
1 什么是低代码/无代码开发?业界对于低代码/无代码开发是否存在其他不同的理解?
2 低代码开发和无代码开发之间的区别是什么?
1 低代码/无代码开发与软件工程领域的一些经典思想、方法和技术,例如软件复用与构件组装、软件产品线、DSL(领域特定语言)、可视化快速开发工具、可定制工作流,以及此前业界流行的中台等概念,之间是什么关系?
2 此外,低代码/无代码开发与DevOps、云计算与云原生架构之间又是什么样的关系?
1 支撑低代码/无代码开发的核心技术是什么?
2 低代码/无代码开发的火热是软件开发技术上的重要变革和突破,还是经典软件工程思想、方法和技术随着技术和业务积累的不断发展而焕发出的新生机?
1 低代码/无代码开发已经发展到什么程度?
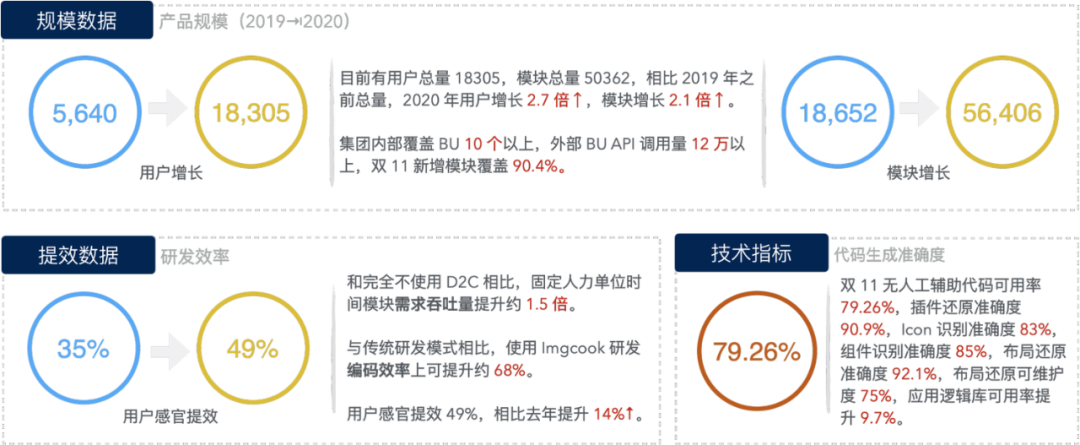
-
2w 多用户、6w 多模块、 0 前端参与研发的双十一等大促营销活动、70% 阿里前端在使用
-
79.26% 无人工参与的线上代码可用率、90.9% 的还原度、Icon 识别准确率 83%、组件识别 85%、布局还原度 92.1%、布局人工修改概率 75%
-
研发效率提升 68%
-
营销活动和大促场景 ui 智能生成比例超过 90%
-
日常频道导购业务 ui 智能生成覆盖核心业务
-
纯 ui 智能化和个性化带来的业务价值提升超过 8%
-
初步完成基于 NLP 的需求标注和理解系统
-
初步完成基于 NLP 的服务注册和理解系统
-
初步完成基于 NLP 的胶水层业务逻辑代码生成能力
-
针对资损防控自动化扫描、CV 和 AI 自动化识别资损风险和舆情问题
-
和测试同学共建的 UI 自动化测试、数据渲染和 Mock 驱动的业务自动化验证
-
和工程团队共建的 AI Codereview 基于对代码的分析和理解,结合线上 Runtime 的识别和分析,自动化发现问题、定位问题,提升 Codereview 的效率和质量
-
社区化运营开源项目,合并 Denfo.js 同其作者共同设立 Datacook 项目,全链路、端到端解决 AI 领域数据采集、存储、处理问题,尤其在海量数据、数据集组织、数据质量评估等深度学习和机器学习领域的能力比肩 HDF5、Pandas……等 Python 专业 LIbrary
-
Google Tensorflow.js 团队合作开发维护 TFData library ,作为 Datacook 的核心技术和基础,共同构建数据集生态和数据集易用性
-
开源了 pipcook[3] 纯前端机器学习框架
-
利用 Boa 打通 Python 技术生态,原生支持 import Python 流行的包和库,原生支持 Python 的数据类型和数据结构,方便跨语言共享数据和调用 API
-
利用 Pipcook Cloud 打通流行的云计算平台,帮助前端智能化实现 CDML,形成数据和算法工程闭环,帮助开发者打造工业级可用的服务和在线、离线算法能力
2 有哪些成熟的低代码/无代码开发平台?
