前言:
大家晚上好,今天给大家分享FFmpeg里面的重采样实践,话不多说,直接开始!
一、重采样:
1、什么是重采样?
通俗的讲,重采样就是改变音频的采样率、sample format(采样格式)、声道数(channel)等参数,使之按照我们期望的参数输出。
2、为什么需要重采样?
做什么事情之前,我们都要问一个为什么,也就是知道原理!那么为什么需要重采样呢?那是因为当原有的音频参数不满足我们实际要求时,比如说在FFmpeg解码音频的时候,不同的音源有不同的格式和采样率等,所以在解码后的数据中的这些参数也会不一致(最新的FFmpeg解码音频后,音频格式为AV_SAMPLE_FMT_TLTP);如果我们接下来需要使用解码后的音频数据做其它操作的话,然而这些参数的不一致会导致有很多额外工作,此时直接对其进行重采样的话,获取我们制定的音频参数,就会方便很多。
再比如说,在将音频进行SDL播放的时候,因为当前的SDL2.0不支持plannar格式,也不支持浮点型的,而最新的FFpemg会将音频解码为AV_SAMPLE_FMT_FLTP,这个时候进行对它重采样的话,就可以在SDL2.0上进行播放这个音频了。
3、重采样参数解析:
-
sample rate(采样率):采样设备每秒抽取样本的次数
-
sample format(采样格式)和量化精度:这个应该好理解,就是采用什么格式进行采集数据;每种⾳频格式有不同的量化精度(位宽),位数越多,表示值就越精确,声⾳表现⾃然就越精准。
-
channel layout(通道布局,也就是声道数):这个就是采样的声道数
这里多补充一下:
在FFmpeg里面主要有两种采样格式:floating-point formats 和 planar sample formats;具体采样参数如下(在(libavutil/samplefmt.h头文件里面):
enum AVSampleFormat {
AV_SAMPLE_FMT_NONE = -1,
AV_SAMPLE_FMT_U8, ///< unsigned 8 bits
AV_SAMPLE_FMT_S16, ///< signed 16 bits
AV_SAMPLE_FMT_S32, ///< signed 32 bits
AV_SAMPLE_FMT_FLT, ///< float
AV_SAMPLE_FMT_DBL, ///< double
AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar
AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar
AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar
AV_SAMPLE_FMT_FLTP, ///< float, planar
AV_SAMPLE_FMT_DBLP, ///< double, planar
AV_SAMPLE_FMT_S64, ///< signed 64 bits
AV_SAMPLE_FMT_S64P, ///< signed 64 bits, planar
AV_SAMPLE_FMT_NB ///< Number of sample formats. DO NOT USE if linking dynamically
};
上半部分就是floating-point formats,下半部分就是planar格式,关于这两种格式的介绍:
-
floating-point formats:
* - The floating-point formats are based on full volume being in the range
* [-1.0, 1.0]. Any values outside this range are beyond full volume level.
-
planar sample formats:
For planar sample formats, each audio channel is in a separate data plane,
* and linesize is the buffer size, in bytes, for a single plane. All data
* planes must be the same size. For packed sample formats, only the first data
* plane is used, and samples for each channel are interleaved. In this case,
* linesize is the buffer size, in bytes, for the 1 plane.
