func (watcher *PodWatcher) Watch() { startTime := time.Now()
watchPods := func(namespace string, k8s *kubernetes.Clientset) (watch.Interface, error) {return k8s.CoreV1().Pods(namespace).Watch(context.Background(), metav1.ListOptions{}) }
podWatcher, err := watchPods(watcher.Namespace, watcher.K8s)if err != nil { log.Errorf("watch pod of namespace %s failed, err:%s", watcher.Namespace, err) watcher.handelK8sErr(err) }
for { event, ok := <-podWatcher.ResultChan()
if !ok || event.Object == nil { log.Info("the channel or Watcher is closed") podWatcher, err = watchPods(watcher.Namespace, watcher.K8s)if err != nil { watcher.handelK8sErr(err) time.Sleep(time.Minute * 5) }continue }
// 忽略监控刚开始的1分钟的事件, 防止是事前挤压的事件传递过来
if time.Now().Before(startTime.Add(time.Second * 20)) {continue } pod, _ := event.Object.(*corev1.Pod)
for _, container := range pod.Status.ContainerStatuses {
if container.State.Terminated != nil || container.State.Waiting != nil{
if pod.ObjectMeta.DeletionTimestamp != nil { log.Warnf("the event is a deletion event. pod:%s namespace:%s, skip", pod.Name, pod.Namespace)continue } now = time.Now()
var isContinue = false
for _, o := range pod.OwnerReferences {if strings.Contains(o.Kind, "Job") || strings.Contains(o.Kind, "PodGroup"){// 如果处于Completed状态的POD是属于JOB的,那是正常结束if container.State.Terminated != nil {if container.State.Terminated.Reason == "Completed" { log.Debugf("Completed container is belong to job, skip. pod: %s", pod.Name) isContinue = true }if time.Now().After(container.State.Terminated.FinishedAt.Time.Add(time.Minute * 5)){ log.Debugf("当前pod属于一个job,并且容器在很久之前就已经处于Terminated状态, 怀疑是k8s重复发送的update事件,所以不予记录和告警, pod:%s, namespace:%s, terminatedTime:%s, nowTime:%s", pod.Name, pod.Namespace, container.State.Terminated.FinishedAt, time.Now()) isContinue = true } }if container.State.Waiting != nil {if time.Now().Before(pod.CreationTimestamp.Add(time.Minute * 5)) { log.Warnf("container Waiting in 5 minutes after pod creation, maybe need an init time. pod:%s namespace:%s, skip", pod.Name, pod.Namespace) isContinue = true } } }else {if time.Now().Before(pod.CreationTimestamp.Add(time.Minute * 5)) { log.Warnf("container terminated in 5 minutes after pod creation, maybe need an init time. pod:%s namespace:%s, skip", pod.Name, pod.Namespace) isContinue = true } } }if isContinue {continue }
var reason stringif container.State.Terminated != nil { reason = container.State.Terminated.Reason }else { reason = container.State.Waiting.Reason }
