学习更多渗透技能!体验靶场实战练习

渗透视频教程 思路技巧 面试案例 渗透思维导图 练手靶场 联系小助理领取
作者:L0ading
转自博客地址:https://www.cnblogs.com/L0ading/p/13186891.html
0X00前言
好兄弟一直让我写一篇关于自动化扫描漏洞的文章,由于在公司实习没时间写一些文章,这段时间离职闲下来后,准备写一下教程。
PS:已经有很多大佬写过了,我这里只是更简单的写一下,以及记录一下我曾经踩过的坑。
0X01自动化原理
原理已经有很多大佬解释过了这里不再赘述,直接上图:
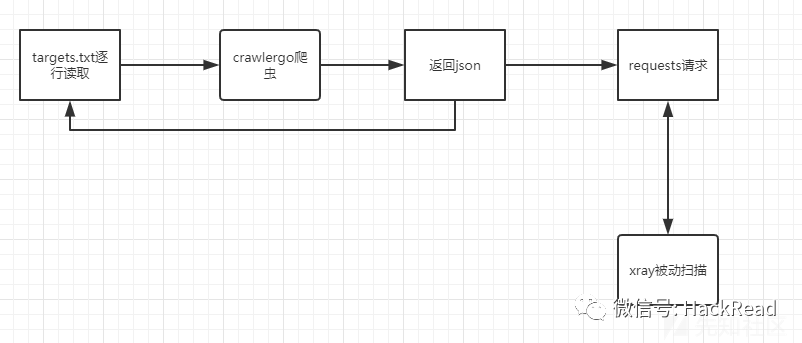
0X02开始搭建
由于我的阿里云服务器是买了一台win2008,因此以下教程都是基于windows的,
Xray:
xray 为单文件二进制文件,无依赖,也无需安装,下载后直接使用。
下载地址为:
Github: https://github.com/chaitin/xray/releases (国外速度快)
网盘: https://yunpan.360.cn/surl_y3Gu6cugi8u (国内速度快)
Xray的简单使用教程请参考:https://www.cnblogs.com/L0ading/p/12388898.html
