本文重点探讨分布式学习框架中针对随机梯度下降(SGD)算法的拜占庭问题。
分布式学习(Distributed Learning)是一种广泛应用的大规模模型训练框架。在分布式学习框架中,服务器通过聚合在分布式设备中训练的本地模型(local model)来利用各个设备的计算能力。分布式机器学习的典型架构——参数服务器架构中,包括一个服务器(称为参数服务器 - Parameter Server,PS)和多个计算节点(workers,也称为节点 nodes)[1]。其中,随机梯度下降(Stochastic Gradient Descent,SGD)是一种广泛使用的、效果较好的分布式优化算法。在每一轮中,每个计算节点根据不同的本地数据集在它的设备上训练一个本地模型,并与服务器共享最终的参数。然后,服务器聚合不同计算节点的参数,并通过与计算节点共享得到的组合参数来启动下一轮训练。关于基于 SGD 优化的分布式框架的网络结构(包括:层数、类型、大小等)在训练开始之前由所有计算节点共同商定确认。
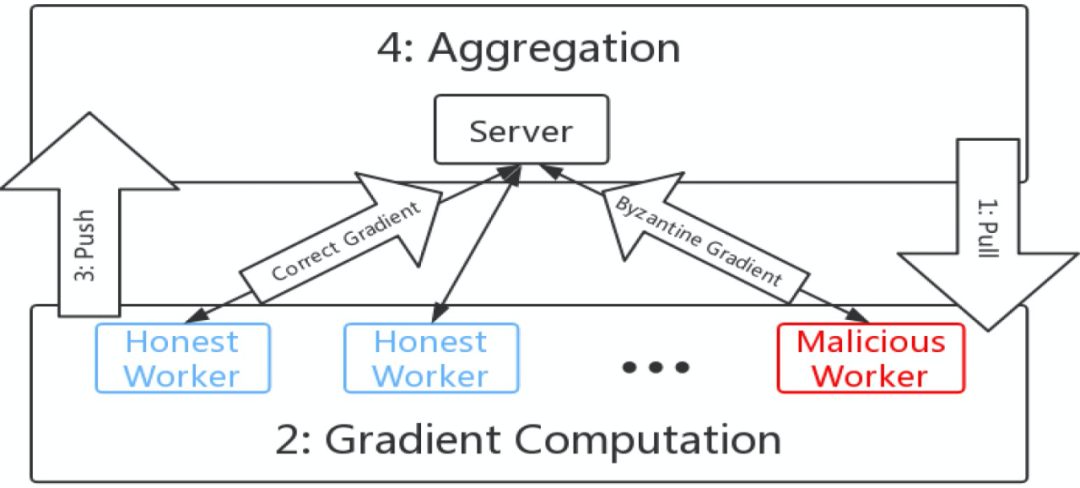
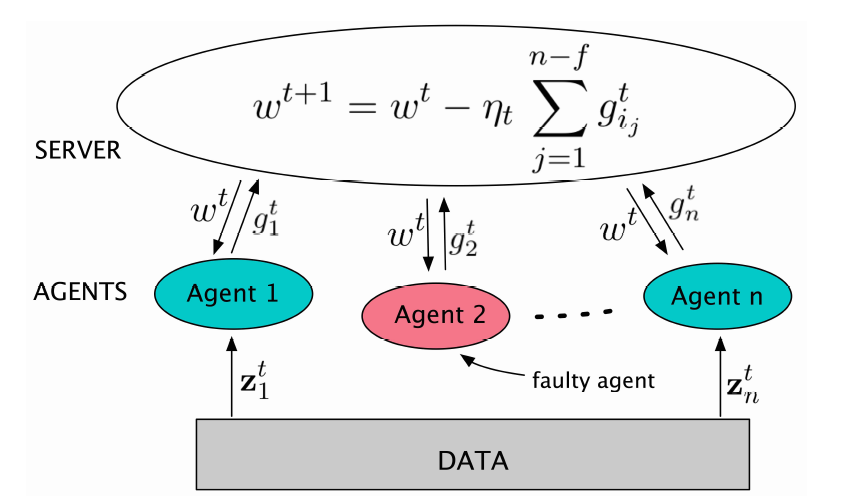
近年来,分布式学习的安全性越来越受到人们的关注,其中,最重要的就是拜占庭威胁模型。在拜占庭威胁模型中,计算节点可以任意和恶意地行事。机器之心在前期的文章中也探讨过分布式学习中的拜占庭问题,主要针对联邦学习中的拜占庭问题。在这篇文章中,我们重点探讨的是分布式学习框架中针对随机梯度下降(SGD)算法的拜占庭问题。如图 1 所示,在 SGD 学习框架中,一些恶意节点(Malicious worker)向服务器发送拜占庭梯度(Byzantine Gradient),而不是计算得到的真实梯度,而拜占庭梯度可以是任意值。恶意节点可以控制计算节点设备本身,也可以控制节点和服务器之间的通信。以 Algorithm 1 中提出的同步 SGD(sync-SGD)协议为例 [4]。攻击者(恶意节点)在使其效果最大化的时间内(即在 Algorithm 1 的第 6 行和第 7 行之间)干扰进程。在此期间,攻击者可以将节点 i 中的参数(p_i)^(t+1) 替换为任意值,然后将此任意值发送到服务器中。攻击方法在设置参数值的方式上有所不同,而防御方法则试图识别损坏的参数并丢弃它们。Algorithm 1 使用平均值(第 8 行中的 AggregationRule( ))聚合计算节点参数。

本文所讨论的分布式学习的核心是这样一个假设:经过训练的网络参数是独立同分布的(Independent and identically distributed,i.i.d.)。根据这一假设,对不同的本地模型生成的参数进行平均化处理后能够得到对期望参数的一个良好估计。此外,这一假设也是设计不同防御机制的基础——在清除掉拜占庭值后就能够成功恢复原始平均值。
目前,研究人员的主要工作聚焦于分布式学习中拜占庭问题的攻击(Attack)和防护(Defense)。我们选择了四篇近期研究成果进行深入分析。其中,第一篇文章聚焦于基于内积操作的攻击策略,而第二篇文章关注的是拜占庭问题的防护策略,前两篇文章是来自 University of Illinois at Urbana-Champaign 的同一个研究小组工作。第三篇文章提出了一种新的攻击模式,恶意节点通过对多个参数进行有限的修改,可能会干扰(interference)或获得分布式学习过程的后门(backdoor)。最后,第四篇文章讨论的是同质多 agent 分布式学习中的拜占庭容错问题。
本文是来自 University of Illinois at Urbana-Champaign 的研究人员发表在 UAI 2019 (International Conference on Uncertainty in Artificial Intelligence)中的一篇文章。作者使用一种基于内积操作(Inner Product)的攻击方法攻破了两个著名的拜占庭容错 SGD 算法:Coordinate-wise Median 和 Krum。
Median 和 Krum 是两种拜占庭鲁棒的聚合规则。在 Median 聚合规则中,对于第 j 个全局模型参数,主设备(服务器)会对 m 个计算节点的第 j 个参数进行排序,并将中位数(median)作为全局模型的第 j 个参数。当 m 为偶数时,中位数是中间两个参数的均值。Krum 则是在 m 个计算节点中选择一个与其他计算节点参数最为相似的计算节点, 将该计算节点的参数作为全局参数。Krum 的想法是即使所选择的参数来自于受攻击 / 恶意的计算节点设备,其能够产生的影响也是受限的,因为它与其他可能的正常计算节点设备的参数是相似的。
如图 1 所示的架构,拜占庭计算节点向服务器发送任意值(拜占庭值),而不是真实的梯度估计。拜占庭值可能导致收敛到次优模型,甚至导致发散。更糟糕的是,拜占庭计算节点可以在任何服务器或任何诚实的计算节点中监视信息。因此,攻击者可以将拜占庭值设定为具有与正确梯度相似的方差和幅度,使得它们更加难以区分。对于传统的分布式计算,拜占庭式容错方法试图在正确值上达成共识。然而,对于机器学习算法来说并不需要达成共识。此外,即使是没有采用任何拜占庭容错机制的机器学习算法也可以容忍输入和执行过程中的一些噪声。因此,对于分布式 SGD,现有的拜占庭容错机制能够保证聚合近似梯度(在拜占庭计算节点下)和真实梯度之间的距离上界。
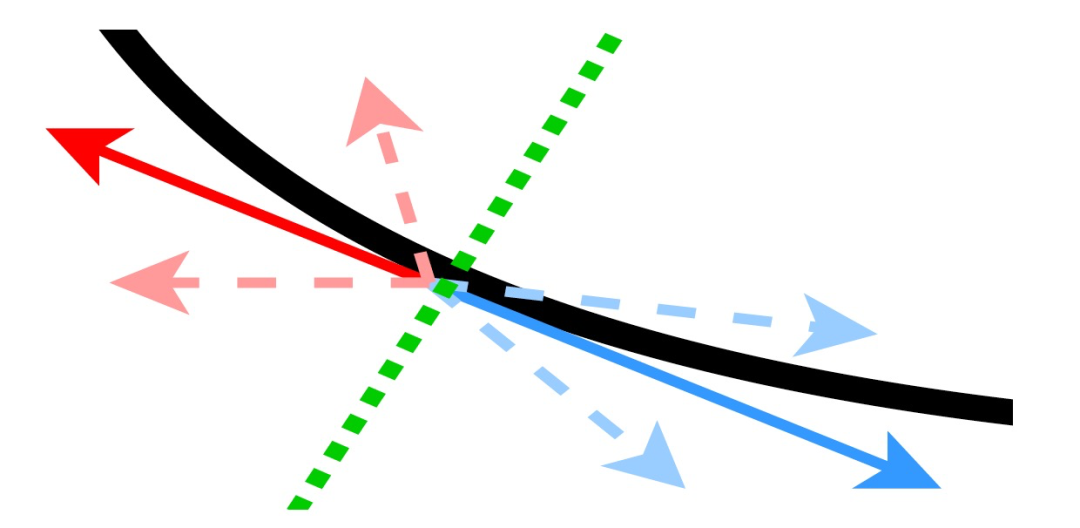
作者发现,梯度下降算法真正重要的是下降的方向。如图 2 所示,为了保证梯度下降算法有效,我们需要保证最终服务器中聚合的向量方向与真实的梯度一致,即聚合向量与真实梯度的内积必须是非负的。而使内积为负的攻击就会打破这一约束,作者称这类新攻击为“内积操纵攻击(“Inner product manipulation attacks)”。作者表示,现有技术所保证的聚合值和真实梯度之间的有界距离不足以抵御分布式同步 SGD 的内积操作攻击。例如,对于坐标中值聚合规则,如果我们将所有拜占庭值设置为真实梯度的负值,则聚合向量和真实梯度之间的内积可以被操纵为负。本文具体研究如何利用内积操纵攻击拜占庭容错 SGD。
图 2. 下降方向。蓝色箭头是与最陡下降方向(负梯度)一致的方向。红色箭头是与最陡上升方向(坡度)一致的方向
其中,F(x)为可微函数,z 从未知分布 D 中采样得到,D 是维数。假设 F(x)至少存在一个极小值,用 x * 表示,其中ᐁF(x*)=0。
在分布式计算问题中,通过 m 个计算节点的分布式协作方式解决上述优化问题。在每次迭代中,每个计算节点从分布 D 中抽取 n 个独立且同分布(i.i.d.)的数据,并计算局部经验损失的梯度。服务器收集和聚合计算节点发送的梯度,并按如下方式更新模型:
其中,Aggr()表示聚合规则。当所有计算节点都诚实时,最常见的聚合规则 Aggr()是求取均值的平均规则:
在拜占庭失效模型(Byzantine failure model)中,恶意计算节点发送的梯度可以取任意值:
其中,* 表示任意值。真实计算节点发送梯度值,而拜占庭计算节点发送任意值。
在以往的拜占庭容错 SGD 算法研究中,大多数鲁棒聚集规则只能保证鲁棒估计量不偏离正确梯度的平均值。换句话说,鲁棒估计量和正确均值之间的距离存在上界。然而,对于梯度下降算法,为了保证损失是下降的,真实梯度和鲁棒估计之间的内积必须是非负的。特别地,如果攻击者操纵拜占庭梯度并使内积为负,则有界距离不足以保证鲁棒性。
内积操作的思想是:当梯度下降算法收敛时,梯度接近 0。因此,即使鲁棒估计量和正确均值之间的距离是有界的,仍然有可能操纵它们的内积为负,特别是当这种距离的上界较大时。
作者定义了一种分布式同步 SGD 的拜占庭容错(Distributed synchronous SGD,DSSGD )。假设在特定的迭代中,服务器接收 (m-q) 个正确的梯度 V={v_1,...,v_(m-q)和 q 个拜占庭梯度 U={u_1,...,u_q}。假设正确的梯度具有相同的期望值:
满足下式的聚合机制 Aggr( )可以被称为是 DSSGD 拜占庭容错的:
作者强调,作者并不认为先前工作中的理论是错误的。相反,作者的主张是有界距离的理论保证并不足以保证分布式同步 SGD 的安全。特别地,DSSGD 拜占庭容错与先前工作中提出的拜占庭容错也是不同的。
作者证明了在某些条件下,Median 不是 DSSGD 拜占庭容错的。服务器接收 (m-q) 个正确的梯度 V={v_1,...,v_(m-q)和 q 个拜占庭梯度 U={u_1,...,u_q}。当 m-2q=1,给定随机梯度和非零坐标方差,存在满足下式的拜占庭梯度:
当梯度下降收敛时,梯度 g 的期望值趋于 0。此外,由于诚实计算节点产生的梯度是随机的,所以方差非零。最终能够满足条件最大值:
SGD 越接近临界点,坐标方向的中位数 median 越不可能实现 DSSGD 拜占庭容错。
从攻击者的角度考虑,在每个坐标中,如果正确期望为正,攻击者只需保证所有拜占庭值远小于最小正确值;如果正确期望为负,攻击者只需保证所有拜占庭值远大于最大正确值。然后,对于攻击者来说,如果方差足够大,最小 / 最大值与正确的期望值具有相反的符号。因此,攻击者可以成功地将聚合值设置为与正确期望相反的方向,以实现攻击。
作者证明了在某些条件下,Krum 不是 DSSGD 拜占庭容错的。服务器接收 (m-q) 个正确的梯度 V={v_1,...,v_(m-q)和 q 个拜占庭梯度 U={u_1,...,u_q}。当 m-2q>2(例如,m-2q=3),定义正确梯度的均值如下:
对于任意两个不同的 v_i 和 v_j,存在任意β,满足:
在上述定理中,假设所有正确的梯度都在以其平均值为中心的欧式球内。这样的假设并不总是可以满足的,但是如果方差不太大的话,要求随机样本在这样一个欧氏球内也是合理的。另一方面,假设正确梯度之间的成对距离的下限为 β>0,且这样的β一定存在。拜占庭攻击者应该是无所不知的。因此,攻击者可以监视诚实的计算节点,并获得 V 和β 。然后,攻击者可以选择一个ε,满足:
从攻击者的角度来看,可以根据上述分析构建对抗梯度。攻击者只需将所有拜占庭值确定如下:
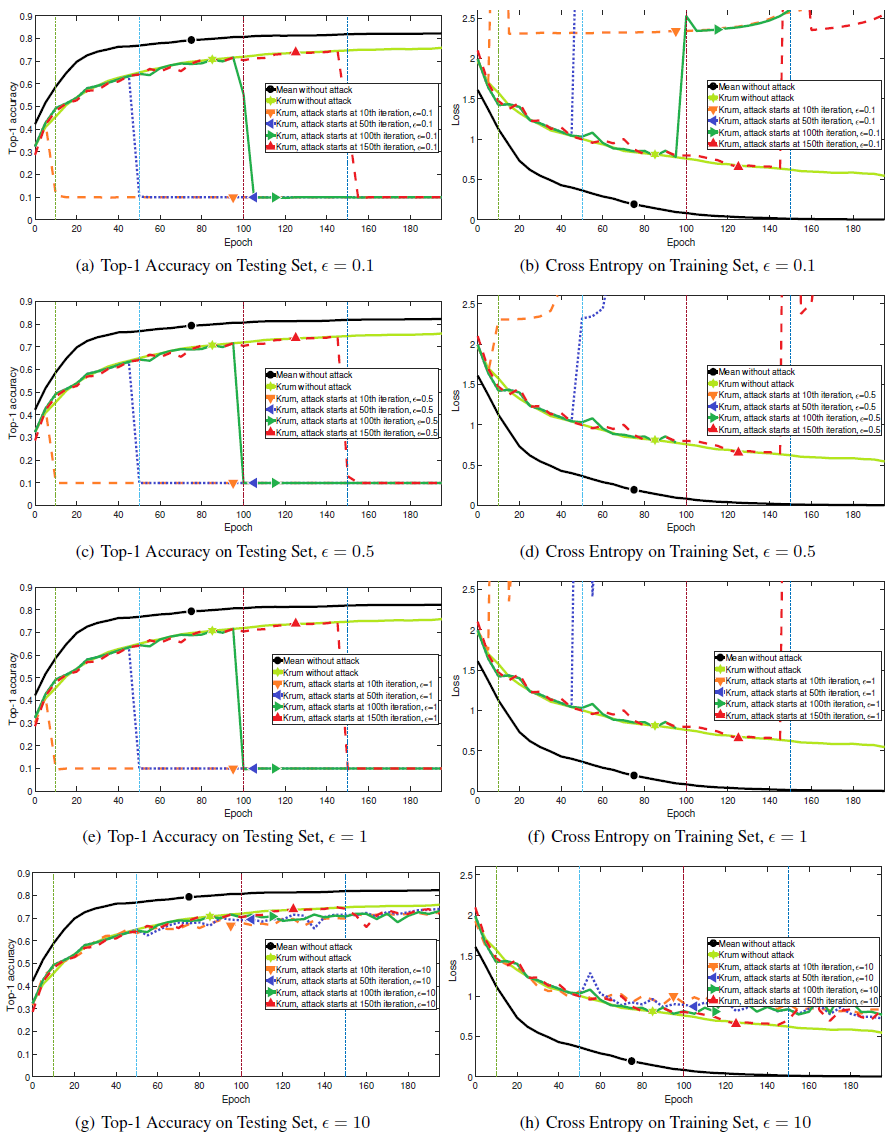
作者在 CIFAR-10 图像分类基准库上进行了实验,该数据库由 50K 的训练图像和 10K 的测试图像组成。作者使用 MXNet,包括 4 个卷积层和 1 个全连接层。SGD 的 minibatch 大小为 50。在每个实验的分布式环境中,作者设置了 25 个计算节点。每个实验重复 10 次,取平均值作为最终结果。使用测试集上的 Top-1 准确度和训练集上的交叉熵损失函数作为评估指标。
图 3. 使用 Median 作为聚合规则的训练集收敛
图 4. 使用 Krum 作为聚合规则的训练集收敛
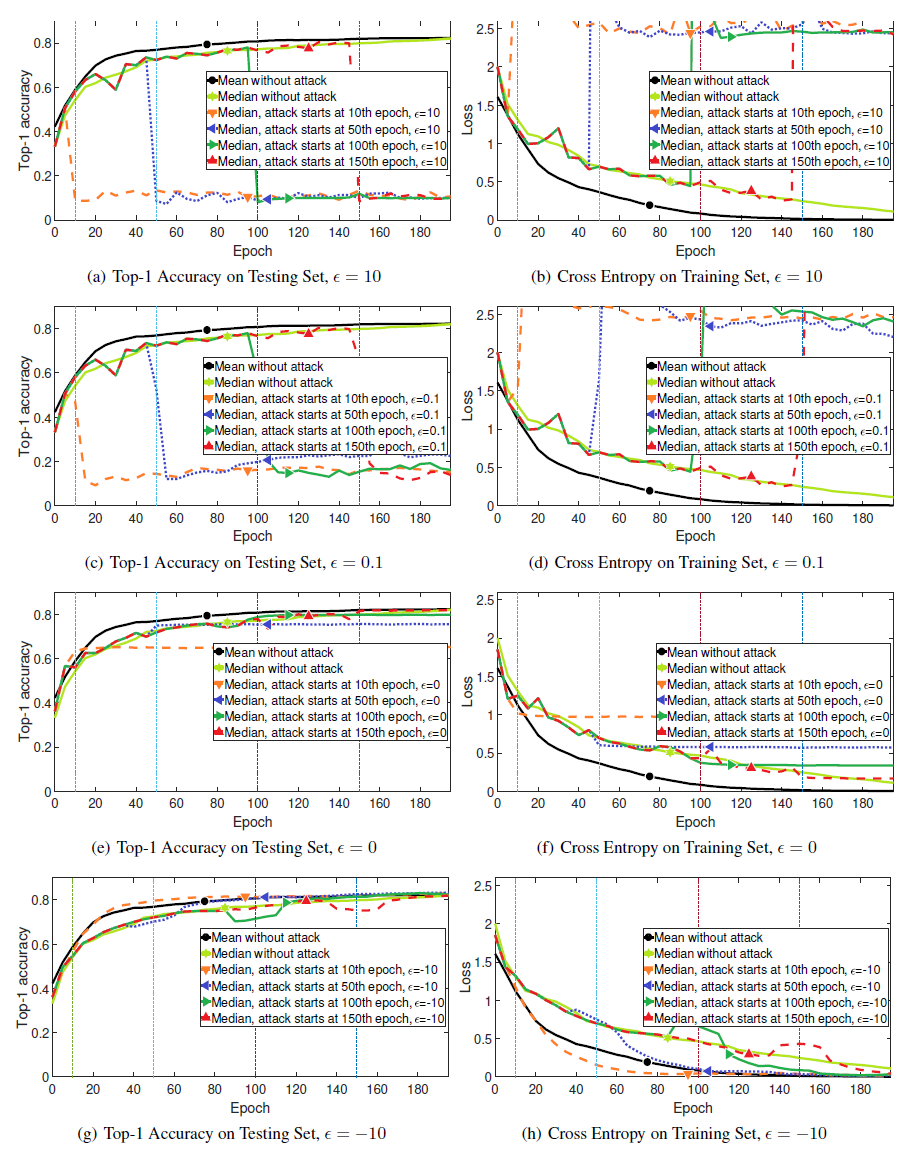
如图 3 和图 4 所示,使用无攻击的平均值 (Mean Without attack)、Median(Median Without attack) 和 Krum(Krum Without attack)作为基线标准。在不同的时期发动攻击,这样 SGD 可以先进行热身并取得一些进展。由图 3,当ε>0,Median 失败。当ε<0,Median 成功抵御了攻击。由图 4,当ε>0 但是取值非常小时,Krum 失败。当ε足够大时,Krum 成功抵御了攻击。
本文是来自 University of Illinois at Urbana-Champaign 的同一组研究人员发表在 ICML 2019 中的一篇文章。对于分布式机器学习的容错问题,许多工作都设定了很强的假设前提,例如,假设整个分布式环境中只有不超过 50% 的计算节点是存在问题的故障计算节点,其它绝大部分计算节点都是无故障 / 非攻击计算节点(nonfaulty nodes)。本文提出一种容错方法 Zeno,将故障模型(Failure model)扩展到分布式网络中存在至少一个无故障 / 非攻击计算节点的情况。
本文关注的也是 SGD 问题,在每次 SGD 迭代中,计算节点从服务器中提取最新的模型,利用局部采样的训练数据计算梯度估计,然后将梯度估计值推送到服务器。服务器聚合梯度估计值并根据聚合梯度值更新模型。本文方法将分布式环境中的每个候选梯度估计值都看做是由可疑的恶意故障节点发送的,使用随机零阶专家(a stochastic zero-order oracle)来确定各个计算节点的分数。分数排名表征计算节点在迭代中的可信度。然后,取分数最高的几个候选计算节点的平均数,从而使得我们能够容忍大量不正确的梯度。作者表示,本文是第一个从理论和实证上研究分布式环境中大多数计算节点都是故障计算节点的案例。
作者用 m 个计算节点分布式工作的方式解决这个优化问题。在每次迭代中,每个计算节点从分布 D 中抽取 n 个独立且同分布(i.i.d.)的数据,并计算局部经验损失的梯度。服务器收集和聚合计算节点发送的梯度,并按如下方式更新模型:
其中,Aggr()表示聚合规则,t 表示更新迭代次数,i 为计算节点计数,m 为计算节点总数。其中,
作者定义故障模型(Failure Model)如下:在第 t 次迭代中,令 {(v_i)^t:i∈[m]} 为独立同分布的随机向量,满足:
将 {(v_i)^t:i∈[m]} 中的一些向量替换为错误向量。此时,正确 / 无故障的梯度为ᐁF_i(x^t),而故障计算节点的错误梯度为 *。假设 m 向量中的 q 是有错误的,其中 q<m。此外,故障计算节点的指标可以在不同的迭代中发生变化。
