解螺旋公众号·陪伴你科研的第2541天
大家好,我是濤濤。众所周知,仙桃生信工具www.xiantao.love一直致力于协助大家在进行生信研究提供便利性。最近,仙桃生信工具又推出了GEO数据集的分析功能!
黑衣人:什么!我终于可以摆脱一直学不会的那个GEO2R了吗?
濤濤醬: 是喔!一站式GEO下游分析,汇聚各式美图,仙桃全都有!
今天我们无代码复现一篇2020年7月IF为2.57分发表在BMC Med Genomics的一篇使用GEO分析非肿瘤生信类型文章。
是喔!一站式GEO下游分析,汇聚各式美图,仙桃全都有!
今天我们无代码复现一篇2020年7月IF为2.57分发表在BMC Med Genomics的一篇使用GEO分析非肿瘤生信类型文章。
疾病:心房颤动
数据:GEO数据集(五个数据集)
实现手段:筛选差异基因(R语言之limma包)
功能聚类(GO、KEGG、DO、Reactome)
互作网络(蛋白—蛋白交互PPI)
关键基因分析(CTD数据库)
(https://www.xiantao.love/products)
(https://www.ncbi.nlm.nih.gov/gds)
(https://maayanlab.cloud/Enrichr/)
(https://www.string-db.org/)
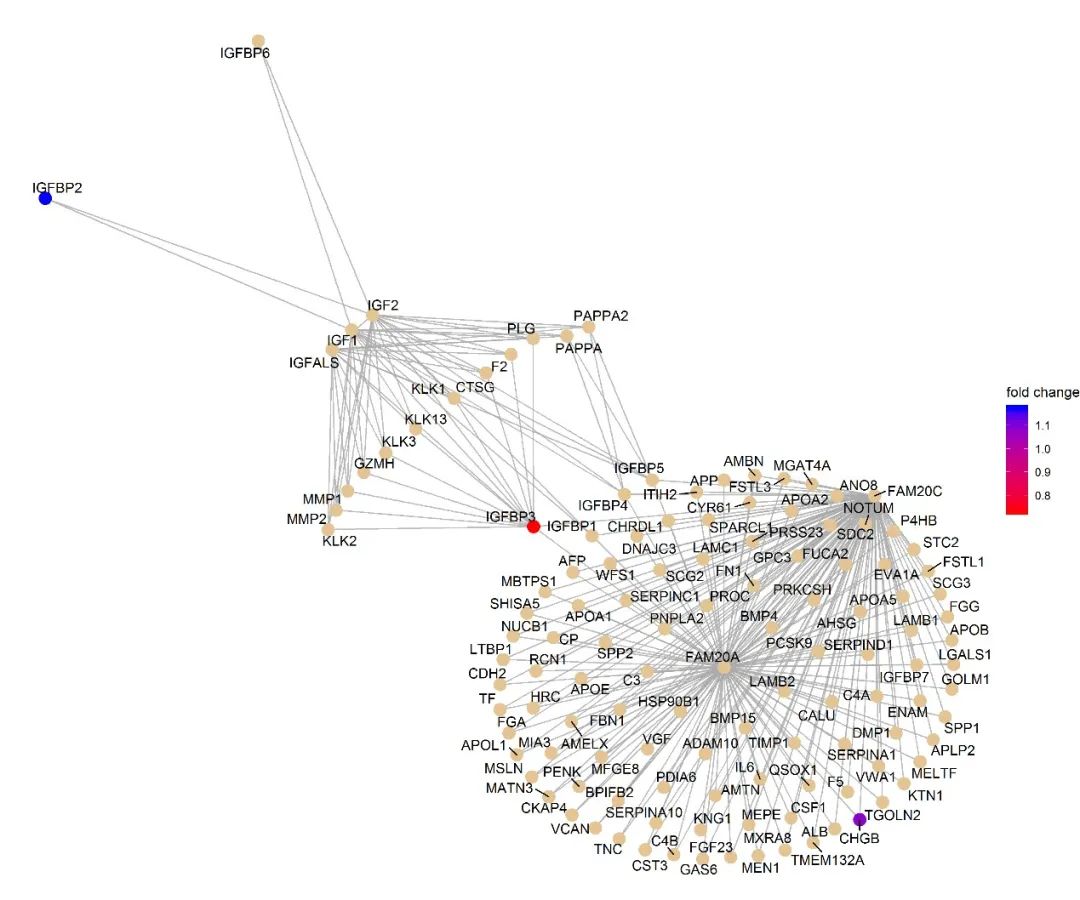
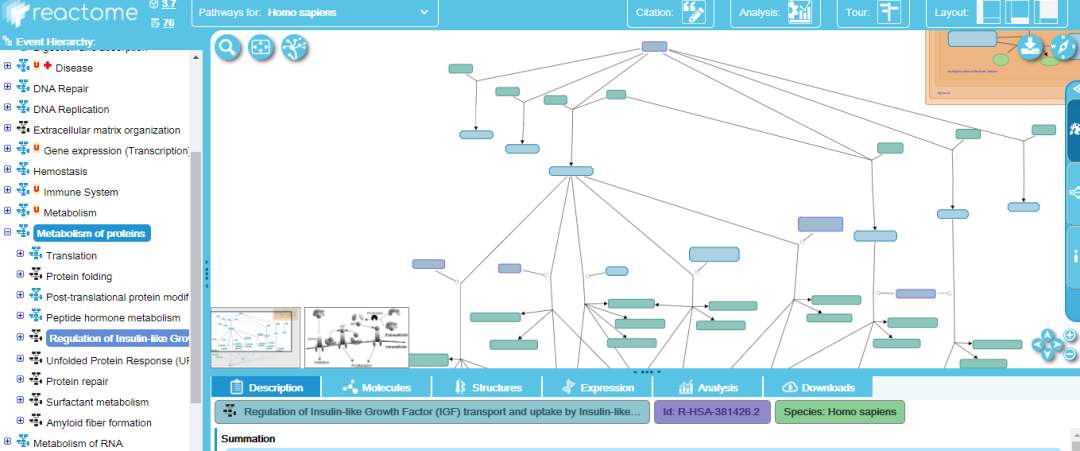
附图3. 使用REACTOME数据库呈现IGF以及IGFBP的富集通路分析
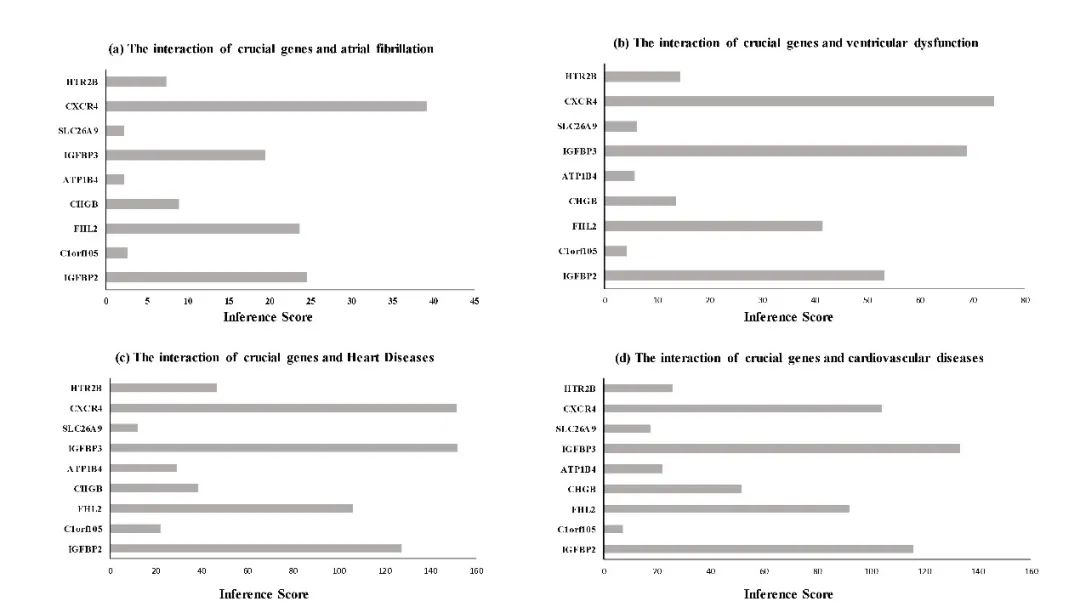
附图6. 基于CTD数据库进行关键基因与疾病的分析
事不宜迟,一起来看看最新最夯最火爆的仙桃GEO无代码复现吧!
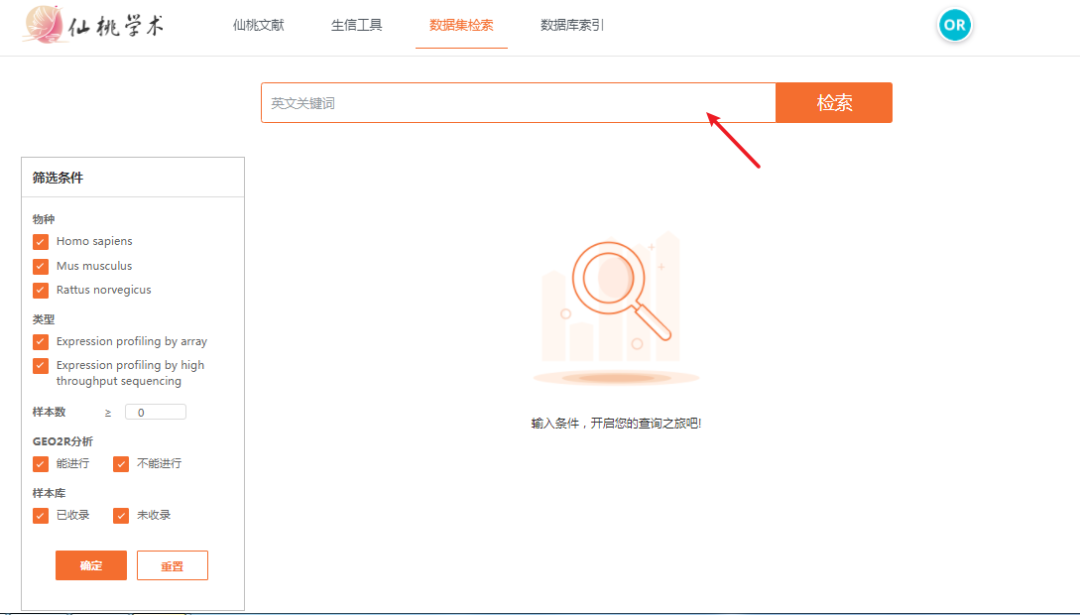
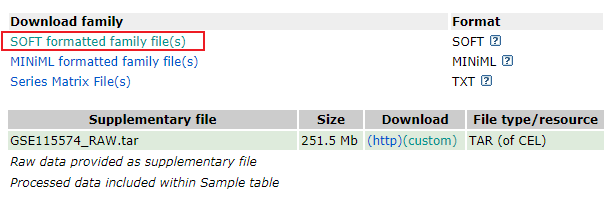
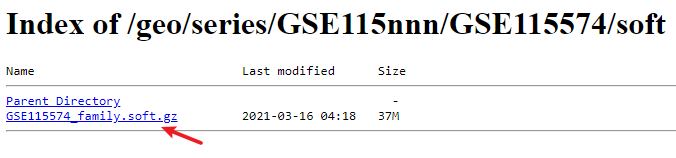
进入仙桃学术工具(https://www.xiantao.love):
