前言:
在前端工程化日趋复杂的今天,模块打包工具在我们的开发中起到了越来越重要的作用,其中webpack就是最热门的打包工具之一。
说到webpack,可能很多小伙伴会觉得既熟悉又陌生,熟悉是因为几乎在每一个项目中我们都会用上它,又因为webpack复杂的配置和五花八门的功能感到陌生。尤其当我们使用诸如umi.js之类的应用框架还帮我们把webpack配置再封装一层的时候,webpack的本质似乎离我们更加遥远和深不可测了。
当面试官问你是否了解webpack的时候,或许你可以说出一串耳熟能详的webpack loader和plugin的名字,甚至还能说出插件和一系列配置做按需加载和打包优化,那你是否了解他的运行机制以及实现原理呢,那我们今天就一起探索webpack的能力边界,尝试了解webpack的一些实现流程和原理,拒做API工程师。
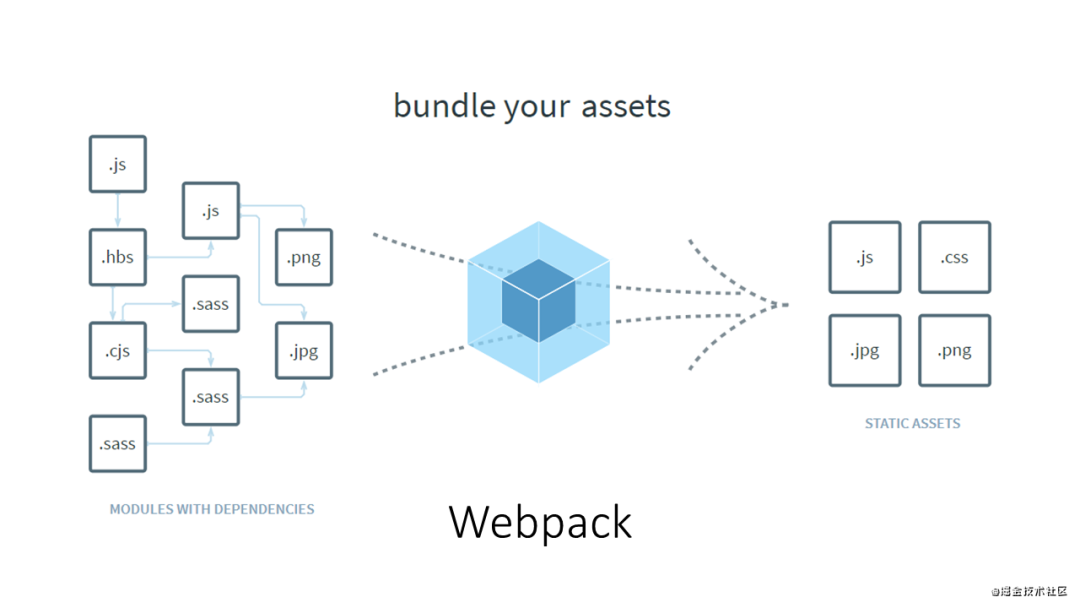
你知道webpack的作用是什么吗?
从官网上的描述我们其实不难理解,webpack的作用其实有以下几点:
-
模块打包。可以将不同模块的文件打包整合在一起,并且保证它们之间的引用正确,执行有序。利用打包我们就可以在开发的时候根据我们自己的业务自由划分文件模块,保证项目结构的清晰和可读性。
-
编译兼容。在前端的“上古时期”,手写一堆浏览器兼容代码一直是令前端工程师头皮发麻的事情,而在今天这个问题被大大的弱化了,通过
webpack的Loader机制,不仅仅可以帮助我们对代码做polyfill,还可以编译转换诸如.less, .vue, .jsx这类在浏览器无法识别的格式文件,让我们在开发的时候可以使用新特性和新语法做开发,提高开发效率。 -
能力扩展。通过
webpack的Plugin机制,我们在实现模块化打包和编译兼容的基础上,可以进一步实现诸如按需加载,代码压缩等一系列功能,帮助我们进一步提高自动化程度,工程效率以及打包输出的质量。
说一下模块打包运行原理?
如果面试官问你Webpack是如何把这些模块合并到一起,并且保证其正常工作的,你是否了解呢?
