
Long
最近我开发了一款名为absurd-sql的SQLite后端。在这款工具的帮助下,你无需将整个数据库加载到内存中,而且写入的数据还可以永久保存下来。在文本中,我将介绍一下这款Web存储API(主要是IndexedDB),展示如何将SQLite的性能提升10倍,同时我还将解释一下这款工具的使用技巧以及锁定/事务语义。
如今在编写Web应用时,大多数人可能都会选择IndexedDB来存储数据,这是唯一能够在所有浏览器上运行的数据库API。
当你尝试构建本地应用时,就会发现这个API并不适合构建整个应用。当然,只使用少量功能还是没问题的。但是,如果我们想构建一款出色的Web应用,那么就需要一种更强大的数据处理方式。
IndexedDB很慢。更糟糕的是,当我在Chrome(目前的主流浏览器)上做测试的时候,发现它的实现速度最慢。即便是一个简单的数据库操作也需要大约10毫秒,而一般SQLite的速度为~.01毫秒。这将对你编写的应用产生了巨大的影响。
如果你想使用IndexedDB查询数据,那就只能靠自己了。它只提供了一个函数:count,其余的API仅返回一系列数据项。你只能通过索引,并用特定的方式组织数据,才能构建自己的查询功能。
你甚至不能随意添加新的“对象存储”。只能先打开数据库才能执行此操作,而且还会强制所有其他标签页终止数据库连接!
也许IndexedDB本来就是底层的技术,你应该寻找一个库来更好地支持这些功能。但是,我看到的每个库都很混乱,而且性能更差(我查看的其中一个最受欢迎的“非常快”的库大约需要45毫秒才能获取一个数据项!?)
接下来,我来说一说我开发的这款工具,它可以极大地减轻开发人员的负担。

absurd-sql简介
SQL是构建应用的一种好方法。尤其是小型本地Web应用。键/值存储可能在大型分布式系统中占有一席之地,但是如果我们可以在Web上使用SQLite,是不是很酷?
absurd-sql就可以实现。absurd-sql是sql.js的文件系统后端,它允许SQLite以小块的形式读/写IndexedDB,就像磁盘一样。
整个项目的建立过程非常奇妙。我为什么构建了这样一款工具?因为除了Chrome之外,在所有的浏览器中IndexedDB都是使用SQLite实现的。
非常感谢 phiresky 撰写的文章《Hosting SQLite databases on Github Pages》(https://phiresky.github.io/blog/2021/hosting-sqlite-databases-on-github-pages/),给了我很多启发。这个技巧非常聪明,于是我才有了这个想法。
如果想在Web上使用SQLite,则可以考虑一下sql.js,这是一个非常优秀的项目。它可以将SQLite编译为WebAssembly,并允许你读取数据库和运行查询。但其主要的问题在于写入操作的数据无法持久地保存下来。它会将整个数据库加载到内存中,并且只能修改内存中的数据。一旦页面刷新,所有数据更新都会丢失。
虽然内存中的数据库有其一定的用途,但如此一来SQLite的作用就减弱了。如果想用SQLite构建应用,我们就需要写入数据并持久保存数据。
absurd-sql可以解决这个问题,具体做法是拦截来自SQLite的读/写请求,并将它们永久地保存到IndexedDB(或任何其他持久后端)。我写了一个完整的文件系统层,它知道SQLite如何读取和写入数据块,并且能够正确地执行操作。
这意味着,它永远不会将数据库加载到内存中,因为它只加载SQLite请求的内容,并永久地保存写入数据。
我们之所以使用sql.js是因为它拥有一个庞大的社区,而且也是迄今为止最常见的在Web上使用SQL的方式。你只需要安装absurd-sql,并添加一些代码来调用它。如下所示:
import initSqlJs from '@jlongster/sql.js';import { SQLiteFS } from 'absurd-sql';import IndexedDBBackend from 'absurd-sql/dist/indexeddb-backend';SQL = await initSqlJs();sqlFS = new SQLiteFS(SQL.FS, new IndexedDBBackend());// This is temporary for nowSQL.register_for_idb(sqlFS);SQL.FS.mkdir('/sql');SQL.FS.mount(sqlFS, {}, '/sql');let db = new SQL.Database('/sql/db.sqlite', { filename: true });
现在你可以正常使用db了,而且还可以读取数据,并持久地保存到 IndexedDB!更多信息,请参阅README文件,或者查看数据库API的sql.js文档。此外,你还可以通过学习示例项目快速入门(https://github.com/jlongster/absurd-example-project)。
let stmt = db.prepare('INSERT INTO kv (key, value) VALUES (?, ?)');stmt.run(['item-id-00001', 35725.29]);let stmt = db.prepare('SELECT SUM(value) FROM kv');stmt.step();console.log(stmt.getAsObject());
虽然我不推荐在生产中使用这个库,但我试着移植了一款应用(https://app-next.actualbudget.com/subscribe),而且一切正常!

