背景
为什么要思考状态管理设计
近些年,随着工业互联网的发展,越来越多的应用选择了在浏览器端实现。浏览器开放的功能也越来越多。可是,在浏览器功能越来越强大的日子,前端也变得繁重起来。状态仓库需要存放的东西也越来越多。如一个简单的前端监控系统,就涉及到错误展示,数据报表,错误筛选查询等等功能。这其中有许多数据都是存在交集的 一旦我们的数据获取存在交集,则就意味着有以下问题存在:
-
1 种类型数据存在 2 份,数据上有冗余 -
获取了不必要的数据,造成了不必要的服务端压力 -
无法很好的组合使用
当然,以上是交集存在的问题。这也会导致单条数据不纯,无法做到很高的抽象和通用性。久而久之,此类管理方式存放的数据模型会越来越混杂,越来越多,造成管理上的麻烦。
用后端的方式思考状态编织
于是,我们非常希望可以将数据的管理模型使其更加抽象,使其可以在任意业务场景都可以灵活组装和使用。这一点也和函数式编程中的“纯函数”概念类似:
纯函数 + 纯函数 = 纯函数
我们将视角转向后端来看。假设错误监控的后端接口,要给我们返回一条 错误捕获信息,后端的数据查询逻辑又该如何编写呢?下图是 2 张表的联查实现。其中一张issue表,一张error表。在后端的数据库设计中,issue和error关联,常常以引用对方的 id 来实现。这样我们就可以将 2 张表解耦设计,在需要联合查询时再进行组装。
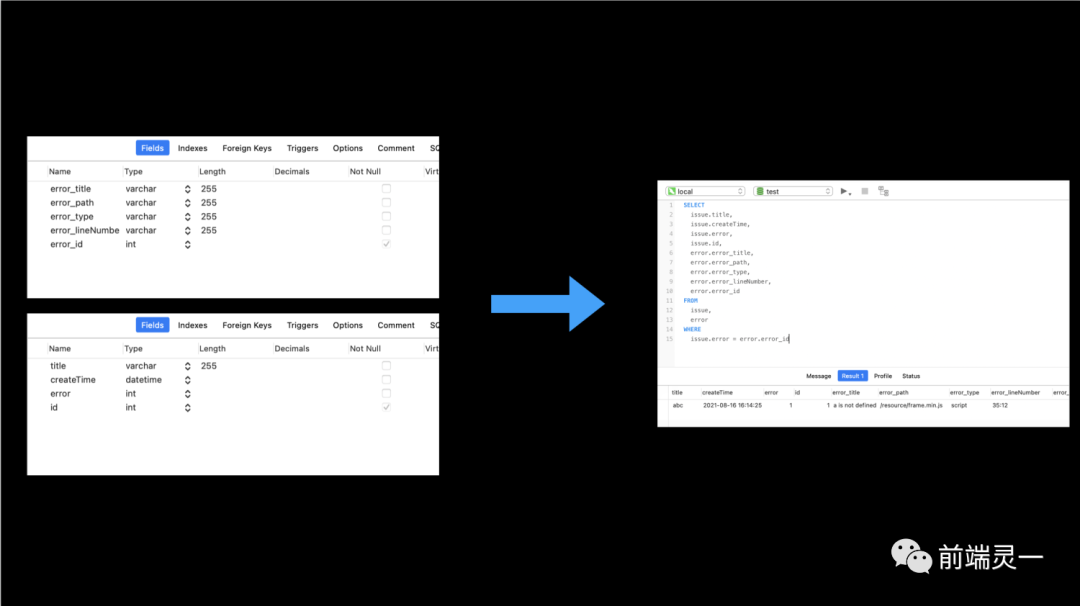
可以看到,得益于许多数据库的多表联查,后端可以轻松地从多张表中拿到想要的数据,最后组装起来,通过接口进行返回。
状态范式化
基于以上考虑,我们可以采用状态范式化方案。在使用范式化方案之前,我们先来了解一下它到底是什么。根据redux官方文档的介绍(https://redux.js.org/usage/structuring-reducers/normalizing-state-shape#designing-a-normalized-state):
Each type of data gets its own "table" in the state. (每种类型的数据在状态树中应该有属于自己的表)Each "data table" should store the individual items in an object, with the IDs of the items as keys and the items themselves as the values.(每一条数据都应当把数据存在一个对象里面。项目的 ID 作为 key,本身作为 value)Any references to individual items should be done by storing the item's ID.(对于单个数据模型的引用应当通过存储 ID 来实现) Arrays of IDs should be used to indicate ordering.(应该用包含 ID 的数组来声明所有数据的排列顺序)
简单来讲,就是将我们的数据从立体化变为扁平化,将可以抽象的数据模型进一步独立管理,数据之间连接模型用 ID 进行引用连接查找,可以加快查找数据的速度。如:

这种存取查找方式,类似数据库的多表联查一样。所以在很多时候,我们期待前端的范式化模型和数据库的模型一一对应。我们根据范式化的概念,可以将我们目前的状态根据模型进行抽象。根据模型将数据抽离,随后根据查询关系,做关联引用抽象完毕后,我们在业务中查找数据的方案也需要进行联合查询。这样以来,我们查询的复杂度就由 O(N)降为了 O(1)。查询性能大幅度提升