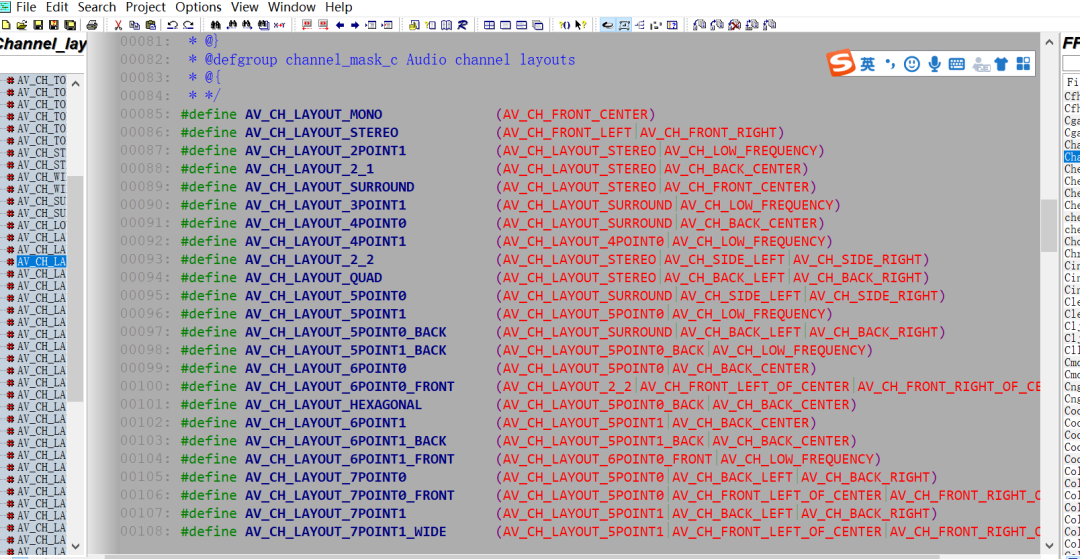
还有就是声道分布参数,这个在FFmpeg也有说明(声道分布在FFmpeg\libavutil\channel_layout.h中有定义,⼀般来说⽤的⽐较多的是 AV_CH_LAYOUT_STEREO(双声道)和AV_CH_LAYOUT_SURROUND(三声道),这两者的定义如下):
#define AV_CH_LAYOUT_STEREO (AV_CH_FRONT_LEFT|AV_CH_FRONT_RIGHT)
#define AV_CH_LAYOUT_SURROUND (AV_CH_LAYOUT_STEREO|AV_CH_FRONT_CENTER)
下面是其他声道数参数:
4、分⽚(plane)和打包(packed):
以双声道为例,带P(plane)的数据格式在存储时,其左声道和右声道的数据是分开存储的,左声道的 数据存储在data[0],右声道的数据存储在data[1],每个声道的所占⽤的字节数为linesize[0]和 linesize[1];
不带P(packed)的⾳频数据在存储时,是按照LRLRLR...的格式交替存储在data[0]中,linesize[0] 表示总的数据量。
这个可以在下面的代码里面可以看到用法,这里简单提一下。
5、⾳频帧的数据量计算:
⼀帧⾳频的数据量(字节)=channel数 * nb_samples样本数 * 每个样本占⽤的字节数 如果该⾳频帧是FLTP格式的PCM数据,包含1024个样本,双声道,那么该⾳频帧包含的⾳频数据量是:
2*1024*4=8192字节
6、⾳频播放时间计算:
以采样率44100Hz来计算,每秒44100个sample,⽽正常⼀帧为1024个sample,可知每帧播放时 间/1024=1000ms/44100,得到每帧播放时间=1024*1000/44100=23.2ms (更精确的是 23.21995464852608)
但是要注意:
-
⼀帧播放时间(毫秒) = nb_samples样本数 1000/采样率 = 10241000/44100=23.21995464852608ms;约等于 23.2ms,精度损失了 0.011995464852608ms,如果累计10万帧,误差>1199毫秒,如果有视频⼀起的就会有⾳视频同步的问题。这个误差太可怕了。。。。
二、FFmpeg之api讲解:
-
分配⾳频重采样的上下⽂:
av_cold struct SwrContext *swr_alloc(void){
SwrContext *s= av_mallocz(sizeof(SwrContext));
if(s){
s->av_class= &av_class;
av_opt_set_defaults(s);
}
return s;
}
struct SwrContext {
const AVClass *av_class; ///< AVClass used for AVOption and av_log()
int log_level_offset; ///< logging level offset
void *log_ctx; ///< parent logging context
enum AVSampleFormat in_sample_fmt; ///< input sample format
enum AVSampleFormat int_sample_fmt; ///< internal sample format (AV_SAMPLE_FMT_FLTP or AV_SAMPLE_FMT_S16P)
enum AVSampleFormat out_sample_fmt; ///< output sample format
int64_t in_ch_layout; ///< input channel layout
int64_t out_ch_layout; ///< output channel layout
int in_sample_rate; ///< input sample rate
int out_sample_rate; ///< output sample rate
int flags; ///< miscellaneous flags such as SWR_FLAG_RESAMPLE
float slev; ///< surround mixing level
float clev; ///< center mixing level
float lfe_mix_level; ///< LFE mixing level
float rematrix_volume; ///< rematrixing volume coefficient
float rematrix_maxval; ///< maximum value for rematrixing output
int matrix_encoding; /**< matrixed stereo encoding */
const int *channel_map; ///< channel index (or -1 if muted channel) map
int used_ch_count; ///< number of used input channels (mapped channel count if channel_map, otherwise in.ch_count)
int engine;
int user_in_ch_count; ///< User set input channel count
int user_out_ch_count; ///< User set output channel count
int user_used_ch_count; ///< User set used channel count
int64_t user_in_ch_layout; ///< User set input channel layout
int64_t user_out_ch_layout; ///< User set output channel layout
enum AVSampleFormat user_int_sample_fmt; ///< User set internal sample format
