回复“书籍”即可获赠Python从入门到进阶共10本电子书
前言
大家好,我是黄伟。上周我们分享了词云,手把手教你使用Python打造绚丽的词云图,这次我们来看看分词。我们从之前学习过的wordcloud可以得知它只能进行英文分词,中文暂不支持,这也正是它美中不足的地方,但是有个模块正好弥补了这一点,它就是----jieba,中文名结巴,没错,你没听错也没看错,就是结巴。
一、jieba的使用
1.安装
jieba的安装不管在哪个地方安装都是一个老大难的问题,这也真是让小编头痛欲裂,幸好小编昨天下好了(花了一天,不好意思说出口)。。
下载好后,我们解压它,在文件主目录中按住shift键然后右击选择‘在此处打开命令窗口’,然后输入命令:
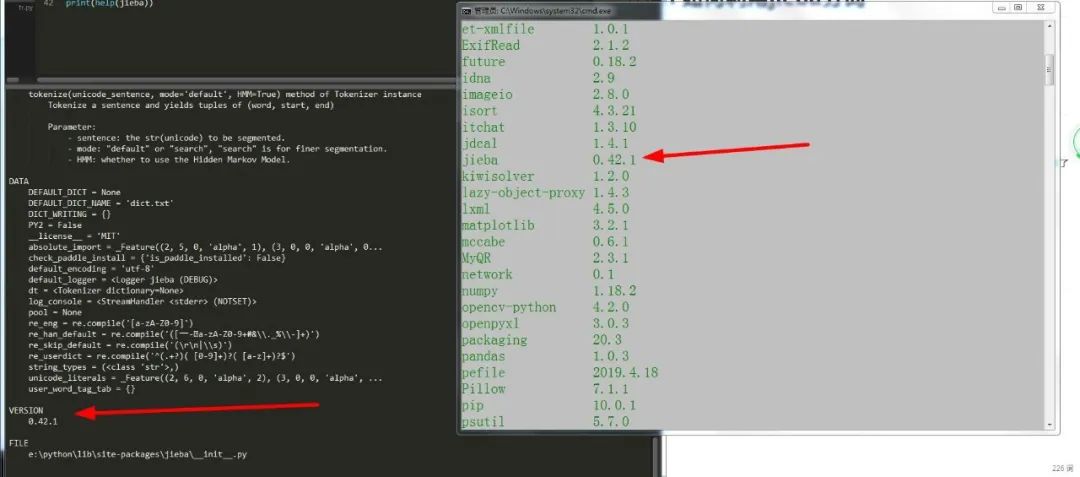
python setup.py install安装即可,可以看到安装的版本信息:
2.jieba的分词模式
一、精确模式
它可以将结果十分精确分开,不存在多余的词。
常用函数:lcut(str) 、 cut(str)
比如我随便找一段话进行拆分:
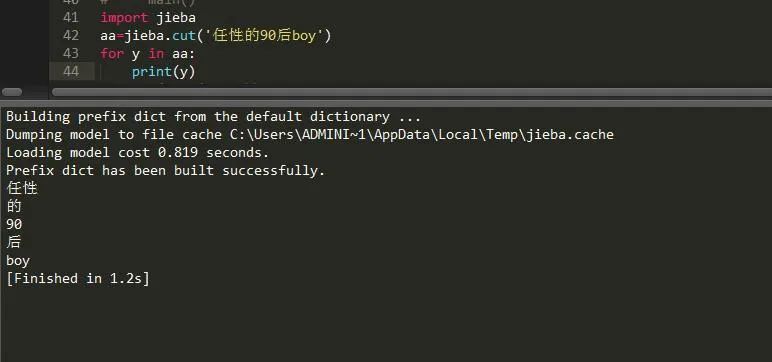
import jiebaaa=jieba.cut('任性的90后boy')
