点击上方“芋道源码”,选择“设为星标”
管她前浪,还是后浪?
能浪的浪,才是好浪!
每天 10:33 更新文章,每天掉亿点点头发...
源码精品专栏
-
介绍 -
为啥要分发数据?场景? -
双写? -
模式一:事务性发件箱(Transactional Outbox) -
Transactional Outbox参考实现 ~ Killbill Common Queue -
Reaper机制 -
Killbill PersistentBus表结构 -
Killbill PersistentBus处理状态迁移 -
模式二:变更数据捕获(Change Data Capture, CDC) -
CDC开源项目(企业级) -
学习参考 ~ Eventuate-Tram -
Transactional Outbox vs CDC -
Single Source of Truth -
结论
介绍
系统架构微服务化以后,根据微服务独立数据源的思想,每个微服务一般具有各自独立的数据源,但是不同微服务之间难免需要通过数据分发来共享一些数据,这个就是微服务的数据分发问题。Netflix/Airbnb等一线互联网公司的实践[参考附录1/2/3]表明,数据一致性分发能力,是构建松散耦合、可扩展和高性能的微服务架构的基础。
本文解释分布式微服务中的数据一致性分发问题,应用场景,并给出常见的解决方法。本文主要面向互联网分布式系统架构师和研发经理。
“
推荐下自己做的 Spring Boot 的实战项目:
https://github.com/YunaiV/ruoyi-vue-pro
为啥要分发数据?场景?
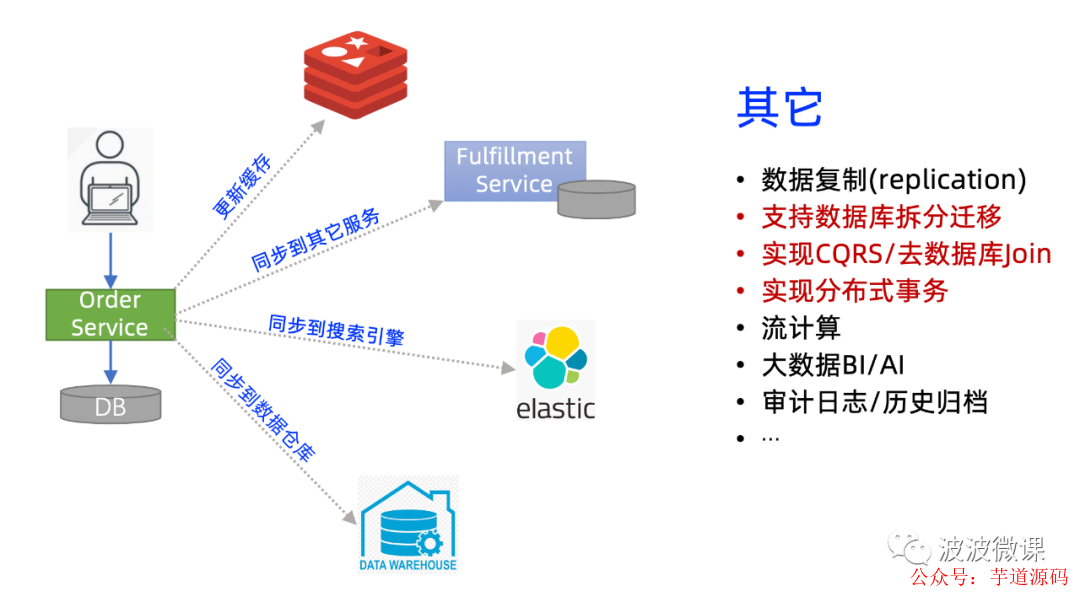
我们还是要从具体业务场景出发,为啥要分发数据?有哪些场景?在实际企业中,数据分发的场景其实是非常多的。假设某电商企业有这样一个订单服务Order Service,它有一个独立的数据库。同时,周边还有不少系统需要订单的数据,上图给出了一些例子:
-
一个是缓存系统,为了提升订单数据的访问性能,我们可以把频繁访问的订单数据,通过Redis缓存起来; -
第二个是Fulfillment Service,也就是订单履行系统,它也需要一份订单数据,借此实现订单履行的功能; -
第三个是ElasticSearch搜索引擎系统,它也需要一份订单数据,可以支持前台用户、或者是后台运营快速查询订单信息; -
第四个是传统数据仓库系统,它也需要一份订单数据,支持对订单数据的分析和挖掘。
当然,为了获得一份订单数据,这些系统可以定期去订单服务查询最新的数据,也就是拉模式,但是拉模式有两大问题:
-
一个是拉数据通常会有延迟,也就是说拉到的数据并不实时; -
如果频繁拉的话,考虑到外围系统众多(而且可能还会增加),势必会对订单数据库的性能造成影响,严重时还可能会把订单数据库给拉挂。
所以,当企业规模到了一定阶段,还是需要考虑数据分发技术,将业务数据同步分发到对数据感兴趣的其它服务。除了上面提到的一些数据分发场景,其实还有很多其它场景,例如:
-
第一个是数据复制(replication)。为了实现高可用,一般要将数据复制多分存储,这个时候需要采用数据分发。 -
第二个是支持数据库的解耦拆分。在单体数据库解耦拆分的过程中,为了实现不停机拆分,在一段时间内,需要将遗留老数据同步复制到新的数据存储,这个时候也需要数据分发技术。 -
第三个是实现CQRS,还有去数据库Join。这两个场景我后面有单独文章解释,这边先说明一下,实现CQRS和数据库去Join的底层技术,其实也是数据分发。 -
第四个是实现分布式事务。这个场景我后面也有单独文章讲解,这边先说明一下,解决分布式事务问题的一些方案,底层也是依赖于数据分发技术的。 -
其它还有流式计算、大数据BI/AI,还有审计日志和历史数据归档等场景,一般都离不开数据分发技术。
总之,波波认为,数据分发,是构建现代大规模分布式系统、微服务架构和异步事件驱动架构的底层基础技术。
“
推荐下自己做的 Spring Cloud 的实战项目:
https://github.com/YunaiV/onemall
双写?
