众所周知,FFmpeg作为开源音视频处理的瑞士军刀,以其开源免费、功能强大、方便易用的特点而十分流行。音视频处理的高计算复杂度使得性能加速成为FFmpeg开发永恒的主题。阿里云视频云媒体处理系统广泛借鉴了开源FFmpeg在性能加速方面的经验,同时根据自身产品和架构进行了端云一体媒体系统架构设计与优化,打造出高性能、高画质、低延时的端云协同的实时媒体服务。

阿里云智能视频云高级技术专家李忠,目前负责阿里云视频云RTC云端媒体处理服务以及端云一体的媒体处理性能优化,是FFmpeg官方代码的维护者及技术委员会委员,参与过多个音视频开源软件的开发。
本次分享的议题是《从FFmpeg性能加速到端云一体媒体系统优化》,主要介绍三个方面的内容:
一、FFmpeg中常见的性能加速方法
二、云端媒体处理系统
三、端+云的协同媒体处理系统
音视频开发者当前主要面临的挑战之一是对计算量的高需求,它不只是单任务算法优化,还涉及到很多硬件、软件、调度、业务层,以及不同业务场景的挑战。其次端、云、不同设备、不同网络,这些综合的复杂性现状,要求开发者要做系统性的架构开发与优化。
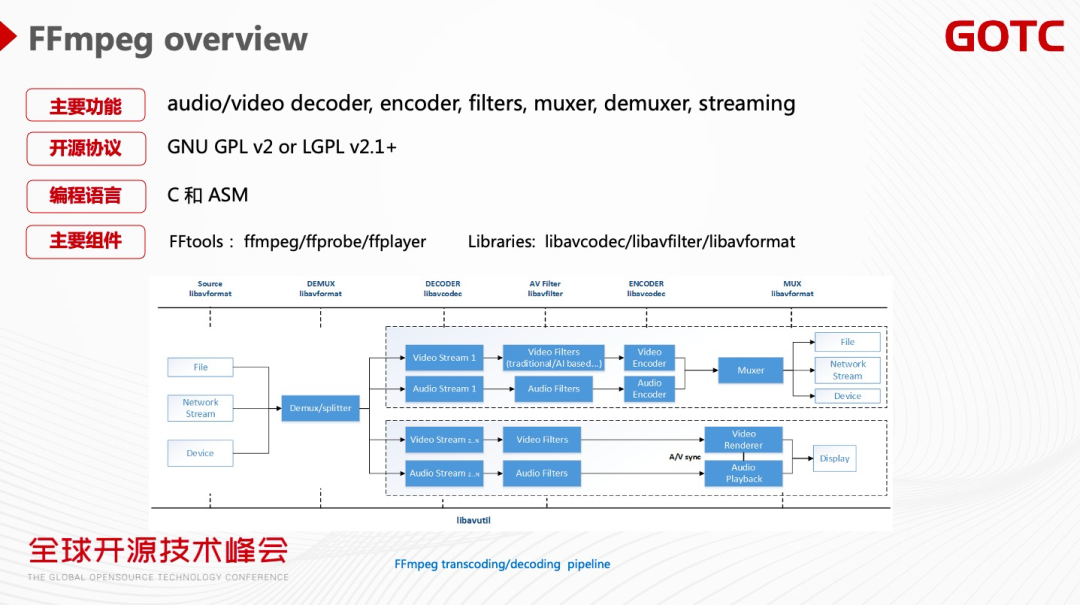
FFmpeg是一个非常强大的软件,包括音视频的解码编码、各种音视频的Filter 、各种协议的支持。作为一个开源软件FFmpeg主要的License是GPL或者LGPL,编程语言是C和汇编。它还提供了很多打开即用的命令行工具,比如转码的ffmpeg 、音视频解析的ffprobe、播放器ffplayer。其核心的Library 有负责编解码的 libavcodec、处理音视频的libavfilter 、支持各种协议的libavformat。
