点击上方蓝色小字,关注“涛哥聊Python”
重磅干货,第一时间送达

来源:未闻Code

之前我们提到目前网上的反检测方法几乎都是掩耳盗铃,因为模拟浏览器有几十个特征可以被检测,仅仅隐藏 webdriver 这一个值是没有任何意义的。
今天我们就来说说应该如何正确解决这个问题
我们首先给出解决方案,然后再说明这个解决方案,我是通过什么方式找到的
解决这个问题的关键,就是一个 js 文件,叫做stealth.min.js,稍后我会说明如何生成这个文件
我们需要设定,让 Selenium 或者 Pyppeteer 在打开任何页面之前,先运行这个 Js 文件
这里,我以 Selenium 为例来说明如何操作,我们编写如下代码:
import time
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
driver = Chrome('./chromedriver', options=chrome_options)
with open('/Users/kingname/test_pyppeteer/stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
driver.get('https://bot.sannysoft.com/')
time.sleep(5)
driver.save_screenshot('walkaround.png')
# 你可以保存源代码为 html 再双击打开,查看完整结果
source = driver.page_source
with open('result.html', 'w') as f:
f.write(source)
运行截图如下:
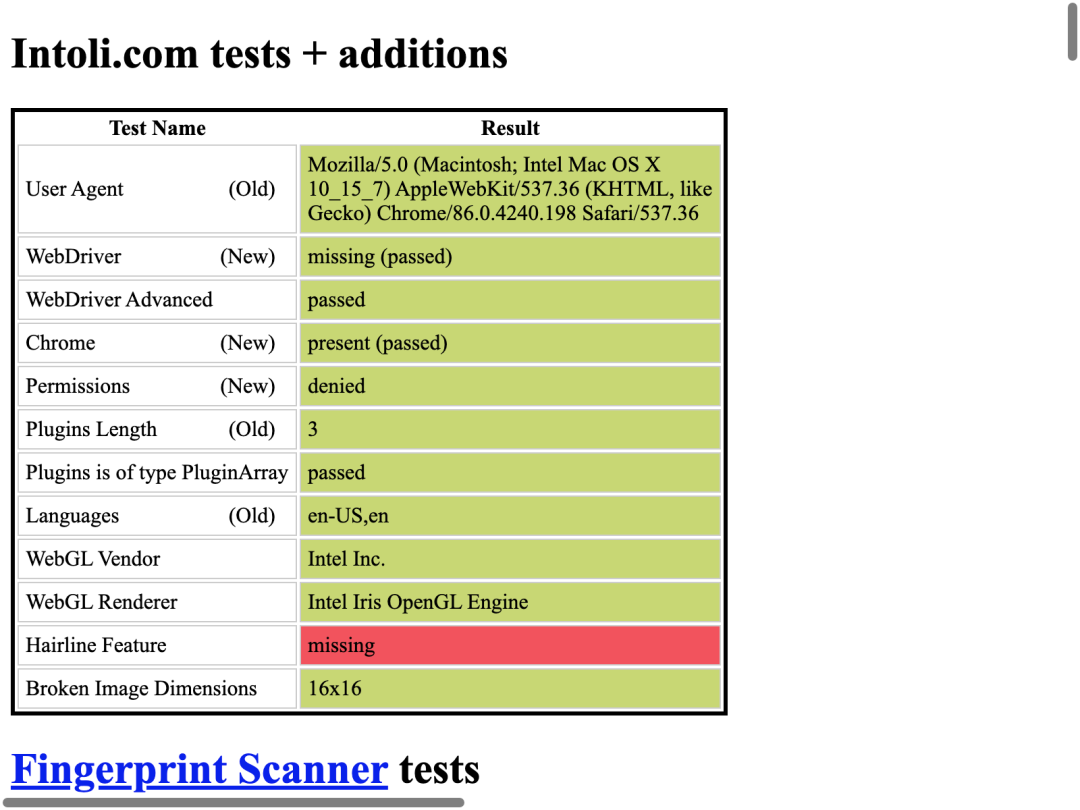
可以看到,虽然我使用的是无头模式,但是能够被识别的特征都被成功隐藏。大家还可以双击打开保存下来的 html 文件,看看是不是结果跟普通浏览器几乎一样。
如果你使用的是 Pyppeteer,那么可以根据我上面文章中给出的方法,试着加载一下这个 js 文件,看看是不是也能成功隐藏特征。
那么,这个stealth.min.js文件是怎么来的呢?这就要说到puppeteer了。我们知道,Python 版本的pyppeteer已经很久没有人维护了,但是Node.js 版本的 puppeteer持续有人维护,并且在持续更新,生态也越来越好。
有开发者给 puppeteer 写了一套插件,叫做puppeteer-extra。其中,就有一个插件叫做puppeteer-extra-plugin-stealth[1]。这个东西,就来专门用来让 puppeteer 隐藏模拟浏览器的指纹特征。