360crawlergo
crawlergo是一个使用chrome headless模式进行URL入口收集的动态爬虫。
使用Golang语言开发,基于chromedp 进行一些定制化开发后操纵CDP协议,对整个页面关键点进行HOOK,灵活表单填充提交,完整的事件触发,尽可能的收集网站暴露出的入口。
同时,依靠智能URL去重模块,在过滤掉了大多数伪静态URL之后,仍然确保不遗漏关键入口链接,大幅减少重复任务。
下载地址为:
https://github.com/0Kee-Team/crawlergo
crawlergo 只依赖chrome运行即可:
新版本chromium下载地址:https://www.chromium.org/getting-involved/download-chromium
Linux下载地址:https://storage.googleapis.com/chromium-browser-snapshots/Linux_x64/706915/chrome-linux.zip
如果觉得分开配置比较麻烦,网上也有大佬直接放在一起的项目
下载链接:https://github.com/timwhitez/crawlergo_x_XRAY
下载好后是这样一个界面;
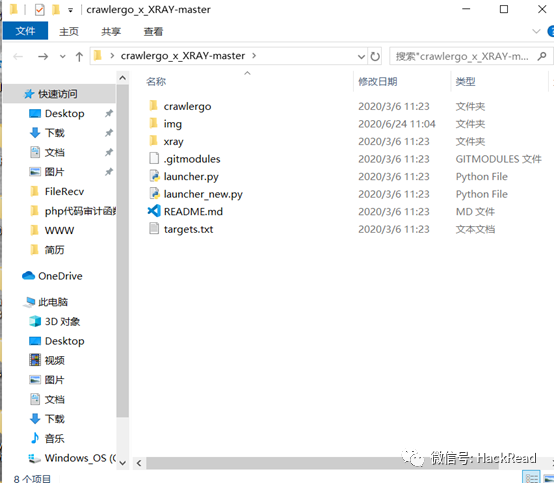