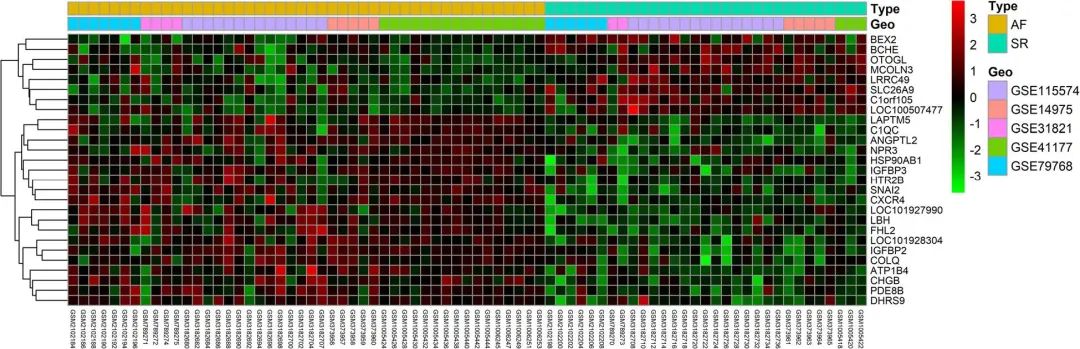
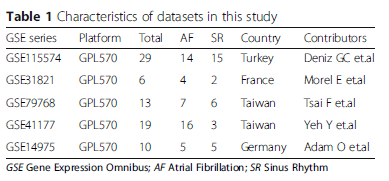
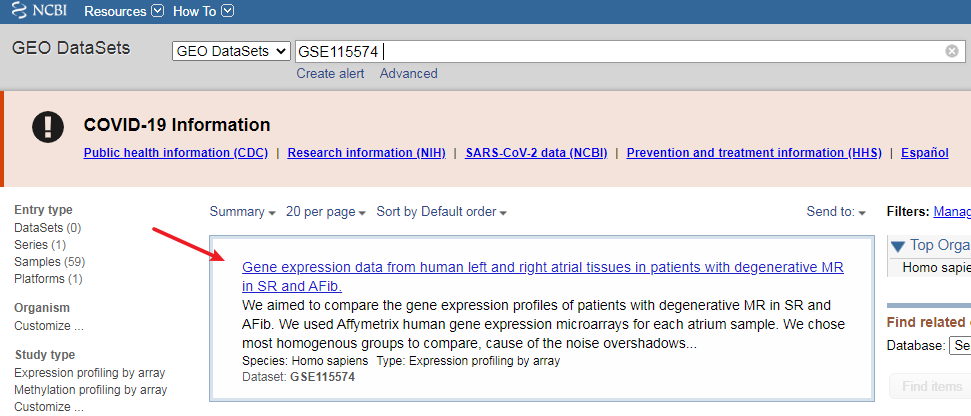
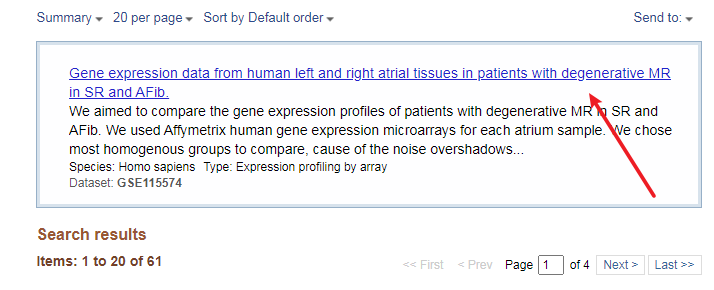
我们知道,这篇文章涉及了五个数据集,分别为GSE115574, GSE31821, GSE79768, GSE41177 和 GSE14975。
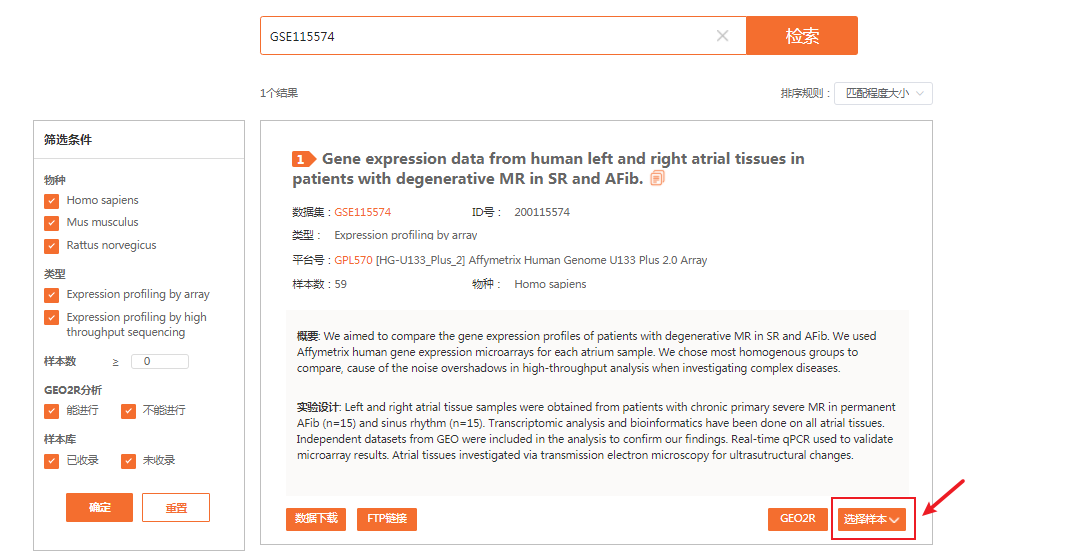
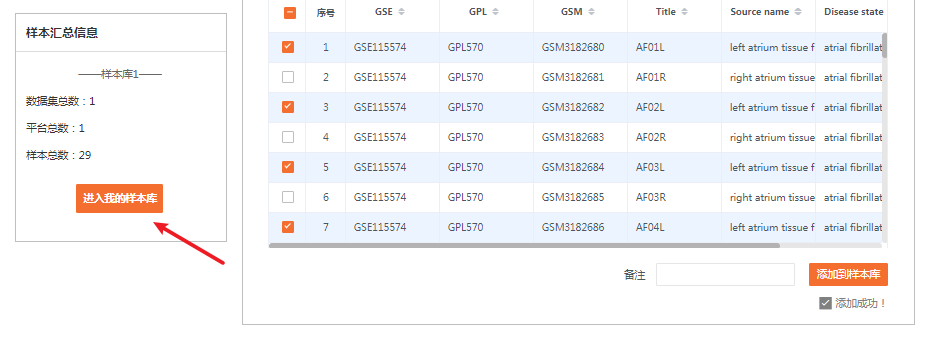
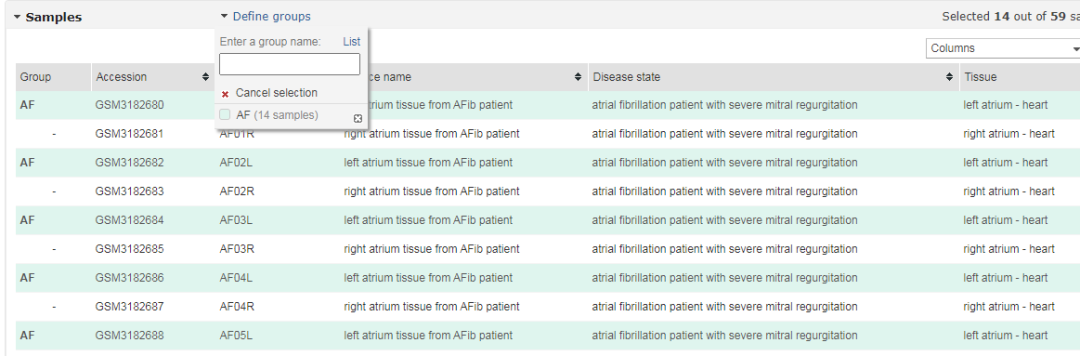
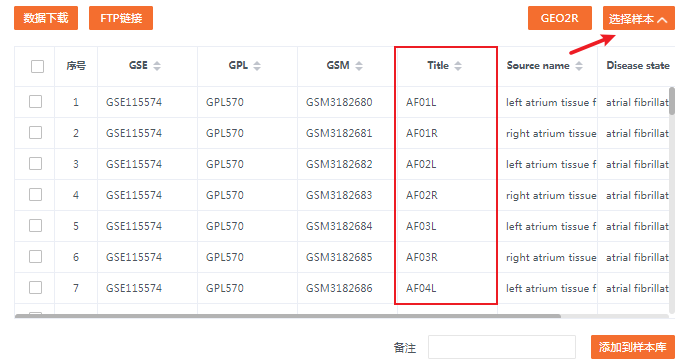
输入后,点击“选择样本”按钮,选择对应数据集的样本。
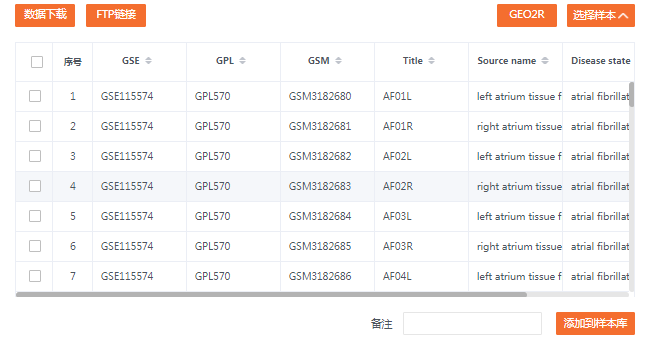
原文中是选择左心耳组织(左心房附属物),所以样本的添加我们都选择左侧。
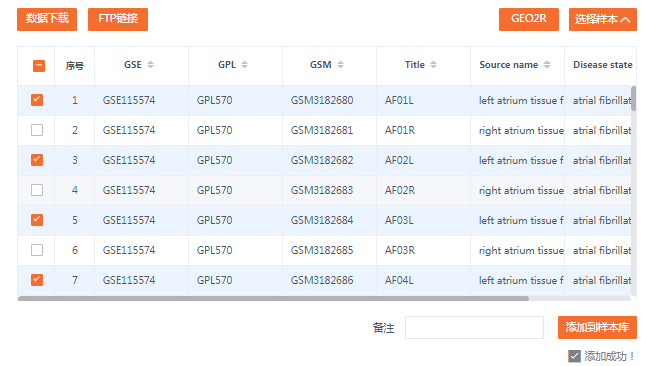
我们把所有的左侧的组织都勾选上,包括心房颤动组以及窦性心律组,最后点选“添加到样本库”即可。
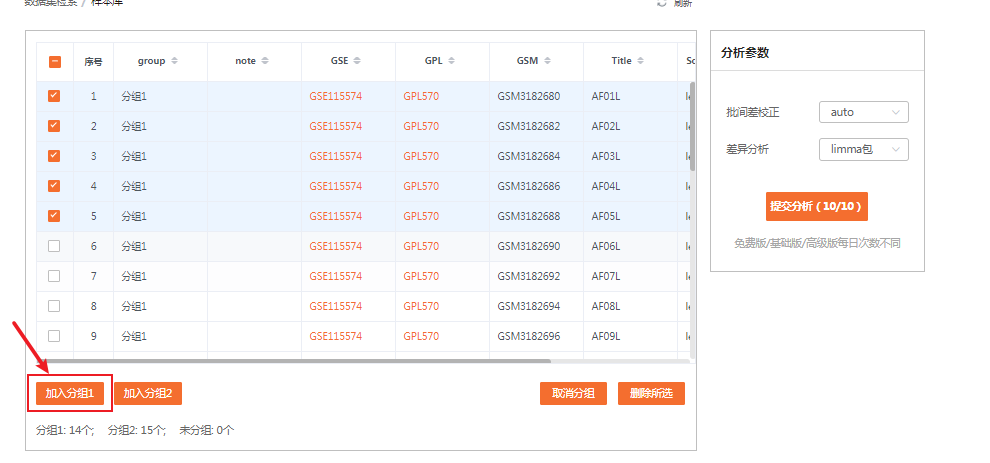
我们将心房颤动组定义为“分组1”,作为对照组;窦性心律组定义为“分组2”,作为实验组。
这样,我们就完成了第一个数据集GSE115574的添加。
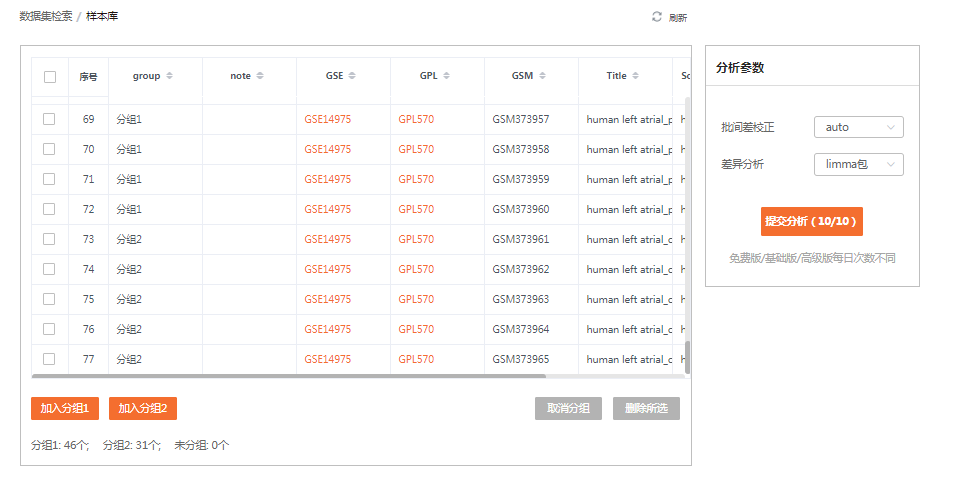
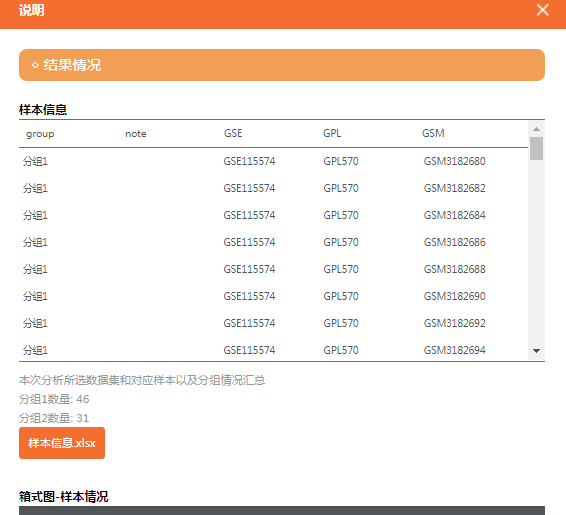
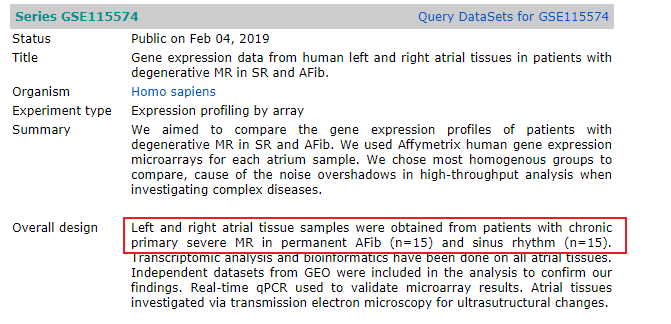
至此,我们得到了46个心房颤动的样本以及31个窦性心律的样本,进入后续分析。
注:不同权限用户的样本库的上限是不一样的,普通用户是20,基础版用户是50,高级版用户是100。仙桃学术后续还会视情况提高总体上限!