这样我们就得到了aa这样一个生成器序列,然后我们将它遍历即可得到最终结果:
如果不想让它换行显示,想让它在一行显示并且能看到效果的话,可以这样做:
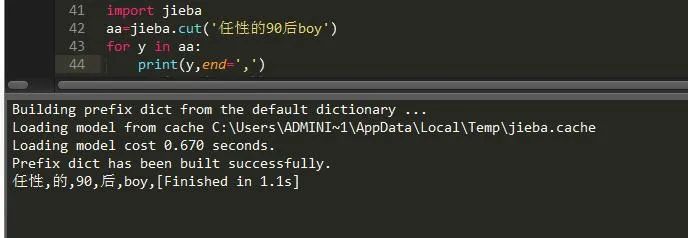
很显然,我的关键字太少,导致它的效果不是很明显,下面增加关键字:
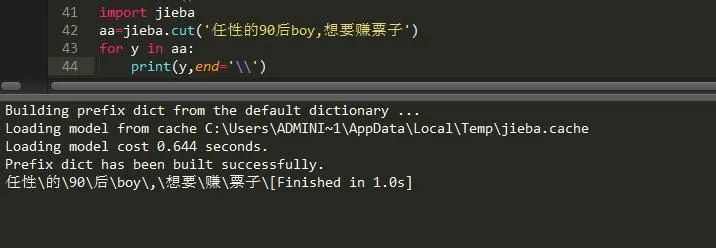
经过这次的修改,是不是就清楚多了了。
二、全模式
它可以将结果全部展现,也就是一段话可以拆分进行组合的可能它都给列举出来了,不信可以来看看
常用函数:
lcut(str,cut_all=True) 、 cut(str,cut_all=True)还是来看下它的妙处:
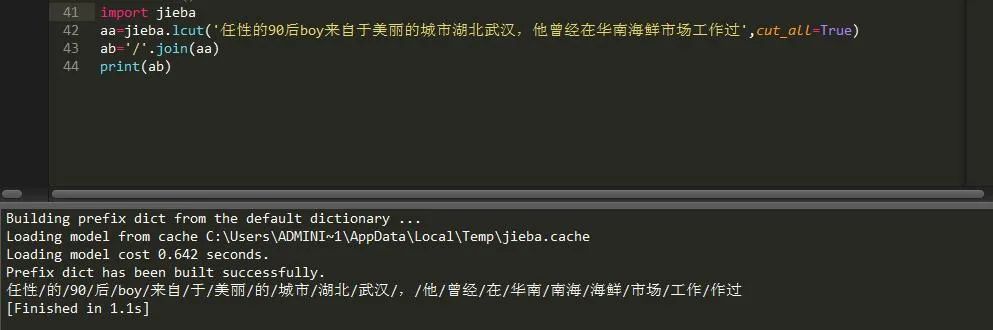
可以看到,它将这段话中所有可能的组合都列举出来了,但是有些组合显然不是我们想要的。
三、搜索引擎模式
将结果精确分开,对比较长的词进行二次切分。
lcut_for_search(str) 、cut_for_search(str)
它的妙处在于它可以将全模式的所有可能再次进行一个重组,下面来看下:
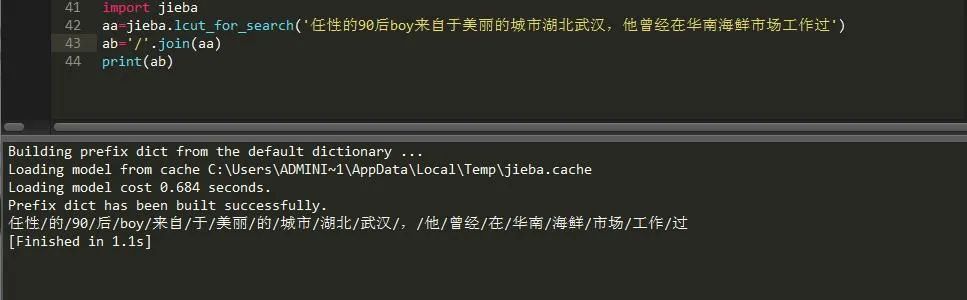
这样就可以看到我们想要的结果了,所以说这种模式十分适合搜索引擎搜索查找功能。