int user_dither_method; ///< User set dither method
struct DitherContext dither;
int filter_size; /**< length of each FIR filter in the resampling filterbank relative to the cutoff frequency */
int phase_shift; /**< log2 of the number of entries in the resampling polyphase filterbank */
int linear_interp; /**< if 1 then the resampling FIR filter will be linearly interpolated */
int exact_rational; /**< if 1 then enable non power of 2 phase_count */
double cutoff; /**< resampling cutoff frequency (swr: 6dB point; soxr: 0dB point). 1.0 corresponds to half the output sample rate */
int filter_type; /**< swr resampling filter type */
double kaiser_beta; /**< swr beta value for Kaiser window (only applicable if filter_type == AV_FILTER_TYPE_KAISER) */
double precision; /**< soxr resampling precision (in bits) */
int cheby; /**< soxr: if 1 then passband rolloff will be none (Chebyshev) & irrational ratio approximation precision will be higher */
float min_compensation; ///< swr minimum below which no compensation will happen
float min_hard_compensation; ///< swr minimum below which no silence inject / sample drop will happen
float soft_compensation_duration; ///< swr duration over which soft compensation is applied
float max_soft_compensation; ///< swr maximum soft compensation in seconds over soft_compensation_duration
float async; ///< swr simple 1 parameter async, similar to ffmpegs -async
int64_t firstpts_in_samples; ///< swr first pts in samples
int resample_first; ///< 1 if resampling must come first, 0 if rematrixing
int rematrix; ///< flag to indicate if rematrixing is needed (basically if input and output layouts mismatch)
int rematrix_custom; ///< flag to indicate that a custom matrix has been defined
AudioData in; ///< input audio data
AudioData postin; ///< post-input audio data: used for rematrix/resample
AudioData midbuf; ///< intermediate audio data (postin/preout)
AudioData preout; ///< pre-output audio data: used for rematrix/resample
AudioData out; ///< converted output audio data
AudioData in_buffer; ///< cached audio data (convert and resample purpose)
AudioData silence; ///< temporary with silence
AudioData drop_temp; ///< temporary used to discard output
int in_buffer_index; ///< cached buffer position
int in_buffer_count; ///< cached buffer length
int resample_in_constraint; ///< 1 if the input end was reach before the output end, 0 otherwise
int flushed; ///< 1 if data is to be flushed and no further input is expected
int64_t outpts; ///< output PTS
int64_t firstpts; ///< first PTS
int drop_output; ///< number of output samples to drop
double delayed_samples_fixup; ///< soxr 0.1.1: needed to fixup delayed_samples after flush has been called.
