前言
软件的开发不仅仅在于解决业务,它还需要程序尽可能的运行下去,这就涉及到了服务的稳定性。稳定性涉及很多因素,硬件软件都需要保证。为了能让这些条件更加充足,我们需要不断的收集数据,分析数据,监控数据,进而优化能优化的点。Prometheus 在这方面就为我们提供了很好的监控方案。
什么是 Prometheus?
Prometheus 是一个开源的监控和报警系统,它将我们关心的指标值通过 PULL 的方式获取并存储为时间序列数据。如果单从它的收集功能来讲,我们也可以通过 mysql、redis 等方式实现。然而,这些数据是在每时每刻产生的,其庞大的规模需要我们好好的考虑其存储方式。另外,这些监控数据大多数时候是跟统计相关的,比如数据与时间的分布情况等,这需要有专业的度量知识。而这些正是 Prometheus 的擅长所在。
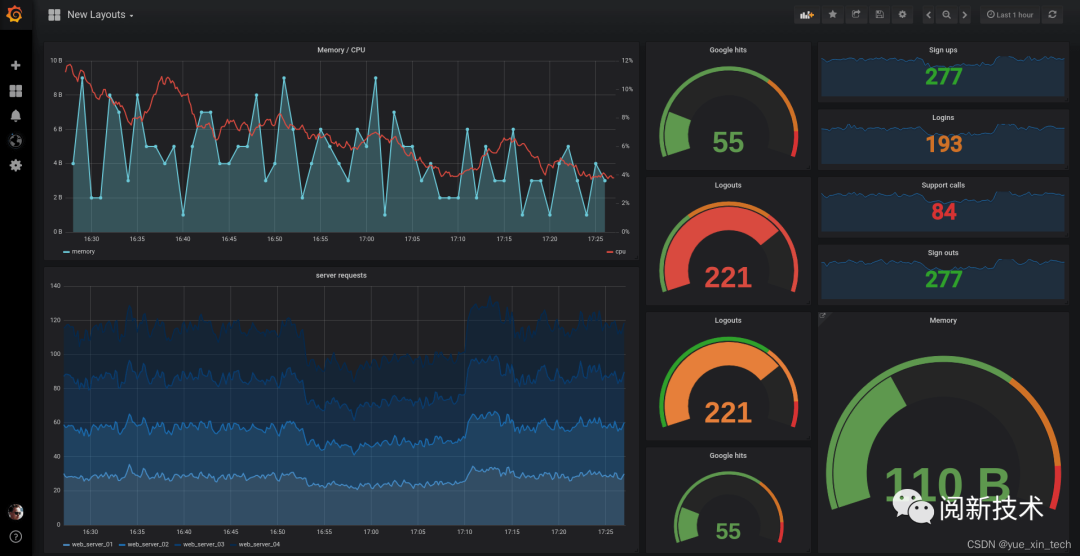
由于 Prometheus 的关注重点在于指标值以及时间点这两个因素,所以外部程序对它的接入成本非常的低。这种易用性可以让我们对数据进行多维度、多角度的观察和分析,使得监控的效果更加具体化,例如内存消耗、网络利用率、请求连接数等。
除此之外,Prometheus 还具备了操作简单、可拓展的数据收集和强大的查询语言等特性,这些特性能帮助我们在问题出现的时候,快速告警并定位错误。所以现在很多微服务基础设施都会选择接入 Prometheus,像 k8s、云原生等。
Prometheus 的整体架构
Prometheus 为了保证它的拓展性、可靠性,在除了提供核心的 server 外还提供了很多生态组件,为了不增加理解的复杂度,我们先从上帝视角,看看它的核心 Prometheus server:
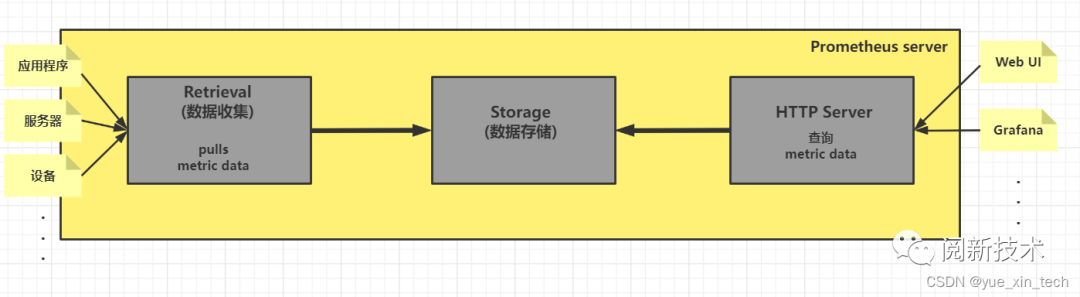