logger := log.WithFields(log.Fields{"pod_name": pod.Name,"container_name": container.Name,"reason": reason,"namespace": pod.Namespace, })var errorMessage stringif container.State.Terminated != nil {if container.State.Terminated.Message == "" { errorMessage = "容器异常退出,请查看日志内容" } else { errorMessage = container.State.Terminated.Message } }else{ errorMessage = container.State.Waiting.Message } logger.Infof("container is not ready, the event type is:%s, reason:%s, message:%s", event.Type, reason, errorMessage)
cLog, _ := watcher.getLog(container.Name, pod.Name)
e := &Event{ PodName: pod.Name, Namespace: watcher.Namespace, Reason: reason, Message: errorMessage, Error: nil, EventType: PodException, ErrorTimestamp: time.Now(), Log: cLog, }
// 获取pod所属的服务名称 serviceName, serviceType, err := watcher.parseServiceInfo(pod)if err != nil { log.Errorf("从pod获取对应的owner的类型失败, 错误信息:%s", err) } e.ServiceName = serviceName e.ServiceType = serviceType
for _, logData := range cLog {if strings.Contains(logData, "unable to retrieve container logs for docker") { log.Debugf("this pod is deleted manully, skip, pod:%s, log: %s", pod.Name, logData) isContinue = true } }if isContinue {continue }
watcher.event <- e } }//} }}
func (watcher *PodWatcher) checkBlackList(pod *corev1.Pod) (ok bool) { ok = falseif watcher.BlackList != nil {for _, v := range watcher.BlackList {if strings.Contains(pod.Name, v) { ok = truebreak } } }return}
func (watcher *PodWatcher) getLog(containerName string, podName string) (map[string]string, error) {// 抓取container日志 line := int64(1000) // 定义只抓取前1000行日志 opts := &corev1.PodLogOptions{ Container: containerName, TailLines: &line, } containerLog, err := watcher.K8s.CoreV1().Pods(watcher.Namespace).GetLogs(podName, opts).Stream(context.Background())if err != nil {return nil, err } clog := make(map[string]string) data, _ := ioutil.ReadAll(containerLog) clog[containerName] = string(data)return clog, nil}
func GetPodsResources(namespaces []string, startTime, endTime string) ([]*PodResourceInfo, error) { resultMap := make(map[string]*PodResourceInfo)
namespaceLabel := parseNamespaceLabel(namespaces)
var podCpuUsageResults *PromResultvar podCpuRequestResults *PromResultvar podCpuLimitResults *PromResult
var podMemoryUsageResults *PromResultvar podMemoryRequestResults *PromResultvar podMemoryLimitResults *PromResult
var podGpuUsageResults *PromResultvar podGpuMemoryResults *PromResult
wg := sync.WaitGroup{} wg.Add(8)
