温馨提示:本文共2163字 24图,预计阅读时间为6分钟
周六了,阳光洒在身上,连呼吸都是值得被感恩的。在这样一个美好的早晨,我打算兑现在上篇文章结尾答应大家的承诺:爬取B站分区100个热门视频排行榜的简介信息和热门信息。
(不知道webscraper是什么玩意儿的小伙伴,请翻看我的上一篇文章)
那么问题来了,B站有那么多个区,到底爬哪个呢?在这里,我借用了在B站上学来的一个思维模型:拍脑袋大法(via 尤子缘)。我一拍脑袋,发现最近娱乐圈的瓜真是瓜出不穷,都让人都点目不暇接了呢,连断网已久的我都略知一二,好了,那我们就来爬娱乐区。So,有了前置条件,话不多说,就让我们和我们的老朋友webscarper一起,了解下B站的小伙伴们都在吃啥瓜吧?。
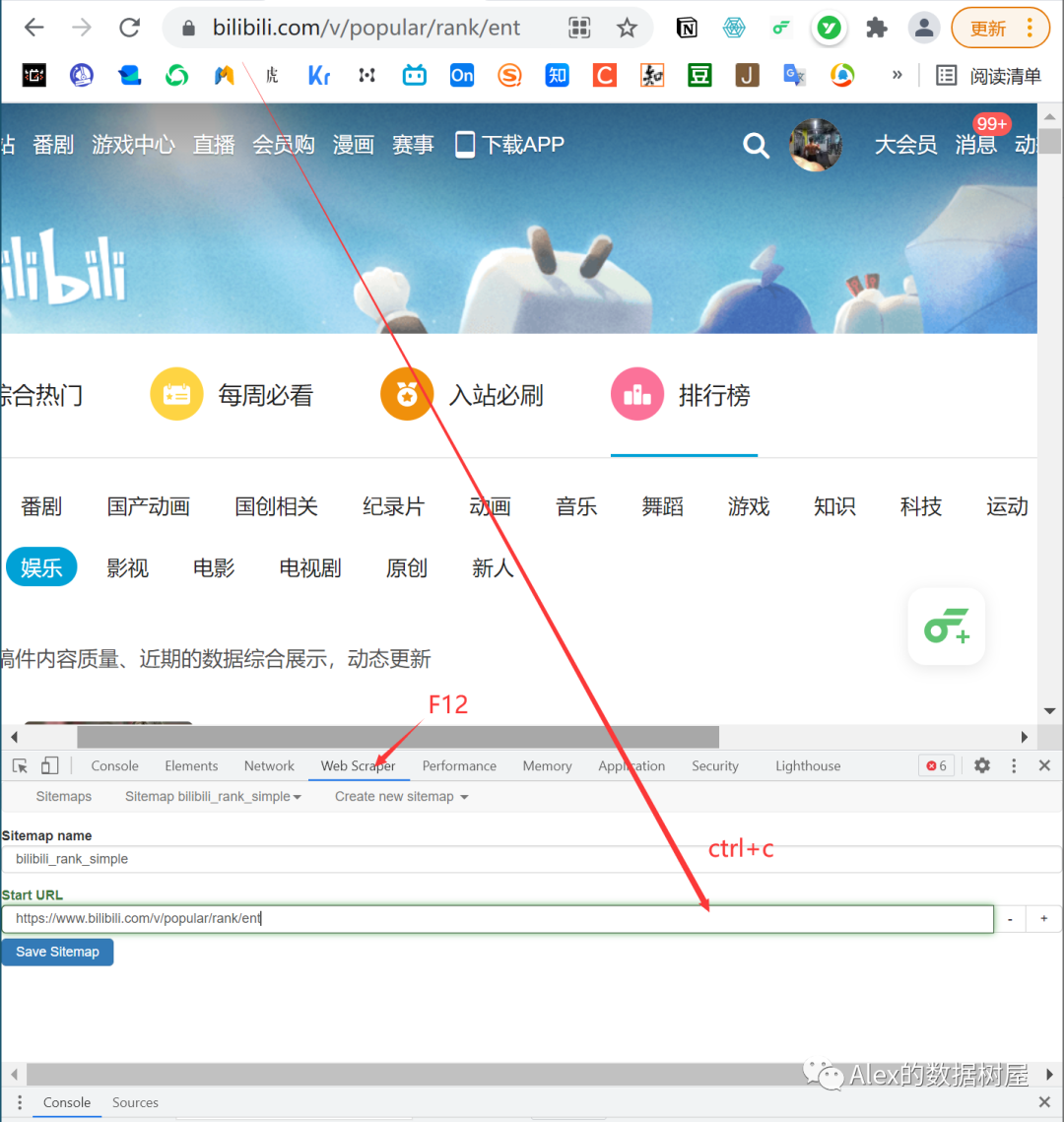