normalizr.js
当然,这样的数据组装方式虽然让读取速度加快,但也让源数据的分离实现变得复杂起来。这里我们可以使用 Redux 官方推荐的 normalizr.js,他可以根据预先设置好的数据模型,把我们的数据快速根据模型进行剥离,我们的数据转换可以变的更加简单。我们可以经过简单的数据模型定义,就可以将数据按照模型进行分离。像上面的演示转换结果一样
import { normalize, schema } from 'normalizr';
// Define a users schema
const user = new schema.Entity('users');
// Define your comments schema
const comment = new schema.Entity('comments', {
commenter: user
});
// Define your article
const article = new schema.Entity('articles', {
author: user,
comments: [comment]
});
const normalizedData = normalize(originalData, article);
重复渲染的烦恼
当然,redux 天生的状态管理方案是存在巨大的性能问题的 —— 需要将状态提升到公共组件去管理。这种实现方式常常会导致不必要的组件重新生成组件树。举个例子,我们有一个错误监控系统,当我们获取最新的错误信息列表时:虽然我们的错误信息条目有所增加,错误类型却始终没有变化。但只使用错误类型的组件依然触发了重新渲染。我们当然不希望这种状况存在,毕竟如果碰到比较复杂的计算时,不必要的重复渲染往往对性能影响都比较大。
useSelector
当然,我们可以借助 react-redux 的 useSelector 钩子来筛选需要的 state。useSelector 自身拥有了多级缓存,可以确保只有在用到的数据更新时,才会触发组件,不会造成不必要的组件更新。从源码中可以看到,每次提交 action 后,都会去执行 equalityFn 函数,将本次 selector 的执行结果与上次的结果进行对比。如果一致,则直接 return。不会触发后面重复渲染的逻辑
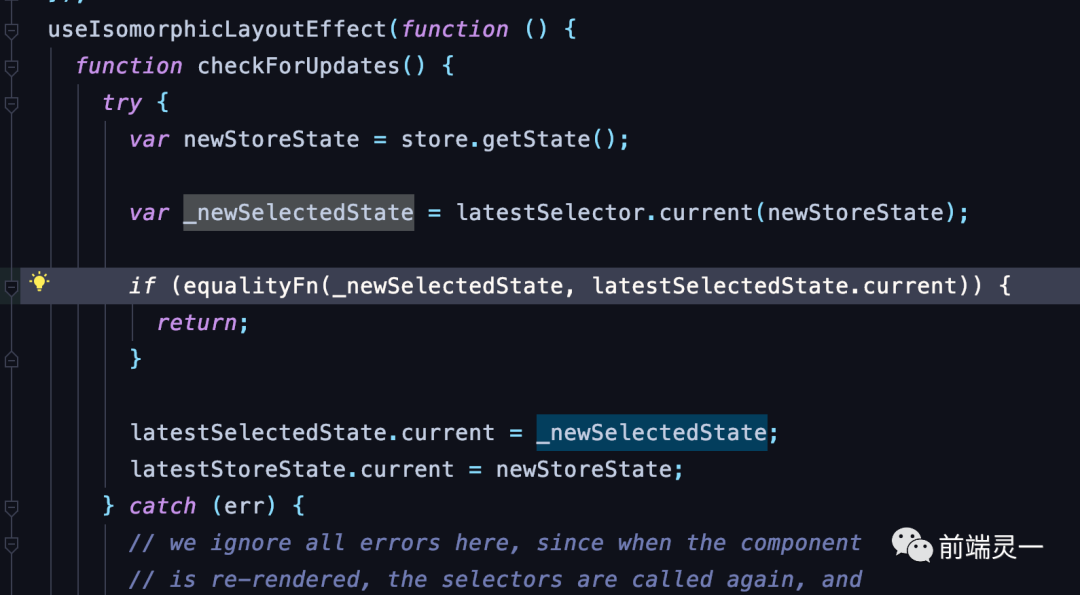
但这种方案依然存在缺陷。在每次 action 提交后,虽然组件不会重新生成,useSelctor的selector的选择函数依然会重新生成(虽然有 reselect,但缓存也是个成本)。且倡导一个useSelctor每次只返回单个非引用类型字段值,不然触发浅比较会导致组件再次重新渲染。
Recoil
概念 & 优势
Recoil 是 Facebook 推出的基于 React 的状态管理框架(目前还是试验阶段)。它的最大优势就是可以基于正交有向图,精准的只触发渲染状态更新的组件,而这一切都是基于订阅来实现。基于订阅,也就避免了 useSelector 的选择器,每次状态更新都需要重新生成的问题。下图可以看到,比起之前redux一颗全局大的状态树的玩法,recoil 更推荐将状态拆为一个个碎片状态,只与用到的组件进行共享。
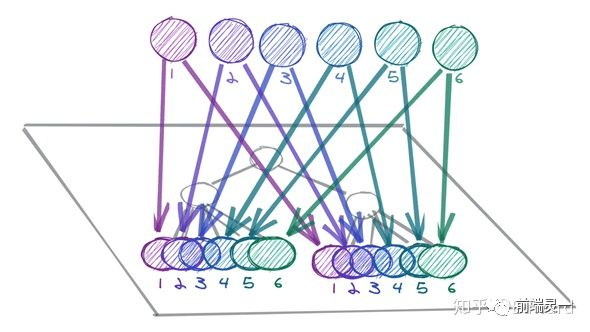
