一、推荐系统介绍
一句话介绍推荐系统的作用:高效地达成用户与意向对象的匹配。
1.1 推荐系统的应用
推荐系统是建立在海量数据挖掘基础上,高效地为用户提供个性化的决策支持和信息服务,以提高用户体验及商业效益。常见的推荐应用场景如:
-
资讯类:今日头条、腾讯公众号等新闻、广告、文章等内容推荐; -
电商类:淘宝、京东、拼多多、亚马逊等商品推荐; -
娱乐类:抖音、快手、爱奇艺等视频推荐; -
生活服务类:美团、大众点评、携程等吃喝玩乐推荐; -
社交类:微信、陌陌等好友推荐;
1.2 推荐系统的目标
构建推荐系统前,首先要根据业务目标确定推荐系统的优化目标,对于不同的应用场景,推荐系统(模型学习)关注的是不同的业务指标,比如:
-
对于电商推荐,不仅要预测用户的点击率(CTR),更重要的是预测用户的转化率(CVR);
-
对于内容推荐,业务关心的除了CTR,还有阅读/观看时长、点赞、转发、评论等指标;
二、推荐系统的技术架构
2.1 推荐系统的层次组成
推荐系统基于海量的物品数据的挖掘,通常由 召回层→排序层(粗排、精排、重排)组成,不同的层次的组成,其实也就是信息筛选的漏斗,这也是工程上效率的需要,把意向对象的数量从粗犷到精细化的筛选过程(这过程就像是找工作的时候,HR根据简历985/211粗筛出一部分,再做技能匹配及面试精准筛选,最终敲定合适的人选):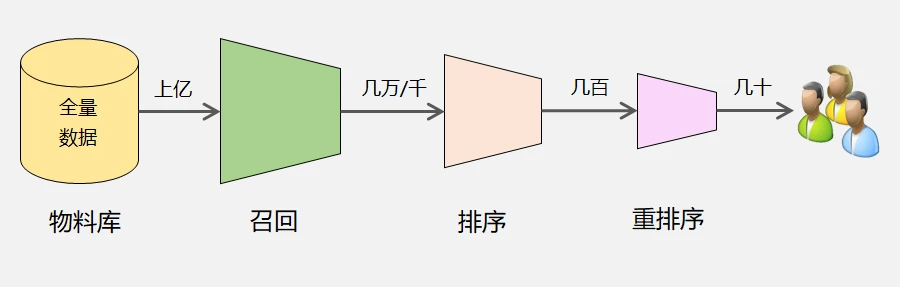
-