可以看到,Prometheus server 的处理链路很清晰,其实就是数据收集-数据存储-数据查询。当然,一个完善的系统肯定会衍生出许多组件来支撑它的特性。所以我们会看到,在 Prometheus 架构里还存在着其他的组件,例如:
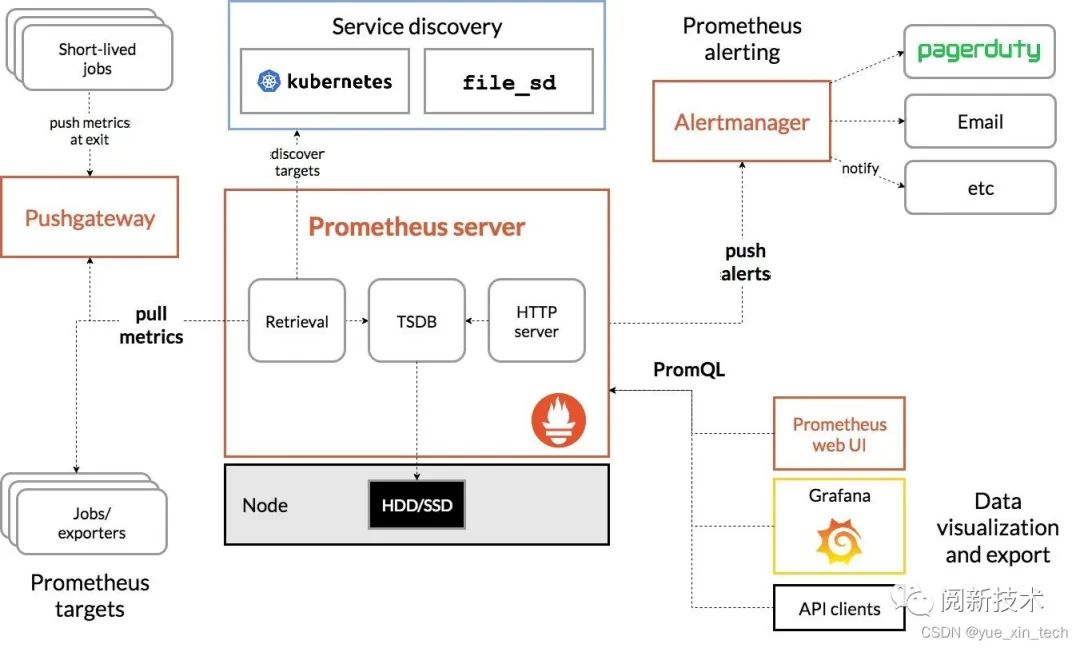
-
Pushgateway:为监控节点提供 Push 功能,再由 Prometheus server 到 Pushgateway 集中 Pull 数据。 -
Targets Discover:根据服务发现获取监控节点的地址。 -
PromQL:针对指标数据查询的语言,类似 SQL。 -
Alertmanager:根据配置规则以及指标分析,提供告警服务。
最后,Prometheus 的整体架构如下:
指标(Metrics)
上面提到 Prometheus 的核心关注点在于指标(Metrics),指标我们可以简单的理解为一个度量值,这个值可以是 CPU 负载、内存使用、请求连接数等。它们来源于操作系统、应用服务、设备数据等,会随着时间的变化而有所不同。为了能让这些指标更好的体现出度量内涵,Prometheus 提供了四种指标类型:
-
Counter(计数器):只增不减的计数器 -
Gauge(仪表盘):可增可减,任意变化的仪表盘 -
Histogram(直方图):将指标进行量化平均,得到类似在 0~10ms 之间的请求数有多少,而 10~20ms 之间的请求数又有多少的直方图 -
Summary(摘要):histogram 在客户端是简单的分桶和分桶计数,由于 prometheus 服务端基于这么有限的数据做百分位估算,不是很准确,summary 就是解决百分位准确的问题而来的。
实际上,在 Prometheus 里指标的组成有几部分:指标名、labels、指标值。(labels 就是我们经常提到的维度)。例如,下面就是一个关于 http 的计数器类型指标数据:
# HELP prometheus_http_requests_total Counter of HTTP requests.
# TYPE prometheus_http_requests_total counter
prometheus_http_requests_total{code="200",handler="/api/v1/label/:name/values"} 7
prometheus_http_requests_total{code="200",handler="/api/v1/query"} 19
prometheus_http_requests_total{code="200",handler="/api/v1/query_range"} 27
prometheus_http_requests_total{code="200",handler="/graph"} 11
prometheus_http_requests_total{code="200",handler="/metrics"} 8929
prometheus_http_requests_total{code="200",handler="/static/*filepath"} 52
prometheus_http_requests_total{code="302",handler="/"} 1
prometheus_http_requests_total{code="400",handler="/api/v1/query_range"} 6
需要注意的是,Prometheus 需要收集的数据是随着时间的增长而增长的,所以它一般不建议保留长期的指标数据,默认保留 15 天。如果监控的数据发现问题,那么需要我们配置告警发现,快速处理。
Prometheus 配置
关于 Prometheus 的使用相信网上有很多详细教程,此处不再说明。我们来看下它的关键配置文件:prometheus.yml:
global:
scrape_interval: 15s
evaluation_interval: 15s
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
可以看到,主要分为了三部分:全局配置(例如数据收集时间间隔)、告警规则、监控节点。告警规则是基于 PromQL 表达式触发条件的,如:
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: Instance has been down for more than 5 minutes
PromQL
PromQL 是 Prometheus 内置的数据查询语言,就像 Mysql 的 SQL 语句一样,为我们提供了丰富的查询功能,可应用在面板上查询过滤、告警规则里的表达式等。下面我们就来初步认识下 PromQL。
PromQL 是面向指标查询的,前面我们说过,指标是由指标名、labels、指标值组成的,所以当我们想要查询某个指标时,便可以在浏览器访问 http://localhost:9090/graph 后输入如下表达式:
prometheus_http_requests_total
然后就可以看到相关的指标值了:
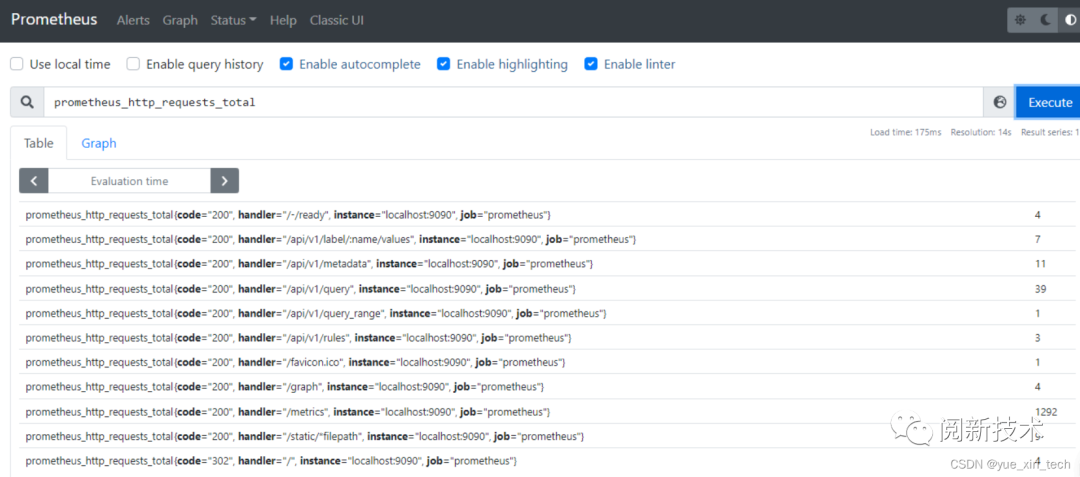
像上面这种查询表达式返回的结果被称之为 瞬时向量,即返回结果里每个标签的每个指标只会存在单个值。如果我们想要按时间范围来查询的话,那么就需要使用区间向量表达式了,通过 [] 来选择我们的时间。例如:
prometheus_http_requests_total[1m]
表示查询最近 1 分钟的样本数据
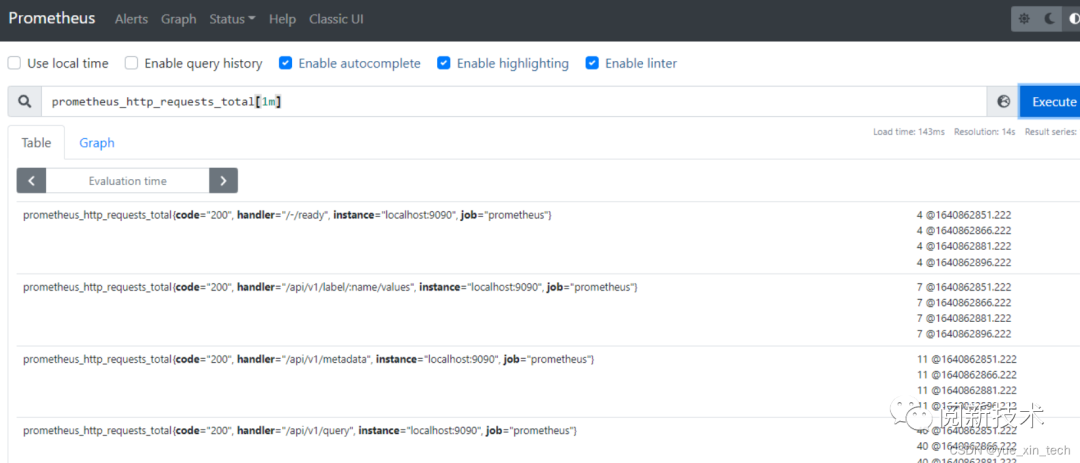
除了瞬时向量、区间向量,PromQL 的返回还有 标量(一个浮点型的数据值)、字符串类型,根据这些结果类型,我们就也做更多的操作了。
运算符
PromQL 支持我们对指标结果进行运算,比如:
-
算术运算符:+(加法)、–(减法)、*(乘法)、/(除)、%(模)、^(幂)。 -
