我们的数据集群目前规模过万,总数据量以EB计,日新增数据量则以PB计……
这些数字来自某移动互联网企业在一次技术交流活动上对自家数据处理能力的介绍。先不说EB,就说说1PB是什么概念吧?大约是2亿张照片或2亿首MP3音乐,如果一个人不停地听这些音乐,能听上1900年。
大家可能会惊叹于这家企业强大的数据处理能力,但并非所有企业都具备同样的能力——激增的数据量如果超过了数据处理能力,就会导致“信息过载“问题,为此,人类发明了能够过滤信息的“搜索引擎”和“推荐系统”,用以高效识别和应用那部分“至关重要”的数据。
然而,据国际数据公司IDC在报告《数据时代2025》 中的预测,到2025年,属于数据分析的全球数据总量将增长至原来的50倍,达到5.2ZB;认知系统“触及”的分析数据总量也将随之增长至原来的100倍,达到1.4ZB!这意味着用来挑选、过滤数据的推荐系统和搜索引擎,也一样难逃”信息过载“。
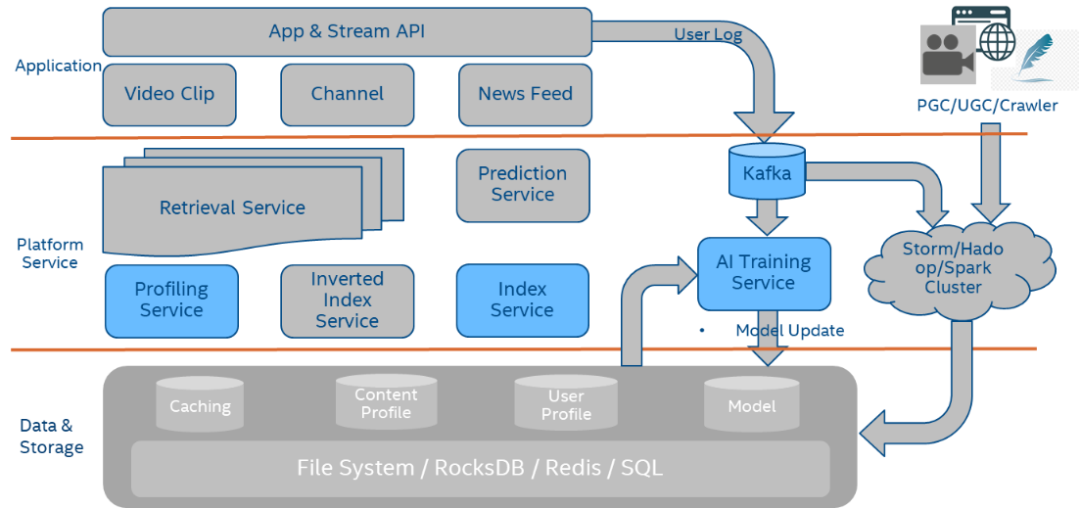
推荐系统本质上就是一个信息过滤系统,通常分为:召回、排序、重排序这三个环节,每个环节逐层过滤,最终从海量数据中筛选出几十个用户可能感兴趣的信息推荐给用户。更直接一些,要想实现推荐系统这三个关键环节,就需要四个模块化的层面,即数据、存储(内存&存储)、服务和应用。
其中,存储层用于存储数据层的数据;服务层是对外提供接口的部分;应用层根据不同场景配置的召回策略来直接对接服务层,发起请求得到推荐反馈。显然,数据、存储是推荐系统的底层逻辑,能够决定引擎“走多远”,而服务层和应用层则是上层建筑,对用户体验起到重要作用。
因此,要想从根本上解决推荐系统的信息过载问题,就要从数据及存储层着手。
从文字发明前,人类就一直在为“合适”的数据寻找“合适”的数据存储方式,例如书写工具作为一种原始存储技术,其让人类有了记录生活的能力;1890年代,穿孔卡的出现为人类打开了另一个全新时代的大门,标志着现代信息程序化的初露锋芒。
