
写在前面
现每个后端的同学的日常都在跟服务(接口)打交道,维护老的比较大单体应用、按业务拆得相对比较细的新服务、无论企业内部用的,面向用户的前端的服务。流量大的有流量小的,有重要的有不那么重要的。
但是,不管怎样的服务,我们总思考过这样的问题:我能不能实时监控/查看服务的运行情况呢,服务一挂掉我马上能收到预警呢?这个问题的答案就是:服务监控。
服务监控一般包括两部分:
-
服务运行环境的监控。毕竟现在云环境所占比例越来越多不能单纯叫服务器(硬件)监控了。我们日常遇到的服务挂掉多少是运行环境出问题,宕机啊,网络,磁盘故障等。(本篇先聊聊这个);
-
服务本身的监控,也就是web应用的监控。下一篇再聊。
Prometheus简介
现在我们做监控一般是这样的:
-
先搭个监控服务端
-
各被监控客户端往服务端push数据(或服务端定时主动去客户端pull,我们现在就是这种模式)
-
服务端把pull的数据存到时序数据库中
-
再搭建一个图形面板Grafana展示收集的监控数据
我们现在用的监控服务端是prometheus
Prometheus官网地址:https://prometheus.io/
Prometheus GitHub:https://github.com/prometheus/prometheus/
Grafana Github: https://github.com/grafana/grafana
其实以上搭配几乎已经成业界标准(个人角度)
prometheus的架构
上一张prometheus架构图
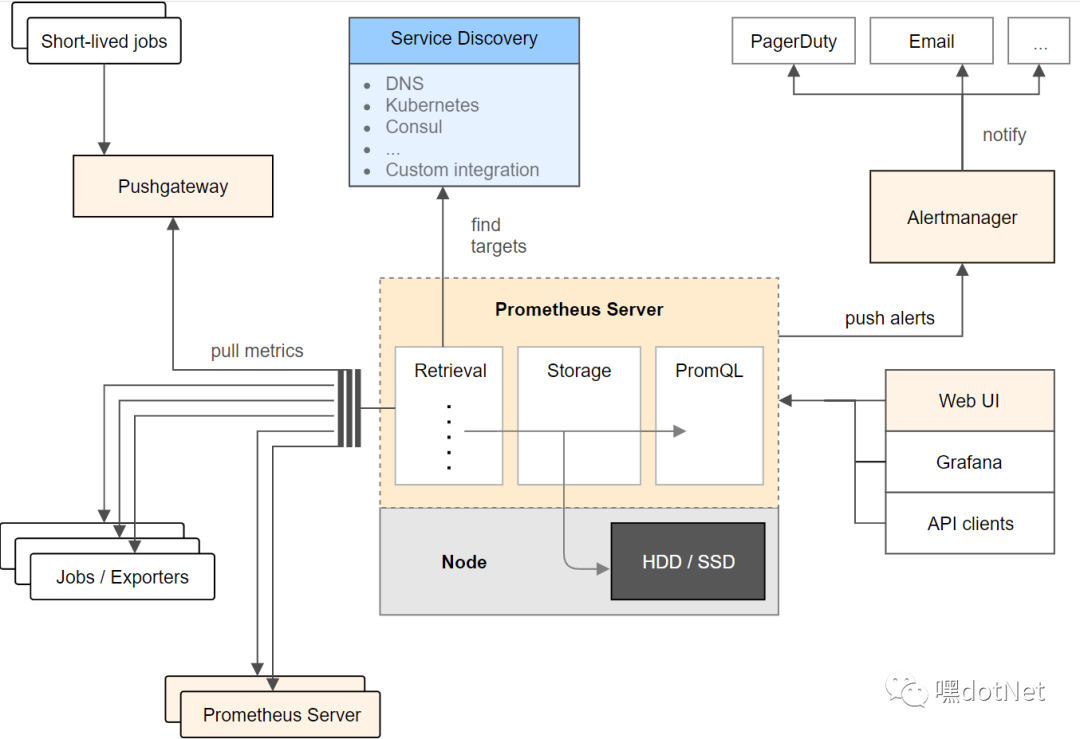
大家可以花点时间看一下
其中
-
Exporter:负责收集目标对象(如Host或Container)的性能数据,并通过HTTP接口供Prometheus Server获取。每一个客户端都会提供一个 /metrics 的get接口
-
Prometheus Server:负责从客户端(Exporters)拉取和存储监控数据,并给用户通过PromQL查询。
-
可视化组件 Grafana:获取Prometheus Server提供的监控数据并通过Web UI的方式展现数据的仪表盘。
-
AlertManager:负责根据告警规则和预定义的告警方式发出例如Email、Webhook之类的告警。
prometheus存储数据结构
我先贴个示例:
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 3109478400
# HELP dotnet_total_memory_bytes Total known allocated memory
# TYPE dotnet_total_memory_bytes gauge
dotnet_total_memory_bytes 4289400
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 4.01
# HELP http_requests_in_progress The number of requests currently in progress in the ASP.NET Core pipeline. One series without controller/action label values counts all in-progress requests, with separate series existing for each controller-action pair.