var err errorvar stepTime = "30"
// 开始收集POD CPU使用率go func() {defer wg.Done() podCpuUsageResults, err = getPromResult( fmt.Sprintf(`sum(irate(container_cpu_usage_seconds_total{container !="",container!="POD", namespace=~"%s"}[2m])) by (namespace, pod)`, namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD CPU Requestgo func() {defer wg.Done() podCpuRequestResults, err = getPromResult( fmt.Sprintf(`sum(container_cpu_cores_request{container !="",container!="POD", namespace=~"%s"}) by (namespace, pod)`, namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD CPU Limitgo func() {defer wg.Done() podCpuLimitResults, err = getPromResult( fmt.Sprintf(`sum(container_cpu_cores_limit{container !="",container!="POD", namespace=~"%s"}) by (namespace, pod)`, namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD memory 使用go func() {defer wg.Done() podMemoryUsageResults, err = getPromResult( fmt.Sprintf(`sum(container_memory_working_set_bytes{container !="",container!="POD", namespace=~"%s"}) by (namespace, pod)`, namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD memory requestgo func() {defer wg.Done() podMemoryRequestResults, err = getPromResult( fmt.Sprintf(`sum(container_memory_bytes_request{container !="",container!="POD", namespace=~"%s"}) by (namespace, pod)`, namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD memory limitgo func() {defer wg.Done() podMemoryLimitResults, err = getPromResult( fmt.Sprintf(`sum(container_memory_bytes_limit{container !="",container!="POD", namespace=~"%s"}) by (namespace, pod)`, namespaceLabel), queryRange, startTime, endTime,stepTime)
}()
// 开始收集POD GPU usagego func() {defer wg.Done() podGpuUsageResults, err = getPromResult(//sum(irate(container_cpu_usage_seconds_total{container !="",container!="POD", namespace=~"%s"}[2m])) by (namespace, pod)//max(container_gpu_utilization{container !="",container!="POD", namespace=~"%s"}) by (pod_name, container_name)/100 fmt.Sprintf(`max(container_gpu_utilization{namespace=~"%s"}) by (namespace, pod_name)/100`, namespaceLabel), queryRange, startTime, endTime,stepTime) }()
// 开始收集POD GPU memory usagego func() {defer wg.Done() podGpuMemoryResults, err = getPromResult(//sum(irate(container_cpu_usage_seconds_total{container !="",container!="POD", namespace=~"%s"}[2m])) by (namespace, pod)//max(container_gpu_memory_total{container !="",container!="POD", namespace=~"%s"}) by (pod_name, container_name) fmt.Sprintf(`max(container_gpu_memory_total{namespace=~"%s"}) by (namespace, pod_name)`, namespaceLabel), queryRange, startTime, endTime,stepTime) }()