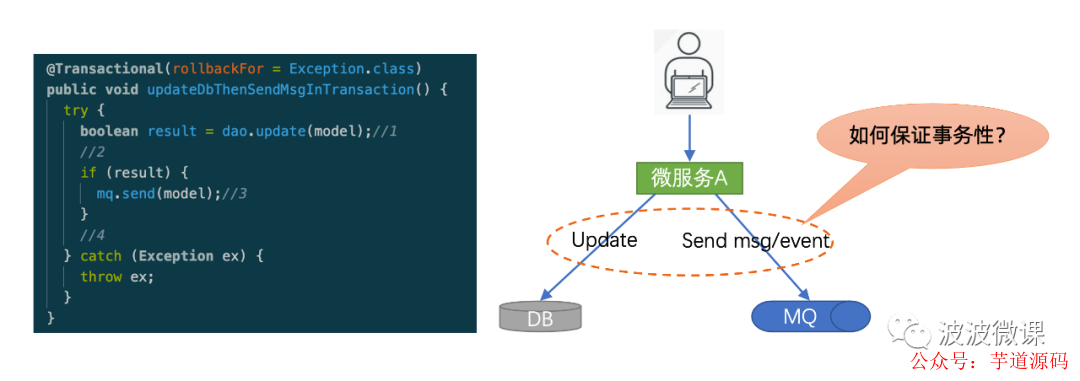
对于数据分发这个问题,乍一看,好像并不复杂,稍有开发经验的同学会说,我在应用层做一个双写不就可以了吗?比方说,请看上图右边,这里有一个微服务A,它需要把数据写入DB,同时还要把数据写到MQ,对于这个需求,我在A服务中弄一个双写,不就搞定了吗?其实这个问题并没有那么简单,关键是你如何才能保证双写的事务性?
请看上图左边的代码,这里有一个方法updateDbThenSendMsgInTransaction ,这个方法上加了事务性标注,也就是说,如果抛异常的话,数据库操作会回滚。我们来看这个方法的执行步骤:
第一步先更新数据库,如果更新成功,那么result设为true,如果更新失败,那么result设为false;
第二步,如果result为true,也就是说DB更新成功,那么我们就继续做第三步,向mq发送消息
如果发消息也成功,那么我们的流程就走到第四步,整个双写事务就成功了。
如果发消息抛异常,也就是发消息失败,那么容器会执行该方法的事务性回滚,上面的数据库更新操作也会回滚。
初看这个双写流程没有问题,可以保证事务性。但是深入研究会发现它其实是有问题的。比方说在第三步,如果发消息抛异常了,并不保证说发消息失败了,可能只是由于网络异常抖动而造成的抛异常,实际消息可能是已经发到MQ中,但是抛异常会造成上面数据库更新操作的回滚,结果造成两边数据不一致。
模式一:事务性发件箱(Transactional Outbox)
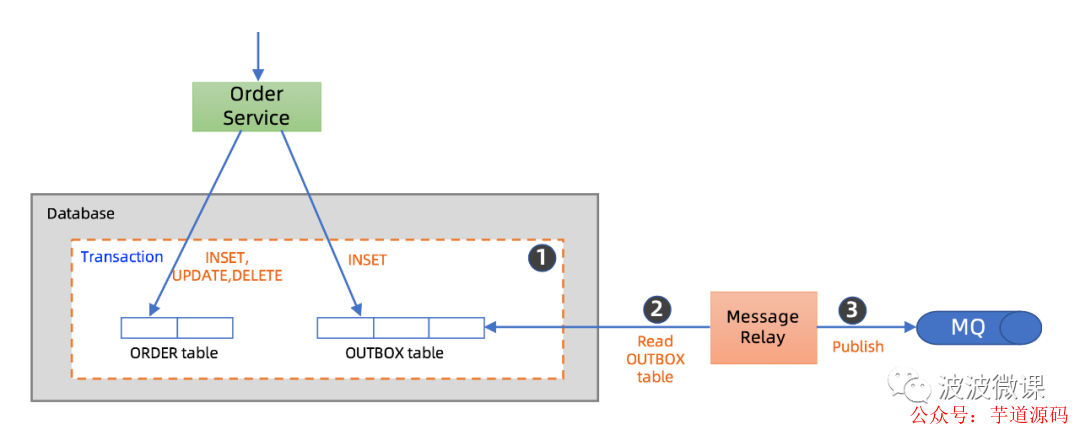
对于事务性双写这个问题,业界沉淀下来比较实践的做法,其中一种,就是采用所谓事务性发件箱模式,英文叫Transactional Outbox。据说这个模式是eBay最早发明和使用的。事务性发件箱模式不难理解,请看上图。
我们仍然以订单Order服务为例。在数据库中,除了订单Order表,为了实现事务性双写,我们还需增加了一个发件箱Outbox表。Order表和Outbox表都在同一个数据库中,对它们进行同时更新的话,通过数据库的事务机制,是可以实现事务性更新的。
下面我们通过例子来展示这个流程,我们这里假定Order Service要添加一个新订单。
首先第一步,Order Service先将新订单数据写入Order表,然后它再向Outbox表中写入一条订单新增记录,这两个DB操作可以包在一个DB事务里头,也就是可以实现事务性写入。
