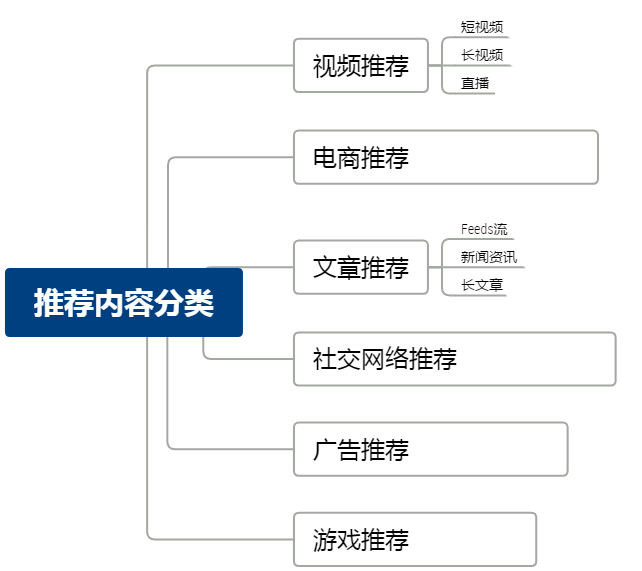
文章推荐:例如新闻内容推荐,需要利用NLP的技术对文章的标题,正文等提取关键词、标签、分类等。
-
视频推荐:除了对于分类、标题关键词的抓取外,还依赖于图片与视频处理技术,例如识别内容标签、内容相似性等。
4.2 环境变量
五、算法构建
5.1 推荐算法流程
-
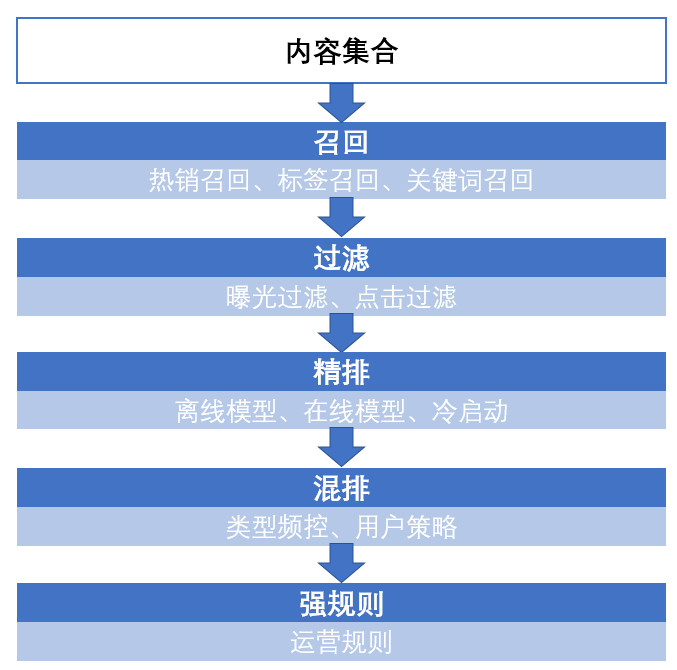
召回:当用户以及内容量比较大的时候,往往先通过召回策略,将百万量级的内容先缩小到百量级。 -
过滤:对于内容不可重复消费的领域,例如实时性比较强的新闻等,在用户已经曝光和点击后不会再推送到用户面前。 -
精排:对于召回并过滤后的内容进行排序,将百量级的内容按照顺序推送。 -
混排:为避免内容越推越窄,将精排后的推荐结果进行一定修改,例如控制某一类型的频次,EE问题处理等。 -
强规则:根据业务规则进行修改,例如在活动时将某些文章置顶以及热点内容的强插等。
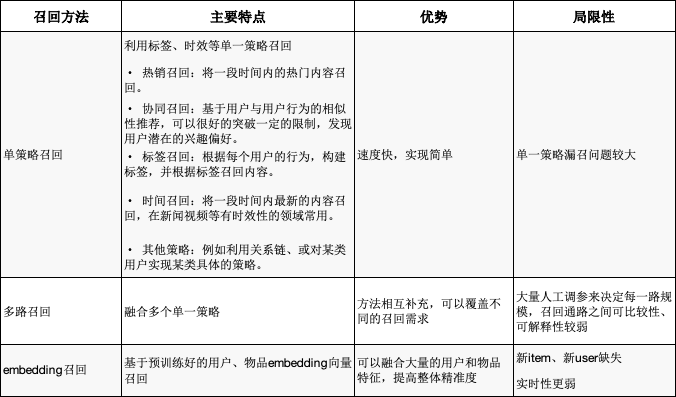
5.2 召回策略
-
召回层目的:当用户与内容的量级比较大,例如对百万量级的用户与内容计算概率,就会产生百万*百万量级的计算量。但同时,大量内容中真正的精品只是少数,对所有内容进行计算将非常的低效,浪费大量的资源和时间。因此采用召回策略,例如热销召回,召回一段时间内最热门的100个内容,只需进行一次计算动作,就可以对所有用户应用。 -
召回层重要性:召回模型是一个推荐系统的天花板,决定了后续可排序的空间。 -
召回层方法:召回对算法的精度、范围、性能都有较高要求。当前业界常采用离线训练+打分或离线训练达到向量表达+向量检索的方式。(对比精排为了提高准确率,更多用离线+实时打分,或在线学习的方式)。
-
召回层与业务场景的结合
-
协同往往只能召回相似的商品,而考虑到推荐目标的替代性和互补性,更多挖掘反应搭配关系的行为集合。 -
数据稀疏且噪音较大,仅仅基于数据构建图,bad case较多,所以需要利用行业的知识图谱。 -