wg.Wait()
if err != nil {return nil, errors.Cause(err) }
// 解析CPU使用率 parsePodResource(podCpuUsageResults, func(result *PodResourceInfo, maxValue, avgValue float64) { result.CpuMaxUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue), 64) result.CpuAvgUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", avgValue), 64) }, resultMap)
// 解析GPU使用率 parsePodResource(podGpuUsageResults, func(result *PodResourceInfo, maxValue, avgValue float64) { result.GpuMaxUtilization, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue), 64) result.GpuAvgUtilization, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", avgValue), 64) }, resultMap)
// 解析GPU Memory 使用 parsePodResource(podGpuMemoryResults, func(result *PodResourceInfo, maxValue, avgValue float64) { result.GpuMemoryMaxUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue), 64) result.GpuMemoryAvgUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", avgValue), 64) }, resultMap)
// 解析CPU Request parsePodResource(podCpuRequestResults, func(result *PodResourceInfo, maxValue, avgValue float64) { result.CpuRequest, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue), 64) }, resultMap)
// 解析CPU Limit parsePodResource(podCpuLimitResults, func(result *PodResourceInfo, maxValue, avgValue float64) { result.CpuLimit, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue), 64) }, resultMap)
// 解析memory usage parsePodResource(podMemoryUsageResults, func(result *PodResourceInfo, maxValue, avgValue float64) { result.MemoryMaxUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue/1000/1000), 64) result.MemoryAvgUsage, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", avgValue/1000/1000), 64) }, resultMap)
// 解析memory request parsePodResource(podMemoryRequestResults, func(result *PodResourceInfo, maxValue, avgValue float64) { result.MemoryRequest, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue/1000/1000), 64) }, resultMap)
// 解析memory limit parsePodResource(podMemoryLimitResults, func(result *PodResourceInfo, maxValue, avgValue float64) { result.MemoryLimit, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", maxValue/1000/1000), 64) }, resultMap)
return mapToPodSlice(resultMap), nil}

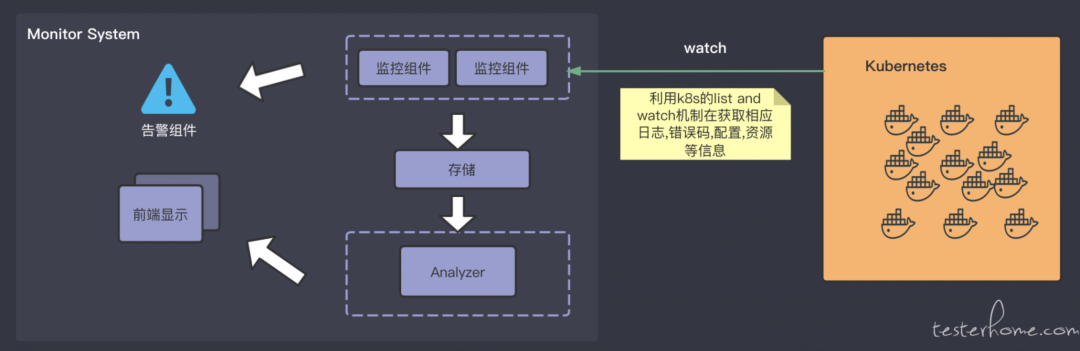
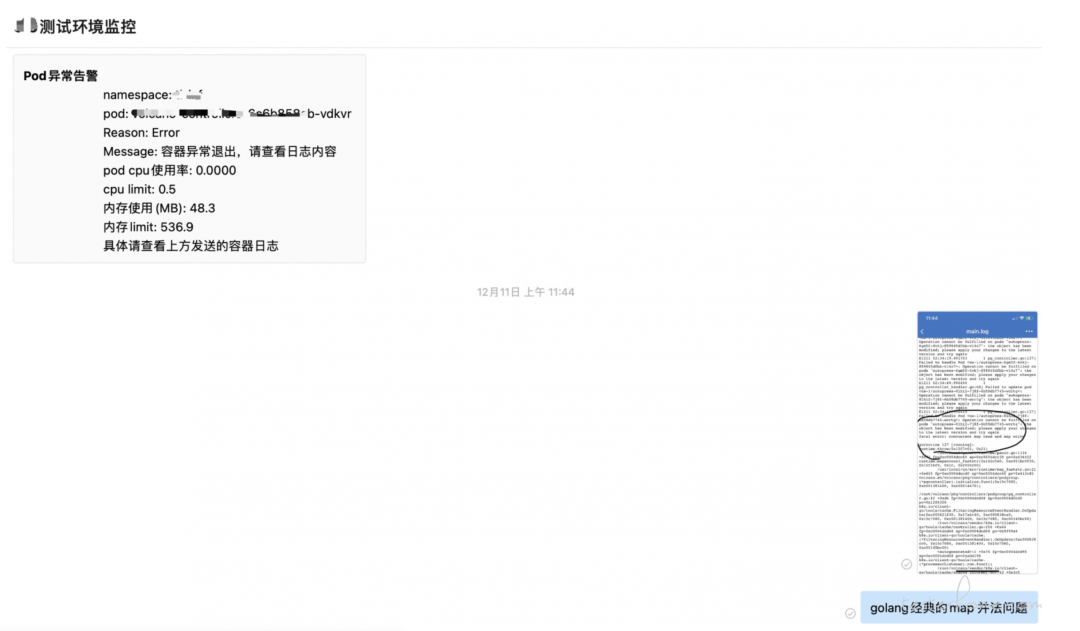
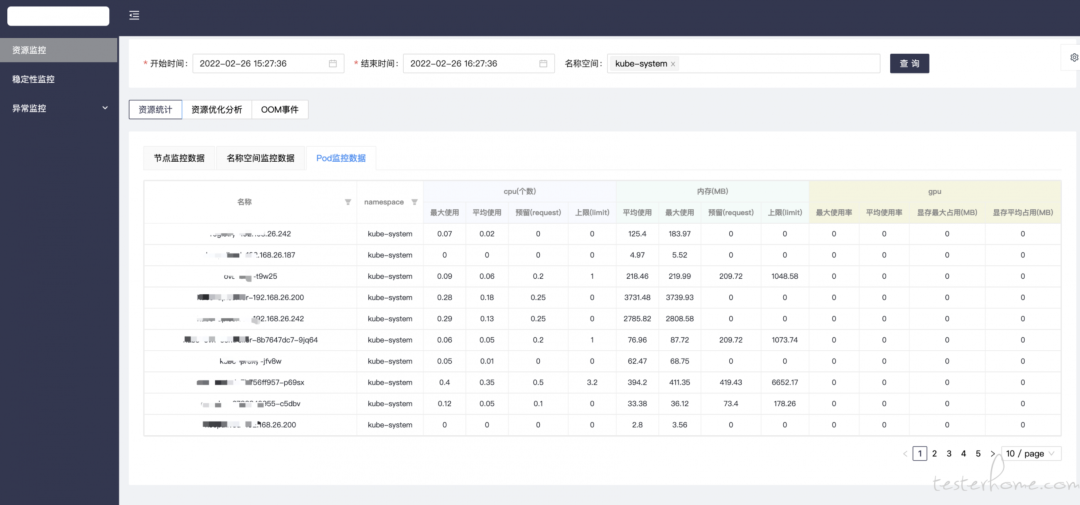
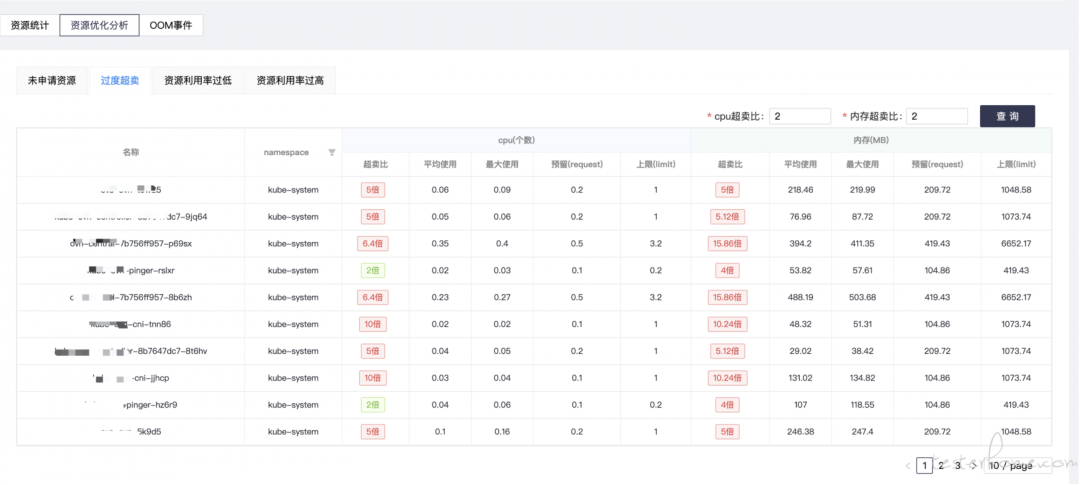


文章评论