目标网页:https://www.bilibili.com/v/popular/rank/ent(娱乐区排行榜)
目标数据:该榜单下100个视频的所有信息(三连+简介)
1、打开F12,新建一个爬虫项目(create new sitemap)
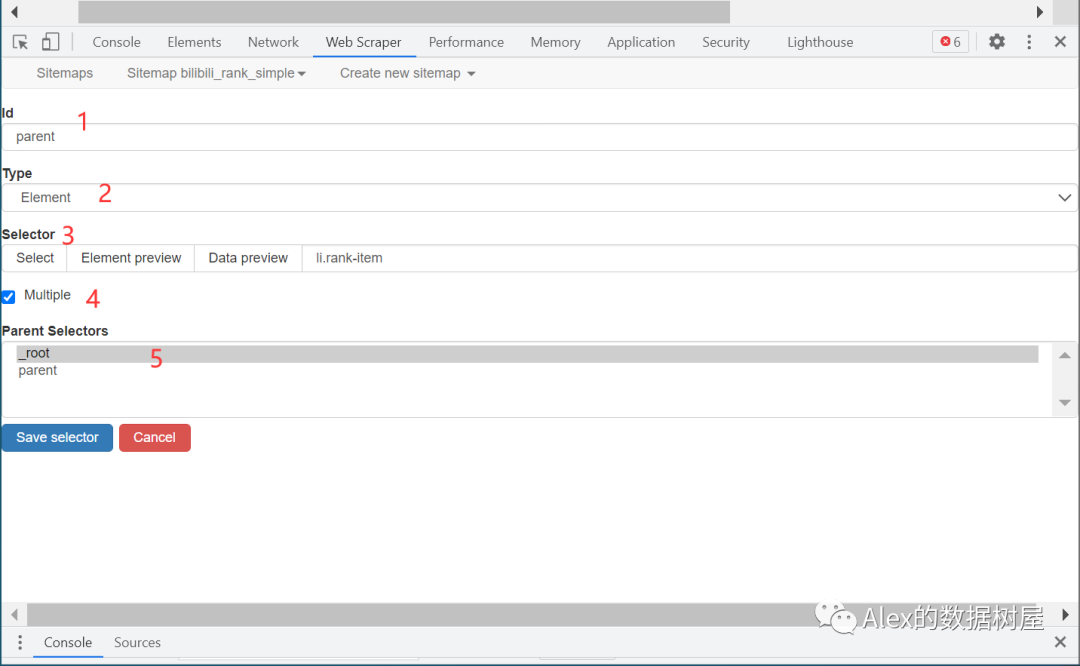
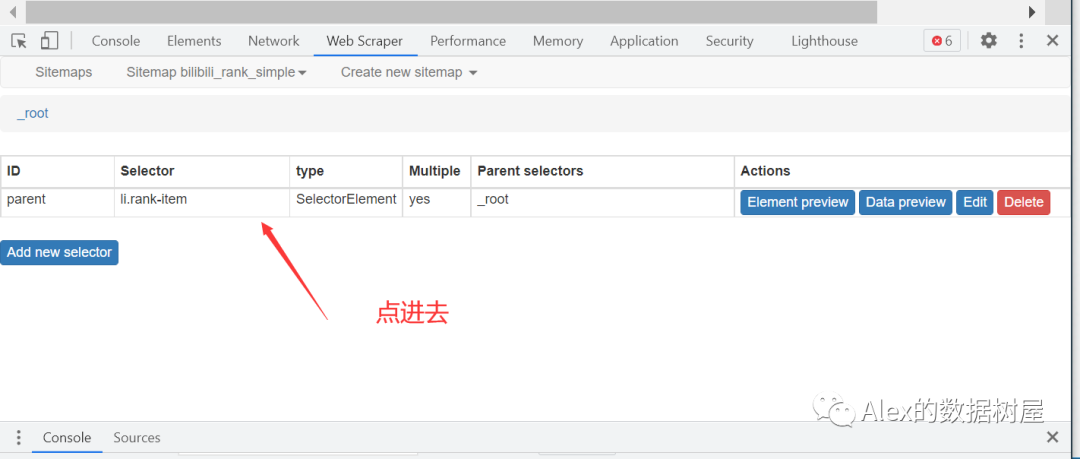
2、和之前一样,新建一个父选择器,用来存放要爬取的信息
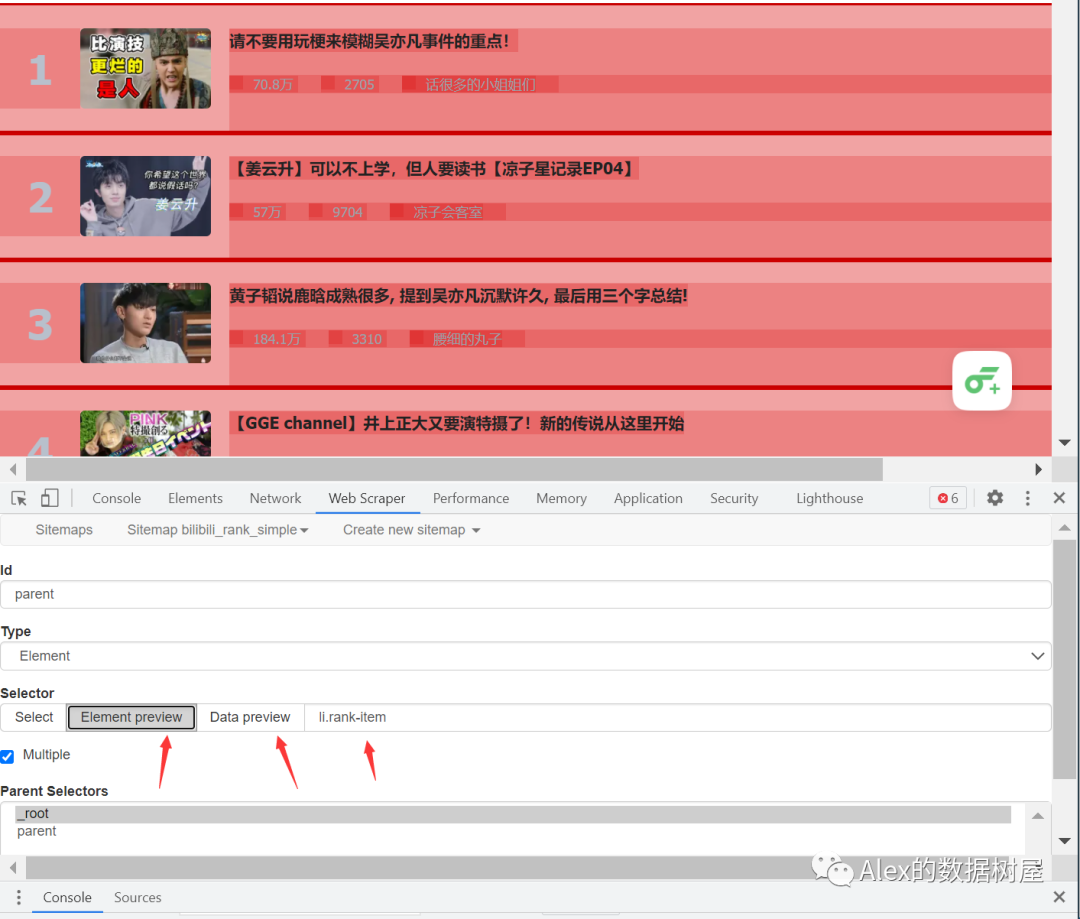
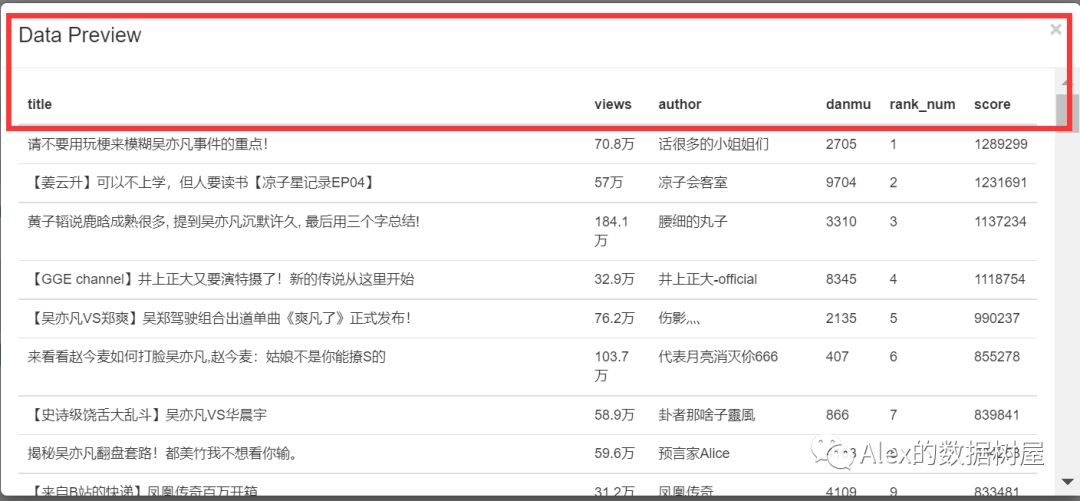
3、选择好以后,和以前一样,点击data preview,在这里可以看到数据已经被我们抓取到了O(∩_∩)O。
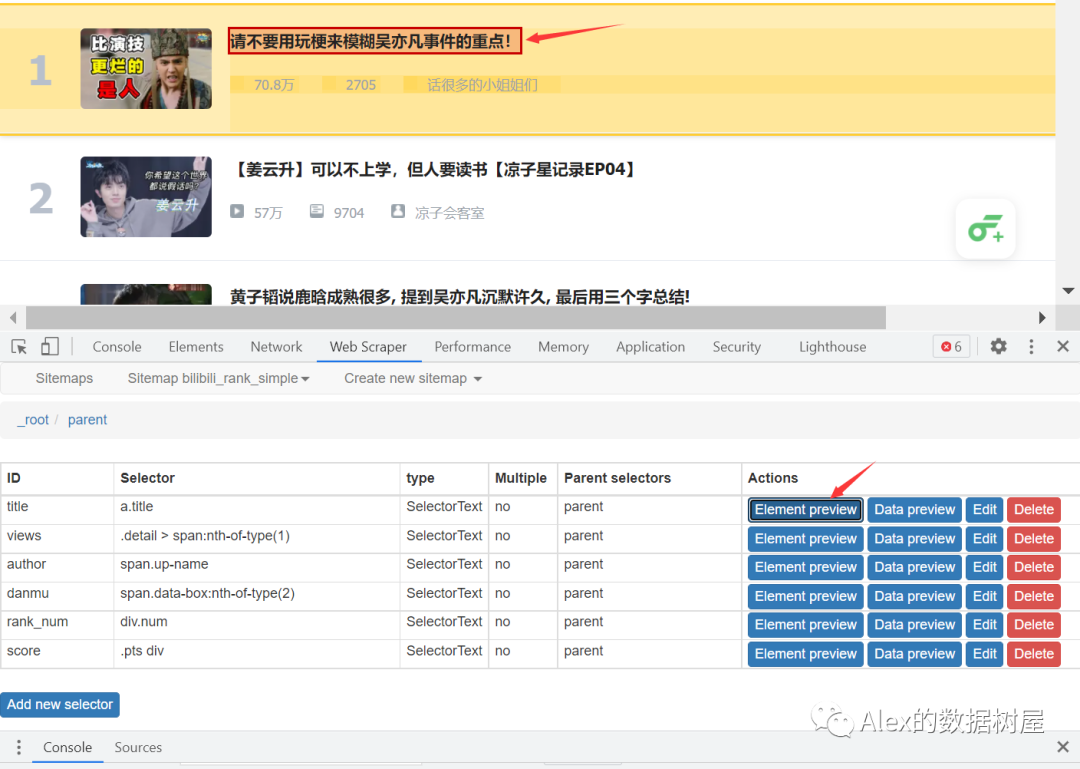