与现有的基于分布式环境中多数无故障 / 非攻击计算节点的方法相比,本文使用随机零阶专家(stochastic zero-order oracle)来计算每个计算节点的候选梯度估计值的分数。根据损失函数的估计下降值和幅度对每个候选梯度估计值进行排序。然后,将得分最高的几个候选项进行聚合。这个分数能够大致显示每个候选人的可信度。
随机下降分数(Stochastic Descendant Score)定义如下,令 D 中取样 f_r(x)为
其中,z_i 为独立同分布的,n_r 为 f_r()的 batch 大小,E[f_r(x)]=F(x)。对于任何更新(梯度估计值)u,基于当前参数 x、学习率γ和恒定权重ρ>0,定义其随机下降分数如下:
使用上面定义的分数,作者建立了以下基于怀疑的聚合规则。为了方便起见,作者在描述中忽略了迭代次数的索引 t。基于怀疑的聚合规则(Suspicion-based Aggregation)定义如下:假定 m 个梯度估计值中有 q 个是错误 / 故障的,x 是当前参数。根据随机的后代分数对序列进行排序:
聚合规则 Zeno 通过取前 m-b 个元素的平均值来聚合梯度估计值:
在每次迭代中,服务器收到全部候选梯度估计值后,对 z_i 进行采样。由于无法预测哪些是故障计算节点,我们不能直接获得 f_r()的准确估计。也就是说,错误 / 故障梯度与 f_r()是无关的。Zeno 聚合规则的流程见下面的 Algorithm 1。
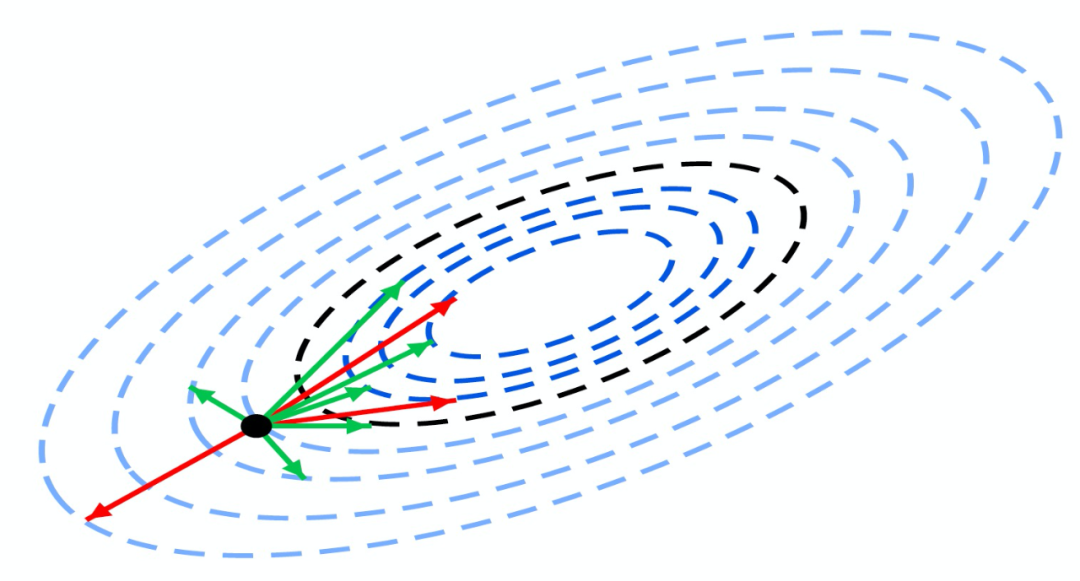
在图 5 中,作者可视化了 Zeno 的含义。图 5 示出,所有选择的候选对象(指向黑色虚线圆内的箭头)由至少一个无故障 / 非攻击候选对象限定。换言之,Zeno 使用至少一个无故障 / 非攻击候选对象来建立一个边界(黑色虚线圆),过滤掉潜在的故障候选对象。边界内的候选对象是无害的,不管他们是否真的有故障。
图 5. 损失面轮廓上的 Zeno。黑点是当前参数 x,箭头是候选更新,红色箭头表示更新不正确,绿色箭头是正确的更新。取 b=3,Zeno 过滤掉指向黑色虚线圆外的 3 个箭头。在所有更新中,这 3 个更新的 loss 函数的后代最少。边界内仍有一些不正确的更新(红色箭头)。但是,由于受到正确更新的限制,这些故障更新是无害的
作者在 CIFAR-10 图像分类基准库上进行了实验,该数据库由 50k 的训练图像和 10k 的测试图像组成。作者使用 MXNet,包括 4 个卷积层和 1 个全连接层。SGD 的 minibatch 大小为 50。在每个实验中,作者设置了 20 个计算节点。每个实验重复 10 次,取平均值。使用测试集上的 top-1 准确度和训练集上的交叉熵损失函数作为评估指标。Zeno 架构可以详见 https://github.com/xcgoner/icml2019_zeno。
实验中使用平均无故障 / 攻击作为基线标准,称为平均无故障(Mean without failures)。请注意,此方法不受 b 或 q 的影响。聚合规则包括均值(Mean)、中值(Median)、Krum。
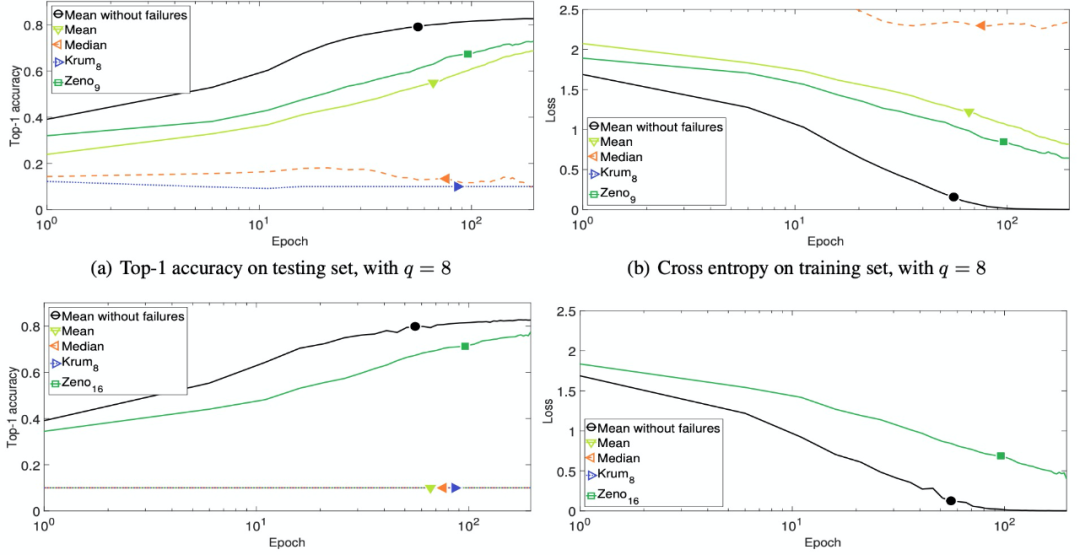
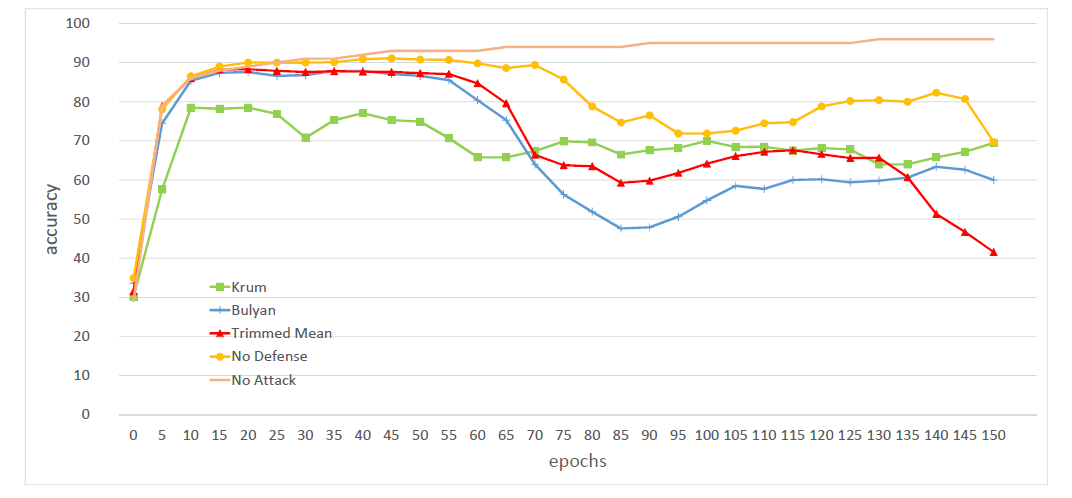
首先在没有错误的情况下测试收敛性。对于 Krum 和 Zeno,取 b=4。结果如图 6 所示。我们可以看到 Zeno 收敛的速度和 Mean 一样快。Krum 收敛稍慢,但收敛速度可以接受。
图 6. 无故障情况下 i.i.d. 训练数据的收敛性
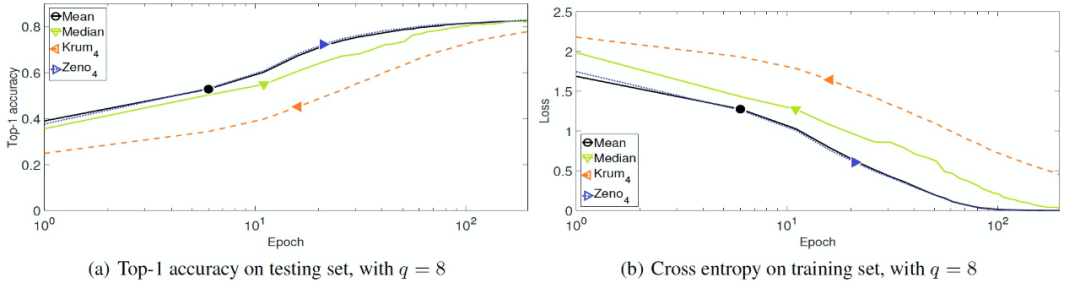
接着,作者测试了标签翻转错误(label-flipping failures)的容错性。当这种故障发生时,计算节点们根据带有 “翻转” 标签的训练数据计算梯度。此类故障 / 攻击可能由数据中毒或软件故障引起。结果如图 7 所示。正如预期的那样,Zeno 可以容忍超过一半的错误梯度。当 q=8 时,Zeno 的结果类似于 Krum。当 q=12 时,Zeno 的性能比基线好得多。当存在错误梯度时,Zeno 收敛速度较慢,但仍比基线具有更好的收敛速度。
图 7. label-flipping failures 情况下 i.i.d. 训练数据的收敛性
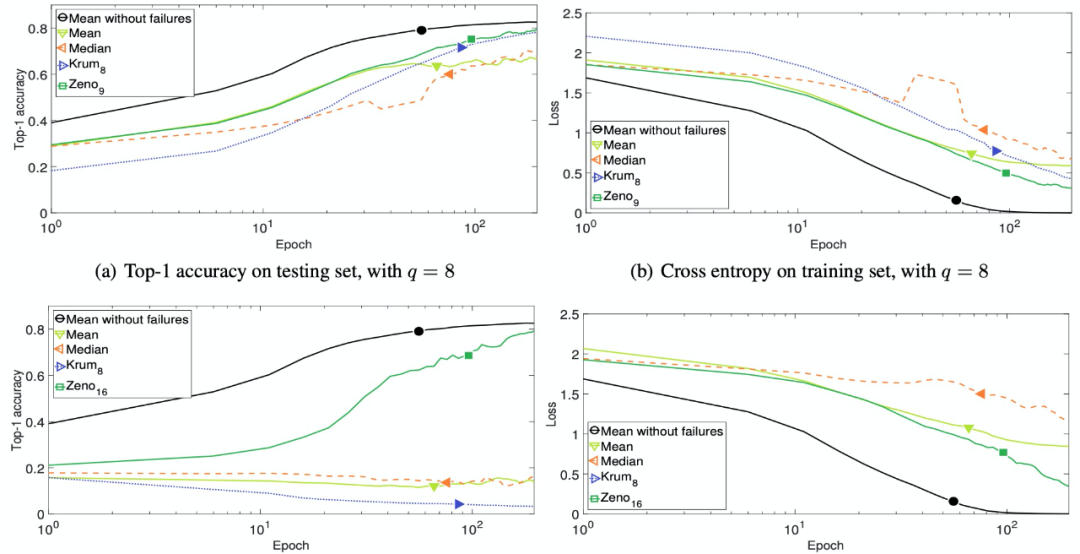
然后,作者测试了一种更严重故障的容错性。在这种情况下,控制浮点数符号的位被翻转(Bit-flipping Failure)。这一类问题可能是由某些硬件故障造成的。错误的计算节点将负梯度而不是真梯度推送到服务器。更糟糕的是,可能将一个错误的梯度复制到另一个错误的梯度并进行覆盖,这意味着所有的错误梯度具有相同的梯度值。结果如图 8 所示。Zeno 可以容忍超过一半的错误梯度。当 q=8 时,均值聚合规则的表现良好。当 q=12 时,Zeno 是唯一能够避免灾难性发散的策略。Zeno 收敛速度较慢,但仍比基线方法收敛得更好。
图 8. Bit-flipping Failure 情况下 i.i.d. 训练数据的收敛性
由上述实验结果,作者进行了一些讨论。当 q=8 时,Mean 的性能较优,但实际上 Mean 并不是一种容错机制。作者分析,可能的原因是标签翻转和位翻转错误都不会改变梯度的大小。当故障梯度数量 q 小于一半时,故障梯度可能被非故障梯度抵消。然而,当量值增大时,Mean 将失效。总的来说,作者发现 Zeno 比目前的方法更健壮。当故障计算节点占主导地位时,Zeno 是所有实验中唯一能够收敛的聚合规则。当无故障 / 非攻击计算节点占主导地位时,Mean 机制的效果也不错,且计算代价很小。
另一个有趣的观察是,尽管 Krum 是一种较为先进的算法,但在本文实验设计的错误情况下,它的性能并不如预期的好。作者分析,这是由于 Krum 基于假设 cσ<||g||,c 为常量,σ为梯度的最大方差,g 为梯度。当 SGD 收敛到一个关键点时,||g||→0。因此,如果方差很大,则无法保证满足这种假设。而且,SGD 收敛性越好,满足这种假设的可能性就越小。
本文为 NeurIPS 2019 中的一篇文章[4]。对于分布式学习的拜占庭问题,攻击模型和防御措施一般都假设恶意计算节点是:(a)无所不知的(知道所有其他计算节点的数据),(b)会导致参数发生很大的变化。但是,作者在这篇文章中证明了这个假设是不正确的:对少数计算节点的许多参数进行有针对性的小的改变也能够击败所有现有的防御,干扰或获得对训练过程的控制。