召回层:从物品库中根据多个维度筛选出潜在物品候选集(多路召回),并将候选集传递给排序环节。在召回供给池中,整个召回环节的输出量往往以万为单位。召回层主要作用是在海量的候选做粗筛,由于召回位置靠前且输入空间较大,所以时延要求较高,偏好简单方法,简单快速地确定候选集。
常用方法有:召回策略(如推荐热门文章、命中某类标签的文章等等)、双塔模型(学习用户及物品的embedding,内积表示预测意向概率)、FM及CF等模型做召回、知识图谱(知识图谱表示学习,知识推理用户对物品的兴趣程度)、用户(多兴趣)行为序列预测做召回等等。

-
粗排层:利用规则或者简单模型对召回的物品进行排序,并根据配额进行截断,截取出 Top N 条数据输出给精排层,配额一般分业务场景,整个粗排环节的输出量往往以千为单位。
-
精排层:利用大量特征的复杂模型,对物品进行更精准的排序,然后输出给重排层,整个精排环节的输出量往往以百为单位。粗排、精排的环节是推荐系统最关键,也是最具有技术含量的部分,使用的方法有深度学习推荐模型(Deep& Cross、NFM等)、强化学习等等。
-
重排层:主要以产品策略为导向进行重排(及融合),常见策略如去除已曝光、去重、打散、多样性、新鲜度、效益优先等策略,并根据点击回退在列表中插入新的信息来提升体验,最后生成用户可见的推荐列表,整个融合和重排环节的输出量往往以几十为单位。

2.2 冷启动方法
对于完整的推荐系统结构,还需要考虑一个问题是:对于新的用户、新的物品如何有效推荐的问题,也就是“冷启动”的问题,因为没有太多数据和特征来学习召回及排序模型,所以往往要用一些冷启动方法替代来达到目的(这个目的不只是提高点击等消费指标,更深层的可能会极大的带动业务增长)。