不仅仅是一个数据库
在本文中,我多次提到IndexedDB,因为它是当今唯一可在所有浏览器上运行的持久存储。问题是它将两种需求合二为一:数据库和持久存储。
如果你利用IndexedDB构建了整个应用,然后Web上出现了一个全新的超快速存储层时,该怎么办?你已经完全被锁定在IndexedDB上了。
我们通过sql.js + absurd-sql抽象出了存储层。后面我会介绍absurd-sql的速度比IndexedDB快很多,但不要搞错:我们的性能还远不如原生的SQLite。与原生SQLite相比,我们的速度大约慢50~100倍,因为我们没有办法加快写入的速度。(不用害怕,在许多情况下这样的速度就足够了,而且我们还有SQLite的缓存。)
IndexedDB只是absurd-sql的一个后端。我尝试过webkitFileSystem后端,但是无法达到IndexedDB的性能。我非常想念批量读取和写入,因为真的是非常慢。
有一个名为Storage Foundation API的新项目正在构建这方面的工具。我已与作者取得了联系,我会尝试一下使用它的后端。(这款工具缺少一些关键的功能,比如锁定,但希望可以解决。)
未来,absurd-sql的性能还可以提高1~2个数量级。如果真的实现了,你所要做的只是换几行代码!

关于IndexedDB的持久性
我们希望出现新的存储API,因为IndexedDB数据无法永久地保存下来。据说浏览器可能会在某些情况下删除IndexedDB数据库。
虽然这种情况很少发生(我还没有见过),但将IndexedDB作为持久存储可能会引发重大问题。目前,你可以将利用它处理云中有备份的数据,但不能用它来处理只保存在本地的数据。希望我们能够获得一个更好的存储API。
下面进入正题!

权衡利弊?哪些利弊?
