本文主要从以下几个方面介绍PostgreSQL高可用集群在360的落地实战
为什么选择Patroni + Etcd + PostgreSQL高可用集群方案
PostgreSQL高可用集群在360的落地实战 Patroni + Etcd 高可用集群架构解析
Patroni + Etcd + PostgreSQL 部署实战
Patroni 日常运维管理
PostgreSQL 监控实现
PostgreSQL 应用连接方式
PostgreSQL 备份恢复方式选择
背景
最近线上重要业务容器云的镜像仓库需要部署一套postgresql 高可用集群,涉及到数据库选型,最终选择了postgresql,为什么不选择mysql呢,postgresql是功能最强大的开源数据库,主要考虑postgresql支持使用函数索引和条件索引,text 没有限制,可以索引,还可以全文检索,不用再接一套es,并且postgresql 开源协议好,开源软件原生支持好,特别对开发来说比较友好,最重要的是kube-bench 只支持postgresql。
为什么选择Patroni + Etcd 方案
PostgreSQL 比较流行的高可用解决方案有很多,常用的主要包含repmgr和patroni等,也是github star前几的高可用组件,并且文档更新比较及时,都可最高支持postgresql 13,repmgr 相对来说功能没有patroni全面以及不能检测备机是否被错误配置为未知或不存在的节点、不能检测远程节点的状态(不具备分布式解决方案)和不能处理单个节点的恢复,本文主要基于patroni 实现。
此方案使用Patroni管理本地库,并结合Etcd作为数据存储和主节点选举,具有以下优势:
-
健壮性: 使用分布式key-value数据库作为数据存储,主节点故障时进行主节点重新选举,具有很强的健壮性
-
支持多种复制方式: 基于内置流复制,支持同步流复制、异步流复制、级联复制
-
支持主备延迟设置: 可以设置备库延迟主库WAL的字节数,当备库延迟大于指定值时不做故障切换
-
自动化程度高:
-
支持自动化初始PostgreSQL实例并部署流复制 -
当备库实例关闭后,支持自动拉起 -
当主库实例关闭后,首先会尝试自动拉起 -
支持switchover命令,能自动将老的主库进行角色转换
-
避免脑裂: 数据库信息记录到ETCD 中,通过优化部署策略(多机房部署、增加实例数)可以避免脑裂
Patroni + Etcd 高可用架构
Patroni 是一个开源工具套件,它是用 Python编写的,可确保 PostgreSQL HA 集群的端到端设置,包括流复制。它的功能通过REST API显示,也通过一个名为 Patronictl 的命令行实用程序显示。它通过使用其运行状况检查API来处理负载平衡来支持与 HAProxy 的集成。在此 HA 解决方案中,etcd 用于分布式配置存储 (DCS),以实现最大的可访问性,下面是官方高可用集群方案的架构图展示,我们基于此完成postgresql 高可用架构集群方案设计,不过并没有使用HAproxy 进行负载均衡,而是使用公司内部的LVS 来实现的,一主两副本,副本部署在不同的idc 实现异地灾备,etcd 也是三节点集群分别部署在三台机器, 如果资源有限,也可以和postgresql/patroni部署在相同机器。
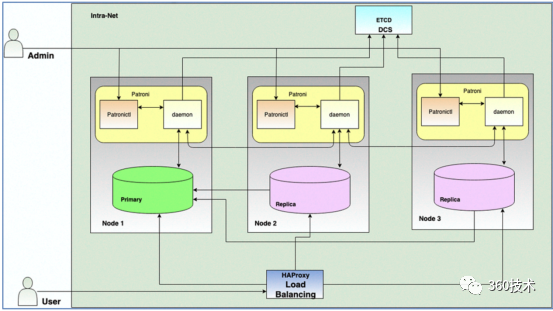
Etcd、Patroni 和PostgreSQL是如何一起工作的
etcd/patroni/postgresql 都是部署的3节点集群
Etcd: 分布式的Key-Value数据库
etcd1、etcd2、 etcd3作为分布式的Key-Value数据库,被partroni1、 patroni2、 patroni3读/写,用于共享/传递信息。每一个 Patroni都能读/写etcd中的数据。
Paroni: 控制/监控本地的PostgreSQL, 把本地PostgreSQL信息/状态写入etcd
每一个 Patroni实例监控/控制本地的PostgreSQL,把本地本地PostgreSQL信息/状态写入etcd , 一个Patroni实例能够通过读取etcd获取外地PostgreSQL的信息/状态。
PostreSQL主节点的选举
Patroni判断本地PostgreSQL是否可以作为Primary库。如果可以,Paroni试图选举本地PostgreSQL作为Primary(Leader) , 选举方式是:把etcd中的某个key更新成为本地PostgreSQL的名字, 如果多个Paroni同时更改同一个key,只有一个能改成功,然后成为Primary(Leader)。