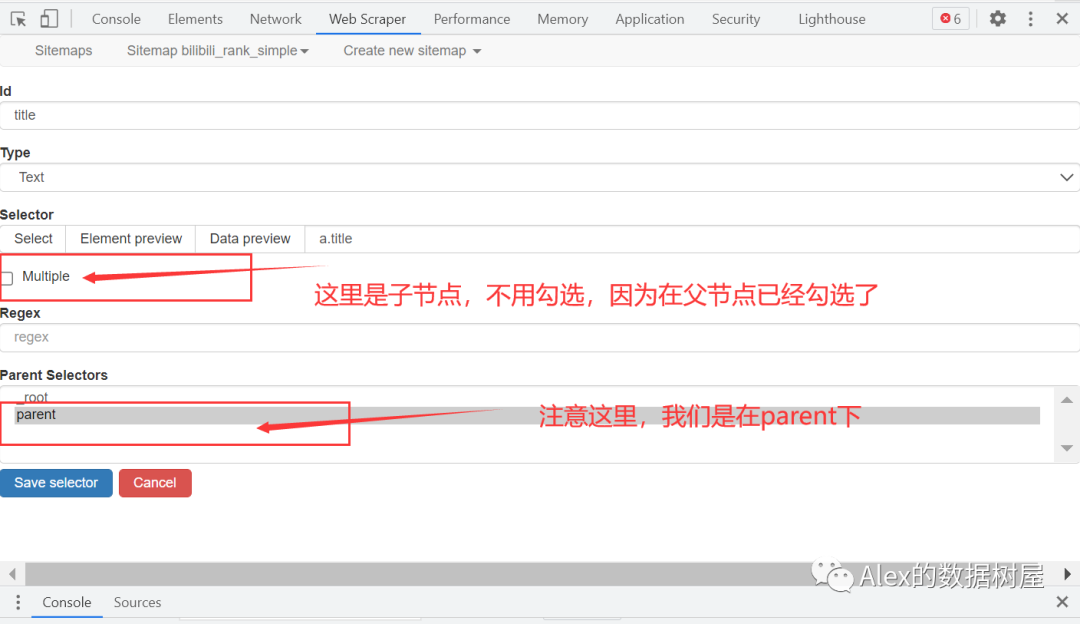
5、依次点击我们要爬取的信息,操作和上次一样,这里就不赘述了,大家直接看图操作,小伙伴们要记住这里的Multiple是选择no的喔(原理自行百度~)
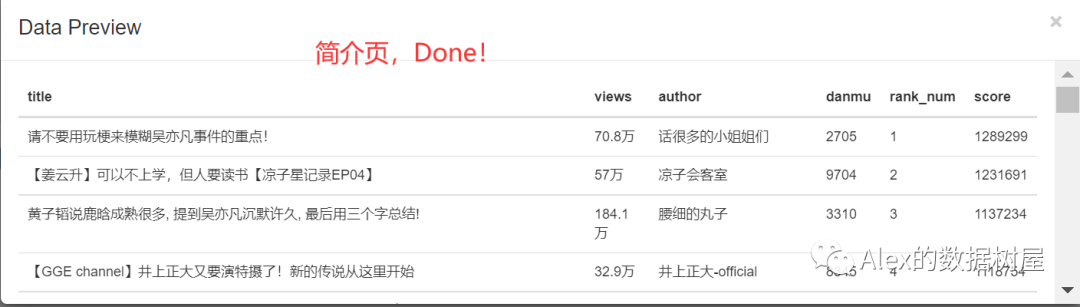
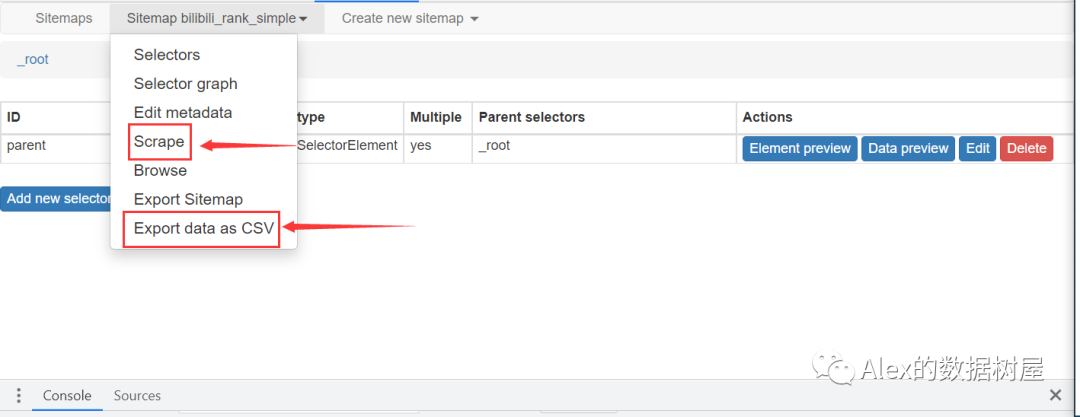
6、做完这些,简介页的数据抓取就已经完成了,点击scrape爬取数据,再点击Export data as CSV导出
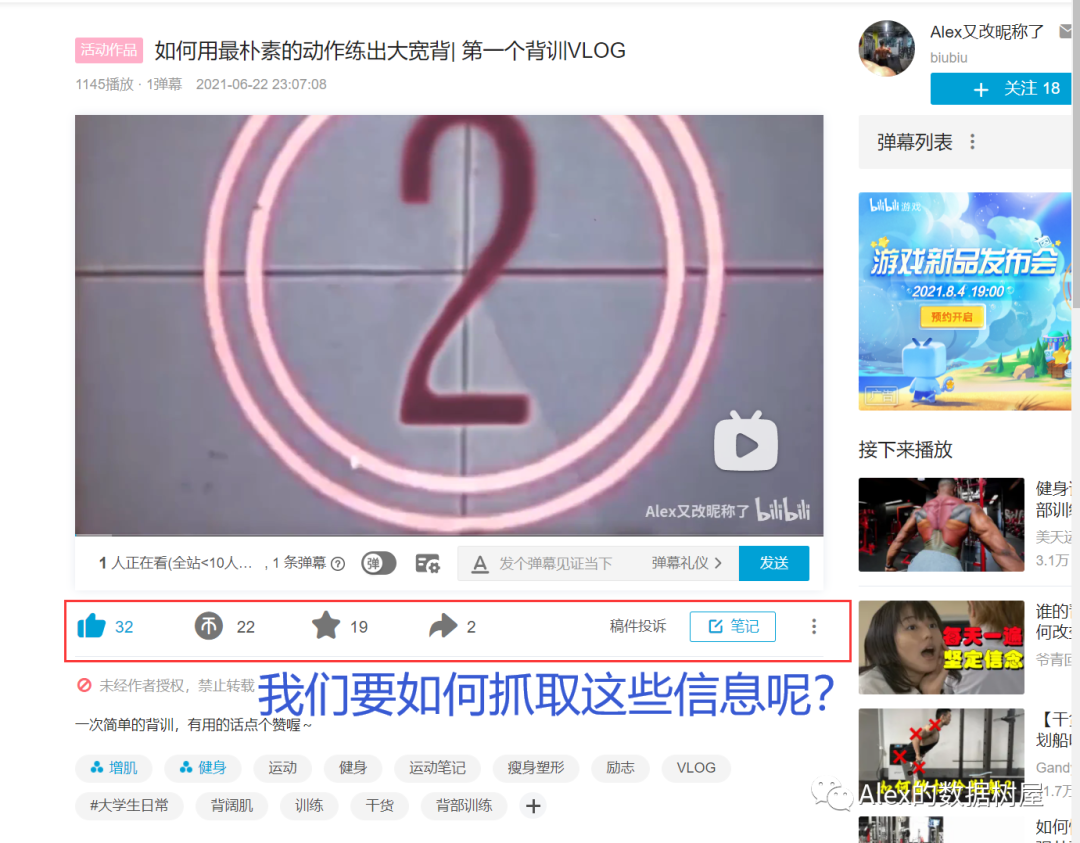
做到这里,聪明好学的小伙伴们要问了,播放、排名、得分这些数据的确抓取到了,但如果要做数据分析的话,数据量好像还不太够的样子呀,列标签也太少了吧?