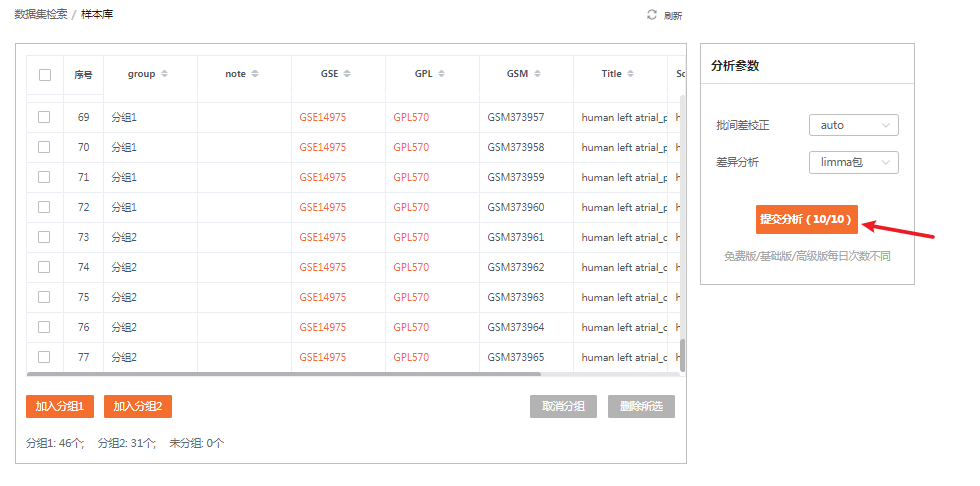
注:不同权限的用户每天可以提交分析的次数是不同的喔,普通用户每天只能提交2次分析,基础版用户每天可以提交5次分析,高级版用户每天可以提交10次分析。
这里的权限跟“生信工具”的是一个内容。想要升级权限可以到生信工具页面进行升级。
点击提交分析后,下面的历史记录中会出现一条分析记录,点击右上角的刷新可以刷新分析任务的进度情况。
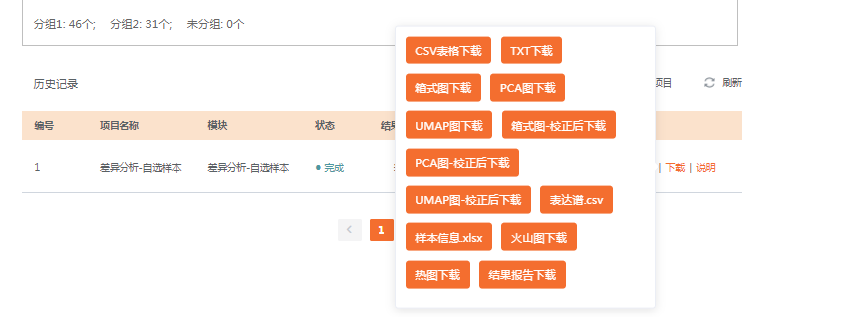
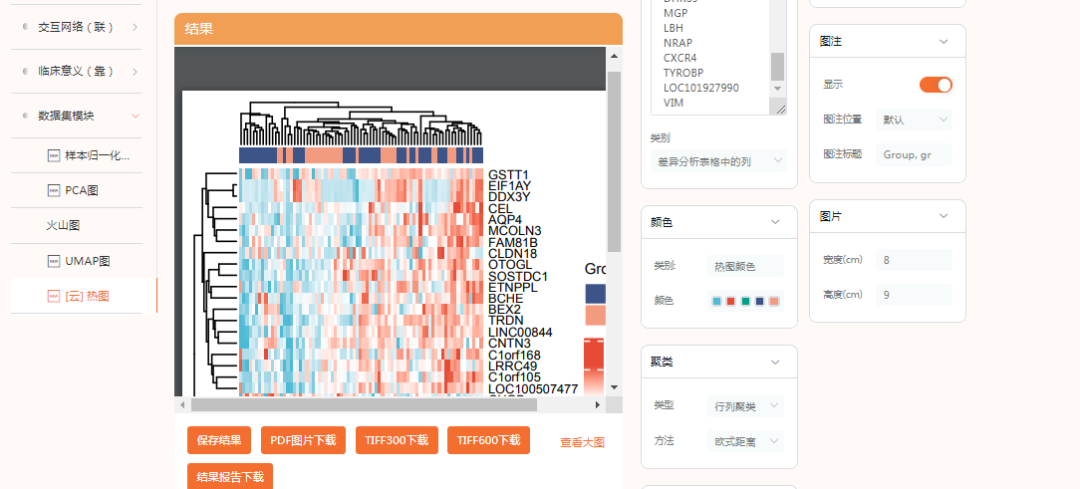
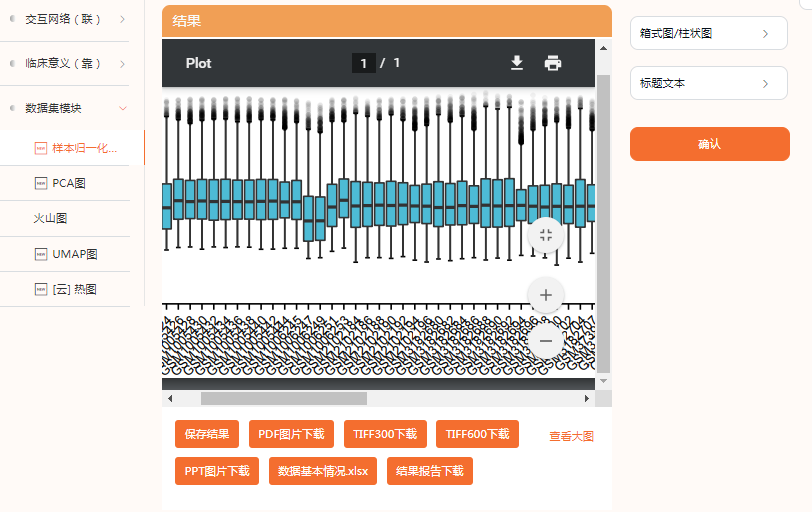
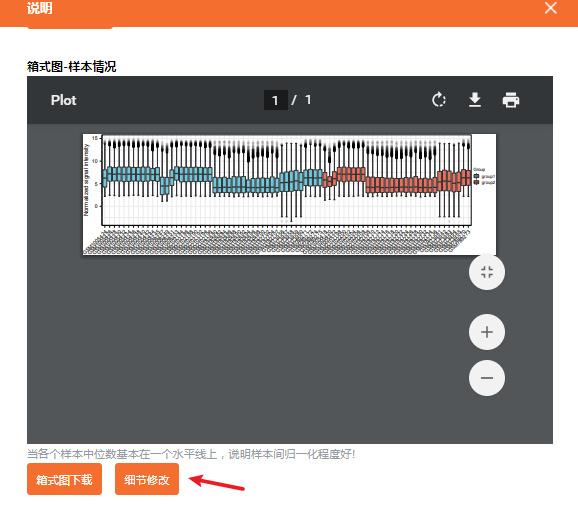
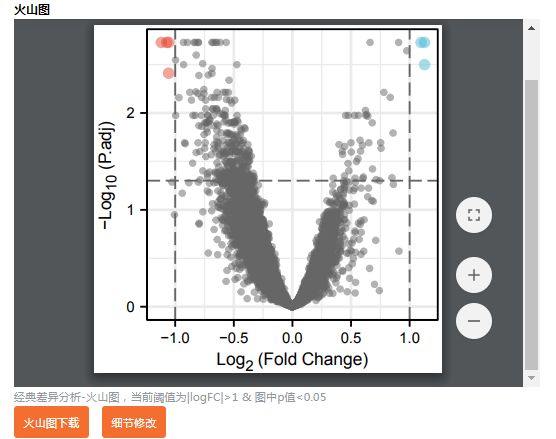
一次性提供了很多的结果内容,包括 箱式图、PCA图、UMAP图、火山图、差异分析结果表格等,以及结果分析报告。
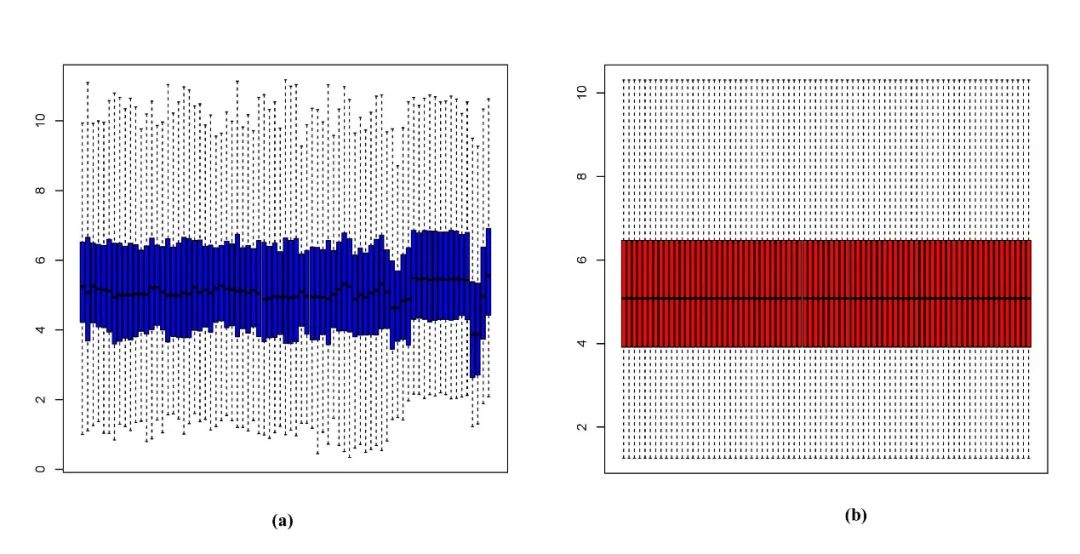
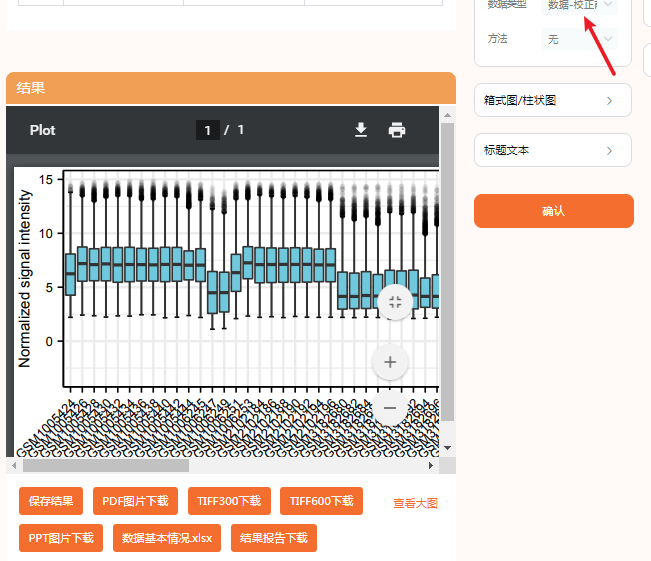
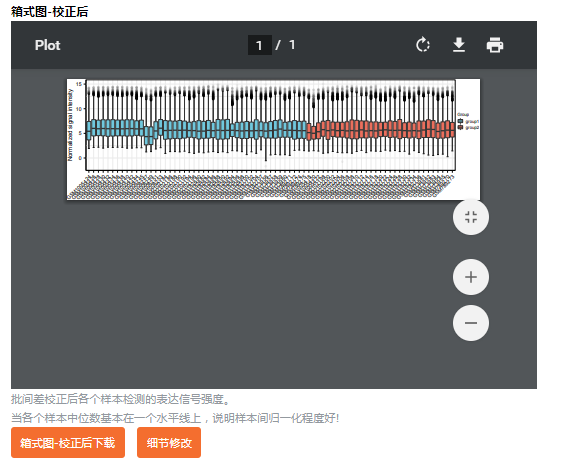
像我们这篇文献有5个数据集合并分析,校正前后的结果比较图显得尤为关键,这个在仙桃学术里也有提供喔(其实就是我们附图1的复现内容)。
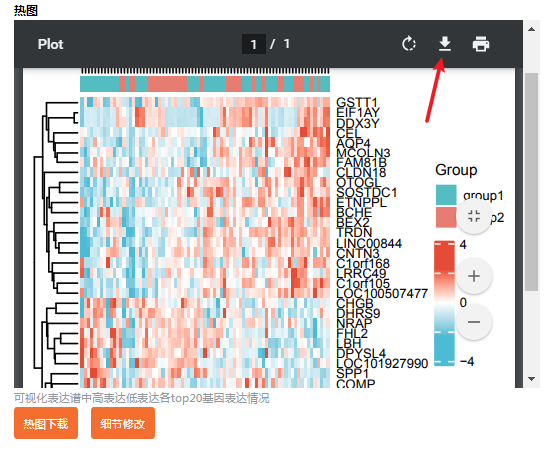
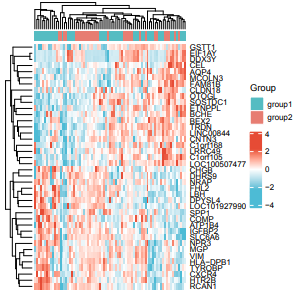
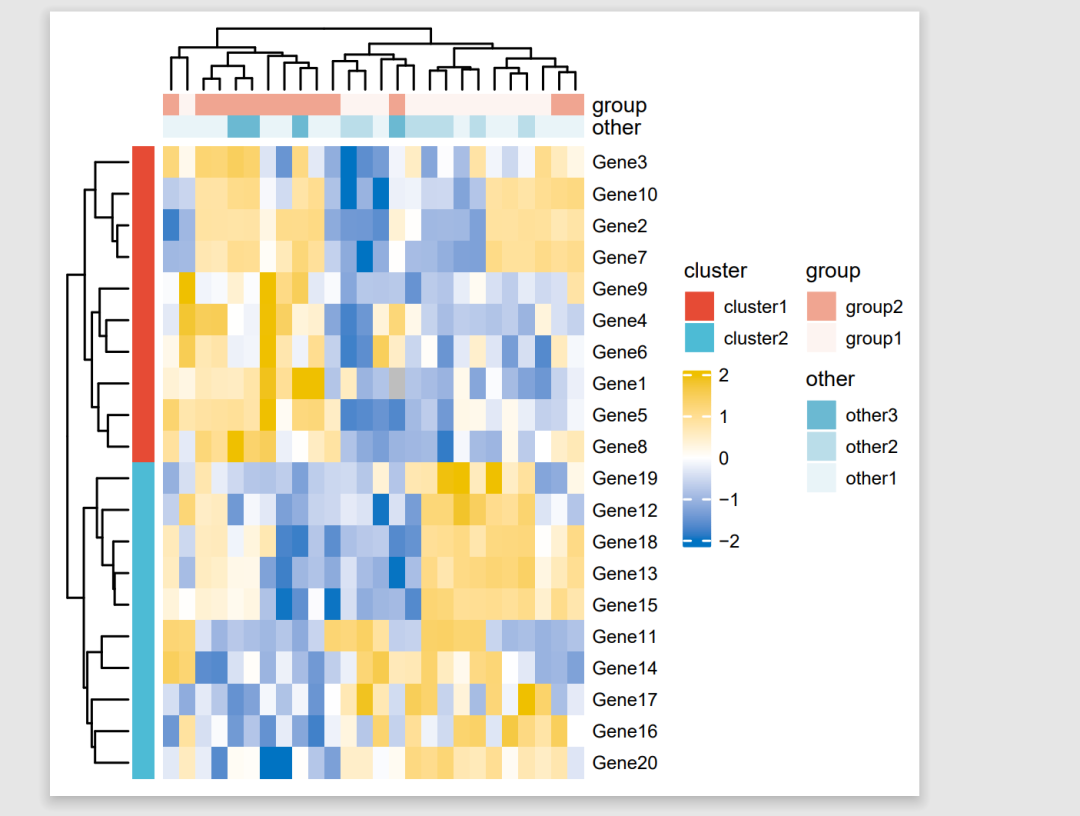
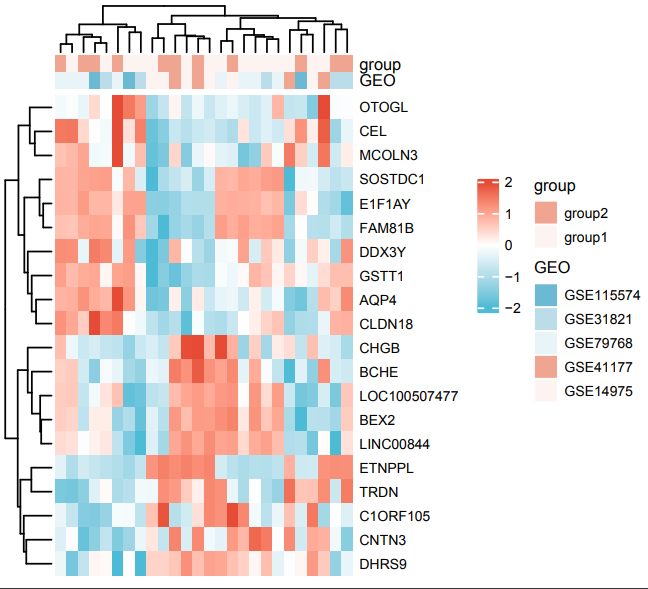
这个版本目前还和原文中的还不太一样,没有不同GEO数据集的图注。这个就是所谓的“普通热图”,而具有不同GEO数据集的图注的应该归类于“复杂热图”。
这个就是我们仙桃工具的内建示例数据上传的复杂热图。
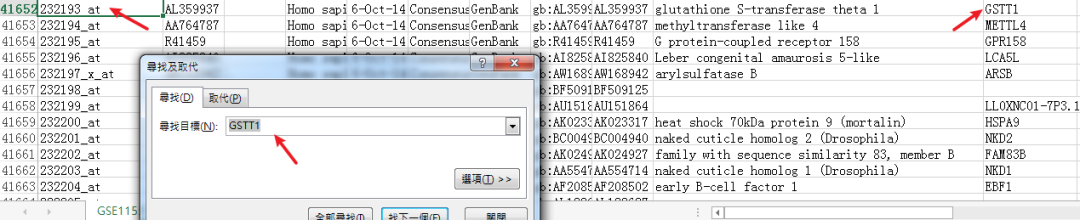
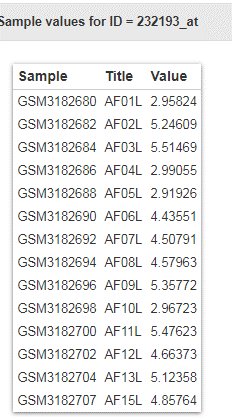
第一步:下载五个数据集,分别为GSE115574, GSE31821, GSE79768, GSE41177 和 GSE14975,分别找出差异基因在其中的表达值,整理成新的excel文件。
打开GEO网站(https://www.ncbi.nlm.nih.gov/gds)
同样的道理,继续在下一个数据集GSE31821中复制粘贴上在其他样本的表达值
最后,采用同法可以获得其他差异基因的一系列表达情况
就可以获得这20个基因在不同样本的表达值,保存该excel
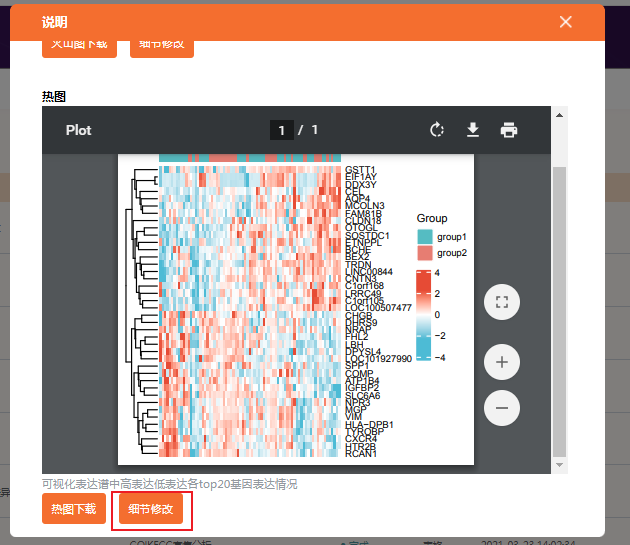
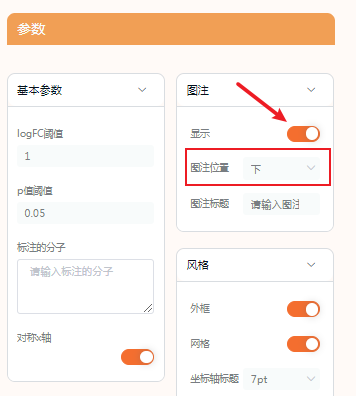
值得注意的是:如果是选择普通的热图,在结果说明里找到热图的部分。点击“细节修改”,即可修改热图。
黑衣人:欸?为什么我的仙桃没法修改啊
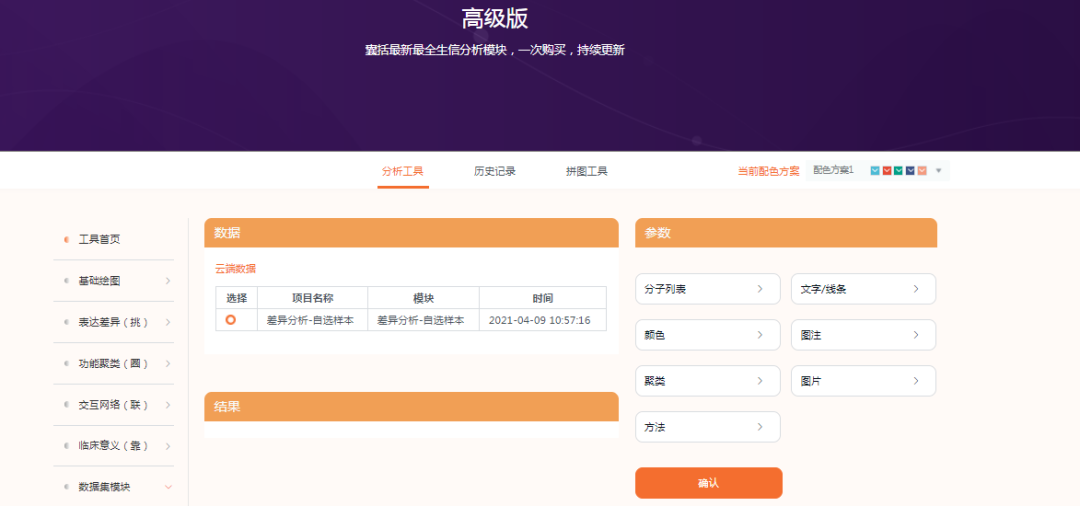
细节修改的内容目前是只有基础版或者高级版才有,部分模块也是只有高级版才有。这些细节修改包括调整配色,样式等等,让结果更加个性化。
黑衣人:啊!稍等一下!为什么我看这个图和原文的图不太一样捏?