穿孔卡所能处理的数据当然不能一劳永逸地满足人类经济生活的需求,1966年,动态随机存取内存(DRAM)出现,开创性地用电容来存储信息,而所谓的“动态“并非是指内部的某个功能,而是指电容终究会丧失电荷,因此必须定期”动态“刷新。这意味着DRAM一旦断电就将面临数据丢失的风险。
内存专注于“数据存储”,结合“数据处理“才能构成数据价值的闭环。1971年英特尔推出全球首款CPU的创举则画全了这个闭环。此后,数据处理的硬件发明一直都在沿着内存与CPU并存的格局发展。
而今,从大数据时代带来数据量暴增,数据类型不断增多,数据处理并发度和速度不断提升这三个现状考虑,是时候对数据处理和存储的硬件技术来次大换代了。其实,将这三个特征纳入推荐系统,就不难发现,在内存上下功夫,会更有助于破解推荐系统的信息过载难题。
让我们来划一下重点吧:数据规模、高并发、实时推荐等这几点,就是所有基于大数据做推荐服务或产品的企业都会遇到的共同问题:
1.数据量指数增长问题:越是精准,越是个性化的推荐,就越需要为每个用户都保存一份推荐数据,也就是说数据量会随着用户线性增长。
2.数据稀疏性问题 :现在待处理的推荐系统规模越来越大,用户和信息(譬如音乐、网页、文献……)数目动辄百千万计,两个用户在选择上的重叠非常少。
3.需要快速及时响应用户请求(运算):随着新闻、短视频等消费用户碎片化时间的应用层出不穷,推荐系统更倚重实时推荐策略。
就如前文所说,要解决这些问题,就要从“数据”和”存储“这两个底层逻辑找答案。
第一个问题的解决,需要大容量存储设备;第二个问题需要“借力”算法,例如通过扩散的算法,从原来的一阶关联到二阶甚至更高阶的关联,甚至通过迭代寻优的方法,考虑全局信息导致的关联,其中“全局”一词背后需要高性能处理器的助力;而应对第三个问题则需要更高性能的存储来支持,例如用户在使用APP时,留给推荐系统的处理时长往往是毫秒级的,这就对推荐系统的存储部分的吞吐量、响应速度、稳定性和意外中断后的恢复能力提出了更高的要求。