FFmpeg开发社区中,音视频性能优化是一个永恒的主题,其开源代码里也提供了非常多的经典性能优化的实现方法,主要是通用加速、CPU 指令加速、GPU 硬件加速。
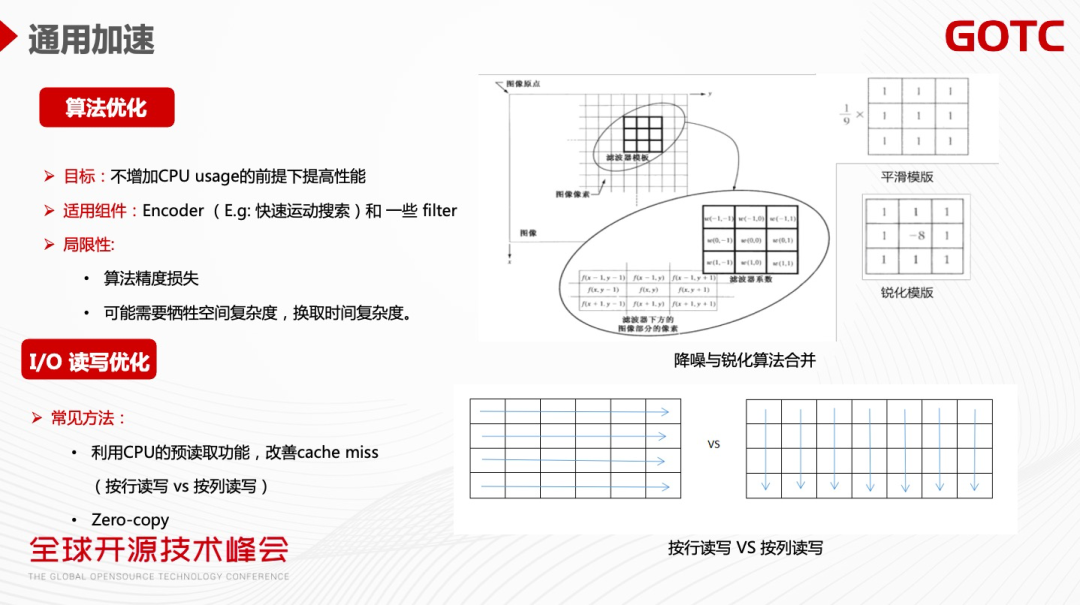
通用加速主要是算法优化、IO 读写优化、多线程优化。算法优化的目标是在不增加CPU Usage的前提下提高性能。最典型是编解码器的各种快速搜索算法,它可以在精度只有少数损失的情况下,大幅优化编码速度。各种前后处理Filter的算法也有类似的方法,也可以通过算法合并来减少冗余的计算,达到性能优化的目的。
下图是一种典型的降噪与锐化卷积模板,它需要做3乘3的矩阵卷积。我们可以看到,这里的锐化模板跟平滑模板是类似的,对于同时要做降噪和锐化的操作,只要在平滑的模板的基础上面做减法可以达到锐化化模板的结果,可以减少冗余的计算,提升性能。当然算法优化也存在局限性,比如编解码算法有精度上的损失,还可能需要牺牲空间复杂度换取时间复杂度。
第二种性能优化的方法是IO读写优化,常见方法是利用CPU 预读取来改善Cache Miss 。上图是通过两种读写的方法达到相同的运算结果,按行读写的方法比按列读写快,主要原因是CPU 在按行读写时可做预读取,在处理当前像素的时候,CPU 已经预读本行的其他像素,可以大大加速IO 读写的速度,提高性能。另外可以尽量减少Memory Copy,因为视频处理YUV 非常大,每读一帧对性能的损耗比较大。
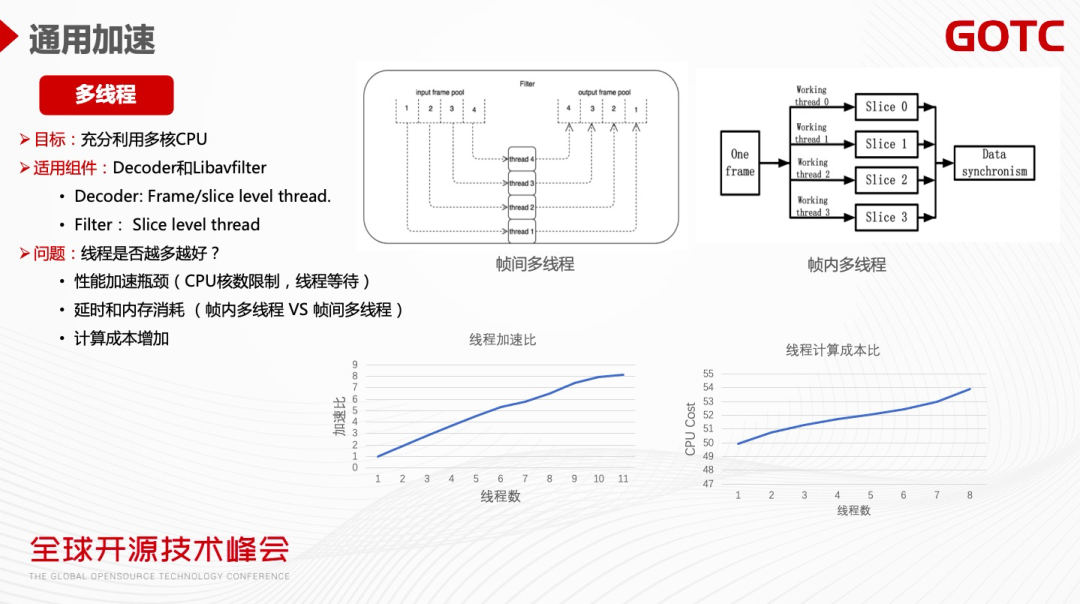
通用加速的多线程优化主要是利用CPU 多核做多线程的并行加速来大幅提升性能。上图中左下角的图表表明随着线程数的增加,性能提升了8倍。随之也会产生一个问题,普遍被使用的多线程加速,线程数是不是越多越好呢?