根据攻击目标的不同,我们可以将攻击大致分为两类,即非定向攻击(Untargeted Attacks)和定向攻击(Targeted Attacks)。非定向攻击的目标是破坏模型,使其无法在主要任务中聚合并达到最佳性能。在定向攻击(通常被称为后门攻击(Backdoor Attacks))中,攻击目标是令模型在主要任务中保持良好的整体性能的同时在某些特定的子任务中表现出较差的性能。后门可以是单个样本,例如错误地将特定的人分类为另一个人,也可以是一类样本,例如设置图像中的一类特定像素模式进而导致对其错误分类。
现有针对拜占庭问题的防御措施包括 Krum、Bulyan、Trimmed mean 等聚合规则,同时也可以采取 No defense 无防御的措施。
-
修整均值(Trimmed mean):使用修正均值进行聚合。具体地,对于第 j 个参数,服务器对 m 个计算节点的第 j 个参数进行排序。删除其中最大和最小的β个参数,计算其余 m-2β个参数的平均值作为模型的第 j 个参数。
-
Krum:寻找一个诚实的计算节点,将该计算节点的数据作为下一轮的选择而抛弃其他计算节点的数据。而所选计算节点是参数最接近其他 n-m-2 个计算节点的计算节点。
-
Bulyan:本质上是 Krum 和修整均值的变体结合。Bulyan 首先迭代应用 Krum 来选择θ(θ≤m-2c)个计算节点数据。然后,Bulyan 使用修整均值的变体汇总θ个计算节点数据。Bulyan 在每次迭代中多次执行 Krum,并且 Krum 计算计算节点数据之间的成对距离。
-
No Defense 不使用任何抵御方法,直接平均所有计算节点的数据。
在经典的拜占庭攻击问题中,一般会假设攻击者最终选择的是远离均值的参数,例如与梯度方向相反的参数。作者表示,本文攻击表明,通过不断地对许多参数进行一些很小的改变,攻击者仍然可能干扰模型收敛或使系统后门。此外,这些防御措施声称可以防御无所不知的攻击者,即知道所有节点的数据。作者表明,由于数据是正态分布的,攻击者控制计算节点中有代表性的部分后,仅使用故障节点中的数据就可以估计到整个数据分布的平均值和标准差,并相应地操纵结果。因此,仅通过控制故障节点就能估计到整个分布式系统中的数据属性,通过这一观察结果使得本文攻击可以应用于非全知攻击者。
如上所述,分布式学习领域的防御策略研究假设所有计算节点的模型参数是 i.i.d. 的,因此可以用正态分布表示。遵循这个假设,在本文其余部分中,作者希望在不被注意的情况下最大化分布式学习模型的 “单位” 就是标准差(standard deviation:σ)。
3.2.1 扰动范围(Perturbation Range)
采用 Trimmed Mean 聚合规则的防御措施独立计算每个参数,因此可以将聚合结果看作是一个一维数组,其中每个条目都是由不同的计算节点发来的值。显然,如果我们将恶意值设置得与平均值差距过大,就很容易利用防御措施丢弃恶意值。因此,作者致力于找到一个范围,在这个范围内,我们可以偏离平均值而不被发现。由于正态分布是对称的,所以相同的值 z^max 将设置平均值周围适用变化的上下限。
攻击者可以在不被检测到的情况下应用的最大更改是什么?为了改变 Trimmed Mean 产生的值,攻击者应该控制中间值。首先,确定需要被 “诱惑” 的无故障计算节点的最小数量 s ,从而满足 “大多数计算节点” 的计算要求。然后,攻击者将使用正态分布的属性,特别是累积标准正态函数(Cumulative Standard Normal Function)φ(z),查找值 z,以便无故障计算节点发送的结果与平均值差距较大。
3.2.2 克服 Krum 和 Bulyan 防御
Krum 输出只有一个被选中的计算节点,即,最终只使用该计算节点的参数而丢弃掉其他所有计算节点的参数。其所依赖的假设是:存在这样一个计算节点,其每个维度的所有参数都接近期望平均值。然而,实践中当参数为高维参数时,即使是最优秀的计算节点也会存在一些远离平均值的参数。为了解决这一问题,我们可以生成一组参数,这些参数与每个参数的平均值相差都很小。这些微小的变化将减少 Krum 计算的欧氏距离,从而选中恶意集合。
当攻击 Krum 而不是 Trimmed Mean 时,只需要几个故障计算节点来估计μ_j 和 σ_j,并且只有一个计算节点需要将恶意参数上传到服务器,因为 Krum 最终只会选择来自单个计算节点的参数集。
Bulyan 是 Krum 和 TrimmedMean 的结合体,那么是不是我们也可以绕过 Bulyan 的防御呢?Bulyan 声称只保护了 25% 的异常计算节点,而不是像 Krum 和 Mean 那样的 50%。为 m=25% 导出的 z^max 似乎不够,但应注意,上面计算的扰动范围是 TrimmedMean 的可能输入,其中 m 可以达到在 Bulyan 第二阶段聚集的 SelectionSet 中 50% 的计算节点。事实上,我们的方法也能有效地对付 Bulyan 攻击。
以阻止收敛为目的,攻击者将使用最大值 z 来规避防御措施。攻击流程详见 Algorithm3。
在 3.2.1 所描述的方法中,我们为每个参数 j 确定了一个范围,在这个范围内攻击者可以扰动参数而不被发现。为了阻止收敛,攻击者将这个范围内的变化最大化。对于后门攻击来说,攻击者的目的是在这个范围内找到能够生成后门所需标签的参数集,同时对无故障的真实输入的功能影响最小。本文通过加权参数为α的损失函数实现:
其中,l_backdoor 与常规损失函数相同,但在后门上训练的是攻击者的目标,而不是真实的目标。l_Δ的作用是令新参数与原参数接近。如果α过大,新参数会与原参数有很大的差异,从而被防御机制所抛弃。因此,攻击者应该使用最小的α来成功引入模型中的后门。此外,攻击者可以利用每个参数的σ_j 而不直接用任何 L^p 距离来表示 l_Δ,将参数之间的差值进行归一化处理,以加快学习速度:
本文在 MNIST 和 CIFAR10 两个数据集中进行实验。对于 MNIST 数据集,作者使用包括 1 个隐藏层的多层感知机,输入为 784 维,使用 ReLU 激活的隐藏层 100 维,以及使用交叉熵目标函数训练得到的 10 维 softmax 输出。对于 CIFAR10 数据集,作者使用一个 7 层 CNN,具体如下:输入大小为 3072,内核大小为 3 x 3 的卷积层,大小为 3x3 的 max-pooling,内核大小为 4x4 的卷积层,大小为 4x4 的 max-pooling,大小分别为 384 和 192 的两个全连接层。输出层大小为 10。
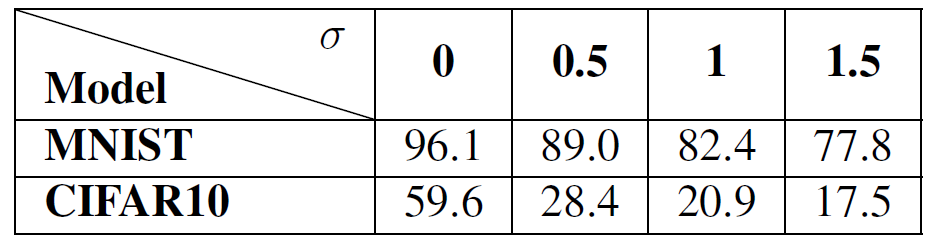
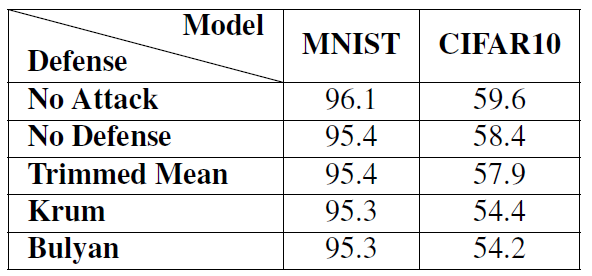
