
一 背景
-
代码评审问题那么多,处理了两三天还不断有新的问题,为什么?是开发者代码水平问题还是自己评审的方式存在不妥的地方?
-
一个开发同学同样的问题每次总是出现,为什么?是业务逻辑本身限制还是编码流程和规范培训得不到位?
-
代码评审提交时间
-
代码评审通过时间
-
代码提交人
-
代码评审人
-
该轮代码评审是否被合并
-
该轮代码评审的轮次
-
其他必要的信息,如提交的评审属于哪个分支,哪个需求,哪个项目等。

-
在调用自定义 NPM Script 的“req”(需求管理,requirements manage)命令进行分支创建和维护时,能够收集到分支和对应的需求相关信息,甚至让开发者预先填好需求的联调、提测、发布等时间节奏;
-
在调用“cr”(提交代码评审,code review)命令提交代码评审时,工具能够通过开发者所在的分支自动识别到其对应需求并自动确认目标分支,自动收集 Commit 信息,触发 Aone 相关提交逻辑,方便地创建代码评审并发送钉钉通知到群;
-
在调用“pub”(发布,publish)命令时通过自动识别到的开发者和需求信息,自动发布准确的预发环境(团队内是多套前端环境并存,互不干扰)。
-
校验工作区是否干净,判断当前分支有效性;
-
找到对应需求,确认目标分支;
-
访问持久化数据,检查是否有前置 CR(即,前一次 CR 未合并,本次有新的 Commit,提交后仍然是同一个CR);
-
查找是否有未上报的已完成 CR 信息,并收集其中有用的信息并上报:
-
在此过程中,会计算前一次 CR 的最新 Commit ID 是否已经包含在目标远程分支的 Commit Log 集合中,若包含则表示代码已合并,即 CR 已完成;
-
若有已完成的 CR 信息,则从持久化 CR 信息中取得 CR 提交时间,从目标分支的 Commit Log 中取得代码合并结点的提交时间作为代码合并时间,即可作为准确的 CR 通过时间;
-
代码检查,自动合并目标分支代码,若产生代码冲突则报错返回;
-
执行真正的提交 CR 逻辑,并将 CR 所有信息合在一起做数据上报和持久化存储,后续钉钉通知到群;
-
最后对 CR Commit 进行打标,方便后续通过 Tag 找到 Commit ID。