部署篇
系统/软件/版本
· CentOS 7.4
· PostgreSQL 12.6
· etcd: 3.2.18
· python: Python 3.6.5
· Patroni: 2.1.0
主机信息
10.16.75.17 pg12/patroni
10.16.75.15 pg12/patroni
10.16.78.53 pg12/patroni
10.24.13.9 etcd
10.24.13.10 etcd
10.24.13.11 etcd
这里用了6台机器,也可以用3台机器组件全部安装在一起
Python3 安装
# 安装依赖
yum install wget gcc make zlib-devel openssl openssl-devel
wget "https://www.python.org/ftp/python/3.6.5/Python-3.6.5.tar.xz"
tar -xvJf Python-3.6.5.tar.xz
# 编译
cd Python-3.6.5 && ./configure prefix=/usr/local/python3
make && make install
ln -fs /usr/local/python3/bin/python3 /usr/bin/python3
ln -fs /usr/local/python3/bin/pip3 /usr/bin/pip3
# virtualenv
pip3 install virtualenv -i https://mirrors.ustc.edu.cn/pypi/web/simple/
ln -fs /usr/local/python3/bin/virtualenv /usr/bin/virtualenv
# 编译安装python的使用
cd /data04 && virtualenv venv4archery --python=python3
# 切换python运行环境到虚拟环境
source venv4archery/bin/activate
创建PG目录和用户
useradd postgres #编译安装的,yum 安装不用创建
mkdir -p /data04/pg15432
mkdir -p /data04/pg15432/data
mkdir -p /data04/pg15432/scripts
chown -R postgres:postgres /data04/pg15432/
创建归档目录
mkdir -p /data04/pg15432/arch
源码安装postgresql12
yum -y install -y readline-devel
mkdir -p /usr/local/pgsql/
./configure --prefix=/usr/local/pgsql
make && make install
cp /usr/local/pgsql/bin/* /sbin/
Etcd 部署
yum install etcd -y
编辑/etc/etcd/etcd.conf 配置文件
Etcd node1配置
ETCD_DATA_DIR="/var/lib/etcd/codis.etcd"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_NAME="node1"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.24.13.9:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://10.24.13.9:2379"
ETCD_INITIAL_CLUSTER="node1=http://10.24.13.9:2380,node2=http://10.24.13.10:2380,node3=http://10.24.13.11:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
Etcd node2 配置
ETCD_DATA_DIR="/var/lib/etcd/codis.etcd"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_NAME="node2"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.24.13.10:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://10.24.13.10:2379"