这个东西是专门给 puppeteer 用的。所以,如果你使用的是 puppeteer,那么你可以根据它的 Readme说明,直接使用。
那么,我们用 Python 的人怎么办呢?实际上也有办法。就是把其中的隐藏特征的脚本提取出来,做成一个单独的 js 文件。然后让 Selenium 或者 Pyppeteer 在打开任意网页之前,先运行一下这个 js 文件里面的内容。
puppeteer-extra-plugin-stealth的作者还写了另外一个工具,叫做extract-stealth-evasions[2]。这个东西就是用来生成stealth.min.js文件的。
如果你在国外,并且网速足够快的话。那么你根据它的 Readme,首先安装 Node.js,然后安装 Npm,接着运行如下命令:
npx extract-stealth-evasions
就会在你执行命令的文件夹下面生成一个stealth.min.js文件。然后你就可以正常使用了。
如果你在国内,那么执行这个命令的过程中,会有一个下载 Chromium 的过程,速度非常慢,虽然只有130MB,但是可能会下载好几个小时。
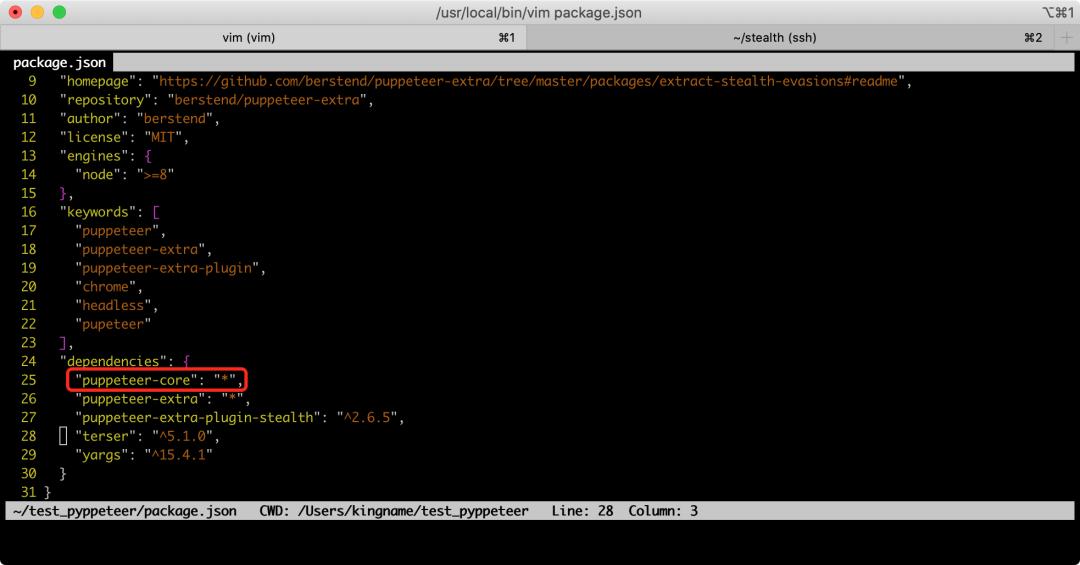
此时,你需要把它的package.json和index.js两个文件保存到本地。然后打开package.json文件,修改其中的dependencies这一项,把里面的puppeteer改成puppeteer-core,如下图所示:
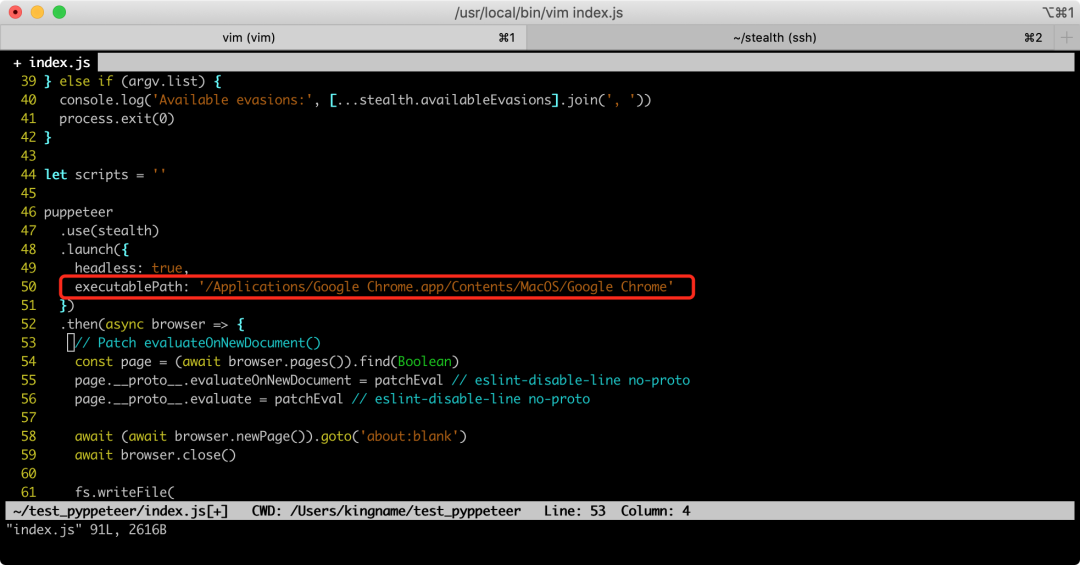
然后修改index.js,给.launch()函数增加一个参数executablePath,指向你电脑上的 Chrome 浏览器,如下图所示:
修改完成以后。首先执行yarn install安装依赖包。然后执行node index.js运行程序。1秒钟以后就会生成stealth.min.js了。
我已经将这个文件上传到公众号后台,回复关键字 stealth 即可获取!
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
·················END·················
你好,我是Sitin涛哥,非著名程序员,项目经理,现在创业中。
在公众号和视频号「涛哥聊Python」分享我的升级打怪经验!
很开心能够遇到你,欢迎添加我的微信 pengtaoshow ,备注来意,一起进步。


文章评论