冷启动一般分为三类,用户冷启动、物品冷启动还有系统冷启动,常用的冷启动方法如:
-
提供热门及多样性内容推荐。即使用统计的方法将最热门的物品进行推荐,越热门且品类丰富的内容被点击的可能性越大; -
利用新用户基本信息关联到相关内容(利用领域、职位、工作年龄、性别和所在地等信息给用户推荐感兴趣或者相关的内容,如年龄-关联电影表、收入-关联商品类型表,性别-文章关联表等等); -
利用新物品的内容关联到相似物品,并对应相关用户。
三、推荐系统的相关技术
纵观推荐技术的发展史,简单来说就是特征工程自动化的过程,从人工设计特征+LR,到模型实现自动特征交互:如基于LR的自动特征交互组合的因式分解机FM及FFM 以及 GBDT树特征+LR ,到自动提取高层次特征的深度学习模型(DNN)。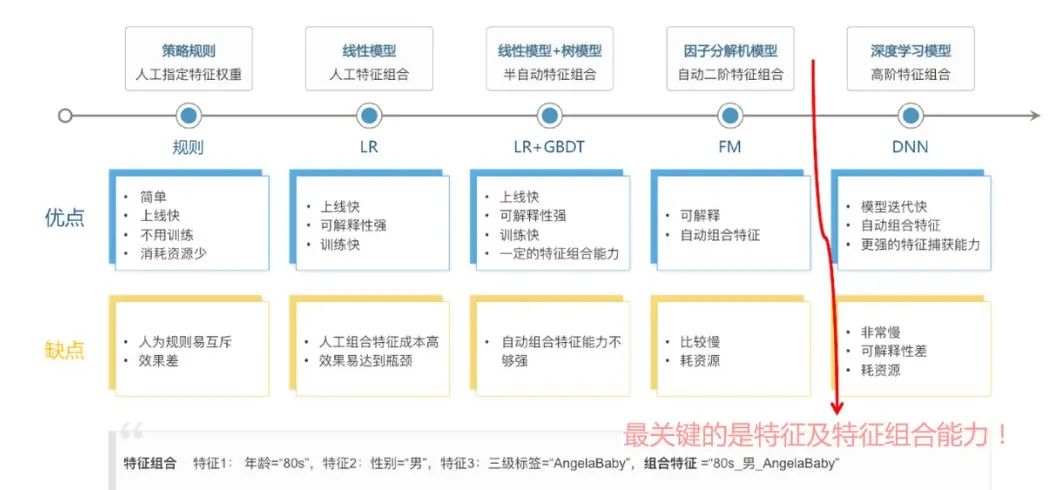
推荐系统整体技术栈可以分为传统机器学习推荐及深度学习推荐,而不同的推荐层偏好不同(复杂度、精确度)的模型或策略(图来源:王喆老师的专栏):
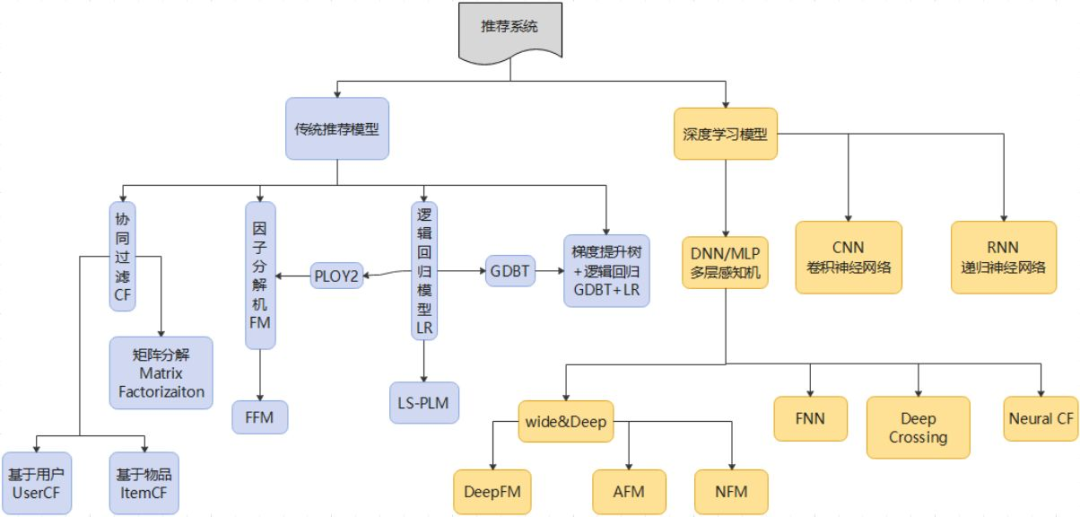
3.1 传统机器学习推荐模型
传统机器学习推荐可以简单划分为协同过滤算法及基于逻辑回归的序列算法: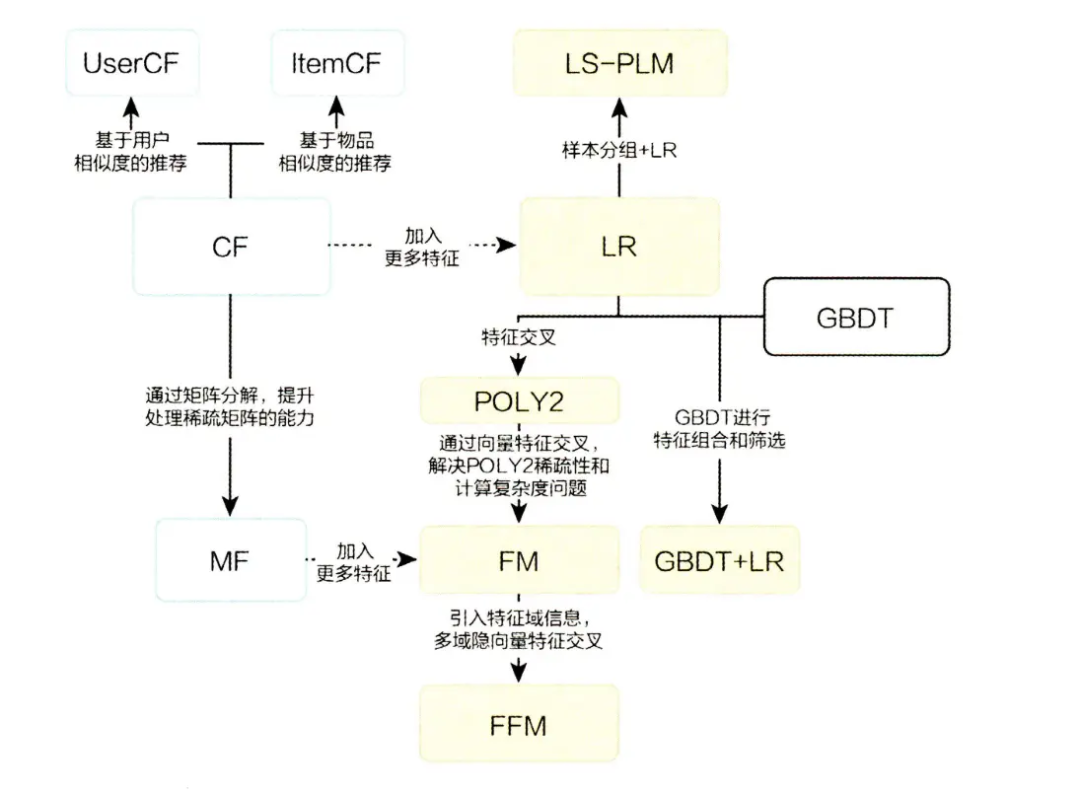
3.1.1 协同过滤的相关算法
协同过滤算法可以简单划分为基于用户/物品的方法:
-
基于用户的协同过滤算法(UserCF)