结合行为序列:行为序列挖掘->构件图(通过知识图谱来增加约束)->序列采样(降低噪音,抑制热门问题)->训练。
-
部分用户存在固定的购买模式。利用Poission-Gamma分布的统计建模。计算在某个时间点,购买某个商品的概率,在正确的时间点给用户推出合适的复购商品。
5.3 粗排策略
-
粗排层目的:为后续链路提供集合。 -
粗排层特点:打分量高于精排,但有严格的延迟约束。 -
粗排层方法:主要分为两种路线
-
集合选择:以集合为建模目标,选出满足后链路需求集合。其可控性较弱,算力消耗较小。(多通道、listwise、序列生成) -
精准预估:以值为建模目标,直接对系统目标进行值预估。可控性较高,算力消耗较大。(pointwise)
-
粗排层发展历史:质量分->LR等传统机器学习->向量内内卷积(双塔模型)->COLD全链路(阿里)
5.4 精排策略
5.4.1 精排目标
-
精排层多目标融合原则
-
用户的效用需要通过多个指标反馈:例如用户对视频的喜好,会通过停留时长、完播、点赞等多个动作反应。 -
产品的目标需要通过多个指标衡量:例如短视频产品不仅需要考虑用户效用,也需要考虑作者效用、平台目标与生态影响。
-
精排层多目标融合实例
-
对用户价值。 -
对作者价值,包括给作者的流量、互动、收入等。 -
对内容生态价值,包括品牌价值、内容安全、平台收入。 -
间接价值,非直接由视频产生,例如用户的评论提醒,会改善用户的留存率。
-
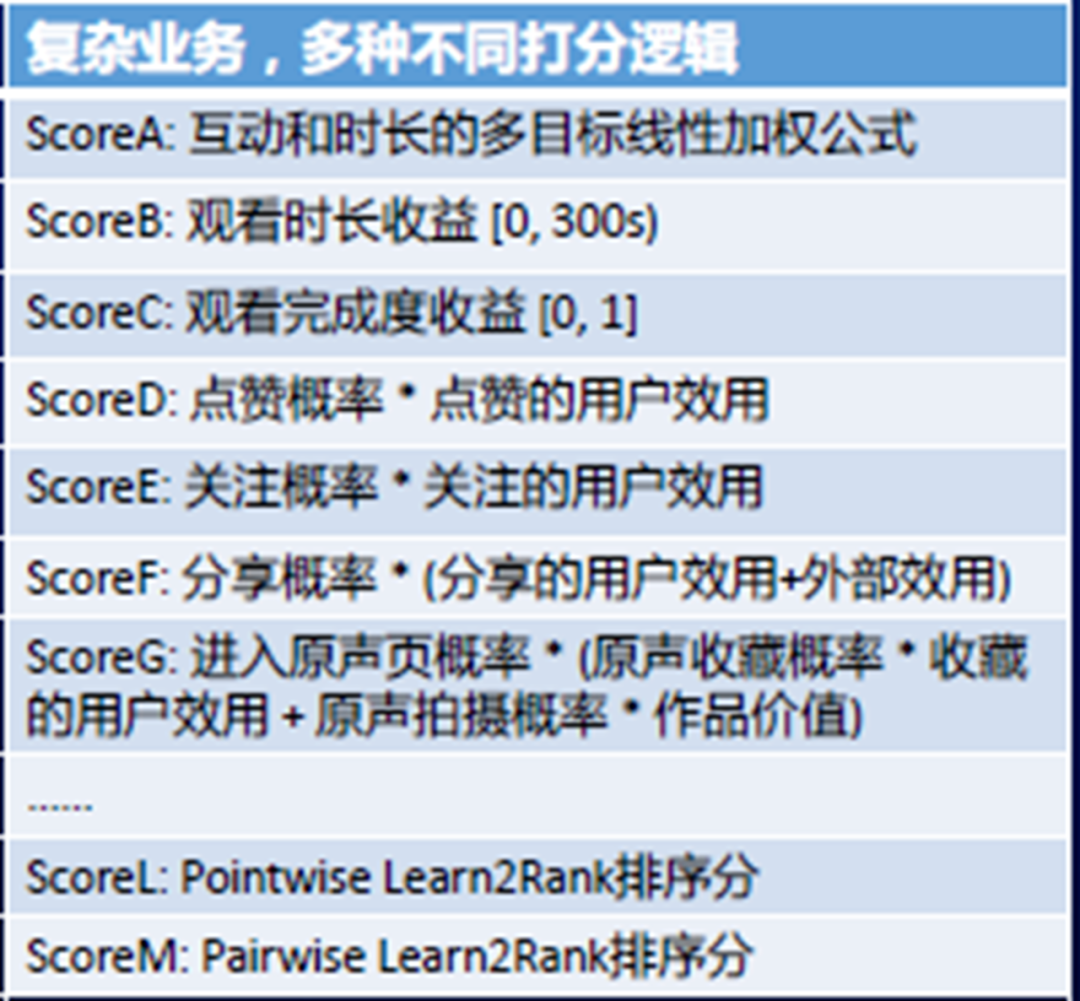
精排层多目标融合方法
-
改变样本权重/多模型分数融合:(1)改变样本权重:先通过权重构造目标值,再进行模型拟合。(2)多模型分数融合:先进行模型拟合在进行加权融合。缺点:依赖规则设计,依赖人工调参,且经常面临以A目标换取B目标的问题。 -
Learn to rank :pairwise、listwise直接排序。 -
结合在线数据自动调参:5%线上流量探索,每次探索N组参数,根据用户的实时reward来优化线上的调参算法。设计约束项,在阈值内线性弱衰减,超出阈值指数强衰减。 -