从上面这个三个方案不难看出,存储既要更大容量,也需要更优性能,换言之推荐系统的IT基础架构既要满足对海量数据存储的承载能力,还需要在大数据量下保证计算分析的时效性。换句话说,上面这三个问题环环相扣,必须要找到一个“三管齐下”的解决方案。
三管齐下说来容易,但又该如何实现呢?其实,只要一步活,就可以步步活。
这一步就是要把更多数据“存放”在更接近CPU的位置进行处理。
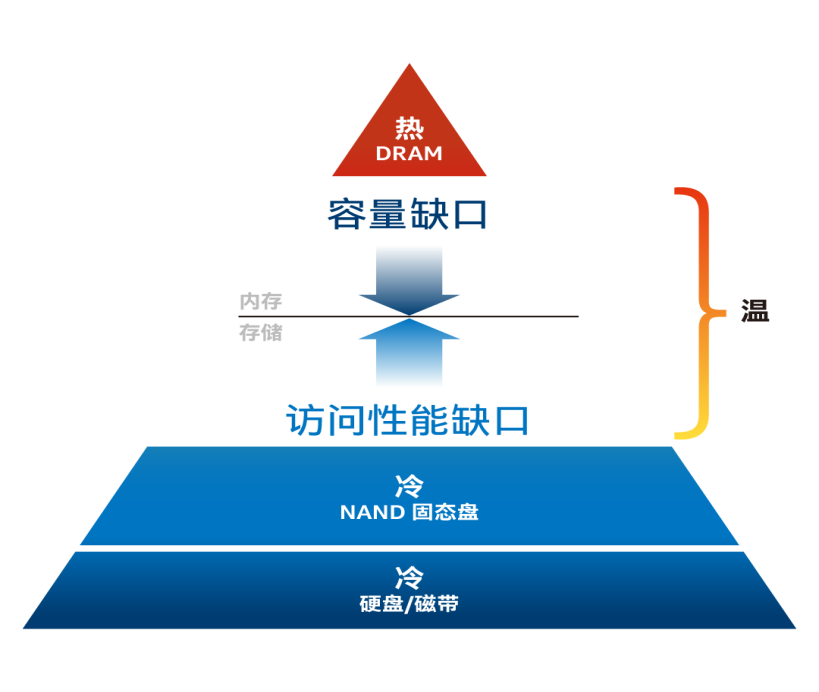
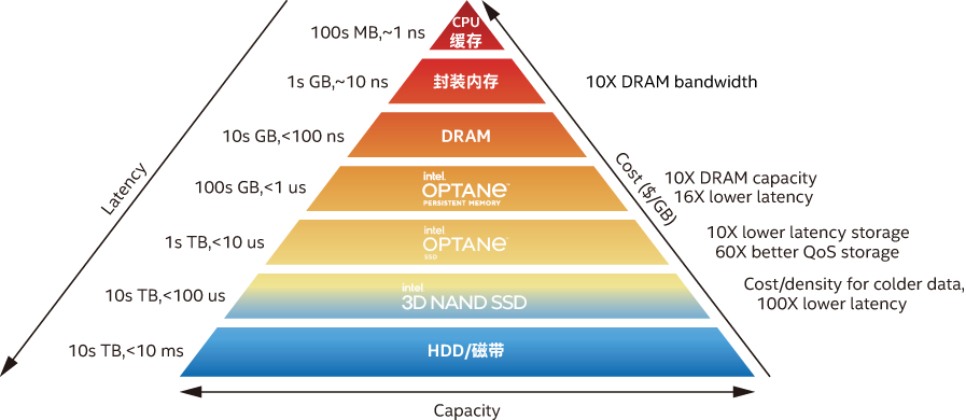
传统上业界存放数据的主流产品包括DRAM,基于NAND技术的固态盘 (SSD)以及传统机械硬盘 (HDD)。这些技术各有优缺点,例如DRAM虽然性能好、时延低,但容量受限、价格昂贵且有数据易失性;与DRAM相比,固态盘 (SSD) 可提供更大容量和更低成本,但无法提供相同的性能水平;传统硬盘 (HDD)就更别提了,胜在容量和成本更优,但有旋转的盘片,很难避免与可靠性、物理空间要求、散热等因素有关的总体拥有成本问题。
总结一下,上述这些产品的不足,概括起来就是:离CPU近的,性能虽好但很难满足承载大体量数据和数据持久性的需求,而距离远的产品容量虽大,即在性能上与DRAM差距较大。
如何解决?当前业界有一个解决方案是开辟全新的产品技术路线:打破内存和存储的特性,将两者的优势融合起来。
这一技术路线的提出者和重要实践者,就是大家熟悉的英特尔,而它将内存和存储特性融合的产品,名为英特尔傲腾持久内存(Optane Persistent Memory, 简称Optane PMem)。这种产品采用的傲腾存储介质正是实现这种融合的基石,已被很多专家和用户视为存储“黑科技”。