首先我们应该简单了解一下webpack的整个打包流程:
-
1、读取
webpack的配置参数; -
2、启动
webpack,创建Compiler对象并开始解析项目; -
3、从入口文件(
entry)开始解析,并且找到其导入的依赖模块,递归遍历分析,形成依赖关系树; -
4、对不同文件类型的依赖模块文件使用对应的
Loader进行编译,最终转为Javascript文件; -
5、整个过程中
webpack会通过发布订阅模式,向外抛出一些hooks,而webpack的插件即可通过监听这些关键的事件节点,执行插件任务进而达到干预输出结果的目的。
其中文件的解析与构建是一个比较复杂的过程,在webpack源码中主要依赖于compiler和compilation两个核心对象实现。
compiler对象是一个全局单例,他负责把控整个webpack打包的构建流程。 compilation对象是每一次构建的上下文对象,它包含了当次构建所需要的所有信息,每次热更新和重新构建,compiler都会重新生成一个新的compilation对象,负责此次更新的构建过程。
而每个模块间的依赖关系,则依赖于AST语法树。每个模块文件在通过Loader解析完成之后,会通过acorn库生成模块代码的AST语法树,通过语法树就可以分析这个模块是否还有依赖的模块,进而继续循环执行下一个模块的编译解析。
最终Webpack打包出来的bundle文件是一个IIFE的执行函数。
// webpack 5 打包的bundle文件内容 (() => { // webpackBootstrap var __webpack_modules__ = ({ 'file-A-path': ((modules) => { // ... }) 'index-file-path': ((__unused_webpack_module, __unused_webpack_exports, __webpack_require__) => { // ... }) }) // The module cache var __webpack_module_cache__ = {}; // The require function function __webpack_require__(moduleId) { // Check if module is in cache var cachedModule = __webpack_module_cache__[moduleId]; if (cachedModule !== undefined) { return cachedModule.exports; } // Create a new module (and put it into the cache) var module = __webpack_module_cache__[moduleId] = { // no module.id needed // no module.loaded needed exports: {} }; // Execute the module function __webpack_modules__[moduleId](module, module.exports, __webpack_require__); // Return the exports of the module return module.exports; } // startup // Load entry module and return exports // This entry module can't be inlined because the eval devtool is used. var __webpack_exports__ = __webpack_require__("./src/index.js"); }) 复制代码和webpack4相比,webpack5打包出来的bundle做了相当的精简。在上面的打包demo中,整个立即执行函数里边只有三个变量和一个函数方法,__webpack_modules__存放了编译后的各个文件模块的JS内容,__webpack_module_cache__ 用来做模块缓存,__webpack_require__是Webpack内部实现的一套依赖引入函数。最后一句则是代码运行的起点,从入口文件开始,启动整个项目。
其中值得一提的是__webpack_require__模块引入函数,我们在模块化开发的时候,通常会使用ES Module或者CommonJS规范导出/引入依赖模块,webpack打包编译的时候,会统一替换成自己的__webpack_require__来实现模块的引入和导出,从而实现模块缓存机制,以及抹平不同模块规范之间的一些差异性。
你知道sourceMap是什么吗?
提到sourceMap,很多小伙伴可能会立刻想到Webpack配置里边的devtool参数,以及对应的eval,eval-cheap-source-map等等可选值以及它们的含义。除了知道不同参数之间的区别以及性能上的差异外,我们也可以一起了解一下sourceMap的实现方式。
sourceMap是一项将编译、打包、压缩后的代码映射回源代码的技术,由于打包压缩后的代码并没有阅读性可言,一旦在开发中报错或者遇到问题,直接在混淆代码中debug问题会带来非常糟糕的体验,sourceMap可以帮助我们快速定位到源代码的位置,提高我们的开发效率。sourceMap其实并不是Webpack特有的功能,而是Webpack支持sourceMap,像JQuery也支持souceMap。
既然是一种源码的映射,那必然就需要有一份映射的文件,来标记混淆代码里对应的源码的位置,通常这份映射文件以.map结尾,里边的数据结构大概长这样:
{ "version" : 3, // Source Map版本 "file": "out.js", // 输出文件(可选) "sourceRoot": "", // 源文件根目录(可选) "sources": ["foo.js", "bar.js"], // 源文件列表 "sourcesContent": [null, null], // 源内容列表(可选,和源文件列表顺序一致) "names": ["src", "maps", "are", "fun"], // mappings使用的符号名称列表 "mappings": "A,AAAB;;ABCDE;" // 带有编码映射数据的字符串 } 复制代码其中mappings数据有如下规则:
-
生成文件中的一行的每个组用“;”分隔;
-
每一段用“,”分隔;
-
每个段由1、4或5个可变长度字段组成;
有了这份映射文件,我们只需要在我们的压缩代码的最末端加上这句注释,即可让sourceMap生效:
//# sourceURL=/path/to/file.js.map 复制代码有了这段注释后,浏览器就会通过sourceURL去获取这份映射文件,通过解释器解析后,实现源码和混淆代码之间的映射。因此sourceMap其实也是一项需要浏览器支持的技术。
如果我们仔细查看webpack打包出来的bundle文件,就可以发现在默认的development开发模式下,每个_webpack_modules__文件模块的代码最末端,都会加上//# sourceURL=webpack://file-path?,从而实现对sourceMap的支持。
是否写过Loader?简单描述一下编写loader的思路?