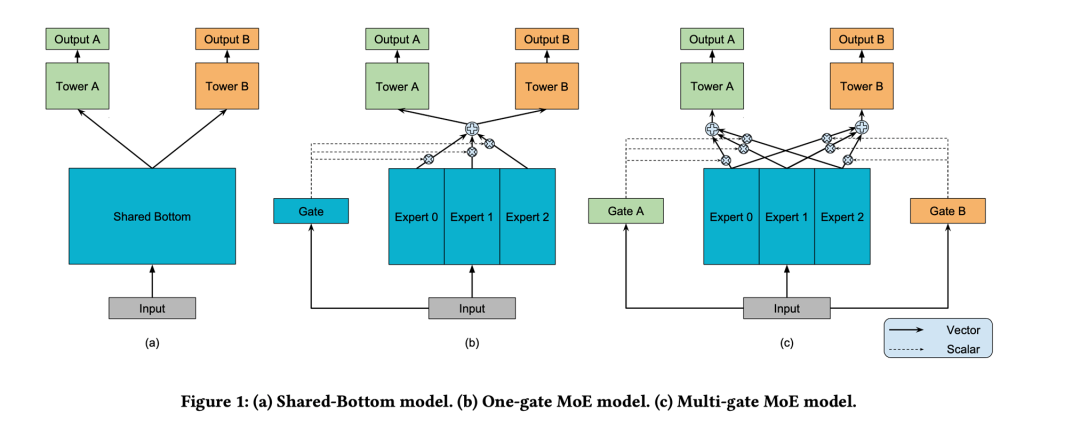
多任务学习:结合深度学习网络,可以共享embedding特征,采用多种特征组合方式,达到相互促进以及泛化的作用。例如MMOE模型,不同的专家可以从相同的输入中提取出不同的特征,由gate attention结构,把专家提取出的特征筛选出各个task最相关的特征,分别接入不同任务的全连接层。不同的任务需要不同的信息,因此每个任务都由独立gate负责。
-
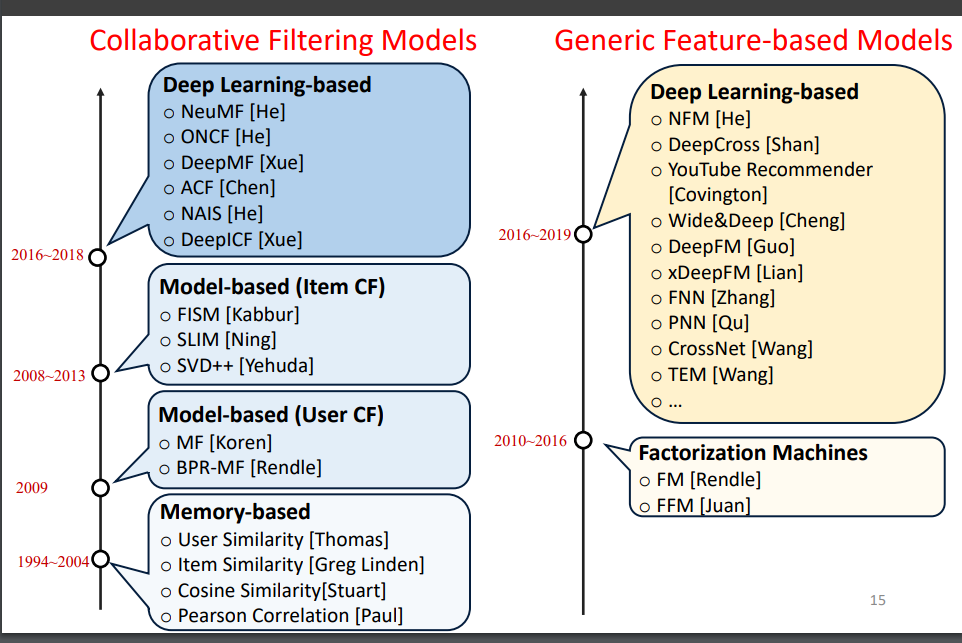
精排模型发展历史
-
精排模型分类
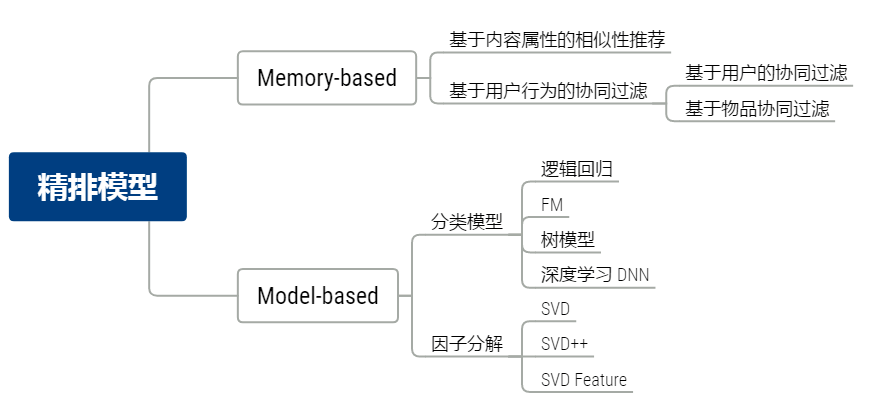
-
精排模型基本原理
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
||
|
|
||
|
|
|
|
-
精排模型优缺点
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
5.4.3 逻辑回归——最简单Model-based模型
-
原理介绍


-
构建流程

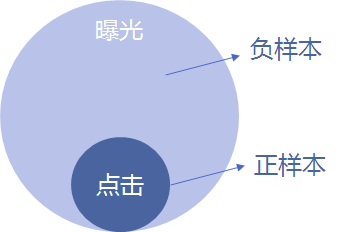
-
基础数据 -
趋势数据 -
时间数据 -
交叉数据
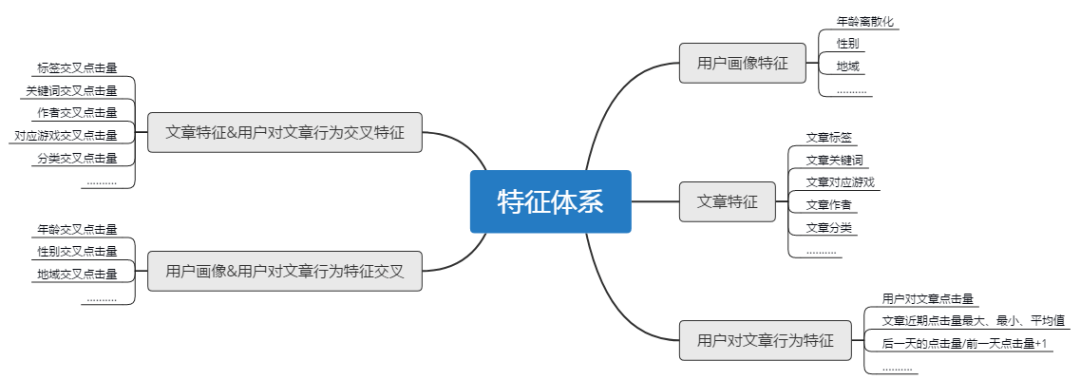
5.4.4 深度学习——当前最新发展方向
-
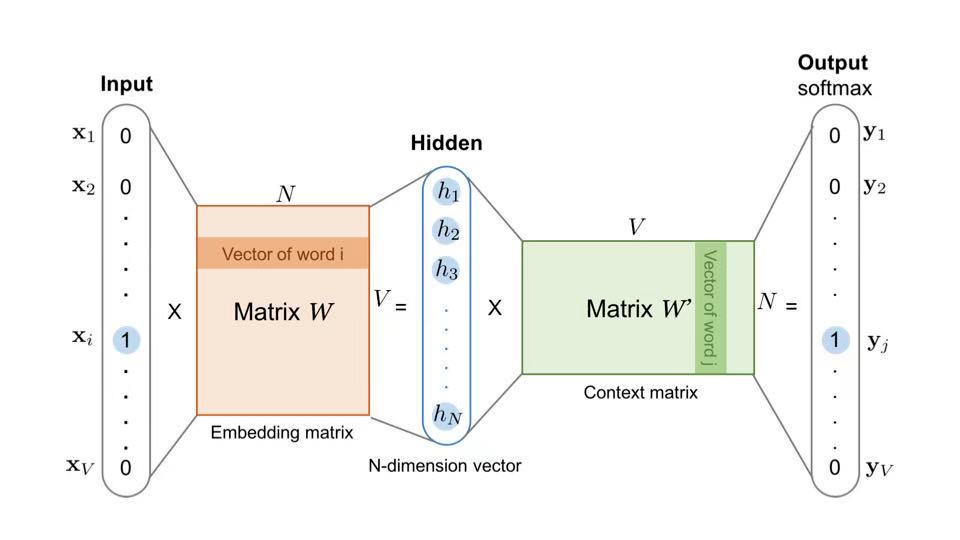
Embedding+MLP 模型结构:微软在 2016 年提出 Deep Crossing,用于广告推荐中。 -
从下到上可以分为 5 层,分别是 Feature 层、Embedding 层、Stacking 层、MLP 层和 Scoring 层。 -
对于类别特征,先利用 Embedding 层进行特征稠密化,再利用 Stacking 层连接其他特征,输入 MLP (多层神经元网络),最后用 Scoring 层预估结果。