通过分析用户喜欢的物品,我们发现如果两个用户(用户A 和用户 B)喜欢过的物品差不多,则这两个用户相似。此时,我们可以将用户 A 喜欢过但是用户 B 没有看过的物品推荐给用户 B。基于用户的协同过滤算法(UserCF)的具体实现思路如下:
(1)计算用户之间的相似度;(2)根据用户的相似度,找到这个集合中用户未见过但是喜欢的物品(即目标用户兴趣相似的用户有过的行为)进行推荐。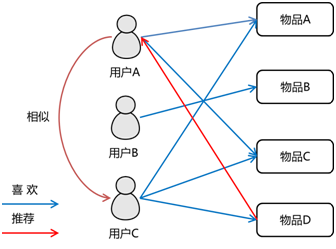
-
基于物品的协同过滤算法(ItemCF)
通过分析用户喜欢的物品,我们发现如果两个物品被一拨人喜欢,则这两个物品相似。此时,我们就会将用户喜欢相似物品中某个大概率物品推荐给这群用户。基于物品的协同过滤算法的具体实现思路如下:
(1)计算物品之间的相似度;(2)就可以推荐给目标用户没有评价过的相似物品。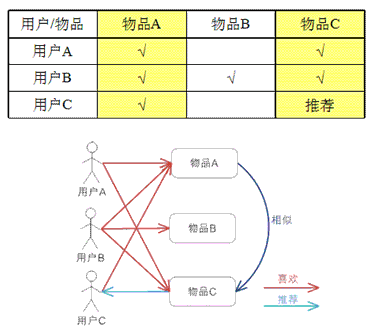
-
矩阵分解法
对于协同过滤算法,它本质上是一个矩阵填充问题,可以直接通过相似度计算(如基于用户的相似、基于物品的相似等)去解决。但有一问题是现实中的共现矩阵中有绝大部分的评分是空白的,由于数据稀疏,因此在计算相似度的时候效果就会大打折扣。这里我们可以借助矩阵分解方法,找到用户和物品的表征向量(K个维度,超参数),通过对用户向量和物品向量的内积则是用户对物品的偏好度(预测评分)。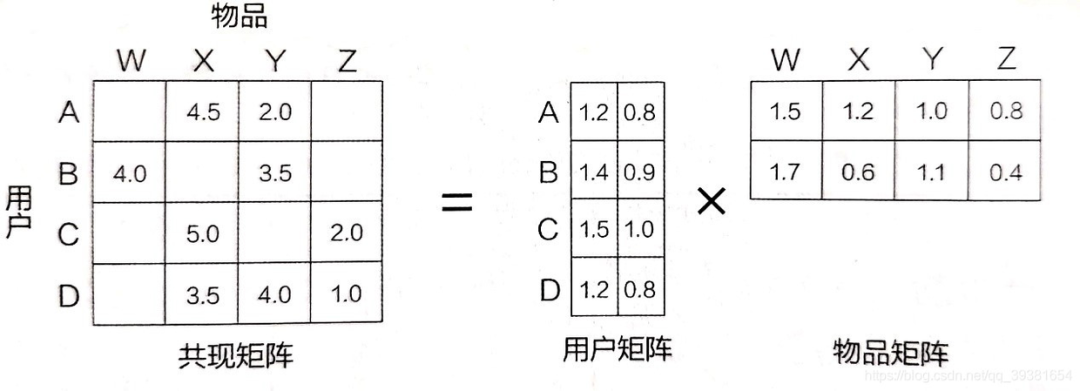