针对收敛性的攻击,为了找出能够对网络产生影响所需要达到的标准差值,作者在分布式学习环境中用 MNIST 和 CIFAR10 数据集对模型进行了四次训练,每次都按 z=0(不改变)、0.5、1 和 1.5 标准差改变参数。在服务器端对所有的计算节点(m = n)进行了无防御的所有参数的训练。如表 1 所示,当参数与实际平均值相差 1.5σ或 1σ,就可以大幅度降低实验结果从而对网络产生影响。此外,表 1 中的实验结果还显示,由于任务性质不同,降低 CIFAR10 的准确度要比 MNIST 简单得多。MNIST 任务简单,所需的样本较少,不同计算节点能够很快地就正确的梯度方向达成一致,从而限制了可以执行的改变。而对于难度较大的 CIFAR10 分类任务,计算节点之间的分歧会比较大,这就给恶意攻击者提供了机会,很容易被恶意攻击者所利用。
表 1. 改变所有计算节点的所有参数时,在 MNIST 和 CIFAR10 数据集上模型的最大准确度
作者针对不同的防御措施进行了攻击,并检查了不同防御措施在这些模型中的恢复能力。图 9 给出了当参数变化为 1.5σ时,不同防御措施的 MNIST 分类模型的准确度结果。其中,分布式环境中有超过 m=12 个恶意计算节点,几乎达到了 24% 的比例。作者还绘制了不施加攻击时的结果,以便可以清楚地看到攻击的效果。可以看出,攻击在所有情况下都有效。Krum 的防御效果最差,因为即使只存在 24% 的故障计算节点,最终还是选中了我们的故障参数集。Bulyan 比 Trimmed Mean 受到的影响更大,这是因为即使故障计算节点的比例是 24%,它最终也可能达到 48% 的效果,而这个比例正是 Trimmed Mean 在 Bulyan 第二阶段使用的比例。Trimmed Mean 比前两个防御措施的性能要好,作者分析,这可能是因为故障参数被根据所选择的非故障计算节点的参数集计算得到的平均值稀释了。
图 9. MNIST 上的模型准确度,m=24%,z=1.5
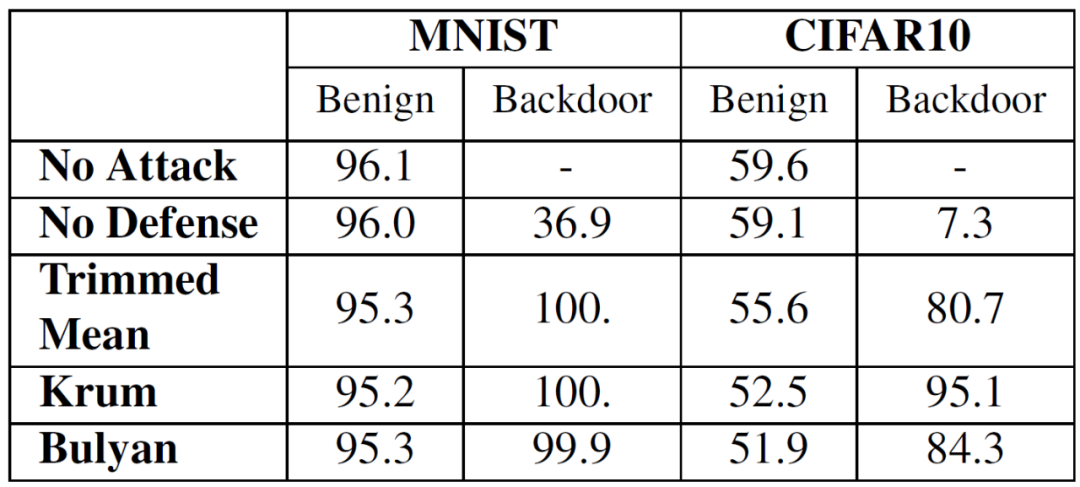
在后门攻击实验中,令 n=51,m=12 (24%)。由于攻击者希望不会影响无故障的真实输入的收敛性,因此选择了较小的 α 和 z(均为 0.2)。在每一轮之后,攻击者用后门对网络进行 5 轮训练。
对于后门样本(Sample Backdooring)任务,每次从每个训练集(MNIST 和 CIFAR10)的前 3 个图像中选择一个,并将它们所需的后门目标设置为(y+1) mod |Y|,其中,y 是原始标签, |Y | 是类别数目。结果见表 2。在整个过程中,分布式计算网络在 95% 以上的时间内为后门样本生成恶意目标,包括达到最大整体准确度的轮次。可以看出,对于类似 MNIST 的简单任务,模型成功地融入了后门,总体准确度下降还不到 1%。而对于 CIFAR10 来说,收敛非常困难,且准确度下降了 9%。
表 2. 后门样本结果。MNIST 和 CIFAR10 模型在后门样本下的最大准确度
对于后门模式(Pattern Backdooring)攻击,攻击者从每轮的数据库中随机抽取 1000 个图像,并将图像左上位置 5x5 的像素设置为最大值。所有这些样本都以 target=0 进行训练。表 3 给出了实验结果。与后门样本攻击的结果类似,在 MNIST 数据集上,模型完美地学习了后门模式,对所有防御措施的良性输入的准确度影响都非常小。对于没有防御情况,攻击再次被许多非故障计算节点的平均值所稀释。在 CIFAR10 数据集上,模型的准确度比后门样本攻击的情况要差,准确度下降了 7%(Trimmed Mean)、12%(Krum)和 15%(Bulyan)。
表 3. 后门模式结果。具有后门模式攻击的 MNIST 和 CIFAR10 模型的最大准确度
4、使用 SGD 和基于 CGE 的拜占庭容错分布式机器学习
本文是美国乔治城大学 Nirupam Gupta 教授在 2020 年发表的一篇报告,讨论的是同质(Homogeneous)多 agent 分布式学习中的拜占庭容错问题。在这个问题中,每个 agent 都会对独立同分布的数据进行采样,agent 的目标是计算出一个数学模型,这个模型最适合于所有 agent 采样的数据。当某些 agent 是拜占庭攻击者时,这些 agent 并不会遵循预先确定的学习算法,同时他们会共享异常信息,以阻止真实 / 非异常的 agent 去学习正确的模型。
本文提出了一种分布式随机梯度下降(Distributed stochastic gradient descent,D-SGD)方法的容错机制,这是一种标准的分布式监督学习算法。本文的容错机制依赖于基于范数的梯度滤波器,称为比较梯度消除(Comparative gradient limination,CGE),旨在通过限制异常 agent 的 Euclidean norms 来减轻异常随机梯度的有害影响。
在 D-SGD 中,服务器保持对最佳学习参数的估计,该参数在算法的每次迭代中更新。初始参数为ω^0,由服务器从 R^d 中任意选择。在每次迭代 t 中,服务器利用下述步骤 1 和步骤 2 计算ω^(t+1):
步骤 1:服务器从 agent 获得其ω^t 轮本地计算的平均损失函数 Q(ω)的随机梯度。其中,拜占庭异常 agent 可能会发送随机梯度的任意向量。Q(ω)的计算方法如下式:
其中,z 表示数据,l()为实(real-valued)损失函数。服务器从 agent i 接收的梯度表示为(g_i)^t。如果没有从某个 agent i 接收到梯度,则认定 agent i 一定是异常的(因为系统被假定为同步的)。此时,将缺失的梯度(g_i)^t 赋值为 0。
为了计算期望损失函数 Q(ω)的随机梯度,在每次迭代 t 中,agent i 选择 k 个数据。每个数据都从概率分布 D 中独立地和相同地取样。损失函数相对于ω的梯度的平均值是真梯度ᐁQ(ω)的无偏噪声估计,可用作 Q(ω)的随机梯度。对于每个非异常的 agent i 则有:
(g_i)^t 的方差与 k 成反比,即如果 agent 在每次迭代中采样更多的数据,则能够提高随机梯度估计的准确度。
步骤 2:为了减轻异常随机梯度的不利影响,使用一个滤波器来 “鲁棒地” 聚合梯度用于计算ω^(t+1)。服务器消除具有最大 f 欧氏范数(Euclidean norms)的随机梯度,并使用使用剩余的 n-f 个随机梯度与 n-f 个最小欧氏范数的集合来计算ω^(t+1)。这种计算方法称为比较梯度消除(CGE)。
从 agent i_j 接收具有第 j 个最小范数的随机梯度(g_ij)^t。服务器仅使用具有最小 n-f 个范数的 n-f 个随机梯度更新其当前估计值,如下所示:
作者还对算法的收敛性能进行了数学论证,我们在这里不再详述,感兴趣的读者可以阅读原文。
作者利用 D-SGD 和不同的梯度滤波器(包括 CGE)对人工神经网络分布式学习的容错性进行了实证研究。为了评估不同梯度滤波器的容错性,使用不同的 agent 异常比例 f/n、不同的异常类型和不同大小的数据 batch k 进行了实验,用于计算非异常 agent 的随机梯度。