struct AudioConvert *in_convert; ///< input conversion context
struct AudioConvert *out_convert; ///< output conversion context
struct AudioConvert *full_convert; ///< full conversion context (single conversion for input and output)
struct ResampleContext *resample; ///< resampling context
struct Resampler const *resampler; ///< resampler virtual function table
double matrix[SWR_CH_MAX][SWR_CH_MAX]; ///< floating point rematrixing coefficients
float matrix_flt[SWR_CH_MAX][SWR_CH_MAX]; ///< single precision floating point rematrixing coefficients
uint8_t *native_matrix;
uint8_t *native_one;
uint8_t *native_simd_one;
uint8_t *native_simd_matrix;
int32_t matrix32[SWR_CH_MAX][SWR_CH_MAX]; ///< 17.15 fixed point rematrixing coefficients
uint8_t matrix_ch[SWR_CH_MAX][SWR_CH_MAX+1]; ///< Lists of input channels per output channel that have non zero rematrixing coefficients
mix_1_1_func_type *mix_1_1_f;
mix_1_1_func_type *mix_1_1_simd;
mix_2_1_func_type *mix_2_1_f;
mix_2_1_func_type *mix_2_1_simd;
mix_any_func_type *mix_any_f;
/* TODO: callbacks for ASM optimizations */
};
-
初始化SwrContext结构体:
int swr_init(struct SwrContext *s);
-
分配SwrContext并设置/重置常⽤的参数:
struct SwrContext *swr_alloc_set_opts(struct SwrContext *s, // ⾳频重采样上下⽂
int64_t out_ch_layout, // 输出的layout, 如:5.1声道
enum AVSampleFormat out_sample_fmt, // 输出的采样格式。
Float, S16,⼀般 选⽤是s16 绝⼤部分声卡⽀持
int out_sample_rate, //输出采样率
int64_t in_ch_layout, // 输⼊的layout enum AVSampleFormat in_sample_fmt, // 输⼊的采样格式
int in_sample_rate, // 输⼊的采样率
int log_offset, // ⽇志相关,不⽤管先,直接为0 void *log_ctx // ⽇志相关,不⽤管先,直接为NULL
);
-
将输⼊的⾳频按照定义的参数进⾏转换并输出:
int swr_convert(struct SwrContext *s, // ⾳频重采样的上下⽂
uint8_t **out, // 输出的指针。传递的输出的数组 int out_count, //输出的样本数量,不是字节数。单通道的样本数量。
const uint8_t **in , //输⼊的数组,AVFrame解码出来的DATA
int in_count // 输⼊的单通道的样本数量。
);
-
释放掉SwrContext结构体并将此结构体置为NULL:
void swr_free(struct SwrContext **s)
-
⾳频重采样,采样格式转换和混合库:
与lswr的交互是通过SwrContext完成的,SwrContext被分配给swr_alloc()或 swr_alloc_set_opts()。它是不透明的,所以所有参数必须使⽤AVOptions API设置。为了使⽤lswr,你需要做的第⼀件事就是分配SwrContext。这可以使⽤swr_alloc()或 swr_alloc_set_opts()来完成。如果您使⽤前者,则必须通过AVOptions API设置选项。后⼀个函数 提供了相同的功能,但它允许您在同⼀语句中设置⼀些常⽤选项。例如,以下代码将设置从平⾯浮动样本格式到交织的带符号16位整数的转换,从48kHz到44.1kHz的下采 样,以及从5.1声道到⽴体声的下混合(使⽤默认混合矩阵)。这是使⽤swr_alloc()函数:
1 SwrContext *swr = swr_alloc();
2 av_opt_set_channel_layout(swr, "in_channel_layout", AV_CH_LAYOUT_ 5POINT1, 0);
3 av_opt_set_channel_layout(swr, "out_channel_layout", AV_CH_LAYOUT_ STEREO, 0);
4 av_opt_set_int(swr, "in_sample_rate", 48000, 0) ;
5 av_opt_set_int(swr, "out_sample_rate", 44100, 0) ;
6 av_opt_set_sample_fmt(swr, "in_sample_fmt", AV_SAMPLE_FMT_FLTP, 0 );
