
最近不少读者都留言说博客中的代码越来越返璞归真,但讨论的问题反倒越来越高大上了,从并发到乱序执行再到内存布局各种放飞自我。
其实这倒不是什么放飞,只是Rust对我来说学习门槛太高了,学习过程中的挫败感也很强,在写完了之前的《Rust胖指针胖到底在哪》之后笔者一度决定脱坑Rust了,但截至本周这个目标还是没有实现,因为我所在的Rust学习群,有一个灵魂拷问,Rust的技术本质什么?不回答好这个问题,我简真是没法得到安宁。

Rust 枚举的本质到底是什么?
1.枚举与一般变量定义的比较:首先说在枚举的处理上Rust与C/C++比较一致,从汇编的角度上看枚举和普通的变量声明的最大区别在于,枚举多存了一个类型的描述符。我们先来看下面的代码:
#[derive(Debug)]enum IpAddr {V4(u8, u8, u8, u8),V6(String),}fn main(){let a=127;let b=0;let c=0;let d=1;let home = IpAddr::V4(127, 0, 0, 1);println!("{:#?}", home);}
IP地址是枚举比较适合使用的场景,IP地址就是分为IPV6和IPV4两种细分类型,。与一般的结构体不同,IPV6与IPV4这两种类型是平等的关系,相互独立,非此即彼,而并非是IP类型下的两个元素,因此这时使用枚举类型IpAddr可以比较好的抽象IP地址这种场景。
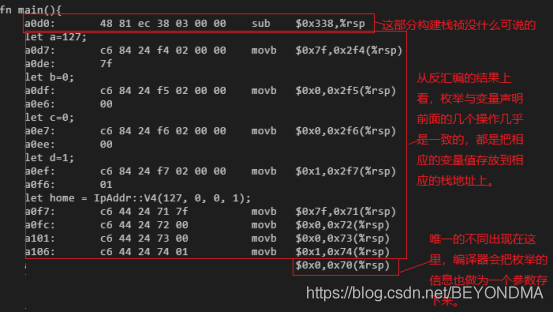
将以上代码进行反汇编,可以看到与普通的变量定义与声明相比枚举对象的定义除了将相应的值存入栈以外,还会多存一个枚举的信息详见下图标红注释:
2.枚举与结构体的异同:我们还是以IP为例说明,IP地址分为V4与V6两大类型,不过单从IPV4的角度上看,如IP地址:127.0.0.1,其中每个网段,对于IPV4的址来说都其中的一部分,是共同组成的关系,这就比较适合使用结构的方式来进行定义,具体如下面的代码:
#[derive(Debug)]enum IpAddr {V4(u8, u8, u8, u8),V6(String),}#[derive(Debug)]struct IPV4(u8, u8, u8,u8);fn main(){let a=127;let b=0;let c=0;let d=1;let home = IpAddr::V4(127, 0, 0, 1);let ipv4home= IPV4(a,b,c,d);let remotehost = IpAddr::V4(119, 3, 187, 35);let loopback = IpAddr::V6(String::from("::1"));let loopStr=String::from("::1");let remotehost1 = IpAddr::V6(String::from("1030::C9B4:FF12:48AA:1A2B"));println!("{:#?}", home);println!("{:#?}", loopback);println!("{}",loopStr);println!("{:?}", remotehost);println!("{:?}", remotehost1);println!("{:?}",ipv4home);}
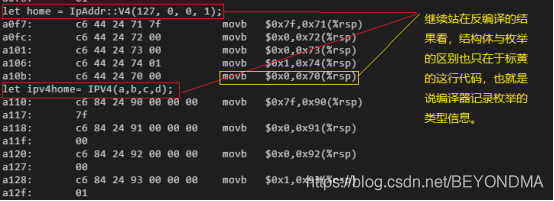
将上述代码反汇编以后,可以看到与结构体相比,枚举也只是增加了一个枚举类型的记录。

