作者论坛账号:白云点缀的藍
前言
继续使用上一篇文章《利用活跃变量分析来去掉vmp的大部分垃圾指令》的样本。有个小问题先需要说明一下,加壳的样本在wow64环境、32位环境和linux wine环境下,样本的执行流程是不同的,因为vmp会根据环境来调整通过sysenter或syscall指令来进行系统调用,比如NtProtectVirtualMemory函数。如果程序是32位的,qiling会设置成32位环境。所以利用qiling模拟执行和调试器的执行流程可能会不一样。本篇文章分析vmp的大致思路是通过机器学习对handle进行分类,然后分别处理和化简。
handle的提取
通过机器学习来进行分类,首先要提取出handle以及它的特征向量。为了能够方便的提取出handle,本文继续使用qiling模拟执行记录样本的vmp壳程序每一条指令以及eax, ebx, ecx, edx, esi, edi, ebp, esp, eip寄存器的值,记录这些寄存器的值是为了方便后面的化简。模拟执行的代码在traceCode.py文件,保存后的文件大小有1G多,大部分都是循环产生的重复指令。然后对这些指令序列根据jmp register和ret指令进行分割。分割后的指令序列需要删除一些因循环产生的重复指令。对于还有call指令的函数调用,需要把函数体对应的指令删除掉。vmp壳程序也是有一些正常函数的,比如一些字符串的解密函数和散列函数。handle的提取、分类和化简都在analyzeInsn.py文件中。主函数代码如下:
复制代码 隐藏代码def analyzeInsnTrace():
with open('G:\\vmpAnalysis\\EliminateVmpJunkCode\\traceInsn.bin', 'rb') as f:
s = f.read()
insnExecInfoList = [] #保存待分析指令信息
i=0
point = 0
while(point < len(s)): #007FFFE8和006D0321两处进行某种循环运算
size = s[point]
point += 1
bInsn = s[point:point+size]
point += size
eax,ebx,ecx,edx,esi,edi,ebp,esp,eip = struct.unpack('IIIIIIIII',s[point:point+36])
point += 36
insn = list(md.disasm(bInsn, eip))[0]
if(capstone.x86_const.X86_INS_JMP == insn.id and \
capstone.x86_const.X86_OP_IMM == insn.operands[0].type):#jmp 0xXXXXXXXX;00416BC1: jmp far ;X86_INS_LJMP
continue
#elif(capstone.x86_const.X86_INS_SYSENTER == insn.id): #wow64环境下通过天堂门进入NtProtectVirtualMemory
# continue
#if(0x0068304e == eip):
# return
insnInfo = InsnExecInfo(insn, eax,ebx,ecx,edx,esi,edi,ebp,esp)
insnExecInfoList.append(insnInfo)
#jmp reg
if((capstone.x86_const.X86_INS_JMP == insn.id and capstone.x86_const.X86_OP_REG == insn.operands[0].type) or\
capstone.x86_const.X86_INS_RET == insn.id):
insnExecInfoList = HandleCallInsn(insnExecInfoList)
if(capstone.x86_const.X86_INS_CALL != insnExecInfoList[-1].csInsn.id):#call里面又有call,通常handle不以call结尾
insnExecInfoList = DeleteRedundantInsnInfo(insnExecInfoList)
insnExecInfoList = GetUsefulInsnList(insnExecInfoList)
TranslateHandle(insnExecInfoList)
insnExecInfoList.clear()
DeleteRedundantInsnInfo函数删除掉循环产生的重复指令,HandleCallInsn函数用来处理含有call的调用。GetUsefulInsnList在提取handle的特征前需要去掉handle一些不需要的指令,比如handle地址的计算和一些寄存器轮转相关的指令。这个可以通过一个简单的污点分析实现,保留与写内存操作相关的指令,实现代码在TaintAnalysis函数中。