# TYPE http_requests_in_progress gauge
http_requests_in_progress{method="GET",controller="",action=""} 1
# HELP process_num_threads Total number of threads
# TYPE process_num_threads gauge
process_num_threads 19
#HELP 是对监控指标(Metric)的注释说明
#TYPE 监控字段的类型 ,比如process_virtual_memory_bytes 是 gauge类型的监控(具体可看这里)
在形式上,所有的指标(Metric)都通过如下格式标示:
<metric name>{<label name>=<label value>, ...}
指标的名称(metric name)可以反映被监控样本的含义(比如,http_request_total - 表示当前系统接收到的HTTP请求总量)。指标名称只能由ASCII字符、数字、下划线以及冒号组成并必须符合正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*。
标签(label)反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等。标签的名称只能由ASCII字符、数字以及下划线组成并满足正则表达式[a-zA-Z_][a-zA-Z0-9_]*。
例如:
api_http_requests_total{method="POST", handler="/messages"}
也可以这样写(比较少见大家看第一种写法就好):
{__name__="api_http_requests_total",method="POST", handler="/messages"}
Prometheus Server环境搭建
运行环境:
我这里有两台测试的虚拟机 192.168.43.215,192.168.43.216
因为这里是测试只用docker启动一台在215即可;
先准备配置文件:/etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
monitor: 'edc-lab-monitor'
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
# - "first.rules"
# - "second.rules"
scrape_configs:
- job_name: 'prometheus_server'
static_configs:
- targets: ['192.168.43.215:9090']
#主机数据收集
- job_name: 'node-exporter'
static_configs:
- targets: ['192.168.43.215:9100','192.168.43.216:9100']
#容器数据收集
- job_name: 'cAdvisor'
static_configs:
- targets: ['192.168.43.215:9101','192.168.43.216:9101']
docker:
docker run -d -p 9090:9090 \
-v /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
--name prometheus \
prom/prometheus
跑起来了
http://192.168.43.215:9090/targets
前面四个State=DOWN表示该数据收集节点挂了,这里因为我们还没运行起来
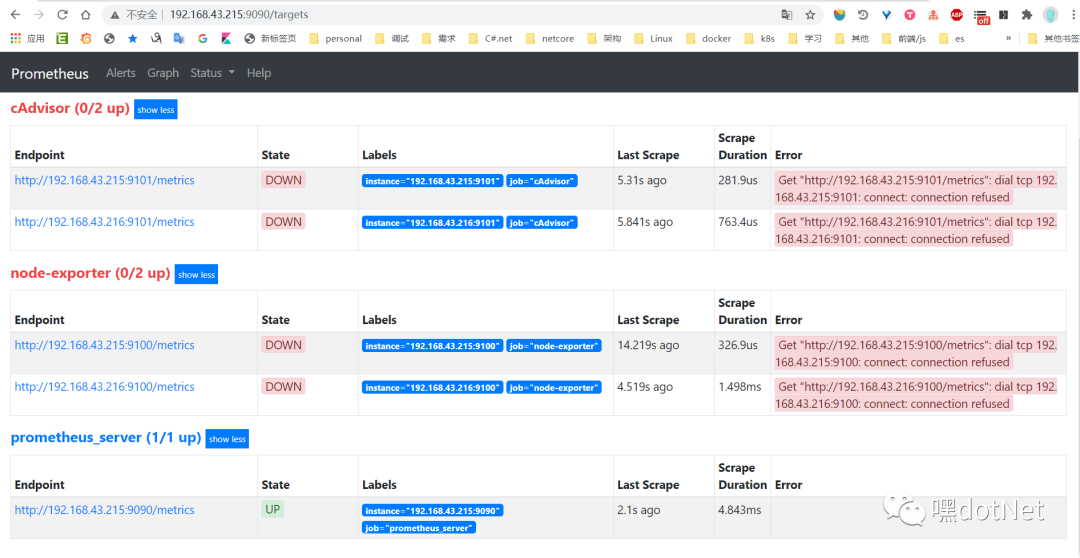
顺便说一下正式环境一般用集群,但是其实prometheus单机也有非常不错的性能。足以满足很多吞吐量不是非常夸张的监控需求。
节点数据收集--主机数据收集
来,开始收集主机数据了,用的是:node_exporter
215,216 都给安排上
docker run
docker run -d -p 9100:9100 \
-v "/proc:/host/proc" \
-v "/sys:/host/sys" \
-v "/:/rootfs" \
--name node-exporter \
prom/node-exporter \
--path.procfs /host/proc \
--path.sysfs /host/sys \
--collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
跑起来了
节点数据收集--docker容器数据收集
docker容器数据的收集用的是:cAdvisor
同样的,215,216 都给安排上
docker run