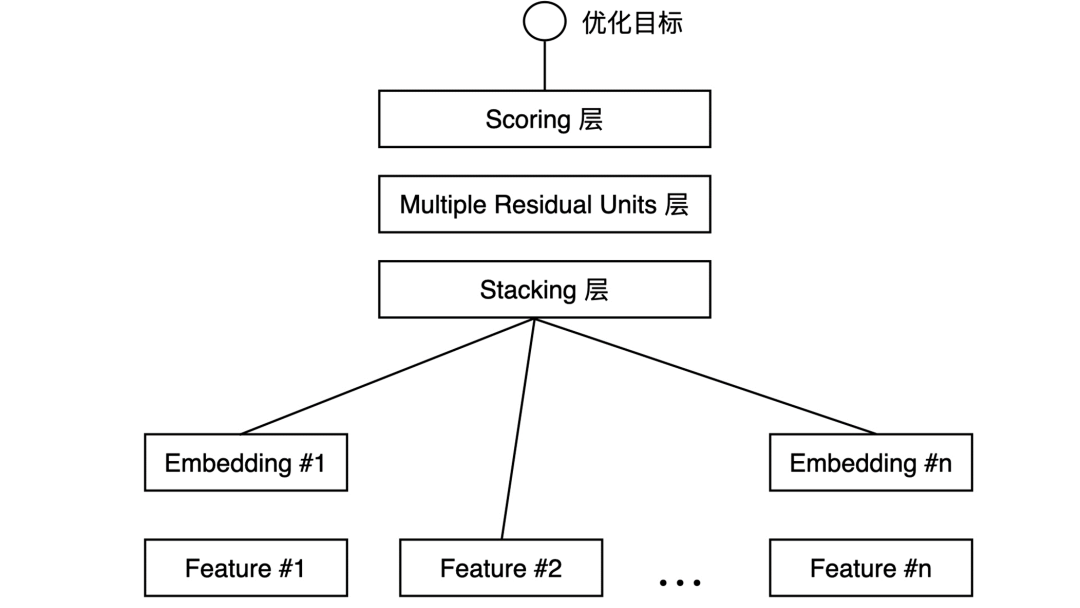
-
改变神经网络的复杂程度。 -
改变特征交叉方式。 -
多种模型组合应用。 -
与其他领域的结合,例如自然语言处理,图像处理,强化领域等。
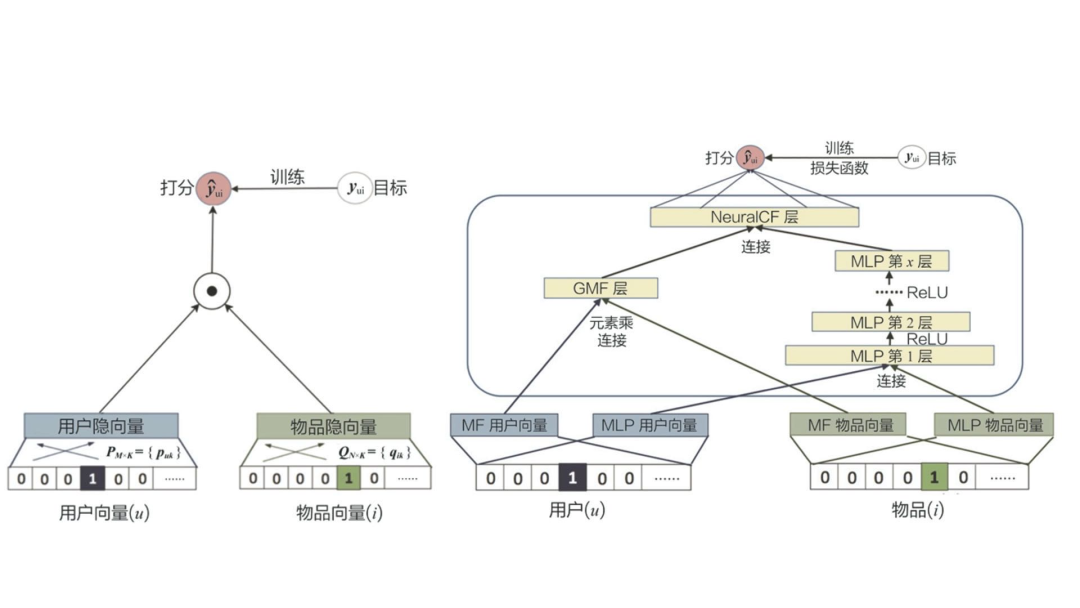
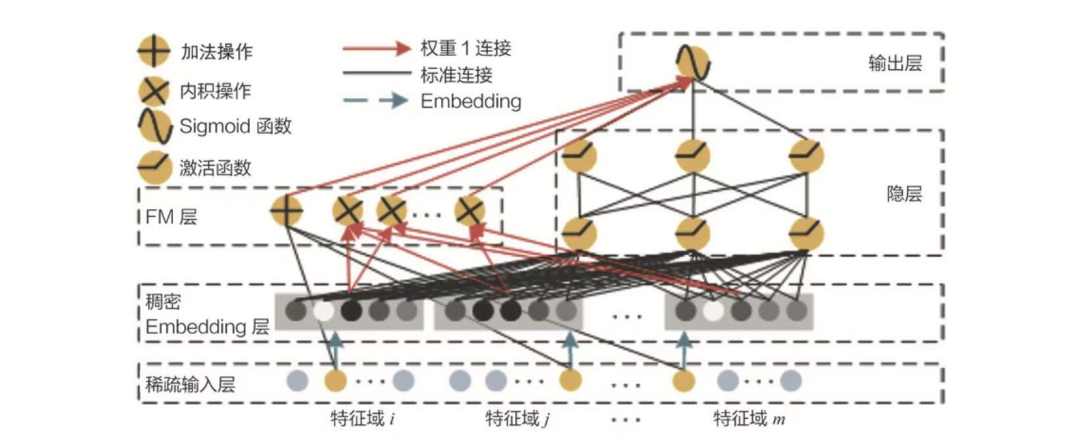
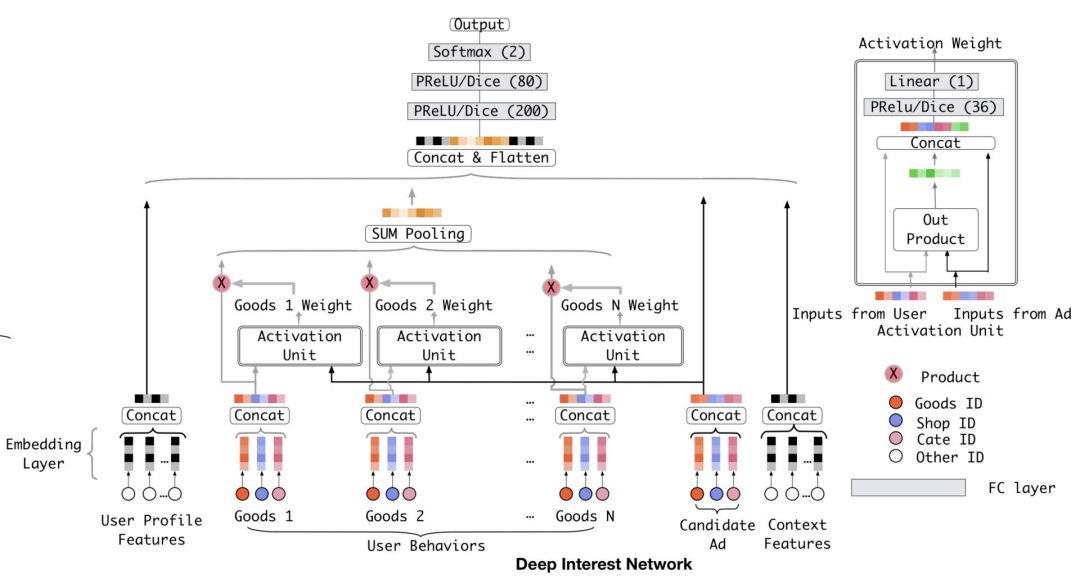
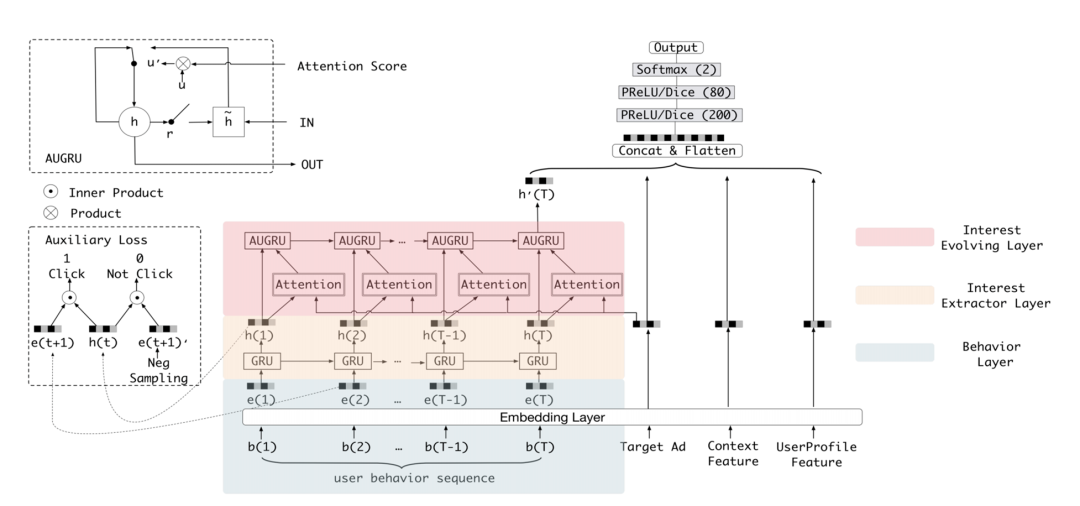
5.5 重排层策略
5.5.1 EE问题
-
MBA问题:所有的选择都要同时考虑寻找最优解以及累计收益最大的问题。 -
解决方案:Bandit算法,衡量臂的平均收益,收益越大越容易被选择,以及臂的方差,方差越大越容易被选择。
-
常用算法:汤普森采样算法,UCB算法,Epsilon贪婪算法,LinUCB算法,与协同过滤结合的COFIBA。
5.5.2 多样性问题
-
多样性问题
-
多样性过差:用户探索不够,兴趣过窄,系统泛化能力以及可持续性变差;流量过于集中在少数item上,系统缺乏活力。 -
多样性过强:用户兴趣聚焦程度弱;item流量分配平均,对优质item激励不足。
-
多样性解法:1. 根据内容的相关性以及相似性进行打散。2. 保持用户以及内容探索比例。3. 人工规则控制。
5.5.3 上下文问题
-
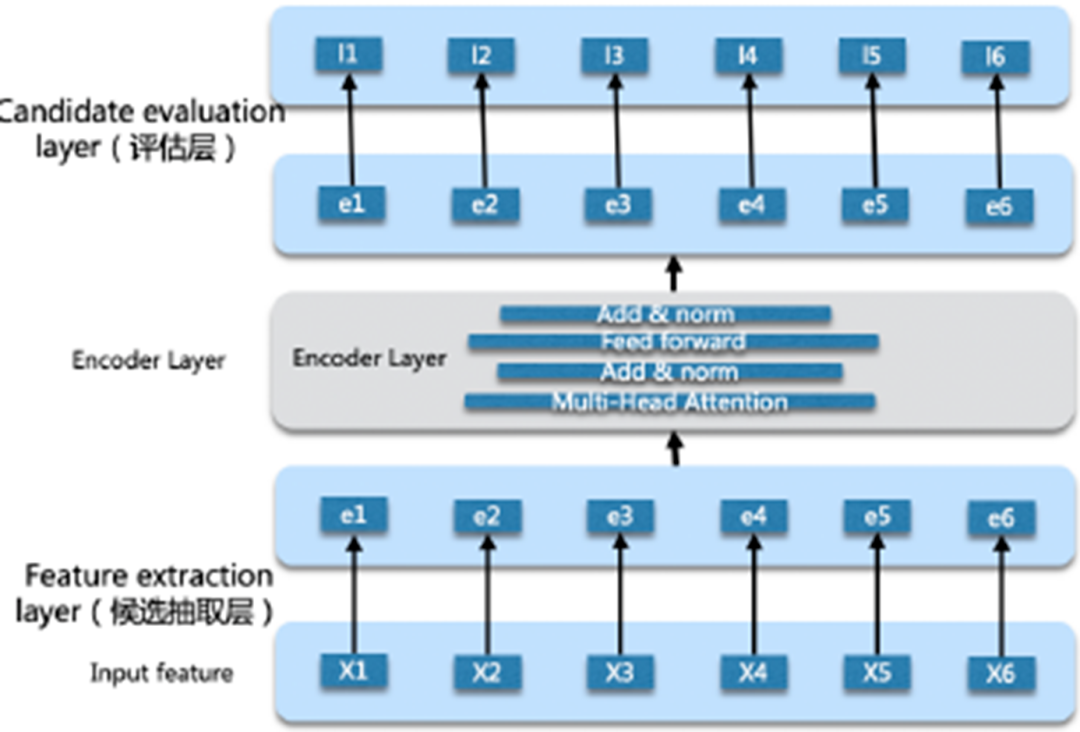
Pointwise考虑单点目标/Pairwise考虑一个pair/Listwise考虑整个集合的指标。 -
Listwise 对视频组合进行transformer建模,刻画视频间的相互影响,前序视频对后续视频观看有影响,前后组合决定总收益。
-
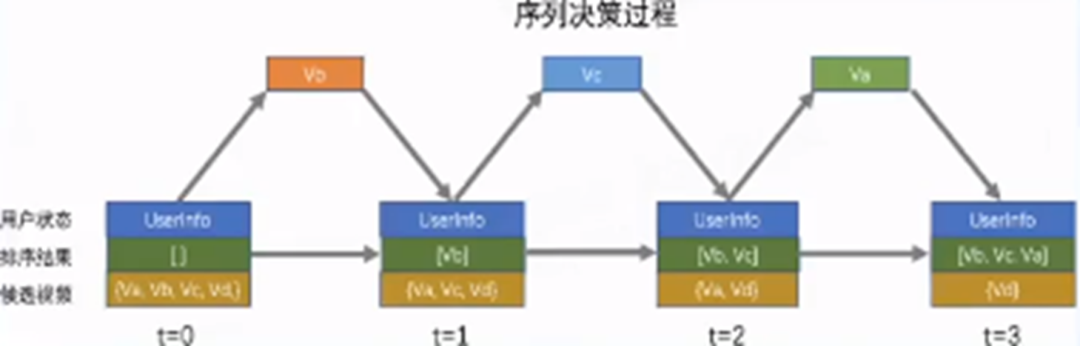
考虑序列决策,从前向后依次贪心的选择动作概率最大的视频。 -
Reward = f(相关性,多样性,约束)。