采用了这种存储“黑科技“的傲腾持久内存,一句话就可以概括其特点,那就是拥有接近DRAM,远超NAND SSD的性能,但容量又比DRAM大(单条容量可达128GiB,256GiB和512GiB),价格或单位容量的成本更实惠,且具备数据非易失能力(断电后数据不会丢失)。
图注:增添了傲腾持久内存和傲腾固态盘的全新内存-存储架构
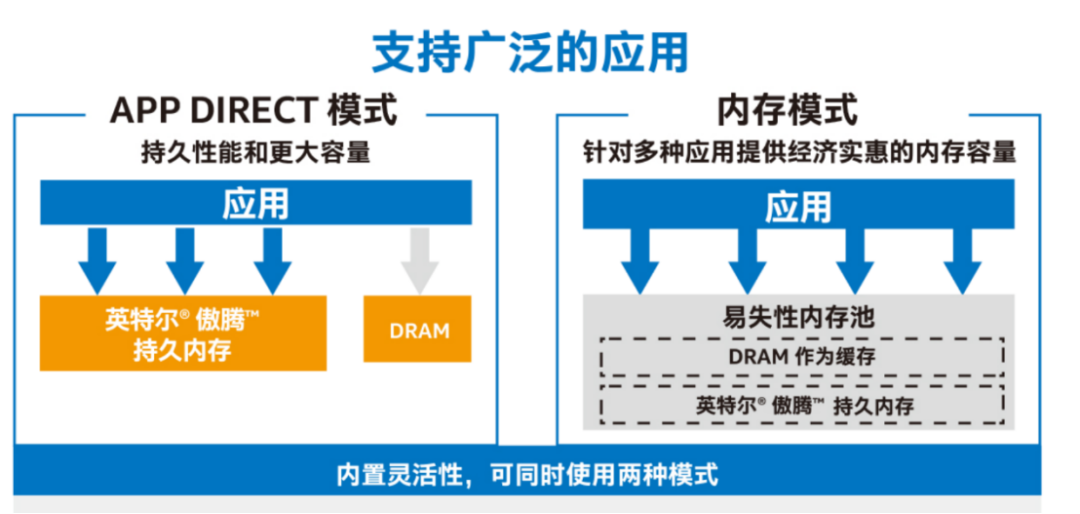
对内存和存储优势的融合让傲腾持久内存得以提供两种工作模式:
一是App Direct 模式,让应用能通过load/store字节访问方式直接访问持久内存,保存到持久内存的数据断电后不丢失。访问持久内存的时延和DRAM接近。
二是内存模式,傲腾持久内存在这种模式下可用作DRAM之外进行容量扩展的易失性内存。
说到这里,结果已经要呼之欲出了:在App Direct模式下工作的傲腾持久内存正是我们寻求的、能兼顾推荐系统两个底层逻辑——数据和存储的答案,它既能把更多数据放在靠近CPU的位置,同时又能满足推荐系统高速数据处理过程中的性能和可靠性要求。
目前,已有数家在推荐技术上处于行业领先地位的企业认识到,并开始借重傲腾持久内存的上述优势,百度就是尝鲜者之一。
人们对于百度的传统观感就是搜索引擎服务,其实百度的搜索引擎早就利用公司在大数据和AI方面的技术优势和积累,增添了基于信息聚合,能向用户投送个性化内容的Feed流服务。在这项服务背后担纲数据层和存储层关键角色的,就是它的核心内存数据库Feed-Cube。
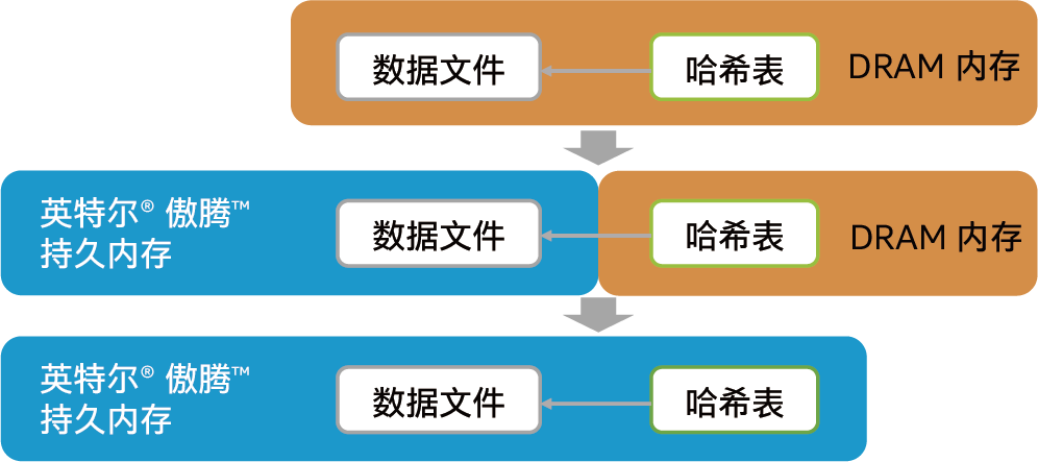
由于业务飞速拓展,百度Feed流服务需要Feed-Cube部署更大容量的内存来承载规模激增的数据,可DRAM高昂的成本和有限的容量规格使得内存扩展带来的TCO压力不断抬升,在这种情况下,百度在初代英特尔傲腾持久内存(100系列)刚刚发布不久,就盯上了它。
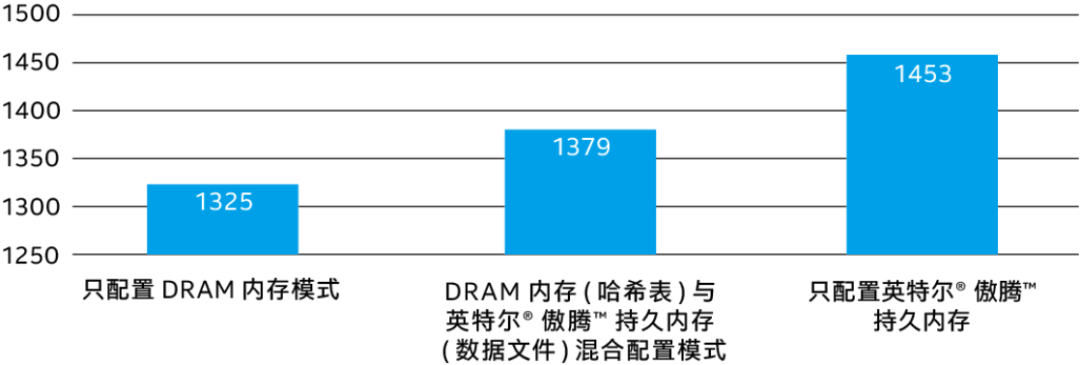