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=9101:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:latest
跑起来了
再看看prometheus server
http://192.168.43.215:9090/targets
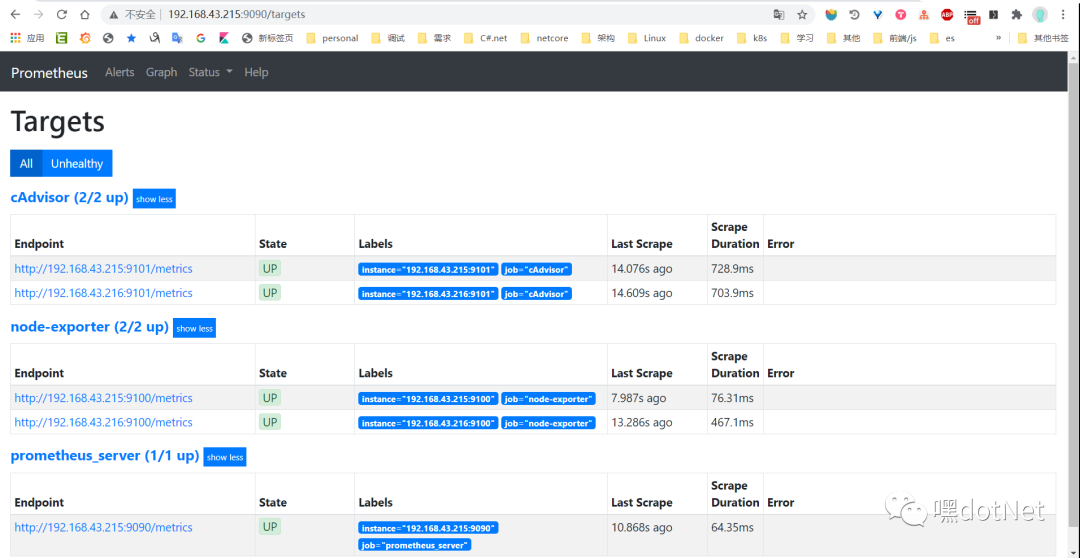
可以看到之前State=DOWN的红色节点都绿油油起来了
数据都准备好了,来看看我们美美的仪表盘吧~
集成Grafana仪表盘
安装,只安装一个215就好了
依旧是 docker run
docker run -d --name=grafana -p 3000:3000 grafana/grafana
首次登录账户密码都是:admin 并会要求你重置

重置密码后进去主页
初始化数据源
点击“Add data source”,选择 Prometheus
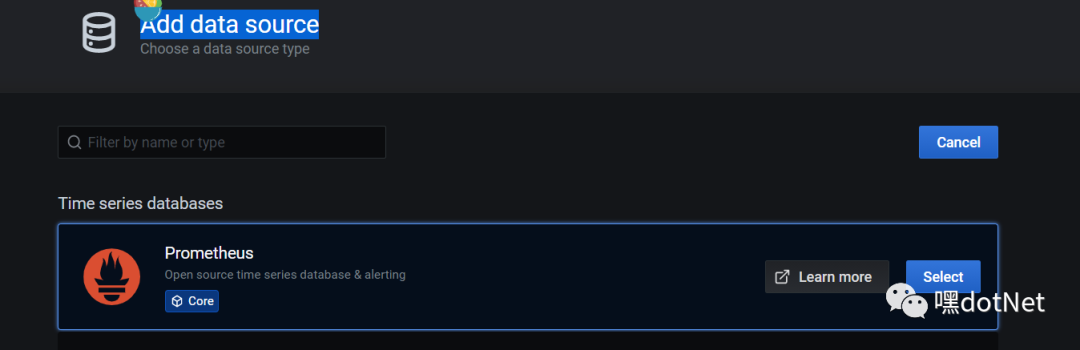
注意填对 prometheus server 地址,点击底部的“保存 & 测试” 按钮
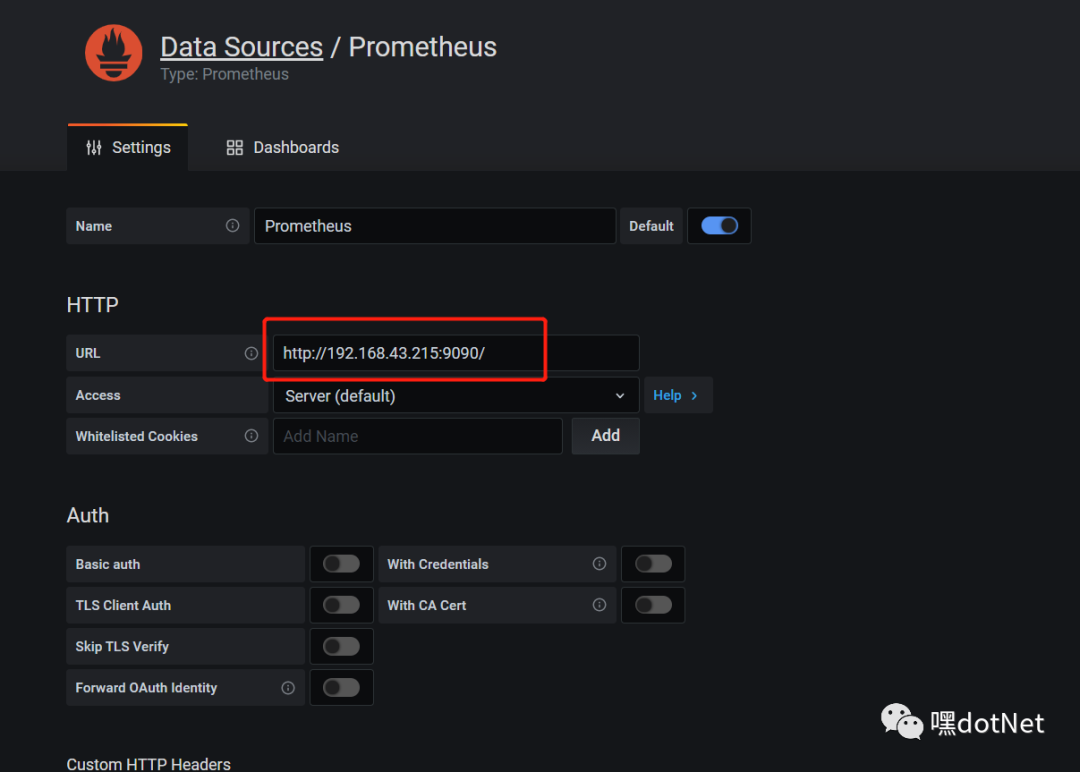
出现这个表示数据源添加成功

数据源添加好了,准备分别为主机监控和容器监控添加仪表盘;
选个合适的仪表盘
https://grafana.com/grafana/dashboards?search=docker 可以在这里顺便搜,选个合适自己的(当然也可以自己构建)