/** 效能工具内核类声明(与埋点上报监控平台相关的部分) */class HornetCore {/** 监控单实例声明 */private static traceInstance: TraceSdkType = null;/** HornetCore 监控初始化 */public static initTrace = (): void => {HornetCore.traceInstance = new TraceLiteSdk({ pid: '<研发效能工具PID>' });};/** 上报参数给监控平台 */public static sendTraceLog = async (/*** 上报类型*/type: string,/*** 上报的参数*/params?: TraceLogParamType,): Promise<void> => {try {// 操作人工号const uid = DYNAMIC_NAMES.ADMIN_WORK_ID;// 操作人const c1 = DYNAMIC_NAMES.ADMIN_NAME;// 应用名const c2 = DYNAMIC_NAMES.PROJECT_NAME;// 分支名const c3 = DYNAMIC_NAMES.BRANCH_NAME;let c4: any;let c5: any;let c6: any;let c7: any;let c8: any;// 工具是否最新版const c9 = HornetCore.isLatestVersion.toString();// 工具内核版本号const c10 = HornetCore.version;switch (type) {case TRACE_LOG_TYPE.CR: {const { targetBranch, crAdmins, crAdminCnt, currentReqName, crSequence } = params || {};[c4, c5, c6, c7, c8] = [targetBranch, crAdmins, crAdminCnt, currentReqName, crSequence];break;}case TRACE_LOG_TYPE.CR_HANDLING: {const { targetBranch, currentReqName, crCount, crStartTime, crEndTime } = params || {};[c4, c5, c6, c7, c8] = [targetBranch, currentReqName, crCount, crStartTime, crEndTime];break;}default:[c4, c5, c6, c7, c8] = [null, null, null, null, null];}const logParams = { type, uid, c1, c2, c3, c4, c5, c6, c7, c8, c9, c10 };return HornetCore.traceInstance.log(logParams);} catch (e) {BasicMessage.error(`上报数据错误: ${SPLIT_VALUE.BREAK}${e}`);return Promise.reject();}};}
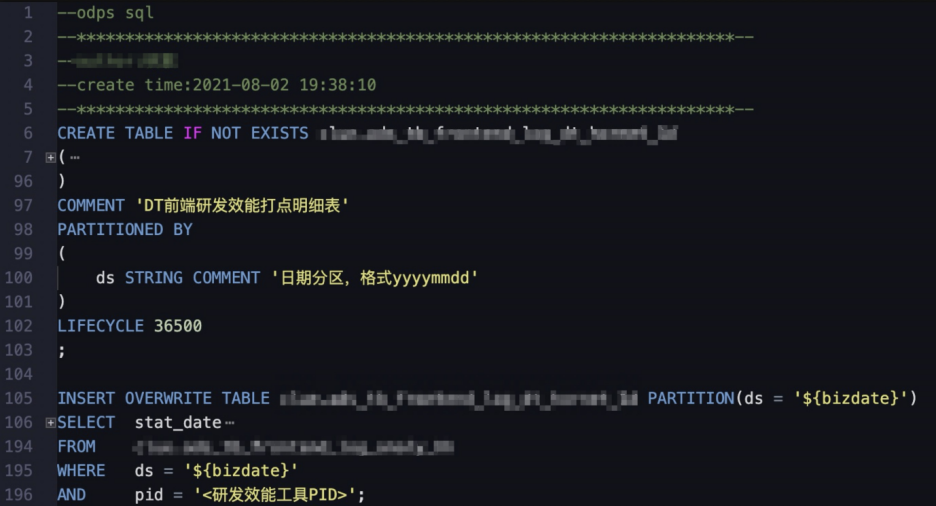
/*代码评审数据明细分析表*/SELECTa.stat_date,a.ds,a.log_day,substr(a.log_hour, 9) as log_hour,substr(a.log_time, 9) as log_time,substr(a.log_second, 9) as log_second,a.c1 as admin_name,b.c2 as project_name, -- 项目中文名信息由维表提供a.c2 as project_en_name,a.c3 as branch_name,a.c4 as target_branch,a.c5 as cr_admins,substring_index(c5, ',', 1) as cr_first_admin, -- 取得第一个评审人为主要评审人信息a.c6 as cr_admin_cnt,a.c7 as cur_req_name,concat(c4, ' ', c7) as cur_branch_and_req_name,a.c8 as cr_sequence,a.c9 as latest_version_flag,a.c10 