由于矩阵分解引入了隐因子的概念,模型解释性很弱。另外的,它只简单利用了用户对物品的打分(特征维度单一),很难融入更多的特征(比如用户信息及其他行为的特征,商品属性的特征等等)。而这些缺陷,下文介绍的逻辑回归的相关算法可以很好地弥补。
3.1.2 逻辑回归的相关算法
逻辑回归(LR)由于其简单高效、易于解释,是工业应用最为广泛的模型之一,比如用于金融风控领域的评分卡、互联网的推荐系统。它是一种广义线性的分类模型且其模型结构可以视为单层的神经网络,由一层输入层、一层仅带有一个sigmoid激活函数的神经元的输出层组成,而无隐藏层。
LR模型计算可以简化成两步,“通过模型权重[w]对输入特征[x]线性求和 ,然后sigmoid激活输出概率”。其中,sigmoid函数是一个s形的曲线,它的输出值在[0, 1]之间,在远离0的地方函数的值会很快接近0或1。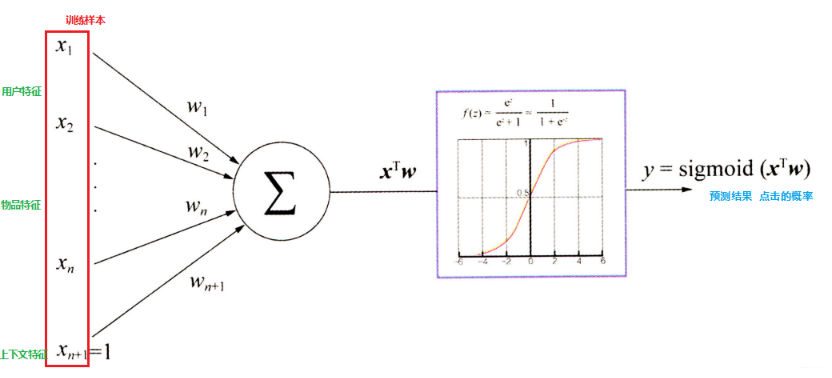
由于LR是线性模型,特征表达(特征交互)能力是不足的,为提高模型的能力,常用的有特征工程的方法或者基于模型的方法。
-
基于特征工程的优化

-
基于模型的优化
另外还可以基于模型的方法提升特征交互的能力。如POLY2、引入隐向量的因子分解机(FM)可以看做是LR的基础上,对所有特征进行了两两交叉,生成非线性的特征组合。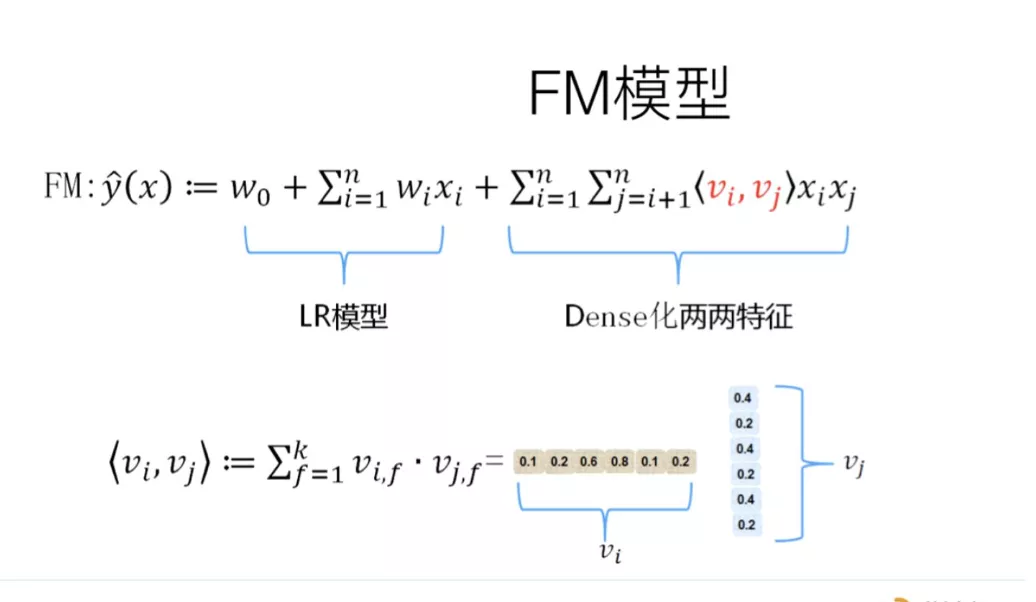