然后第二步,我们再引入一个称为消息中继Message Relay的角色,它负责定期Poll拉取Outbox中的新数据,然后第三步再Publish发送到MQ。如果写入MQ确认成功,Message Relay就可以将Outbox中的对应记录标记为已消费。这里可能会出现一种异常情况,就是Message Relay在将消息发送到MQ时,发生了网络抖动,实际消息可能已经写入MQ,但是Message Relay并没有得到确认,这时候它会重发,直到明确成功为止。所以,这里也是一个At Least Once,也就是至少交付一次的消费语义,消息可能被重复投递。因此,MQ之后的消费方要做消息去重或幂等处理。
总之,事务性发件箱模式可以保证,对Order表的修改,然后将对应事件发送到MQ,这两个动作可以实现事务性,也就是实现数据分发的事务性。
注意,这里的Message Relay角色既可以是一个独立部署的服务,也可以和Order Service住在一起。生产实践中,需要考虑Message Relay的高可用部署,还有监控和告警,否则如果Message Relay挂了,消息就发不出来,然后,依赖于消息的各种消费方也将无法正常工作。
Transactional Outbox参考实现 ~ Killbill Common Queue
事务性发件箱的原理简单,实现起来也不复杂,波波这边推荐一个生产级的参考实现。这个实现源于一个叫killbill的项目,killbill是美国高朋(GroupOn)公司开源的订阅计费和支付平台,这个项目已经有超过8~9年的历史,在高朋等公司已经有不少落地案例,是一个比较成熟的产品。killbill项目里头有一些公共库,单独放在一个叫killbill-commons的子项目里头,其中有一个叫killbill common queue,它其实是事务性发件箱的一个生产级实现。上图有给出这个queue的github链接。
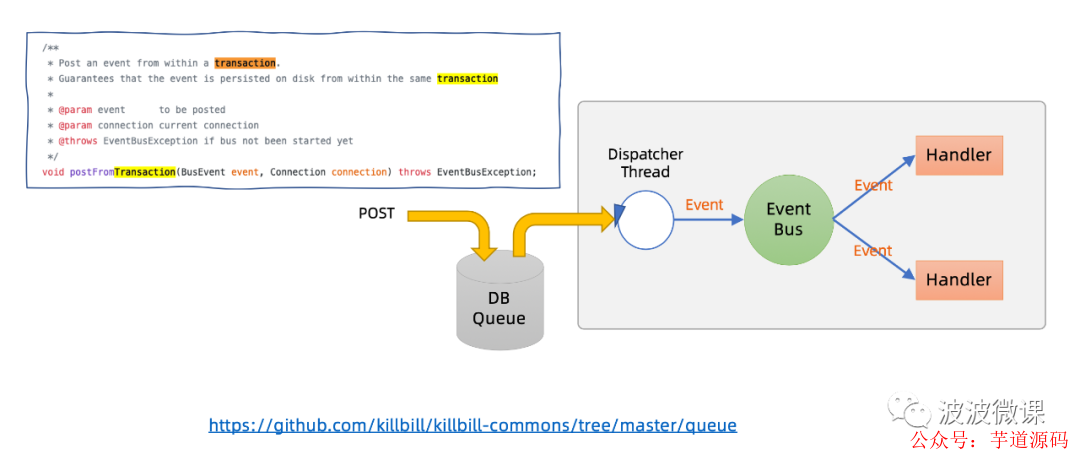
Killbill common queue也是一个基于DB实现的分布式的队列,它上层还包装了EventBus事件总线机制。killbill common queue的总体设计思路不难理解,请看上图:
在上图的左边,killbill common queue提供发送消息API,并且是支持事务的。比方说图上的postFromTransaction方法,它可以发送一个BusEvent事件到DB Queue当中,这个方法还接受一个数据库连接Connection参数,killbill common queue可以保证对事件event的数据库写入,和使用同一个Connection的其它数据库写入操作,发生在同一个事务中。这个做法其实就是一种事务性发件箱的实现,这里的发件箱存的就是事件event。