濤濤醬:→_→ 你追求一模一样的有什么意思?大学马原学到哪去了?要抓住主要矛盾!
濤濤醬:所谓复现,就是只要能表达出一个意思的东西出来就可以了。正所谓“人不能两次踏入相同的河流”,所以没有两幅完全一模一样的图。更何况,我们这个热图,这颜色不是更好看吗?难道你喜欢红配绿赛哔—(自动消音)的神奇口味?
黑衣人:说得有道理!好吧,那以后我一定抓住主要矛盾,领会生信作图精神…… 在合并的数据集中做出非配对样本的箱型图,目前这个功能还在开发中。
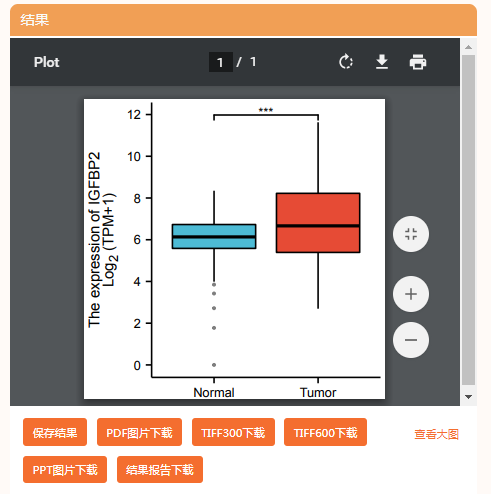
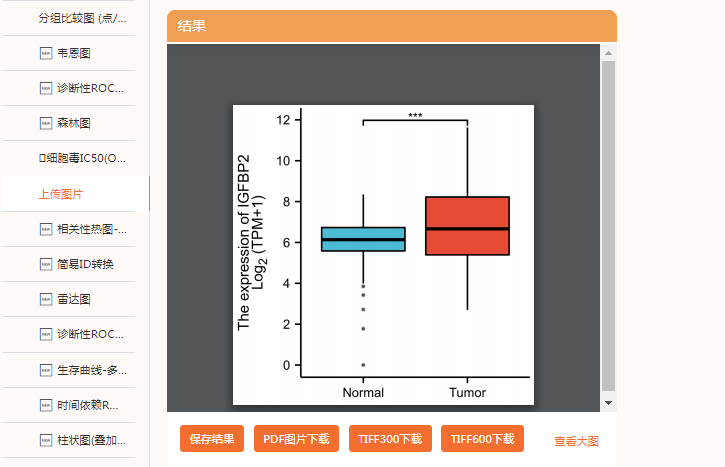
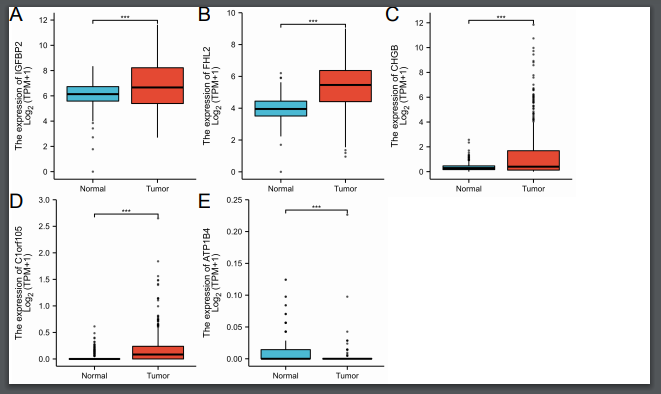
不过如果研究的是在肿瘤中的表达水平,我们可以把这个基因放在TCGA里探究其表达情况。
进入仙桃学术工具(https://www.xiantao.love/products);选择高级版,点击“立即使用”
注:免费版和基础版都可以进行统计和可视化,由于高级版功能最全,这里选择高级版作为范例
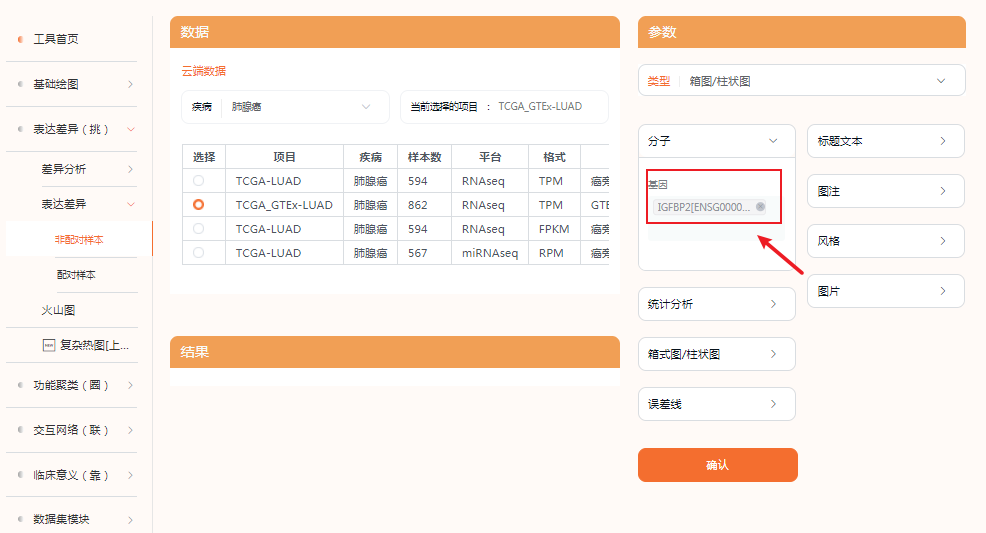
选择表达差异(挑)—表达差异—非配对样本,点击进入。
假设我们要研究的肿瘤非肺腺癌,那此处选择疾病-肺腺癌。
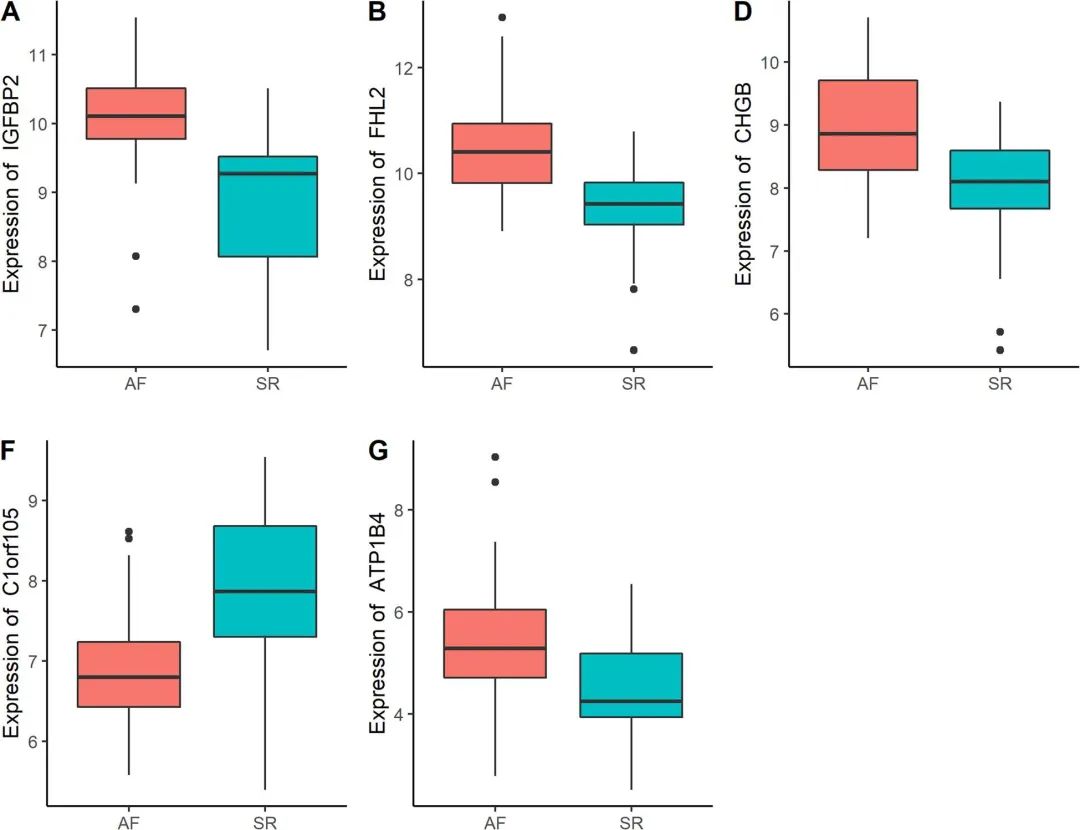
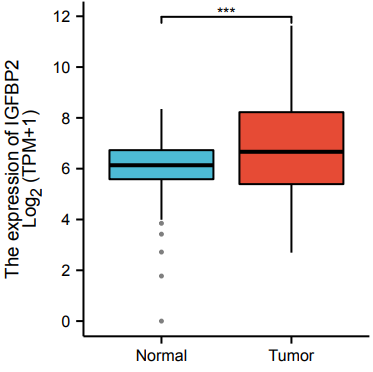
另外四个基因也是同理可得,最后采用我们仙桃最炙手可热的拼图功能喔!仙桃工具拼图比Illustratior或是Photoshop要节省不少时间!仙桃工具只要一分钟,AI或者PS可能要拼至少一天时间。
进入仙桃学术工具(https://www.xiantao.love/products);选择高级版,点击“立即使用”
注:免费版和基础版都可以进行统计和可视化,由于高级版功能最全,这里选择高级版作为范例
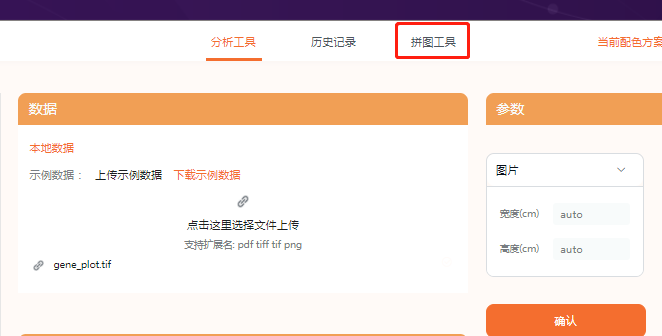
此处开始上传自己的图片,但是记得图片要为pdf、tiff、tif、png的格式喔!
上传好之后,可以调整图片的宽度和高度参数,最后点击确认。
记得点击下方第一个“保存结果”按钮,才能进行下一步的拼图喔!
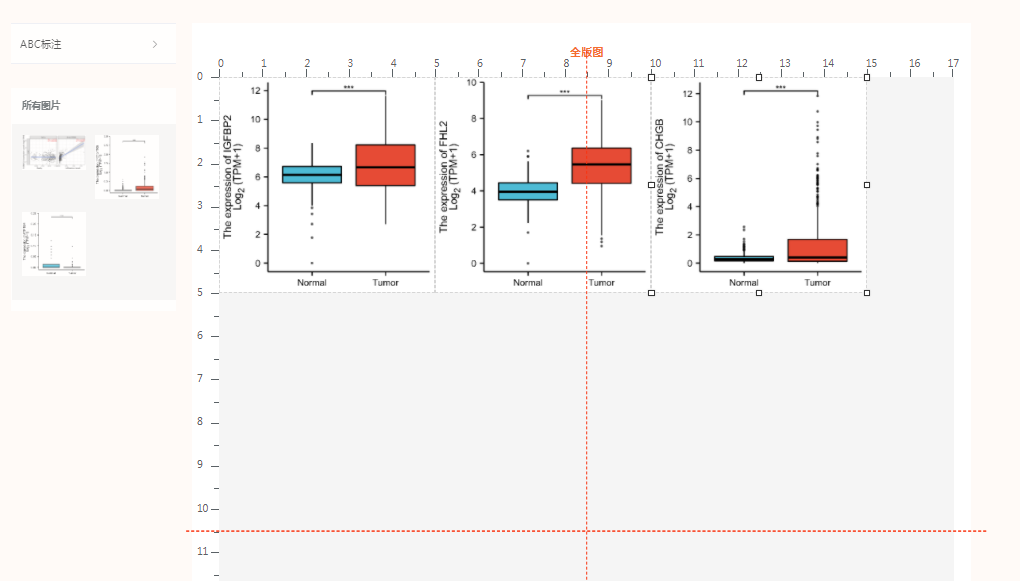
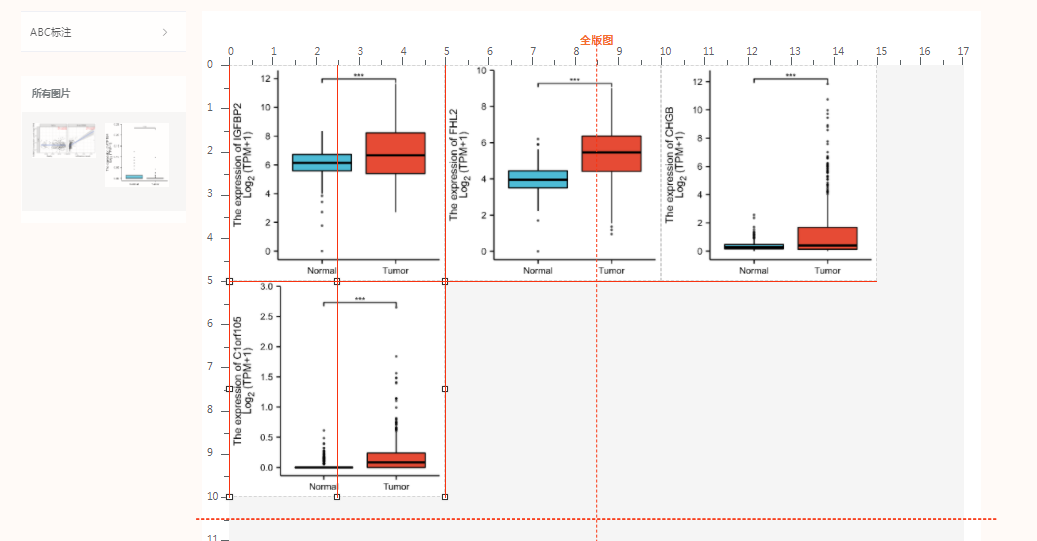
拖拽目标图片进入画布。(在对齐图片的时候可以选择横向参考线和纵向参考线辅助对齐。两个图片对齐时,接近辅助线的时候还有磁吸功能,拼图非常便利!