但FM等方法只能够做二阶的特征交叉,更高阶的,可以利用GBDT自动进行筛选特征并生成特征组合,也就是提取GBDT子树的特征划分及组合路径作为新的特征,再把该特征向量当作LR模型输入,也就是经典的GBDT +LR方法。(需要注意的,GBDT子树深度太深的化,特征组合层次比较高,极大提高LR模型拟合能力的同时,也容易引入一些噪声,导致模型过拟合)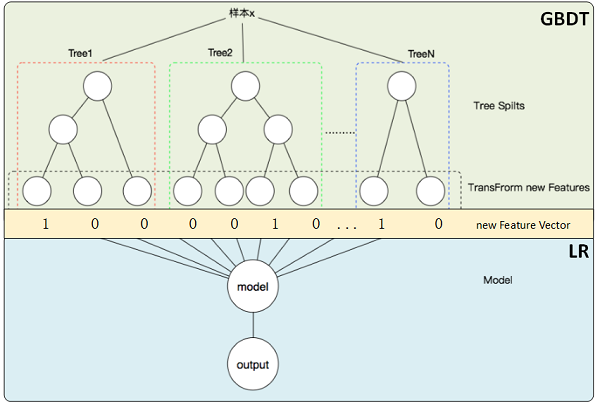
3.2 深度学习推荐模型
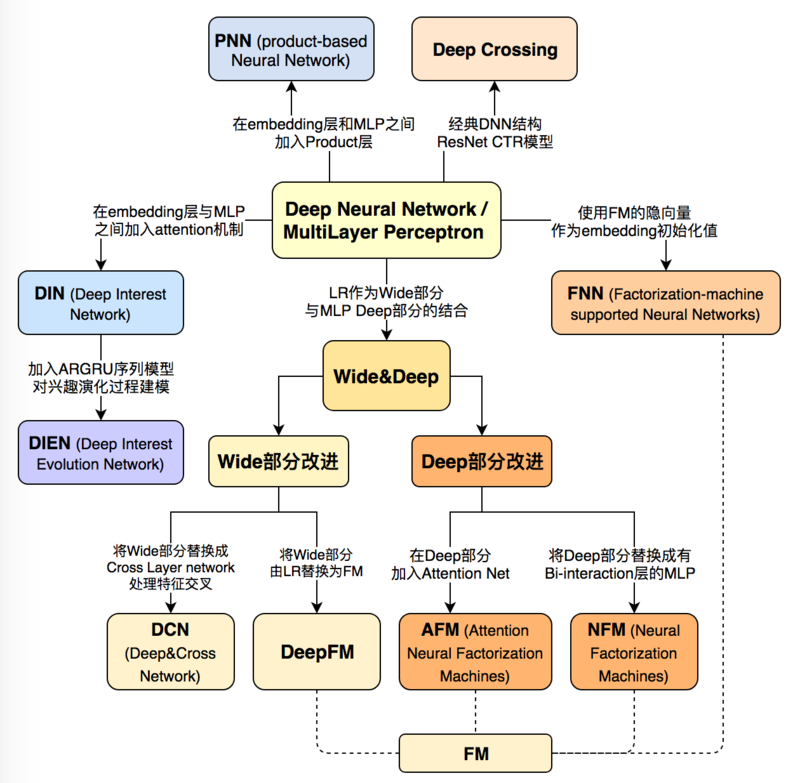
深度学习能够全自动从原有数据中提取到高层次的特征,深度学习推荐模型的进化趋势简单来说是 Wide(广)及 Deep(深)。Wide部分善于处理大量稀疏的特征,便于让模型直接“记住”大量原始的特征信息,Deep部分的主要作用有更深层的拟合能力,发现更高层次特征隐含的本质规律。
3.2.1 深度矩阵分解(双塔结构)
深度矩阵分解模型(Deep Matrix Factorization Model,DMF)是以传统的矩阵分解(MF)模型为基础,再与 MLP 网络组合而成的一种模型,其中 MF 主要负责线性部分,MLP 主要负责非线性部分,它主要以学习用户和物品的高阶表征向量为目标。
DMF 模型的框架图如下所示:该模型的输入层为交互矩阵 Y,其行、列分别对应为对用户和对物品的打分,并采用 multi-hot 形式分别表征用户和物品。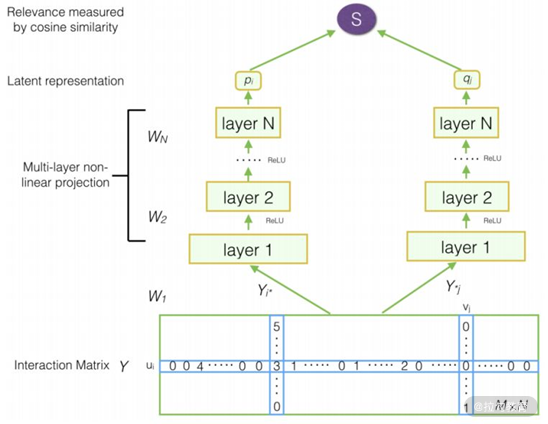 我们将用户表征 Yi* 和物品表征 Y*j 分别送入 MLP 双塔结构,生成用户隐向量表征 Pi 和物品隐向量表征 qj。最后对二者使用余弦点积匹配分数。