除了POST写入API,killbill common queue还支持类似前面提到的Message Relay的功能,并且是包装成EeventBus + Handler方式来实现的。开发者只需要实现事件处理器,并且注册订阅在EventBus上,就可以接收到DB Queue,也就是发件箱当中的新事件,并进行消费处理。如果事件处理成功,那么EvenbBus会将对应的事件从发件箱中移走;如果事件处理不成功,那么EventBus会负责重试,直到处理成功,或者超过最大重试次数,那么它会将该事件标记为处理失败,并移到历史归档表中,等待后续人工检查和干预。这个EventBus的底层,其实有一个Dispatcher派遣线程,它负责定期扫描DB Queue(也就是发件箱)中的新事件,有的话就批量拉取出来,并发送到内部EventBus的队列中,如果内部队列满了,那么Dispather Thread也会暂停拉取新事件。
在killbill common queue的设计中,每个节点上的Dispather线程只负责通过自己这个节点写入的事件,并且在一个节点上,Dispather线程也只有一个,这样才能保证消息消费的顺序性,并且也不会重复消费。
Reaper机制
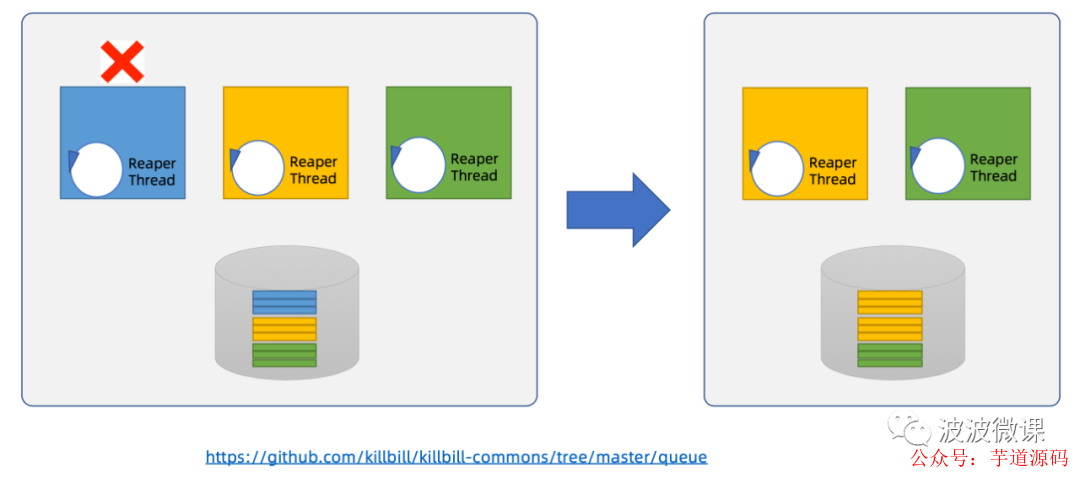
killbill common queue,其实是一个基于集中式数据库实现的分布式队列,为什么说它是分布式队列呢?请看上图,killbill common queue的设计是这样的,它的每个节点,只负责消费处理从自己这个节点写入的事件。比方说上图中有蓝色/黄色和绿色3个节点,那么蓝色节点,只负责从蓝色节点写入,在数据库中标记为蓝色的事件。同样,黄色节点,只负责从黄色节点写入,在数据库中标记为黄色的事件。绿色节点也是类似。这是一种分布式的设计,如果处理容量不够,只需按需添加更多节点,就可以实现负载分摊。
这里有个问题,如果其中某个节点挂了,比方说上图的蓝色节点挂了,那么谁来继续消费数据库中蓝色的,还没有来得及处理的事件呢?为了解决这个问题,killbill common queue设计了一种称为reaper收割机的机制。每个节点上都还住了一个收割机线程,它们会定期检查数据库,看有没有长时间无人处理的事件,如果有,就抢占标记为由自己负责。比方说上图的右边,最终黄色节点上的收割机线程抢到了原来由蓝色节点负责的事件,那么它会把这些事件标记为黄色,也就是由自己来负责。
收割机机制,保证了killbill common queue的高可用性,相当于保证了事务性发件箱中的Message Relay的高可用性。
Killbill PersistentBus表结构

基于killbill common queue的EventBus,也被称为killbill PersistentBus。上图给出了它的数据库表结构,其中bus_events就是用来存放待处理事件的,相当于发件箱,主要的字段包括:
-
event_json,存放json格式的原始数据。 -
creating_owner,记录创建节点,也就是事件是由哪个节点写入的。 -