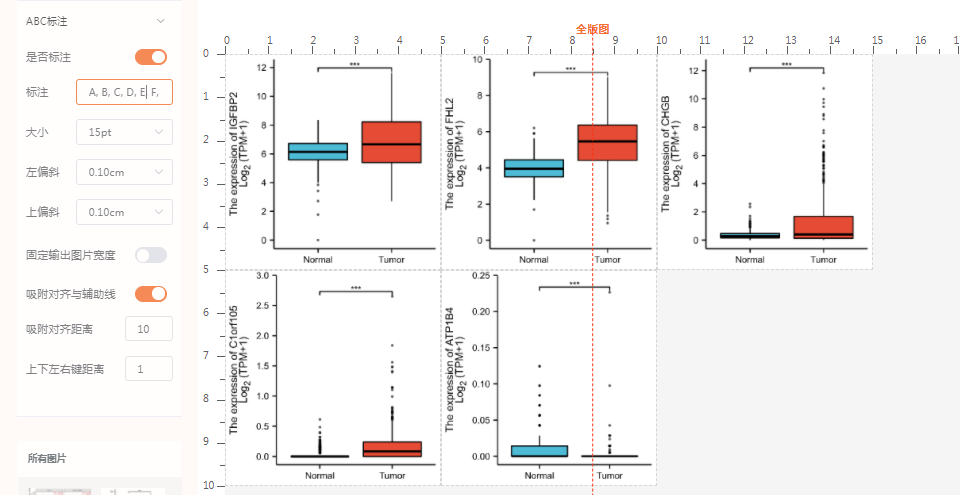
点击PDF下载,还会自动标记字母哦!点击下载,即可保存成pdf图片。(小贴士,这里也可以把图稍微放大,或者两图直接的行间距放大,可以在右侧减少留白)
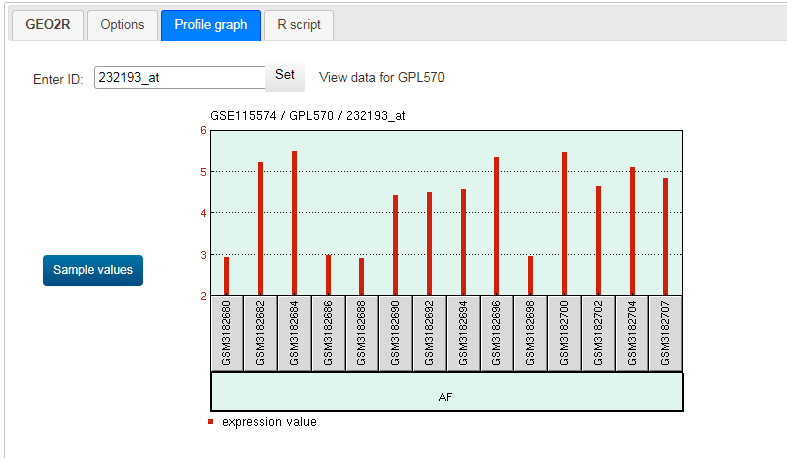
濤濤醬在此还想说的是,目前全网还没有一个在线工具能做到“整合多个GEO数据集,并且在其中绘制单个基因的表达差异箱型图”,但是我们可以变化我们的思路啊!
在合并的数据集中做出非配对样本的箱型图,目前这个功能还在开发中。
不过如果研究的是在肿瘤中的表达水平,我们可以把这个基因放在TCGA里探究其表达情况。
进入仙桃学术工具(https://www.xiantao.love/products);选择高级版,点击“立即使用”
注:免费版和基础版都可以进行统计和可视化,由于高级版功能最全,这里选择高级版作为范例
选择表达差异(挑)—表达差异—非配对样本,点击进入。
假设我们要研究的肿瘤非肺腺癌,那此处选择疾病-肺腺癌。
另外四个基因也是同理可得,最后采用我们仙桃最炙手可热的拼图功能喔!仙桃工具拼图比Illustratior或是Photoshop要节省不少时间!仙桃工具只要一分钟,AI或者PS可能要拼至少一天时间。
进入仙桃学术工具(https://www.xiantao.love/products);选择高级版,点击“立即使用”
注:免费版和基础版都可以进行统计和可视化,由于高级版功能最全,这里选择高级版作为范例
此处开始上传自己的图片,但是记得图片要为pdf、tiff、tif、png的格式喔!
上传好之后,可以调整图片的宽度和高度参数,最后点击确认。
记得点击下方第一个“保存结果”按钮,才能进行下一步的拼图喔!
拖拽目标图片进入画布。(在对齐图片的时候可以选择横向参考线和纵向参考线辅助对齐。两个图片对齐时,接近辅助线的时候还有磁吸功能,拼图非常便利!
点击PDF下载,还会自动标记字母哦!点击下载,即可保存成pdf图片。(小贴士,这里也可以把图稍微放大,或者两图直接的行间距放大,可以在右侧减少留白)
濤濤醬在此还想说的是,目前全网还没有一个在线工具能做到“整合多个GEO数据集,并且在其中绘制单个基因的表达差异箱型图”,但是我们可以变化我们的思路啊!
黑衣人:蛤?什么意思?
濤濤醬:因为这几个基因的表达情况都在热图中呈现了嘛,那我们可以更多维度呈现我们的生信分析结果啊,比如可以用PCA图来反应组间差异,这个在我们刚刚GEO分析结果里也有喔
黑衣人:喔,我明白了!这样审稿人就不会追着你一直问了,同时文章也更加饱满了!
濤濤醬:当然我们的仙桃小哥哥还是会继续努力马上把这个功能丰富上的,请大家多多转发此推文,让仙桃小哥哥加鸡腿喔!
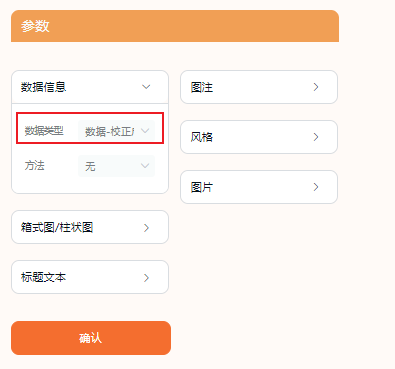
即,校正前、校正后,all in one pack!
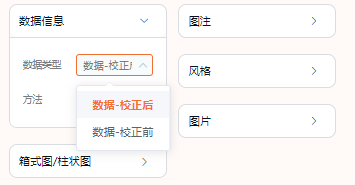
点击“数据类型”就可以选择校正前、校正后的不同情况
还有另外一个方法,就是在历史记录里,也可以查找到我们刚刚的结果。
最后把两图放在Illustrator或者Photoshop软件采用我们仙桃的拼图功能喔!
黑衣人:这题我会!
濤濤醬:哈哈,you can you up!那你来说说看
濤濤醬:你就会这种偷懒的答案(¬_¬) 不过呢,你确实说对了,我们可以直接拿现成的仙桃结果!
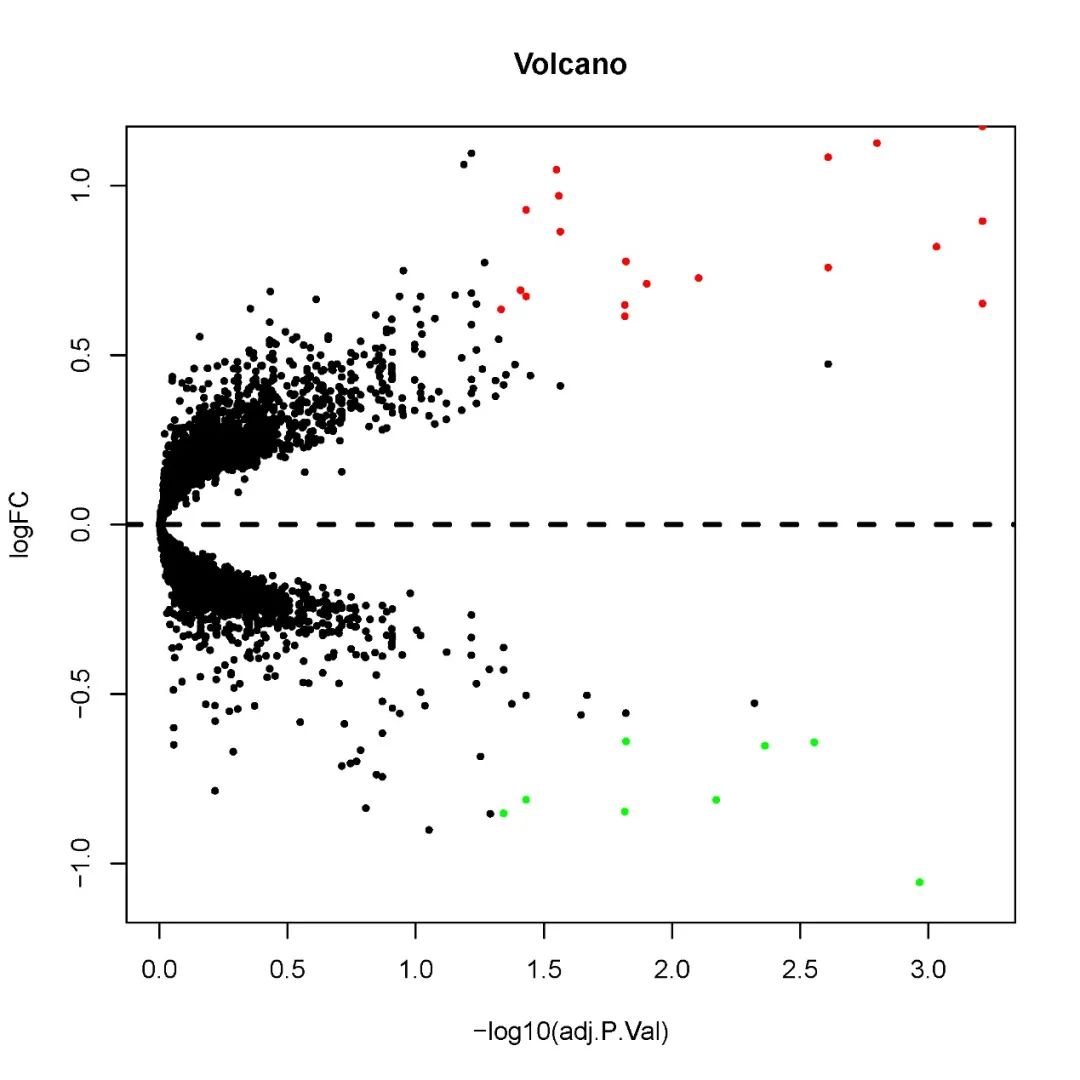
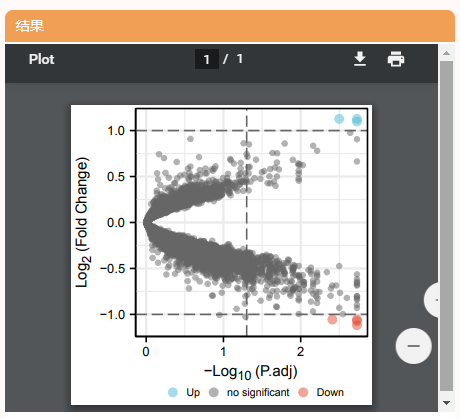
这样一幅图就清晰呈现啦,连上调、下调的情况都标注出来了!