首先,因为CPU 核数限制,多线程等待和调度,多线程优化会碰到性能瓶颈。以左下角的图表为例,线程数等于10的加速比跟线程数等于11时非常接近,可以看出多线程优化存在边际效应的递减,同时也会带来延时和内存消耗的增加(尤其是普遍使用的帧间多线程)。
第二,帧间(Frame level)多线程需要建立Frame Buffer Pool 进行多线程并行,这需要缓冲很多帧,对于延迟非常敏感的媒体处理,比如低延时直播、RTC ,会带来比较大的负面效应。与之对应的是,FFmpeg 支持帧内(Slice level)的多线程,可以把一帧划分成多个Slice,然后做并行处理,这样能够有效避免帧间的Buffer 延迟。
第三,当线程数增多,线程同步和调度的成本也会增加。以右下图的一个FFmpeg Filter 加速为例,随着线程数的增加,CPU Cost 也在明显增加, 且图表曲线末端开始往上倾斜,这表明其成本的增加变得更明显。
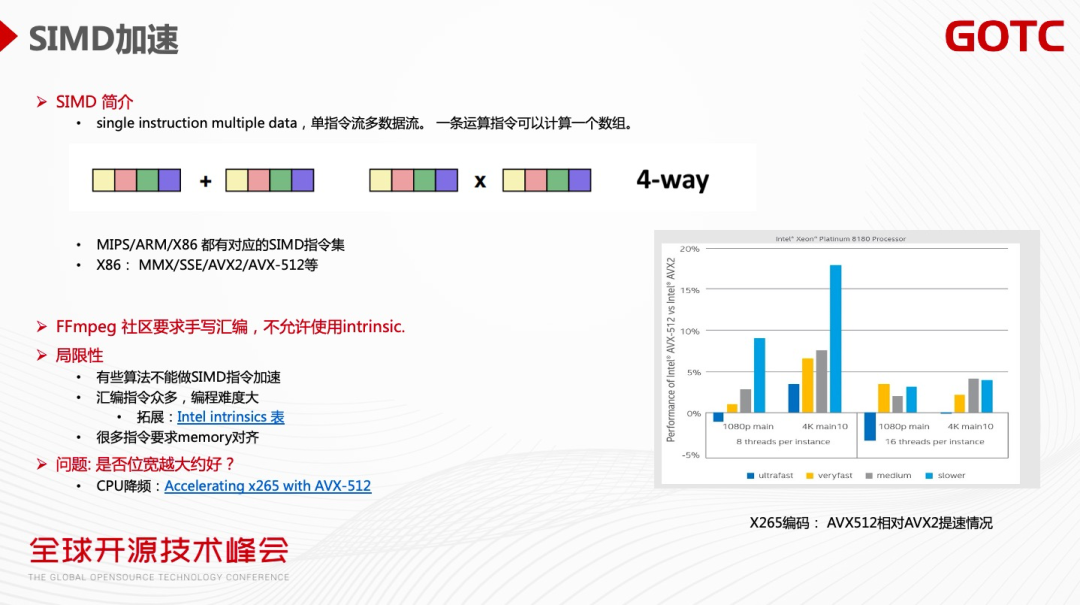
CPU 指令加速即SIMD(单指令多数据流)指令加速。传统通用的寄存器和指令,一条指令处理一个元素。但一条SIMD指令可以处理一个数组中的多个元素,从而达到非常显著的加速效果。
现在主流的CPU 架构都有对应的SIMD 指令集。X86架构SIMD指令包括MMX指令、SSE指令、AVX2、AVX-512指令。其中AVX-512的一条指令可处理512个bits,加速效果非常明显。
FFmpeg 社区的SIMD指令写法包括内联汇编、手写汇编。FFmpeg 社区不允许使用intrinsic编程,原因是它对编译器的版本存在依赖,不同编译器编译出的代码及其加速效果也是不一致的。
虽然SIMD 指令有好的加速效果,但它也存在一定的局限性。
首先,很多的算法不是并行处理的,不能进行SIMD指令优化。
其次,编程难度比较大。汇编编程的难度就要大些,另外SIMD指令对编程有一些特殊的要求,比如Memory 对齐。AVX-512 要求Memory 最好能够做到64字节对齐,如果没有对齐的话,可能会有性能上的损耗,甚至会引起程序的Crash。