作者通过生成多个线程(一个用于服务器,另一个用于 agent)来模拟基于分布式服务器的系统体系结构,其中线程间通信通过消息传递接口(MPI)完成。使用 PyTorch 和 MPI4py 在 Python 中构建模拟器,并部署在 Google 云平台集群上,其中,所适用的集群有 64 个 vCPU 内核和 100GB 的内存。实验考虑了人工神经网络分布式学习对两个基准数据集的监督分类任务:MNIST 数据集和 CIFAR-10 数据集。
除了 CGE 梯度滤波器外,作者在实验中还通过四种最先进的梯度滤波器来评估容错性:几何中值(Geometric median)、几何平均中值(Geometric median of means)、坐标修剪均值(Coordinate-wise trimmed mean)和多重 KRUM(multi-KRUM)。
Geometric median (GeoMed):
对于给定的向量几何{y_1,...,y_n},其几何中值定义为:
几何中值对边缘向量的敏感度低于算术平均值。在步骤 2 中,对于几何中值方法来说,服务器计算接收到的随机梯度的几何中值,并将当前估计值更新为ω^t:
Geometric median of means (MoM):
对于 MoM 梯度过滤器,服务器将 agents 划分为从 1 到 l 的 l 个组。为简单起见,假设 agent 的总数 n 是 l 的倍数。因此,每个组都有 b=n/l 个 agent。令 agents{1,...b}属于 group 1,agents{b+1,...,2b}属于 group 2,以此类推。
在步骤 2 中,对于每个 group j,服务器计算平均随机梯度值:
服务器计算所有组的平均随机梯度的几何中值,最终更新估计值ω^t:
Coordinate-wise trimmed mean (CWTM):
给定一组实值量值{a_1,...a_n},f - 修剪平均值(f-trimmed mean) 定义为:
在 CWTM 梯度滤波器中,在每次迭代中,服务器使用向量更新其当前估计,向量的元素是所接收的随机梯度的相应元素的 f - 修剪平均值。在步骤 2 中,服务器计算梯度:
在 multi-KRUM 梯度滤波器中,每次迭代 t 服务器计算从 agent 接收到的每个随机梯度的 KRUM 分数。服务器选择 m 个最小 KRUM 分数的随机梯度并计算它们的平均值,更新估计值ω^t:
拜占庭异常 agent 可以表现出任意的异常。作者对 5 种不同类型的异常进行了实验。在前三种异常类型中,异常 agent 被假定为拜占庭式的和全知的。在后两种异常类型中,异常 agent 被假定为无意的。
-
梯度反转异常(Gradient-reverse faults):在这种异常类型中,每个异常 agent 将其正确的随机梯度进行反转处理,并将反转的梯度缩放 100 倍。
-
坐标异常(Coordinate-wise faults):在这种异常类型中,每个异常 agent 发送一个向量,其元素等于由非异常 agent 计算的随机梯度的第 f 个最小元素。
-
范数混淆异常(Norm-confusing faults):在这种异常类型中,每个异常 agent 反转其正确的随机梯度,并进行缩放处理,使其范数等于所有非异常 agent 计算的随机梯度中的第(f+1)大范数。
-
标签翻转异常(Label-flipping faults):在这种异常类型中,异常 agent 由于其采样数据的输出分类标签异常而发送不正确的随机梯度。
-
随机异常(Random faults):在这种异常类型中,每个异常 agent 都会在每次迭代中向服务器发送随机选择的向量。
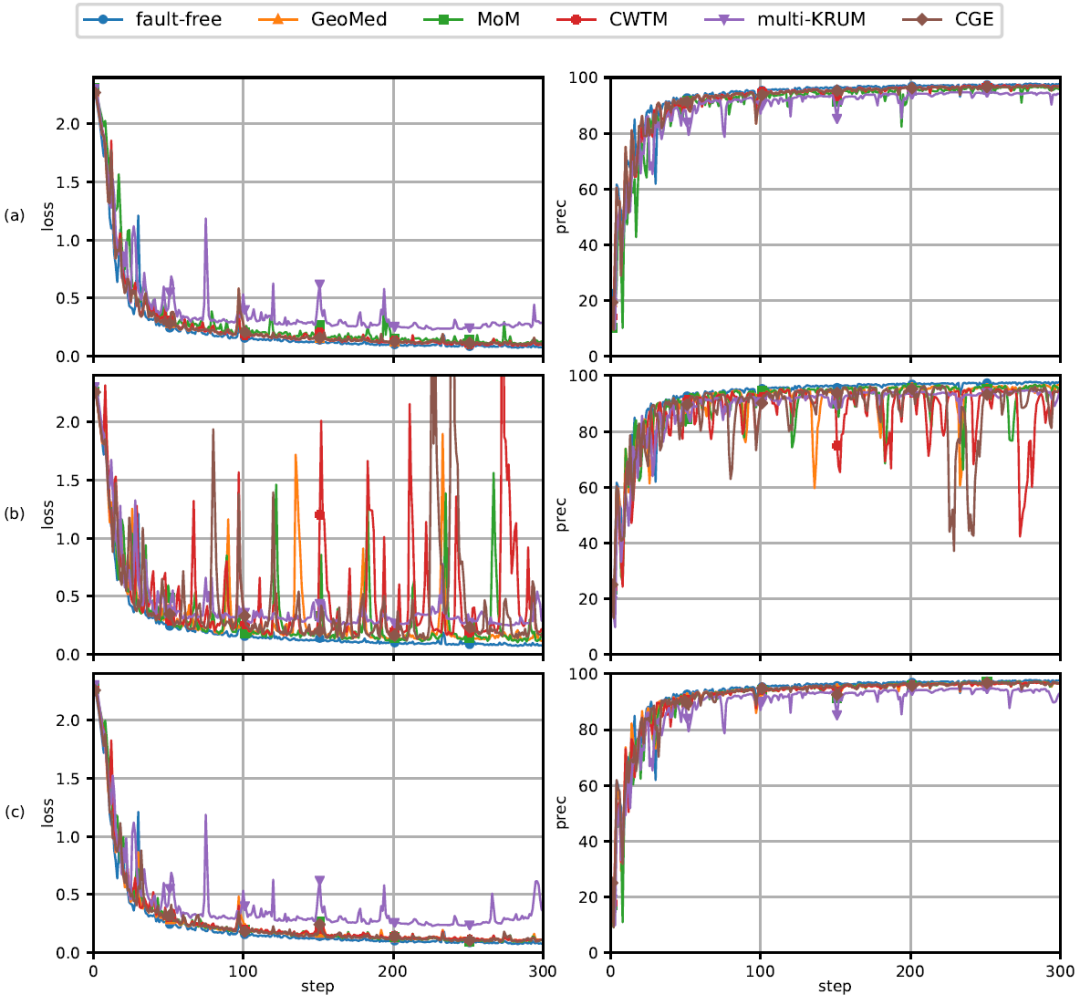
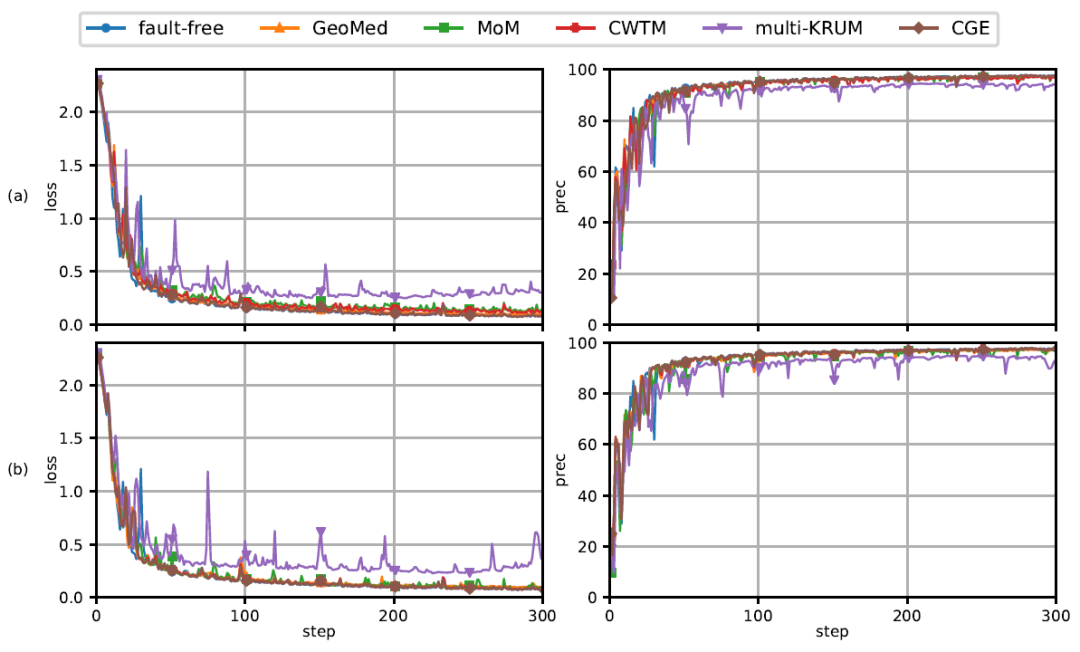
MNIST 是一个手写数字图像分类数据集,由 60000 个训练样本和 10000 个测试样本组成。作者使用 LeNet 卷积神经网络完成包含 431080 个学习参数的分类任务。d=431080。图 11 中的曲线图显示了不同拜占庭式异常的学习曲线。如图 11 所示,由于异常 agent 的比例很小,D-SGD 方法在所有五个梯度滤波器的情况下都收敛。此外,与其他梯度滤波器不同,CGE 梯度滤波器的容错性对于所有不同类型的异常都是一致的。在图 11(b)所示的坐标异常的情况下,所有梯度滤波器的学习曲线都非常不稳定。图 12 给出了另外两种异常的实验结果曲线。
图 11. 基于 D-SGD 方法和不同梯度滤波器的 MNIST 神经网络分布式学习。每行对应不同的异常类型:(a)梯度反转,(b)坐标,和(c)范数混淆。第一列绘制训练损失,第二列绘制测试准确度与迭代次数或步骤次数的关系
图 12. 基于 D-SGD 方法和不同梯度滤波器的基于 MNIST 数据集的神经网络分布式学习。每行对应不同类型的异常:(a)标签翻转和(b)随机。两列分别绘制了训练损失和测试准确度
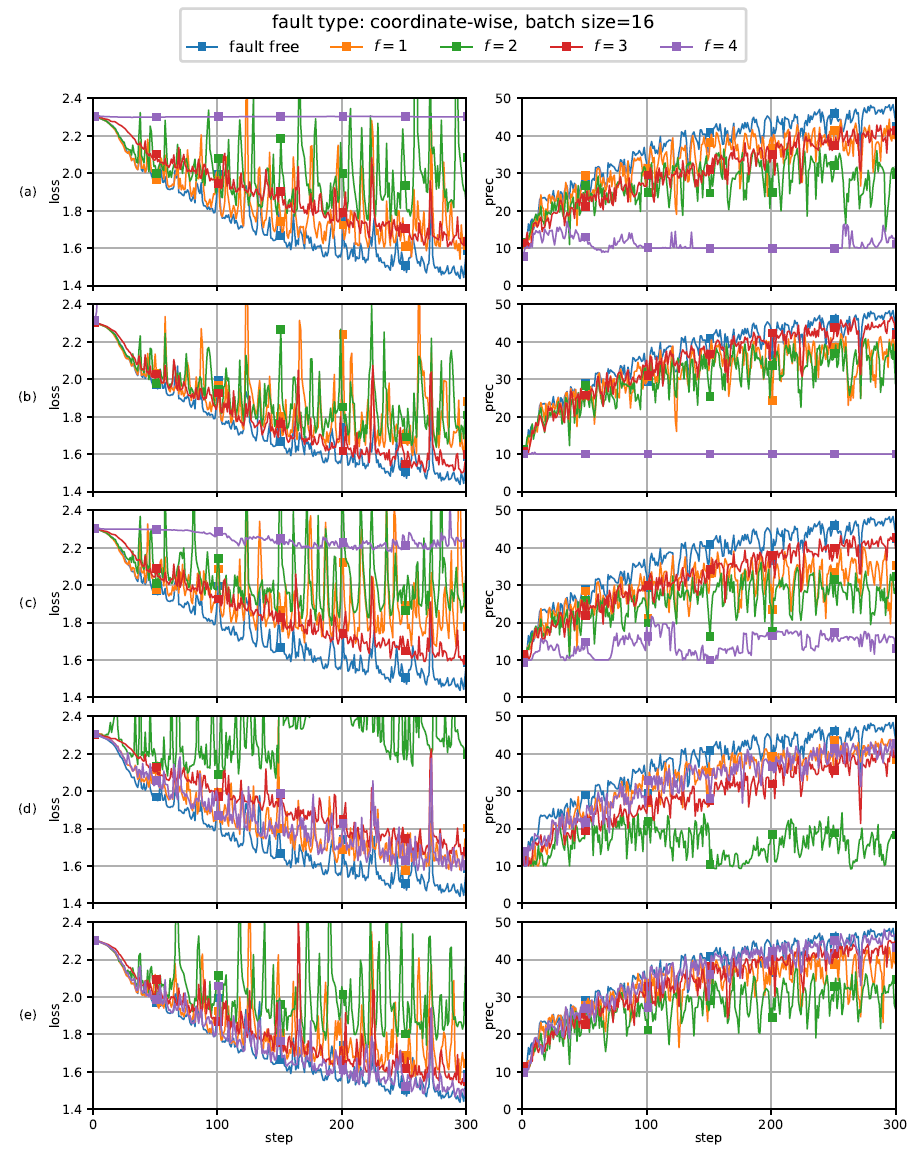
CIFAR-10 也是一个图像分类数据集,由 60000 个小的彩色图像组成。这些图像分为 10 个类别,每个类别中的图像数量相等。实验结果见图 13,主要针对的是坐标异常。其中,不同的行对应于不同的梯度滤波器:(a)几何中值,(b)均值中值,(c)坐标修剪均值,(d)m=2 的 multi-KRUM,(e)CGE
图 13. 基于 D-SGD 方法和不同梯度滤波器的 CIFAR-10 神经网络分布式学习
现代人工智能、机器学习方法和模型离不开数据。随着数据的不断增长,单台设备越来越无法满足数据集中存储的需要。同时,数据产生的来源越来越多,大量数据是分散存储在不同设备中的,将多源数据聚合存放在一起也是不现实的。在这样的背景下,分布式学习问题引起了研究人员以及工程技术人员的广泛关注。分布式学习通过聚合多台机器中的数据、模型、参数等实现协同学习一个强大而有效的模型。不过,由于拜占庭节点的问题,传统分布式学习中假设全部节点都是真实可靠以及正确的这一点是不成立的。
本文探讨了基于 SGD 方法的分布式机器学习中的拜占庭问题。这四篇文章分别从拜占庭攻击、拜占庭防御等不同的角度进行了分析。文章中给出的实验结果能够证明在实验条件下这些方法的有效性。不过,这几篇文章都是假设各个节点中数据是独立同分布的(i.i.d.),在实际应用场景中这显然是很难保证的,而非独立同分布数据中的拜占庭问题的攻击和抵御问题显然更加复杂。如何进一步改进方法或框架,使分布式机器学习更加具有实用性,有待更深入的研究。
[1] Li, M., Andersen, D. G., Park, J. W., Smola, A. J., Ahmed, A., Josifovski, V., Long, J., Shekita, E. J., and Su, B.-Y.