附图3. 使用REACTOME数据库呈现IGF以及IGFBP的富集通路分析
作者在材料中提到,这个是利用Reactome的数据库为基础,再用R语言实现的
那我们就一起来看看Reactome(https://reactome.org/)数据库
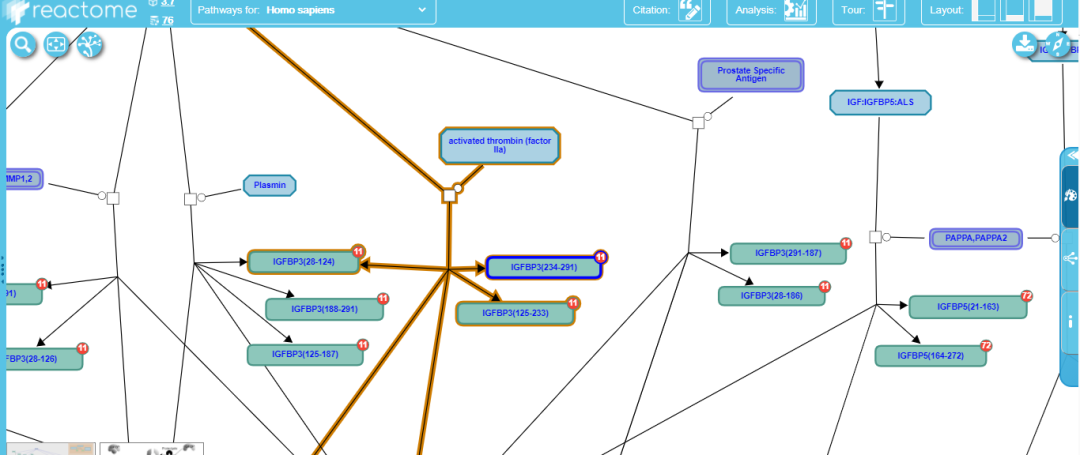
我们根据文中上调的差异基因情况,将三个基因(IGFBP2, IGFBP3, CHGB)输入进搜索框中
因为原文的图是用R包制作而成,所以复现时略有差异。
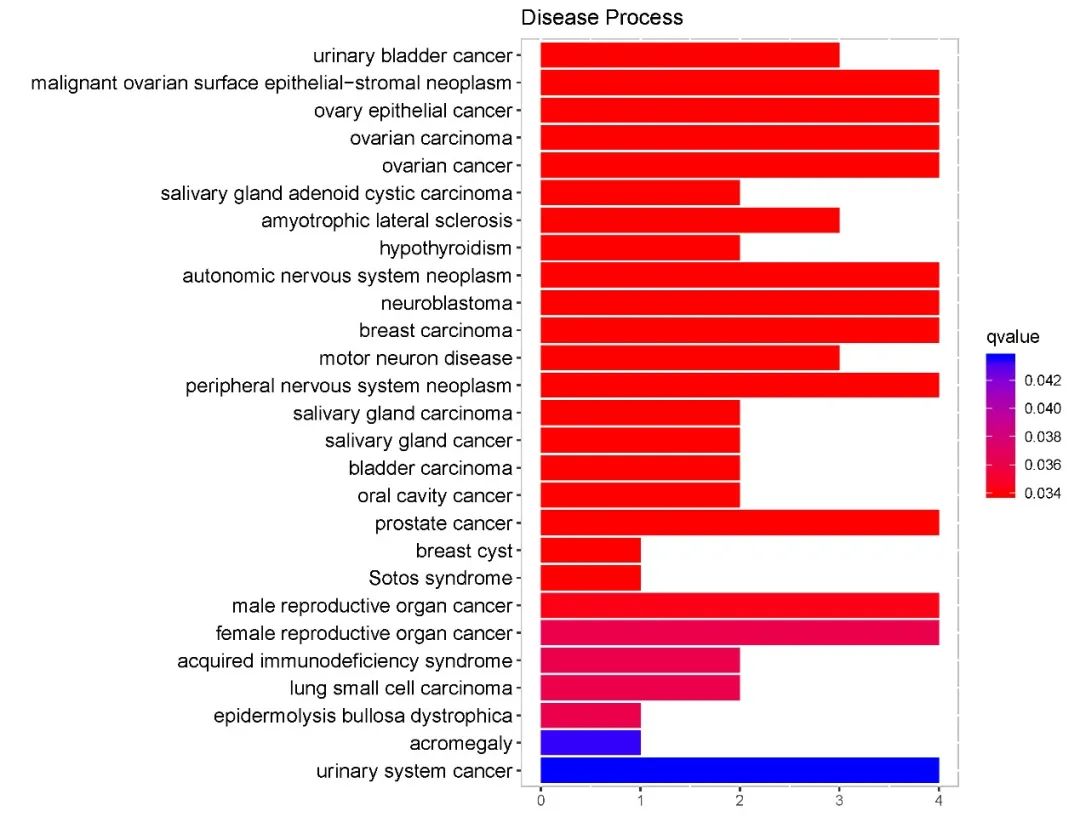
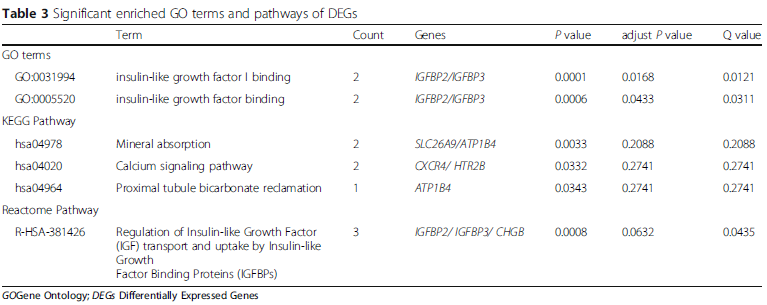
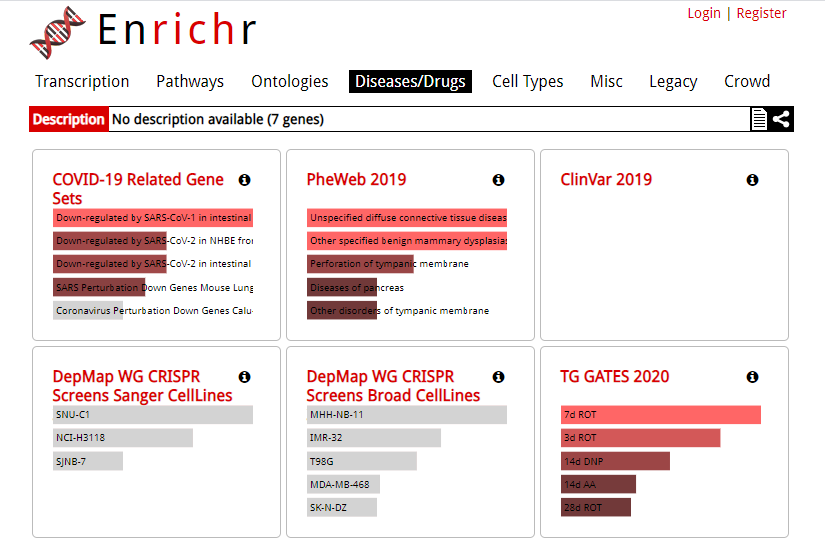
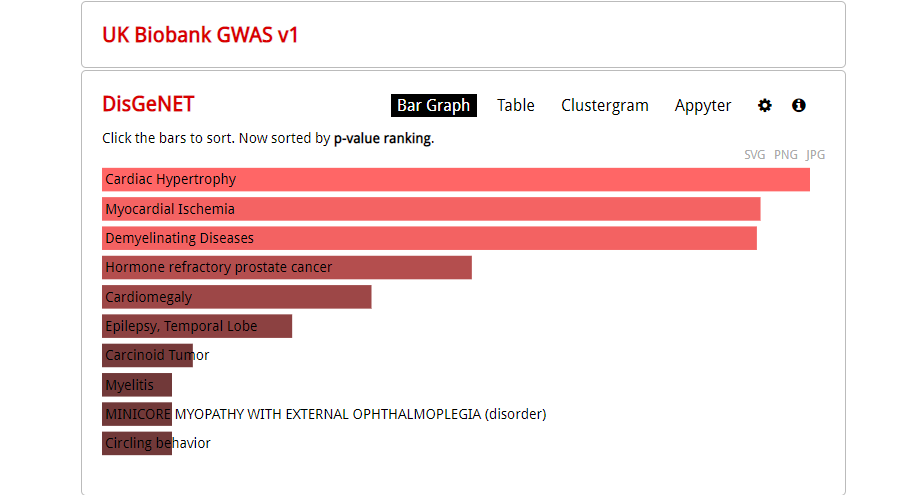
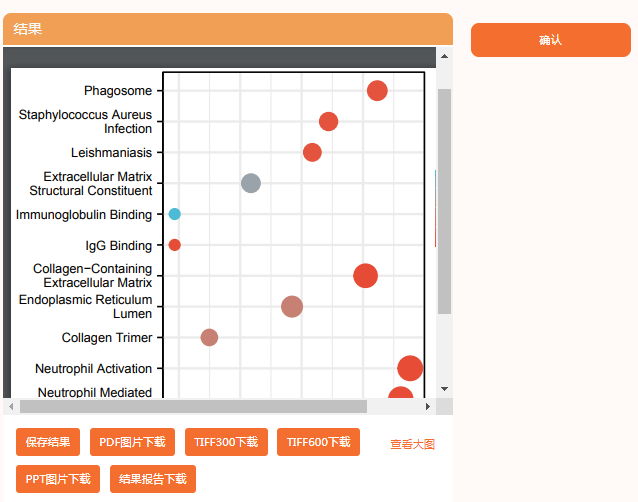
这张看似是GO|KEGG分析的条形图,其实是疾病富集分析
根据材料与方法部分的陈述,作者采用R语言里的DO(Disease Ontology)进行富集分析。
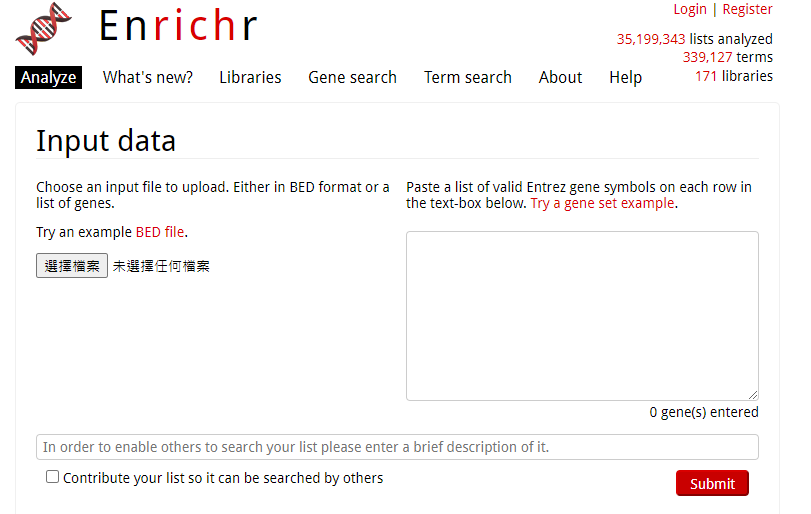
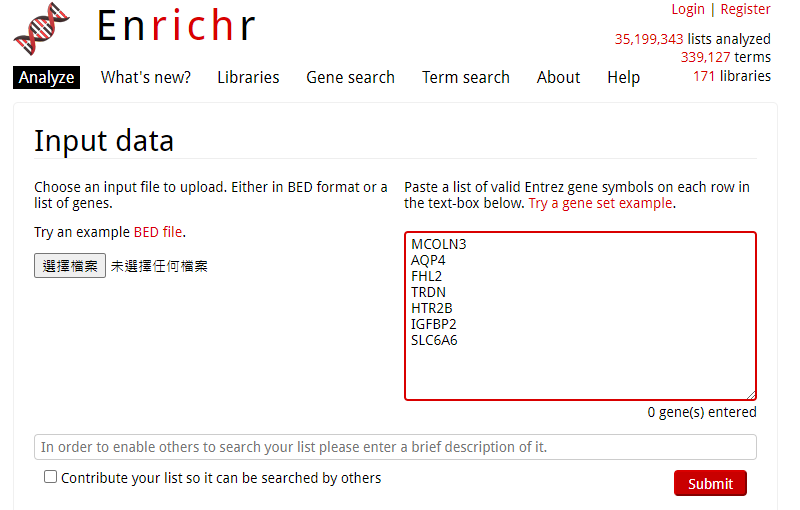
那我们不妨试试看Enrichr这个在线工具(https://maayanlab.cloud/Enrichr/)。
看到首页就是要输入基因,要么采用上传表格的方式,要么采用贴上方框的形式。
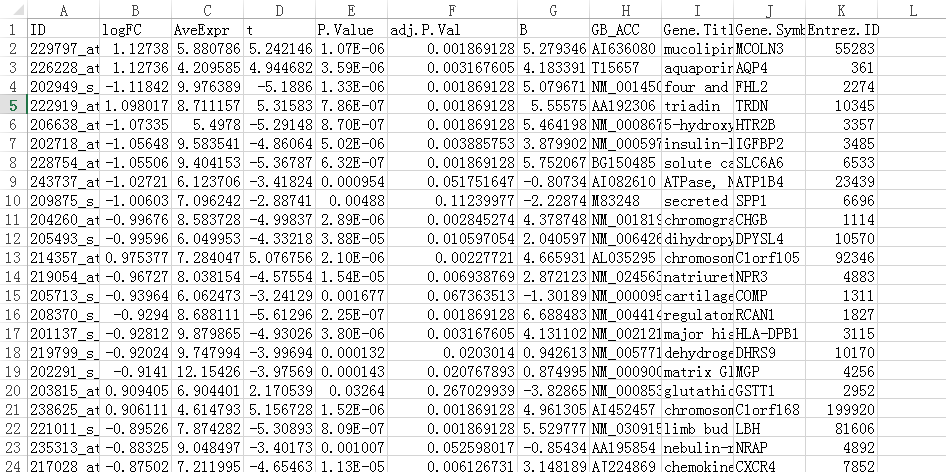
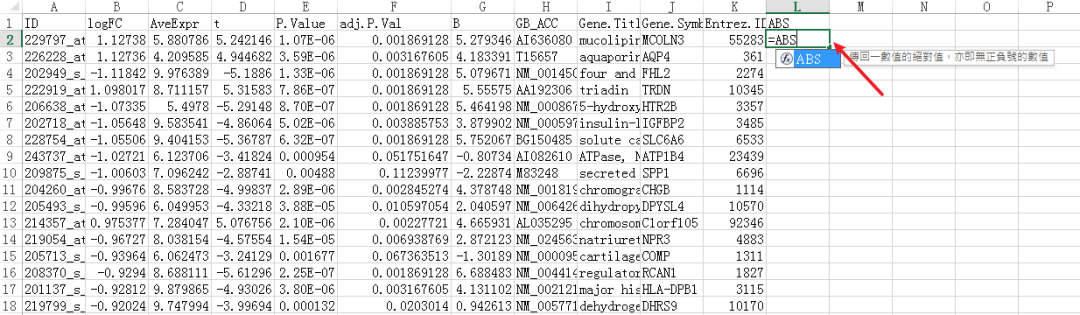
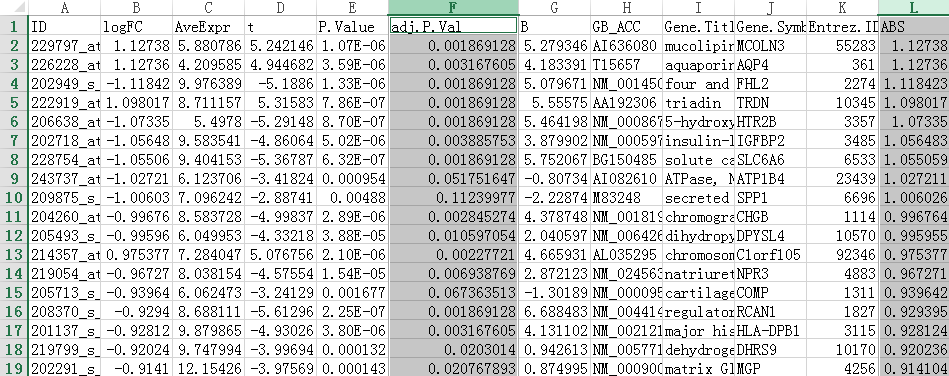
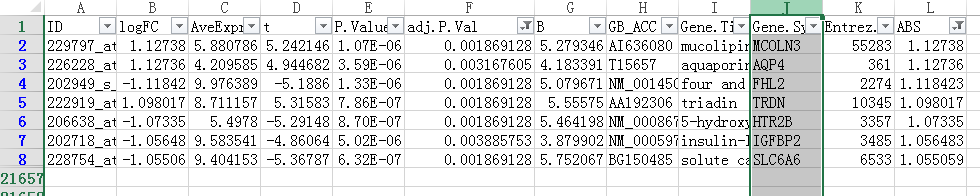
因为要输入差异表达基因,所以我们打开仙桃帮我们分析好的结果