我要如何抓取每个视频里对应的一键三连信息呢?没有点赞投币收藏转发的B站视频,还算一个有灵魂的B站视频吗?我要这币有何用?(疯狂暗示)
放心,你们的心思都被我猜到了?,怎么能get不到你们的意思呢?我们就来尝试用webscraper来搞一下。
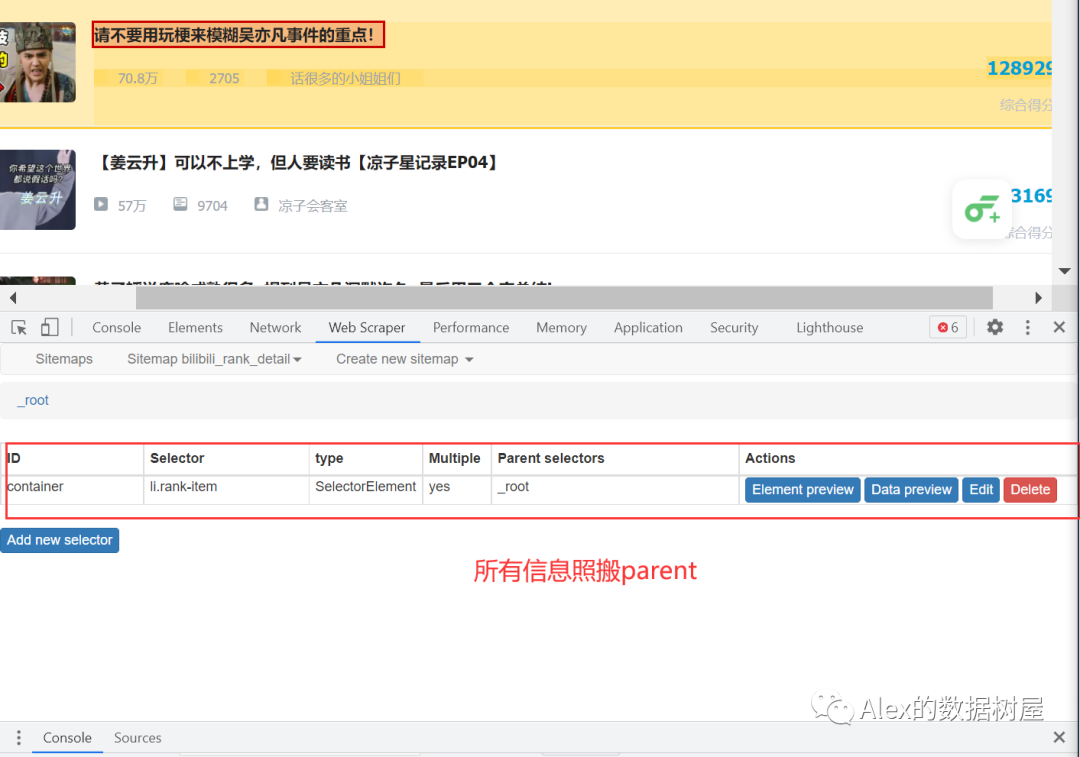
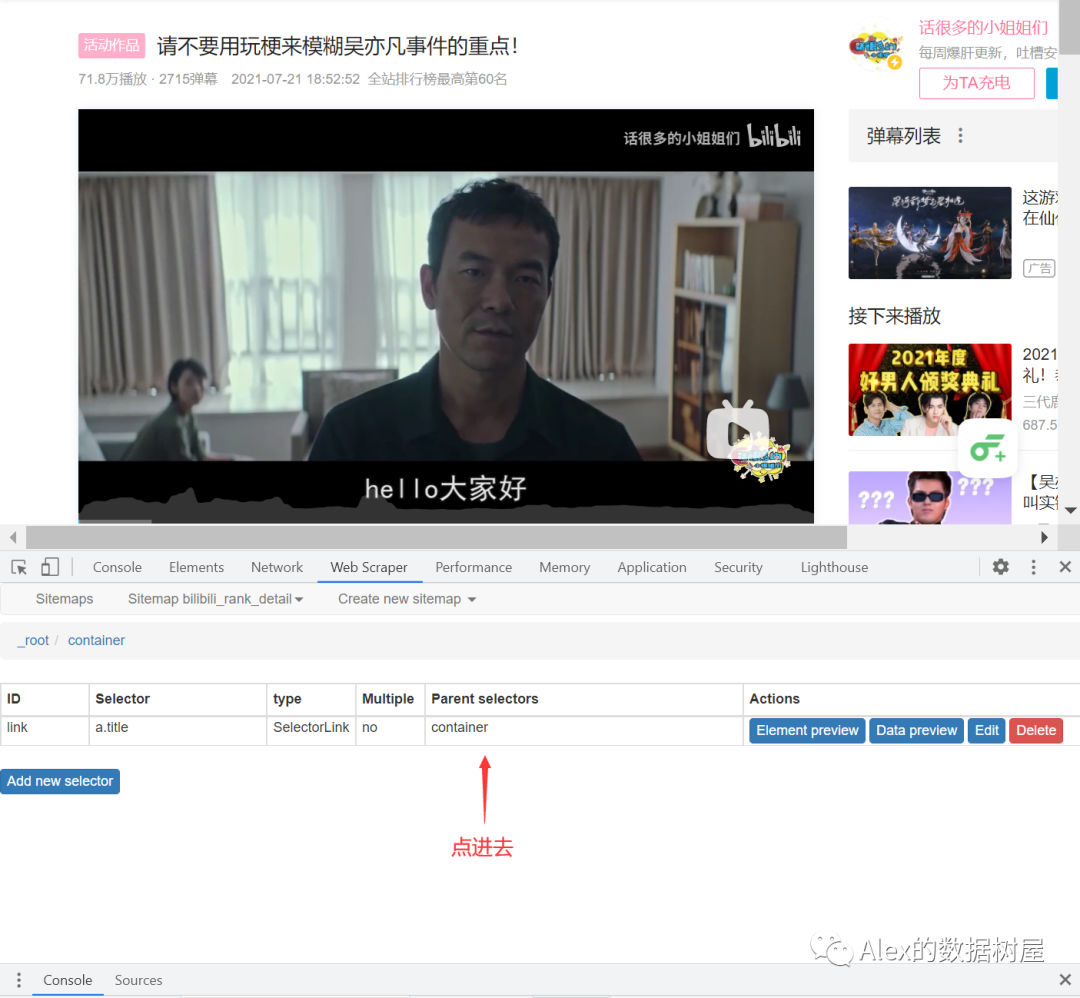
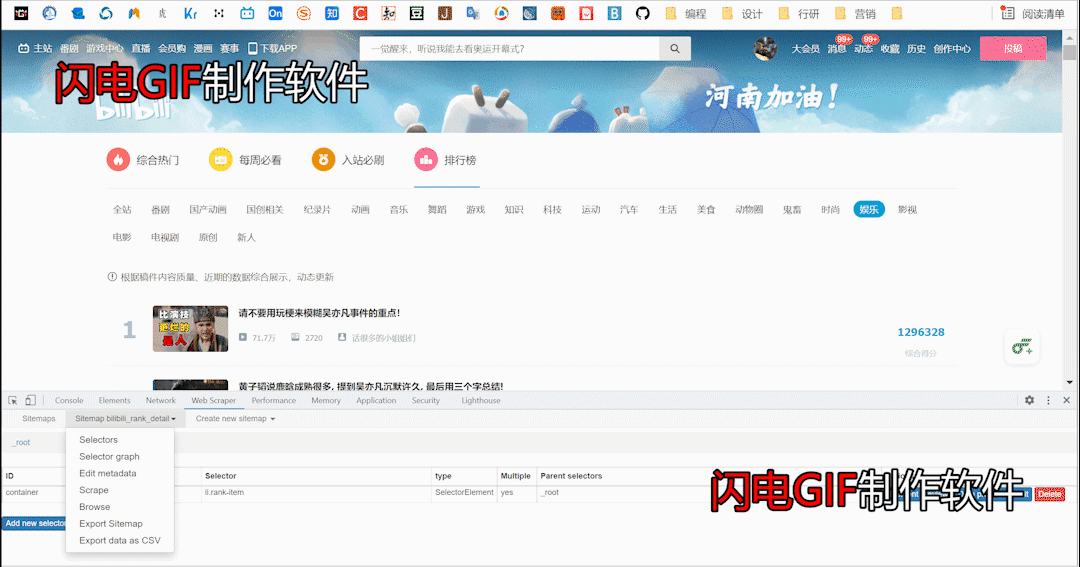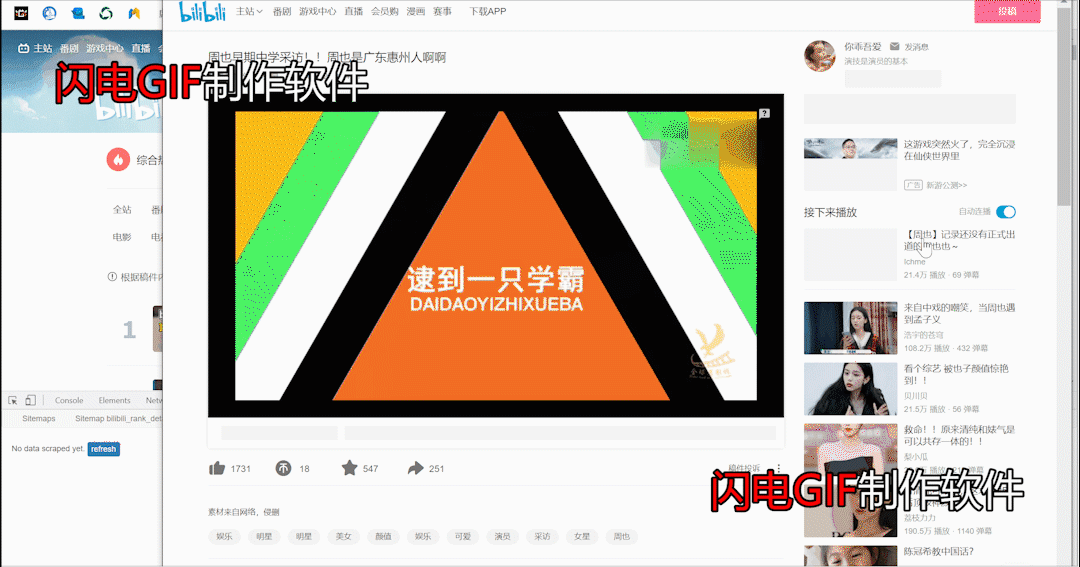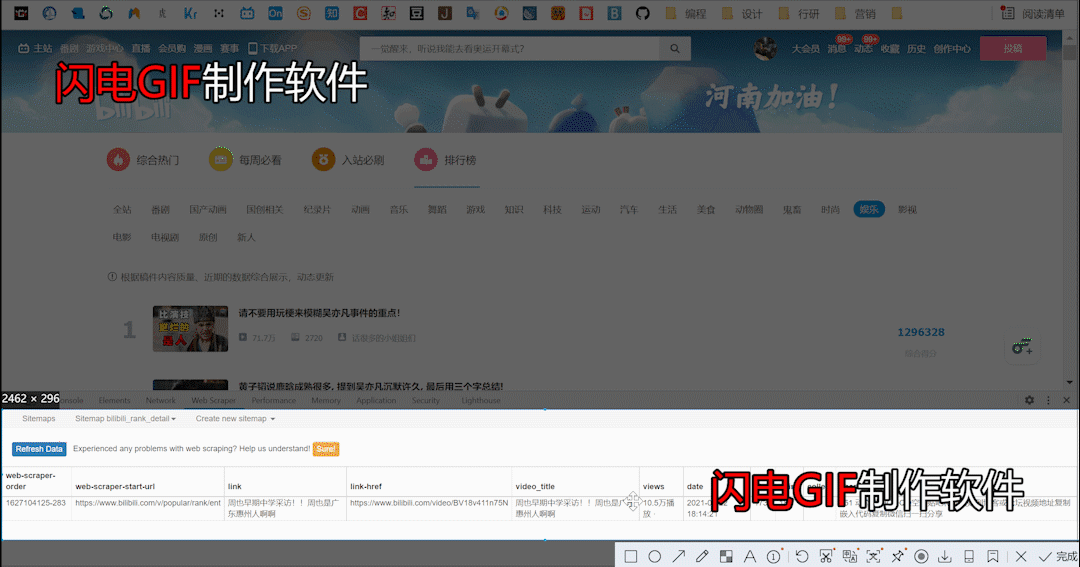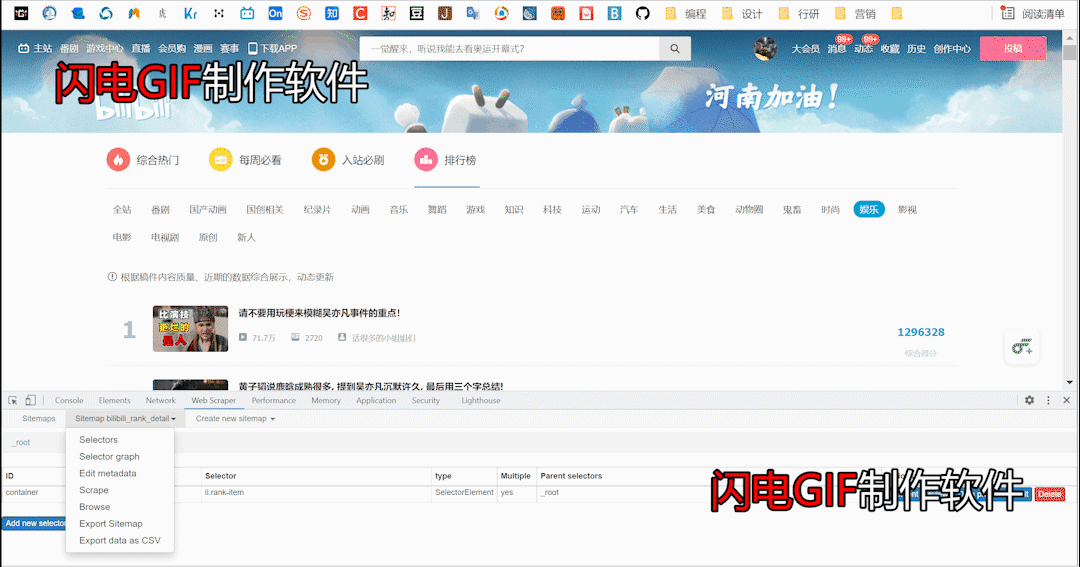