5.6 冷启动
5.6.1 用户冷启
-
side information 补充:例如商品类目、领域知识图谱、第三方公司数据的补充。 -
Cross domain:利用共同的用户在不同地方的数据进行冷启。 -
用户填写兴趣。 -
元学习:利用多任务间具有泛化能力的模型,进行少样本学习(few-shot learning)。
-
主动学习、在线学习、强化学习:快速收集数据,且反馈到特征与模型中。 -
增强模型实时化以及收敛能力。
5.6.2 内容冷启
六、当前发展
-
推荐系统中的特征向量和用户最终的反馈(比如点击、点赞等)之间的关系是由因果关系和非因果关系共同组成。因果关系是反应物品被用户偏好的原因,非因果关系仅反应用户和物品之间的统计相关性,比如曝光模式、公众观念、展示位置等。而现有推荐算法缺乏对这两种关系的区分。 -
A Model-Agnostic Causal Learning Framework for Recommendation using Search Data。论文提出了一个基于工具变量的模型无关的因果学习框架 IV4Rec,联合考虑了搜索场景和推荐场景下的用户行为,利用搜索数据辅助推荐模型。即将用户的搜索行为作为工具变量,来帮助分解原本推荐中 特征( treatments),使用深度神经网络将分离的两个部分结合起来,来完成推荐任务。
-
推荐系统倾向于学习每个用户对物品的长期和静态的偏好,但一个用户的所有的历史交互行为对他当前的偏好并非同等重要,用户的短期偏好和跟时间相关的上下文场景所包含的信息更加实时也更加灵敏。基于会话的推荐系统从一个用户的最近产生的会话中捕获他的短期偏好,以及利用会话和会话间的偏好变化,进行更精准和实时推荐。 -
TKDE 2022 | Disentangled Graph Neural Networks for Session-based Recommendation。用户选择某个物品的意图是由该物品的某些因素驱动的,本文的方法建模了这种细粒度的的兴趣来生成高质量的会话嵌入。
-