(2014a). Scaling distributed machine learning with the parameter server. In OSDI, volume 14, pages 583–598.
[2] Xie, C., Koyejo, S., and Gupta, I. Fall of empires: Breaking byzantine-tolerant sgd by inner product manipulation. arXiv preprint arXiv:1903.03936, 2019.http://proceedings.mlr.press/v115/xie20a.html.
[3] Xie, C., Koyejo, S., and Gupta, I. Zeno: Distributed Stochastic Gradient Descent with Suspicion-based Fault tolerance,Proceedings of the 36th International Conference on Machine Learning, Long Beach, California, PMLR 97, 2019.http://proceedings.mlr.press/v97/xie19b.html.
[4] Moran Baruch, Gilad Baruch, Yoav Goldberg. A Little Is Enough: Circumventing Defenses For Distributed Learning. NeurIPS 2019.https://papers.nips.cc/paper/9069-a-little-is-enough-circumventing-defenses-for-distributed-learning
[5] Gupta N , Liu S , Vaidya N H . Byzantine Fault-Tolerant Distributed Machine Learning Using Stochastic Gradient Descent (SGD) and Norm-Based Comparative Gradient Elimination (CGE). 2020. https://arxiv.org/pdf/2008.04699.pdf.
本文作者为仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。


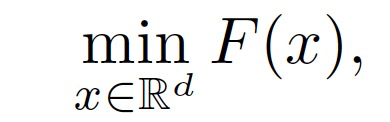
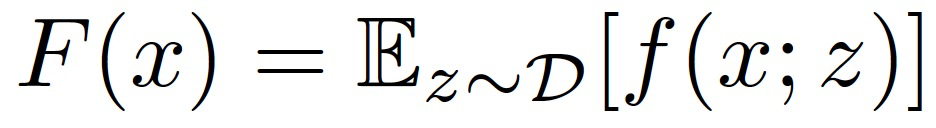
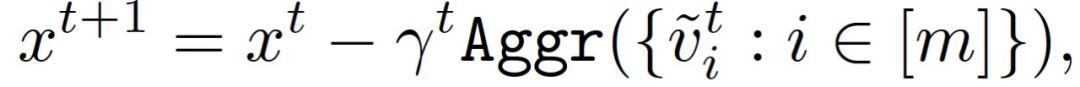
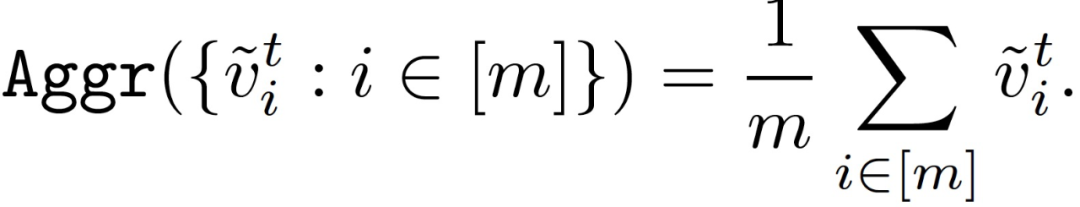
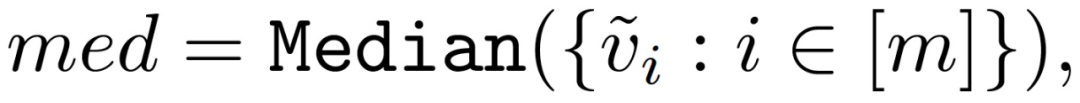
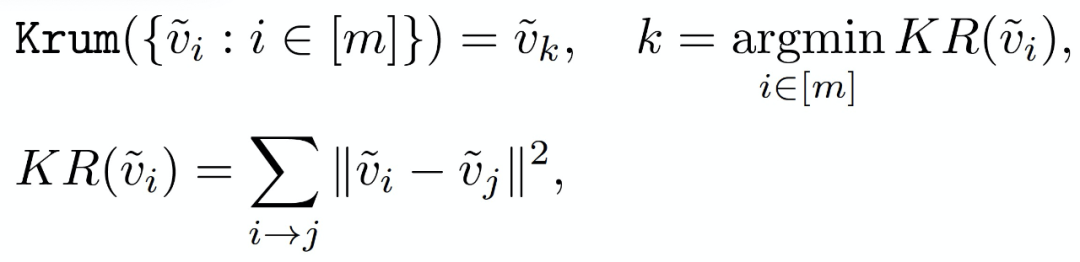
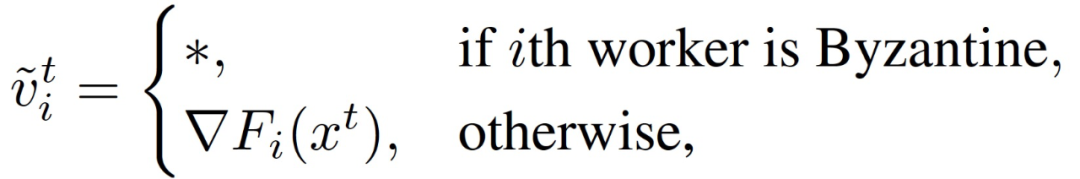
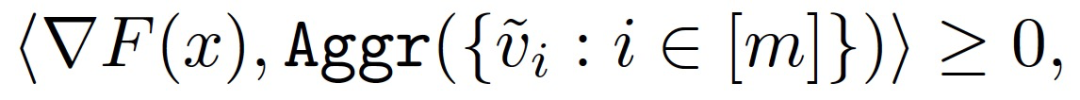