其中xray文件夹以及crawlergo文件夹都是空文件夹,目的是用来存放xray以及crawlergo
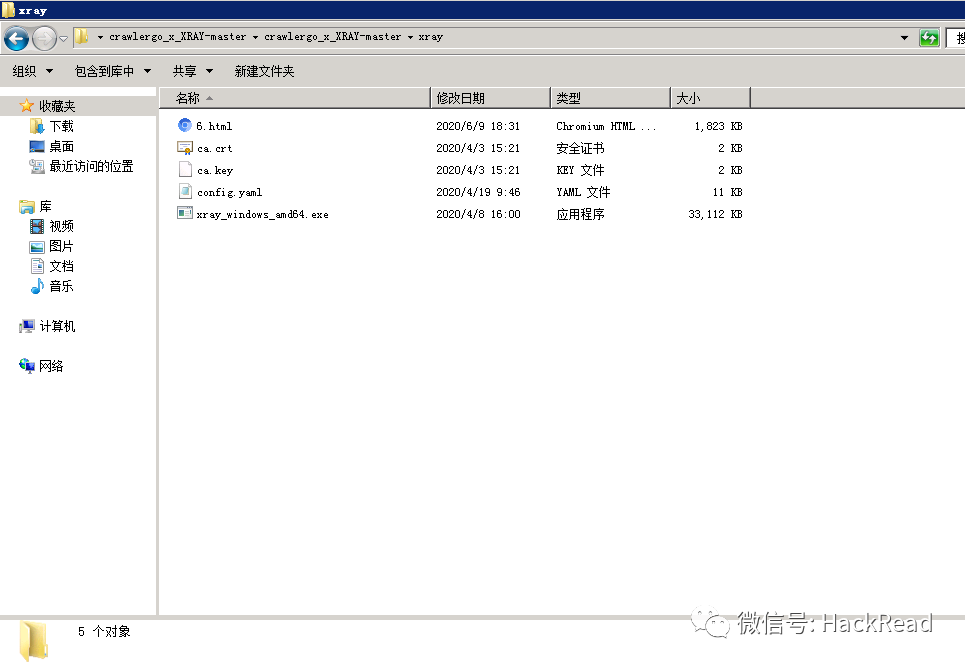
将最新版的xray放入xray文件夹中:
然后生成ca证书等一系列常规操作。
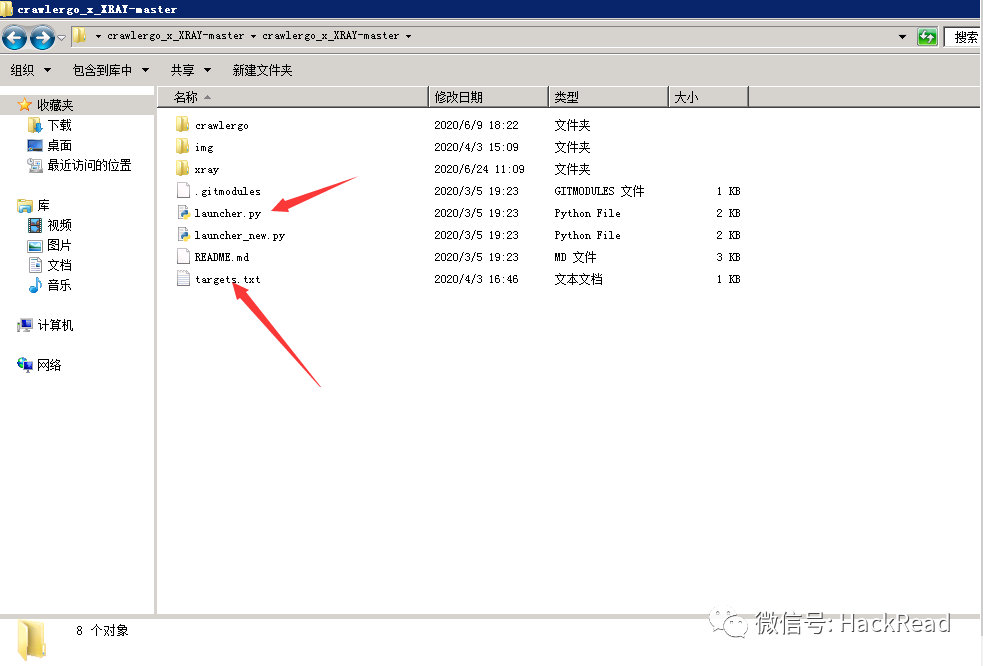
在crawlergo文件夹中放入下载好的最新的crawlergo.exe可执行文件,
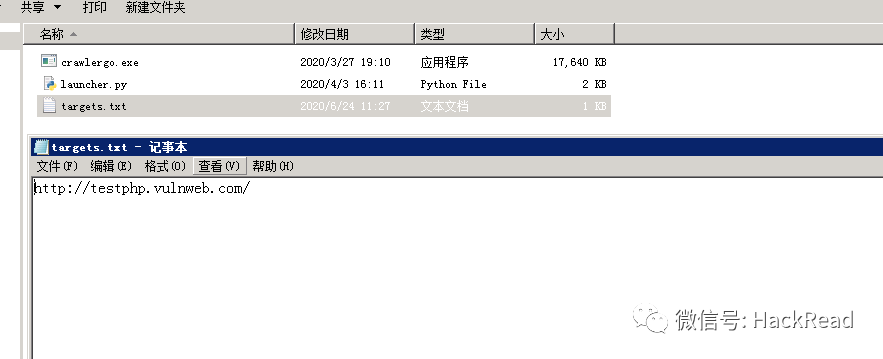
再将launcher.py以及target.txt放入crawlergo文件夹中
接下来便是踩坑环节
配置好launcher.py的cmd变量中的crawlergo爬虫配置(主要是chrome路径改为本地路径), 默认为:
./crawlergo -c C:\Program Files (x86)\Google\Chrome\Application\chrome.exe -t 20 -f smart --fuzz-path --output-mode json target
这个路径是你安装chrome的路径
比如我的chrome.exe在改文件夹下
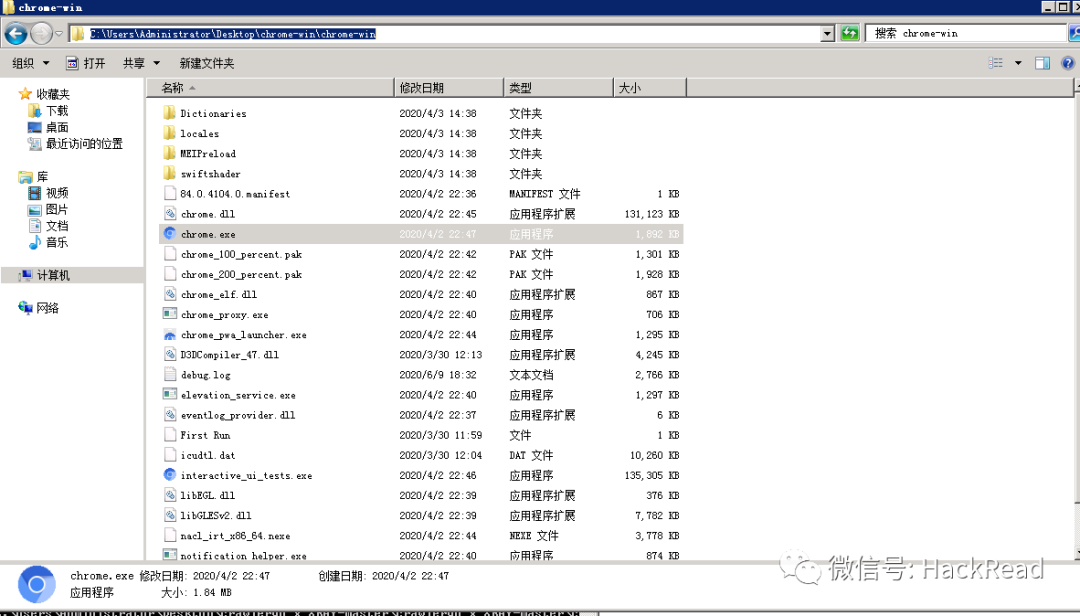
因此配置路径为