比如有如下handle:
复制代码 隐藏代码mov ecx, [esi]
add esi, 4
lea ebp, [ebp-1]
movzx edx, byte ptr [ebp+0]
xor dl, bl
ror dl, 1
add dl, 0B3h
neg dl
not dl
neg dl
xor bl, dl
mov [esp+edx+0], ecx
sub ebp, 4
mov edx, [ebp+0]
xor edx, ebx
dec edx
rol edx, 1
not edx
inc edx
bswap edx
xor ebx, edx
add edi, edx
push edi
retn
有用的指令就这么两条:
复制代码 隐藏代码mov ecx, [esi]
mov [esp+edx+0], ecx
handle的特征提取及模型训练
特征可以人工选取或者通过自然语言处理的一些模型得到,比如word2vec和bert模型,把汇编指令看成一个单词,handle看成一个句子。通过自然语言处理提取代码的特征可以参考一些代码相似度检测相关的论文。本文采用人工定义的特征和kmeans聚类算法,主要是实现简单,可以快速验证这个思路是否可靠。一个handle的特征定义如下:
复制代码 隐藏代码push指令的个数
pop指令的个数
数据转移指令的个数
算术运算指令的个数
位操作指令的个数
串操作指令的个数
call指令的个数
分支指令的个数
其它一些需要分析的指令个数(sysenter、cpuid、jmp far)
立即数的个数
指令总数
代码实现如下:
复制代码 隐藏代码def ExtractFeature(insnExecInfoList):
NumOfPushInsn = 0
NumOfPopInsn = 0
NumOfDataTransferInsn = 0 #数据转移指令的个数
NumOfArithmeticInsn = 0 #算术运算指令的个数
NumOfBitManipulationInsn = 0 #位操作指令的个数
NumOfStringInsn = 0 #串操作指令的个数
NumOfCall = 0 #call指令的个数
NumOfBranchInsn = 0 #分支指令的个数
NumOfOtherInsn = 0
NumOfImmOperand = 0 #立即数的个数
NumOfInsn = len(insnExecInfoList)
for insnInfo in insnExecInfoList:
insn = insnInfo.csInsn
#print("%08x %s %s" % (insn.address, insn.mnemonic, insn.op_str))
if(insn.id in g_pushInsnId):
NumOfPushInsn += 1
elif(insn.id in g_popInsnId):
NumOfPopInsn += 1
elif(insn.id in g_dataTransferInsnId):
NumOfDataTransferInsn += 1
elif(insn.id in g_arithmeticInsnId):
NumOfArithmeticInsn += 1
elif(insn.id in g_bitManipulationInsnId):
NumOfBitManipulationInsn += 1
elif(insn.id in g_stringInsnId):
NumOfStringInsn += 1
elif(capstone.x86_const.X86_INS_CALL == insn.id): #操作数可能为立即数
NumOfCall += 1
continue
elif(insn.group(capstone.x86_const.X86_GRP_BRANCH_RELATIVE)): #操作数可能为立即数
NumOfBranchInsn += 1
continue
elif(insn.id in g_otherInsnId):
NumOfOtherInsn += 1
for op in insn.operands:
if(capstone.x86_const.X86_OP_IMM == op.type):
NumOfImmOperand += 1
return [NumOfPushInsn, NumOfPopInsn, NumOfDataTransferInsn, NumOfArithmeticInsn, NumOfBitManipulationInsn, \
NumOfStringInsn, NumOfCall, NumOfBranchInsn, NumOfOtherInsn, NumOfImmOperand, NumOfInsn]
壳程序所有handle的提取在ExtractHandleFeature函数实现。特征提取后,通过t-sne对这些数据降维然后可视化,效果如下: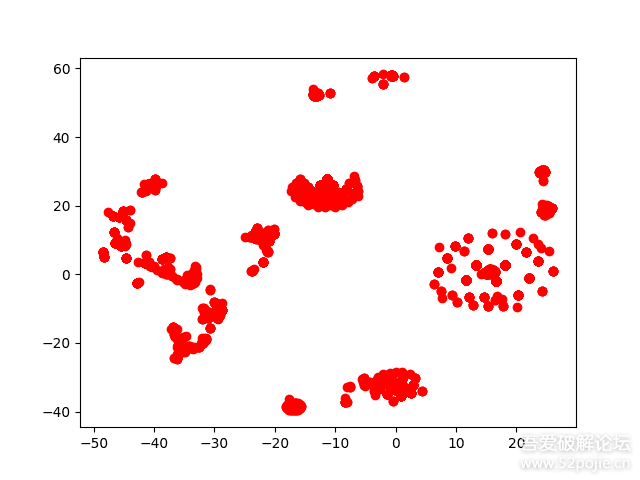
