


-
延迟:服务请求的时间。
-
通讯量:监控当前系统的流量,用于衡量服务的容量需求。
-
错误:监控当前系统所有发生的错误请求,衡量当前系统错误发生的速率。
-
饱和度:衡量当前服务的饱和度。主要强调最能影响服务状态的受限制的资源。例如,如果系统主要受内存影响,那就主要关注系统的内存状态。
-
反映用户体验,衡量系统核心性能。如:在线系统的时延,作业计算系统的作业完成时间等。
-
反映系统的吞吐量。如:请求数,发出和接收的网络包大小等。
-
帮助发现和定位故障和问题。如:错误计数、调用失败率等。
-
反映系统的饱和度和负载。如:系统占用的内存、作业队列的长度等。 除了以上常规需求,还可根据具体的问题场景,为了排除和发现以前出现过或可能出现的问题,确定相应的测量对象。比如,系统需要经常调用的一个库的接口可能耗时较长,或偶有失败,可制定Metrics以测量这个接口的时延和失败数。
-
线上服务系统(Online-serving systems):需对请求做即时的响应,请求发起者会等待响应。如Web服务器。
-
线下计算系统(Offline processing):请求发起者不会等待响应,请求的作业通常会耗时较长。如批处理计算框架Spark等。
-
批处理作业(Batch jobs):这类应用通常为一次性的,不会一直运行,运行完成后便会结束运行。如数据分析的MapReduce作业。
-
线上服务系统:主要有请求、出错的数量,请求的时延等。
-
线下计算系统:最后开始处理作业的时间,目前正在处理作业的数量,发出了多少items,作业队列的长度等。
-
批处理作业:最后成功执行的时刻,每个主要stage的执行时间,总的耗时,处理的记录数量等。
-
使用的库(Libraries):调用次数,成功数,出错数,调用的时延。
-
日志(Logging):计数每一条写入的日志,从而可找到每条日志发生的频率和时间。
-
Failures:错误计数。
线程池:排队的请求数,正在使用的线程数,总线程数,耗时,正在处理的任务数等。
-
缓存:请求数,命中数,总时延等。
-
数据类型类似但资源类型、收集地点等不同
-
Vec内数据单位统一
-
不同资源对象的请求延迟
-
不同地域服务器的请求延迟
-
不同http请求错误的计数
-
……
-
resource