as cur_versionFROMsource_table aLEFT OUTER JOIN (SELECTcode,c1,c2FROMsource_table_dim -- 维表存储不经常更改的维度信息) b ON a.c2 = b.c1WHEREa.code = 'code_review'AND b.code = 'project_name'AND a.c4 != 'develop' -- 过滤掉提交到主发布分支的 CR,因为其不是关键信息AND a.ds > 20210630; -- 限定有数据的 ds 范围,增加查询性能/*代码评审处理数据明细分析表*/SELECTa.stat_date,a.ds,a.log_day,substr(a.log_hour, 9) as log_hour,substr(a.log_time, 9) as log_time,substr(a.log_second, 9) as log_second,a.c1 as admin_name,b.c2 as project_name,a.c2 as project_en_name,a.c3 as branch_name,a.c4 as target_branch,a.c5 as cur_req_name,concat(a.c4, ' ', a.c5) as cur_branch_and_req_name,concat(b.c2, ' ', a.c5) as cur_project_and_req_name,c.c1 as cur_req_admin_name,a.c6 as cr_count,a.c7 as cr_start_time,a.c8 as cr_end_time,datediff(to_date(a.c8, 'yyyy-mm-dd hh:mi:ss'),to_date(a.c7, 'yyyy-mm-dd hh:mi:ss'),'mi') as cr_duration, -- 使用 datediff 函数来计算CR处理时长a.c9 as latest_version_flag,a.c10 as cur_versionfromsource_table aLEFT OUTER JOIN (SELECTcode,c1,c2FROMsource_table_dimWHEREcode = 'project_name' -- 关联项目名称信息) b ON a.c2 = b.c1LEFT OUTER JOIN (SELECTdistinct code,c1,c2,c3,c4FROMsource_tableWHEREcode = 'requirements' -- 关联需求信息) c ON a.c5 = c.c4WHEREa.code = 'code_review_handling'AND a.c4 != 'develop'AND a.c8 IS NOT NULL -- 没有CR结束时间的定义为废弃CR,此处过滤掉AND a.c8 != 'null'AND a.ds > 20210720;/*代码评审汇总分析表*/SELECTstat_date,project_name,project_name_and_req_name,cur_req_name,admin_name,COUNT(admin_name) as cr_cnt -- 统计CR提交次数FROM(SELECTa.stat_date,a.ds,a.log_day,substr(a.log_hour, 9) as log_hour,substr(a.log_time, 9) as log_time,substr(a.log_second, 9) as log_second,a.c1 as admin_name,b.c2 as project_name,a.c2 as project_en_name,a.c3 as branch_name,a.c4 as target_branch,a.c5 as cr_admins,substring_index(a.c5, ',', 1) as cr_first_admin,a.c6 as cr_admin_cnt,a.c7 as cur_req_name,concat(b.c2, ' ', a.c7) as project_name_and_req_name,a.c8 as cr_sequence,a.c9 as latest_version_flag,a.c10 as cur_versionFROMsource_table aLEFT OUTER JOIN (SELECTcode,c1,c2FROMsource_table_dim) b