ETCD_INITIAL_CLUSTER="node1=http://10.24.13.9:2380,node2=http://10.24.13.10:2380,node3=http://10.24.13.11:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
Etcd node3 配置
ETCD_DATA_DIR="/var/lib/etcd/codis.etcd"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_NAME="node3"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.24.13.11:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://10.24.13.11:2379"
ETCD_INITIAL_CLUSTER="node1=http://10.24.13.9:2380,node2=http://10.24.13.10:2380,node3=http://10.24.13.11:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
#注意etcdnode1 每个节点都不一样,etcd-cluster-1 是集群名字统一
systemctl daemon-reload
systemctl enable etcd
systemctl start etcd
Etcd 成员列表显示
etcdctl member list

Etcd集群健康检查
etcdctl --endpoints http://10.24.13.9:2379 cluster-health

Patronic 部署
cd /data04 && virtualenv venv4archery --python=python3
source venv4archery/bin/activate
pip3 install psycopg2-binary -i https://mirrors.aliyun.com/pypi/simple/
或者pip3 install psycopg2>=2.5.4 -i https://mirrors.aliyun.com/pypi/simple/
pip3 install patroni[etcd,consul,zookeeper,kubernetes] -i https://mirrors.aliyun.com/pypi/simple/
#启动patroni集群需非root用户
集群进行初始化(所有节点执行)
patroni /etc/patroni.yml > patroni_member_1.log 2>&1 &
可以使用centos7的service启动:
[Unit]
Description=Runners to orchestrate a high-availability PostgreSQL
After=syslog.target network.target
[Service]
Type=simple
User=postgres
Group=postgres
#StandardOutput=syslog
ExecStart=/sbin/patroni /etc/patroni.yml
ExecReload=/bin/kill -s HUP $MAINPID
KillMode=process
TimeoutSec=30
Restart=no
[Install]
WantedBy=multi-user.target
/etc/patroni.yml (可根据自己需求定制化)
scope: postgresql
namespace: /service/
name: postgresql1
restapi:
listen: 10.16.75.17:8008
connect_address: 10.16.75.17:8008
etcd:
host: 10.24.13.9:2379
host: 10.24.13.10:2379
host: 10.24.13.11:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