大部分的信息本质上都是图结构,GNN能够自然地整合节点属性信息和拓扑结构信息,来减少特征处理中的信息折损。 -
ICDE 2021 | Multi-Behavior Enhanced Recommendation with Cross-Interaction Collaborative Relation Modeling。利用图神经网络建模Multi-Behavior 推荐。
-
先验的知识图谱可以对推荐系统进行很好的信息补充和信息约束,特别是在数据较为稀疏的场景下。(1)知识图谱中的结构化知识可以在冷启动场景中提供更多的信息。(2)对于数据稀疏,方差过大的情况下,增加有效约束。(3)先验知识纠正数据偏差。(4)增强推荐算法可解释性。 -
Conditional Graph Attention Networks for Distilling and Refining Knowledge Graphs in Recommendation 由于知识图谱的泛化性和规模性,大多数知识关系对目标用户-物品预测没有帮助。为了利用知识图谱来捕获推荐系统中特定目标的知识关系,需要对知识图谱进行提取以保留有用信息,并对知识进行提炼以捕获更准确的用户偏好。这篇文章提出了Knowledge-aware Conditional Attention Networks(KGAN)网络,对于给定target(即用户-物品对),基于知识感知的注意力自动从全局的知识图谱中提取出特定于target的子图。通过在子图上应用条件注意力机制进行邻居聚合,以此实现对知识图谱的细化,进而获得特定target的节点表示。
-
与传统推荐算法不同,其主要描述和解决智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。 -
CIKM 2021 | Supervised Advantage Actor-Critic for Recommender Systems。现有的RL+(self-)supervised sequential learning方式由于缺乏负奖励信号,q值的估计往往偏向于正值。此外,q值还严重依赖于序列的特定时间戳。本文提出负采样策略来训练RL分量,并将其与有监督序列学习相结合。