processingowner,记录处理节点,也就是事件最终是由哪个节点处理的;通常由creatingowner自己处理,但也可能被收割,由其它节点处理。 -
processing_state,当前的处理状态。 -
error_count,处理错误计数,超过一定计数会被标记为处理失败。
当前处理状态主要包括6种:
-
AVAILABLE,表示待处理 -
IN_PROCESSING,表示已经被dispatcher线程取走,正在处理中 -
PROCESSED,表示已经处理 -
REMOVED,表示已经被删除 -
FAILED,表示处理失败 -
REPEATED,表示被其它节点收割了
除了bus_events待处理事件表,还有一个对应的bus-events-history事件历史记录表。不管成功还是失败,最终,事件会被写入历史记录表进行归档,作为事后审计或者人工干预的依据。
上图下方给出了数据库表的github链接,你可以进一步参考学习。
Killbill PersistentBus处理状态迁移
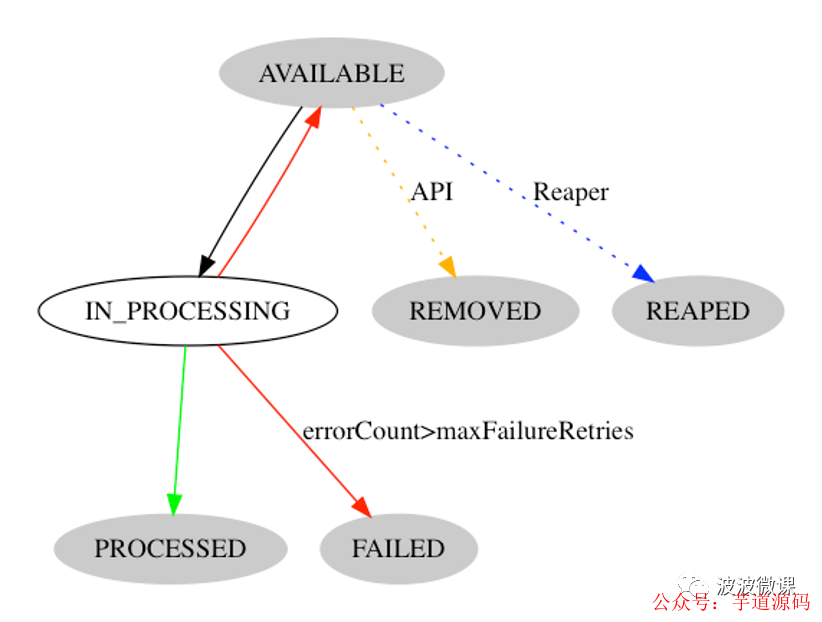
上图给出了killbill PersistentBus的事件处理状态迁移图。
-
刚开始事件处于AVAILABLE待处理状态; -
之后事件被dispatcher线程拉取,进入IN_PROCESSING处理中状态; -
之后,如果事件处理器成功处理了事件,那么事件就进入PROCESSED已经处理状态; -
如果事件处理器处理事件失败,那么事件的错误计数会被增加1,如果错误计数还没有超过最大失败重试阀值,那么事件就会重新进入AVAILABLE状态; -
如果事件的错误数量超过了最大失败重试阀值,那么事件就会进入FAILED失败状态; -
如果负责待处理事件的节点挂了,那么到达一定的时间间隔,对应的事件会被收割进入REAPED被收割状态。
上图有一个通过API触发进入的REMOVED移除状态,这个是给通知队列用的,用户可以通过API移除对应的通知消息。顺便提一下,除了事件/消息队列,Killbill queue也是支持通知队列(或者说延迟消息队列)的。
模式二:变更数据捕获(Change Data Capture, CDC)
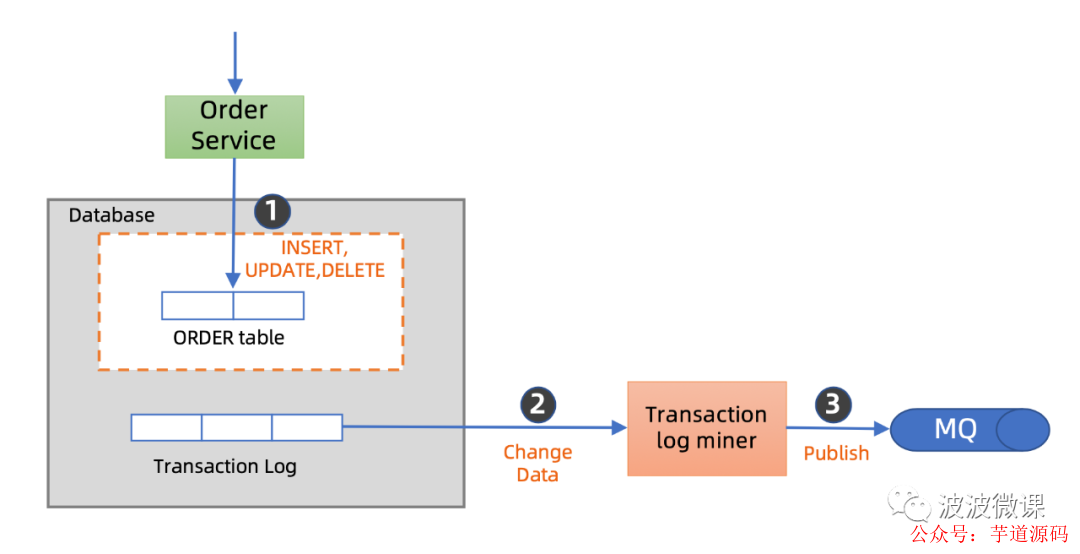
对于事务性双写这个问题,业界沉淀下来比较实践的做法,其中第二种,就是所谓的变更数据捕获,英文称为Change Data Capture,简称CDC。
变更数据捕获的原理也不复杂,它利用了数据库的事务日志记录。一般数据库,对于变更提交操作,都记录所谓事务日志Transaction Log,也称为提交日志Commit Log,比方说MySQL支持binlog,Postgres支持Write Ahead log。事务日志可以简单理解为数据库本地的一个文件队列,它记录了按时间顺序发生的对数据库表的变更提交记录。