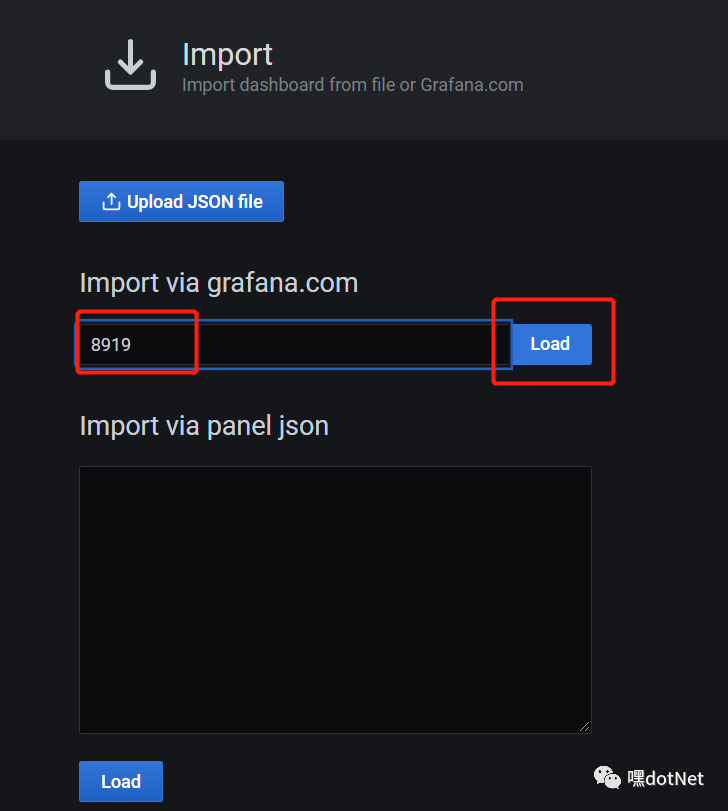
我为node_exporter选择id=8919,cadvisor选了id=11558,大佬们做好的仪表盘
import仪表盘
点击这个import
填入8919,后点击load
加载成功后继续点import
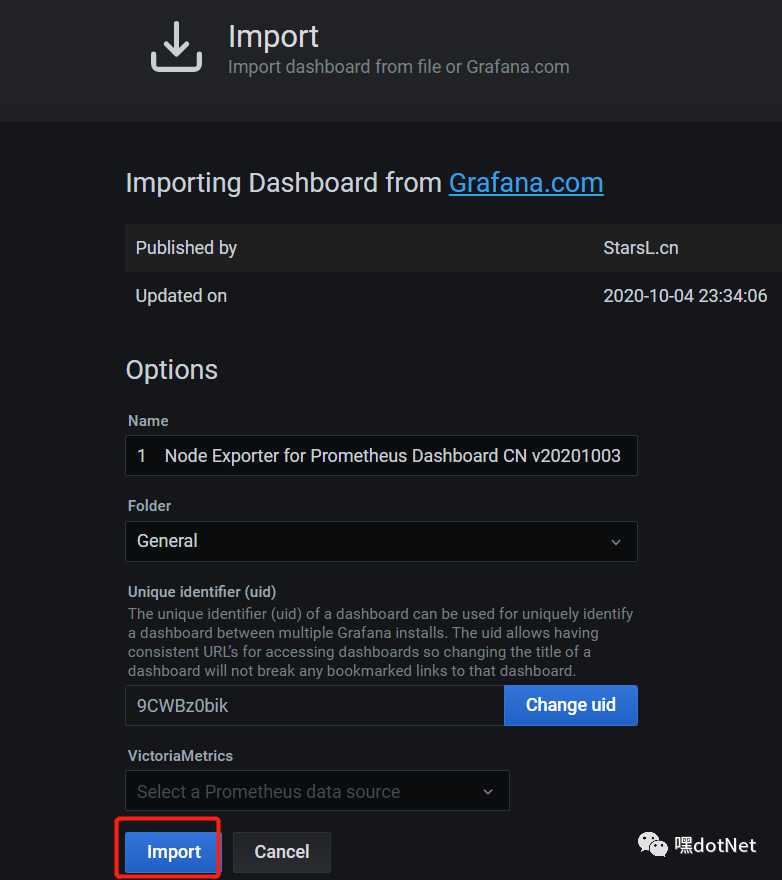
美滋滋
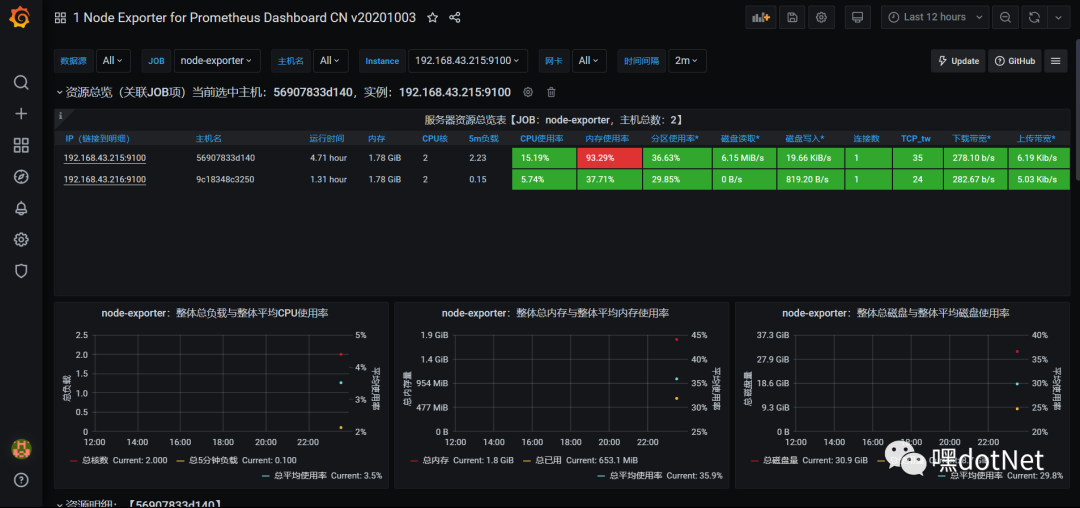
同样流程把cadvisor的11558也给安排上:
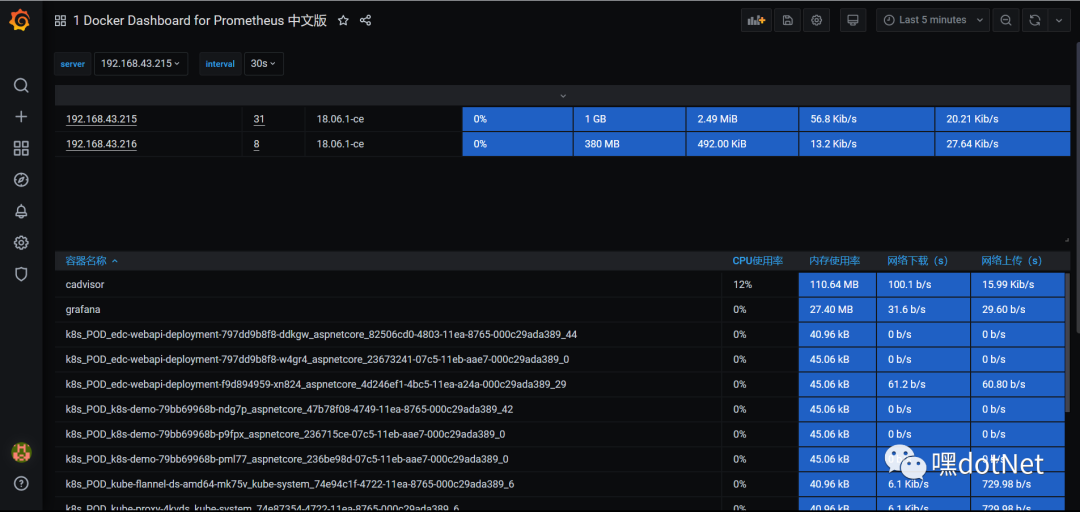
爽歪歪~~,当然还有更多选择,这里只是抛砖引玉,大家可以慢慢找个符合自己需求的仪表盘,实在找不到自己绘制也行。
总结
因为硬件、服务环境监控这些主要是运维的业务范畴,我就写简单带过。
下篇讲讲怎么在Asp.Net Core WebApi中集成。有时间也会多写写Alert预警等,先挖坑。
参考
主要还是跟随龙哥(Edison Zhou)步伐
https://www.cnblogs.com/edisonchou/p/docker_monitor_introduction_part3.html
https://www.cnblogs.com/edisonchou/p/docker_monitor_introduction_part2.html
https://yunlzheng.gitbook.io/prometheus-book/
https://www.cnblogs.com/catcher1994/p/13513184.html

文章评论