-
region
-
type
-
……
my_metric{label=a} 1 my_metric{label=b} 6 my_metric{label=total} 7
-
需要符合pattern: a-zA-Z*:*
-
应该包含一个单词作为前缀,表明这个Metric所属的域。如:
-
prometheus_notifications_total
-
process_cpu_seconds_total
-
ipamd_request_latency
-
应该包含一个单位的单位作为后缀,表明这个Metric的单位。如:
-
http_request_duration_seconds
-
node_memory_usage_bytes
-
http_requests_total(for a unit-less accumulating count)
-
逻辑上与被测量的变量含义相同。
-
尽量使用基本单位,如seconds,bytes。而不是Milliseconds,megabytes。
-
region:shenzhen/guangzhou/beijing
-
owner:user1/user2/user3
-
stage:extract/transform/load
-
需要知道数据的大致分布,若事先不知道可先用默认桶({.005, .01, .025, .05, .1, .25, .5, 1, 2.5, 5, 10})或2倍数桶({1,2,4,8...})观察数据分布再调整 buckets。
-
数据分布较密处桶间隔制定的较窄一些,分布稀疏处可制定的较宽一些。
-
对于多数时延数据,一般具有长尾的特性,较适宜用指数形式的桶(ExponentialBuckets)。
-
初始桶上界一般覆盖10%左右的数据,若不关注头部数据也可以让初始上界更大一些。
-
若为了更准确计算特定百分位数,如90%,可在90%的数据处加密分布桶,即减少桶的间隔。
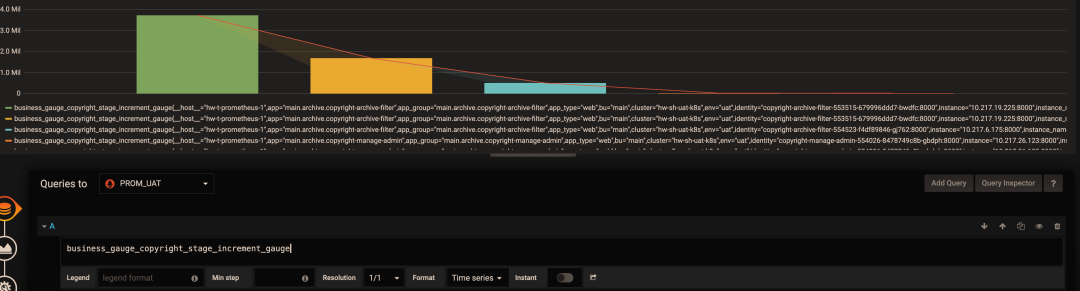
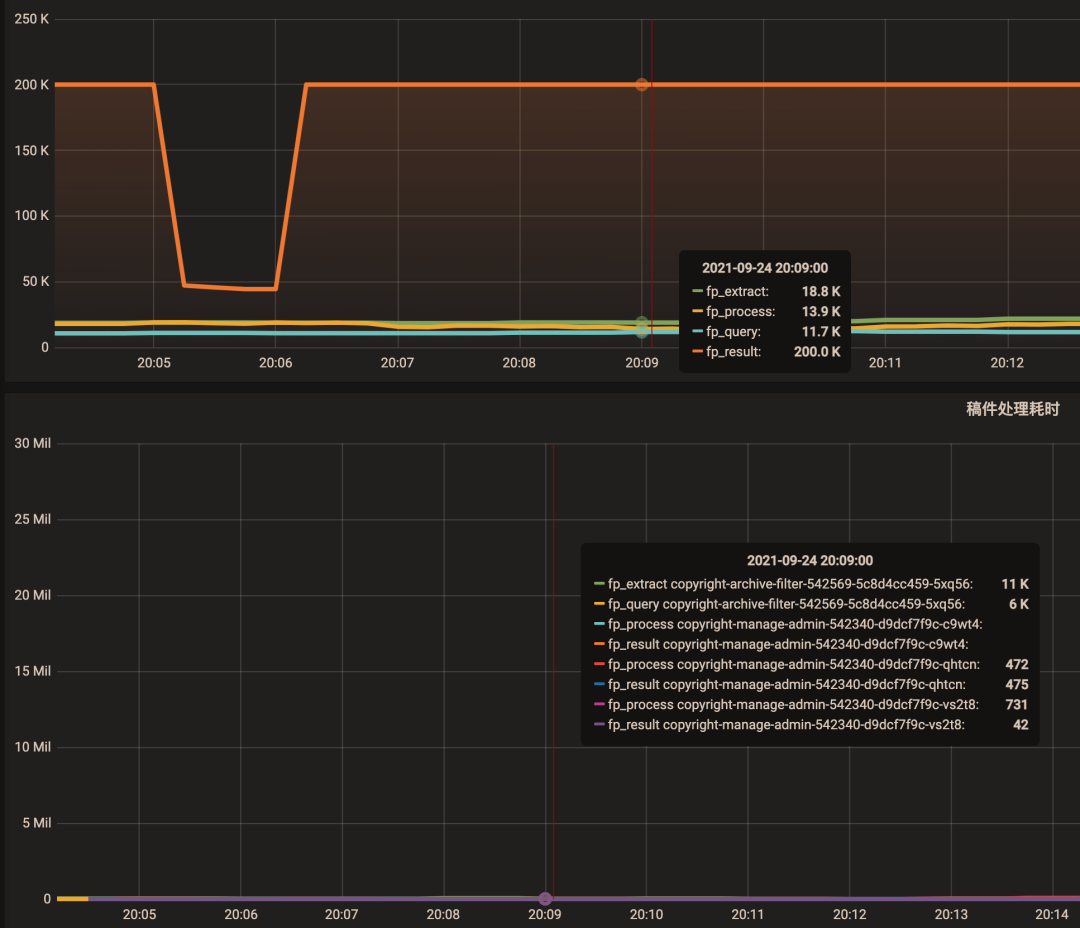

专场一览 ⬇️

近期好文:
Filebeat、Logstash、Rsyslog 各种姿势采集Nginx日志

文章评论