可以看出这数据还是具有可分性的,一个簇一类,大致可以划分为14类。数据的可视化和模型的训练相关的代码在model.py。代码如下:
复制代码 隐藏代码g_dataDict = dict()
with open('handleFeature.txt','r') as f:
dataDictStr = f.read()
g_dataDict = json.loads(dataDictStr)
f.close()
data = []
for addr in g_dataDict:
data.append(g_dataDict[addr])
x_train = np.array(data)
#model = joblib.load('kmeans.pkl')
#labels = model.labels_
model = KMeans(n_clusters=14)
model.fit(x_train)
joblib.dump(model,'kmeans.pkl')
tsne = TSNE(perplexity=30, n_components=2, random_state=0)
x_2d = tsne.fit_transform(x_train)
plt.figure()
color = ['c', 'b', 'g', 'r', 'm', 'y', 'k', 'bisque', 'slategray', 'pink', 'grey', 'chocolate', 'aqua', 'lime', 'gold']
for i in range(len(x_2d)):
x = x_2d[i]
plt.scatter(x[0],x[1], c='red')#c=color[labels[i]]
plt.savefig("Figure_Perp30.png")
plt.show()
部分分类出的handle如下:
复制代码 隐藏代码0077e533 push 0xfeddf3fd
0077e538 call 0x64d713
0064d713 push esi
0064d71c push ebp
0064d71d push edx
0064d71e push ecx
0064d71f pushfd
0064d726 push eax
0064d728 push edi
0064d72c xchg edi, edi
0064d72e push ebx
0064d734 shld di, sp, 0x8f
0064d739 mov edx, 0
0064d745 push edx
0064d748 mov ebp, dword ptr [esp + 0x28]
0064d74c sub ebp, 0x1d6f2625
0064d752 bswap ebp
0064d75b neg ebp
0064d76b not ebp
0064d772 sub ebp, 0x38be537b
0064d77f rol ebp, 3
0064d789 lea ebp, [ebp + edx]
0064d78d mov esi, esp
0064d797 inc edi
0064d798 sub esp, 0xc0
[10, 0, 6, 5, 2, 0, 1, 0, 0, 7, 25] 5
007c053c mov ecx, dword ptr [esi]
006b22f6 mov dword ptr [esp + edx], ecx
[0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 2] 0
007f839c mov edx, dword ptr [ebp]
007f83a7 xor edx, ebx
007f83a9 bswap edx
007f83ab not edx
007f83b1 rol edx, 1
007f83bc xor edx, 0x6f3b0b63
007f83c8 xor ebx, edx
007f83d9 mov dword ptr [esi], edx
[0, 0, 3, 0, 5, 0, 0, 0, 0, 2, 8] 4
0064fb73 mov eax, dword ptr [esi]
0064fb7d mov edx, dword ptr [esi + 4]
006b7076 add eax, edx
006b707f mov dword ptr [esi + 4], eax
006b7087 pushfd
006b708a pop dword ptr [esi]
[1, 1, 3, 1, 0, 0, 0, 0, 0, 0, 6] 10
0081c8fb mov ecx, dword ptr [esi]
0081c903 mov edx, dword ptr [esi + 4]
0081c906 not ecx
006e651b not edx
006e651e or ecx, edx
0069a067 mov dword ptr [esi + 4], ecx
0069a06a pushfd
0069a072 pop dword ptr [esi]