尽管SQLite是在IndexedDB之上实现的,但其各个方面的性能表现都超出了 IndexedDB。这就很荒谬了。
我编写了一个基准测试应用,并测试了各种情况。这款应用可以运行几个不同的查询,而且还允许你以各种方式配置SQLite,并测试原始的IndexedDB实现:
-
所有数据都在这个电子表格中:https://docs.google.com/spreadsheets/d/1Cpb9r3cZlbZgp1RoSTmh22wOPCRMqINzMUelUTIDo8Y/edit
-
基准代码在这里:
https://github.com/jlongster/absurd-sql/tree/master/src/examples/bench
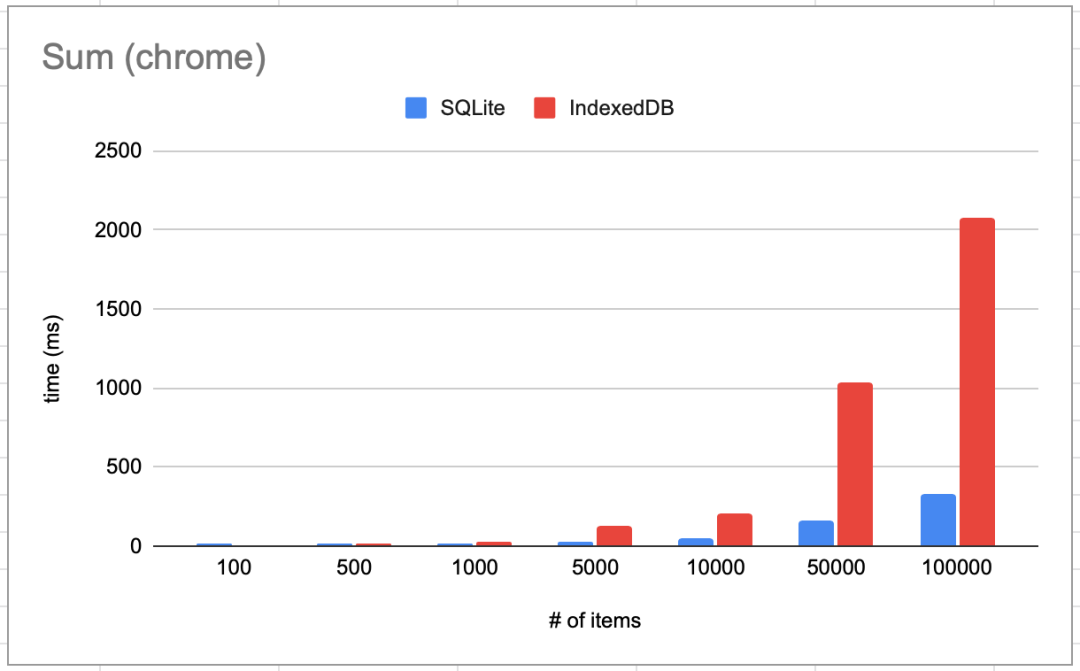
读取
我们来执行如下查询:SELECT SUM(*) FROM kv,这条查询会强制数据库读取所有数据项。IndexedDB会打开一个游标,并求每个数据项的总和。
写入
我们来执行如下写入操作:INSERT INTO kv (key, value) VALUES("large-uuid-string-0001", 53234.22),并使用IndexedDB 的批量操作put (我们只需等待事务成功)处理数据:
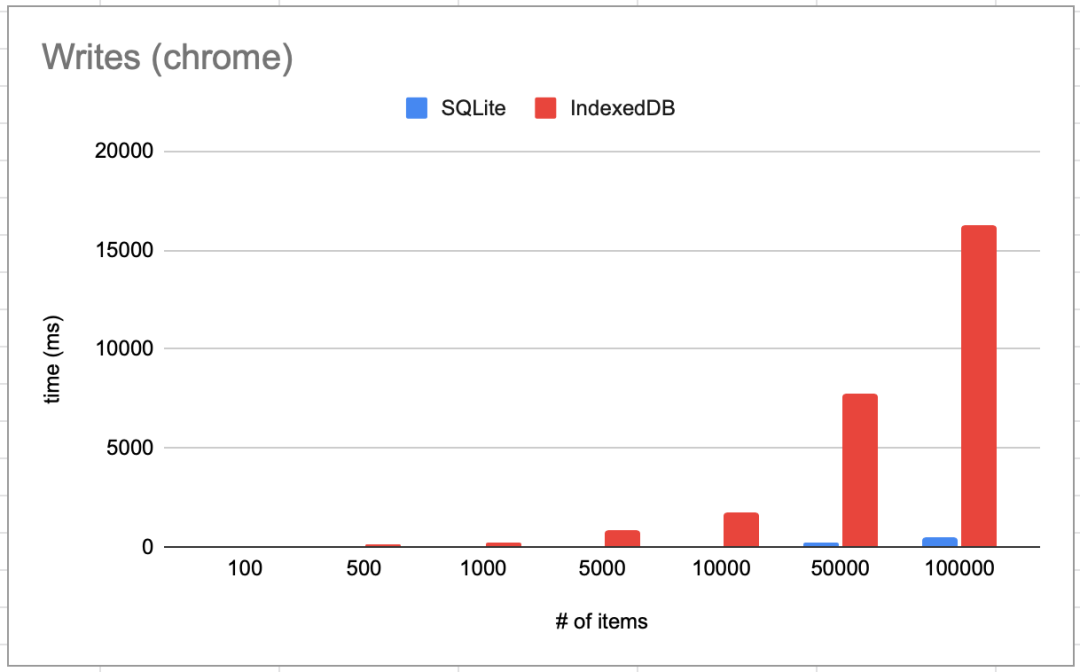
我发现写入操作的性能很难测量,我在努力尝试寻找一个公平的比较。IndexedDB可以批量插入数据,而且速度应该非常快。我没有使用特殊的技巧,比如不要让SQLite等待磁盘刷新等。二者都使用了相同的流程。