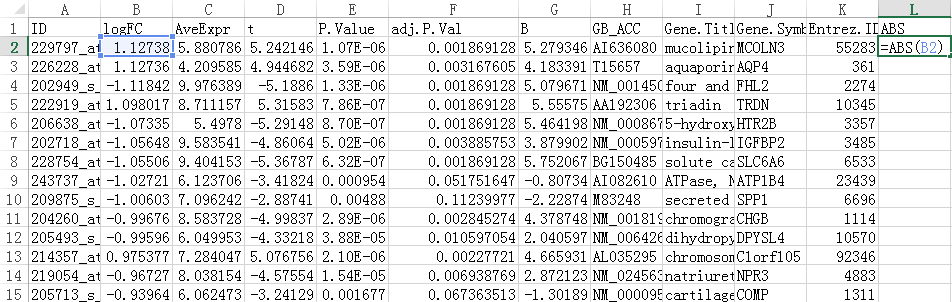
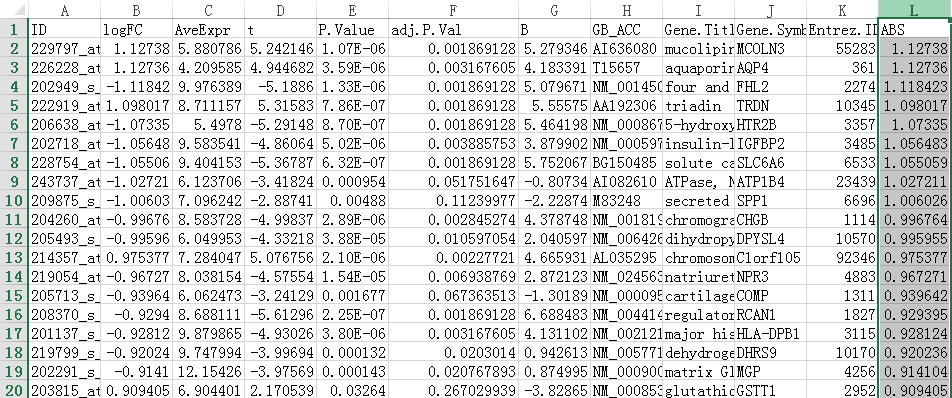
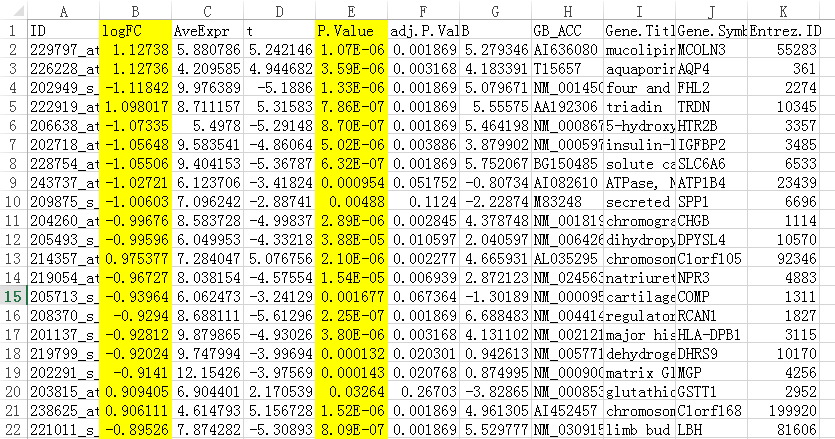
我们在后一栏新增一个logFC的绝对值,命名为ABS
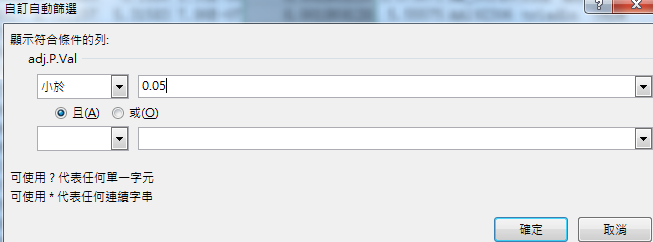
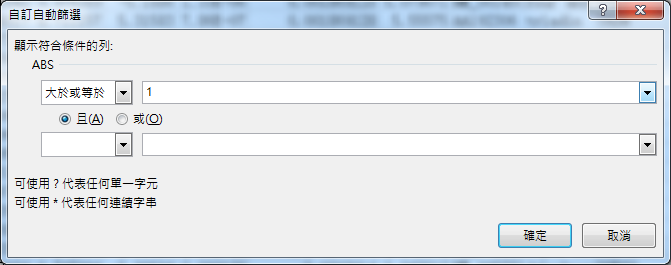
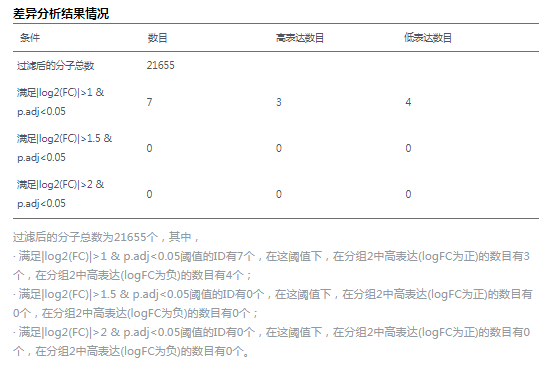
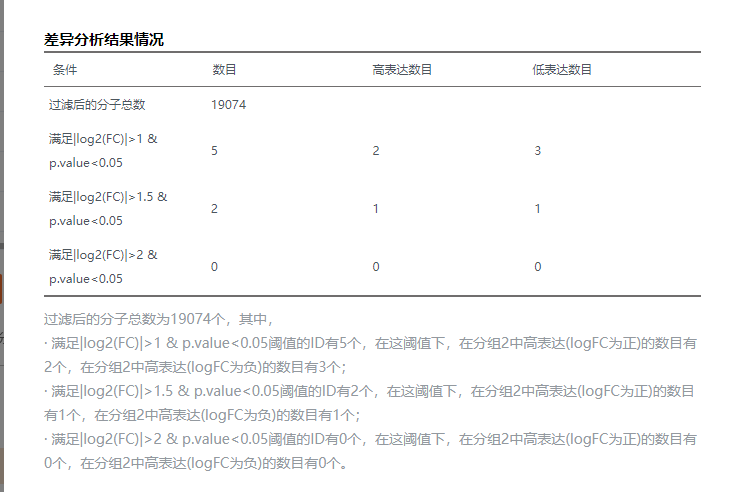
所以我们在excel里筛选ABS这列≥1 & adj.P.Val这列<0.05
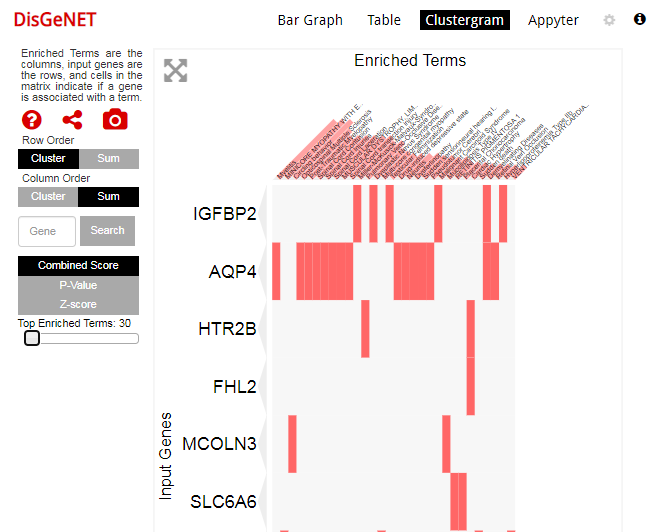
我们可以任意挑选有关于疾病的数据库,比如DisGeNET
可以调节其中的参数以及富集的条目,以富集前30个条目为例
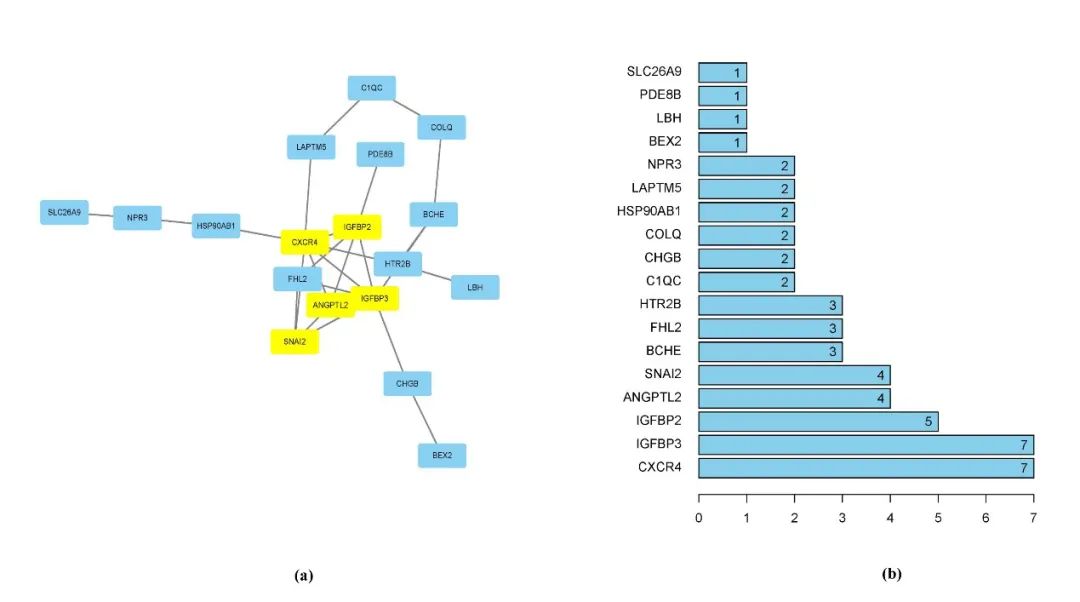
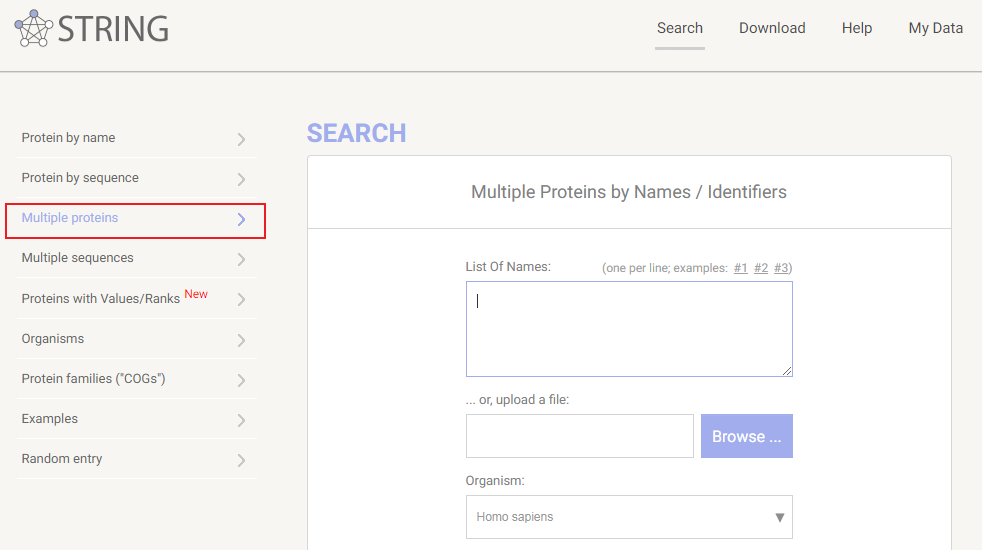
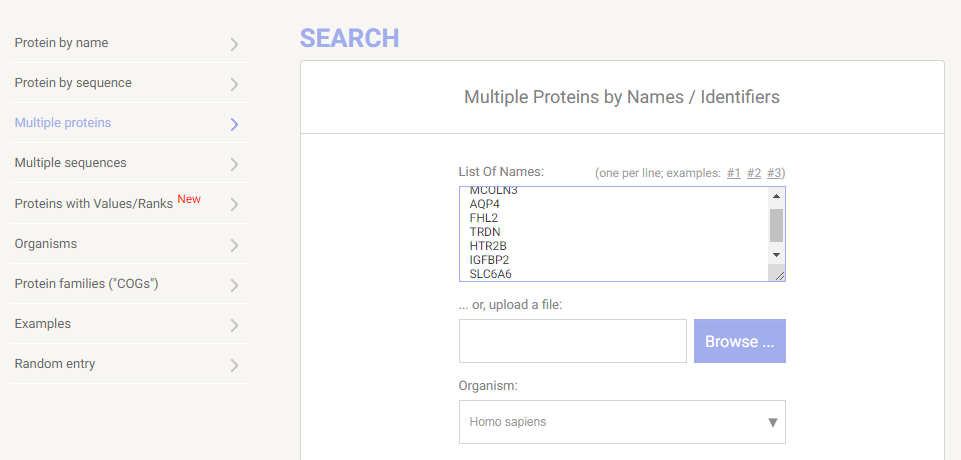
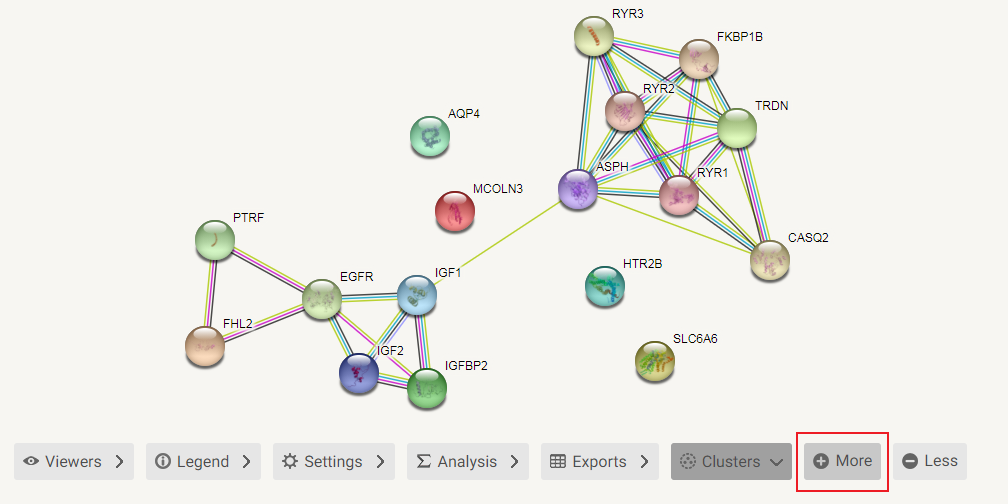
我们借助String来完成这项操作(https://www.string-db.org/)
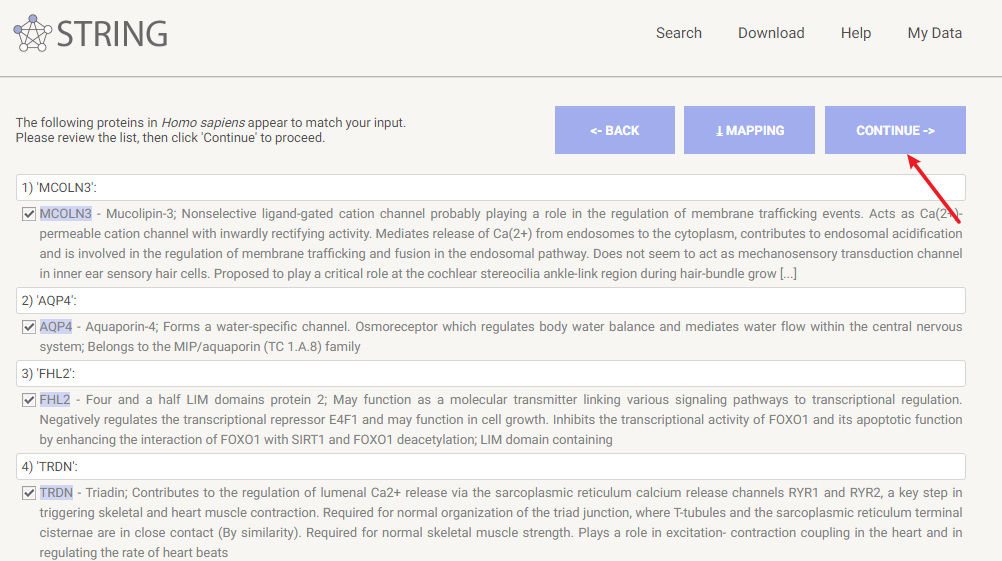
点击Search之后出现如下界面,再点击Continue
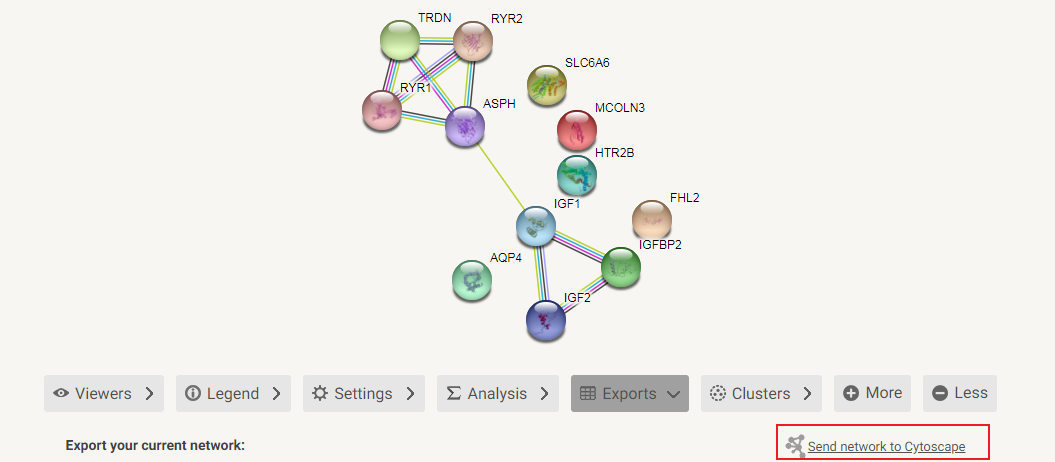
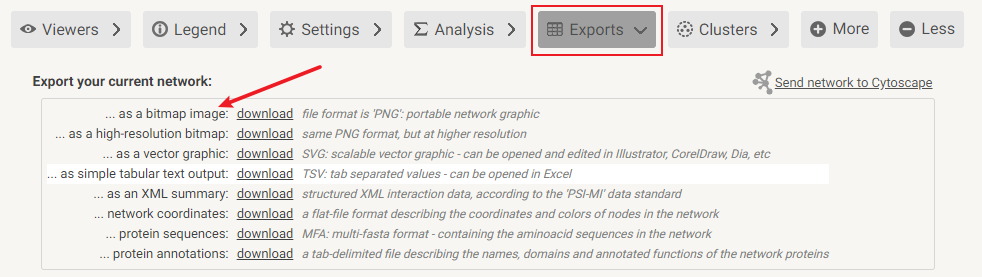
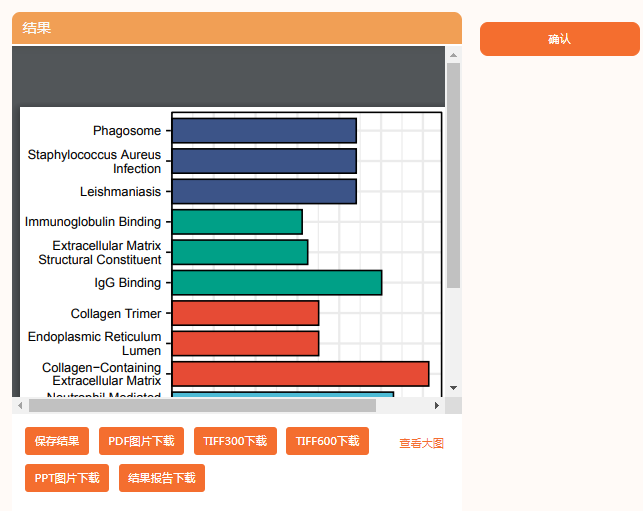
小贴士:会使用cytoscape的同学可以将这些结果导入cytoscape里,能更改成更好看的样式喔!