-
短视频推荐业务中,涉及的上下文信息包含图像,语音,文本,社交网络,知识图谱,将不同的上下文特征进行融合。 -
Arxiv 2021 | MultiHead MultiModal Deep Interest Recommendation Network。在DIN模型的基础上,增加了多头多模态模块(MultiHead MultiModal),丰富了模型可以使用的特征集,同时增强了模型的交叉组合和拟合能力。
七. 算法衡量标准
7.1 指标选择
-
硬指标:对于大多数的平台而言,推荐系统最重要的作用是提升一些“硬指标”。例如新闻推荐中的点击率,但是如果单纯以点击率提升为目标,最后容易成为一些低俗内容,“标题党”的天下。 -
软指标:除了“硬指标”,推荐系统还需要很多“软指标”以及“反向指标”来衡量除了点击等之外的价值。好的推荐系统能够扩展用户的视野,发现那些他们感兴趣,但是不会主动获取的内容。同时推荐系统还可以帮助平台挖掘被埋没的优质长尾内容,介绍给感兴趣的用户。

7.2 推荐效果

-
离线效果:通过反复在数据样本进行实验来获得算法的效果。通常这种方法比较简单、明确。但是由于数据是离线的,基于过去的历史数据,不能够真实的反应线上效果。同时需要通过时间窗口的滚动来保证模型的客观性和普适性。 -
白板测试:当在离线实验阶段得到了一个比较不错的预测结果之后,就需要将推荐的结果拿到更加真实的环境中进行测评,如果这个时候将算法直接上线,会面临较高的风险。因为推荐结果的好坏不能仅仅从离线的数字指标衡量,更要关注用户体验,所以可以通过小范围的反复白板测试,获得自己和周围的人对于推荐结果的直观反馈,进行优化。 -
在线测试(AB test):实践是检验真理的唯一标准,在推荐系统的优化过程中,在线测试是最贴近现实、最重要的反馈方式。通过AB测试的方式,可以衡量算法与其他方法、算法与算法之间的效果差异。

八. 除了算法本身之外...
8.1 推荐算法是否会导致信息不平等和信息茧房?