7 av_opt_set_sample_fmt(swr, "out_sample_fmt", AV_SAMPLE_FMT_S16, 0 );
同样的⼯作也可以使⽤swr_alloc_set_opts():
SwrContext *swr = swr_alloc_set_opts(NULL, // we're allocating a new context
2 AV_CH_LAYOUT_STEREO, // out_ch_layout
3 AV_SAMPLE_FMT_S16, // out_sample_fmt
4 44100, // out_sample_rate
5 AV_CH_LAYOUT_5POINT1, // in_ch_layout
6 AV_SAMPLE_FMT_FLTP, // in_sample_fmt
7 48000, // in_sample_rate
8 0, // log_offset
9 NULL
); // log_ctx
⼀旦设置了所有值,它必须⽤swr_init()初始化。如果需要更改转换参数,可以使⽤ AVOptions来更改参数,如上⾯第⼀个例⼦所述; 或者使⽤swr_alloc_set_opts(),但是第 ⼀个参数是分配的上下⽂。您必须再次调⽤swr_init()。
转换本身通过重复调⽤swr_convert()来完成。请注意,如果提供的输出空间不⾜或采样率转换完成 后,样本可能会在swr中缓冲,这需要“未来”样本。可以随时通过使⽤swr_convert()(in_count可以 设置为0)来检索不需要将来输⼊的样本。在转换结束时,可以通过调⽤具有NULL in和in incount的 swr_convert()来刷新重采样缓冲区。
下面是一般重采样的流程:
-
分配:swr_alloc()
-
设置参数:av_opt_set_channel_layout();av_opt_set_int();av_opt_set_sample_fmt()
-
初始化:swr_init()
-
转换: swr_convert()
三、重采样demo:
说明一下,这里代码有参考FFmpeg给的demo哈:
/*
* Copyright (c) 2012 Stefano Sabatini
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
* THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
* THE SOFTWARE.
*/
/**
* @example resampling_audio.c
* libswresample API use example.
*/
#include <libavutil/opt.h>
#include <libavutil/channel_layout.h>
#include <libavutil/samplefmt.h>
#include <libswresample/swresample.h>
static int get_format_from_sample_fmt(const char **fmt,
enum AVSampleFormat sample_fmt)
{
int i;
struct sample_fmt_entry {
enum AVSampleFormat sample_fmt; const char *fmt_be, *fmt_le;
} sample_fmt_entries[] = {
{ AV_SAMPLE_FMT_U8, "u8", "u8" },
{ AV_SAMPLE_FMT_S16, "s16be", "s16le" },
{ AV_SAMPLE_FMT_S32, "s32be", "s32le" },
{ AV_SAMPLE_FMT_FLT, "f32be", "f32le" },
{ AV_SAMPLE_FMT_DBL, "f64be", "f64le" },
};
*fmt = NULL;
for (i = 0; i < FF_ARRAY_ELEMS(sample_fmt_entries); i++) {
struct sample_fmt_entry *entry = &sample_fmt_entries[i];
if (sample_fmt == entry->sample_fmt) {
*fmt = AV_NE(entry->fmt_be, entry->fmt_le);
return 0;
}
}
fprintf(stderr,
"Sample format %s not supported as output format\n",
av_get_sample_fmt_name(sample_fmt));
return AVERROR(EINVAL);
}
/**
* Fill dst buffer with nb_samples, generated starting from t. 交错模式的
*/
static void fill_samples(double *dst, int nb_samples, int nb_channels, int sample_rate, double *t)
{
int i, j;
double tincr = 1.0 / sample_rate, *dstp = dst;
const double c = 2 * M_PI * 440.0;
/* generate sin tone with 440Hz frequency and duplicated channels */
for (i = 0; i < nb_samples; i++) {
*dstp = sin(c * *t);
for (j = 1; j < nb_channels; j++)
dstp[j] = dstp[0];
dstp += nb_channels;
*t += tincr;
}
}
int main(int argc, char **argv)
{
// 输入参数