我们看到不同的CPU 厂商都在做指令集竞赛,支持的位宽越来越多,从SSE 到AVX2再到AVX-512 ,位宽显著增加。那位宽是不是越宽越好?上图可以看到X265编码AVX 512相对AVX 2 的提速情况,AVX 512的位宽是AVX 2位宽的两倍,但性能提升实际上往往远达不到一倍提升,甚至达不到10%。在某些情况下,AVX 512的性能会比AVX 2 还要低。
首先,一次性的数据输入可能并没有512 bits这么多,可能只有128 bits或者是256 bits。
第二,有很多的复杂运算步骤(如编码器)不能做指令集的并行。
第三,AVX 512功耗较高,会引起CPU 的降频,导致CPU 整体处理的速度会有所下降。我们看上图的X265 ultrafast档次编码,AVX 512的编码比AVX 2 还要慢。(详见:https://networkbuilders.intel.com/docs/accelerating-x265-the-hevc-encoder-with-intel-advanced-vector-extensions-512.pdf)
FFmpeg比较主流的硬件加速是GPU 加速。硬件加速接口分为两大块,一是硬件厂商提供不同的加速接口。英特尔主要提供QSV和VAAPI的接口,英伟达提供NVENC、CUVID、NVDEC 、VDPAU,AMD提供AMF和VAAPI的接口。二是不同的OS 厂商提供不同的加速接口和方案,比如Windows 的DXVA2,安卓的 MediaCodec ,苹果的VideoToolbox 。
硬件加速可以显著提升媒体处理的性能,但是它也会带来一些问题。
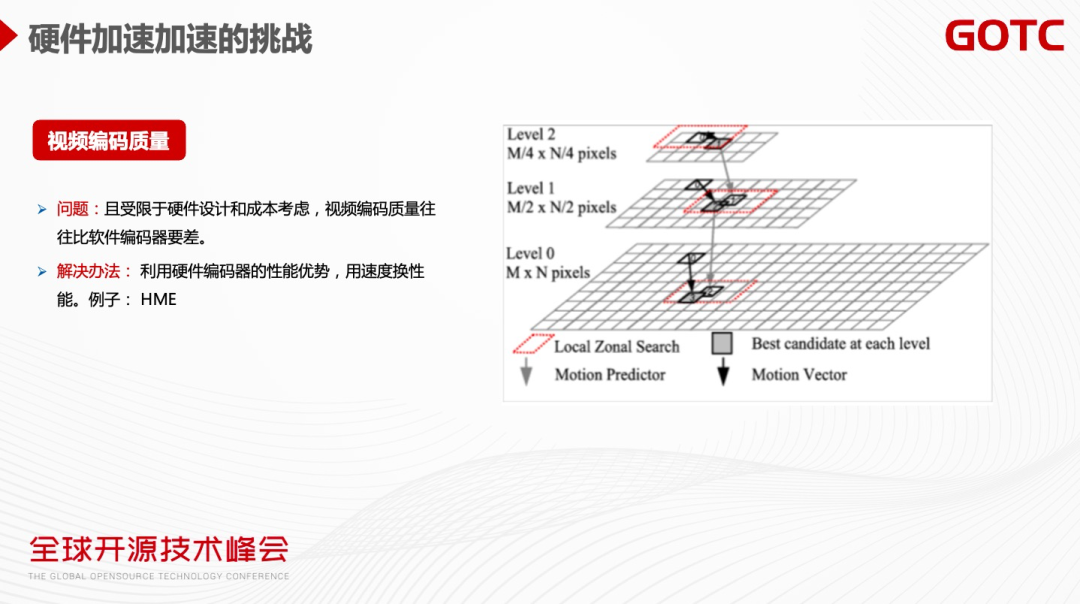
第一,硬件的编码质量受限于硬件的设计及成本,硬件编码的质量往往是会比软件编码质量差。但硬件编码有非常明显的性能优势,可以用性能去换编码质量。下图的例子可看出,硬件编码器运动搜索的窗口比较小,导致编码质量的下降。其解决方法是HME算法,在搜索窗口比较小的情况下,先把比较大的Picture缩放到非常小的Picture,在这个Picture 上做运动搜索,再逐级做搜索和放大,这样可以显著提高运动搜索的范围,然后找到最匹配的块,从而改善编码质量。