1、同样,我们新建一个sitemap,这里我去取名为bilibili_rank_detail,然后,和上面一样,我们新建一个名为container的父节点,这里的container和上面的parent里的操作完全是一样的,操作完成后,我们点击建好的container
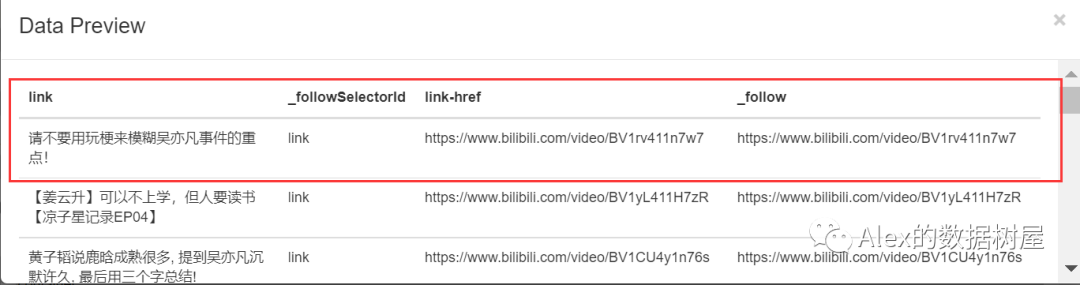
2、点进去后,点击add selector,新建一个SelectorLink子节点,参数如图,操作完成后点击data preview查看,可以看到,每个视频对应的链接就被我们爬取到了
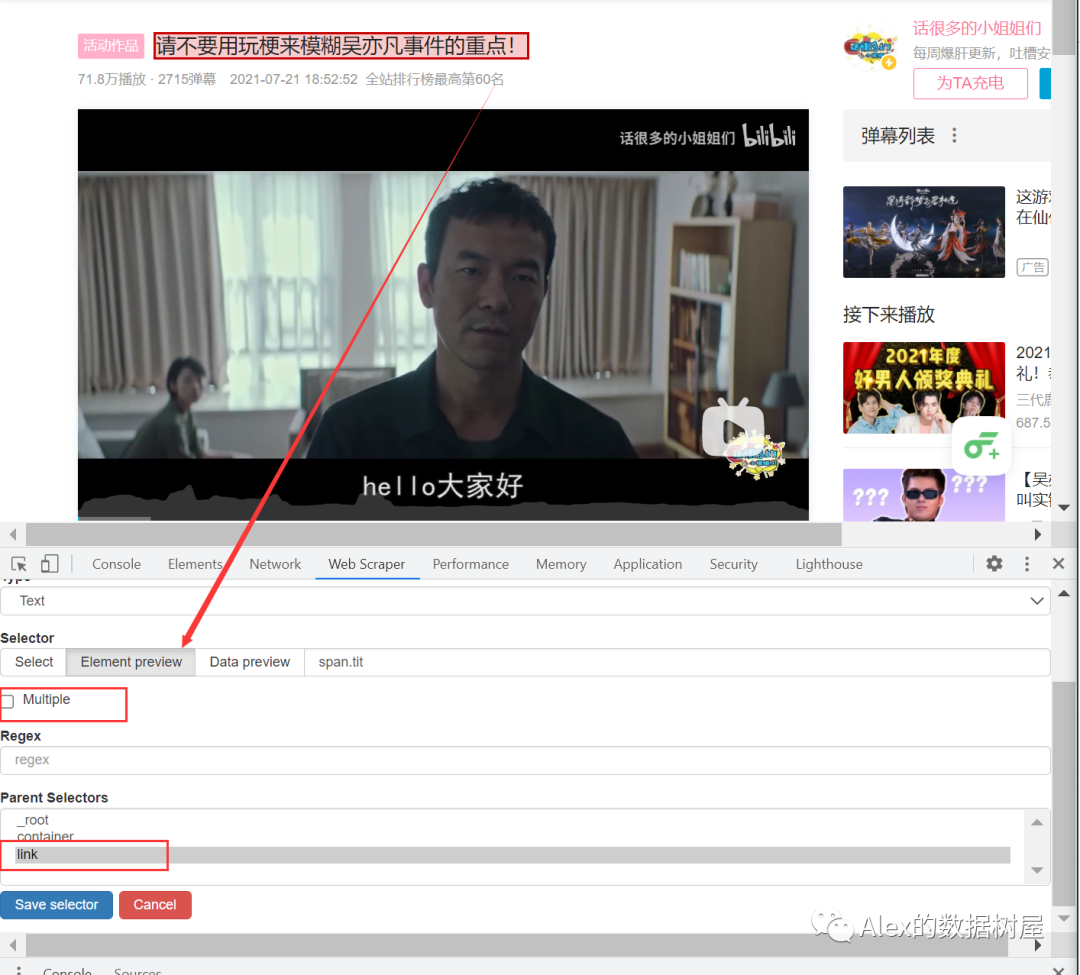
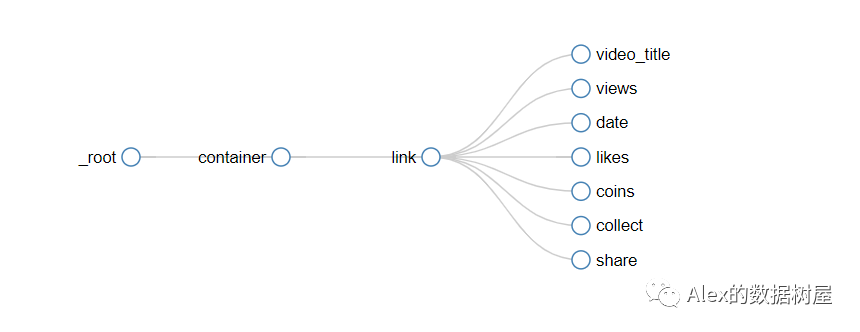
我们点击榜单中的一个视频,来到一个新页面,再打开webscraper,点进去link这个子节点,我们接下来要爬取的三连数据,就是通过在link这个子节点下,建立多个孙子节点来完成我们目标数据的爬取(子子孙孙无穷尽也~)