listen_addresses: "0.0.0.0"
wal_level: logical
archive_mode: "on"
max_connections: 6000
Shared_buffers: 32GB
archive_command: 'DATE=`date +%Y%m%d`;DIR="/data04/pg15432/arch/$DATE";(test -d $DIR || mkdir -p $DIR)&& cp %p $DIR/%f'
hot_standby: "on"
wal_keep_segments: 100
max_wal_senders: 10
max_replication_slots: 10
wal_log_hints: "on"
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host replication repl 127.0.0.1/32 md5
- host replication repl 10.16.75.17/0 md5
- host replication repl 10.16.75.15/0 md5
- host replication repl 10.206.87.218/0 md5
- host replication repl 0.0.0.0/0 md5
- host all all 0.0.0.0/0 md5
users:
admin:
password: admin
options:
- createrole
- createdb
postgresql:
listen: 10.16.75.17:15432
connect_address: 10.16.75.17:15432
bin_dir: /usr/local/pgsql/bin
data_dir: /data04/pg15432/data
pgpass: /tmp/pgpass1
authentication:
replication:
username: repl
password: "1a23s6c54f"
superuser:
username: postgres
password: "59687411134be622"
parameters:
unix_socket_directories: '.'
synchronous_commit: "on"
synchronous_standby_names: "*"
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
重点关注上面标红的参数设置,如果初始化未设置也没关系,部署完成一定验证下重要参数设置,未设置的可以通过patronictl 进行设置。
PG集群信息查看
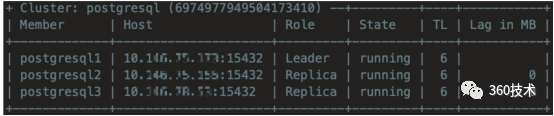
数据库账户创建
CREATE USER docker WITH PASSWORD 'xxxx';
CREATE DATABASE docker OWNER docker;
GRANT ALL PRIVILEGES ON DATABASE docker to docker;
远程连接数据库
psql -U docker -d docker -p xxxx-h xxxx
尝试对主节点进行读写
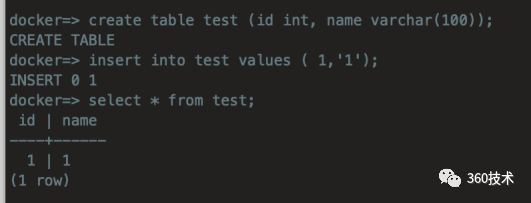
以上完成对整个集群的部署并确保数据库可以正常进行读写
Patronictl 日常运维
参数设置查看
shared_buffers
类似mysql innodb_buffer_pool_size,该参数主要设置数据库服务器将使用的共享内存缓冲区量,建议是设置系统内存的25%,过高也会造成一些工作负载,还是需要跟业务沟通获取预估的数据量以及估算热数据量来针对性制定参数值。
修改shared_buffers
patronictl -c /etc/patroni.yml edit-config -p "shared_buffers='32GB'"
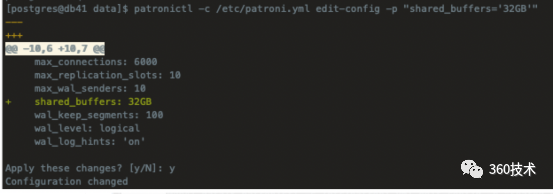
patronictl -c /etc/patroni.yml restart postgresql (重启生效)
max_connections
决定数据库的最大并发连接数。默认值通常是 100 个连接,但是如果内核设置不支持(initdb时决定),可能会比这个 数少。这个参数只能在服务器启动时设置。