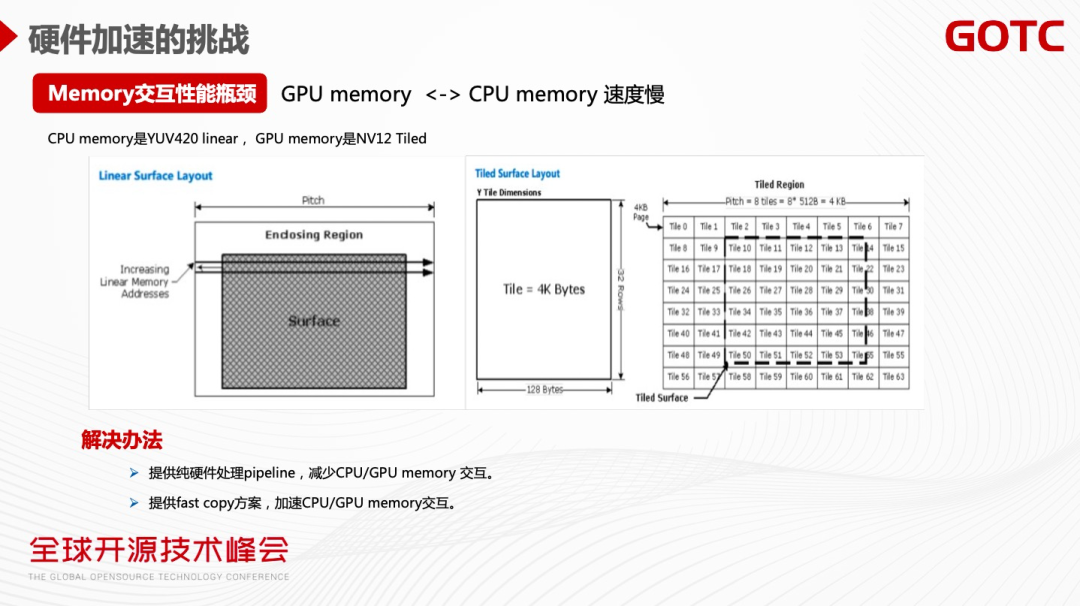
第二,硬件加速的CPU 和GPU 的Memory Copy 性能交互会带来性能的下降。
CPU 和GPU 的交互不仅仅是简单的数据搬移过程,实际上要做对应的像素的格式转换,比如CPU 是I420 linear 格式,GPU擅长矩阵运算,采用NV12 Tiled格式。
这种内存格式的转化,会带来明显的性能损耗。可以通过构建纯硬件的Pipeline ,有效的规避CPU/GPU Memory 交互的问题。当CPU 和GPU 必须交互的情况下,可以采取Fast Memory Copy 的方式,采用GPU 去做Memory Copy ,加速这一过程。
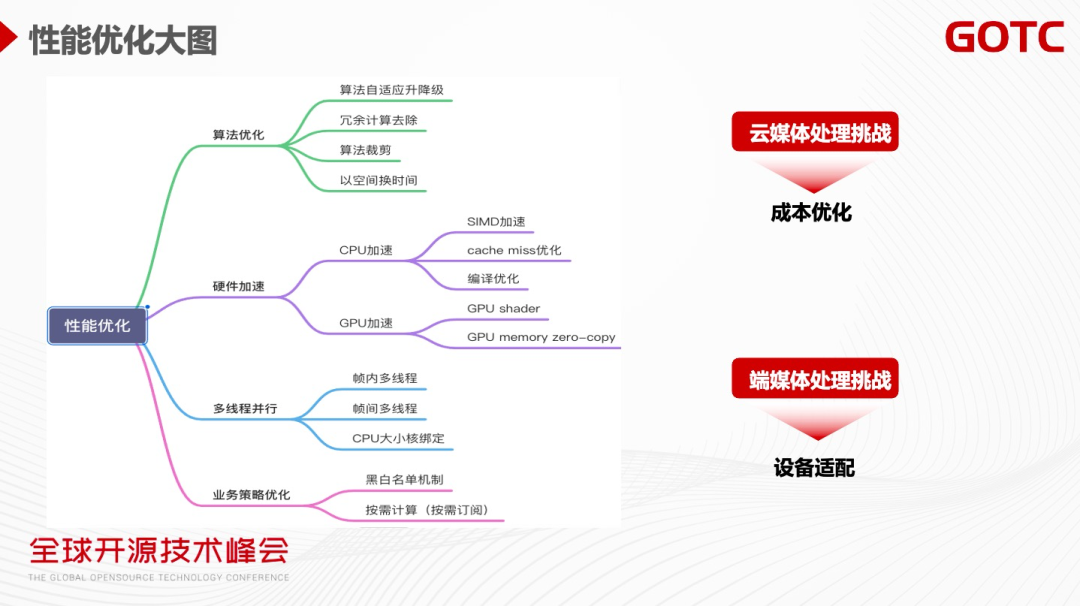
下图是性能优化的总结大图。除了前面提到一些优化方法外,客户端上的媒体处理还有一些特殊性,比如手机CPU 是大小核架构,线程调度如果调度到小核上,它的性能会明显比大核要差,导致性能的不稳定。
另外很多的算法不管如何优化,在某些机型上就是无法跑通,这时要在业务策略上面做优化,比如制定黑白名单,不在支持名单的机器就不开启该算法。
对于媒体处理来说分为两大挑战,一是云端的成本优化,二是客户端设备适配及兼容。下图是云端媒体处理的典型系统:包括单机层、集群调度层、业务层。
单机层包括FFmpeg Pipeline处理框架、编解码、硬件层。以云端转码系统为例,它的核心技术指标包括画质、处理速度、延时、成本。画质方面,阿里云视频云独创了窄带高清的技术以及S265编码技术,可以显著改善编码画质。处理速度和延时优化方面,我们广泛借鉴FFmpeg性能加速方法,比如SIMD指令、多线程加速以及异构计算的支持。成本是一个比较复杂的系统,它会包括调度层、单机层、业务层,需要进行快速的弹性扩缩容,单机资源精确画像,减少单任务的计算成本。
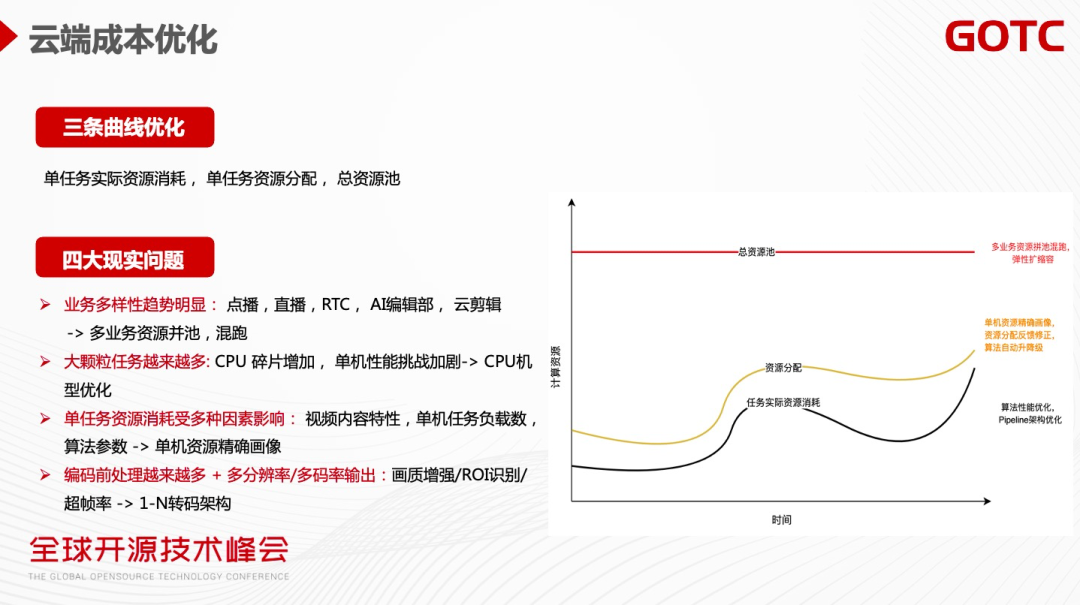
云端成本优化的核心是围绕三条曲线去做优化,针对单任务实际资源消耗、单任务资源预估分配、总资源池这三条曲线分别做对应的优化。在优化过程中需要面对四个现实的问题:
第一,在视频云的业务里,业务多样性的趋势会越来越明显,业务包括点播、直播、RTC、 AI 编辑部、云剪辑。业务多样性带来的挑战是如何将多种业务共用一个资源池做混跑。
第二,大颗粒的任务越来越多,几年前主流视频是480P,而现在的主流是720P、1080P的处理任务,未来可以预见4K、8K、VR这样的媒体处理会越来越越多,这带来挑战是对单机性能的渴求会越来越大。
第三,调度层需要预估每个任务的资源消耗,但单机任务的实际消耗会受到非常多因素的影响。视频内容的复杂度,不同算法参数,多进程的切换,都会影响任务资源消耗。
第四,编码的前处理会越来越多,同时一个转码任务需要做多码率或者多分辨的输出。各种前处理(画质增强/ROI识别/超帧率/超分等)都会大幅增加的处理成本。
实际任务的资源消耗优化,主要方法是每个任务的性能优化、算法的性能优化、Pipeline 架构优化。
资源的分配核心目标就是使上图的黄色曲线能够不断地贴近黑色曲线,减少资源分配的浪费。当资源分配不足的情况下,可以做算法的自动升降级,以免线上任务出现卡顿,比如编码器的preset从medium档降低为fast档。
对于总资源池优化,首先可以看到黄色曲线有波峰波谷,如果当前点播任务处在波谷的状态,可以把直播的任务调过来,这样可以在整个池子的峰值没有变化的情况下跑更多的任务。第二,总资源池怎么样能够快速的弹性,在一定时间窗口内能够快速释放掉资源,降低资源池消耗,这也是调度需要考虑的成本优化的核心。
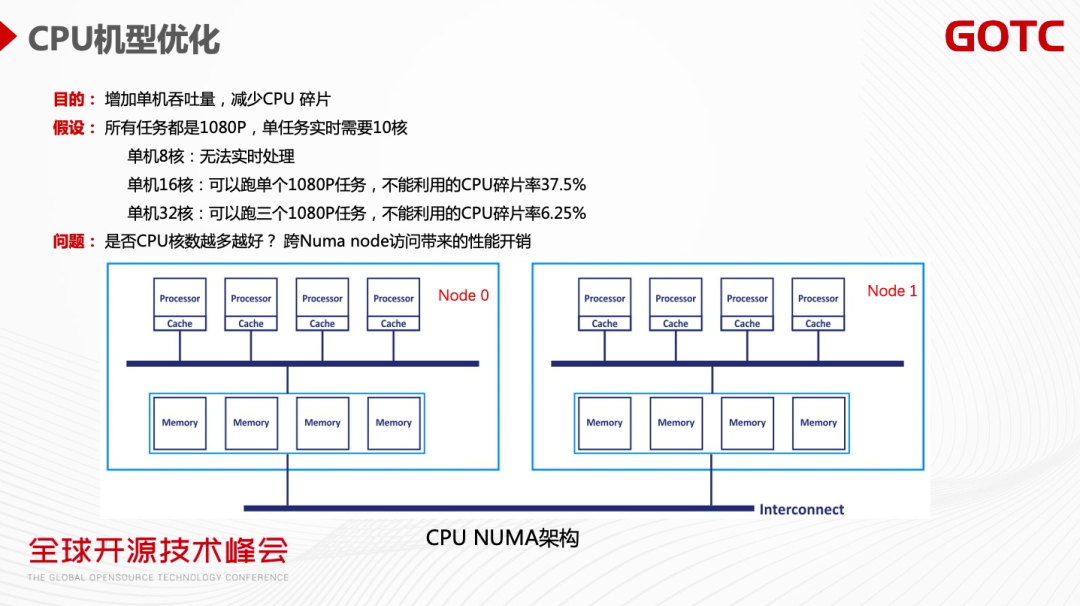
CPU 机型优化的主要目标是增加CPU 单机的吞吐量,减少CPU 碎片。上图描述了多核CPU带来的优势。但多核CPU也可能会带来多个NUMA node直接的内存访问,从而导致性能下降。
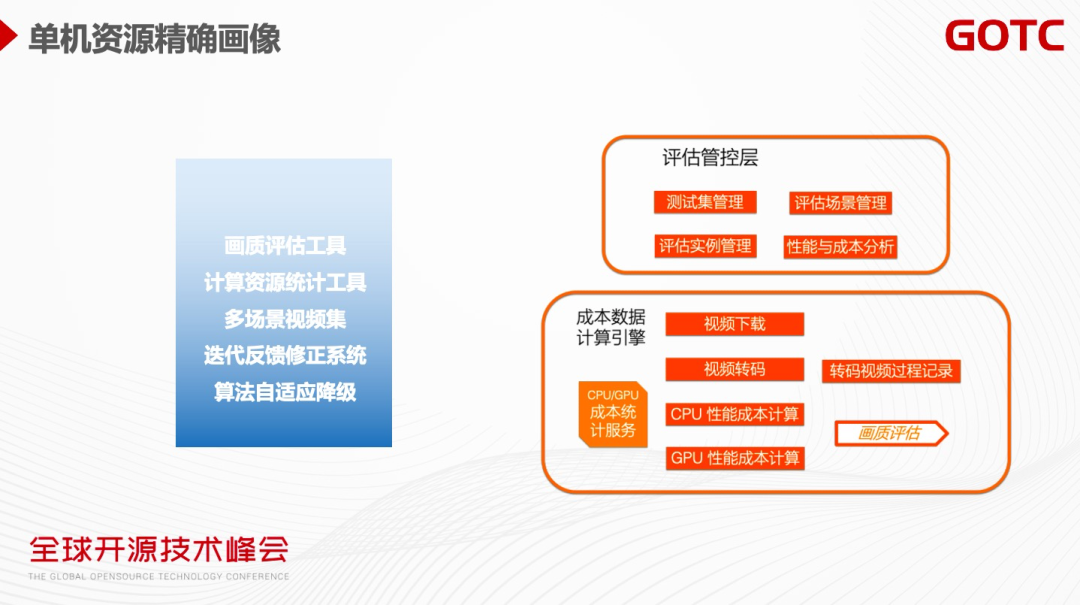
单机资源精确画像主要目标是能够精确知道每个任务它需要多少资源,它是一个系统性的工具,需要有画质评估的工具、计算资源统计的工具、需要包括各种多场景复杂的视频集、以及能够去做各种计算资源和迭代反馈,修正成本计算的消耗,指导算法的自适应升降级。