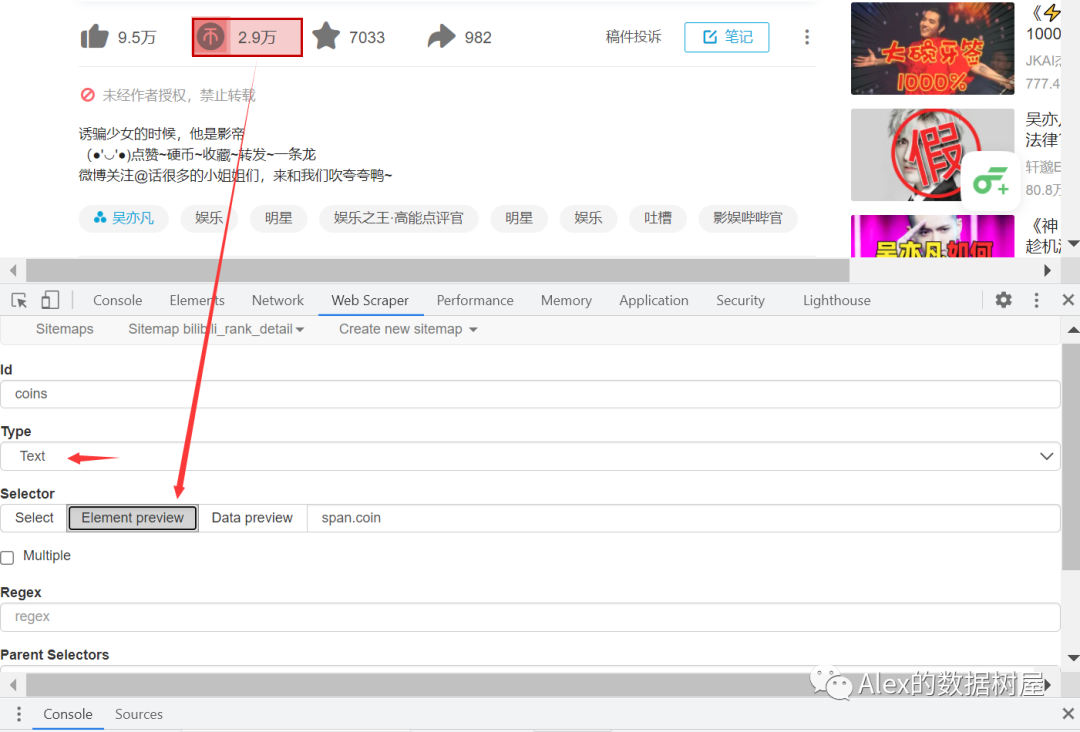
这里,我们就以title和硬币来作示例,其余操作都是一样的,大家自行爬取想要的数据就行(这里看不懂的,请翻看我上一篇干货,讲了Link的知识点)
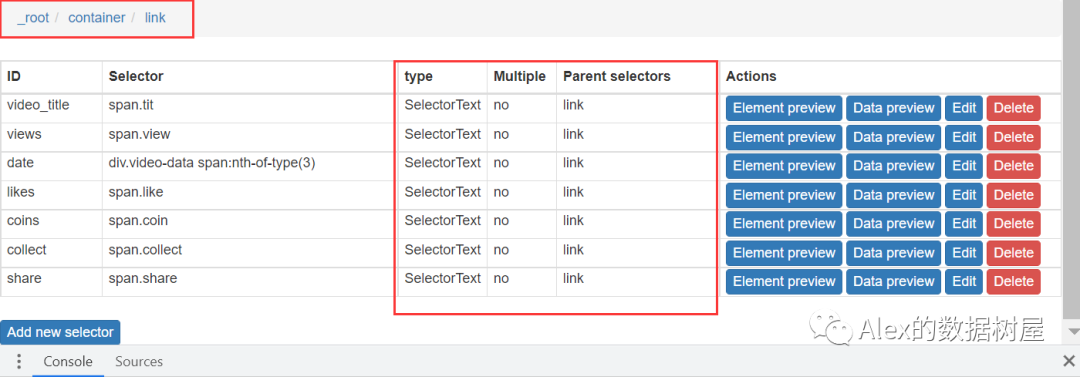
4、各节点的关系结构图如下,是不是神似sklearn里的决策树?
做完这些,我们本次爬虫目的就达到啦!让我们回到排行榜页面,点击scrape开始爬虫,几分钟就能爬取全部的100个视频三连信息,这里我精心录了一个gif让大伙更清楚地了解整个制作流程。
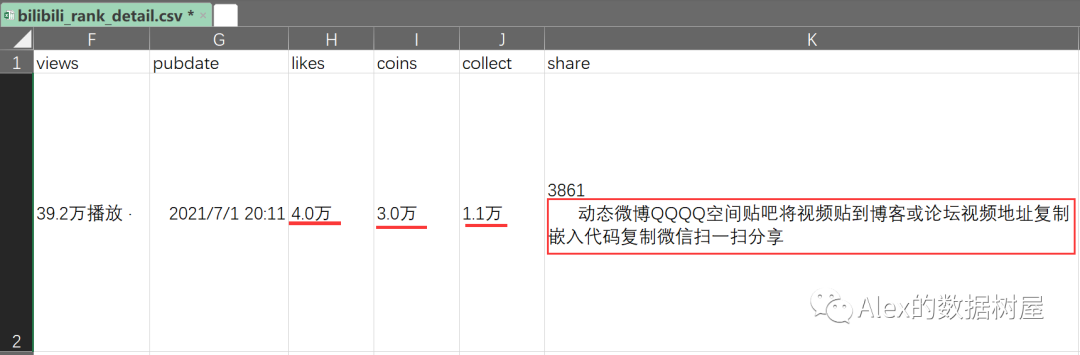