我们将用户表征 Yi* 和物品表征 Y*j 分别送入 MLP 双塔结构,生成用户隐向量表征 Pi 和物品隐向量表征 qj。最后对二者使用余弦点积匹配分数。
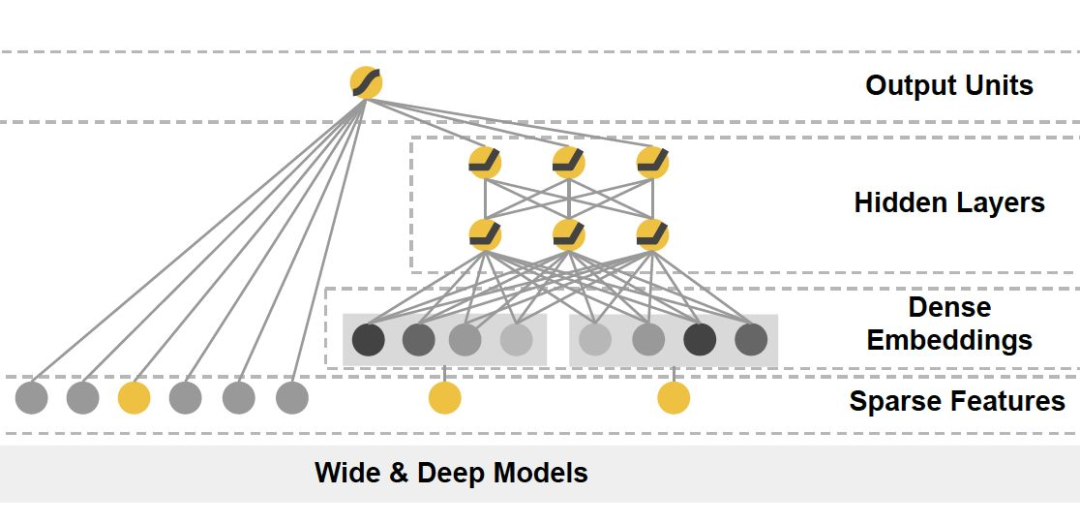
3.2.2 Wide&Deep
与其说广深(Wide&Deep)模型是一种模型,倒不如说是一套通用的范式框架。Wide&Deep 模型由 LR+MLP 两部分并联组成,综合了传统机器学习和深度学习的长处。
-
Wide 部分根据历史行为数据推荐与用户已有行为直接相关的物品;
-
Deep 部分负责捕捉新的特征组合,从而提高推荐的多样性。
3.2.3 深度因子分解机(DeepFM)模型
深度因子分解机(Deep Factorization Machine,DeepFM)模型是从广深(Wide&Deep)框架中演化出来的一种模型。它使用 FM 模型替换掉了 LR 部分,从而形成了 FM&Deep 结构。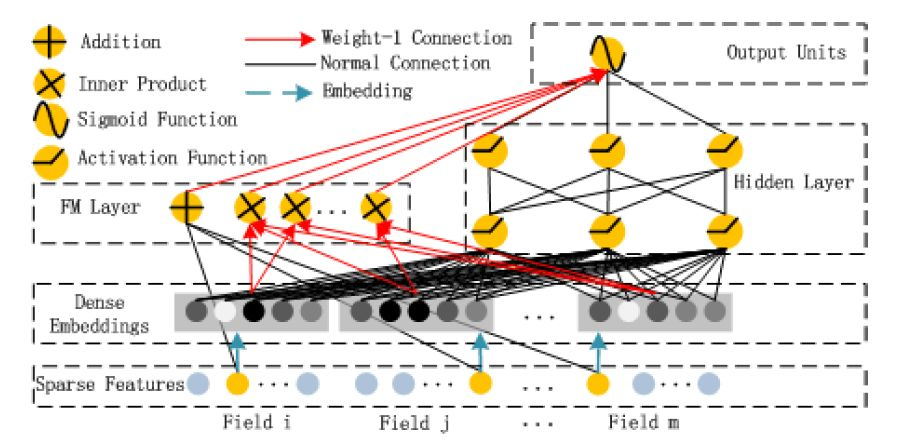
3.2.4 Deep&Cross
深度和交叉网络(Deep & Cross Network,DCN)模型是从广深(Wide&Deep)框架中演化出来的一个模型。DCN 模型将 Wide 部分替换为由特殊网络结构实现的特征交叉网络,它的框架如下图所示:左侧的交叉层除了接收前一层的输出外,还会同步接收原始输入层的特征,从而实现特征信息的高阶交叉。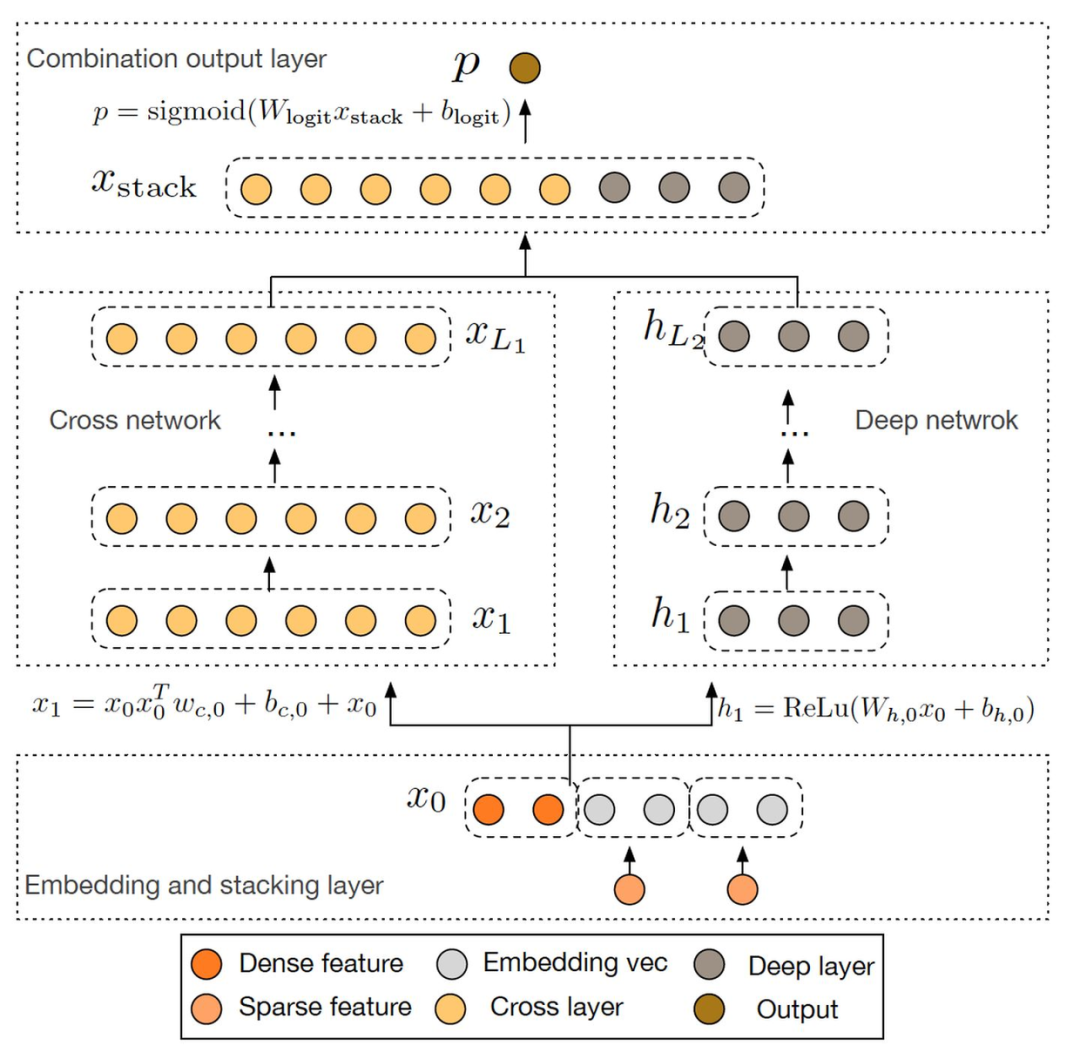