从上面的打包代码我们其实可以知道,Webpack最后打包出来的成果是一份Javascript代码,实际上在Webpack内部默认也只能够处理JS模块代码,在打包过程中,会默认把所有遇到的文件都当作 JavaScript代码进行解析,因此当项目存在非JS类型文件时,我们需要先对其进行必要的转换,才能继续执行打包任务,这也是Loader机制存在的意义。
Loader的配置使用我们应该已经非常的熟悉:
// webpack.config.js module.exports = { // ...other config module: { rules: [ { test: /^your-regExp$/, use: [ { loader: 'loader-name-A', }, { loader: 'loader-name-B', } ] }, ] } } 复制代码通过配置可以看出,针对每个文件类型,loader是支持以数组的形式配置多个的,因此当Webpack在转换该文件类型的时候,会按顺序链式调用每一个loader,前一个loader返回的内容会作为下一个loader的入参。因此loader的开发需要遵循一些规范,比如返回值必须是标准的JS代码字符串,以保证下一个loader能够正常工作,同时在开发上需要严格遵循“单一职责”,只关心loader的输出以及对应的输出。
loader函数中的this上下文由webpack提供,可以通过this对象提供的相关属性,获取当前loader需要的各种信息数据,事实上,这个this指向了一个叫loaderContext的loader-runner特有对象。有兴趣的小伙伴可以自行阅读源码。
module.exports = function(source) { const content = doSomeThing2JsString(source); // 如果 loader 配置了 options 对象,那么this.query将指向 options const options = this.query; // 可以用作解析其他模块路径的上下文 console.log('this.context'); /* * this.callback 参数: * error:Error | null,当 loader 出错时向外抛出一个 error * content:String | Buffer,经过 loader 编译后需要导出的内容 * sourceMap:为方便调试生成的编译后内容的 source map * ast:本次编译生成的 AST 静态语法树,之后执行的 loader 可以直接使用这个 AST,进而省去重复生成 AST 的过程 */ this.callback(null, content); // or return content; } 复制代码更详细的开发文档可以直接查看官网的 Loader API[1]。
是否写过Plugin?简单描述一下编写plugin的思路?
如果说Loader负责文件转换,那么Plugin便是负责功能扩展。Loader和Plugin作为Webpack的两个重要组成部分,承担着两部分不同的职责。
上文已经说过,webpack基于发布订阅模式,在运行的生命周期中会广播出许多事件,插件通过监听这些事件,就可以在特定的阶段执行自己的插件任务,从而实现自己想要的功能。
既然基于发布订阅模式,那么知道Webpack到底提供了哪些事件钩子供插件开发者使用是非常重要的,上文提到过compiler和compilation是Webpack两个非常核心的对象,其中compiler暴露了和 Webpack整个生命周期相关的钩子(compiler-hooks[2]),而compilation则暴露了与模块和依赖有关的粒度更小的事件钩子(Compilation Hooks[3])。
Webpack的事件机制基于webpack自己实现的一套Tapable事件流方案(github[4])
// Tapable的简单使用 const { SyncHook } = require("tapable"); class Car { constructor() { // 在this.hooks中定义所有的钩子事件 this.hooks = { accelerate: new SyncHook(["newSpeed"]), brake: new SyncHook(), calculateRoutes: new AsyncParallelHook(["source", "target", "routesList"]) }; } /* ... */ } const myCar = new Car(); // 通过调用tap方法即可增加一个消费者,订阅对应的钩子事件了 myCar.hooks.brake.tap("WarningLampPlugin", () => warningLamp.on()); 复制代码Plugin的开发和开发Loader一样,需要遵循一些开发上的规范和原则:
-
插件必须是一个函数或者是一个包含
apply方法的对象,这样才能访问compiler实例; -
传给每个插件的
compiler和compilation对象都是同一个引用,若在一个插件中修改了它们身上的属性,会影响后面的插件; -
异步的事件需要在插件处理完任务时调用回调函数通知
Webpack进入下一个流程,不然会卡住;
了解了以上这些内容,想要开发一个 Webpack Plugin,其实也并不困难。
class MyPlugin { apply (compiler) { // 找到合适的事件钩子,实现自己的插件功能 compiler.hooks.emit.tap('MyPlugin', compilation => { // compilation: 当前打包构建流程的上下文 console.log(compilation); // do something... }) } } 复制代码更详细的开发文档可以直接查看官网的 Plugin API[5]。
最后
本文也是结合一些优秀的文章和webpack本身的源码,大概地说了几个相对重要的概念和流程,其中的实现细节和设计思路还需要结合源码去阅读和慢慢理解。
Webpack作为一款优秀的打包工具,它改变了传统前端的开发模式,是现代化前端开发的基石。这样一个优秀的开源项目有许多优秀的设计思想和理念可以借鉴,我们自然也不应该仅仅停留在API的使用层面,尝试带着问题阅读源码,理解实现的流程和原理,也能让我们学到更多知识,理解得更加深刻,在项目中才能游刃有余的应用。
作者:希沃ENOW大前端
链接:https://juejin.cn/post/6943468761575849992
感谢大家
1.看到这里了就点个在看支持下吧,您的「点赞,在看」是我创作的动力。
2.“关注”公众号前端热点分析,回复「前端架构设计」将限时领取书籍一份,每天只限10份,已累计领取超过39000份,好评率超过98%。
“在看转发”是最大的支持

文章评论