下面我们通过例子来展示这个变更数据捕获的流程,我们这里假定Order Service要添加一个新订单。
第一步,Order Service将新订单记录写入Order表,并且提交。因为这是一次表变更操作,所以这次变更会被记录到数据库的事务日志当中,其中内容包括发生的变更数据。
第二步,我们还需要引入一个称为Transaction Log Miner这样的角色,这个Miner负责订阅在事务日志队列上,如果有新的变更记录,Miner就会捕获到变更记录。
然后第三步,Miner会将变更记录发送到MQ消息队列。同之前的Message Relay一样,这里的发送到MQ也是At Least Once语义,消息可能会被重复发送,所以MQ之后的消费者需要做去重或者幂等处理。
总之,CDC技术同样可以保证,对Order表的修改,然后将对应事件发送到MQ,这两个动作可以实现事务性,也就是实现数据分发的事务性。
注意,这里的CDC一般是一个独立部署的服务,生产中需要做好高可用部署,并且做好监控告警。否则如果CDC挂了,消息也就发不出来,然后,依赖于消息的各种消费方也将无法正常工作。
CDC开源项目(企业级)
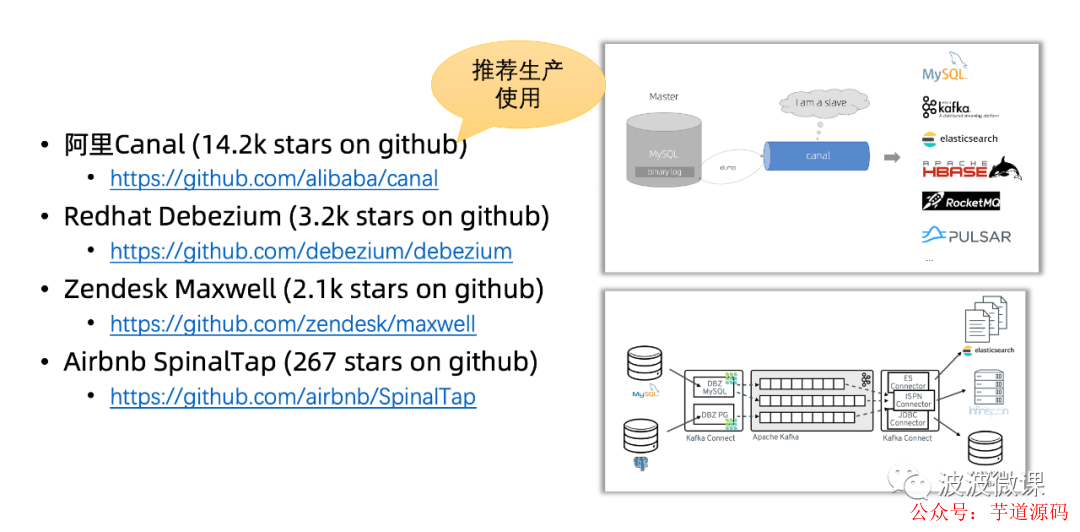
当前,有几个比较成熟的企业级的CDC开源项目,我这边收集了一些,供大家学习参考:
-
第一个是阿里开源的Canal,目前在github上有超过1.4万颗星,这个项目在国内用得比较多,之前在拍拍贷的实时数据场景,Canal也有不少成功的应用。Canal主要支持MySQL binlog的增量订阅和消费。它是基于MySQL的Master/Slave机制,它的Miner角色是通过伪装成Slave来实现的。这个项目的使用文档相对比较完善,建议大家一步参考学习。 -
第二个是Redhat开源的Debezium,目前在github上有超过3.2k星,这个项目在国外用得较多。Debezium主要是在Kafka Connect的基础上开发的,它不仅支持mysql数据库,还支持postgres/sqlserver/mongodb等数据库。 -
第三个是Zendesk开源的Maxwell,目前在github上有超过2.1k星。Maxwell是一个轻量级的CDC Deamon,主要支持MySQL binlog的变更数据捕获和处理。 -
第四个是Airbnb开源的SpinalTap,目前在github上有两百多颗星。SpinalTap主要支持MySQL binlog的变更捕获和处理。这个项目的星虽然不多,但是它是在Airbnb SOA服务化过程中,通过实践落地出来的一个项目,值得参考。
