
作者 | Tiferet Gazit
编译 | 张洁 责编 | 屠敏
一开始,安全人员都是通过人工查找危险函数代码的,但随着代码数量的增加,很难靠人工去查找并且覆盖所有的代码。这时候出现了一些检索工具(比如:rips和cobra)可以去帮助查找危险代码,但美中不足的是还需要人工去判断是否存在安全漏洞。
随着科技行业的发展,后面也慢慢出现了不少的自动化代码安全审核产品,如Checkmarx。但是这些都不是免费的,且价格昂贵。自从GitHub发布CodeQL以来,越来越多的安全人员用它来做代码安全评估工作。
CodeQL是一个免费的静态扫描代码工具,可以扫描发现代码库中的漏洞并提供相对应的改善方法。GitHub的代码扫描现在使用ML (机器学习) 来提醒开发人员注意其代码中的潜在安全漏洞。

抵御漏洞,预防为先
代码安全漏洞可能允许有恶意行为的人操纵软件并以有害的方式运行。防止此类攻击的最好方法就是在漏洞被利用之前检测并修复漏洞代码。GitHub的代码扫描功能利用CodeQL分析引擎来发现源代码中的安全漏洞,并在拉动请求中出现警报。
为了检测存储库中的漏洞,CodeQL引擎首先构建了一个数据库,该数据库对特殊的代码进行编码。安全员可以在该数据库上进行一系列的CodeQL查询,每次查询都是为了查找特定类型的安全问题。
许多漏洞都是由单一的重复模式引起的:用户数据未经过清理,随后以危险的方式使用。为了防止不安全的用户数据最终进入危险的位置,CodeQL查询封装了大量潜在用户数据源(例如,Web框架)以及潜在风险接收器。安全社区的成员与GitHub的安全专家一起,不断扩展和改进这些查询,对其他常见库和已知模式进行建模。然而,手动建模可能会很耗时,而且总会有很多不常见的库和私有代码,这时将无法手动建模。
研究人员使用人工模型来训练DL(深度学习)神经网络,该网络可以确定一个代码片段是否包含一个潜在的风险。因此,安全员可以发现安全漏洞,即使它们是由从未见过的库引起的。

训练集的建立,漏洞哪里“逃”
安全员需要训练ML模型来识别易受攻击的代码。虽然我们已经对一些没有监督的学习进行了实验,但不出所料,安全员发现有监督的学习效果更好。但这是有代价的!要求代码安全专家手动将数百万个代码片段标记为安全或易受攻击,这显然是不可能的。那么我们从哪里获取数据呢?
手动编写的CodeQL查询已经体现了编写和完善它们的安全专家的专业知识很扎实。安全员把这些手动查询标记示例,然后用于训练模型。此类查询检测到的每个接收器都用作训练集中的正例。由于绝大多数代码片段不包含漏洞,因此手动模型未检测到的片段可以视为反例。他们从十万多个公共存储库中提取数千万个片段,对它们进行CodeQL查询,并将每个片段标记为每个查询的正面或负面示例。这成为ML模型的训练集,可以将代码片段分类为易受攻击或非易受攻击型。
当然,安全员想要训练一个智能的模型来发现漏洞。实际上,安全员希望ML算法改进当前版本的手动查询,就像当前版本改进旧版本一样。为了看看是否可以做到这一点,安全员从检测到较少漏洞的旧版查询中构建了所有的训练数据。然后,将经过训练的模型应用到未经过训练的新存储库中。