一行无关代码,却让效率提高10%?
以上有关枚举的说明部分,比较容易理解,不过这不是今天的重点。最近我所在的Rust学习群有不少同仁正在做一些并发和内存布局方面的研究。
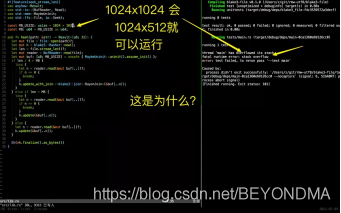
我一顺手恰好将上面的代码实际上放在了一个Rust的并行原型程序中了,结果却意外发现执行时间缩短了5%-10%,我们刚刚也说了枚举类型与一般的变量定义区别不大,因此把代码简化后如下:
use std::thread;fn main() {let mut s = String::with_capacity(100000000);let mut s1 = String::with_capacity(100000000);let handle = thread::spawn(move || {let mut i = 0;while i < 10000000 {s.push_str("hello");i += 1;}});let handle1 = thread::spawn(move || {let mut i = 0;while i < 10000000 {s1.push_str("hello");i += 1;}});handle.join().unwrap();handle1.join().unwrap();}
上述代码的执行时间测试结果如下:
[root@ecs-a4d3 hello_world]# rustc hello7.rs[root@ecs-a4d3 hello_world]# time ./hello7real 0m0.999suser 0m1.906ssys 0m0.050s[root@ecs-a4d3 hello_world]# time ./hello7real 0m1.093suser 0m2.005ssys 0m0.060s[root@ecs-a4d3 hello_world]# time ./hello7real 0m1.079suser 0m1.979ssys 0m0.069s[root@ecs-a4d3 hello_world]# time ./hello7real 0m1.011suser 0m1.902ssys 0m0.066s[root@ecs-a4d3 hello_world]# time ./hello7real 0m1.031suser 0m1.944ssys 0m0.053s
但是在定义了一个无关的变量,并打印的步骤之后,代码如下:
use std::thread;fn main() {let mut s = String::with_capacity(100000000);let reverbit="abcdefghijk";let mut s1 = String::with_capacity(100000000);let handle = thread::spawn(move || {let mut i = 0;while i < 10000000 {s.push_str("hello");i += 1;}});let handle1 = thread::spawn(move || {let mut i = 0;while i < 10000000 {s1.push_str("hello");i += 1;}});handle.join().unwrap();handle1.join().unwrap();println!("{}",reverbit);}
在加了这个无关的变量定义之后,这段代码的执行时间和之前相比至少缩短了5%,这个成绩还是在多执行了print这个IO操作的基础上达到的。
[root@ecs-a4d3 hello_world]# time ./hello7abcdefghijkreal 0m0.963suser 0m1.856ssys 0m0.050s[root@ecs-a4d3 hello_world]# time ./hello7abcdefghijkreal 0m0.960suser 0m1.844ssys 0m0.055s[root@ecs-a4d3 hello_world]# time ./hello7abcdefghijkreal 0m0.964suser 0m1.846ssys 0m0.065s[root@ecs-a4d3 hello_world]# time ./hello7abcdefghijkreal 0m0.958suser 0m1.858ssys 0m0.045s[root@ecs-a4d3 hello_world]# time ./hello7abcdefghijkreal 0m0.963suser 0m1.862ssys 0m0.052s[root@ecs-a4d3 hello_world]# time ./hello7abcdefghijkreal 0m0.963suser 0m1.853ssys 0m0.047s
在确认编译方法没有问题,之后我基本确认这个性能提升不是一个可以忽略的偶然事件。
前导小贴士初始化内存时尽量指定合适的容量:这段Rust程序其实就是通过两个线程handle、handle1分别去处理加工s、s1两个字符串,从程序本身来讲,只有一个小Tip要讲,就是初始化字符串的方式是通过 String::with_capacity方法来进行的,这里先回顾一下上次博客中所说的String内存布局。
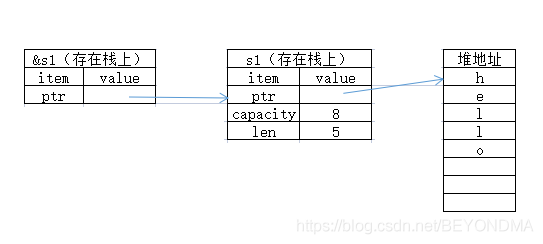
在上面这个内存状态下,执行push_str("!")操作,字符串的capacity容量还没有溢出,不会向系统重新申请堆内存空间,也不会造成ptr指针的变化,只是将len+1,并在o后再加上!,完成后如下图:

也就是说提前将capacity容量设置成比较合适的大小,将避免反复向系统申请动态堆内存,提升程序运行效率。

无关代码提高效率的原因何在?
这里先给出的结论,这又是一个内存、缓存以及CPU多核之间的竞争协同效率问题。在分析这个问题之前我们还是要先回到上次博文中内容,其中String对象在栈上的三个成员ptr、capacity和len都是64位长,加在一起共192位也就是24byte,详见下图:
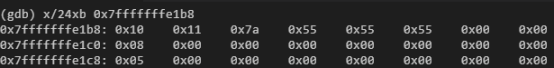
X86CPU的高速缓存每行容量却是64byte,也就是说按照我们最初的定义方式:
let mut s = String::with_capacity(100000000);let mut s1 = String::with_capacity(100000000);
字符串s和s1占用连续的48byte栈空间,这种内存分配布局就使它们很可能位于同一个内存缓存行上,也就是说不同的CPU在分别操作s和s1时,其实操作的是同一缓存行,那么这样的操作就可能相互影响,从而使效率降低。
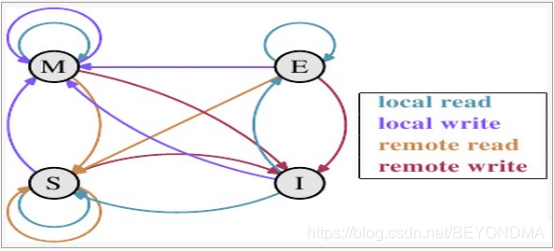
我们知道现代的CPU都配备了高速缓存,按照多核高速缓存同步的MESI协议约定,每个缓存行都有四个状态,分别是E(exclusive)、M(modified)、S(shared)、I(invalid),其中:
-
M:代表该缓存行中的内容被修改,并且该缓存行只被缓存在该CPU中。这个状态代表缓存行的数据和内存中的数据不同。
-
E:代表该缓存行对应内存中的内容只被该CPU缓存,其他CPU没有缓存该缓存对应内存行中的内容。这个状态的缓存行中的数据与内存的数据一致。
-
I:代表该缓存行中的内容无效。
-
S:该状态意味着数据不止存在本地CPU缓存中,还存在其它CPU的缓存中。这个状态的数据和内存中的数据也是一致的。不过只要有CPU修改该缓存行都会使该行状态变成 I 。
四种状态的状态转移图如下:
我们上文也提到了,在容量足够的情况下,执行执行push_str操作,并不会使程序向系统再次malloc内存,但是会使len的值有所变化,那么由于不同CPU在同时处理s1和s时其实是在操作同一缓存行,CPU0在操作s的len的同时CPU1很可能也在操作s1的len,这种remote write的操作,使该缓存行的状态总是会在S和I之间进行状态迁移,而一旦状态变为I将耗费比较多的时间进行状态同步。
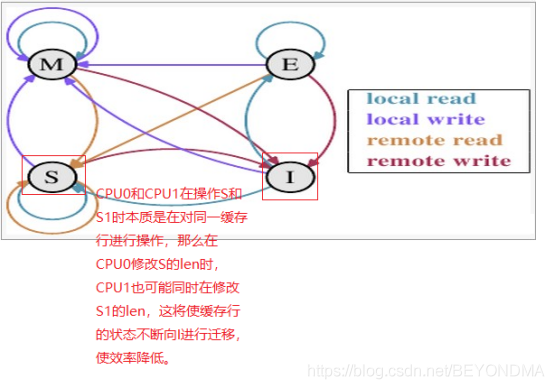
因此我们可以基本得出let reverbit="abcdefghijk";这行无关的代码之后,改变了栈上的内存空间布局,无意中使s1和s被划分到了不同的缓存行上,这也使最终的执行效率有所提高。当然由于dump高速缓存的状态将从很大程度上改变程序的行为,因此本文的求证过程不像前几篇那么严谨,如有错漏还请各位读者指正。
这行看似啥用没有的let reverbit="abcdefghijk";代码最终却使效率提升了近10%,这也让人不得不感叹编程到了最后绝对是一门艺术,闲棋与闲子反而最显功力。
马超,CSDN博客专家,阿里云MVP、华为云MVP,华为2020年技术社区开发者之星。


☞字节跳动宣布取消大小周;淘宝、支付宝等阿里系App取消开屏广告;Python 3.10 beta 4 发布|极客头条
☞从摩托罗拉、诺基亚再到航空领域应用,这款开源数据库的成功如何成就天才程序员?


文章评论