在recoil中,有 2 个最核心的概念:atom和 selector。atom是状态的最小单位。当atom被更新时,订阅的组件也会被触发更新。如果多个组件都订阅了同一个atom,则它们共享这份状态。你可以简单地认为,atom 是 recoil 中最小的数据源
const fontSizeState = atom({
key: 'fontSizeState',
default: 14,
});
而 selector 的意义则是搭配 atom 使用。selector 可以为 atom 加入自定义的 getter 和setter。而 atom 发生更改时,订阅它的 selector 也会发生变化,从而被订阅 selector 的组件重新 render
const fontSizeLabelState = selector({
key: 'fontSizeLabelState',
get: ({get}) => {
const fontSize = get(fontSizeState);
const unit = 'px';
return `${fontSize}${unit}`;
},
});
当然,recoil 也支持状态的读写粒度不一致问题。例如我的状态中包含了 a 和 b 两个属性,我在读的时候,只读其中的 a 属性,则只用到 b 属性的组件不会更改。这一点对性能的提升巨大,也一定程度上间接避免了recoil的状态拆分过细问题
配合 Suspense
当然,Recoil 最赞的地方是 状态读取支持异步函数。且同步异步可以混用,同步函数也可以接受异步读取的值。 当然,这一个点要配合 Suspense 优势才最大。例如下面代码。我在 selector 中定义的状态 get 为异步函数,而在我组件中使用时却是同步的。这对于使用者来说是无感使用的。当然,配合 Suspense 的效果更好,我们就不需要另外的状态,来判断这个异步计算是否已经拿到数据。
const currentUserIDState = atom({
key: 'CurrentUserID',
default: 1,
});
const currentUserNameQuery = selector({
key: 'CurrentUserName',
get: async ({get}) => {
const response = await myDBQuery({
userID: get(currentUserIDState),
});
return response.name;
},
});
function CurrentUserInfo() {
const userName = useRecoilValue(currentUserNameQuery);
return <div>{userName}</div>;
}
function MyApp() {
return (
<RecoilRoot>
<React.Suspense fallback={<div>加载中。。。</div>}>
<CurrentUserInfo />
</React.Suspense>
</RecoilRoot>
);
}
总结
-
用后端的状态模型重新思考状态设计 -
尽可能地抽象模型,保证单条数据的纯度。便于在业务中灵活组装 -
过于灵活的状态设计,可能会导致不必要的组件重复渲染。需要把控粒度 -
警惕不必要的重复渲染带来的性能损耗。可以使用缓存等策略避免重复渲染
长按图片加 ssh 为好友,我会第一时间和你分享前端行业趋势,学习途径等等。2021 陪你一起度过!

文章评论