我最初的目标是一百万条数据,absurd-sql能够很好地处理这个数据量。虽然有点慢,写入需要4~6秒,读取需要2~3秒。但是IndexedDB更慢,我甚至没有足够的耐心等到它完成操作。最终,写入大约耗费了2~3分钟,读取大约在1分钟范围内。
操作的数据项越多,IndexedDB的性能就越糟糕。而且不完全是线性的,在到达某个点后就完全无法使用了。
absurd-sql的缺点是什么?
那么,absurd-sql有哪些缺点?为了提高性能我们需要付出怎样的代价?
使用absurd-sql有一个缺点:你需要下载一个1MB的WebAssembly文件(压缩后只有 409KB)。但仅此而已。这是唯一的缺点,剩下的全是好处,而且还可以使用WASM流式编译,解析/编译的成本也相对较低。对于真正的应用来说想都不用想,尤其是这款工具永远不会发生变化。
你不仅可以获得出色的性能,还可以获得数据库操作的所有功能:
-
事务处理(而且还可以自动提交)
-
完整的查询系统
-
视图
-
表常用的表达式
-
触发器
-
全文本搜索
-
缓存(更主要的加速)
-
等等

这怎么可能?
这款工具好得有点令人难以置信,你确定没有遗漏什么吗?
首先,怎么可能如此轻松地超越IndexedDB?如果真的可行,为什么我们不使用原生SQLite实现同样的性能,并在SQLite里塞入一个SQLite db?
这款工具之所以如此突出,是因为IndexedDB太慢了。如此简单的批处理读写操作就可以获得如此之大的性能提升,任何CPU都达不到这样的效果。我们在读写操作上节省了大量时间,CPU的性能可以忽略不计了。

不够快?还有缓存!
正如我在本文前面提到的,虽然这些结果非常振奋人心,但是原生SQLite的性能依然无可比拟,它快了1~2个数量级。
如果你需要进行大量的读取操作,则如今的性能不足以支持一款真正的应用。但是,我们还有一个非常简单的解决方法:使用SQLite缓存!