于是2019年时,百度就围绕如何在Feed-Cube上利用傲腾持久内存的优势开展了一系列尝试。它先后对比测试了仅使用DRAM,DRAM+持久内存和仅使用持久内存支持Feed-Cube的状况。结果表明,在第二代至强可扩展处理器与傲腾持久内存组合上,如果使用DRAM和持久内存的混合配置,Feed-Cube在2,000万大并发访问压力下的平均访问耗时仅上升约30微秒(约24%),CPU的整机消耗占比上升7%,性能波动完全可接受,由于换来的单服务器上的DRAM使用量可以减半,从成本角度而言则是个大好消息。
百度还发现,即使只基于傲腾持久内存来构建Feed-Cube,在每秒50万次查询(QPS)的访问压力下,其平均时延与只配置DRAM的方案对比上升约9.66%,性能波动也可接受。
图注:百度Feed-Cube内存配置的变化路径,和不同路径或配置下的处理时延对比
对傲腾存储“黑科技”优势的初步认可,让百度开始了在更多关键应用场景中发掘其应用价值的探索之路。包括在关键业务中考查其持久性对数据恢复的加速,还有优化BigSQL数据处理平台(基于SPARK SQL)的交互式查询性能和成本等。
这些成功的尝试,最终促使百度决定基于傲腾持久内存,从存储引擎层面开启了更大的创新或者说是改造,即推出使用持久内存和PMDK(英特尔开源的持久内存开发工具包)优化的新一代用户态单机存储引擎,为百度离线与部分在线业务提供高效稳定、低时延、低成本和易扩展的存储服务。
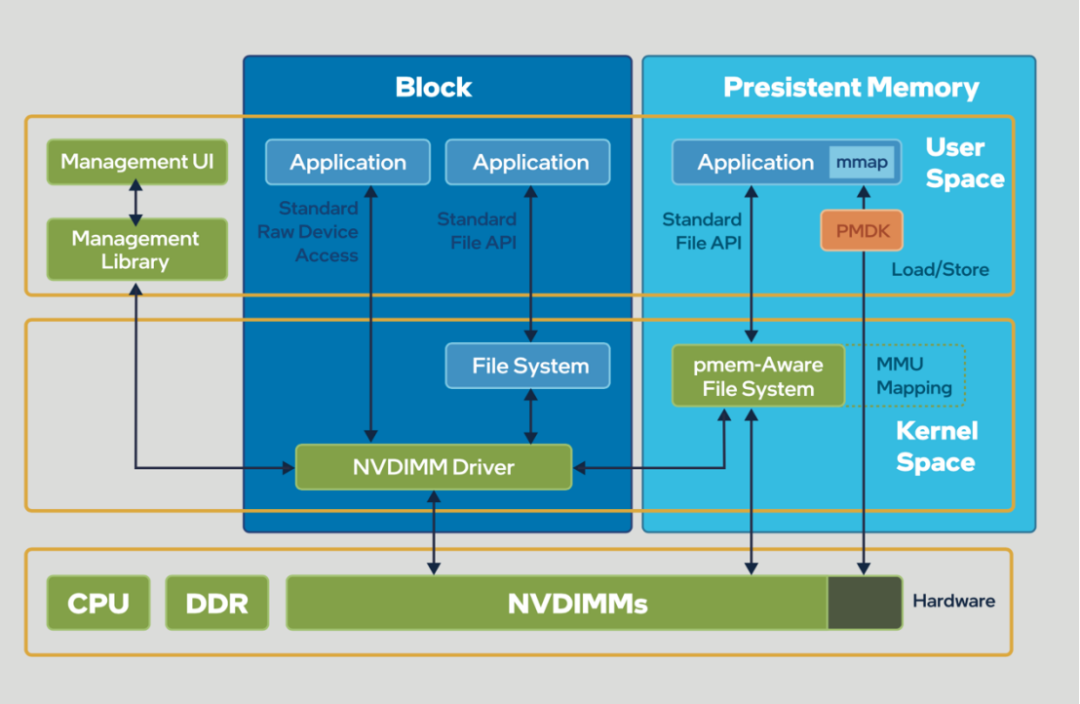
该引擎可用于块、文件和对象存储等多种应用场景,将傲腾持久内存(APP Direct模式)用作引擎缓存层的存储介质,来存储元数据、缓存和索引。并通过PMDK进行内存调度,加速这些数据的读写,最大程度减少资源损耗。
图注:SNIA编程模型和PMDK工作示意图。傲腾持久内存遵循SNIA编程模型, PMDK可帮助应用直接访问持久内存设备,而不需要经过文件系统的页高速缓存系统、系统调用和驱动,避免了数据IO产出的开销,可大大降低数据时延。