int64_t src_ch_layout = AV_CH_LAYOUT_STEREO;
int src_rate = 48000;
enum AVSampleFormat src_sample_fmt = AV_SAMPLE_FMT_DBL;
int src_nb_channels = 0;
uint8_t **src_data = NULL; // 二级指针
int src_linesize;
int src_nb_samples = 1024;
// 输出参数
int64_t dst_ch_layout = AV_CH_LAYOUT_STEREO;
int dst_rate = 44100;
enum AVSampleFormat dst_sample_fmt = AV_SAMPLE_FMT_S16;
int dst_nb_channels = 0;
uint8_t **dst_data = NULL; //二级指针
int dst_linesize;
int dst_nb_samples;
int max_dst_nb_samples;
// 输出文件
const char *dst_filename = NULL; // 保存输出的pcm到本地,然后播放验证
FILE *dst_file;
int dst_bufsize;
const char *fmt;
// 重采样实例
struct SwrContext *swr_ctx;
double t;
int ret;
if (argc != 2) {
fprintf(stderr, "Usage: %s output_file\n"
"API example program to show how to resample an audio stream with libswresample.\n"
"This program generates a series of audio frames, resamples them to a specified "
"output format and rate and saves them to an output file named output_file.\n",
argv[0]);
exit(1);
}
dst_filename = argv[1];
dst_file = fopen(dst_filename, "wb");
if (!dst_file) {
fprintf(stderr, "Could not open destination file %s\n", dst_filename);
exit(1);
}
// 创建重采样器
/* create resampler context */
swr_ctx = swr_alloc();
if (!swr_ctx) {
fprintf(stderr, "Could not allocate resampler context\n");
ret = AVERROR(ENOMEM);
goto end;
}
// 设置重采样参数
/* set options */
// 输入参数
av_opt_set_int(swr_ctx, "in_channel_layout", src_ch_layout, 0);
av_opt_set_int(swr_ctx, "in_sample_rate", src_rate, 0);
av_opt_set_sample_fmt(swr_ctx, "in_sample_fmt", src_sample_fmt, 0);
// 输出参数
av_opt_set_int(swr_ctx, "out_channel_layout", dst_ch_layout, 0);
av_opt_set_int(swr_ctx, "out_sample_rate", dst_rate, 0);
av_opt_set_sample_fmt(swr_ctx, "out_sample_fmt", dst_sample_fmt, 0);
// 初始化重采样
/* initialize the resampling context */
if ((ret = swr_init(swr_ctx)) < 0) {
fprintf(stderr, "Failed to initialize the resampling context\n");
goto end;
}
/* allocate source and destination samples buffers */
// 计算出输入源的通道数量
src_nb_channels = av_get_channel_layout_nb_channels(src_ch_layout);
// 给输入源分配内存空间
ret = av_samples_alloc_array_and_samples(&src_data, &src_linesize, src_nb_channels,
src_nb_samples, src_sample_fmt, 0);
if (ret < 0) {
fprintf(stderr, "Could not allocate source samples\n");
goto end;
}
/* compute the number of converted samples: buffering is avoided
* ensuring that the output buffer will contain at least all the
* converted input samples */
// 计算输出采样数量
max_dst_nb_samples = dst_nb_samples =
av_rescale_rnd(src_nb_samples, dst_rate, src_rate, AV_ROUND_UP);
/* buffer is going to be directly written to a rawaudio file, no alignment */