SQLite会自动使用2MB的页面缓存,因此你甚至不会注意到任何性能问题。它会缓存所有读取请求的结果,并在发生写入操作时,驱逐读取缓存。一般常见的应用拥有大量读取操作,而写入操作相对较少,因此SQLite的这种方式非常有效。
如果你需要处理大量的数据,则可以试试看提高页面缓存。即使提高到10MB的页面缓存也没问题。我们就是将大量数据库加载到内存中,然后交由SQLite管理。
增加页面大小是减少读取次数的另一种方法,下面我们来详细看一看。
页面大小
首先在演示应用中加载数据,然后打开开发者工具,并查看IndexedDB数据。你可以看到如下内容:
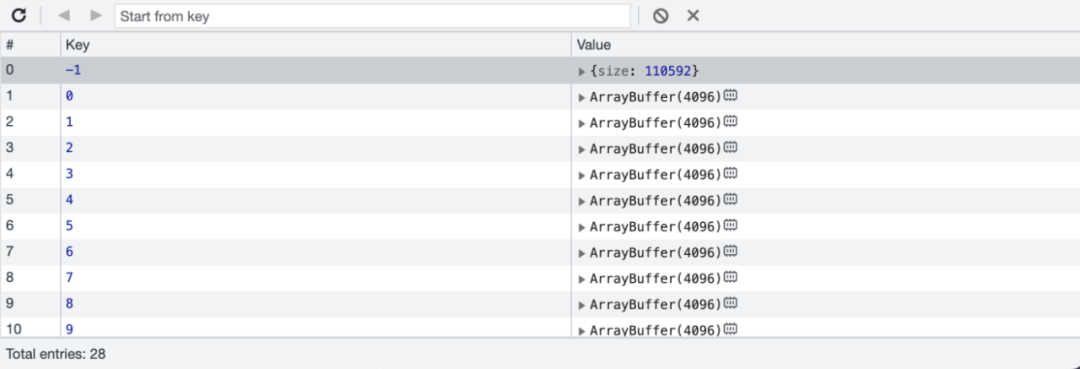
注意,此处存储的数据是大小为4096的字节块,这是SQLite的默认页面大小。页面越小,读取的次数就越多,起初我以为这个设置太小。然而,通过以下优化后就可以正常工作。
你可以随意增加页面大小,但必须是2的幂,因此可以试试看8192。这个页面可以让读取次数减少一半,而且性能也会得到提升。只不过,块越大意味着它可能会读取或写入大量不需要的数据。你可以自己试试看。所有的性能基准测试都使用4096的页面大小,也就是说为了比较的公平性,我们不应该使用性能较低的配置。
如何更改页面大小?只需使用SQLite:
let stmt = db.prepare(`PRAGMA page_size=8192;VACUUM;`);
你必须执行VACUUM才能让设置生效。SQLite必须重构整个数据库,才能更改页面大小。修改完毕后,我们存储数据的方式也会自动变化:
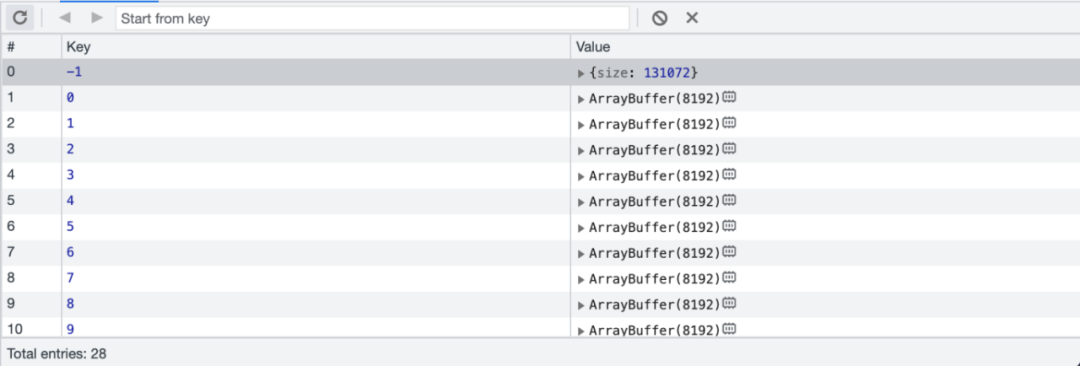
注意,现在数据块的大小为8192。我们直接从文件中读取页面大小的字节数。

实现原理
为了获得这个水平的性能,需要一些技巧。因为IndexedDB太慢了,如果不正确处理,最后的性能可能比原始IndexedDB还要糟糕。
我们的目标是实现你的愿望:如果SQLite需要进行一系列的读取操作,则它应该打开一个游标并遍历数据。而不是每次读取都打开一个新事务。这很难做到,因为我们只有一个read函数,而且它只接受偏移量和长度。但是,我们可以通过一些技巧来实现。
另一个目标是尽量不要维护状态。我们不应该跟踪锁定状态、我们自己的变更计数器或页面大小。我们可以在需要时直接从SQLite文件中读取,并利用IndexedDB的事务语义锁定数据。我们唯一需要存储的状态就是文件的大小。
问题:同步API
最大的问题是在sqlite执行读写操作时,API是完全同步的,因为它基于的是C API。而 IndexedDB的访问是异步的,我们应该如何解决这个问题?