[1, 1, 3, 0, 3, 0, 0, 0, 0, 0, 8] 8
00744a93 mov esi, dword ptr [esi]
00744a9e sub ebp, 4
00744aa4 mov ecx, dword ptr [ebp]
00744aa8 xor ecx, ebx
00744aab rol ecx, 2
00744ab5 lea ecx, [ecx - 0x1f6841de]
00744ac4 xor ecx, 0x309024f1
00744aca rol ecx, 2
00744acd xor ebx, ecx
00744acf add edi, ecx
007aea6c lea edx, [esp + 0x60]
007aea70 cmp esi, edx
0071dc9f ja 0x7c537e
007c537e push edi
007c537f ret
[1, 0, 4, 3, 5, 0, 0, 1, 0, 4, 15] 2
006db779 mov eax, dword ptr [esi]
006db782 add esi, 4
006db78f mov edi, eax
0071f41c mov ebx, edi
0071f41e xor ecx, 0x75526e46
0071f424 mov edx, 0
0071f429 sbb bp, 0x6722
0071f42e setae cl
0071f431 sub ebx, edx
0071f433 lea ebp, [0x71f433]
0071f43e sub edi, 4
0071f444 mov ecx, dword ptr [edi]
0071f449 xor ecx, ebx
0071f44b xor ecx, 0x34ce6bee
0071f451 not ecx
0071f455 neg ecx
0071f459 xor ecx, 0xb326d42
0071f466 xor ebx, ecx
0071f468 add ebp, ecx
0071f46a jmp ebp
[0, 0, 6, 6, 6, 0, 0, 0, 0, 7, 20] 6
007dbb9c movzx edx, byte ptr [ebp]
007dbba3 add ebp, 1
007dbbb0 xor dl, bl
007dbbb2 not dl
007dbbba xor dl, 0x12
007dbbc4 add dl, 0xd2
007dbbcf xor dl, 0x30
007dbbd7 not dl
007dbbe0 xor bl, dl
007dbbe2 push ebp
007dbbe3 push edi
007dbbef push ebx
007dbbf0 mov ebp, esi
007dbbf5 mov ebx, edx
007dbbfb mov edx, ebx
007dbc00 shl edx, 2
007dbc0f mov eax, ebp
007dbc11 lea eax, [eax + edx]
007dbc16 mov dword ptr [ebp - 4], eax
007dbc1d test ebx, ebx
006f49e6 je 0x675996
006f49ec mov eax, dword ptr [ebp + ebx*4]
0070a50a push eax
00739240 sub ebx, 1
00675990 jne 0x6f49ec
00675996 mov eax, dword ptr [ebp]
0064251e call eax
00642520 mov ebp, dword ptr [ebp - 4]
00642527 mov dword ptr [ebp], eax
00642531 mov esi, ebp
00642539 pop ebx
0064253f pop edi
0064254b pop ebp
0064254c mov ecx, dword ptr [ebp]
00642554 add ebp, 4
0064255a xor ecx, ebx
0064255c rol ecx, 1
00818174 not ecx
0073abf7 inc ecx
0073abf8 ror ecx, 1
0078d48d lea ecx, [ecx + 0x491c2c38]
0078d493 bswap ecx
0078d49b xor ebx, ecx
0078d4a1 add edi, ecx
007c4fa8 push edi
007c4fa9 ret
[5, 3, 14, 6, 13, 0, 1, 2, 0, 9, 46] 1
handle下面一行是特征向量和类别,大部分handle的分类还是正确的。错误分类的也有,比如:
复制代码 隐藏代码006d7174 mov esp, esi
006d717b pop ebp
006d717e pop ecx
006d7180 pop ebx
006d7181 pop eax
006d7185 pop edi