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 低代码/无代码开发能够在多大程度上改变当前的软件开发方式?
1 低代码/无代码开发未来发展的方向是什么?
2 围绕低代码/无代码开发存在哪些技术难题需要学术界和工业界共同探索?
-
需求的识别:通过 NLP 、知识图谱、图神经网络、结构化机器学习……等 AI 技术,识别用户需求、产品需求、设计需求、运营需求、营销需求、研发需求、工程需求……等,识别出其中的概念和概念之间的关系
-
设计稿的识别:通过 CV、GAN、对象识别、语义分割……等 AI 技术,识别设计稿中的元素、元素之间的关系、设计语言、设计系统、设计意图
-
UI 的识别:通过用户用脚投票的结果进行回归,后验的分析识别出 UI 对用户行为的影响程度、影响效果、影响频率、影响时间……等,并识别出 UI 的可变性和这些用户行为影响之间的关系
-
计算机程序的识别:通过对代码、AST ……等 Raw Data 分析,借助 NLP 技术识别计算机程序中,语言的表达能力、语言的结构、语言中的逻辑、语言和外部系统通过 API 的交互等
-
日志和数据的识别:通过对日志和数据进行 NLP、回归、统计分析等方式,识别出程序的可用性、性能、易用性等指标情况,并识别出影响这些指标的日志和数据出自哪里,找出其间的关系
-
横向跨领域的理解:对识别出的概念进行降维,从而在底层更抽象的维度上找出不同领域之间概念的映射关系,从而实现用不同领域的概念进行类比,进而在某领域内理解其它领域的概念
-
纵向跨层次的理解:利用机器学习和深度学习的 AI 算法能力,放宽不同层次间概念的组成关系,对低层次概念实现跨层次的理解,进而形成更加丰富的技术、业务能力供给和使用机会
-
常识、通识的理解:以常识、通识构建的知识图谱为基础,将 AI 所面对的开放性问题领域化,将领域内的常识和通识当做理解的基础,不是臆测和猜想,而是实实在在构建在理论基础上的理解
-
个性化:借助大数据和算法实现用户和软件功能间的匹配,利用 AI 的生成能力降低千人前面的研发成本,从而真正实现个性化的软件服务能力,把软件即服务推向极致
-
共情:利用端智能在用户侧部署算法模型,既可以解决用户隐私保护的问题,又可以对用户不断变化的情绪、诉求、场景及时学习并及时做出响应,从而让软件从程序功能的角度急用户之所急、想用户之所想,与用户共情、让用户共鸣。举个例子:我用 iPhone 在进入地铁站的时候,因为现在要检查健康码,每次进入地铁站 iOS 都会给我推荐支付宝快捷方式,我不用自己去寻找支付宝打开展示健康码,这就让我感觉 iOS 很智能、很贴心,这就是共情。
相关链接
[1]https://juejin.cn/post/6844904116708196365
[2]https://juejin.cn/post/6844904104448393223
[3]https://github.com/alibaba/pipcook
[4]http://imgcook.com
免费领取电子书
《PostgreSQL实战教程》
PostgreSQL是世界上最流行的开源数据库之一,它以可靠性和稳定性而著称,在处理复杂SQL方面也表现出了绝对的优势,同时还具备许多高级功能。本书共7个章节,7位大咖从实战出发,带你从0到1了解PostgreSQL,快速掌握其核心架构及特色功能。


文章评论