我们还可以使用列表的count方法统计出分词中某个词出现的频率:
print(ab.count('武汉')) #这样的话就是1通过对上文的了解,相信大家对于lcut 和cut的区别还有点陌生,其实lcut和cut都能达到中文分词的效果,只是不同的是lcut返回的结果是列表,而cut返回的是生成器罢了。
3.jieba的其它应用
1)、添加新词
它是将本身存在于文本中的词进行一个重组,让它成为一个个体,使之更为形象而设立的:
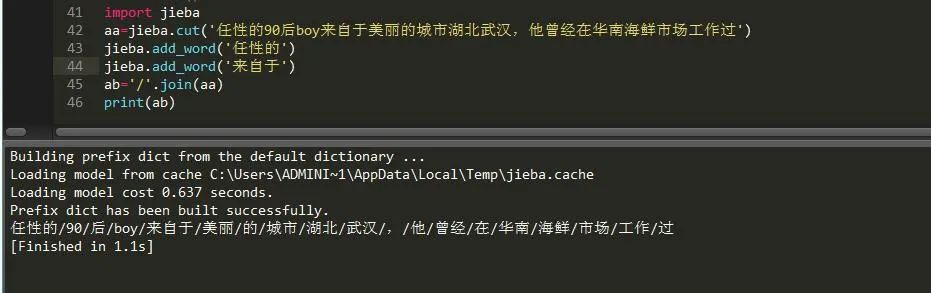
可以看到,它现在就可以将我设置的两个词连贯起来,这对于名字分词是很有帮助的,有时候分词会将三个字甚至是多个字的人名划分开来,这个时候我们就需要用到添加新词了。当然,如果你添加了文本中没有的词,那是没有任何效果,可以看到:
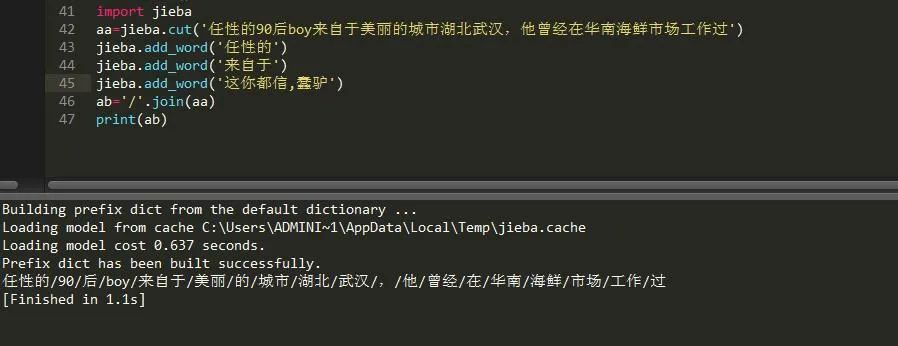
这个自己定义的是无法显示在这上面的,jieba添加新词只会添加文本里有的词,如果想添加其它词,我们得用到字典,添加属于自己的字典。
2)、添加字典
jieba可以添加属于自己的字典,用来切分查找关键词。这样就可以有效缩小查找范围,从而使得匹配完成度更高,时间更短。我们可以使用load_userdict函数来读取自定义词典,它需要传入一个文件名,格式如下:
#文件一行只可写三项参数,分别为词语、词频(可省略)、词性(可省略)空格隔开,顺序不可颠倒jieba.load_userdict(file)
这样就可以读取到该文件中的所有文本,然后我们让它去匹配我们要进行分词的文本,然后利用三大模式中的一种就可以精确匹配到要查找的内容。
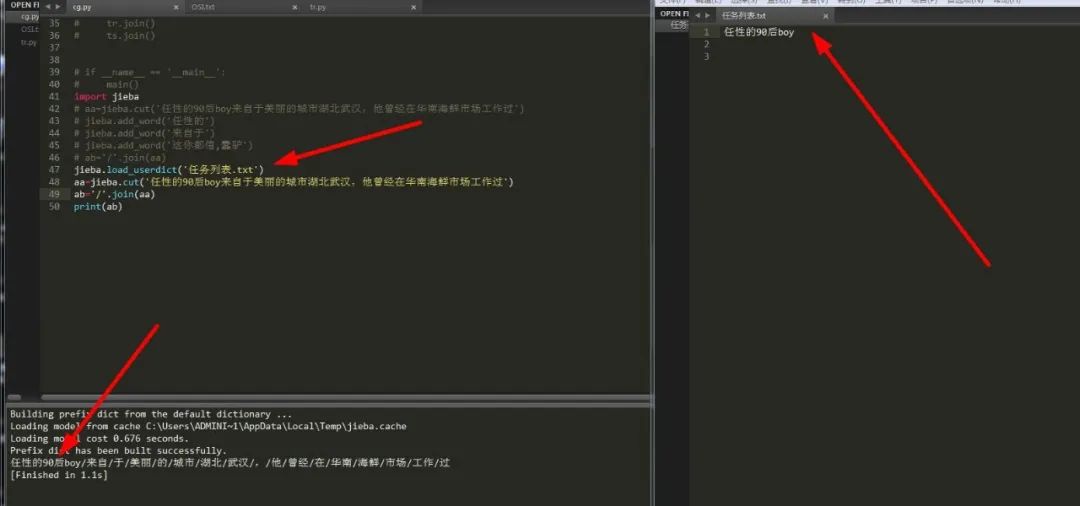

可以看到,我们成功匹配到了以文件字典为结构体的内容,这样我们就可以更加精确的匹配到结果而不至于添字掉字。
3)、删除新词
有添加肯定就有删除,那么删除新词是怎么一回事呢?如果我们对自己所添加的新词不满意,可以直接删除,这样就可以。
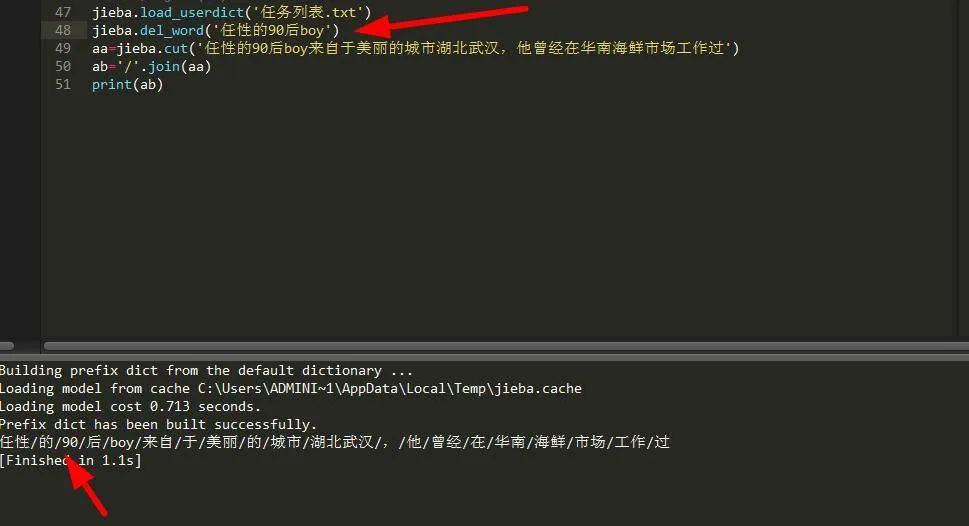
可以看到,分词结果又回到了原来的形式,不过由于我只删除了一个,所以另一个保留,依然是‘湖北武汉’。
4)、处理停用词
在有时候我们处理大篇幅文章时,可能用不到每个词,需要将一些词过滤掉,这个时候我们需要处理掉这些词,比如我们比较熟悉的‘的’ ‘了’、 ‘哈哈’ 什么的,这些都是可有可无的词,下面我们来学习下如何去除:
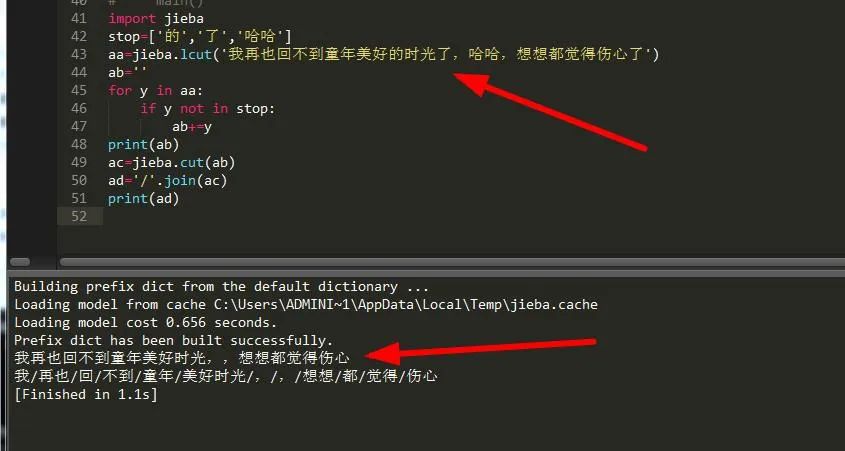