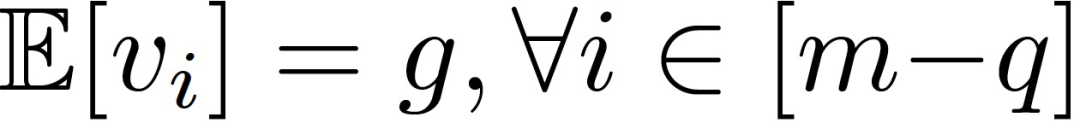
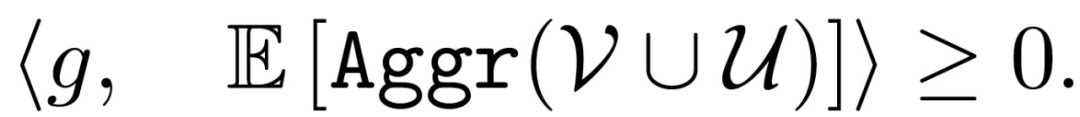
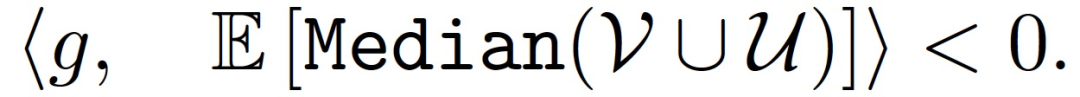
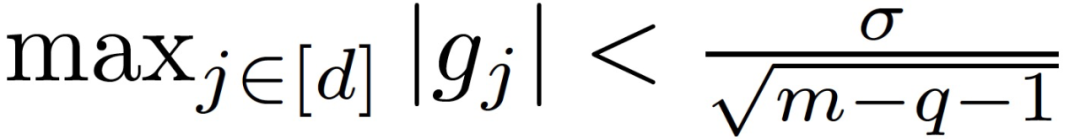
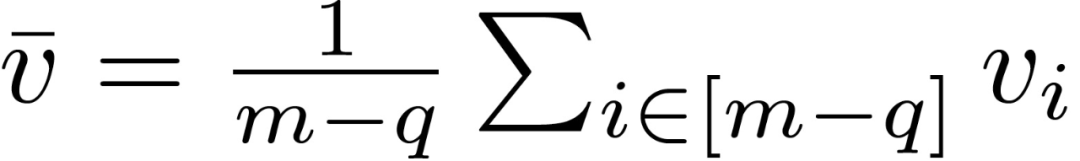
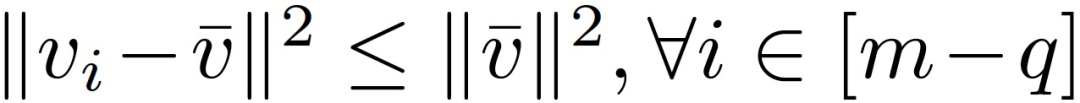
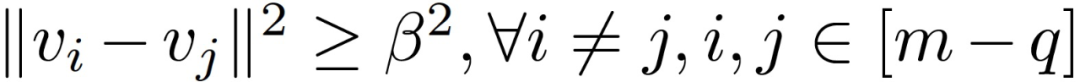
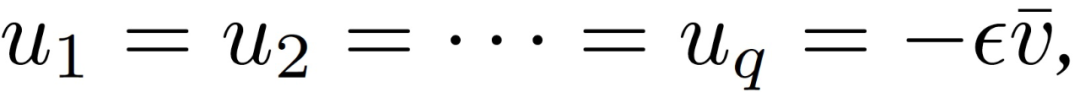
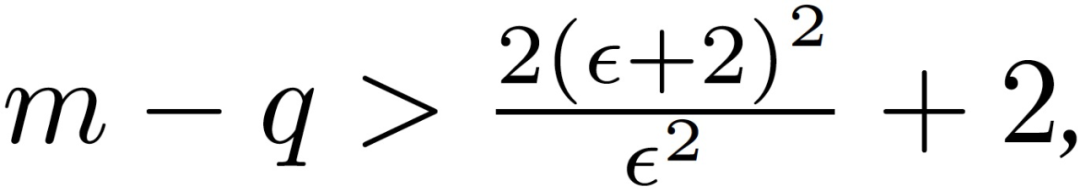
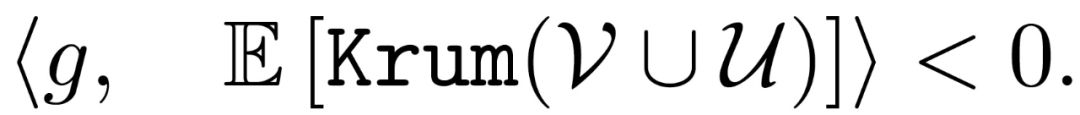
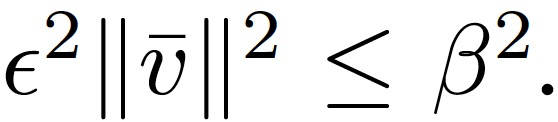
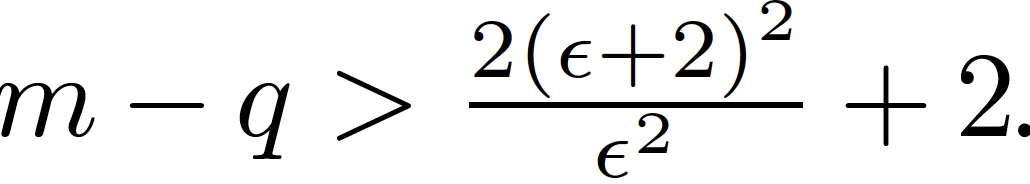
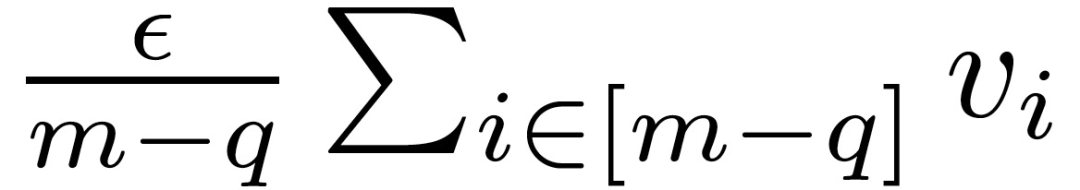

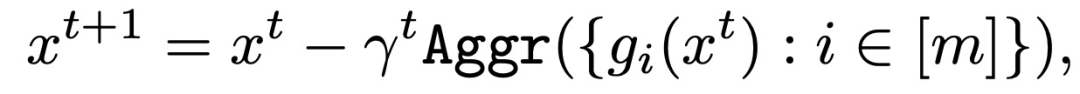
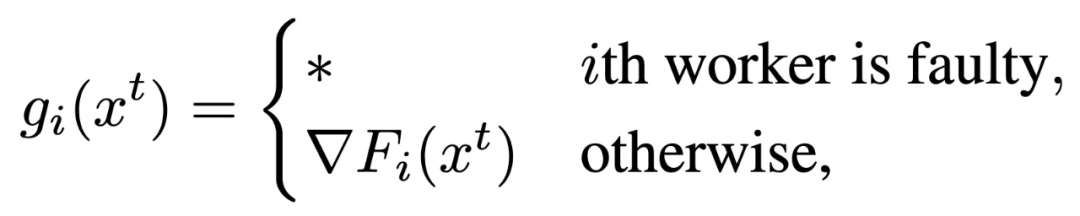
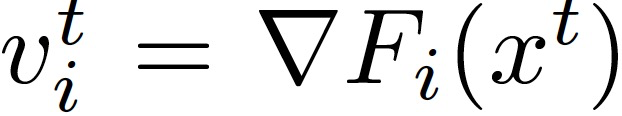
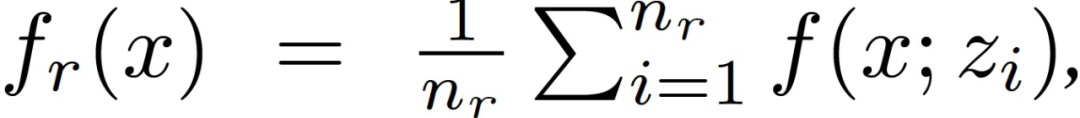
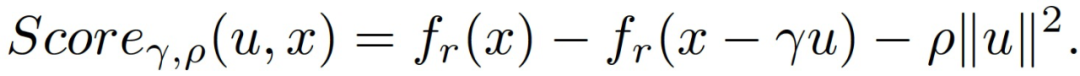
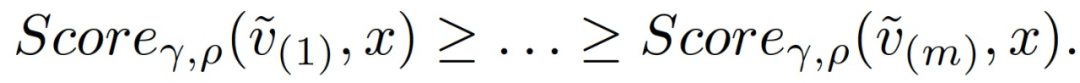
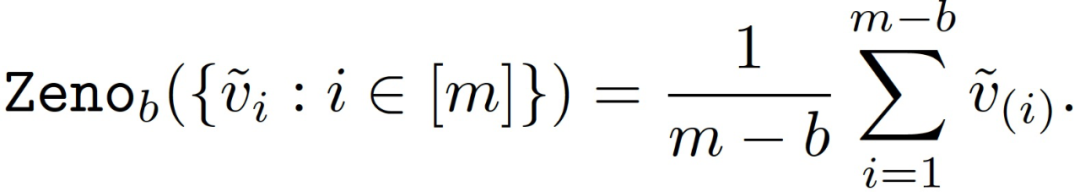




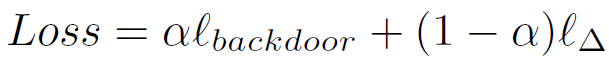
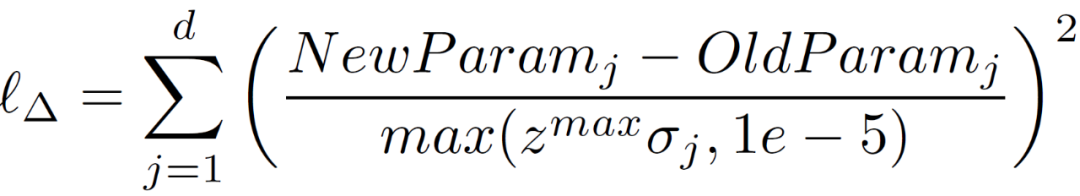


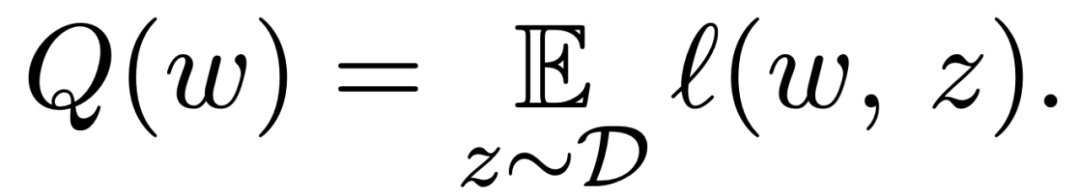
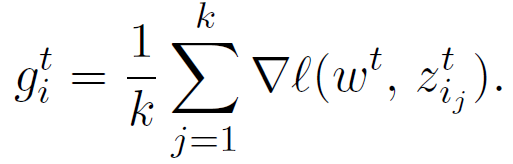
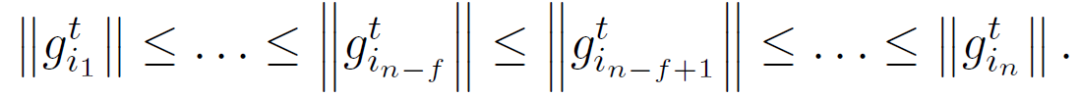
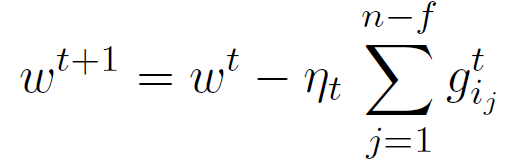
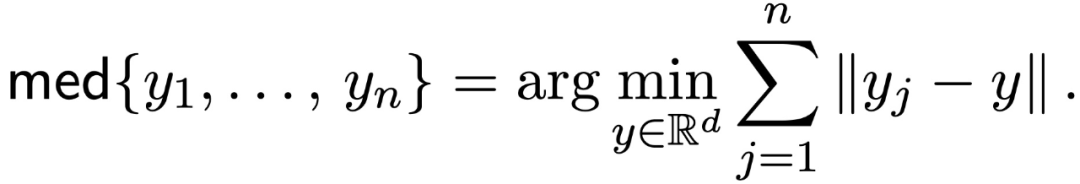
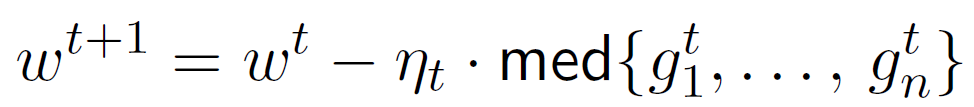
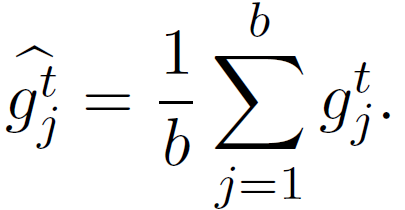
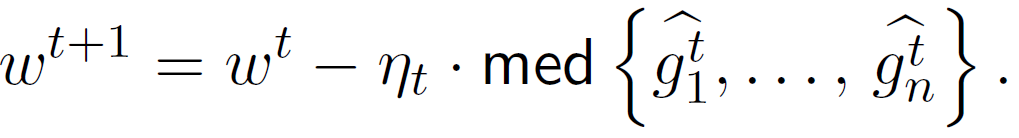
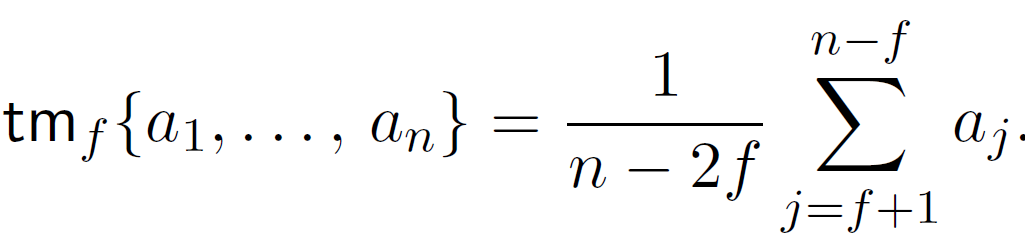
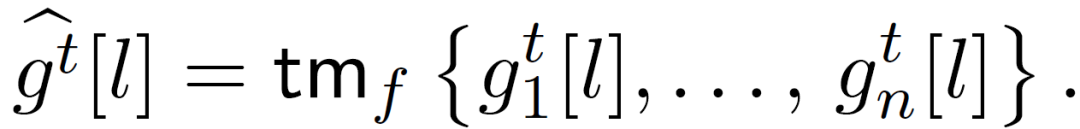
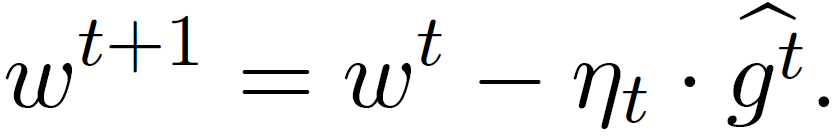
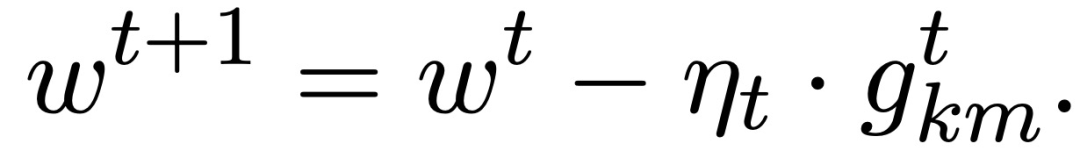

文章评论