我们生成一个worker进程,并给它一个SharedArrayBuffer,然后使用 Atomics API通过缓冲区进行通信。例如,我们的后端将读取请求写入共享缓冲区,然后工作进程读取请求,并执行异步读取,然后将结果写回缓冲区。
我编写了一个小的通道抽象,通过SharedArrayBuffer发送不同类型的数据(https://github.com/jlongster/absurd-sql/blob/master/src/indexeddb/shared-channel.js)。
最关键的部分是Atomics.wait API。在调用这个API的时候,它会完全阻塞 JS,直到满足条件。你可以使用它来等待SharedArrayBuffer中的一些数据,我们就是利用它将异步读写转换为同步读写。后端在等待worker进程的结果时,通过调用它来阻塞进程。
另一种选择是使用Asyncify,这是一种Emscripten技术,用于将同步C调用转换为异步调用。然而,我不会使用这种方法。它的工作原理是将整个代码转换为一连串的unwind和rewind操作,会大幅度影响性能,还会让二进制代码大幅度膨胀。这种做法太具侵入性,会迫使SQLite具有异步API。
我们可以通过Atomics.wait实现一些关键的性能改进,这就足够了。
长期存在的IndexedDB事务
IndexedDB有一个糟糕的行为,一旦事件循环处理完成,它就会自动提交事务。这导致我们无法长期使用事务,而且你必须在执行大量读取操作时重新创建一个新事务。创建事务非常慢,这对性能来说是一个巨大的冲击。
然而,我们可以再次利用Atomics.wait来解决这个问题。我们可以调用它来阻塞保持事务活动的进程。我们打开一个事务,然后阻塞整个线程,这样系统就不能提交事务了。
这意味着在处理来自SQLite的请求时,我们可以在所有请求中重用一个事务。即便需要执行1千次读取,我们也可以使用同一个只读事务,这可以极大地提升速度。
使用游标迭代
使用游标迭代数据更快。不过,我们只能收到单独的读取请求,怎么使用游标呢?
我们可以让一个读取数据的事务持续打开一段时间,因此就可以在检测到顺序读取时打开游标。这其中包含一些权衡利弊,因为在有些浏览器中打开游标的操作非常缓慢,但迭代的速度远远超过了大量的get请求。该后端能够自动检测何时出现多次顺序读取,并自动切换到使用游标。
有趣的是,在Firefox中使用游标是一个巨大的加速。而在Chrome中,只是稍微快一点。
文件锁定与事务语义
对于数据库来说,文件锁定与事务语义非常重要,如果处理不正确,就可能会破坏整个数据库。如果数据库遭到破坏,谁还在乎性能。
我们如何确保正确地写入数据呢?无需多说,这很复杂,但我相信我们采用的这个算法非常可靠。
原子提交
首先我们需要理解SQLite做出的假设。我们需要百分百满足这些假设,否则就有破坏数据库的风险。
在SQLite中,原子提交很好地描述了写入的工作方式。我还研究了大量的代码以及其他要求。总结起来大致如下:
-
SQLite使用日志,而且还会写入两次,首先是写入日志,然后是普通文件。
-
你无法避免发生停电之类的意外,而且一旦停电计算机就会在刷新写入的过程中关闭。因为SQLite进行两次写入,因此如果发生这种情况,至少可以保证其中一个文件是完好无损的。如果数据库文件写了一半,则它还有一个“热日志”,只需重新应用该日志即可。如果是日志写了一半,那也没什么大不了,我们只需忽略这次写入操作。这可以保证原子提交(全有或全无)。
-
这一切都依赖于fsync正常工作。在调用fsync后,它会假定所有写入都已成功写入磁盘。如果写入失败,则两个文件的写入都可能不完整。
我们必须满足的第一个要求是提供一个fsync方法,以原子方式刷新写入。