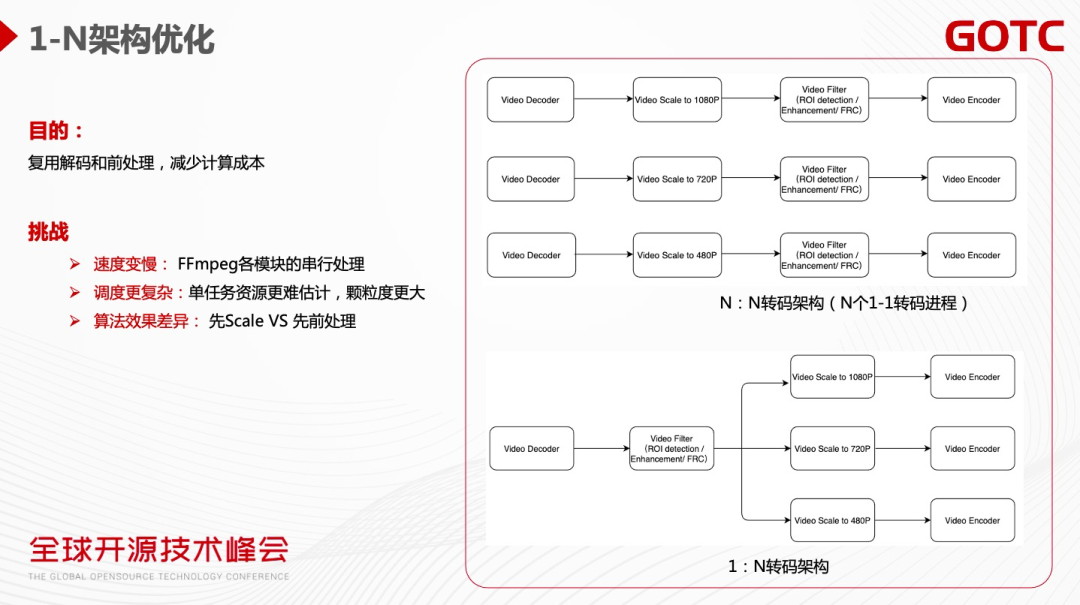
一个转码任务可能要输出不同的分辨率和码率,传统的方法是起N个独立的一转一的进程。这样的架构显而易见会有一些问题,比如冗余的解码计算和编码前处理。一个优化方法是把这些任务做整合,从N到N的转码变成一到N的转码。这样视频解码和编码前处理都只需要做一次,从而达到成本优化的目标。
1-N转码也会带来新的挑战。FFmpeg转码工具支持1-N转码,但是各模块是串行处理的,单个一转N任务的速度会比单个一转一的任务慢。第二,调度的挑战,单任务资源颗粒度会更大,所需要资源的分配也更难估计。第三,算法效果的差异,因为有的视频的前处理可能是在Scale 之后,对于一到N的转码架构会把前处理放到Scale 之前。媒体处理的流程变化会引起算法效果的差别(通常这个问题不是特别大,因为画质在处理前没有Scale 损失,在Scale 前做处理反而是更好的)。
端侧媒体处理的优势是可利用手机端现成的算力来降低成本,所以理想情况是充分利用各种端侧的算力,每个算法都做非常好的性能优化、端侧的适配,在每个端都能零成本的落地。
第一,端侧适配的困难。需要大量的OS 硬件机型适配。
第二,算法接入的困难。现实情况下不可能把所有的算法在所有端上都进行优化,所以端侧的性能瓶颈会导致算法落地困难。
第三,体验优化的困难。客户会有不同的SDK ,或者说阿里云的SDK 也会有不同的版本,SDK 本身存在碎片化导致一些方案难以落地。比如非标的H264编码,实际上H265编解码算法的落地也遇到挑战,一些设备并不支持H265。
第四,用户接入的困难,客户升级SDK 或替换SDK的周期比较漫长。
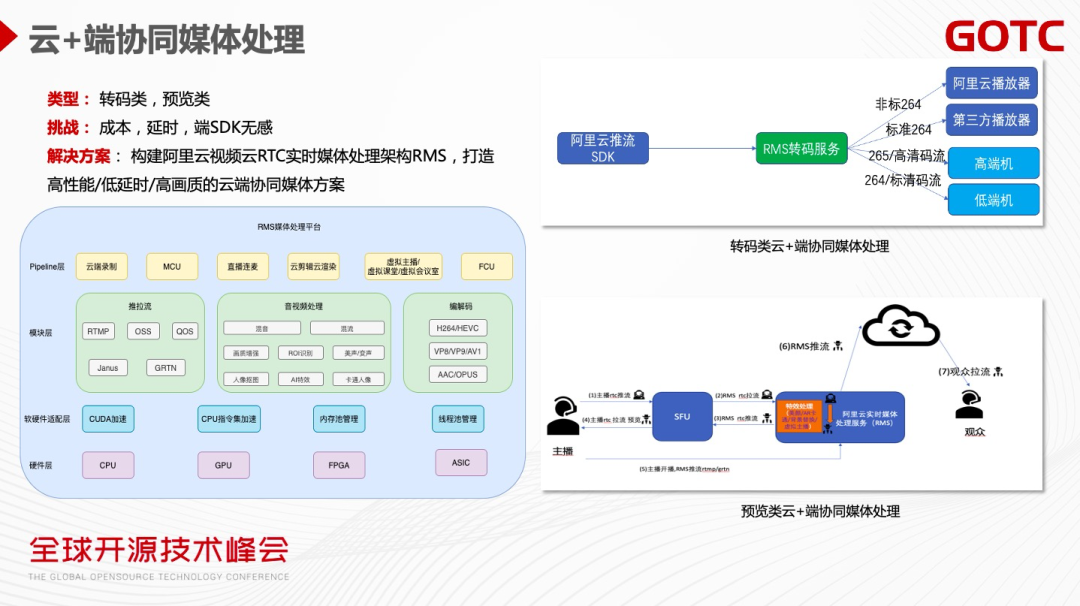
面对这样的现实,我们提出云和端协同的媒体处理解决方案。主要思路是通过云上处理+端侧渲染的方案,达到比较好的用户体验。
云和端的协同的媒体处理主要类型是转码类和预览类。转码类是单向的数据流。预览类需要把各种流先推到云端,再加各种特效,然后再拉回来给主播看效果是不是符合他的预期,最后再从CDN 推到观众端。