不想导出到cytoscape再编辑的朋友,可以直接在此输出保存
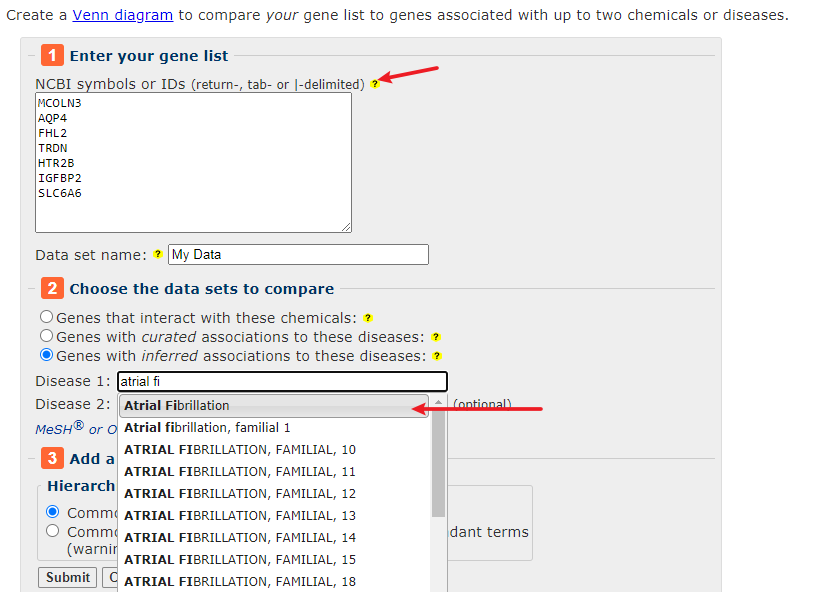
根据文章介绍,作者采用的是CTD数据库(http://ctdbase.org/ )
这个数据库是一个集结了基因——药物——疾病为一体的数据库,所以对于非肿瘤研究还是蛮有优势的。
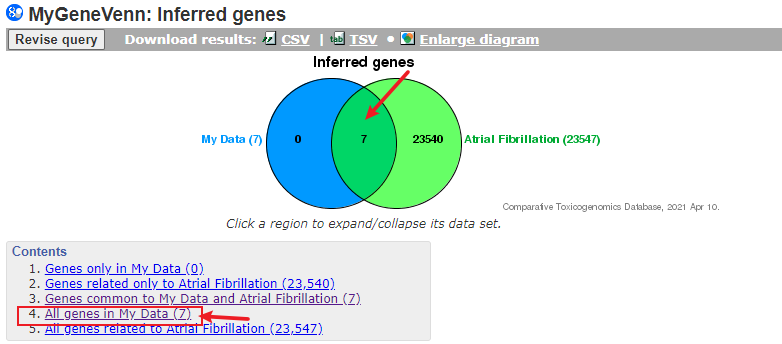
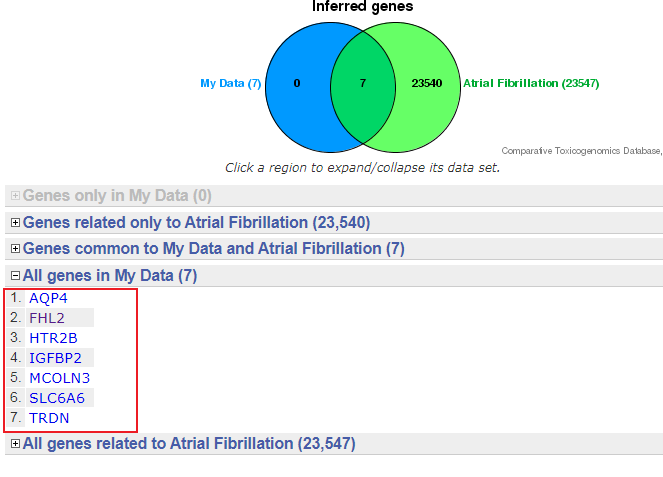
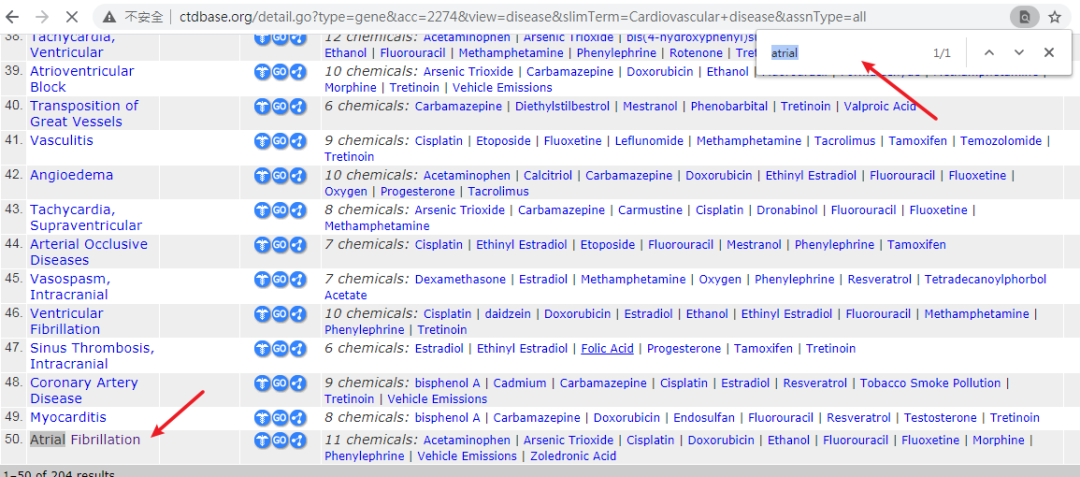
接下来可以点击Venn图的交集部分,或者点击第4项
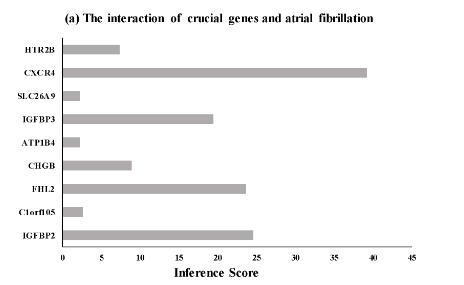
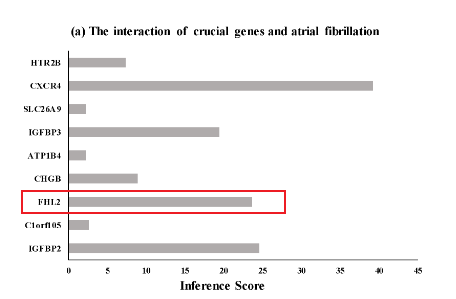
接下来我们就一个一个基因来查看他的inference score
黑衣人:我懂了,原来图a是一个一个值查看然后记录下来,手动做成的条形图啊
进一步查看该基因的inference score为23.24
接下来同理可得其他关键基因的inference score
进一步地,可以查询其他疾病,也可以获得其他几幅图,再将它们拼图起来就可以了!
是的,这就是作者总结了五个数据集的基本情况,再通过三线表的形式整理出来,简洁明了
点击“选择样本”,即可根据红色标记栏手动整理出表1的内容啦!
黑衣人:如果是用GEO怎么整理?
濤濤醬:我前面说的难道都白说了吗→_→ 那我就再说一遍吧o(╥﹏╥)o
打开GEO数据库(https://www.ncbi.nlm.nih.gov/gds)
可根据描述部分来手动整理分组,但是要留意(左侧或右侧)喔!
心细的朋友可能发现,这个与我们通过仙桃学术所计算出来的有些许差别
可能是在数据清洗时的处理模式不同,导致后续的体现在结果的logFC、P value有偏差
黑衣人:那……要怎么办呢?
黑衣人:我懂了!不能盲目跟风,算出什么就是什么!做自己!
所以这也解释了为什么前文几个图复现结果会与文章有些差异的原因。
不过没关系,以事实为基准,没有孰对孰错。开心就好(能发文章就很开心,对吧?)
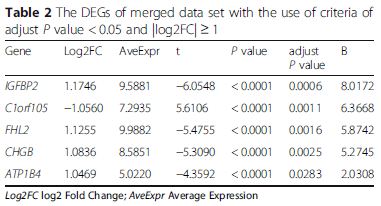
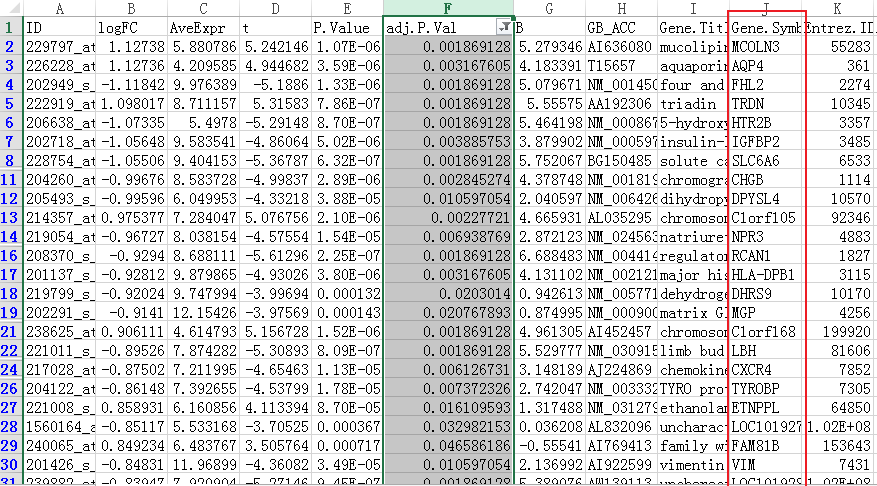
由于7个差异基因过少,没法分析,所以我们放宽指征,更改筛选模式,只要纳入adj.p.Value <0.05即可。
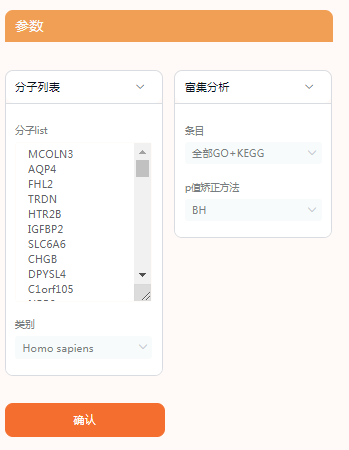
将该列基因复制到方框中,富集条目选择GO+KEGG,点击确认。
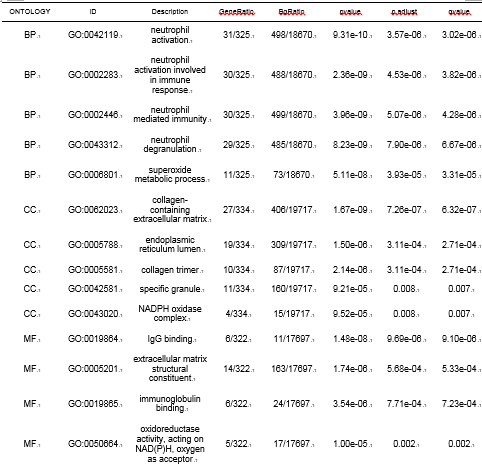
根据作者需要,选择BP、MF、CC的具体内容整理表格即可。
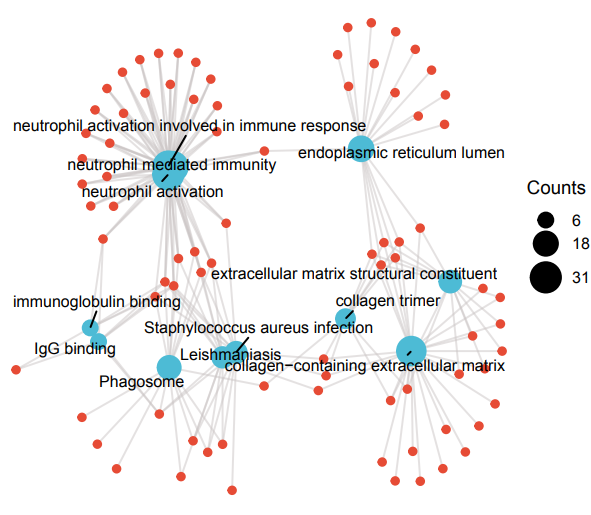
接下来,在“功能聚类(圈) GO|KEGG可视化”中
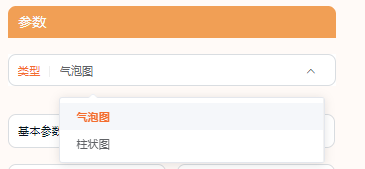
同样,如果想做“柱状图”,在类型中更改相应的柱状图即可完成。
聚类分析可视化网络图是在“功能聚类(圈) GO|KEGG可视化网络”中
本次直播将在哔哩哔哩和微信视频号同步播出,同时也会在双平台进行直播抽奖。大家可以去微信视频号进行直播预约,点赞推荐直播预告还有机会赢得199元解螺旋精品课。
戳按钮预约直播


 是喔!一站式GEO下游分析,汇聚各式美图,仙桃全都有!
是喔!一站式GEO下游分析,汇聚各式美图,仙桃全都有!













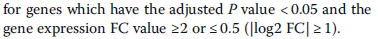
















文章评论