006d7187 pop edx
006d718d pop esi
006d718e popfd
006d718f ret
这个handle归类为8,8和10应该分为同一类。为了提高正确率,可以重新定义其它的特征、调调参数或者使用其它模型,感兴趣的坛友可以去试试。
handle的化简
化简的思路是只保留和内存操作相关的指令,vmp是基于堆栈的虚拟机,执行过程含有大量的栈操作,本质上也是内存操作,把读写内存的操作数直接替换成绝对地址。比如如下handle:
复制代码 隐藏代码mov ecx, [esi]
mov [esp+edx+0], ecx
然后通过qiling模拟执行保留的寄存器信息转换成
复制代码 隐藏代码mov ecx, dword ptr [0xffffcfd4]
mov dword ptr [0xffffcf50], ecx
0xffff开头的地址是qiling默认的栈地址。这么做可以不用考虑寄存器轮转的问题和下一条handle的地址计算。去掉绝大部分指令,保留核心的指令还能够很好的分类。本文只实现了部分handle的转换,具体参考TranslateHandle函数实现的代码。vmp壳程序的执行会多次进入虚拟机、退出虚拟机、执行一个正常的函数然后又重新进入虚拟机。本文以第一次进入虚拟机然后退出虚拟机之间的代码作为转换例子,然后通过keystone转换到二进制文件,最后通过ida反编译。效果如下:
复制代码 隐藏代码void __usercall __noreturn sub_0(int a1@<eax>, int a2@<edx>, int a3@<ecx>, int a4@<ebx>, int a5@<ebp>, int a6@<edi>, int a7@<esi>)
{
MEMORY[0xFFFFCFE8] = a3;
MEMORY[0xFFFFCFE4] = 0xEF;
MEMORY[0xFFFFCFE0] = a1;
MEMORY[0xFFFFCFDC] = a6;
MEMORY[0xFFFFCF3C] = a5;
MEMORY[0xFFFFCF38] = a7;
MEMORY[0xFFFFCFFC] = a5;
MEMORY[0xFFFFCFEC] = 0xEF;
MEMORY[0xFFFFCFF0] = 0xEF;
MEMORY[0xFFFFCFF8] = 0xFFFFCFDC;
MEMORY[0xFFFFCFF4] = 0xEF;
MEMORY[0xFFFFCF48] = 0xEF;
MEMORY[0xFFFFCFD8] = a2 + 0x74B591;
MEMORY[0xFFFFCFC0] = 0xFFFFCFDC;
MEMORY[0xFFFFCFBC] = a3;
MEMORY[0xFFFFCFB8] = a7;
MEMORY[0xFFFFCFB4] = 0xEF;
MEMORY[0xFFFFCFB0] = a4;
MEMORY[0xFFFFCFAC] = a2;
MEMORY[0xFFFFCFA8] = a2 + 0x7E3DF9;
MEMORY[0xFFFFCF50] = a2;
MEMORY[0xFFFFCF20] = a4;
MEMORY[0xFFFFCF14] = 0xEF;
MEMORY[0xFFFFCF44] = a7;
MEMORY[0xFFFFCF28] = a3;
MEMORY[0xFFFFCF2C] = a1;
MEMORY[0xFFFFCF1C] = a2;
MEMORY[0xFFFFCF30] = a6;
MEMORY[0xFFFFCF24] = 0xEF;
MEMORY[0xFFFFCFD4] = 0xFFFFCFDC;
MEMORY[0xFFFFCF34] = 0xFFFFCFD4;
MEMORY[0xFFFFCFD0] = -1;
MEMORY[0xFFFFCFCC] = a2 + 0x75A6C0;
MEMORY[0xFFFFCF18] = 0xEF;
MEMORY[0xFFFFCFC8] = a2 + 0x4296C0;
MEMORY[0xFFFFCF4C] = 0xEF;
MEMORY[0xFFFFCFC4] = 0;
MEMORY[0xFFFFCF4C] = __readfsdword(0);
MEMORY[0xFFFFCFC4] = MEMORY[0xFFFFCF4C];
MEMORY[0xFFFFCF48] = 0xEF;
MEMORY[0xFFFFCF2C] = 0xEF;
MEMORY[0xFFFFCFB8] = 0xEF;
MEMORY[0xFFFFCF38] = 0xEF;
MEMORY[0xFFFFCF40] = 0xEF;
MEMORY[0xFFFFCFC0] = 0xFFFFCB70;
MEMORY[0xFFFFCF18] = 239;
MEMORY[0xFFFFCAAC] = a6;
MEMORY[0xFFFFCAA8] = a7;
MEMORY[0xFFFFCAA4] = 239;
MEMORY[0xFFFFCB6C] = MEMORY[0xFFFFCABC];