这样的方案也会碰到一些挑战。首先,云端处理会有计算成本的增加(当然可以有各种方式优化,因为客户端没有直接体感)。第二,延时会增加,云端的处理增加了链路的延时。
随着RTC技术越来越成熟,通过RTC低延时的传输协议,再加云端的各种成本优化,可以低成本/低延时地支持云上的媒体处理,打造一个云加端的实时媒体处理服务。阿里云视频云构建的RTC实时媒体处理服务RMS,可以做到高性能、低成本、高画质、低延时、更智能的云端协同媒体处理的方案。
上面的左图是RMS整体架构图,分为Pipeline 层、模块层、硬件适配层,硬件层。Pipeline 可以做各种业务场景的组装模块层,模块层是音视频处理的核心,实现各种AI 或者是低延时高画质的效果。
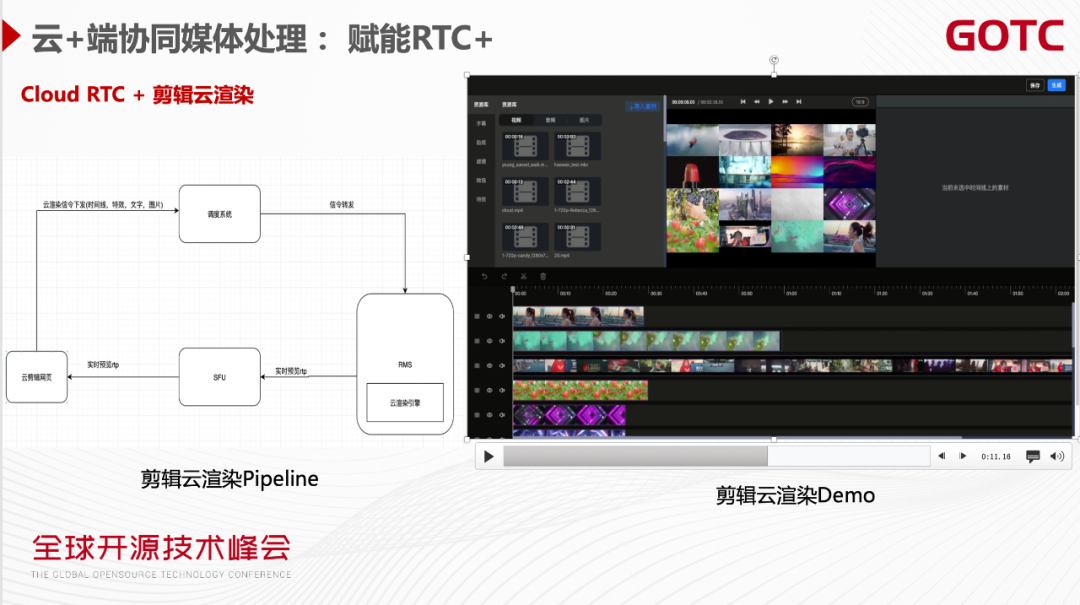
以剪辑云渲染为例,传统的剪辑方案要保证多端体验一致性及流畅的性能是比较困难的。我们的思路是端上只做指令的下发,视频的合成、渲染都是在云上实现,可以支持非常多的特效,也能够保证多端的效果一致性。

我们看下剪辑云渲染的Pipeline。云渲染的网页负责信令下发,通过调度层把剪辑指令转发到RMS媒体处理引擎做云上媒体处理的渲染,合成之后再编码通过SFU推流,最后在剪辑的网页端看剪辑效果。上图的Demo可以看到,网页把很多Track 合成一个Track ,4乘4的宫格在端上处理的话,在低端机跑起来是比较费力的,但云能够轻易跑出这样的效果。
高码率低清晰度的视频流到云端后,通过阿里云视频云的云端窄带高清技术处理,可以达到更高清晰度更低码率的目标。下图Demo中启用窄带高清后,视频的清晰度有明显的提升(码率也有显著下降)。
同时利用 RTC 低延时,再加AI 特效的处理,可以产生很多有意思的场景。把真人的流推到云端,云端做卡通人像的输出处理,然后输出卡通人像做实时的交流,在会场的观众相互看到的是各自的卡通人像。
搭配云端的抠图技术很容易就能实现虚拟的教育场景和虚拟的会议室场景。比如虚拟课堂,可以把人像抠到PPT 里增加整个效果演示的沉浸感。虚拟会议室里不同的参会者通过抠图把他们排列到虚拟的会议室场景里来,达到虚拟会议室的效果。
觉得不错,请点个在看呀







 觉得不错,请点个在看呀
觉得不错,请点个在看呀
文章评论