cmd = ["crawlergo.exe", "-c", "C:/Users/Administrator/Desktop/chrome-win/chrome-win/chrome.exe","-t", "20","-f","smart","--fuzz-path", "--output-mode", "json", target]
此处最需要注意的是在windows上复制文件路径后斜杠为\
我们需要将路径中的\改为/
同时我们还要配置地址和xray监听地址为一致
0X03开始被动扫描挖洞
1.将目标url一个一个写入crawlergo文件夹下的target.txt文件中。
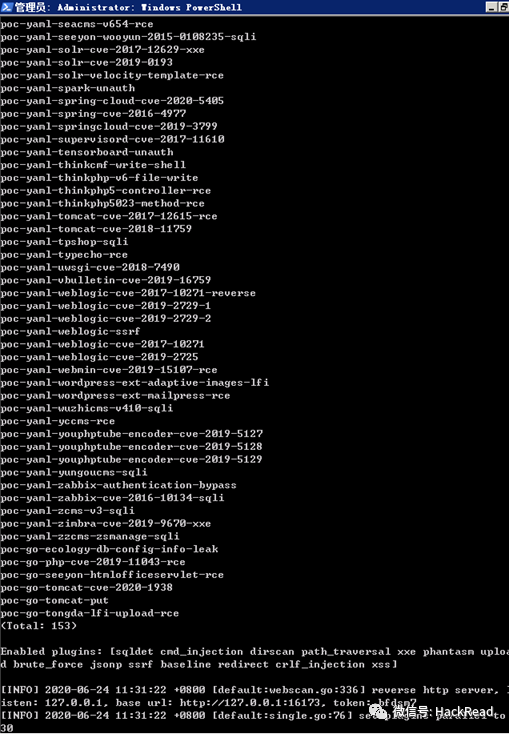
2.进入xray文件夹启动xray的被动监听状态
如:.\xray_windows_amd64.exe webscan --listen 127.0.0.1:7777 --html-output proxy.html
3. 进入crawlergo文件夹执行360爬虫进行爬取
我们在target.txt文件中写入awvs的测试站点http://testphp.vulnweb.com/
执行:python launcher.py
可以看到xray已经接收到流量并开始扫描出漏洞