当运行一个后备服务器时,你必须设置这个参数等于或大于主服务器上的参数。否则,后备服务器上可能无法允许查询。
修改max_connections
patronictl -c /etc/patroni.yml edit-config -p 'max_connections=6000'
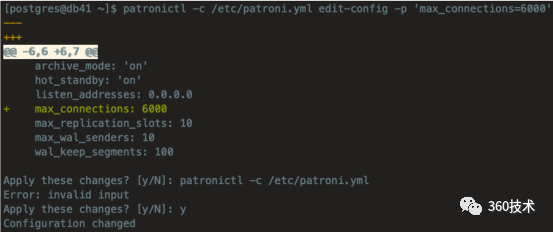
patronictl -c /etc/patroni.yml restart postgresql (重启生效)
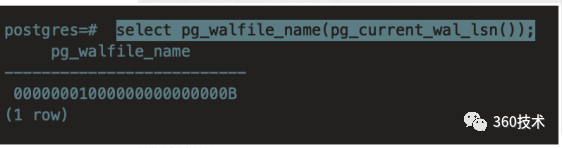
查看当前归档日志
select pg_walfile_name(pg_current_wal_lsn());
手动切换归档
select pg_walfile_name(pg_current_wal_lsn());
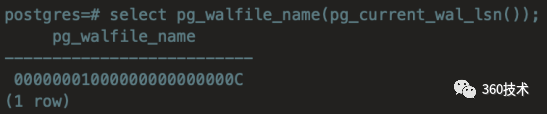
可以看到归档已经由...0000B 切换到...0000C
设置开启慢日志
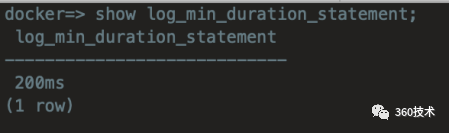
阈值为200ms
patronictl -c /etc/patroni.yml edit-config -p 'log_min_duration_statement=200'
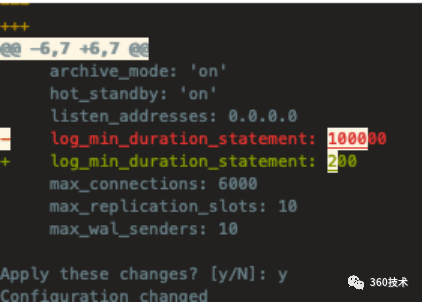
查看慢日志设置阈值
高可用故障转移测试
Kill 主节点进程
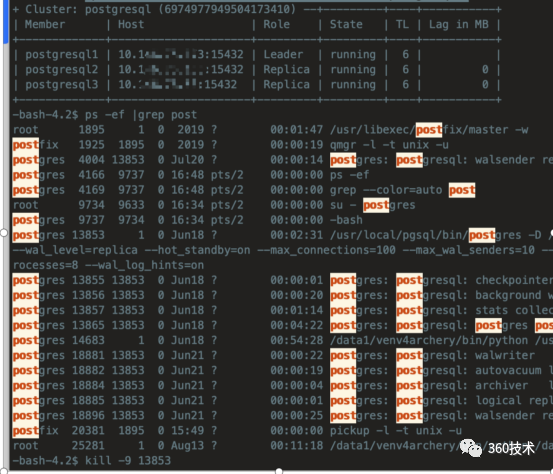
会发现patroni 会自动拉起postgresql进程,并且还是主节点,并未进行切主
手工切主
假设切主到postgresql2 155节点
patronictl -d etcd://10.16.75.17:2379 switchover postgresql
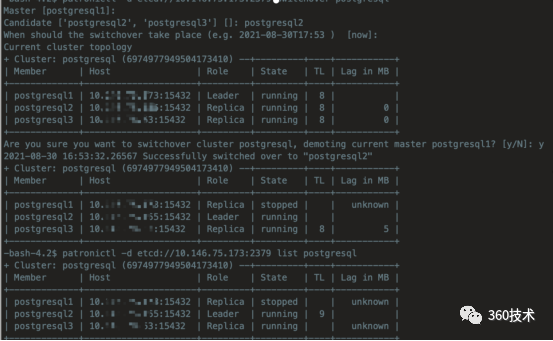
切主期间会出现中间状态unknown,瞬间会恢复正常如下,切主成功到155。

重启集群
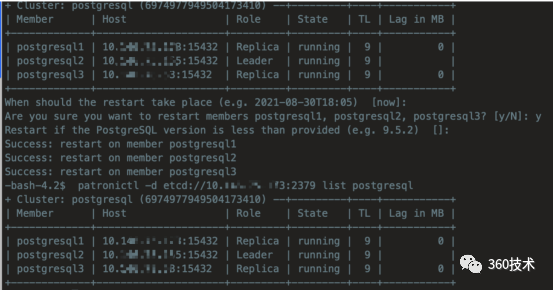
可看到主节点也是没切主,拓扑和以前是一样的。
主/从节点机器重启
机器宕机是常有的事情,当postgresql 某个节点所在机器宕机恢复后,需要手动拉起节点 patroni /etc/patroni.yml > patroni_member_1.log 2>&1 &
禁用开启故障转移
当pause 后,这时候集群是不会进行自动故障转移的,可以在某些特定场景使用,然后用resume 恢复就可以了。

还有其它一些功能可以参考patronictl --help
PostgreSQL监控
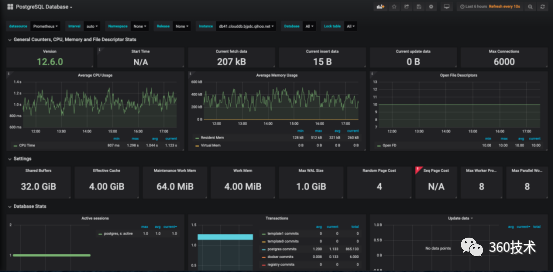
监控是眼睛,对于运维来说非常重要,这边主要采用的是Grafana + Prometheus 监控PostgreSQL,自带PG监控指标模版,也可自己定制详尽指标,结合内部告警平台编写api 实现告警短信发送以及推推内部沟通软件推送,具体部署这里就不详细阐述了,监控界面如下:
应用连接方式

PostgreSQL 备份
PostgreSQL流复制备份可选择物理备份或者逻辑备份,逻辑备份可选择pg_dump 进行单表备份或者pg_dumpall进行全库备份,物理备份可选择pg_basebackup 或者pg_rman 备份,在此我选择pg_rman 进行备份,下面重点介绍下强大的pg_rman 备份工具。
pg_rman可支持的主要功能如下:
-
全量备份
-
增量备份
-
检验备份集
-
列出备份集
-
按指定时间从catalog 删除备份集
-
物理删除已从catalog删除的备份集
相信用过oracle的同学了解oracle rman 备份的强大就清楚pg_rman 的功能强大之处,具体可参考http://mysql.taobao.org/monthly/2016/09/05/
PostgreSQL 在最新的数据库DB-Engines 9月榜单高居第四,是功能最强大的开源数据库,增势迅速,稳定性极强,特别是在GIS领域处于优势地位,有丰富统计函数和统计语法支持对开发特别友好,而且高可用复制架构越来越完善,相信在不久的将来在国内应用会越来越广泛。
PostgreSQL中文社区欢迎广大技术人员投稿
投稿邮箱:press@postgres.cn

文章评论