3.2.5 注意力因子分解机(AFM)
注意力因子分解机(Attentional Factorization Machine,AFM)模型也是Wide&Deep 框架中的一种,它通过添加 Attention 网络,自动学习不同特征之间交互的重要性。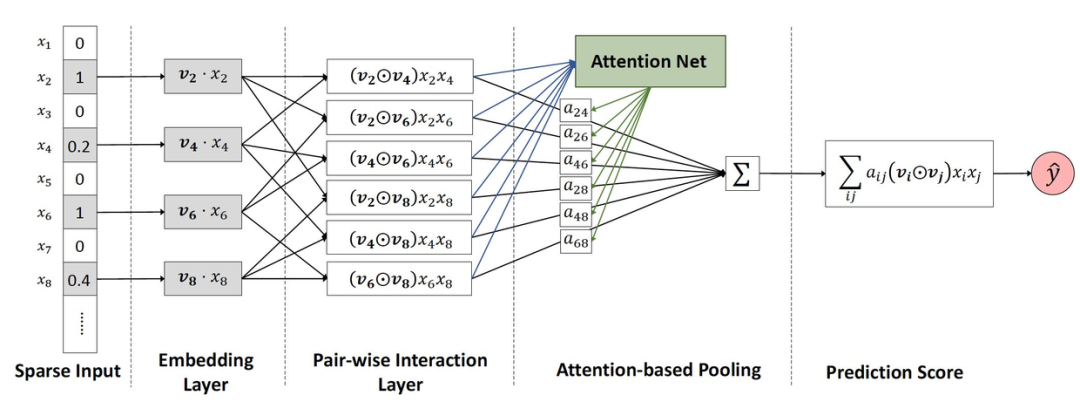
3.2.6 神经因子分解机(NFM)
神经因子分解机(Neural Factorization Machine)模型也是 Wide&Deep 框架中的一种。NFM 模型把 Wide 部分放到一边不做变化,Deep 部分在 FM 的基础上结合了 MLP 部分。其中,FM 部分能够提取二阶线性特征,MLP 部分能够提取高阶非线性特征,从而使模型具备捕捉高阶非线性特征的能力。
NFM 模型框架的 Deep 部分如下图所示,NFM 模型是在 Embedding 层后将 FM 的输出进行 Bi-Interaction Pooling 操作(将表征向量的两两元素相乘后,再将所有组合的结果进行求和),然后在后面接上 MLP。
参考文献:
https://zhuanlan.zhihu.com/p/100019681
https://zhuanlan.zhihu.com/p/63186101
https://zhuanlan.zhihu.com/p/61154299
- EOF -
觉得本文对你有帮助?请分享给更多人
推荐关注「Python开发者」,提升Python技能
点赞和在看就是最大的支持❤️

文章评论