-
内容的不平等或许更多的产生于用户天性本身,而推荐算法的作用更像是帮助用户“订阅”了不同的内容。用户天然的会对信息产生筛选,并集中在自己的兴趣领域。在过去杂志订阅的阶段,虽然每个杂志和报纸的内容都是完全相同的,但是用户通过订阅不同的杂志实际接受到了完全不同的消息。而今天的内容APP提供了各种话题,各种类型的内容,但用户通过推荐算法,在无意识的情况下“订阅”了不同的“杂志”。
-
人们更加集中于垂直的喜好是不可逆转的趋势。从内容供给的角度来讲,从内容的匮乏到繁荣,从中心化到垂直聚群,用户的选择更贴近自己的喜好是不可逆转的趋势。在没有提供太多选项的时候,人们会更多的集中在某几个内容上面,而当今天层出不穷的内容出现,人们开始追逐更加个性化,精细化的内容。
-
产品价值与数据指标的平衡:推荐算法是对短期数据指标的高度拟合,一定阶段后会发现对推荐系统的人工干扰往往会造成负向的指标波动。但推荐算法往往只能带来短期的局部最优解。产品仍需要从本质出发,来看待产品给用户带来的本质价值。对产品方向的判断、以及对产品价值的坚持才是产品寻找全局最优解的方式。
8.2 算法可能产生的蝴蝶效应
8.2.1 推荐算法对feed传播的影响
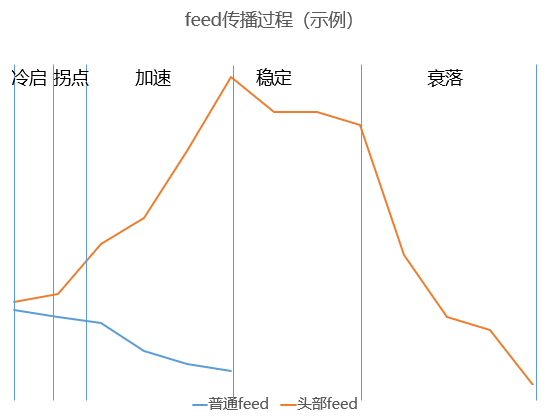
-
feed特性:优质度、传播性、普适性,这三点决定其传播速度、传播稳定性以及天花板。 -
feed发表时间:feed与时间的“对抗性”。因为(1)feed无法重复消费且一段时间内目标受众有限(2)由于环境背景、文化潮流、热点等feed具有一定时效性(3)不确定性,时间越长影响其传播的因素越多,受众的注意力发生转移的可能越大。
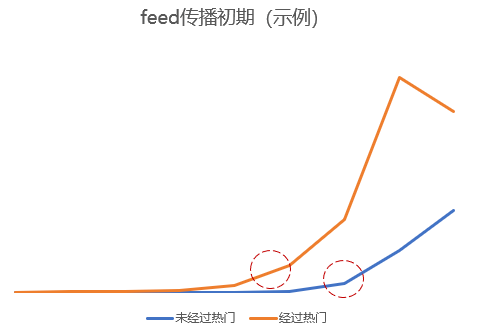
8.2.2 推荐算法对平台的影响
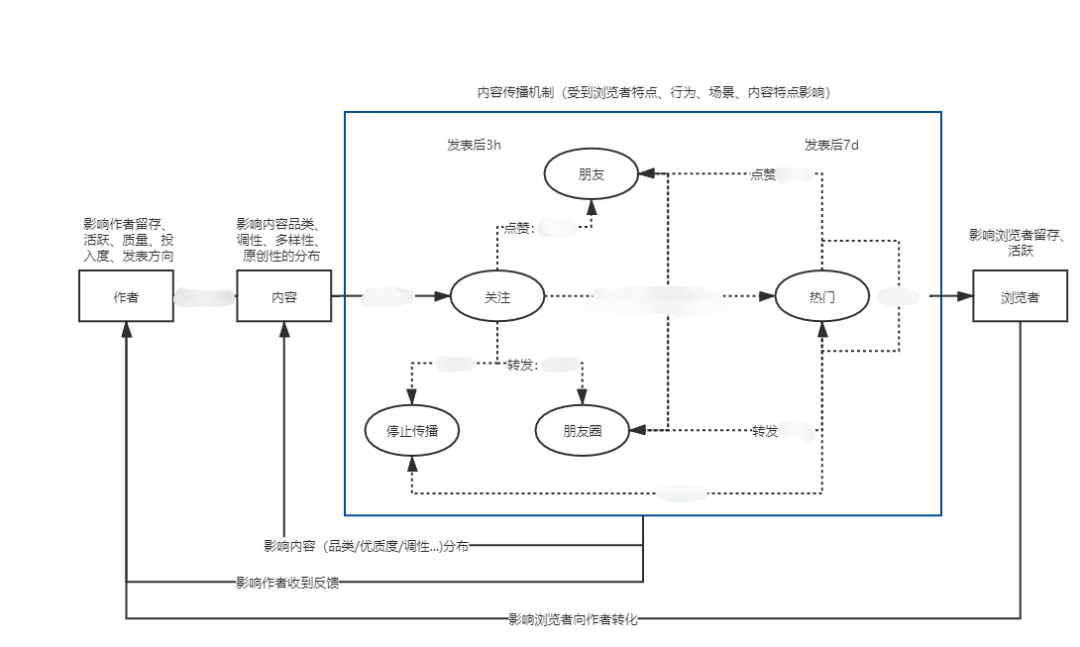
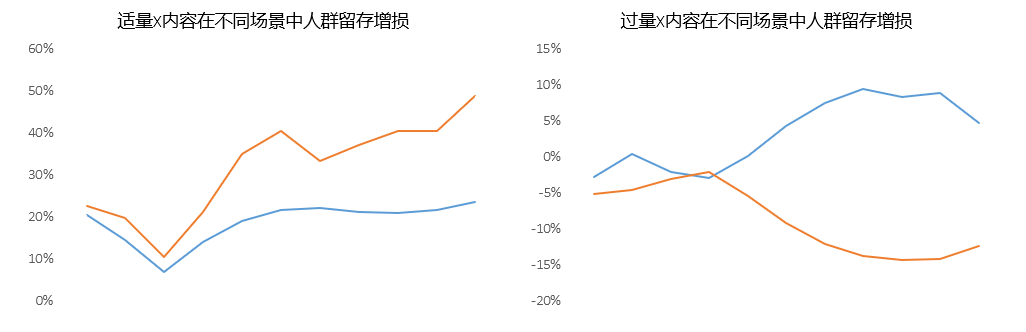



文章评论