MEMORY[0xFFFFCB68] = MEMORY[0xFFFFCAE0];
MEMORY[0xFFFFCB64] = MEMORY[0xFFFFCACC];
MEMORY[0xFFFFCFBC] = 0xFFFFCB64;
MEMORY[0xFFFFCFB4] = 0;
MEMORY[0xFFFFCAB4] = MEMORY[0xFFFFCABC];
MEMORY[0xFFFFCF74] = MEMORY[0xFFFFCAEC] + 0x400000;
MEMORY[0xFFFFCABC] = MEMORY[0xFFFFCAD0];
MEMORY[0xFFFFCAC4] = MEMORY[0xFFFFCAD0] - 32;
MEMORY[0xFFFFCF84] = ~(0x3FFFFF - (MEMORY[0xFFFFCAEC] + 0x400000));
MEMORY[0xFFFFCB30] = MEMORY[0xFFFFCAEC] + 7536667;
MEMORY[0xFFFFCAD0] = MEMORY[0xFFFFCAB4];
MEMORY[0xFFFFCAD8] = MEMORY[0xFFFFCACC];
MEMORY[0xFFFFCB62] = 6;
MEMORY[0xFFFFCAD4] = 0xEF;
MEMORY[0xFFFFCB54] = MEMORY[0xFFFFCAB8];
MEMORY[0xFFFFCB50] = 0xEF;
MEMORY[0xFFFFCB4C] = MEMORY[0xFFFFCAC4];
MEMORY[0xFFFFCB48] = MEMORY[0xFFFFCACC];
MEMORY[0xFFFFCB44] = MEMORY[0xFFFFCAEC] + 0x400000;
MEMORY[0xFFFFCB40] = MEMORY[0xFFFFCABC];
MEMORY[0xFFFFCB3C] = MEMORY[0x433F20];
MEMORY[0xFFFFCB38] = MEMORY[0xFFFFCAEC];
MEMORY[0xFFFFCB34] = MEMORY[0xFFFFCAEC] + 7538412;
MEMORY[0xFFFFCAC0] = MEMORY[0xFFFFCAEC];
MEMORY[0xFFFFCAB4] = MEMORY[0x433F20];
MEMORY[0xFFFFCAE4] = MEMORY[0xFFFFCABC];
MEMORY[0xFFFFCAB8] = MEMORY[0xFFFFCAEC] + 0x400000;
MEMORY[0xFFFFCAB0] = MEMORY[0xFFFFCACC];
MEMORY[0xFFFFCAE8] = MEMORY[0xFFFFCAC4];
MEMORY[0xFFFFCAEC] = 0xEF;
MEMORY[0xFFFFCAC4] = MEMORY[0xFFFFCB54];
MEMORY[0xFFFFCABC] = MEMORY[0xFFFFCAD0];
MEMORY[0xFFFFCAD0] = 0xEF;
MEMORY[0xFFFFCAC8] = 0xEF;
MEMORY[0xFFFFCADC] = 0xEF;
MEMORY[0xFFFFCB60] = ~MEMORY[0xFFFFCAD8] & MEMORY[0xFFFFCAD8];
MEMORY[0xFFFFCAD8] = 0xEF;
MEMORY[0xFFFFCAE0] = MEMORY[0xFFFFCB60];
MEMORY[0xFFFFCB60] = 0xB0;
MEMORY[0xFFFFCB5C] = MEMORY[0xFFFFCAE0];
MEMORY[0xFFFFCB54] = 0xEF;
MEMORY[0xFFFFCACC] = MEMORY[0x7D92CC];
MEMORY[0xFFFFCB58] = MEMORY[0x7D92CC];
MEMORY[0x7D92CC]();
MEMORY[0xFFFFCF8C] = MEMORY[0xFFFFCB60];
MEMORY[0x5036EEC] = MEMORY[0xFFFFCAE0];
MEMORY[0x5036ECC] = 0x7FC2;
MEMORY[0x5036ED0] = 0x46F0;
MEMORY[0x5036EE8] = 0x7637;
MEMORY[0xFFFFCB48] = MEMORY[0xFFFFCAE0];
MEMORY[0xFFFFCB40] = MEMORY[0xFFFFCAC4];
MEMORY[0xFFFFCB30] = MEMORY[0xFFFFCAC0] + 0x7B041E;
MEMORY[0xFFFFCADC] = MEMORY[0xFFFFCAC0];
MEMORY[0xFFFFCAB4] = MEMORY[0xFFFFCABC];
MEMORY[0xFFFFCB50] = MEMORY[0xFFFFCAC4];
MEMORY[0xFFFFCB34] = MEMORY[0xFFFFCAC0] + 0x6BC6A6;