对于上面的这些项目,如果你想生产使用的话,波波推荐的是阿里的Canal,因为这个项目毕竟是国内大厂阿里落地出来,而且在国内已经有不少企业落地案例。其它几个项目,你也可以参考研究。
学习参考 ~ Eventuate-Tram
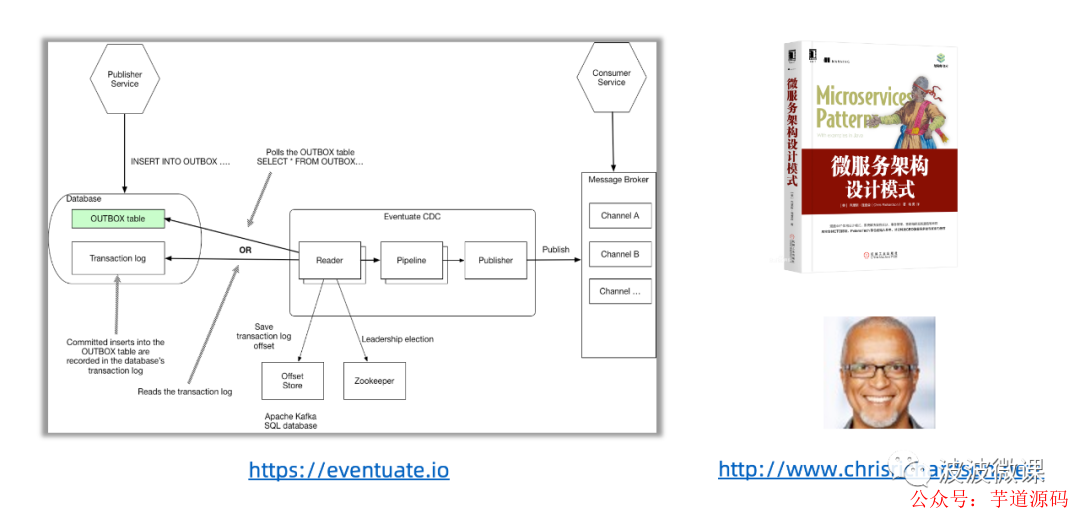
既然谈到这个CDC,这里有必要提到一个人和一本书,这个人叫Chris Chardson,他是美国的老一辈的技术大牛,曾今是第一代的Cloud Foundry项目的创始人(后来Cloud Foundry被Pivotal所收购)。近几年,Chris Chardson开始转战微服务领域,这两年,他还专门写了一本书,叫《微服务设计模式》,英文名是《Microservices Patterns》。这本书主要是讲微服务架构和设计模式的,内容还不错,是我推荐大家阅读的。
Charis Chardson还专门开发了一个叫Eventuate-Tram的开源项目(这个项目也有商业版),另外他的微服务书里头也详细介绍了这个项目。这个项目可以说是一个大集成框架,它不仅实现了DDD领域驱动开发模式,CQRS命令查询职责分离模式,事件溯源模式,还实现了Saga事务状态机模式。当然,这个项目的底层也实现了CDC变更数据捕获模式。
波波认为,Charis的项目,作为学习研究还是有价值的,但是暂不建议生产级使用,因为他的东西不是一线企业落地出来的,主要是他个人开发的。至于说Charis的项目能否在一线企业落地,还有待时间的进一步检验。
Transactional Outbox vs CDC
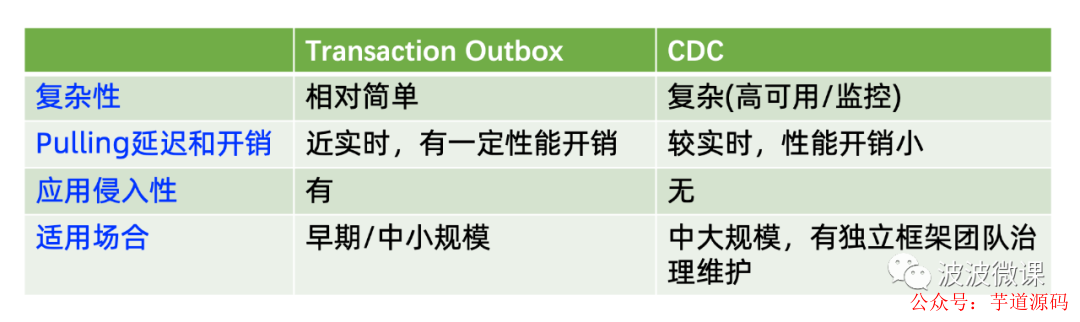
好的,前面我介绍了解决数据的事务性分发的两种落地模式,一种是事务性发件箱模式,另外一种是变更数据捕获模式,这两种模式其实各有优劣,为了帮助大家做选型决策,我这边对这两种模式进行一个比较,请看上面的比较表格:
-
首先比较一下复杂性,事务性发件箱相对比较简单,简单做法只需要在数据库中增加一个发件箱表,然后再启一个Poller线程拉消息和发消息就可以了。CDC技术相对比较复杂,需要你深入理解数据库的事务日志格式和协议。另外Miner的实现也不简单,要保证不丢消息,如果生产部署的话,还要考虑Miner的高可以部署,还有监控告警等环节。 -
第二个比较的是Polling延迟和开销。事务性发件箱的Polling是近实时的,同时如果频繁拉数据库表,难免会有性能开销。CDC是比较实时的,同时它不侵入数据库和表,所以它的性能开销相对小。 -
第三个比较的是应用侵入性。事务性发件箱是有一定的应用侵入性的,应用在更新业务数据的同时,还要单独发送消息。CDC对应用是无侵入的,因为它拉取的是数据库事务日志,这个和应用是不直接耦合的。当然,CDC和事务性发件箱模式并不排斥,你可以在应用层采用事务性发件箱模式,同时仍然采用CDC到数据库去捕获和发件箱中的消息对应的事务日志。这个方法对应用有一定的侵入性,但是通过CDC可以获得较好的数据同步性能。 -