经测试,这个全新的存储引擎写入一个4K数据的整体时间消耗大约为4.5微秒,而将其中的持久内存换成DRAM,全程用时大约是3微秒,在时延上相差不大。但使用DRAM和使用持久内存的成本却相差很大,相同的成本投入下,持久内存的空间是DRAM的三倍之多,这意味着可以缓存更多数据,也能以更合理的方式进行数据存盘,有效提高后端存储设备的IO效率。
百度将傲腾持久内存导入包括Feed流服务在内各种产品和服务进行尝试,以及采用它开发新一代用户态单机存储引擎的意义,并不在于它使用这种存储“黑科技”解决了自身的业务需求,更多的,是为傲腾持久内存在搜索、推荐系统和更多大数据场景中的应用进行了重要的探索,能为遇到或即将面临同样信息过载问题的企业和用户提供值得借鉴的宝贵经验。
或许很快,就会有更多倚重搜索、推荐技术或服务的企业导入傲腾持久内存,尤其是英特尔在今年四月刚刚发布了与傲腾持久内存搭配的全新算力干将——面向单路和双路服务器的第三代至强可扩展处理器。它在内存通道的支持上从上一代产品的6通道升级到了8通道,速度也从上一代的2666MT/提升到了高达3200MT/s,在与DRAM和傲腾持久内存200系列配合使用时,每路内存容量可达6TB之多。这款全新处理器还支持了PCI-E 4.0技术,并新添了支持PCI-E 4.0的傲腾固态盘P5800X(也是基于傲腾存储介质构建),这表明傲腾固态盘与傲腾持久内存的数据交互也将进一步提速。
图注:存储“黑科技“两款新品——傲腾持久内存200系列和傲腾固态盘P5800X
由此不难看出,英特尔对这项存储“黑科技“的改进、优化、升级和普及的步伐一直在持续,也许还会越来越快,现在已有消息称,下一代傲腾持久内存单条容量就会达到1TB……这样一来,也许大家担心存储系统“信息过载”的日子,离我们就越来越远了。







文章评论