比较运算符:>(大于)、<(小于)、==(等于)、!=(不等于)、>=(大于或等于)、<=(小于或等于) -
逻辑运算符:and(与)、or(或)、unless(排除) -
聚合运算:sum(和)、min(最小)、avg(平均)、count(总数)、stddev(计算维度上的总体标准偏差)、stdvar(计算维度上的总体标准方差)等
有了这些运算符,我们就可更灵活的处理指标值了。
数据过滤
当然,我们也可以对数据进行过滤,在 PromQL 里主要有以下两种过滤表达式:
-
完全匹配:即 = 和 != 的用法 -
正则匹配:携带了正则表达式,可以用 =~ 和!~ 分表表示正向和反向匹配
例如:process_cpu_seconds_total{job="Node Exporter"} 将筛选标签 job = Node Exporter 的指标数据。
数据存储
Prometheus 2.x 默认将时间序列数据库保存在本地磁盘中,当然,我们也可以将数据保存到第三方的存储服务中。
本地存储
Prometheus 按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中。每个块都是一个单独的目录,里面包含了对应时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。
其中索引文件会将指标名称和标签索引到样板数据的时间序列中。此期间如果通过 API 删除时间序列,删除记录会保存在单独的逻辑文件 tombstone 当中。
而样本数据所在的块则会被直接保存在内存中,不会持久化到磁盘中。为了确保 Prometheus 发生崩溃或重启时能够恢复数据,Prometheus 启动时会通过预写日志(write-ahead-log(WAL))重新记录,从而恢复数据。
预写日志文件保存在 wal 目录中,每个文件大小为 128MB。wal 文件包括还没有被压缩的原始数据,所以比常规的块文件大得多。一般情况下,Prometheus 会保留三个 wal 文件,但如果有些高负载服务器需要保存两个小时以上的原始数据,wal 文件的数量就会大于 3 个。
远程存储
受限于可拓展性和持久性,Prometheus 的本地存储仅限于单个节点,所以 Prometheus 并没有提供集群的存储解决方案,而是提供了一系列的接口,以便和远程存储系统相结合,比如当我们在 prometheus.yml 配置文件里配置了 Remote Write(远程写) 的 URL 地址后,Prometheus 就会将采集到的样本数据通过 HTTP 的形式发送给适配器,后续用户就可以在适配器里对接外部服务了。外部服务可以是真正的存储系统,也可以是云存储、消息队列等。

和Remote Write(远程写) 一样,当我们在配置文件里配置了 Remote Read(远程读) 的 URL 地址后,就会通过 HTTP 的形式到 Adaptor 里查询数据,然后 Adaptor 再去第三方存储服务里获取数据转发回来。

Prometheus 缺点
由于 Prometheus 是以指标为关键数据,所以当我们想要对数据进行一条链路的走向时,是达不到的。而且它的数据是面向时间顺序的,如果我们想要提供一些报表处理,那是挺难的。
另外,由于 Prometheus 是奔着简单易拓展目的设计的,所以在分布式存储、集群、多租户等方面基本没有涉及,它更专注于实时监控。
总结
系统监控其实是每一个成熟架构都需要考虑的重点,它是基础设施里的重要组成部分,能让我们提前发现问题,解决问题。而 Prometheus 作为流行的开源监控系统,现在逐渐成为了标准,所以提前熟悉它,使用它,还是大有收益的,毕竟保证业务的稳定性,也是我们开发工作的一部分呢。
参考
-
[1]what is prometheus? -
[2]一篇文章带你理解和使用prometheus的指标 -
[3]prometheus 中文文档
感兴趣的朋友可以搜一搜公众号「 阅新技术 」,关注更多的推送文章。
可以的话,就顺便点个赞、留个言、分享下,感谢各位支持!
阅新技术,阅读更多的新知识。

文章评论