更高级别的特征,由模型说了算
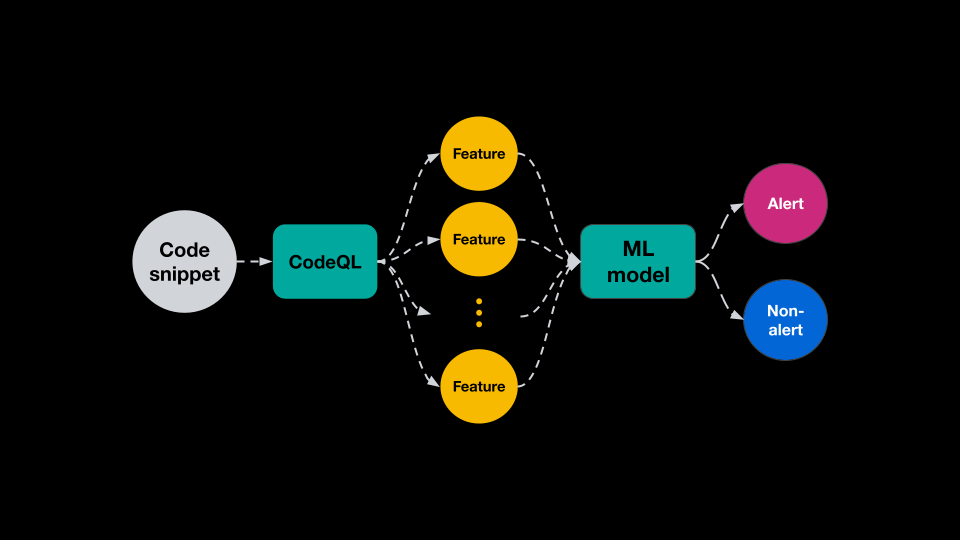
安全员为每个片段提取特征并训练DL模型对新示例进行分类。安全员利用CodeQL的强大功能来访问有关底层源代码的大量信息,并利用这些信息为每个代码片段创造高信息量的特征。
DL模型的主要优势之一是它们能够结合大量特征的信息来创建更高级别的特征。通过与GitHub的安全和编程语言专家合作,安全员使用CodeQL提取专家可能检查的信息来告知决策。然而,安全员可以开发一些未知的功能,或者在某些情况下可能有用但不是全部有用的功能,例如作为函数参数的代码片段的参数索引。这些特征可能包含人类看不到的模式,但神经网络可以检测到。因此,安全员会让ML模型决定是否使用这些,以及如何将它们结合起来为每个片段做出最佳决策。
一旦为每个示例提取特征,就会像NLP应用程序中通常所做的那样对它们进行标记和子标记,并进行一些修改以捕获特定于代码语法的特征。安全员从训练数据中生成一个词汇表,并将索引列表输入到一个相当简单的DL分类器中,其中包含几层特征处理,然后是跨特征连接和几层组合处理。
由于离线数据标记、特征提取和训练管道的规模,安全员利用云计算,包括用于模型训练的 GPU(图形处理器)。然而,在推理时,不需要GPU。

对存储库的测试:召回率约为80%,精确度约为60%
一旦拥有训练有素的ML模型,就会使用它来分类新的代码片段并检测每个查询可能存在的漏洞。当存储库所有者启用ML生成的警报时,CodeQL会计算该代码库中代码片段的源代码特征,并将它们提供给分类器模型。该框架获取给定代码片段代表漏洞的概率,并使用该概率来显示可能的新警报。
整个过程在GitHub Action运行器上运行,并且在大型存储库上增加一些运行时间,它对用户是透明的。代码扫描完成后,用户可以看到ML生成的警报以及手动查询出现的警报。在评估ML生成的警报时,安全员只考虑手动查询未标记的新警报。
为了大规模地测量指标,安全员使用上述实验设置,其中训练集中的标签是由手动查询的旧版本确定的。然后,在没有训练集的资源库上,安全员测试了该模型,并衡量其恢复的能力。衡量标准因查询而异,就平均而言,测量的召回率约为80%,精确度约为60%。
研究人员目前正在将ML生成的警报扩展到JavaScript和Typescript的安全查询,并努力提高它们的性能和运行时间。未来的计划包括扩展更多的编程语言,以及能够查找到更多的漏洞。
参考链接:https:// github.blog/2022-02-17-leveraging-machine-learning-find-security-vulnerabilities/
《新程序员001-004》全面上市,对话世界级大师,报道中国IT行业创新创造

《新程序员003》聚焦“云原生时代的开发者”与“全面数字化转型”两大主题,点击订阅

☞

文章评论