可以看到,我们成功去除了我们不需要的词:‘的’,‘了’,‘哈哈’,那么这到底是个什么骚操作呢?哦,其实很简单,就是将这些需要摒弃的词添加到列表中,然后我们遍历需要分词的文本,然后进行判读,如果遍历的文本中的某一项存在于列表中,我们便弃用它,然后将其它不包含的文本添加到字符串,这样生成的字符串就是最终的结果了。
5)、权重分析
很多时候我们需要将关键词以出现的次数频率来排列,这个时候就需要进行权重分析了,这里提供了一个函数可以很方便我们进行分析,
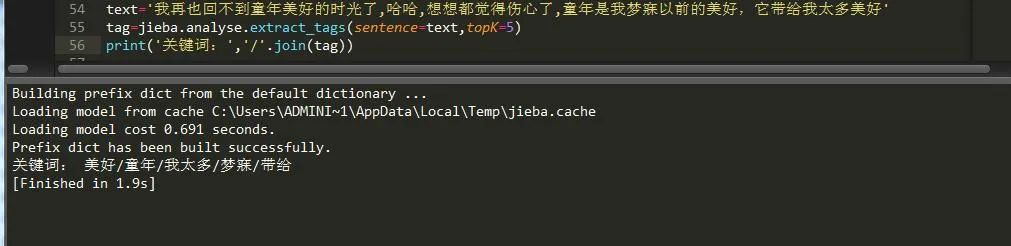
可以看到它将字符串中出现频率最高的几个词按顺序排列了出来,如果你想打印出这几个词的频率的话,只需添加一个withWeight参数即可:

那么这些参数是什么意思呢?哦,原来topK就是指你想输出多少个词,withWeight指输出的词的词频。
6)、调节单个词语的词频
在分词过程中,我们可以将某个词显示进行划分。不过,词频在使用 HMM 新词发现功能时可能无效,需要将它设置为False。
aa=jieba.lcut('我再也回不到童年美好的时光了,哈哈,想想都觉得伤心了',HMM=False) #为调节词频做准备print('/'.join(aa))jieba.suggest_freq(('美','好'),tune=True)#加上tune参数表示可以划分aa=jieba.lcut('我再也回不到童年美好的时光了,哈哈,想想都觉得伤心了',HMM=False)print('/'.join(aa)) #生成新词频