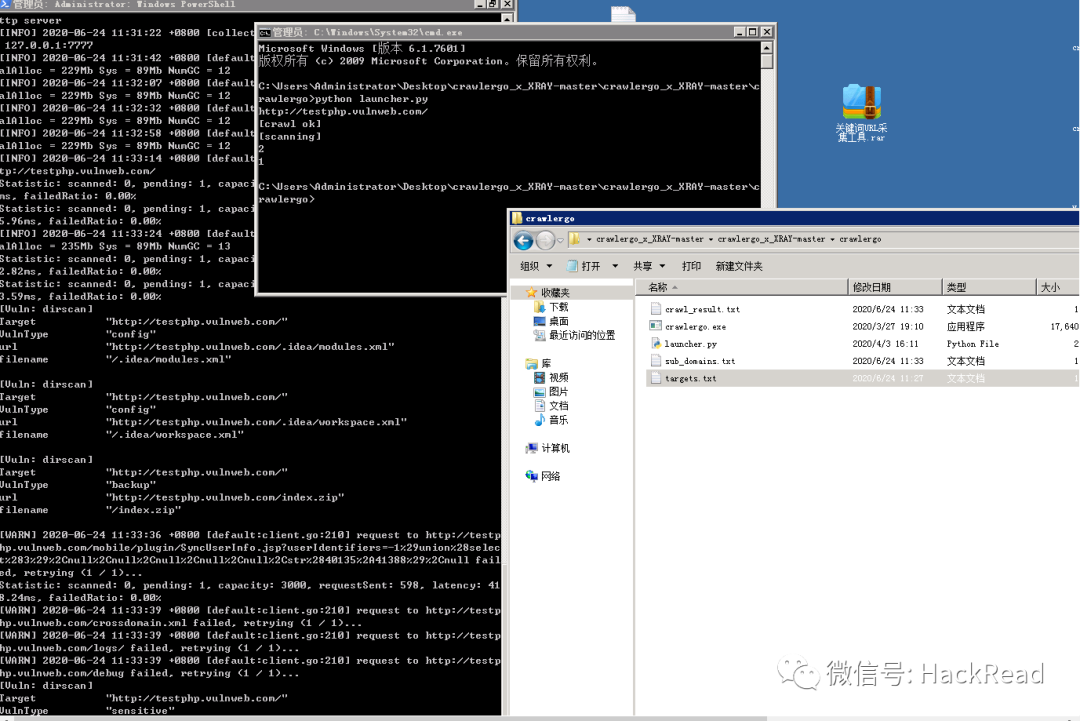
Crawlergo文件夹下多出来的文件
sub_domains.txt为爬虫爬到的子域名, crawl_result.txt为爬虫爬到的ur
进入xray文件夹下可以看到多出一个html文件,该文件为xray扫描结果
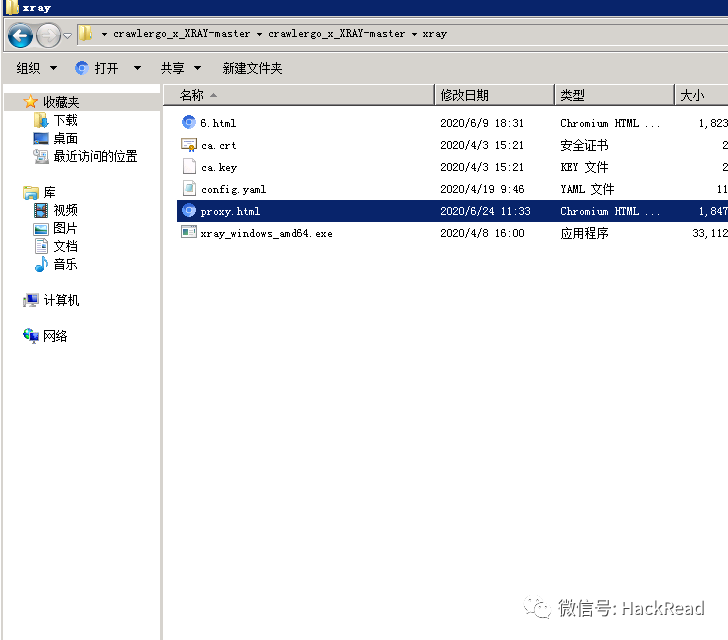
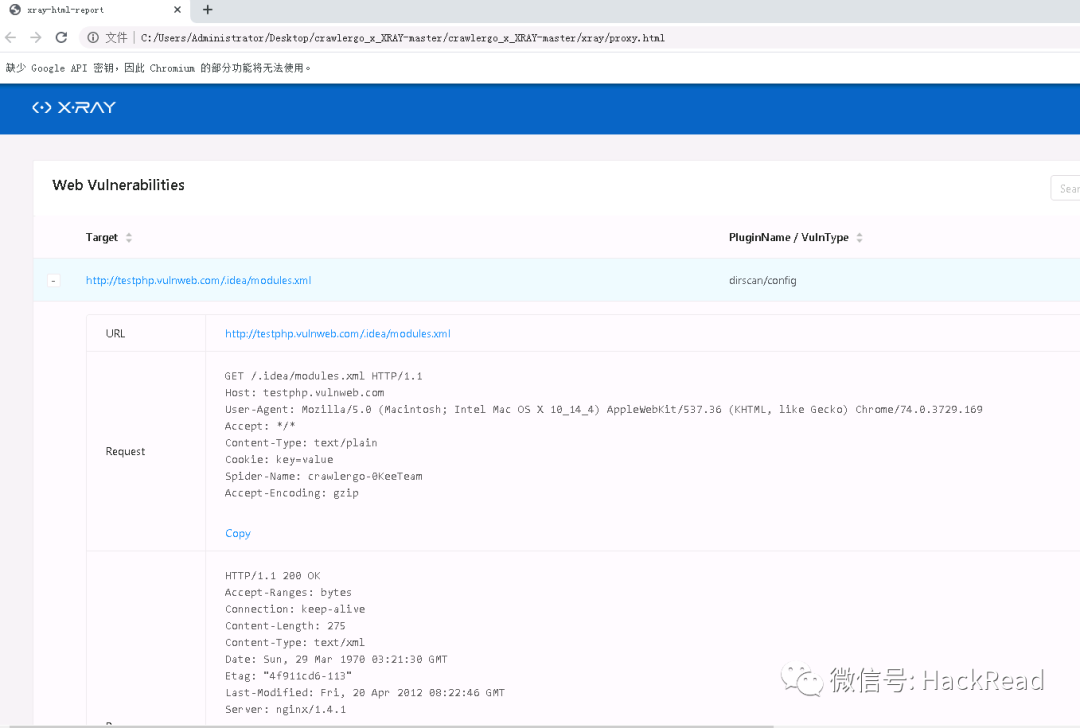
0X04后续
这样我们便可以快乐的自动挖洞了。
我们还可以利用server酱实现漏洞的自动推送。作者也在博客中发过了,可以去看看:https://www.cnblogs.com/L0ading/p/13228449.html
0X05参考链接
https://github.com/timwhitez/crawlergo_x_XRAY
https://xz.aliyun.com/t/7047
https://github.com/timwhitez/crawlergo_x_XRAY
https://github.com/0Kee-Team/crawlergo
声明:本公众号所分享内容仅用于网安爱好者之间的技术讨论,禁止用于违法途径,所有渗透都需获取授权!否则需自行承担,本公众号及原作者不承担相应的后

文章评论