MEMORY[0xFFFFCACC] = MEMORY[0xFFFFCAC0];
MEMORY[0xFFFFCABC] = MEMORY[0xFFFFCAE4];
MEMORY[0xFFFFCAD4] = MEMORY[0xFFFFCAE4] - 0x20;
MEMORY[0xFFFFCAE0] = MEMORY[0xFFFFCAB4];
MEMORY[0xFFFFCAC4] = ~(MEMORY[0xFFFFCFB4] - 0x34C612);
MEMORY[0xFFFFCAD0] = MEMORY[0xFFFFCB48];
MEMORY[0xFFFFCAEC] = MEMORY[0xFFFFCB40];
MEMORY[0xFFFFCAC0] = MEMORY[0xFFFFCB60];
MEMORY[0xFFFFCAE4] = 0xEF;
MEMORY[0xFFFFCAC8] = 0xEF;
MEMORY[0xFFFFCB38] = 0xEF;
MEMORY[0xFFFFCAB0] = 0xEF;
MEMORY[0xFFFFCAD8] = MEMORY[0xFFFFCADC] + 0x77CB5A;
MEMORY[0x5036EDC] = ~(~(MEMORY[0xFFFFCFB4] - 0x34C612) & 0x6963) & ~((MEMORY[0xFFFFCFB4] - 0x34C612) & 0xFFFF969C);
MEMORY[0x5036EE0] = 0x7D05;
MEMORY[0xFFFFCAE8] = 0xEF;
MEMORY[0xFFFFCF44] = MEMORY[0xFFFFCB48];
MEMORY[0xFFFFCAB4] = 0xEF;
MEMORY[0x5036E44] = 0x7ED5;
MEMORY[0xFFFFCB60] = MEMORY[0xFFFFCADC] + 0x74FBF3;
MEMORY[0xFFFFCADC] = 0xEF;
MEMORY[0xFFFFCB5C] = MEMORY[0xFFFFCACC] + 0x68304E;
MEMORY[0xFFFFCAB8] = 0xEF;
MEMORY[0xFFFFCB58] = 0xEF;
MEMORY[0xFFFFCB54] = MEMORY[0xFFFFCAC0];
MEMORY[0xFFFFCB4C] = MEMORY[0xFFFFCB48];
MEMORY[0xFFFFCB48] = MEMORY[0xFFFFCAD8];
MEMORY[0xFFFFCB44] = MEMORY[0xFFFFCAE0];
MEMORY[0xFFFFCB40] = MEMORY[0xFFFFCAD4];
MEMORY[0xFFFFCB3C] = MEMORY[0xFFFFCABC];
JUMPOUT(0x2E1B);
}
由于之前没有保存状态寄存器的值,所以暂时用0xef代替,主要是以下指令产生的
复制代码 隐藏代码pushfd
pop dword ptr [esi]
这两条指令是直接转换到mov dword ptr [0xXXXXXXXX], 0xef。观察上面的反编译代码,可以看到有一个call调用,地址0x7D92CC刚好是LocalAlloc导入表中的地址。这个call是由vmCall产生的,vmCall的转换没有保留参数,感兴趣可以自己修改一下代码。
总结
通过机器学习对vmp的handle进行分类是可行的,重点是提高分类的正确率,单纯使用聚类算法的正确率并不是很高,而且人为设置的特征又不够灵活。对于特征的提取,还是最好选择自然语言处理中的模型,比如word2vec或者bert。提取出特征后,可以先用聚类算法进行分类,然后筛选出一些正确分类的handle,再通过这些handle训练出一个有监督学习中的算法去预测其它未分类的handle,比如svm或者其它一些神经网络,最后根据这些分好类的handle再次进行训练。特征的提取可以参考以下论文
Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization
Neural Machine Translation Inspired Binary Code Similarity Comparison beyond Function Pairs
Investigating Graph Embedding Neural Networks with Unsupervised Features Extraction for Binary Analysis
Instruction2vec: Efficient Preprocessor of Assembly Code to Detect Software Weakness with CNN
Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection
附件见左下角论坛原文。
--官方论坛
www.52pojie.cn
--推荐给朋友
公众微信号:吾爱破解论坛
或搜微信号:pojie_52

文章评论