第四点是适用场合。事务性发件箱主要适用于中小规模的企业,因为做法比较简单,一个开发人员也可以搞定。CDC则主要适用于中大规模互联网企业,最好有独立框架团队负责CDC的治理和维护。像Netflix/Airbnb这样的一线互联网公司,也是在中后期才引入CDC技术的[参考附录1/2/3]。
Single Source of Truth
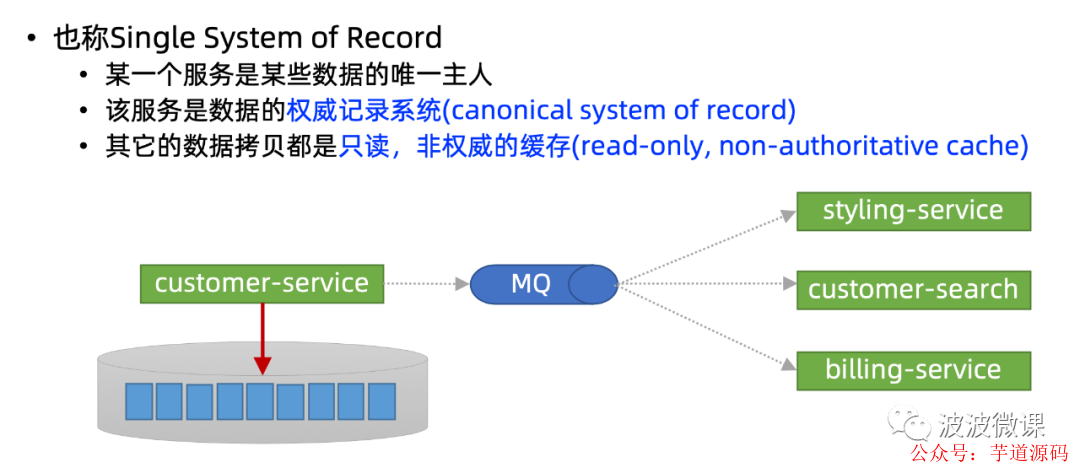
前面我解答了如何解决微服务的数据一致性分发问题,也给出了可落地的方案。最后,我特别说明在实践中进行数据分发的一个原则,叫Single Source of Truth,翻成中文就是单一真实数据源。它的意思是说,你要实现数据分发,目标服务可以有很多,但是一定要注意,数据的主人只能有一个,它是数据的权威记录系统(canonical system of record),其它的数据都是只读的,非权威的拷贝(read-only, non-authoritative copy)。
换句话说,任何时候,对于某类数据,它主人应该是唯一的,它是Single Source of Truth,只有它可以修改数据,其它的服务可以获得数据拷贝,做本地缓存也没问题,但是这些数据都是只读的,不能修改。
只有遵循这条原则,数据分发才能正常工作,不会产生不一致的情况。
结论
-
Netflix和Airbnb等一线互联网公司的实践证明,企业要真正实现松散耦合、可扩展和高性能的微服务架构,那么底层的数据分发同步能力是非常关键的。 -
数据分发技术,简单的可以采用事务性发件箱模式来实现,重量级的可以考虑变更数据捕获CDC技术来实现。事务性发件箱可以参考Killbill Queue的实现,CDC可以参考阿里的Canal等开源产品来实现。 -
最简单的双写也是实现数据分发的一种方式,但是为了保证一致性,需要引入后台校验补偿程序。 -
最后,数据分发/同步的原则是:确保单一真实数据源(Single Source of Truth)。系统中数据的主人应该只有一个,只有主人可以写入数据,其它都是只读拷贝。
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:

已在知识星球更新源码解析如下:




最近更新《芋道 SpringBoot 2.X 入门》系列,已经 101 余篇,覆盖了 MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 4W 行代码的电商微服务项目。
获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)

文章评论