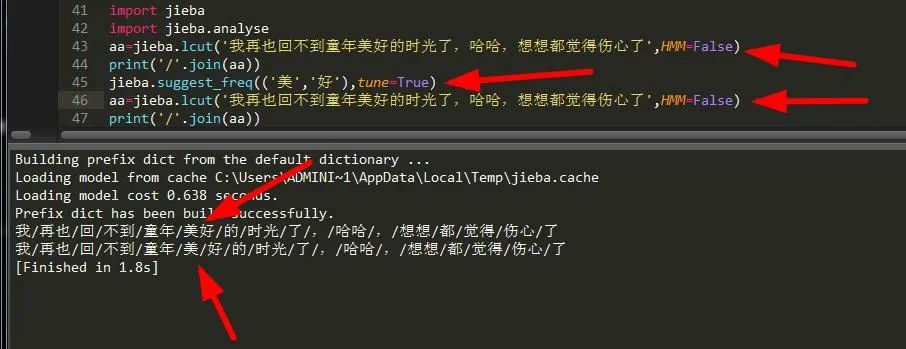
可以看到它将美和好分开了。
7)、查看文本内词语的开始和结束位置
有时候我们为了得到某个词的准确位置以及分布情况我们可以使用函数tokenize()来定位。
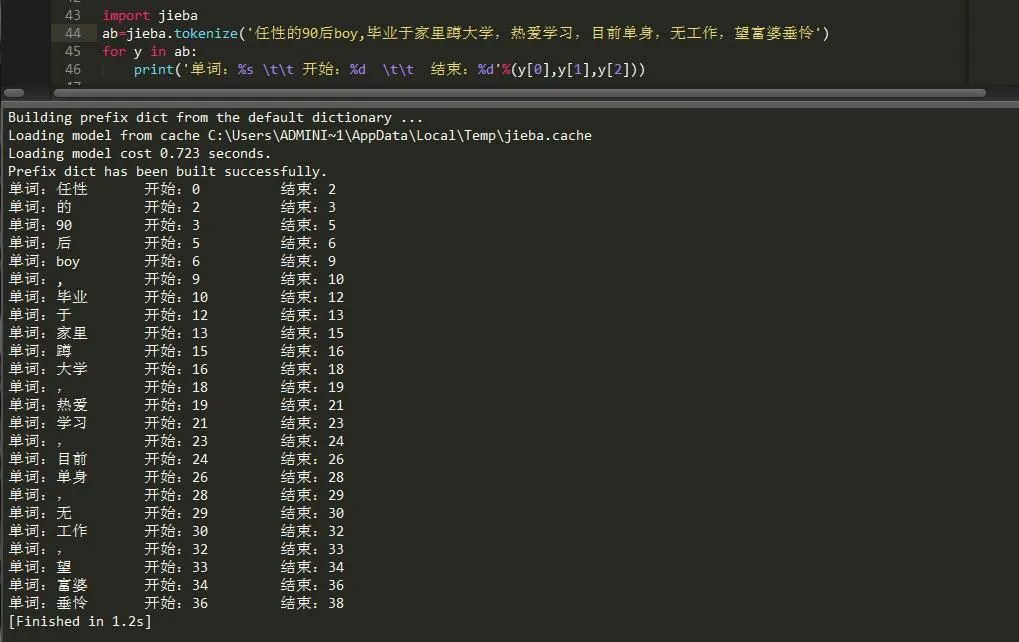
8)、修改字典路径
如果你觉得当前使用字典无法满足要求,你可以重新设置字典,刚才我们介绍了读取字典、添加字典、删除字典的方法,现在我们来说一种重新设置字典的方法,它就是:jieba.set_dictionary(file),里面还是加的文件名,但是你在重新设置前必须要初始化jieba,不然可能设置失误,方法如下:
import jiebajieba.initialize() #初始化jeibajieba.set_dictionary('OSI.txt') #设置字典
四、总结
jieba这款分词工具,总体来说还是挺厉害的,我们可以用它来获取并过滤许多对于我们来说比较核心的东西,它就等于数据分析中的一块敲门砖,当然它只是其中的一块而已,哈哈哈。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~

文章评论