ON a.c2 = b.c1WHEREa.code = 'code_review'AND a.c4 != 'develop'AND a.ds > 20210715AND b.code = 'project_name')GROUP BY -- 选择日期、项目名称、需求名称、开发者等维度stat_date,project_name,cur_req_name,admin_name,project_name_and_req_name;
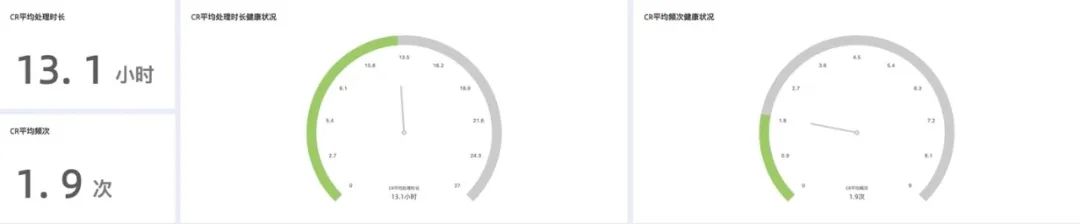

-
CR 平均处理时长及健康状况,认为 24 小时以下为健康;
-
CR 平均频次及健康状况,认为每人每天 1-3 次为健康;
-
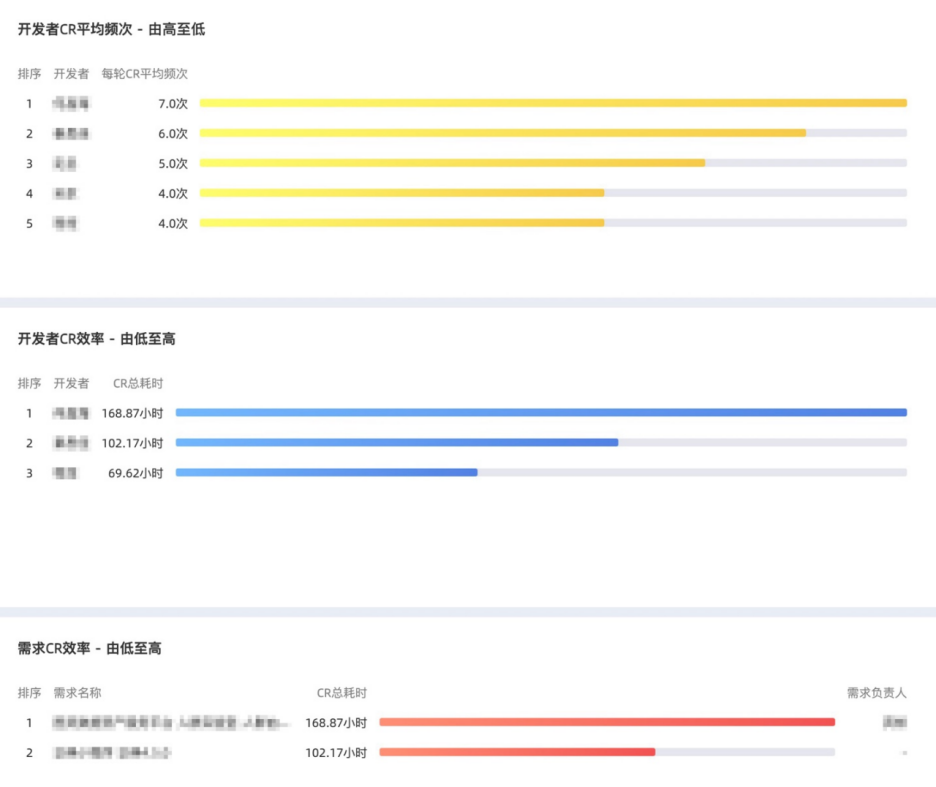
CR 平均处理时长按开发者、需求的排行榜;
-
CR 平均频次按开发者的排行榜(为避免内卷,当频次由高到低排列时,只展示超出健康度范围外的数据)。
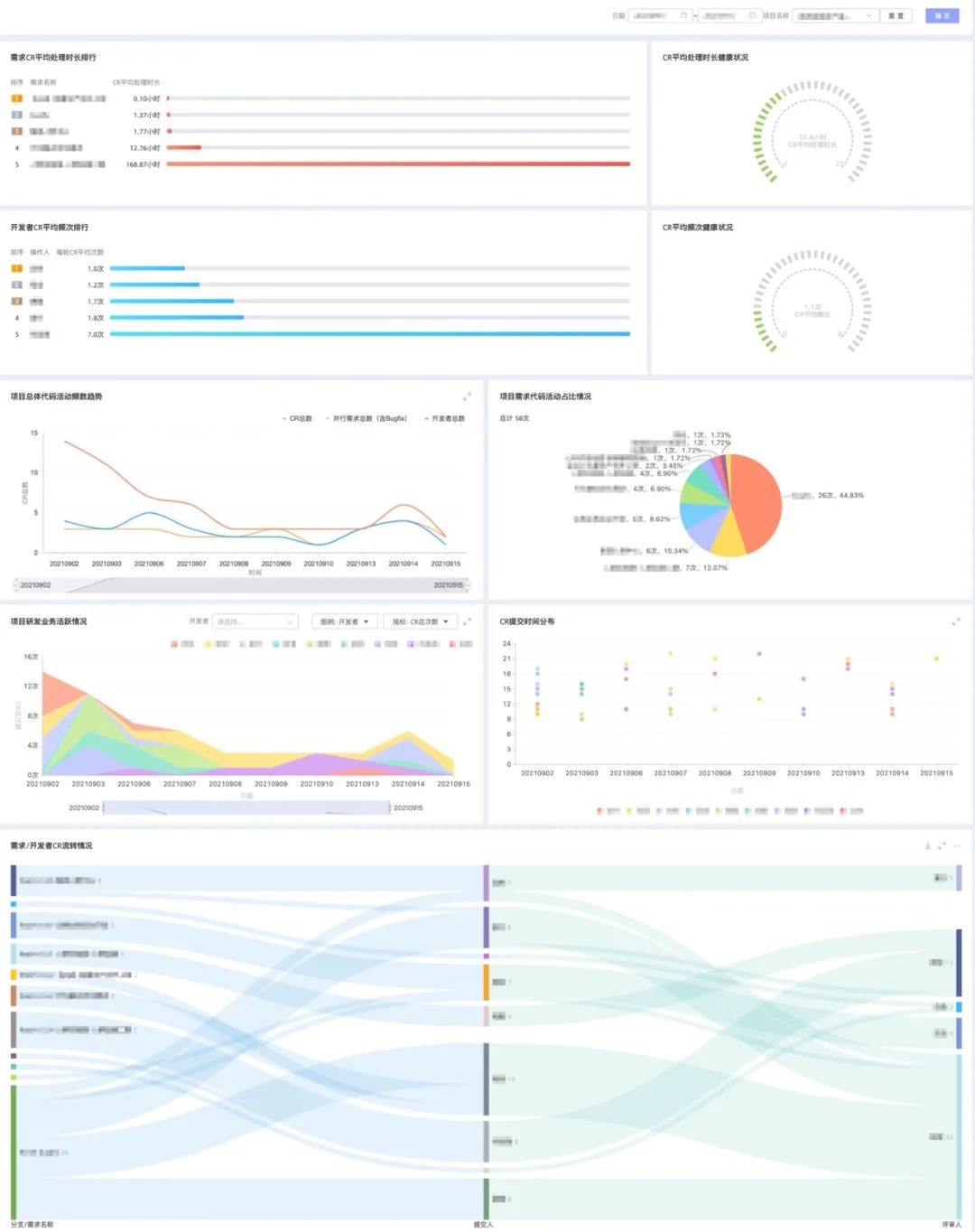
-
项目粒度的代码活动健康度(CR 平均处理时长、CR 平均频次);
-
项目下各需求 CR 占比;
-
项目 CR 提交时间分布;
-
项目粒度的需求 CR 流转情况(需求-开发者-主要评审人);
-
项目下各开发者的 CR 提交频数与负责需求数对比等。
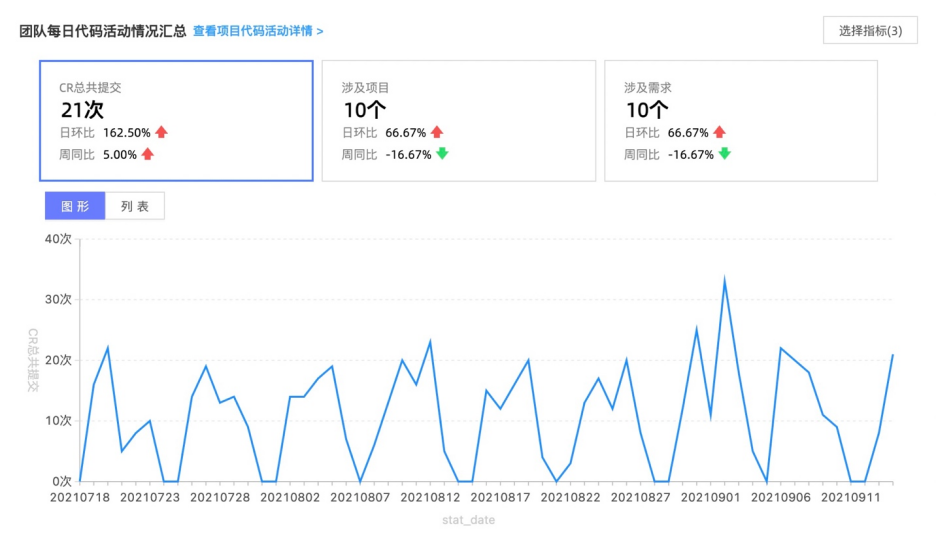
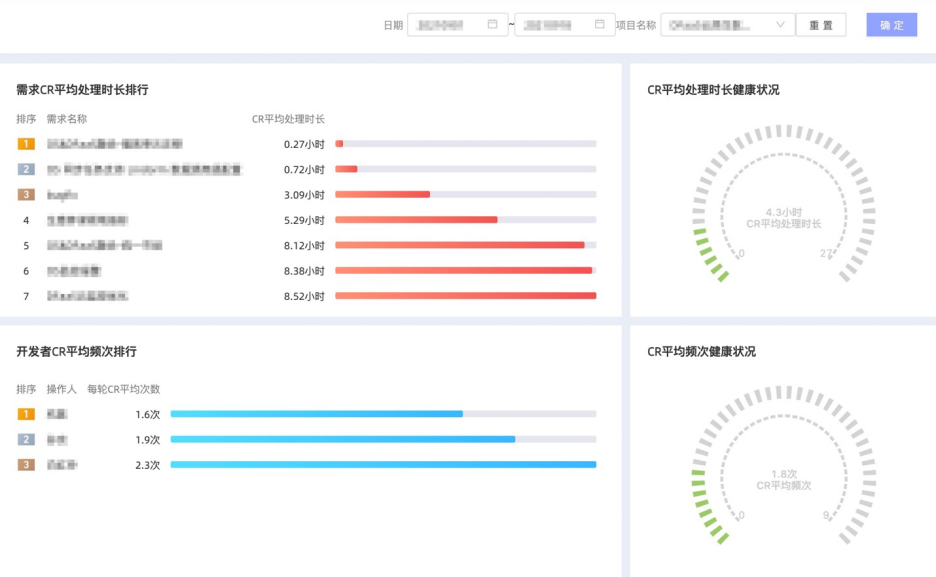
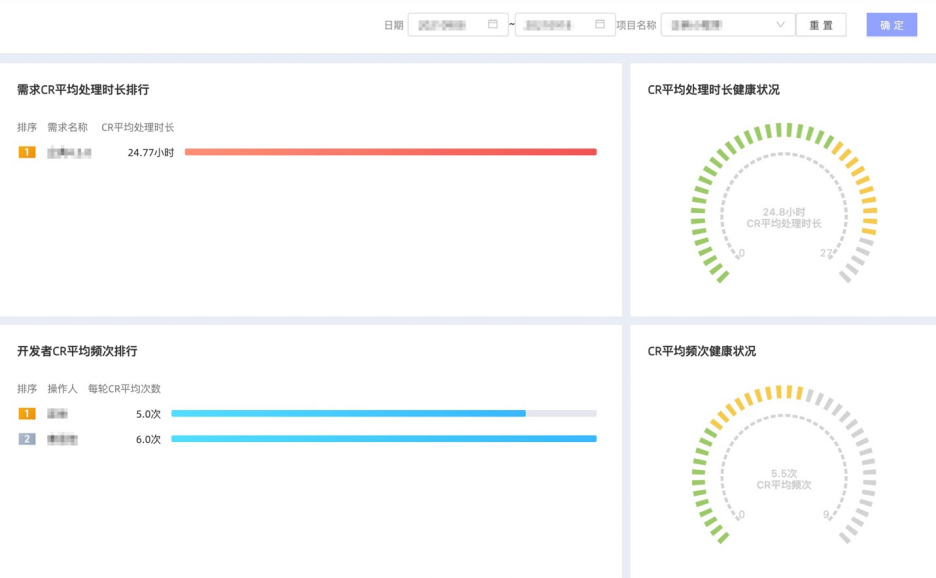
-
项目排期是否正常?
-
项目开发者是否遇到了困难?
-
开发习惯和模式是否需要调整?等等。
SpringMVC框架入门
Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面。Spring 框架提供了构建 Web 应用程序的全功能 MVC 模块。
在使用Spring进行WEB开发时,可以选择使用Spring的SpringMVC框架或集成其他MVC开发框架,如Struts2等。点击阅读原文查看课程详情~

文章评论