如果使用IndexedDB,则我们完全不必担心这些问题。IndexedDB提供了事务语义,如果打开一个事务并进行大量写入操作,则要么写入全部成功,要么全部不成功。这可以减轻我们的负担,我们可以依靠它。
我们甚至不需要日志文件。我们可以设置journal_mode=OFF,告诉SQLite不要使用日志文件,但它仍然需要记录回滚事务(ROLLBACK)。因此,我们应该设置journal_mode=MEMORY,将日志保存在内存中,这比将其写入磁盘要快得多。
还有预写日志,或“WAL 模式”。如果是磁盘读写,会更有效。但是,为了提高性能,需要使用mmap之类共享内存的技术。我认为我们无法将这些语义可靠地映射到IndexedDB。如果只是写入IndexedDB,WAL可能会导致开销增加。写入的结构对我们来说并不重要。
文件锁定
SQLite使用“劝告式锁”来协调数据库连接。SQLite的原子提交中详细描述了如何使用锁(https://www.sqlite.org/atomiccommit.html)。
我们需要以SQLite期望的方式锁定我们的数据,否则连接可能会相互覆盖。尽管我们依赖于IndexedDB事务,但这并不意味着它们的顺序是正确的。
然而,我们可以依靠事务。我们只需要做一些额外的工作。IndexedDB中的只读事务可以并行运行,而读写事务一次只能运行一个。我们可以利用它来实现锁定,启动一个读写事务就相当于锁定了文件。
当请求共享锁时,我们打开一个只读事务。即便同时存在多个共享锁也没问题,而且还可以并行运行多个只读事务。然而,当请求写入锁时,我们打开一个读写事务。一旦该事务运行,根据IndexedDB的语义,我们就知道我们拥有了数据库的控制权。
唯一的问题在于,在我们请求读写锁之后,在等待获取读写锁的这段时间内,另一个线程可能写入了数据。SQLite可以为我们提供了这些信息。在获得读写事务后,我们可以读取代表 SQLite“变更计数器”的文件。如果该计数器与我们请求写入时的计数相同,则表明写入是安全的。
SQLite会在写入事务开始(即执行BEGIN TRANSATION时)时锁定文件,然后在事务结束时解锁。在某种程度上,我们将SQLite事务映射成了IndexedDB的读写事务,但我不这么认为,因为我们不会将ROLLBACK转换成IndexedDB的abort()。我们利用IndexedDB事务来确保原子写入的安全,而且还会写入 SQLite传来的数据。
这是唯一的实现方式,因为我们有长期存在的IndexedDB事务,因为我们可以打开一个读写事务,并且在整个写入锁定过程中保持这个读写事务开放。如果我们必须重新打开它,则会导致数据无法安全地写入数据库,而且数据库也容易遭到破坏。
没有SharedArrayBuffer的备用模式
虽然大多数浏览器都支持SharedArrayBuffer,但Safari还不支持。我不太担心,因为我相信将来Safari一定会支持的,但眼下我们仍然需要提供某种支持。
遇到SharedArrayBuffer不可用的情况,absurd-sql还准备了备用模式,它可以在开始时读取所有数据,这样以后的读取就是同步的。
然而写入会更困难,因为它假设写入总是成功的,但实际上写入操作需要在后台排队运行。我们实现了相同的事务语义(仅在安全时写入),但实际操作发生在后台。
这样做的主要问题是,如果写入不成功,则整个数据库都是旧数据。我们再也不能写入文件了。我们可能需要重新启动数据库并再次读取整个文件,但这感觉很复杂。
最终结果是,如果在Safari中打开了两个标签页,则实际上只有其中一个可以执行写入操作。如果两个选项卡同时写入数据,则其中一个会检测到数据的变化,而且永远不会写入数据库。所有写入操作只能继续在内存中执行,一旦刷新页面,所有数据都会丢失。当这种情况发生时,应用程序应该通知用户,避免数据丢失。
参考链接:https://jlongster.com/future-sql-web



文章评论