打开excel看一下我们的爬取到的数据,大体上看没啥毛病,但细心的你们应该注意到了,点赞,收藏,转发等列的数据内容都是字符串和数字连在一起的(俗称“脏数据”)。要如何把数据变干净呢?又如何把上面爬取到的两个表格用简单高效的方式连接在一起,在一个表格内呈现呢?如何用商业的视角去解读这些数据呢?
Alex本想在这里和大家继续分享如何在pandas上进行数据预处理的,但我看了一下右下角的字数提示,已经超过1000字了,这次爬虫分享的信息密度又比较大,担心大家消化不过来。(我也要去忙其他的了?)
因此,我打算把关于B站的内容分3期来和大家分享,本篇是爬虫,下篇是使用pandas对脏数据数据预处理和词频统计,下下篇就是python数据可视化+文本分析+sklearn机器学习建模探索各个列标签之间的关系。
我做这个号的主要目的是,在梳理做过的项目和学习笔记之余,和大家分享一些和实际生活紧密联系的数据技巧(或其他工具,定位没那么清晰,不会框死),总之,大家敬请期待?。
总结一下,我们本次爬虫的主要内容就是:通过Link来建立简介页视频和详情页视频的关系,从而去爬取到我们想要的数据。大家先试着用webscraper爬一下(成功了记得留言ヾ(≧▽≦*)o)。
1.看到这里的你,一定很可爱(●'◡'●),如果你觉得本次分享对你有帮助的话,点个关注,点个在看,留个小言,伙伴们的每一份支持,都是我持续分享的动力喔。
2.着急用数据不想动手操作的小伙伴们,可以关注公众号,回复关键词“数据”就可获得本次分享的源码(直接复制就能用)
3.最后的最后,引用产品沉思录主理人少楠??(flomo创始人、播客《奇思驿》主理人、即刻ID:少楠Melow)说过的一句话作为结尾:前方的道路并不拥挤,因为坚持的人并不多。Love and peace。





文章评论