dst_nb_channels = av_get_channel_layout_nb_channels(dst_ch_layout);
// 分配输出缓存内存
ret = av_samples_alloc_array_and_samples(&dst_data, &dst_linesize, dst_nb_channels,
dst_nb_samples, dst_sample_fmt, 0);
if (ret < 0) {
fprintf(stderr, "Could not allocate destination samples\n");
goto end;
}
t = 0;
do {
/* generate synthetic audio */
// 生成输入源
fill_samples((double *)src_data[0], src_nb_samples, src_nb_channels, src_rate, &t);
/* compute destination number of samples */
int64_t delay = swr_get_delay(swr_ctx, src_rate);
dst_nb_samples = av_rescale_rnd(delay + src_nb_samples, dst_rate, src_rate, AV_ROUND_UP);
if (dst_nb_samples > max_dst_nb_samples) {
av_freep(&dst_data[0]);
ret = av_samples_alloc(dst_data, &dst_linesize, dst_nb_channels,
dst_nb_samples, dst_sample_fmt, 1);
if (ret < 0)
break;
max_dst_nb_samples = dst_nb_samples;
}
// int fifo_size = swr_get_out_samples(swr_ctx,src_nb_samples);
// printf("fifo_size:%d\n", fifo_size);
// if(fifo_size < 1024)
// continue;
/* convert to destination format */
// ret = swr_convert(swr_ctx, dst_data, dst_nb_samples, (const uint8_t **)src_data, src_nb_samples);
ret = swr_convert(swr_ctx, dst_data, dst_nb_samples, (const uint8_t **)src_data, src_nb_samples);
if (ret < 0) {
fprintf(stderr, "Error while converting\n");
goto end;
}
dst_bufsize = av_samples_get_buffer_size(&dst_linesize, dst_nb_channels,
ret, dst_sample_fmt, 1);
if (dst_bufsize < 0) {
fprintf(stderr, "Could not get sample buffer size\n");
goto end;
}
printf("t:%f in:%d out:%d\n", t, src_nb_samples, ret);
fwrite(dst_data[0], 1, dst_bufsize, dst_file);
} while (t < 10);
ret = swr_convert(swr_ctx, dst_data, dst_nb_samples, NULL, 0);
if (ret < 0) {
fprintf(stderr, "Error while converting\n");
goto end;
}
dst_bufsize = av_samples_get_buffer_size(&dst_linesize, dst_nb_channels,
ret, dst_sample_fmt, 1);
if (dst_bufsize < 0) {
fprintf(stderr, "Could not get sample buffer size\n");
goto end;
}
printf("flush in:%d out:%d\n", 0, ret);
fwrite(dst_data[0], 1, dst_bufsize, dst_file);
if ((ret = get_format_from_sample_fmt(&fmt, dst_sample_fmt)) < 0)
goto end;
fprintf(stderr, "Resampling succeeded. Play the output file with the command:\n"
"ffplay -f %s -channel_layout %"PRId64" -channels %d -ar %d %s\n",
fmt, dst_ch_layout, dst_nb_channels, dst_rate, dst_filename);
end:
fclose(dst_file);
if (src_data)
av_freep(&src_data[0]);
av_freep(&src_data);
if (dst_data)
av_freep(&dst_data[0]);
av_freep(&dst_data);
swr_free(&swr_ctx);
return ret < 0;
}
输出out.pcm:
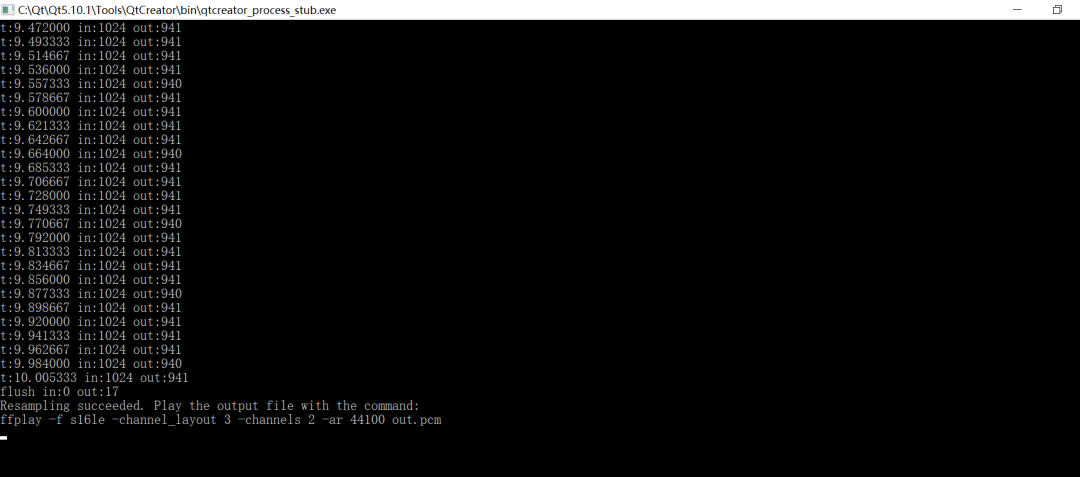
然后进行播放一下:
ffplay -f s16le -channel_layout 3 -channels 2 -ar 44100 out.pcm
四、总结:
好了,本周的分享就到这里了,我是txp,我们下期见!

文章评论